







文章目录
1068. 产品销售分析 I
- 题目
销售表 Sales:
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
+-------------+-------+
(sale_id, year) 是销售表 Sales 的主键(具有唯一值的列的组合)。
product_id 是关联到产品表 Product 的外键(reference 列)。
该表的每一行显示 product_id 在某一年的销售情况。
注意: price 表示每单位价格。
产品表 Product:
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
+--------------+---------+
product_id 是表的主键(具有唯一值的列)。
该表的每一行表示每种产品的产品名称。
编写解决方案,以获取 Sales 表中所有 sale_id 对应的 product_name 以及该产品的所有 year 和 price 。
返回结果表 无顺序要求 。
结果格式示例如下。
示例 1:
输入:
Sales 表:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product 表:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
输出:
+--------------+-------+-------+
| product_name | year | price |
+--------------+-------+-------+
| Nokia | 2008 | 5000 |
| Nokia | 2009 | 5000 |
| Apple | 2011 | 9000 |
+--------------+-------+-------+
个人解题思路
- 创建题中两张表
- 数据输入表内,需要注意product_name是varchar类型,需要加单引号,varchar类型需要给一个初始长度,一般为10或20,不给会出错,因为varchar是可变字符串,int如果不给初始长度则默认长度为11
- 题中说(sale_id, year) 是销售表 Sales 的主键(具有唯一值的列的组合),主键是一个列组合,意味着此时要用到复合主键,复合主键
constraint 约束名 primary key (字段名),而唯一主键则直接字段 数据类型 primary key - 关联外键要在创表最后添加
constraint 外键名 foreign key 外键列名 references 主表名(主表列名),题中说product_id 是关联到产品表 Product 的外键(reference 列),意味着product_id就是外键列名,Product则是主表,在主表内的主表列名为product_id,此时就能写出外键约束foreign key (product_id) references Product(product_id),这里偷个懒不想起约束名了,直接使用默认的约束名 - 编写解决方案,当Sales表的product_id等于Product表的product_id,就能获取到Sales表内sale_id对应的product_name,此时就能获取题中所需
注意:主表放上面,从表放下面,外键在哪个表,哪个表就是从表,一定要先运行主表再运行从表,否则会报错
- 1.创建产品表
create table Product(
product_id int primary key,
product_name varchar(20)
)
- 2.添加产品数据
insert into Product(product_id,product_name)
values (100,'Nokia'),
(200,'Apple'),
(300,'Samsung');
- 3.查看产品表 是否添加成功
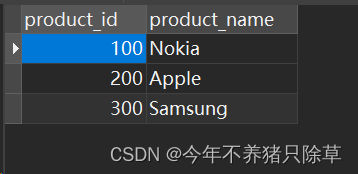
select * from Product;
Product表-主表
- 4.创建销售表
create table Sales(
sale_id int,
product_id int,
year int,
quantity int,
price int,
primary key (sale_id,year),
foreign key (product_id) references Product(product_id)
);
- 5.添加销售数据
insert into Sales(sale_id,product_id,year,quantity,price)
values (1,100,2008,10,5000),
(2,100,2009,12,5000),
(7,200,2011,15,9000);
- 6.查看销售表 是否添加成功
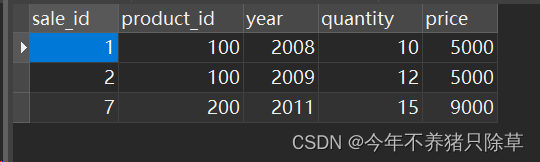
select * from Sales;
Sales表-从表
- 7.编写解决方案
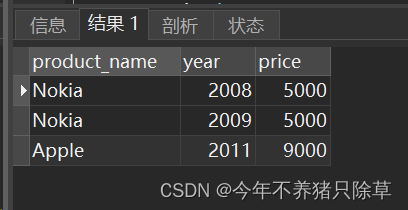
