







 本文围绕SPSS展开,介绍其特点、主要窗口、运行方式及数据分析步骤。阐述了数据文件的建立、管理、预处理方法,涵盖排序、计算、分组等。还讲解了基本统计分析,如频数、描述统计量等,以及参数检验方法,包括单样本t检验等,为数据分析提供全面指导。
本文围绕SPSS展开,介绍其特点、主要窗口、运行方式及数据分析步骤。阐述了数据文件的建立、管理、预处理方法,涵盖排序、计算、分组等。还讲解了基本统计分析,如频数、描述统计量等,以及参数检验方法,包括单样本t检验等,为数据分析提供全面指导。
一、SPSS概述
1.1特点
操作简便。绝大多数操作是通过菜单、按钮、对话框完成的。
无需计算机编程、需记忆大量命令和参数。
分析方法丰富、分析结果清晰、直观。
可以直接读取其他软件格式的数据文件,如:xls、sas等。
最新版本采用分布式分析系统,适应互联网,支持动态收集、分析数据和HTML报告
不方便与一般的办公软件直接兼容
1.2SPSS主要窗口:数据编辑器窗口
窗口标题:数据编辑器(数据集)
功能:对SPSS的数据文件进行录入、 修改、管理等基本操作的窗口。
组成:窗口主菜单、工具栏、数据编辑区、状态区
特点:
SPSS运行过程中自动打开
SPSS中各统计分析功能都是针对该窗口中的数据进行的
窗口中的数据文件以.sav存于磁盘上
两个视图:数据视图和变量视图
1.3SPSS主要窗口:数据查看器窗口
窗口标题:查看器
功能:SPSS统计分析报表及图形的输出的窗口。
组成:窗口主菜单、工具栏、结果显示区、状态区
特点:
输出窗口可以关闭,窗口内容以.SPV存于磁盘上
两个部分:目录视图和内容视图
1.4SPSS基本运行方式
完全窗口菜单方式:
所有分析操作过程都是通过菜单和按钮及对话框方式进行的.
是经常使用的一种运行方式,适用于一般分析和SPSS的初学者.
程序运行方式:
手工编写SPSS命令程序
一次性提交计算机运行
适用于大规模的分析工作和熟练的SPSS程序员.
实现方法:
(1)打开语法窗口并编写和修改SPSS程序
(2)点击语法窗口中的运行菜单项,选择运行方式运行
菜单程序混合运行方式:
先通过菜单选择分析过程和参数,不立即提交(确定)执行,而是按粘贴按钮.
计算机自动将用户刚定义的分析过程和参数转换成SPSS的命令,并显示到语法窗口中.
用户可对其进行必要的修改后再提交给计算机执行.
一般适用于熟练的SPSS程序员.
1.5利用SPSS进行数据分析的步骤
1.建立SPSS数据文件
定义数据文件结构
录入修改和编辑待分析数据
2.数据的统计分析
统计分析之前的预处理
统计分析
3.数据和分析结果的保存
4.结果的说明和解释
二、SPSS 数据文件的建立和管理
SPSS的数据文件
SPSS数据组织的特点
单选项问题和多选项问题
SPSS数据的结构
2.1SPSS数据文件
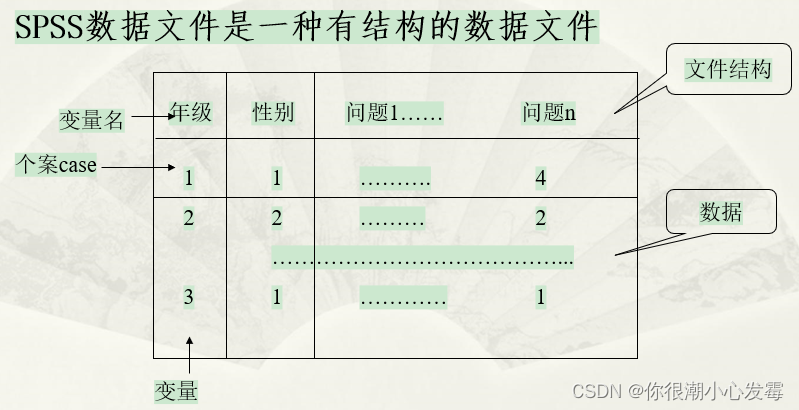
2.2SPSS数据的结构
定义变量的内容

变量名(Variable name):变量存取的唯一标志。
默认变量名为VARn(如var00001)
变量类型(type)与显示宽度(width)
标准数值型(Numeric):默认类型 8.2
如: 12345678、12345.67、-1234.56
带逗号的数值型(Comma): 从个位开始三位一个逗号8.2
如:1,234.56
科学计数法(Scientific Notation):表示很大或很小的数据 8.2
如:1.2E+05
带美元符号(Dollar):表示货币
格式很多,如:$12.30
变量类型(type)与存储宽度(width)
字符型(String): 存储字符数据 8位
如:beijing 处理时用双引号扩起来
日期型(Date):存储日期数据
格式很多,如:20-AUG-1999
其他:
如:圆点数值型(dot)等
标签(变量名标签 Variable label)
对变量名的一些解释说明,增强分析结果的可视性。可以省略
值(变量值标签 Value label)
对变量所取值的一些解释说明,增强分析结果的可视性。可以省略
变量列格式(Column Format)
对齐方式(Text Alignment):左对齐(Left):字符型默认;右对齐(Right):数值型默认;居中对齐(Center)
列宽度(Column Width):默认值为变量的存储宽度
列宽度不影响存储宽度
度量标准(计量尺度 Measurement)
度量(Scale):定距
序号(Ordinal):有固有顺序
名义(Nominal):无固有顺序
缺失(缺失值 Missing Values)
缺失值:漏填数据;明显错误的数据
SPSS的用户缺失值:
指定某个特定值为缺失值
一般处理
事先指定:指定某个特定值为用户缺失值
修正:以均值、众数替代等
SPSS的系统缺失值:
数值型:点 (•)
字符型:空
2.3定义SPSS数据结构
操作方法:
利用变量视图
2.4SPSS数据的录入与保存
录入时应注意:
1.黄框单元当前数据单元。
2.录入带有变量值标签的数据:
手工输入变量值
打开值标签开关:屏幕显示变量值标签,从下拉框中选择。
数据保存格式:
(1).sav :SPSS数据文件(默认)。
(2).xls : Excel工作表文件。
注意:有些信息会丢失
2.5SPSS数据的编辑
(一)打开数据文件
菜单选项:文件 -> 打开 -> .sav
(二)数据定位
按个案号码定位
菜单: 编辑->转至个案-> 输入样本号
按值定位
光标定位到某列变量上 -> 编辑-> 查找
(三)插入和删除一个个案
插入:编辑-> 插入个案
删除:选定待删行,鼠标右键选择清除
(四)插入和删除一个变量
插入:光标定位到某列变量上 -> 编辑 -> 插入变量(插到某列前) 或鼠标右键选择菜单
删除:选定列,鼠标右键选择清除
(五)数据移动、复制和删除
定义源数据块
鼠标右键:选择相应菜单项
确定目标单元
鼠标右键:选择相应菜单项
2.6与其他软件数据共享
1.数据共享
1.1xls格式文件的共享
是否有存放变量名的单元
1.2文本数据的读入
利用文本向导读入数据
1.3数据库文件的共享
利用ODBC共享数据
2.7SPSS数据文件的合并
目的:
将两个SPSS数据文件合并到一个数据文件中。
文件合并的方式:
纵向合并
横向合并
(一)纵向数据合并
(1)含义:
将磁盘或其他数据编辑器窗口中的SPSS数据追加到当前数据编辑器窗口中的数据文件中。
(2)前提:
两个SPSS数据文件应可以合并的内容,且最好有相同的变量名和变量类型。
(3)菜单选项:
数据 -> 合并文件 -> 添加个案
(二)横向数据合并
(1)含义:
将磁盘或其他数据编辑器窗口中的SPSS数据中的若干个变量增加到当前数据编辑器窗口中的数据文件中。
(2)前提:
a.两个数据文件必须有一个共同的变量名为关键字段—合并的依据;
b. 两个数据文件应事先按关键字段升序排序。
(3)菜单选项:
数据 -> 合并文件 -> 添加变量
(4)选项说明:
以关键字作为合并标志。
合并后的文件的数据由两个文件共同提供。
以当前数据编辑器中的数据为基础添加。
以磁盘文件或其他编辑器窗口中的数据为基础添加。
三、SPSS数据的预处理
主要内容:
个案排序
变量计算
数据分组
个案选取
计数
分类汇总
指定加权变量
3.1数据排序
目标:排序在数据分析中的作用?
