







 本节介绍了如何在数据分析中进行数据文件的合并,包括添加个案和变量,以及处理不匹配的变量。接着讲解了数据排秩的概念,即个案等级排序,并展示了如何根据变量进行分组和处理相同观测值的结。最后,阐述了个案加权的重要性,说明了如何在统计分析中为不同个案分配权重,并通过列联表展示加权效果。
本节介绍了如何在数据分析中进行数据文件的合并,包括添加个案和变量,以及处理不匹配的变量。接着讲解了数据排秩的概念,即个案等级排序,并展示了如何根据变量进行分组和处理相同观测值的结。最后,阐述了个案加权的重要性,说明了如何在统计分析中为不同个案分配权重,并通过列联表展示加权效果。
- 第七节 数据文件的合并
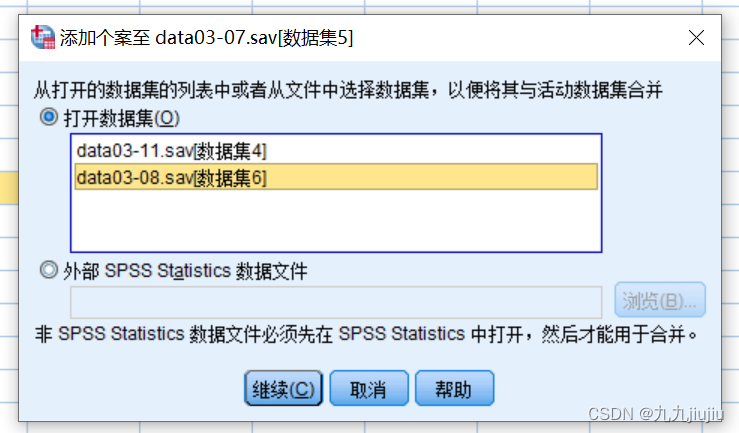
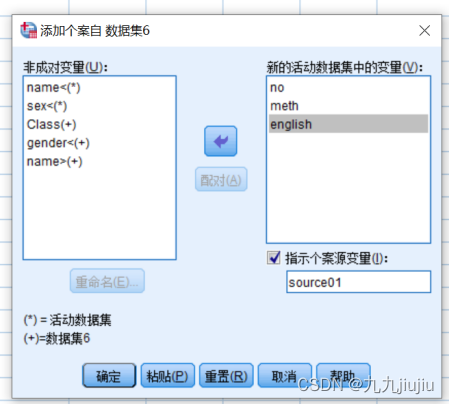
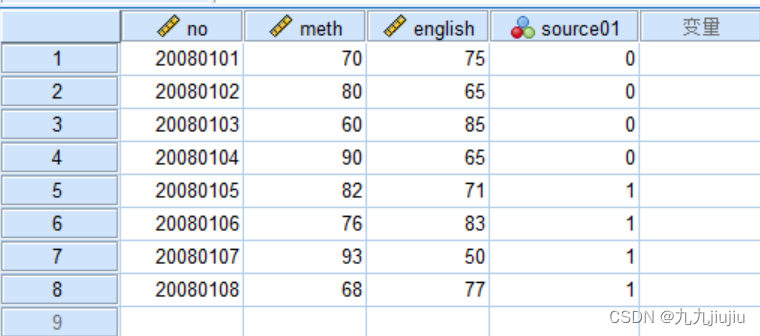
首先选择菜单“数据”-“合并文件”-“添加个案”,在弹出的对话框中选择要合并的数据集。各选项含义如下:“非成对变量”:显示两个变量中不匹配的变量名;“新的活动数据集中的变量”:显示合并后的新数据集包含的变量;“将个案源表示为变量”:表示合并后的数据集生成一个新变量,用来表示个案的来源;“配对”:匹配两个数据文件中变量名不同、数据含义和属性相同的变量。