select b.product_name,a.year,a.price
from Sales a,Product b
where a.product_id=b.product_id
运行解决方案,如果成功则会出现下图,与题中所给示例一致
627. 变更性别
- 题目
Salary 表:
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| id | int |
| name | varchar |
| sex | ENUM |
| salary | int |
+-------------+----------+
id 是这个表的主键(具有唯一值的列)。
sex 这一列的值是 ENUM 类型,只能从 ('m', 'f') 中取。
本表包含公司雇员的信息。
请你编写一个解决方案来交换所有的 'f' 和 'm' (即,将所有 'f' 变为 'm' ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。
注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
结果如下例所示。
示例 1:
输入:
Salary 表:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
+----+------+-----+--------+
输出:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
+----+------+-----+--------+
解释:
(1, A) 和 (3, C) 从 'm' 变为 'f' 。
(2, B) 和 (4, D) 从 'f' 变为 'm' 。
个人解题思路
- 创建薪水表,唯一主键在创表时
字段 数据类型 primary key - sex值是ENUM类型的书写方式:sex ENUM(‘m’,‘f’)
- 编写方案,当sex为m时要变更为f,当sex为f时要变更为m,二者要同时进行,此时就需要运用流程控制函数
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 .... [ELSE resultn] END,相当于Java的if…else if…else…
- 1.创建薪水表
create table Salary(
id int primary key,
name varchar(20),
sex ENUM('m','f'),
salary int
)
- 2.添加数据
insert into Salary(id,name,sex,salary)
values (1,'A','m',2500),
(2,'B','f',1500),
(3,'C','m',5500),
(4,'D','f',500);
- 3.查看薪水表 是否添加成功
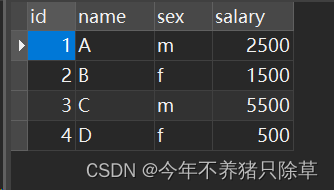
select * from Salary;
薪水表
- 4.编写解决方案
合理运用流程控制函数
update Salary
set sex=(case sex when 'm' then 'f' when 'f' then 'm' end)
运行解决方案,如果成功则会出现下图提示语句,受影响的行数为四行
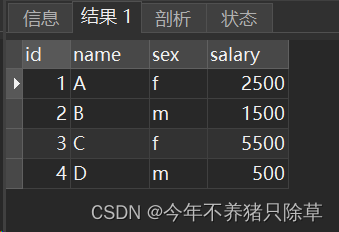
运行成功后可以再查看薪水表,查看是否变更性别成功,成功则会出现下图,与题中所给示例一致
511. 游戏玩法分析 I
- 题目
活动表 Activity:
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
在 SQL 中,表的主键是 (player_id, event_date)。
这张表展示了一些游戏玩家在游戏平台上的行为活动。
每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
查询每位玩家 第一次登陆平台的日期。
查询结果的格式如下所示:
Activity 表:
+-----------+-----------+------------+--------------+
| player_id | device_id | event_date | games_played |
+-----------+-----------+------------+--------------+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-05-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+-----------+-----------+------------+--------------+
Result 表:
+-----------+-------------+
| player_id | first_login |
+-----------+-------------+
| 1 | 2016-03-01 |
| 2 | 2017-06-25 |
| 3 | 2016-03-02 |
+-----------+-------------+
