







监督式学习算法基础
2.1监督式学习的基本概念
2.1.1 基本概念解释
特征组:将每个对象的 n n n个特征构成的向量 x = ( x 1 , x 2 , . . . , x n ) ∈ R n x=(x_1,x_2,...,x_n)\in\mathbb{R^n} x=(x1,x2,...,xn)∈Rn称为该对象的特征组,设 X ⊆ R n X\subseteq\mathbb{R^n} X⊆Rn是特征组的所有可能取值构成的集合,称 X X X为样本空间
标签:在回归问题中,训练数据含有一个数值标签 y ∈ R y\in\mathbb{R} y∈R;在 k k k元分类问题中,训练数据含有一个向量标签 y ∈ [ 0 , 1 ] k y\in[0,1]^k y∈[0,1]k。设 Y Y Y为全体可能的取值,称 Y Y Y为标签空间
特征分布:
标签分布:
举例说明:特征
X
X
X(就是变量)是在
[
−
1
,
1
]
[-1,1]
[−1,1]服从均匀分布,标签
y
y
y服从分布
N
(
x
,
0.1
)
N(x,0.1)
N(x,0.1)的正态分布。
记均匀分布为
D
D
D,称
D
D
D为特征分布,用
x
∼
D
x\sim D
x∼D表示
x
x
x为依特征分布
D
D
D的一个随机采样
x
x
x对应的标签
y
y
y服从
D
x
D_x
Dx,称
D
x
D_x
Dx为特征组
x
x
x的标签分布,用
y
∼
D
x
y\sim D_x
y∼Dx表示
y
y
y为依
D
x
D_x
Dx的标签分布
eg.
x
=
1
x=1
x=1时
y
y
y的标签分布为
N
(
1
,
0.1
)
N(1,0.1)
N(1,0.1)
2.1.2损失函数举例
损失函数:设
Y
Y
Y为标签分布。损失函数时一个从
Y
×
Y
Y\times Y
Y×Y映射到正实数的函数
l
:
Y
×
Y
→
R
+
l:Y\times Y\to \mathbb{R^+}
l:Y×Y→R+,并且要求其具有如下性质:对任意
y
∈
Y
y\in Y
y∈Y,有
l
(
y
,
y
)
=
0
l(y,y)=0
l(y,y)=0
eg. 0-1损失函数
l
(
y
,
z
)
=
{
0
如
果
z
=
y
1
如
果
z
≠
y
l(y,z) = \begin{cases} 0 & 如果z=y \\ 1 & 如果z\ne y \\ \end{cases}
l(y,z)={01如果z=y如果z=y
eg. 平方损失函数
l
(
y
,
z
)
=
(
y
−
z
)
2
l(y,z)=(y-z)^2
l(y,z)=(y−z)2
损失函数就是用来计算模型误差,以此来输出优化模型
2.2经验损失最小化架构
训练数据与经验损失:给定损失函数
l
l
l以及一组数据
S
=
{
(
x
(
1
)
,
y
(
1
)
)
,
(
x
(
2
)
,
y
(
2
)
)
,
.
.
.
,
(
x
(
m
)
,
y
(
m
)
)
}
S=\{(x^{(1) },y^{(1)}),(x^{(2) },y^{(2)}),...,(x^{(m) },y^{(m)}) \}
S={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
其中,
x
(
1
)
,
x
(
2
)
,
.
.
.