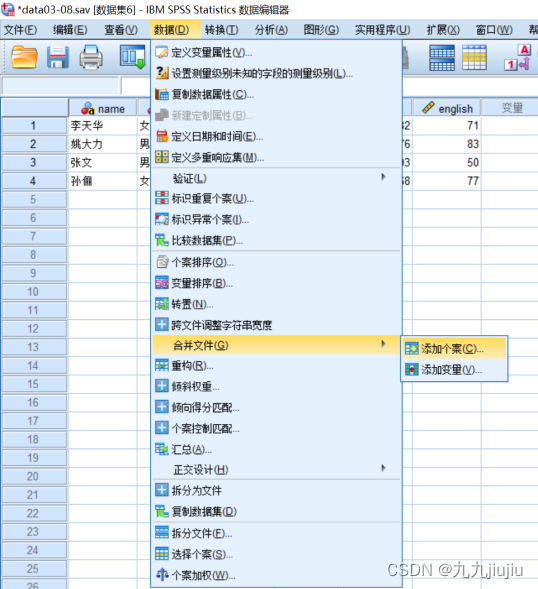
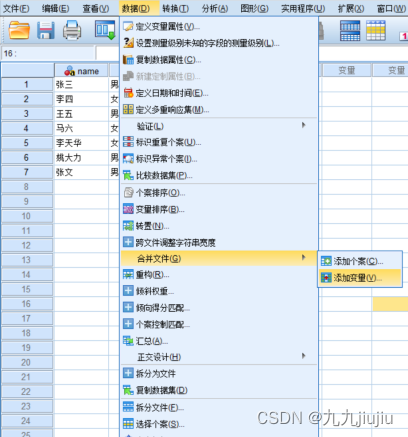
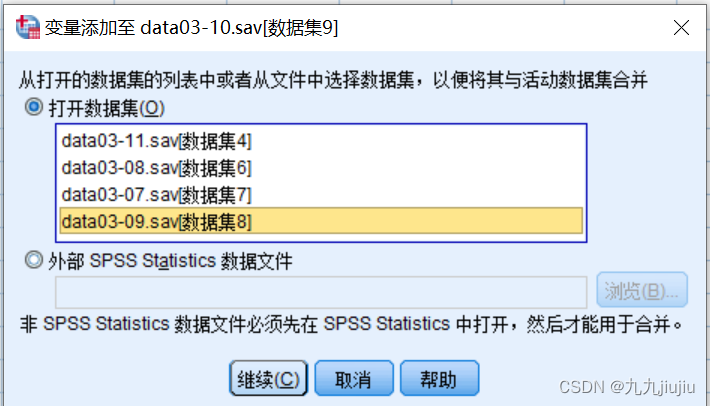
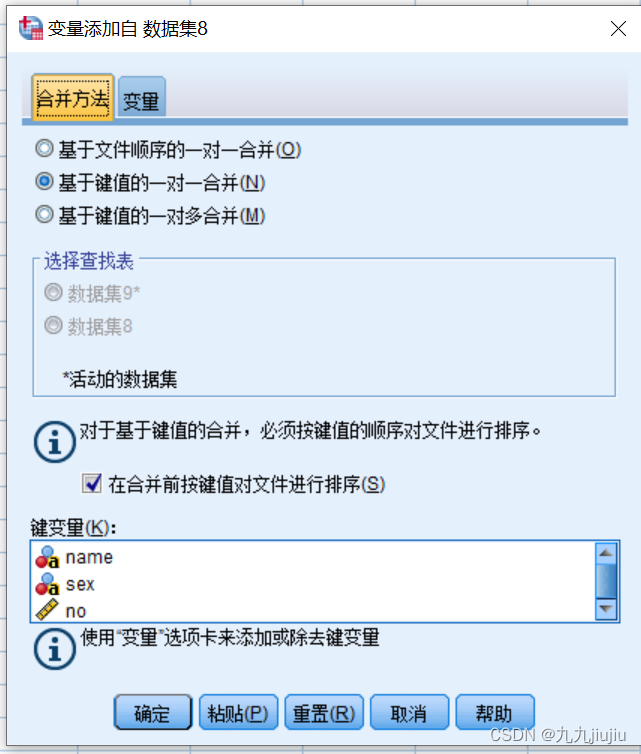
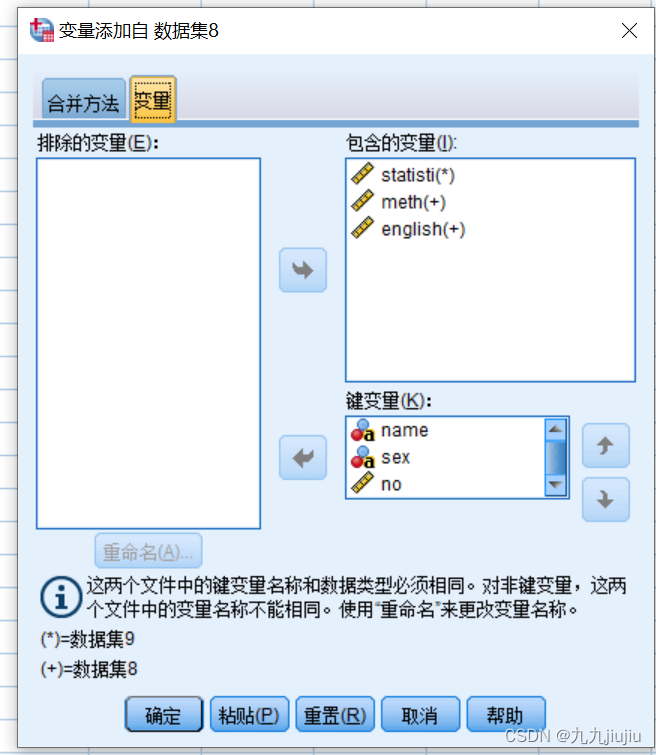
首先选择菜单“数据”-“合并文件”-“添加变量”,在弹出的对话框中选择要合并的数据集。“排除的变量”显示的是出现的在两个初始文件中但不出现在合并后文件里的变量;“键变量”显示标识和匹配不同文件的变量,但需要先进行排列。
第八节 数据排秩
“秩”理解为级别或等级。数据排秩也称为个案等级排序,是将个案排序结果生成一个新变量,新变量的取值即排序后的顺序号
“结”是某一变量的观测值按升序排列后,数值相等的一组值称为一个结。例如:“1.00,2.50,2.60,2.60,2.60,2.60,3.50,4.50”这一列中的3-6的观测值“2.60,2.60,2.60,2.60”是一个结。具体操作步骤如下:
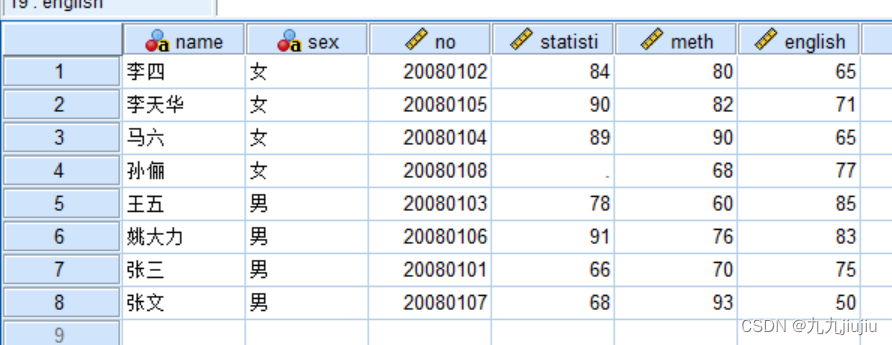
下图是一张数据表,点击“转换”-“个案排秩”。
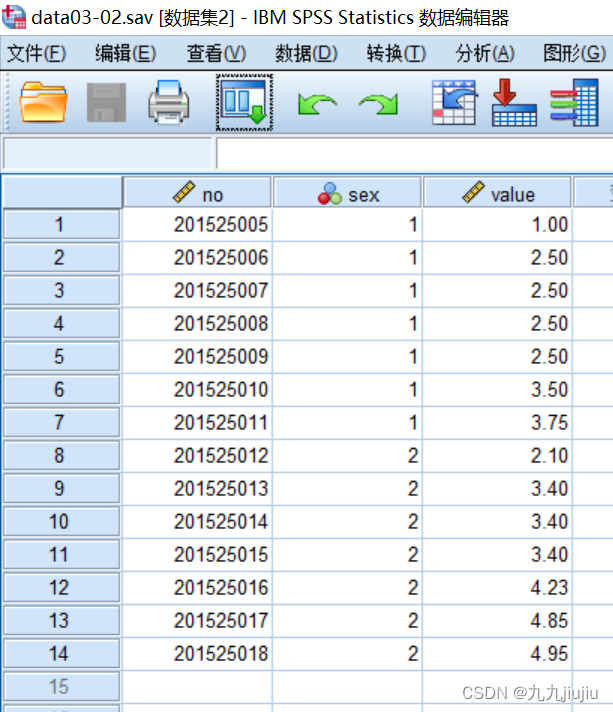
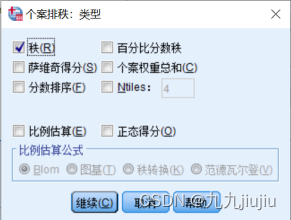
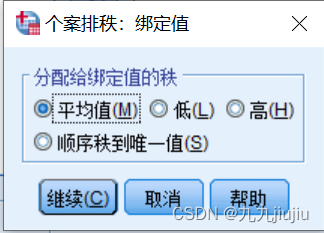
选择排秩的变量“value”,按照“sex”变量进行分组;选择秩1定义为“最小值”(即按升序排列),并在“类型排秩”的参数中,选择“秩”选项;在“绑定值”参数中,可以选择结的处理方式,有“平均值”“低”“高”“顺序等级到唯一值”的选项,即相同值(结)的秩取结中个案所在序号的相应值。
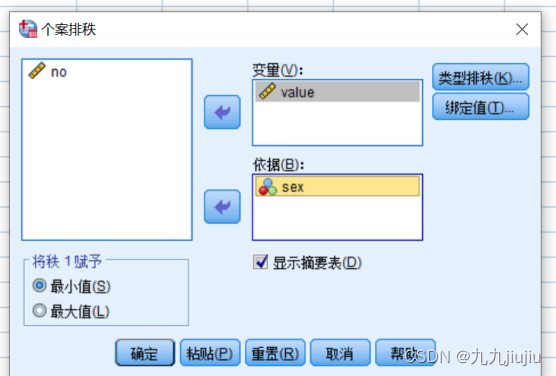
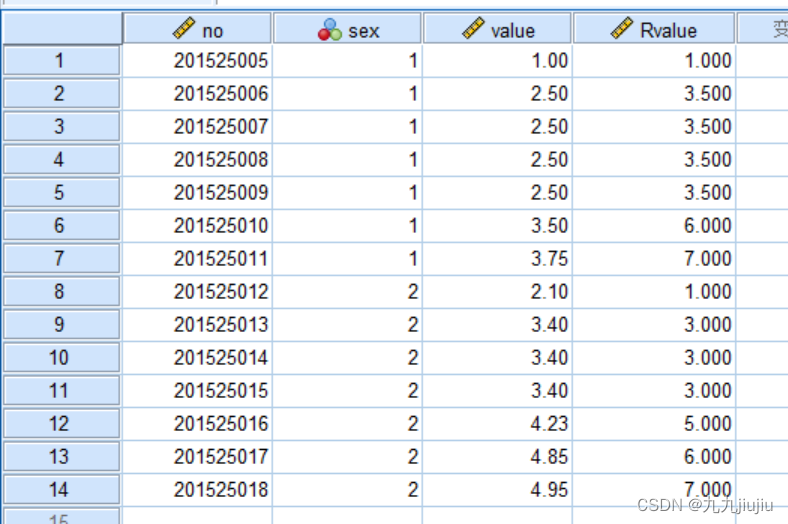