个人解题思路
- 创建活动表-Activity,复合主键
constraint 约束名 primary key (字段名) date日期值,输入数据时需要用单引号把数据引起- 编写解决方案,要查询每位玩家第一次登陆平台的日期,先根据player_id将玩家分类,分组查询用
group by,再在分好组的event_date列中找出最小值,最小值用到min,注意Result表的event_date更改为了first_login,要用到别名
- 1.创建活动表
create table Activity(
player_id int,
device_id int,
event_date date,
games_played int,
constraint main primary key (player_id,event_date)
);
- 2.添加活动数据
insert into Activity (player_id,device_id,event_date,games_played)
values (1,2,'2016-03-01',5),
(1,2,'2016-05-02',6),
(2,3,'2017-06-25',1),
(3,1,'2016-03-02',0),
(3,4,'2018-07-03',5);
- 3.查看活动表 是否添加成功
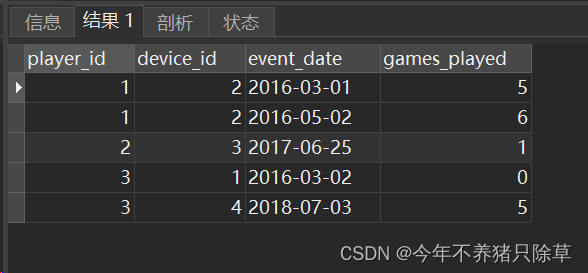
select * from Activity;
活动表
- 4.编写解决方案
select player_id,min(event_date)as first_login
from Activity
group by player_id
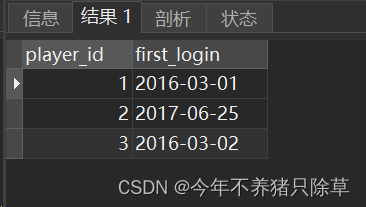
运行解决方案,如果成功则会出现下图,与题中所给Result表一致
175. 组合两个表
- 题目
表: Person
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
+-------------+---------+
personId 是该表的主键(具有唯一值的列)。
该表包含一些人的 ID 和他们的姓和名的信息。
表: Address
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
+-------------+---------+
addressId 是该表的主键(具有唯一值的列)。
该表的每一行都包含一个 ID = PersonId 的人的城市和州的信息。
编写解决方案,报告 Person 表中每个人的姓、名、城市和州。如果 personId 的地址不在 Address 表中,则报告为 null 。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入:
Person表:
+----------+----------+-----------+
| personId | lastName | firstName |
+----------+----------+-----------+
| 1 | Wang | Allen |
| 2 | Alice | Bob |
+----------+----------+-----------+
Address表:
+-----------+----------+---------------+------------+
| addressId | personId | city | state |
+-----------+----------+---------------+------------+
| 1 | 2 | New York City | New York |
| 2 | 3 | Leetcode | California |
+-----------+----------+---------------+------------+
输出:
+-----------+----------+---------------+----------+
| firstName | lastName | city | state |
+-----------+----------+---------------+----------+
| Allen | Wang | Null | Null |
| Bob | Alice | New York City | New York |
+-----------+----------+---------------+----------+
解释:
地址表中没有 personId = 1 的地址,所以它们的城市和州返回 null。
addressId = 1 包含了 personId = 2 的地址信息。
个人解题思路
- 创建题中两张表
- 数据输入表内,唯一主键则直接
字段 数据类型 primary key - 编写解决方案,题中不仅需要满足personId 的地址在 Address 表中的Person信息,还需要不满足该条件的Person信息,且可以以任意顺序返回结果表,让人想到