快速找到可能的离群点
手段:将所有个案按照用户指定的某一个或多个变量的变量值的升序或降序重新排列
菜单选项:
数据 -> 排序个案
注意:
(1)排序的次序:升序、降序。
(2)多重排序,选择变量名的次序很关键。
3.2查找重复个案
3.3变量计算
目的:产生新变量或对原变量进行必要的转换
(如:预测问题 产生比率数据 偏态数据的正态处理 时间序列的平稳处理等)
(1)含义:根据用户给出的SPSS算术表达式,对所有或部分样本数据进行加工。
(2)菜单选项:
转换-> 计算变量; 如果按钮
(3)SPSS算术表达式:
由算术运算符(+ 、-、 *、 /、 **)、SPSS函数以及SPSS变量名组成的式子。
(4) SPSS函数

(5)SPSS条件表达式:由SPSS关系运算符、逻辑运算符、SPSS函数以及SPSS变量名组成的式子。
关系运算符: > (大于)、<(小于)、=(等于)、~=(不等于)、>=(大于等于)、<=(小于等于)
如:nl>32、sr<=700
逻辑运算符:&(AND):并且、|(OR):或者、 ~(NOT):非
如:(nl>32) and (sr<=700)
如:(nl=32) | (sr<>700)
如: not xb=1
3.4个案选取
目标:个案选取的意义?
手段:从现有数据中选出部分数据
按条件选取;随机选取;选取指定区间中的样本
例:对住房调查数据
挑出本市户口的样本
随机挑出70%的样本
注意:以后的操作都针对选出的数据进行
3.5计数
目标:
例:学生成绩整体状况的分析
例:住房满意程度的粗略分析
手段:对所有或部分个案,计算若干个变量中有几个变量的值落在指定的区域内,并将结果存入新变量中
例:
学生成绩得优门次的整体状况分析
住房满意程度的粗略分析
3.6数据分组
目标:更好地了解连续型变量的分布特点
手段:组距分组
指定按哪个变量分组;定义分组区间(不重不漏);指定存放分组结果的组标志变量
SPSS的区间
狭义区间:
职工工资的分组(850以下,851至900,901至950,951至1000,1000以上)
广义区间:
用户缺失值的定义;变量类别的重新调整
性格打分(内向、一般、外向)
1、与生人交往会“自来熟”
(1)从不 (2)偶尔 (3)有时 (4)经常
2、与不熟悉的异性交往,会脸红
(1)从不 (2)偶尔 (3)有时 (4)经常
3、 在公众场合下你会大声发表自己的意见
(1)从不 (2)偶尔 (3)有时 (4)经常
极为内向:3分;较为内向:6分;较为外向:9分;极为外向:12分
3.7分类汇总
目标:分析各分组下样本的统计特征
手段:
按指定的分组变量值对样本分组
分别计算各组中汇总变量的基本统计量
例:对比男女职工的平均年龄和平均工资
原始数据:
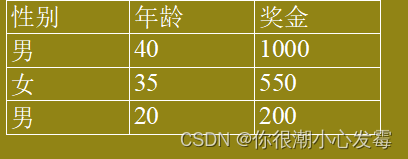
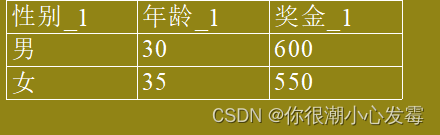
按性别变量汇总数据:
菜单选项:
数据 -> 分类汇总
说明:
多重分组时,变量名的选择顺序。
生成的新文件名默认为:aggr.sav。可修改。
生成的新变量名默认为原变量名后加_1。可修改
可以在新文件中存贮各分组个案数.
3.8指定加权变量
目标:
例:蔬菜的平均价格、男足打分
手段:指定某一变量为加权变量
例:蔬菜的平均价格
菜单选项:
数据 -> 加权个案
说明:
如果取消加权变量应重新定义
3.9数据转置&数据拆分
四、SPSS基本统计分析
主要内容:
频数分析
计算描述统计量
列联分析
多选项分析
4.1频数分析
目的:粗略把握变量值的分布状况。
例:研究被调查者的特征(如:性别,年龄,收入)
研究被调查者对某个问题的总体看法(如:教学方式,选修课程)
采用的方法
计算频分布表:包括频数、累计频数、百分比、累计百分比
绘制统计图形:条形图、饼图
基本操作步骤
(1)菜单选项:分析->描述统计->频率
(2)选择几个待分析的变量到变量框.
