






原理理解
HashMap 是用数组+链表/红黑树实现的,我们要想往 HashMap 中添加数据(元素/键值对)或者取数据,就需要确定数据在数组中的下标(索引)。
先把数据的键进行一次 hash:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}再做一次取模运算确定下标:
i = (n - 1) & hash
那这样的过程容易产生两个问题:
- 数组的容量过小,经过哈希计算后的下标,容易出现冲突;
- 数组的容量过大,导致空间利用率不高。
加载因子是用来表示 HashMap 中数据的填满程度:
加载因子 = 填入哈希表中的数据个数 / 哈希表的长度
这就意味着:
- 加载因子越小,填满的数据就越少,哈希冲突的几率就减少了,但浪费了空间,而且还会提高扩容的触发几率;
- 加载因子越大,填满的数据就越多,空间利用率就高,但哈希冲突的几率就变大了。
- 这就必须在“哈希冲突”与“空间利用率”两者之间有所取舍
为什么加载因子会选择 0.75 呢?为什么不是 0.8、0.6 呢?
在介绍这个问题之前,首先阐述一下二项分布的概念:
在概率论和统计学中,二项分布是n个独立的成功/失败试验中成功的次数的离散概率分布,其中每次试验的成功概率为p。n次试验中正好得到k次成功的概率由概率质量函数给出:![]()
以此理论为基础:我们往哈希表中扔数据,如果发生哈希冲突就为失败,否则为成功。
我们的目的是往长度为s的哈希表中仍n次数据,发生哈希冲突的为0的概率尽可能大些。
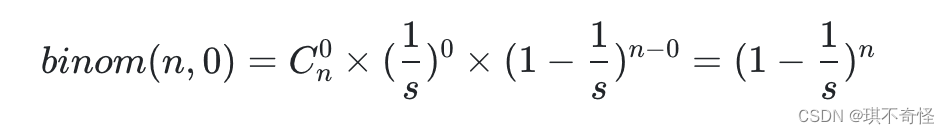
这个概率值需要大于 0.5,我们认为这样的 hashmap 可以提供很低的碰撞率。
负载因子就是n/s。(当哈希表长度为s的时候,填充n次数据就可以进行扩容了)

求得负载因为的值
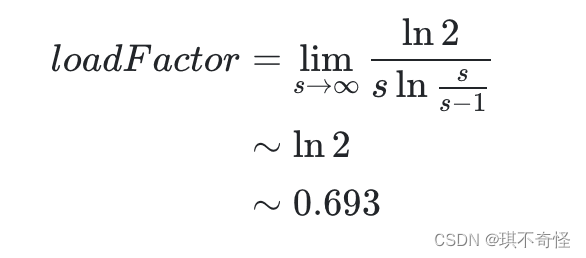
考虑到 HashMap 的容量有一个要求:它必须是 2 的 n 次幂。当加载因子选择了 0.75 就可以保证它与容量的乘积为整数。
除了 0.75,0.5~1 之间还有 0.625(5/8)、0.875(7/8)可选,从中位数的角度,挑 0.75 比较完美。另外,维基百科上说,拉链法(解决哈希冲突的一种)的加载因子最好限制在 0.7-0.8 以下,超过 0.8,查表时的 CPU 缓存不命中(cache missing)会按照指数曲线上升。
综上,0.75 是个比较完美的选择。
面试时候回答
HashMap的负载因子决定元素个数达到多少时候扩容。
假如我们设的比较大,元素比较多,空位比较少的时候才扩容,那么发生哈希冲突的概率就增加了,查找的时间成本就增加了。
我们设的比较小的话,元素比较少,空位比较多的时候就扩容了,发生哈希碰撞的概率就降低了,查找时间成本降低,但是就需要更多的空间去存储元素,空间成本就增加了。
选择 0.75 这个值是为了在时间和空间成本之间达到一个较好的平衡点,既可以保证哈希表的性能表现,又能够充分利用空间。

















 1826
1826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