外连接,不仅需要Person表内满足条件的信息,还需要不满足条件的信息,此时让Person表当左表,Address表当右表,进行左外连接
- 1.创建Person表
create table Person(
PersonId int primary key,
FirstName varchar(20),
LastName varchar(20)
)
- 2.创建Address表
create table Address(
AddressId int primary key,
PersonId int,
City varchar(20),
State varchar(20)
)
- 3.添加Person数据
insert into Person(PersonId,LastName,FirstName)
values (1,'Wang','Allen'),
(2,'Alice','Bob');
- 4.查看Person表 是否添加成功
select * from Person;
Person表
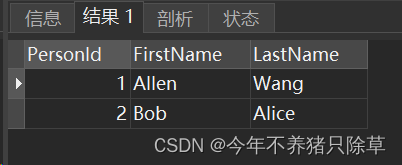
- 5.添加Address数据
insert into Address(AddressId,PersonId,City,State)
values (1,2,'New York City','New York'),
(2,3,'Leetcode','California');
- 6.查看Address表 是否添加成功
select * from Address;
Address表
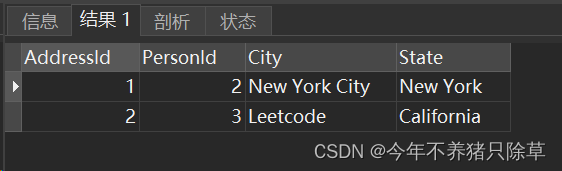
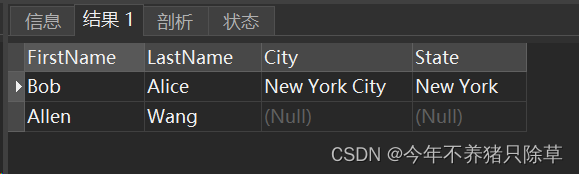
- 7.编写解决方案
select p.FirstName,p.LastName,a.City,a.State
from Person p left outer join Address a
on p.PersonId=a.PersonId
运行解决方案,如果成功则会出现下图,与题中所给示例一致
1075. 项目员工 I
- 题目
项目表 Project:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| project_id | int |
| employee_id | int |
+-------------+---------+
主键为 (project_id, employee_id)。
employee_id 是员工表 Employee 表的外键。
员工表 Employee:
+------------------+---------+
| Column Name | Type |
+------------------+---------+
| employee_id | int |
| name | varchar |
| experience_years | int |
+------------------+---------+
主键是 employee_id。
请写一个 SQL 语句,查询每一个项目中员工的 平均 工作年限,精确到小数点后两位。
查询结果的格式如下:
Project 表:
+-------------+-------------+
| project_id | employee_id |
+-------------+-------------+
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
| 2 | 4 |
+-------------+-------------+
Employee 表:
+-------------+--------+------------------+
| employee_id | name | experience_years |
+-------------+--------+------------------+
| 1 | Khaled | 3 |
| 2 | Ali | 2 |
| 3 | John | 1 |
| 4 | Doe | 2 |
+-------------+--------+------------------+
Result 表:
+-------------+---------------+
| project_id | average_years |
+-------------+---------------+
| 1 | 2.00 |
| 2 | 2.50 |
+-------------+---------------+
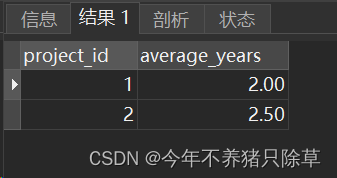
第一个项目中,员工的平均工作年限是 (3 + 2 + 1) / 3 = 2.00;第二个项目中,员工的平均工作年限是 (3 + 2) / 2 = 2.50
个人解题思路
- 创建题中两张表
- 由题中
employee_id 是员工表 Employee 表的外键可知项目表是从表,员工表为主表 - 复合主键
constraint 约束名 primary key (字段名),唯一主键则直接字段 数据类型 primary key - 查询每个项目的平均工作年限需要分组查询