(3)图表选项,选择所需要的图形
频数分析中的其他分析
计算分位数:适用于定距数据
数据按升序排序后,找到若干个分位点上的变量值
计算四分位数:25%(QL)、50%(中位数)、75%(QU)
分位数的应用:在排除极端值影响的条件下,通过计算分位数差,比较两组样本数据的离散程度
例:( QL=50,QU=80)和(QL=70,QU=75)的比较
与频数分析相关的图形:
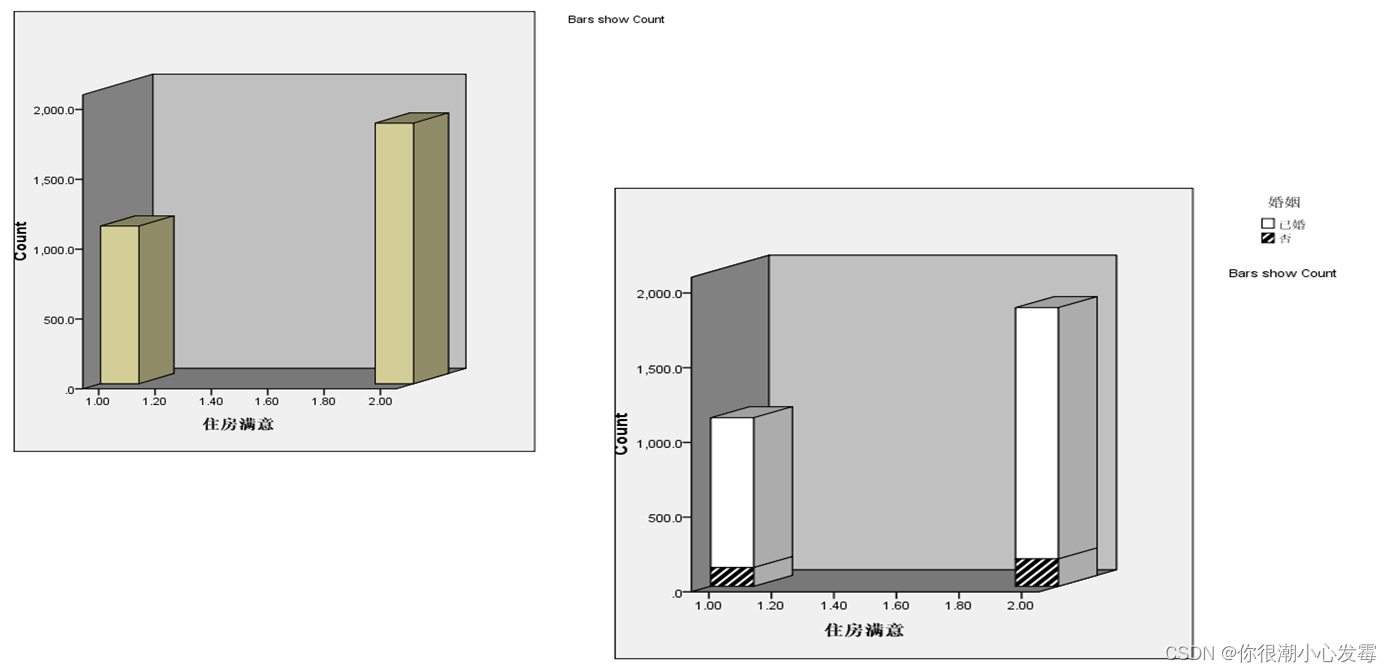
以制作条形图为例

第一种模式:用于变量在各组下的频数对比
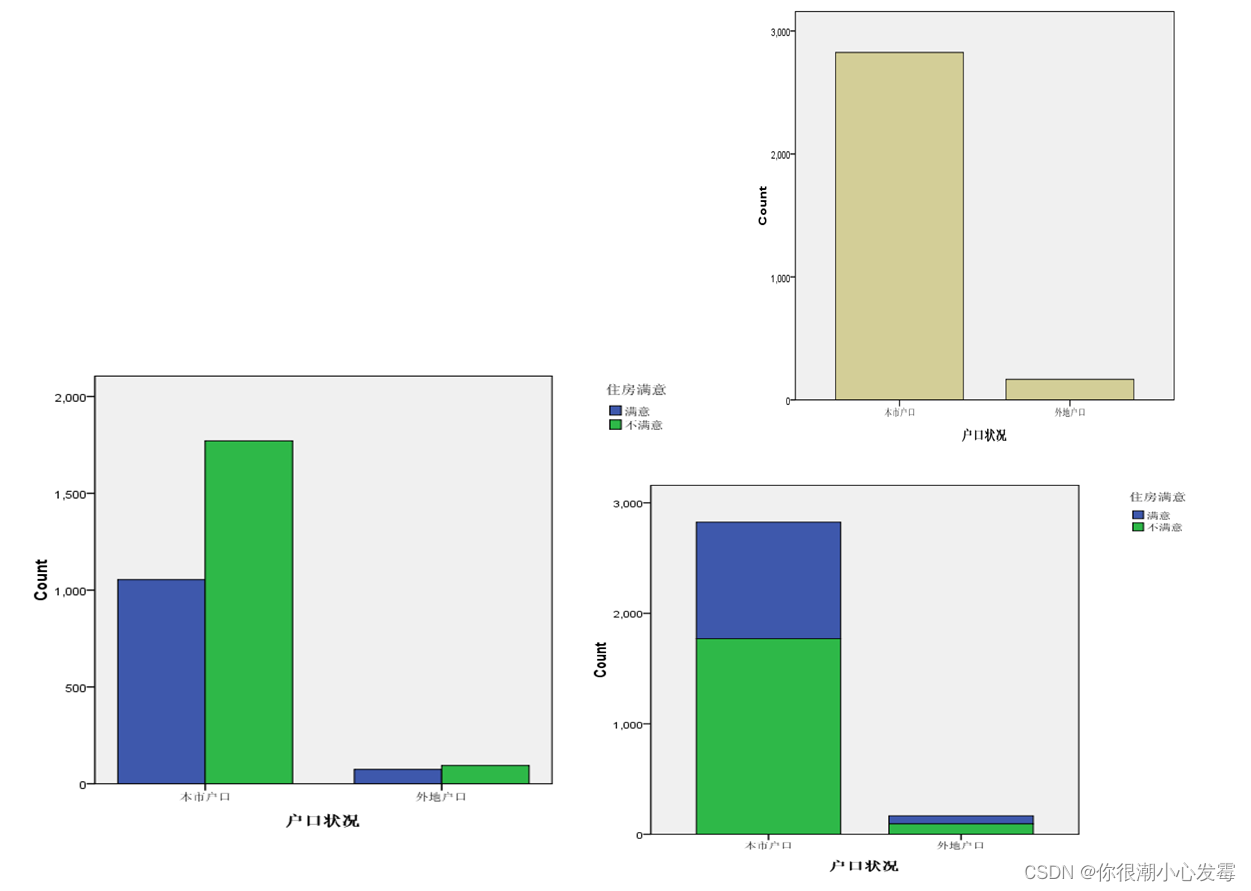
第二种模式:用于多个变量基本描述统计量的对比
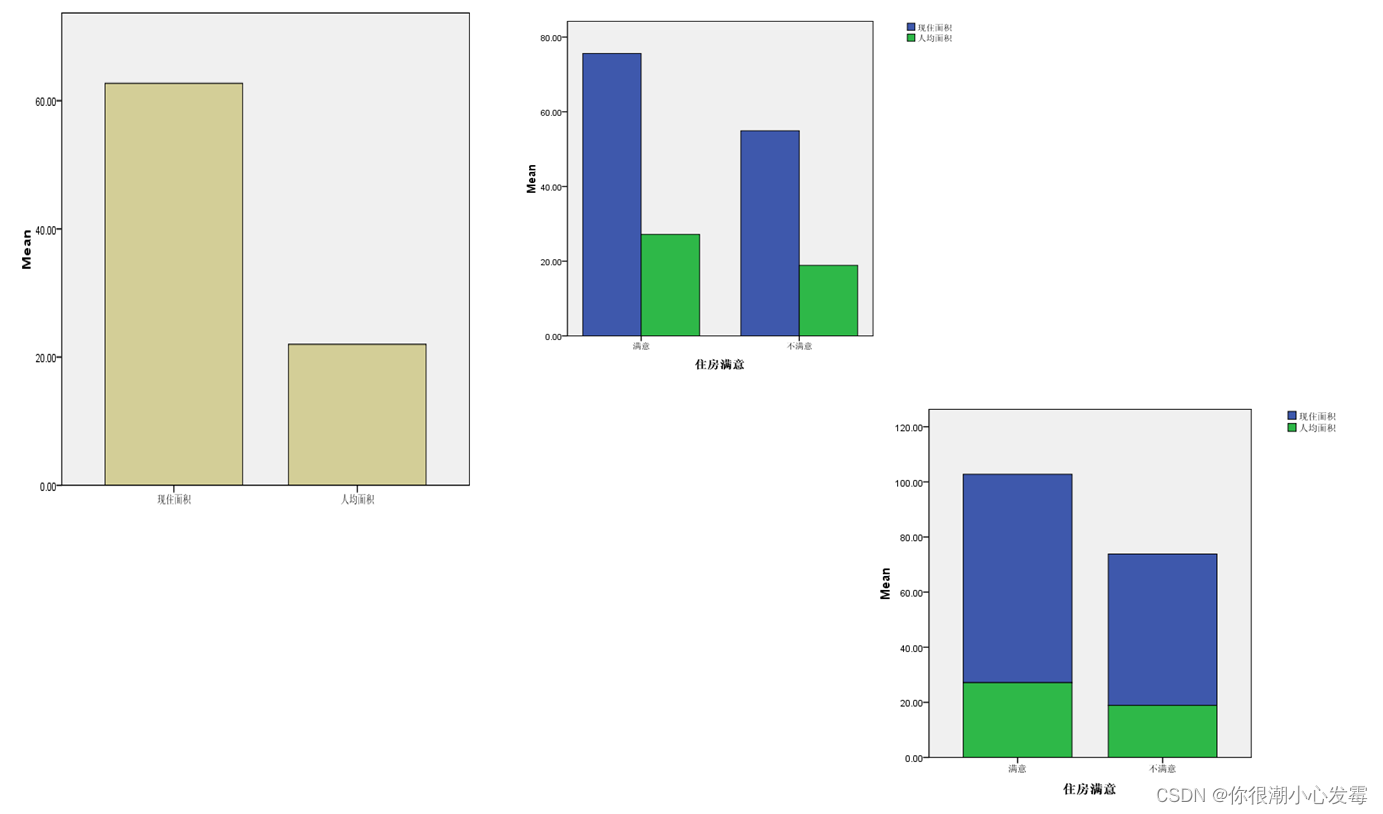
交互作图:以制作条形图为例
4.2计算描述统计量
目的:精确把握变量的总体分布状况,了解数据的集中趋势、离散趋势、对称程度、陡峭程度。
基本方法:
计算基本描述统计量
描述集中趋势的统计量:
均值:表示某变量所有变量值集中趋势或平均水平的统计量。
适用于定距数据。
特点:利用了全部数据,易受极端值的影响。
