







代码:https://github.com/NandaYanxr/RLtutorial/tree/main/FrozenLakeTest
youtube大佬的详细讲解:https://www.youtube.com/watch?v=1W_LOB-0IEY
=================================================================
1. install library: gymnasium; pygame
2. Q-learning
原理:
3. 贪心策略 
探索与利用;epsilon指的是选择探索的改了吧,大部分时候探索的机会很小。
#伪代码
p=random()
if p<epsilon
pull random action
else
pull current-best action一般还会让epsilon随时间衰减。
4.在Frozen Lake上实验
Frozen Lake游戏的设定是有slippery (有滑动,即env.step(action)不一定是指的前面选出来的action,有一定概率是其他的方向)和 not slippery(不滑动,即env.step(action)就是指的前面选出来的action,类似于deterministic policy),
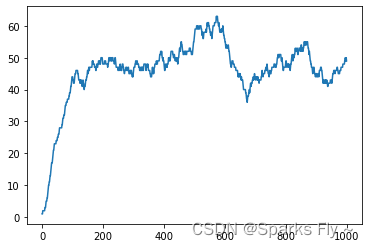
(1)先试验无滑动的情况:is_slippery=False;
main函数线运行15000 次
run(15000)
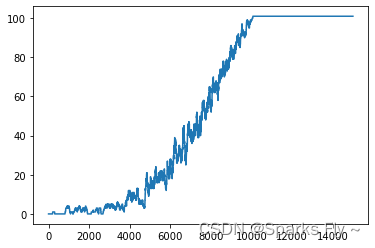
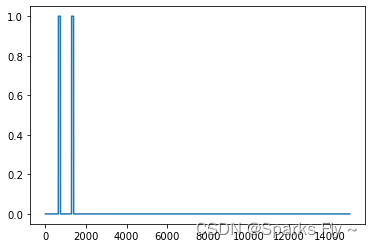
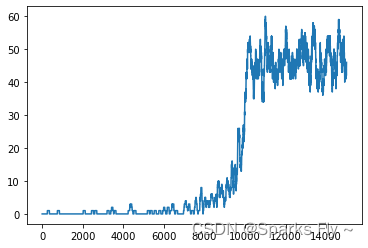
图如下,根据小人的状态有不同的情况:(图表示每100个episode的累计奖励)

然后打开仿真环境看看小人怎么跑的
run(1,is_training=false,render=true)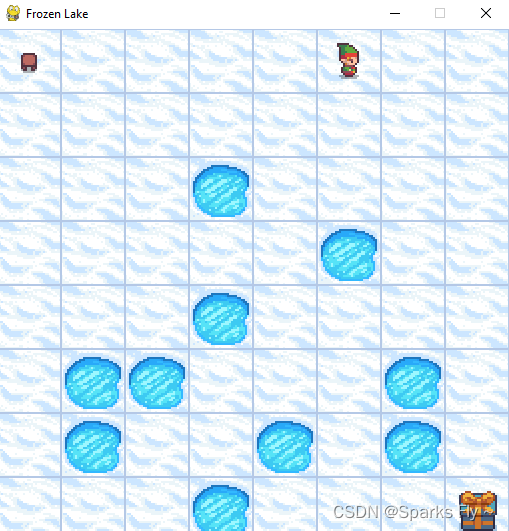
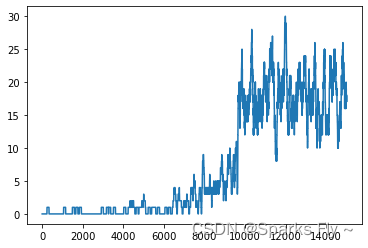
(2)测试考虑滑动的情况
可以看到明显的reward变低了,因为有一定的随机性















 2230
2230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