,
x
(
m
)
∼
D
x^{(1)},x^{(2)},...,x^{(m)}\sim D
x(1),x(2),...,x(m)∼D为
X
X
X中
m
m
m个依特征分布
D
D
D的独立采样,并且对任意
1
≤
i
≤
m
1\leq i\leq m
1≤i≤m有
y
(
i
)
∼
D
x
(
i
)
y^{(i)}\sim D_x^{(i)}
y(i)∼Dx(i)。将
S
S
S称为训练数据。将
h
h
h在
S
S
S中所有数据的平均损失为
h
h
h的经验损失,用如下记号表示
L
S
(
h
)
=
1
m
∑
i
=
1
m
l
(
h
(
x
(
i
)
)
,
y
(
i
)
)
L_S(h)=\frac{1}{m} \sum_{i=1}^ml(h(x^{(i)}), y^{(i)})
LS(h)=m1i=1∑ml(h(x(i)),y(i))
当训练数据的规模足够大时,Hoeffding不等式保证了经验损失能够良好地近似期望损失。
Hoeffding不等式个人理解就是在样本足够大时误差可以足够小
2.2.1无约束经验损失最小化算法架构
无约束经验损失最小化算法架构
给定样本空间 X X X、标签空间 Y Y Y、模型空间 ϕ \phi ϕ和损失函数 l : Y × Y → R + l:Y\times Y\to \mathbb{R^+} l:Y×Y→R+
输入: m m m条训练数据 S = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } S=\{(x^{(1) },y^{(1)}),(x^{(2) },y^{(2)}),...,(x^{(m) },y^{(m)}) \} S={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
输出模型: h S = a r g m i n h ∈ ϕ L S ( h ) h_S=\underset{h\in \phi}{argmin}L_S(h) hS=h∈ϕargminLS(h)
无约束经验损失最小化算法的特点在于它精确的拟合了训练数据。实际上可以应用拉格朗日插值法构造一个多项式 h S ( x ) h_S(x) hS(x),使经验损失 L S ( h ) = 0 L_S(h)=0 LS(h)=0。但是这就引出了机器学习中常发生的问题——过度拟合。
下面举例直观感受过度拟合
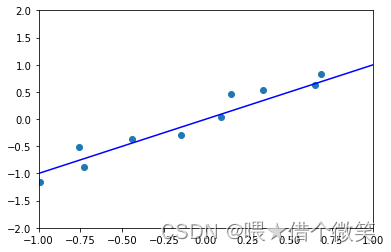
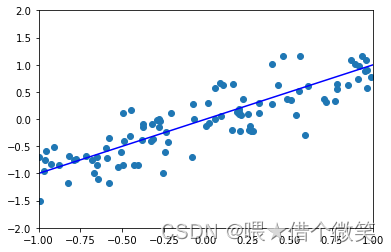
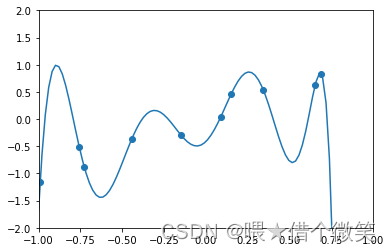
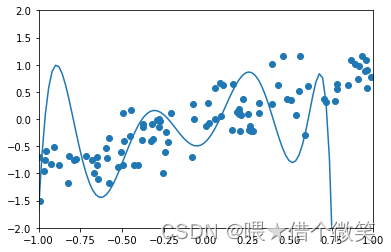
容易看出过下面的模型出现了过度拟合。
由此引出概念——模型假设通过对训练数据的观察以及对背景的理解,可以对模型做出合理假设,从而降低过拟合。
2.2.2带模型假设的经验损失最小化算法架构
模型假设:模型空间
ϕ
\phi
ϕ的任意一个子集
H
H
H都称为一个模型假设。
一个带有模型假设的经验损失最小化算法的任务是计算在假定的模型假设中的经验损失最小的那个模型
带模型假设的经验损失最小化算法架构
给定样本空间 X X X、标签空间 Y Y Y、模型空间 ϕ \phi ϕ和损失函数 l : Y × Y → R + l:Y\times Y\to \mathbb{R^+} l:Y×Y→R+
取定模型假设 H H H
输入: m m m条训练数据 S = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } S=\{(x^{(1) },y^{(1)}),(x^{(2) },y^{(2)}),...,(x^{(m) },y^{(m)}) \} S={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
输出模型: h S = a r g m i n h ∈ ϕ L S ( h ) h_S={argmin}_{h\in \phi}L_S(h) hS=argminh∈ϕLS(h)