描述离散程度的统计量:
标准差:表示某变量的所有变量值离散程度的统计量。
SPSS中计算的是样本标准差
极差:最大值—最小值
描述对称程度的统计量:
偏度(skewness):描述某变量分布形态的偏斜程度和方向的统计量.
偏度为0表示对称;
大于0表示正偏差大(右偏)
小于0表示负偏差大(左偏)
描述陡峭程度的统计量:
峰度(kurtosis):描述某变量所有变量值分布形态陡缓程度的统计量。
峭度为0表示与标准正态分布峭度相同。
大于0表示比标准正态分布陡,尖峰。
小于0表示比标准正态分布缓,平峰。
其他统计量:
均值标准误差(means of S.E)
中心极限定理认为:样本均值~N(u,2/n)
反映样本均值与总体真值间的平均离散程度
样本数越大,样本均值的离散程度越小,对真值的估计越准确
基本操作步骤
(1)菜单选项:分析->描述统计->描述
(2)选择将参加计算的数值型变量名到变量框
其他功能
数据标准化处理
新变量的均值为0,标准差为1;
小于0表示在平均水平下,大于0反之.
正态分布的数据标准化后呈标准正态分布
3准则:(68.2%,95.4%,99.7%)
将变量作标准化后,结果存入名为“Z+原变量名”的新变量中.