最终结果如图所示。其中,红色圈出内容为一个结,按照平均数进行赋值(对序号总和求平均,2+3+4+5=14,14/4=3.5),因此赋值为3.5。由于,在执行任务时,按照性别进行分组,因此,在性别为2的观测值重新开始编号(例:序号8转换为序号1、序号11转换为序号4),所以在3.4的同一结中计算公式为:2+3+4=9,9/3=3,因此赋值为3。
第九节 个案加权
个案加权是指在统计分析过程中对不同个案定义不同权重,用以制作列联表、散点图、直方图等方面。其中加权数必须为正数,不能为0、负数或缺失值。具体操作步骤如下:
打开“数据”-“个案加权”,选择加权依据(频率变量)为“人数”。
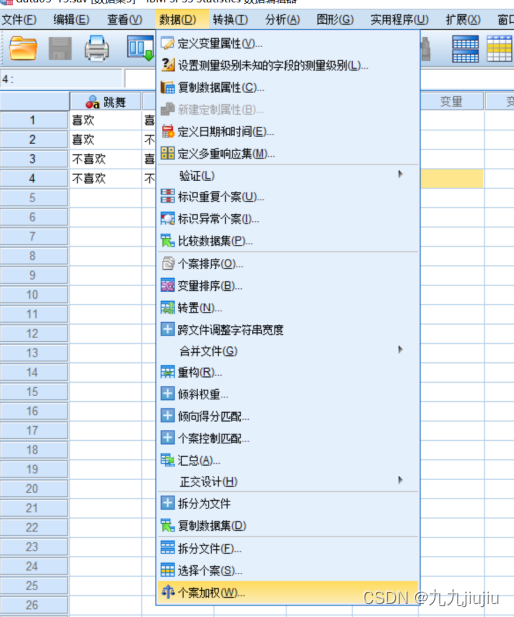
执行命令后,原数据表右下方出现“权重开启”标识。

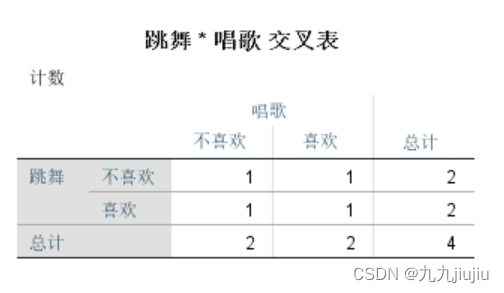
此时,点击“分析”-“描述统计”-“交叉表”,选择行变量与列变量绘制列联表如下所示。
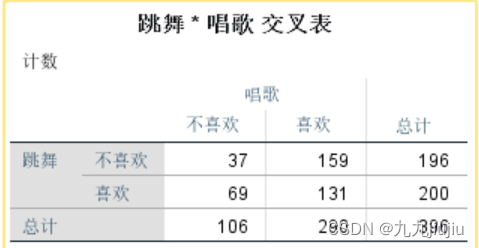
如果未进行加权,则相同步骤下,列联表绘制样式如下。


















 3753
3753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