2.3监督式学习与经验损失最小化实例
2.3.1鸢尾花实例
鸢尾花数据集,数据集包含150个样本,分属于3个鸢尾花种:山鸢尾、变色鸢尾以及弗吉尼亚鸢尾。
5个鸢尾花数据集的样本
| 花萼长 | 花萼宽 | 花瓣长 | 花瓣宽 | 属种 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 山鸢尾 |
| 7.0 | 3.2 | 4.7 | 1.4 | 变色鸢尾 |
| 4.8 | 3.0 | 1.4 | 0.3 | 山鸢尾 |
| 6.4 | 2.8 | 5.6 | 2.1 | 弗吉尼亚鸢尾 |
| 6.2 | 3.0 | 4.9 | 1.8 | 弗吉尼亚鸢尾 |
区分山鸢尾和非山鸢尾
横坐标花萼长,纵坐标花萼宽
蓝色 山鸢尾+1,黄色非山鸢尾-1
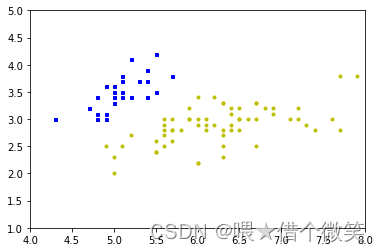
2.3.2感知器算法
假定一条直线有如下方程:
<
w
,
x
>
+
b
=
0
<w,x>+b=0
<w,x>+b=0。
对平面上的一个点
x
∗
=
(
x
1
∗
,
x
2
∗
)
x^*=(x_1^*,x_2^*)
x∗=(x1∗,x2∗),
如果它位于直线上方,则
<
w
,
x
∗
>
+
b
>
0
<w,x^*>+b>0
<w,x∗>+b>0;
如果它位于直线下方,则
<
w
,
x
∗
>
+
b
<
0
<w,x^*>+b<0
<w,x∗>+b<0;
如果它恰巧位于直线上,则
<
w
,
x
∗
>
+
b
=
0
<w,x^*>+b=0
<w,x∗>+b=0。
若
<
w
,
x
∗
>
+
b
=
0
<w,x^*>+b=0
<w,x∗>+b=0的直线能够分离训练数据中的正负采样,
则它一定满足如下条件:
y
(
i
)
=
S
i
g
n
(
<
w
,
x
(
i
)
>
+
b
)
,
i
=
1
,
2
,
.
.
.
,
m
y^{(i)}=Sign(<w,x^{(i)}>+b),i=1,2,...,m
y(i)=Sign(<w,x(i)>+b),i=1,2,...,m
这里的
y
(
i
)
y^{(i)}
y(i)就是样本的标签
其中
S
i
g
n
Sign
Sign是如下符号函数:
S
i
g
n
(
z
)
=
{
−
1
如
果
z
<
0
0
如
果
z
=
y
+
1
如
果
z
>
0
Sign(z) = \begin{cases} -1 & 如果z<0 \\ 0 & 如果z= y \\ +1 & 如果z>0 \end{cases}
Sign(z)=⎩⎪⎨⎪⎧−10+1如果z<0如果z=y如果z>0
作出假设:取定
w
=
(
w
1
,
w
2
)
∈
R
2
w=(w_1,w_2)\in \mathbb{R^2}
w=(w1,w2)∈R2以及
b
∈
R
b\in \mathbb{R}
b∈R
h
w
,
b
=
S
i
g
n
(
<
w
,
x
>
+
b
)
h_{w,b}=Sign(<w,x>+b)
hw,b=Sign(<w,x>+b)
并定义模型假设
H
=
{
h
w
,
x
:
w
∈
R
2
,
b
∈
R
2
}
H=\{h_{w,x}:w\in \mathbb{R^2},b\in \mathbb{R^2}\}
H={hw,x:w∈R2,b∈R2}
采用0-1损失函数,有如下形式:
l
(
h
w
,
x
(
x
(
i
)
)
,
y
(
i
)
)
=
1
−
y
(
i
)
S
i
g
n
(
<
w
,
x
(
i
)
>
+
b
)
2
l(h_{w,x}(x^{(i)}),y^{(i)})=\frac{1-y^{(i)}Sign(<w,x^{(i)}>+b)}{2}
l(hw,x(x(i)),y(i))=21−y(i)Sign(<w,x(i)>+b)
可见经验损失最小化算法的目标应当为:
经验损失最小化算法的目标就是使经验损失函数最小,误差最小
m
i
n
w
,
b
1
m
∑
i
=
1
m
1
−
y
(
i
)
S
i
g
n
(
<
w
,
x
(
i
)
>
+
b
)
2