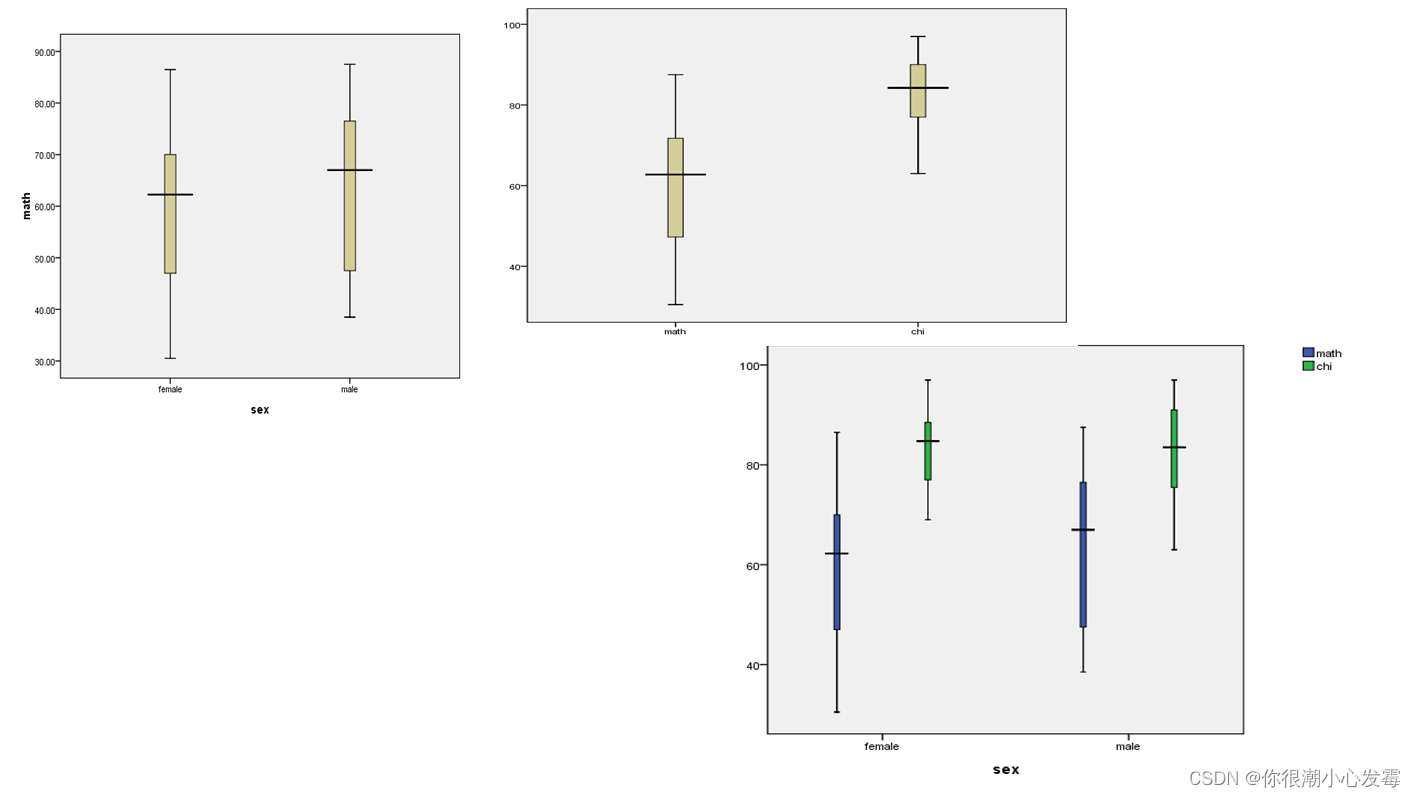
描述连续变量分布的图形:
箱线图:以四分位差的1.5倍为标准剔除极端值
直方图和金字塔图
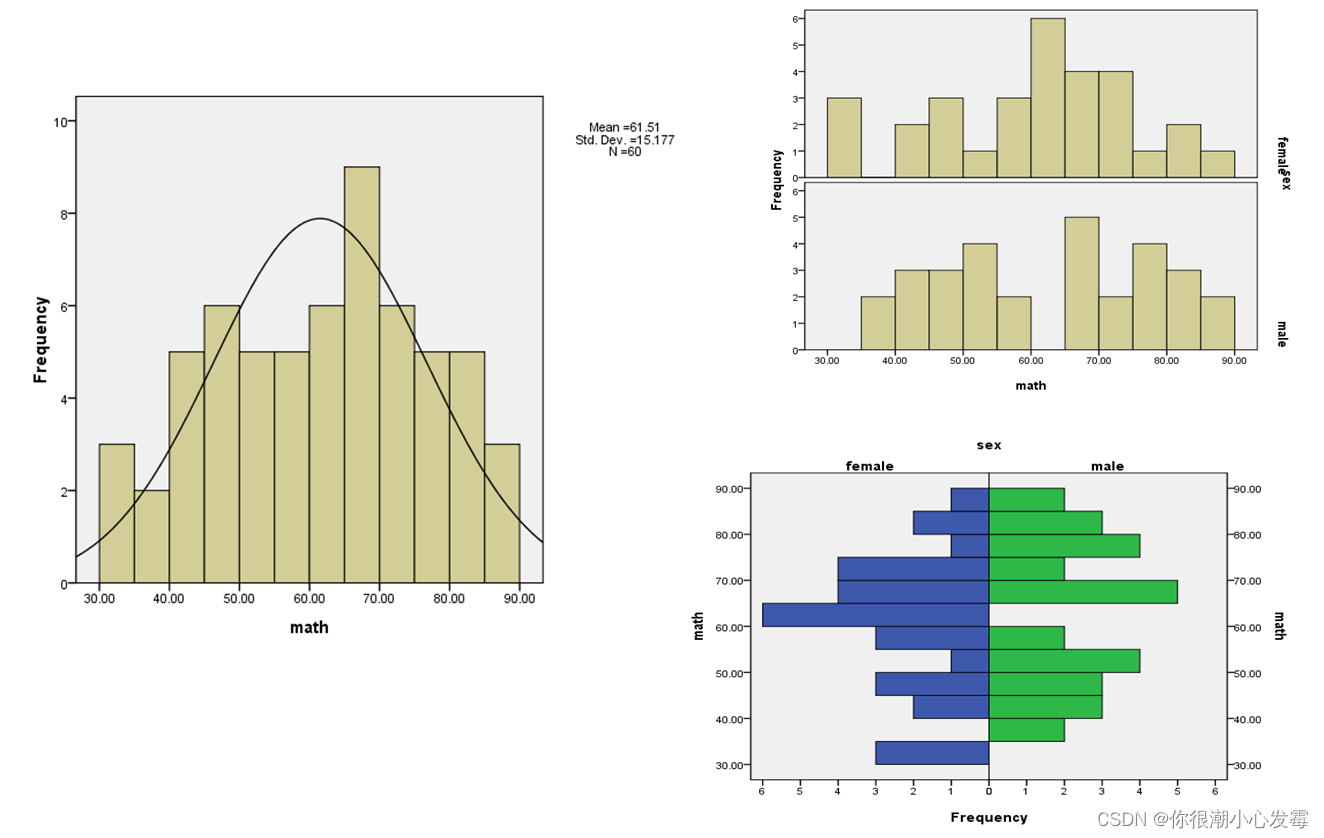
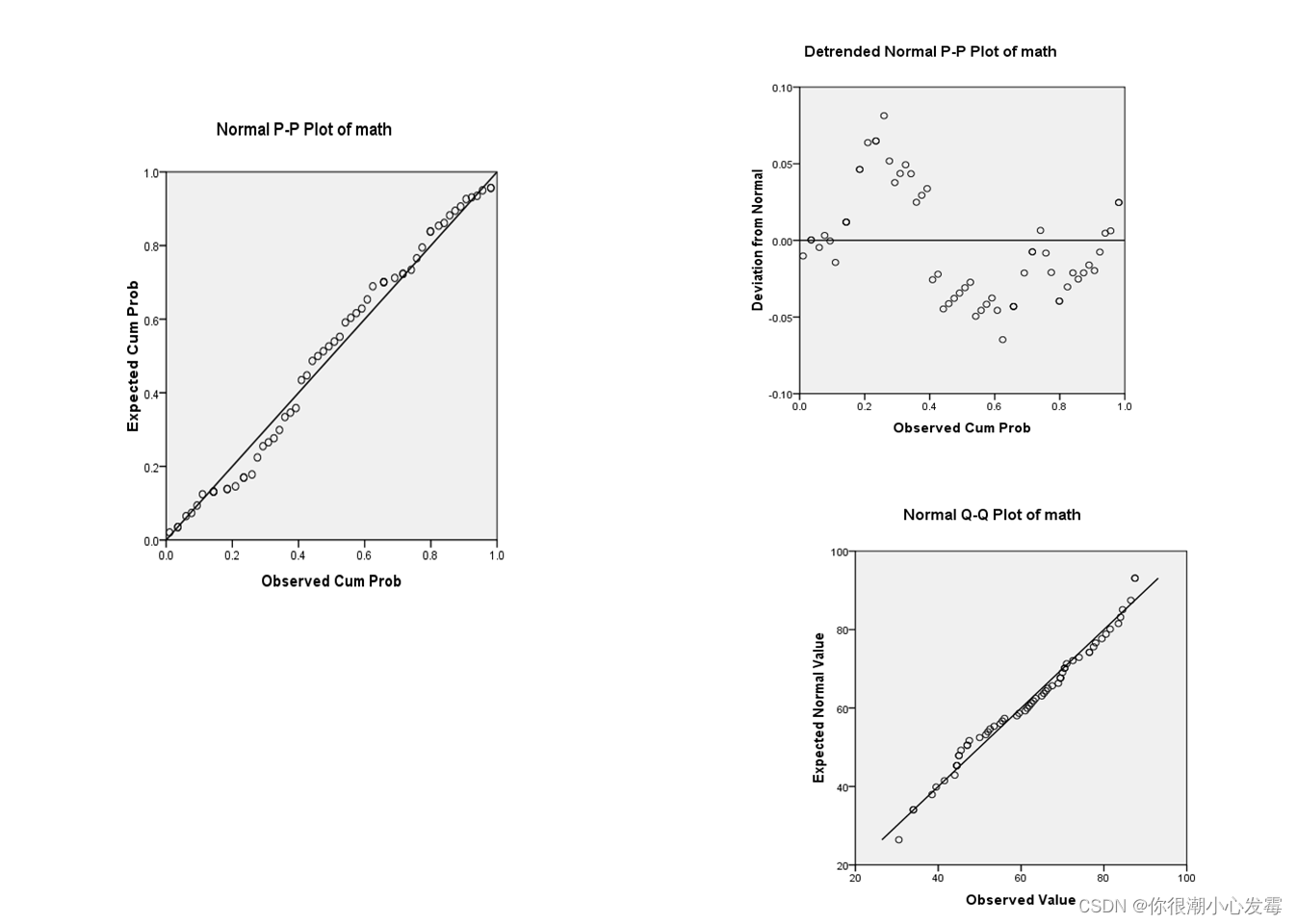
Q-Q图和P-P图:累计分布函数(CDF)和概率密度函数(PDF)函数的应用
4.3交叉分组下的频数分析
目的:了解不同变量在不同水平下的数据分布