group by再根据项目中员工的experience_years进行avg平均计算 - 结果中平均工作年限的字段名为average_years,查询的时候记得起好别名
- 1.创建员工表-Employee
create table Employee(
employee_id int primary key,
name varchar(20),
experience_years int
)
- 2.创建项目表 Project
create table Project(
project_id int,
employee_id int,
primary key (project_id, employee_id),
foreign key (employee_id) references Employee (employee_id)
)
- 3.添加员工数据
insert into Employee(employee_id,name,experience_years)
values (1,'Khaled',3),
(2,'Ali',2),
(3,'John',1),
(4,'Doe',2);
- 4.查看员工表 是否添加成功
select * from Employee;
员工表
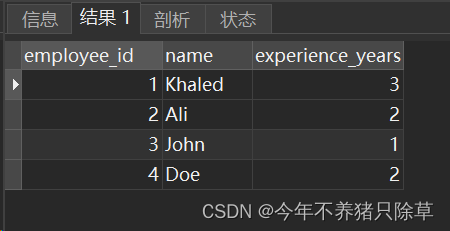
- 5.添加项目数据
insert into Project(project_id,employee_id)
values (1,1),
(1,2),
(1,3),
(2,1),
(2,4);
- 6.查看项目表 是否添加成功
select * from Project;
项目表
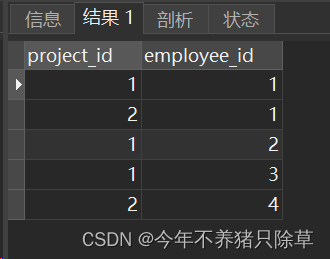
- 7.编写解决方案
select p.project_id,round(avg(experience_years),2) as average_years
from Project p,Employee e
where p.employee_id=e.employee_id
group by p.project_id
运行解决方案,如果成功则会出现下图,与题中所给示例一致
182. 查找重复的电子邮箱
- 题目
表: Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| email | varchar |
+-------------+---------+
id 是该表的主键(具有唯一值的列)。
此表的每一行都包含一封电子邮件。电子邮件不包含大写字母。
编写解决方案来报告所有重复的电子邮件。 请注意,可以保证电子邮件字段不为 NULL。
以 任意顺序 返回结果表。
结果格式如下例。
示例 1:
输入:
Person 表:
+----+---------+
| id | email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
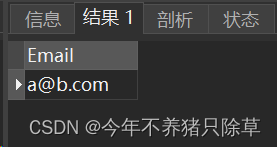
输出:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
解释: a@b.com 出现了两次。
个人解题思路
- 创建题中Person表
- 看到重复邮件可以选择用
count(Email),如果大于1则代表有重复 - 首先要按照email字段
分组查询,再在having内判断重复 - 最后题中返回结果字段是开头大写的Email 要注意
- 还可以使用内连接的方式,自己连接自己,条件内要加上
表1的id不等于表2的id避免自连,还要避免一个笛卡尔积的问题,在select后加上distinct即可解决
由于我是在一个库内写的这一系列练习题,所以小小改了一下表名
- 1.创建emailPerson表
create table emailPerson(
id int primary key,
email varchar(20)
)
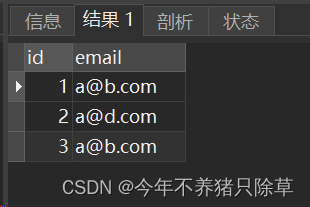
- 2.添加emailPerson数据
insert into emailPerson(id,email)
values (1,'a@b.com'),
(2,'a@d.com'),
(3,'a@b.com');
- 3.查看emailPerson表 是否添加成功
select * from emailPerson;
emailPerson表
- 4.编写解决方案
- 4.1方案一
select Email
from emailPerson
group by Email
having count(Email)>1;
- 4.2方案二
select distinct a.Email
from emailPerson a inner join emailPerson b
on a.Email=b.Email and a.Id<>b.Id;
运行解决方案,如果成功则会出现下图,与题中所给示例一致
之后的题目就都简化写了,留个印象
1148. 文章浏览 I
- 题目
Views 表:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| article_id | int |