\underset{w,b}{min}\frac{1}{m}\sum_{i=1}^m\frac{1-y^{(i)}Sign(<w,x^{(i)}>+b)}{2}
w,bminm1i=1∑m21−y(i)Sign(<w,x(i)>+b)
上式经过简单整理,就等价于如下优化问题:
m a x w , b 1 m ∑ i = 1 m y ( i ) S i g n ( < w , x ( i ) > + b ) \underset{w,b}{max}\frac{1}{m}\sum_{i=1}^my^{(i)}Sign(<w,x^{(i)}>+b) w,bmaxm1i=1∑my(i)Sign(<w,x(i)>+b)
y ( i ) y^{(i)} y(i)是符号函数 S i g n Sign Sign的取值 +1,-1,确切来说是样本的标签,样本本身自带的数据
分离后正采样点应位于直线上方,负采样点位于直线下方
如果存在位于直线下方的正采样点感知器算法将感知空间中的点并朝着这个点旋转,直至该点位于直线上方,在解析几何中,为了使直线
y
=
<
w
,
x
>
+
1
y=<w,x>+1
y=<w,x>+1朝着点
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)},y^{(i)})
(x(i),y(i))转动,可以采用如下方法:
w
←
w
+
y
(
i
)
x
(
i
)
b
←
b
+
y
(
i
)
w\gets w+y^{(i)}x^{(i)}\\ b\gets b+y^{(i)}
w←w+y(i)x(i)b←b+y(i)
感知器算法
w w w=(0,0),b=0,done=False
while not done:
done = True
for i=1,2,…,m
if y ( i ) S i g n ( < w , x ( i ) > + b ) ≤ 0 y^{(i)}Sign(<w,x^{(i)}>+b)\leq0 y(i)Sign(<w,x(i)>+b)≤0:
w ← w + y ( i ) x ( i ) w\gets w+y^{(i)}x^{(i)} w←w+y(i)x(i)
b ← b + y ( i ) b\gets b+y^{(i)} b←b+y(i)
done = False
return w , b w,b w,b
2.3.3感知器算法实现山鸢尾花分类

下图为预测
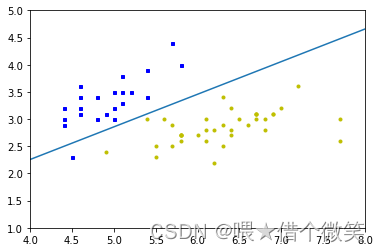
2.4正则化算法
奥卡姆剃刀法则:如无必要,勿增实体
n
n
n元
d
d
d次多项式可以用
(
n
+
d
n
)
\begin{pmatrix}n+d \\ n\\ \end{pmatrix}
(n+dn)个实参数
{
w
a
1
,
a
2
,
.
.
.
,
a
n
:
a
1
,
a
2
,
.
.
.
,
a
n
∈
z
≥
0
,
a
1
+
a
2
+
.
.
.
+
a
n
≤
d
}
\{w_{a_1,a_2,...,a_n}:a_1,a_2,...,a_n\in \mathbb{z}_{\ge 0},a_1+a_2+...+a_n \leq d \}
{wa1,a2,...,an:a1,a2,...,an∈z≥0,a1+a2+...+an≤d}表示。证明方法类似与高中排列组合中学过的隔板法
L
1
L_1
L1范数
∣
w
∣
\begin{vmatrix}w\end{vmatrix}
∣∣w∣∣定义为:
∣
w
∣
=
∣
w
1
∣
+
∣
w
2
∣
+
.
.
.
+
∣
w
n
∣
\begin{vmatrix}w \end{vmatrix}=\begin{vmatrix}w_1 \end{vmatrix}+\begin{vmatrix}w_2 \end{vmatrix}+...+\begin{vmatrix}w_n \end{vmatrix}
∣∣w∣∣=∣∣w1∣∣+∣∣w2∣∣+...+∣∣wn∣∣
L
2
L_2
L2范数
∥
w
∥
\begin{Vmatrix}w\end{Vmatrix}
∥∥w∥∥定义为:
∥
w
∥
=
w
1
2
+
w
2
2
+
.
.
.