例:学习成绩与性别有关联吗?(两变量)
例:职业、性别、爱逛商店有关联吗?(三变量)
分析的主要步骤
产生交叉列联表
分析列联表中变量间的关系
4.4列联表
列联表中的元素:
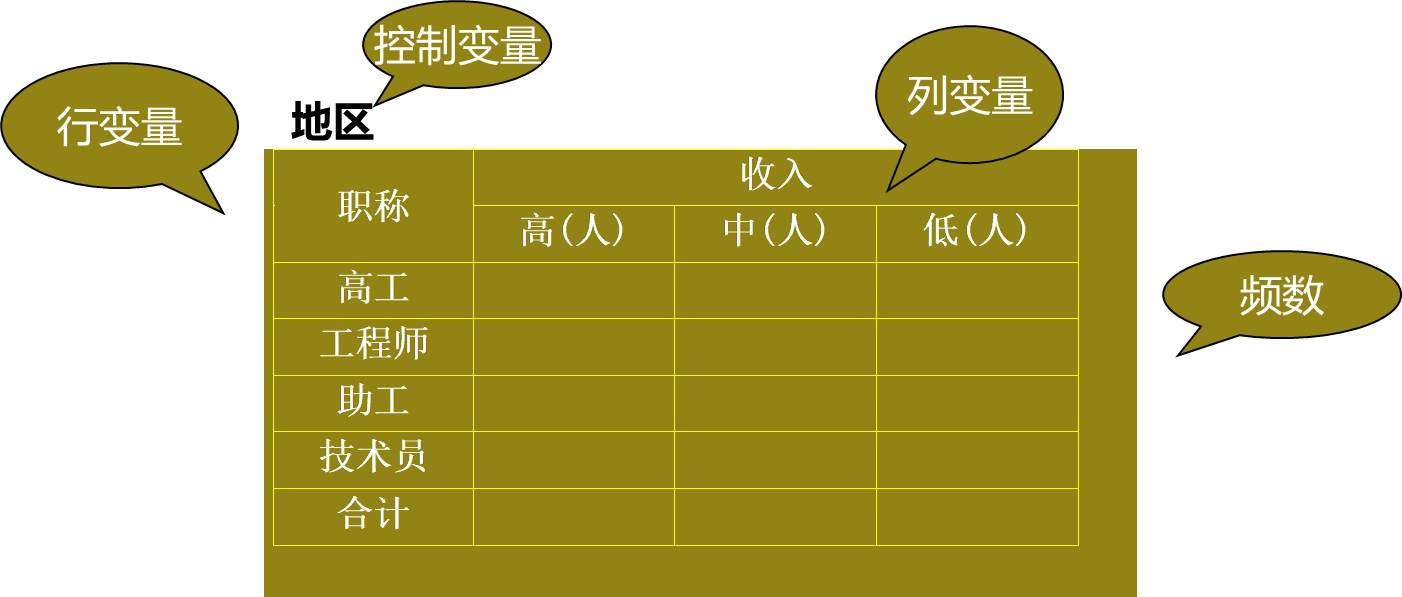
产生交叉列联表
基本操作步骤
(1)菜单选项: 分析->描述统计-> 交叉表
(2)选择一个变量作为行变量到行框.
(3)选择一个变量作为列变量到列框.
(4)可选一个或多个变量作为控制变量到层框.
控制变量的层次设置:同层为水平数加;不同层为水平数积.