| author_id | int |
| viewer_id | int |
| view_date | date |
+---------------+---------+
此表可能会存在重复行。(换句话说,在 SQL 中这个表没有主键)
此表的每一行都表示某人在某天浏览了某位作者的某篇文章。
请注意,同一人的 author_id 和 viewer_id 是相同的。
请查询出所有浏览过自己文章的作者
结果按照 id 升序排列。
查询结果的格式如下所示:
示例 1:
输入:
Views 表:
+------------+-----------+-----------+------------+
| article_id | author_id | viewer_id | view_date |
+------------+-----------+-----------+------------+
| 1 | 3 | 5 | 2019-08-01 |
| 1 | 3 | 6 | 2019-08-02 |
| 2 | 7 | 7 | 2019-08-01 |
| 2 | 7 | 6 | 2019-08-02 |
| 4 | 7 | 1 | 2019-07-22 |
| 3 | 4 | 4 | 2019-07-21 |
| 3 | 4 | 4 | 2019-07-21 |
+------------+-----------+-----------+------------+
输出:
+------+
| id |
+------+
| 4 |
| 7 |
+------+
个人解题思路
- 题中说作者id和浏览者id是相同的,那么在代码中写入这个条件就能知道是谁在浏览自己的文章
- 有重复行可以用
distinct去重 - 升序排列
asc降序排列desc
- 解决方案
select distinct author_id id
from Views
where author_id=viewer_id
order by author_id asc
最后结果如图
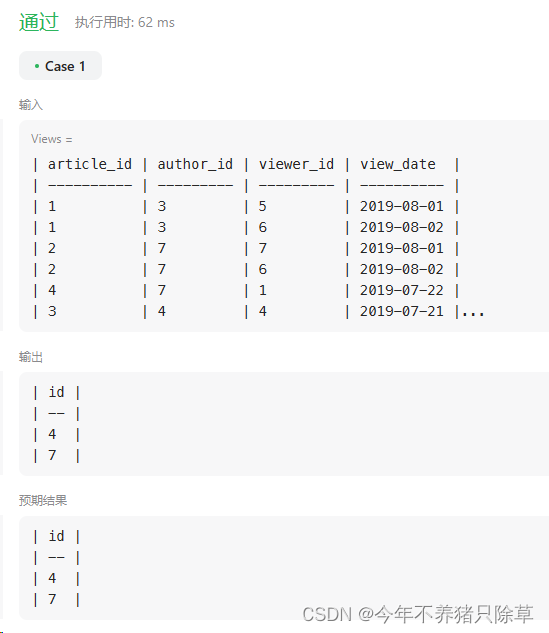
183. 从不订购的客户
个人解题思路
查询的是从不购物的客户,那么Orders表内就不会有这个客户的购物记录,我们只要嵌套一个查询就能得到不购物的客户
- 先查询购物的客户,得到他们的customerId
- 再查询不在这些customerId里的剩余customerId
select name Customers
from Customers
where Customers.id not in (select customerId from Orders)
最后结果如图

577. 员工奖金
个人解题思路
- 在empId相等的时候就能知道是哪些员工有奖金
- 这时我们要找的有奖金但小于1000的员工已经找到
- 此时还有员工表内没有奖金的员工,用奖金是空来表示,两者结合就是所有的奖金小于1000的员工
- 代码实现
select e.name,b.bonus
from Employee e left outer join Bonus b
on e.empId=b.empId
where b.bonus < 1000 or b.bonus is null
- 测试结果

584. 寻找用户推荐人
个人解题思路
- 寻找没被id=2的客户推荐的客户姓名,首先客户分为两类,一类是有老客户推荐的,一类是没有客户推荐的,那没被id=2的客户推荐的就包含了被其他客户推荐以及没有客户推荐的
- 其他客户推荐的可以写推荐id不为2
referee_id != 2,没有客户推荐的可以写referee_id is null
- 代码实现
select name
from Customer
where referee_id != 2 or referee_id is null
- 测试结果
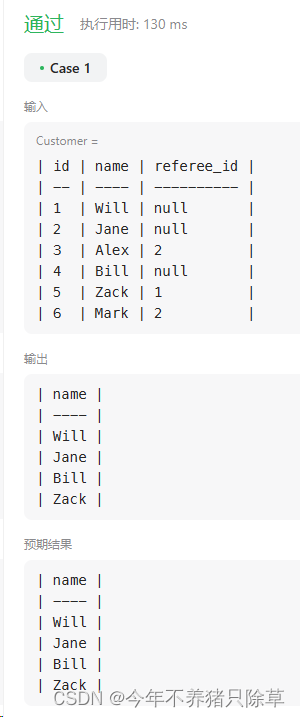
586. 订单最多的客户
个人解题思路
- 首先想到分组查询,将customer_number分组查询,这样就能按照顾客号将她们的订单分开
- 接着用降序排列order_number的次数,这样次数最多的就会在第一排
- 再用分页思想把排名第一的顾客号查询到,这样就解决了这个问题
- 代码实现
select customer_number
from Orders
group by customer_number
order by count(order_number) desc
limit 0,1
- 测试结果

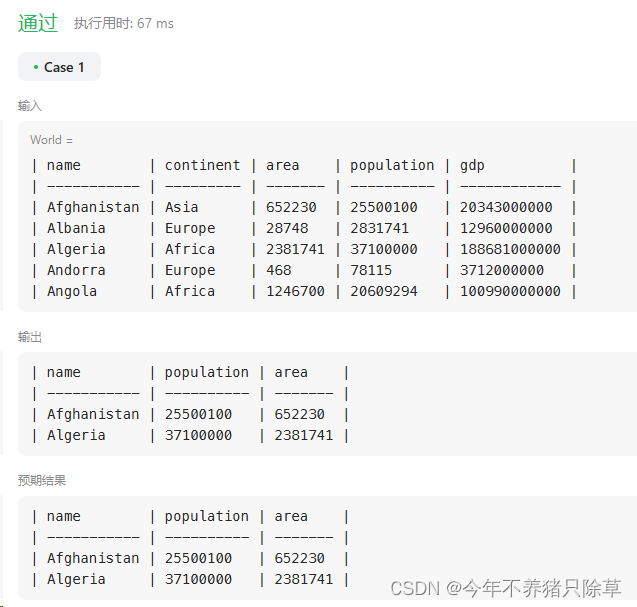
595. 大的国家
个人解题思路
满足条件之一即可认为该国是大国,可以在条件过滤语句中用or来连接两个条件
- 代码实现
select name,population,area
from World
where area>=3000000 or population >=25000000
- 测试结果















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