+
w
n
2
\begin{Vmatrix}w\end{Vmatrix}=\sqrt{w_1^2+w_2^2+...+w_n^2}
∥∥w∥∥=w12+w22+...+wn2
机器学习中普遍认为范数
w
w
w越小,模型就越简单
2.4.1 L 1 L_1 L1正则化
L 1 L_1 L1正则化经验损失最小化算法
参数化模型假设 H = { H w : w ∈ R n } H=\{H_w:w\in \mathbb{R^n}\} H={Hw:w∈Rn}
输入: m m m条训练数据 S = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } S=\{(x^{(1) },y^{(1)}),(x^{(2) },y^{(2)}),...,(x^{(m) },y^{(m)}) \} S={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
计算优化问题模型 w ∗ w^* w∗:
m i n w ∈ R n L S ( h w ) + λ ∣ w ∣ \underset{w\in \mathbb{R^n}}{min}L_S(h_w)+\lambda \begin{vmatrix}w\end{vmatrix} w∈RnminLS(hw)+λ∣∣w∣∣
输出:模型 h w ∗ h_w^* hw∗
2.4.2 L 2 L_2 L2正则化
由于 L 1 L_1 L1范数求解的目标函数不可微,因此使用 L 2 L_2 L2正则化(L1正则化的求解可以使用搜索算法中的随机梯度下降算法求解)
L 2 L_2 L2正则化经验损失最小化算法
参数化模型假设 H = { H w : w ∈ R n } H=\{H_w:w\in \mathbb{R^n}\} H={Hw:w∈Rn}
输入: m m m条训练数据 S = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } S=\{(x^{(1) },y^{(1)}),(x^{(2) },y^{(2)}),...,(x^{(m) },y^{(m)}) \} S={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
计算优化问题模型 w ∗ w^* w∗:
m i n w ∈ R n L S ( h w ) + λ ∥ w ∥ 2 \underset{w\in \mathbb{R^n}}{min}L_S(h_w)+\lambda\begin{Vmatrix}w\end{Vmatrix}^2 w∈RnminLS(hw)+λ∥∥w∥∥2
输出:模型 h w ∗ h_w^* hw∗
2.4.1 L 1 , L 2 L_1,L_2 L1,L2正则化解释
正则化算法就是在原来的线性模型中,加入一个惩罚项,引导算法在
L
S
L_S
LS接近的情况下选出范数较小的那个(大道至简)
L
1
L_1
L1引导算法参数逐个将为0
m
i
n
L
S
(
h
w
)
约
束
:
∣
w
∣
≤
R
minL_S(h_w)\\ 约束:\begin{vmatrix}w\end{vmatrix}\leq R
minLS(hw)约束:∣∣w∣∣≤R
模型的约束区间为多面体
L
2
L_2
L2 正则化均匀的降低多项式的系数,输出越来越平滑的模型
m
i
n
L
S
(
h
w
)
约
束
:
∥
w
∥
2
≤
R
2
minL_S(h_w)\\ 约束:\begin{Vmatrix}w\end{Vmatrix}^2\leq R^2
minLS(hw)约束:∥∥w∥∥2≤R2
约束区间为圆、球…
代码
'''鸢尾花'''
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from perceptron import Perceptron
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X= iris["data"][:,(0,1)]
y = 2 * (iris["target"]==0).astype(np.int) - 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=3)
plt.figure(1)
plt.axis([4,8,1,5])
plt.plot(X_train[:, 0][y_train==1], X_train[:, 1][y_train==1], "bs", ms=3)
plt.plot(X_train[:, 0][y_train==-1], X_train[:, 1][y_train==-1], "yo", ms=3)
model = Perceptron()
model.fit(X_train, y_train)
plt.figure(2)
plt.axis([4,8,1,5])
plt.plot(X_train[:, 0][y_train==1], X_train[:, 1][y_train==1]+0.1, "bs", ms=3)
plt.plot(X_train[:, 0][y_train==-1], X_train[:, 1][y_train==-1]-0.1, "yo", ms=3)
x0 = np.linspace(4, 8, 200)
w = model.w
b = model.b
line = -w[0]/w[1] * x0 - b/w[1]
plt.plot(x0, line)
plt.figure(3)
plt.axis([4,8,1,5])
plt.plot(X_test[:, 0][y_test==1], X_test[:, 1][y_test==1], "bs", ms=3)
plt.plot(X_test[:, 0][y_test==-1], X_test[:, 1][y_test==-1], "yo", ms=3)
x0 = np.linspace(4, 8, 200)
line = -w[0]/w[1] * x0 - b/w[1]
plt.plot(x0, line)















 4501
4501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