(5)是否显示复式条形图
进一步计算
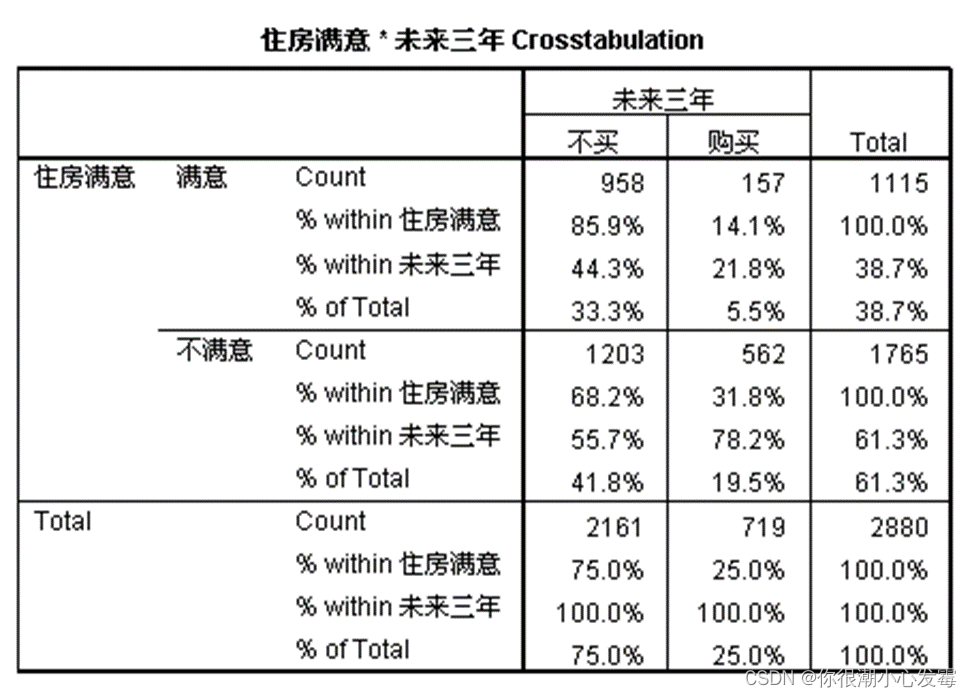
单元格选项:选择在频数分析表中输出各种百分比.
行百分比;列百分比;总百分比
列联表
例:住房满意程度与购房计划
4.5列联表中行列变量间的关系
目的:通过列联表分析,检验行列变量之间是否独立
方法:卡方检验(分类变量相关性的检验)
年龄与工资收入交叉列联表
低 中 高
青 400 0 0
中 0 500 0
老 0 0 600
低 中 高
青 0 0 500
中 0 600 0
老 400 0 0
卡方检验基本步骤
(1)H0:行列变量独立
(2)构造卡方统计量:从(r-1)*(c-1)个自由度的卡方分布
期望分布反映的是H0成立情况下的分布特征
(3)计算卡方的观测值,得到概率P值
(4)比较显著性水平和概率P值。小于等于则拒绝H0,否则不能拒绝
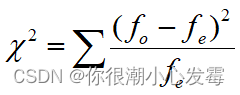
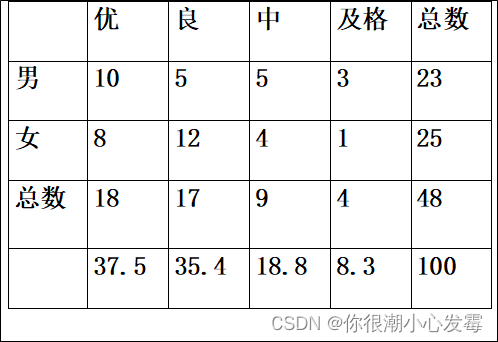
例:不同行业的人职业选择标准是否存在差异?
制造业 服务业
物质报酬 105 45
稳定性 40 35
2乘2的列联表进行yates连续性校正:
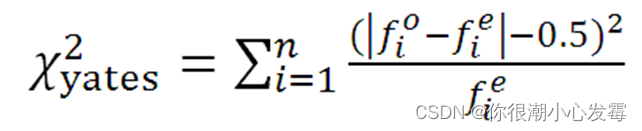
卡方检验的要求:
一般要求列联表中期望频数小于5的格子数不超过20%,否则会夸大卡方值,容易得出拒绝结论,可以合并单元格。
卡方值会受样本数的影响


4.6多选项分析
多选项分析是针对多选项问题的
SPSS多选项问题的处理思路:
将一个问题定义成几个变量。分别用几个变量描述问题的几个可能被选择的答案
具体策略:采用不同的编码方式
多选项二分法(multiple dichotomize method)
–将每个答案作为一个变量,每个变量只有两个取值(0或1)
多选项分类法(multiple category method)
–预先指定多选项问题被选择的最多答案数
–每个答案建立一个变量,取值为多选项问题的备选答案
多选项分析的基本思路:
定义多选项变量集
多选项频数分析
多选项交叉分组下的频数分析
定义多选项变量集:
目的:将已分解的变量定义为一个集合,便于进行多选项分析
菜单选项:分析->多重响应->定义变量集
从原变量中选取被分解的变量(数值型)到集合中的变量框
指定被分解的变量是按多选项二分法分解还是按多选项分类法分解的
为变量集命名。系统自动在名字前加字符$.
多选项频数分析
–菜单选项:分析->多重响应->频率
多选项交叉分析下的频数分析
–菜单选项:分析->多重响应->交叉表
五、SPSS的参数检验
主要内容:
1.单个总体的均值检验
2.两个总体的均值比较
利用两个独立样本
利用两个配对样本
统计学的范畴:推论统计
根据样本数据推断总体的分布或均值方差等总体统计参数
方法:
参数检验
非参数检验
5.1假设检验概述
假设检验是一种根据样本数据推断总体的分布或均值、方差等总体统计参数的方法。
根据样本来推断总体的原因:
总体数据不可能全部收集到。如:质量检测问题
收集到总体全部数据要耗费大量的人力和财力
假设检验包括:
参数检验
非参数检验
5.2假设检验的基本步骤
提出基本假设H0
构造服从某种理论分布的检验统计量
利用样本数据和基本假设计算检验统计量的观测值,并得到概率P值(检验统计量在特定极端区域取值在H0成立时的概率)
如果概率P值小于用户给定的显著性水平a,则拒绝H0;否则,不拒绝H0
5.3假设检验的基本原理
基本信念:利用小概率原理进行反证明。小概率事件在一次实验中不可能发生。
例如:对大学男生平均身高进行推断
H0:平均身高为173
样本平均身高为178,由于存在抽样误差,不能直接拒绝H0。而需要考虑:在H0成立的条件下,一次抽样得到平均身高为178的可能性有多大。如果可能性较大,是个大概率事件(与相比较),则认为H0正确。否则,如果可能性较小,是个小概率事件,但确实发生了,则只能认为H0不正确。
概率P值即为观测结果或更极端现象在零假设成立时出现的概率
5.4SPSS中的参数检验方法
单样本t检验
两独立样本t检验
两配对样本t检验
5.4.1单样本t检验
目的:对某个总体的均值与指定的检验值之间是否存在显著差异进行检验
例:大学毕业生的月平均工资与3500元是否有显著差异
手段:利用单个样本的均值对总体均值进行检验
理论依据:样本均值的抽样分布
抽样分布:样本统计量的概率分布
结果来自容量相同的所有可能样本
提供了有关样本统计量的概率信息,是推断的理论基础,是抽样推断科学性的重要依据
当总体服从正态分布N~(μ,σ2)时,来自该总体的所有容量为n的样本的均值X也服从正态分布,X的数学期望为μ,方差为σ2/n。即X~N(μ,σ2/n)
设从均值为,方差为 2的一个任意总体中抽取容量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ2/n的正态分布
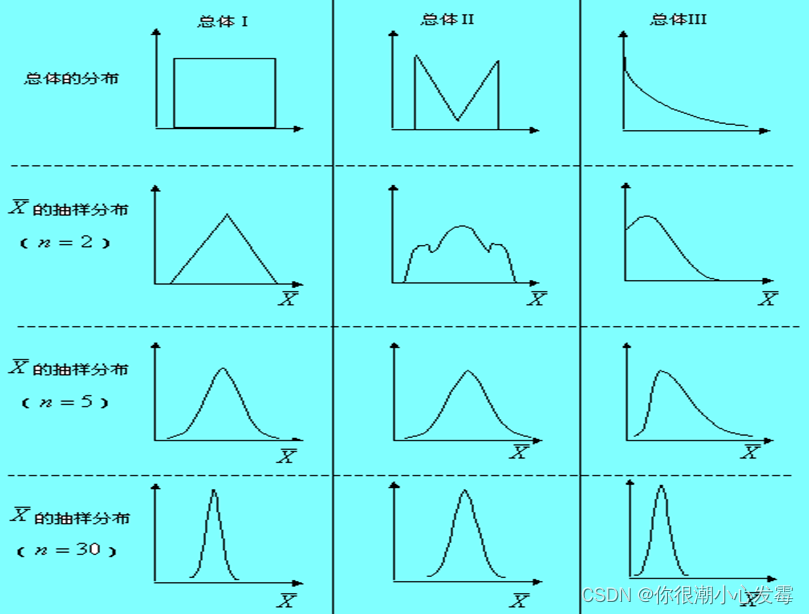
基本步骤:
H0:u=u0,总体均值与检验值之间不存在显著差异
选择检验统计量
计算t统计量的观测值和概率P值
结论:P≤α,拒绝H0,认为总体均值与检验值之间有显著差异.P>α,不能拒绝H0
注意:SPSS给出的双侧检验的概率P值
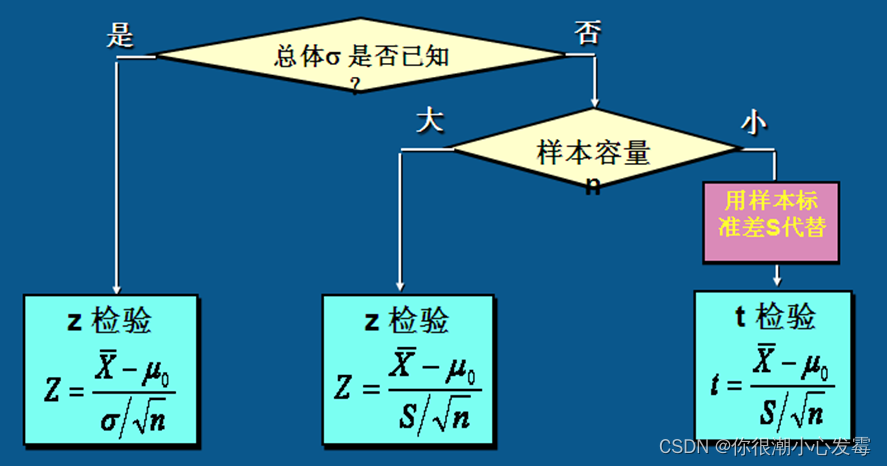
基本操作步骤
(1)菜单选项:分析->比较均值->单样本T检验
(2)指定检验值: 在检验值框中输入原假设值
SPSS中的选项
置信区间:指定输出-0的置信区间.默认值为95%.
缺失值的处理策略
当涉及缺失值变量的计算时剔除包含缺失值的样本
剔除所有含缺失值的个案后再计算
5.4.2两独立样本t检验
5.4.3两配对样本t检验
1.回归分析的基本理论与一般线性回归分析步骤:
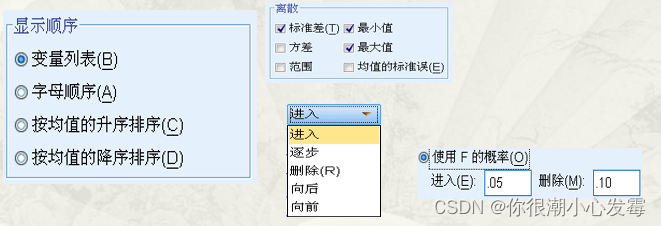
分析-回归-线性-方法(步进)-统计(估算值、模型拟合、共线性诊断)、图(Y-ZRESID标准化残差,X-ZPRED标准化预测值)、保存(标准化,未标准化)、选项里默认。
2.带虚拟解释变量的回归分析
3.曲线步骤:
分析-回归-曲线估计-因变量&变量(时间暂时不选)-模型可选择线性&二次-个性标签(勾选在方程中包括常量&模型绘图)-勾选显示ANOVA表(即方差分析的表)
序列图画法:分析-时间序列预测-序列图-变量选择因变量,时间轴标签选择年份等时间
此时预测未来年份的消费数据:即在曲线分析时勾选时间,点击保存-曲线估算里预测值,对应预测范围可以输入观测值22(即2022年)
4.聚类分析步骤
4.1层次聚类分析:分析-分类-系统聚类分析-统计(勾选集中计划、近似值矩阵,解的范围设置最小/最大聚类数)-图(勾选谱系图)-方法(区间改为欧式距离)-保存(解的范围设置同上)
层次聚类分析案例2、层次聚类分析案例3
4.2K-means聚类分析(快速聚类、K-均值聚类)
因子分析:变量选入好几个因子->描述(选单变量描述,初始解,系数,反映象,KMO和巴特利特球形度检验)->提取(主成分,相关性矩阵,未旋转因子,碎石图,基于特征值默认–这个后面改为因子的固定数目)->旋转(选中最大方差法,旋转后的解,载荷图)->得分(选中保存为变量,方法为回归,选中显示因子得分系数矩阵)


















 7261
7261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









