







今天从第三章节:“实现细节”开始介绍。
目录
三、实现细节
我们在多尺度图像上训练和测试区域建议和目标检测网络。这是在KITTI目标检测基准[13]上基于CNN的目标检测的趋势。例如,在[16]中,输入图像被上采样4倍,在[17]中被上采样3倍。这可能是由于以下原因。(i) CNN的卷积层跨距大于1。(ii)最大池化层减少了空间维度。(iii)由于CNN网络是在固定的224 × 224尺度下进行预训练的,因此无法对不同尺度下的对象生成丰富的特征。我们在不同的尺度组合下训练和测试,这样最短的边有s个像素。
在训练过程中,每个真实值被分配到最接近的尺度。在测试过程中,通过非最大抑制(non - maximum suppression, NMS)单元(IoU阈值为0.7)筛选出最优的K1建议后,只选择最优的K2建议。此外,在每个尺度上独立地进行检测,稍后将它们连接起来并通过NMS单元(IoU阈值:0.3)来删除重复的检测框。
以下参数用于使用随机动量梯度下降进行4步交替训练。(i & iii)批处理大小:256。总迭代次数:80,000次。基本学习率:0.001。步长:60,000。学习率比例因子:0.1。动量:0.9。重量衰减:0.0001。(ii & iv)批量大小:128。总迭代次数:40,000次。其余参数保持不变。
四、实验
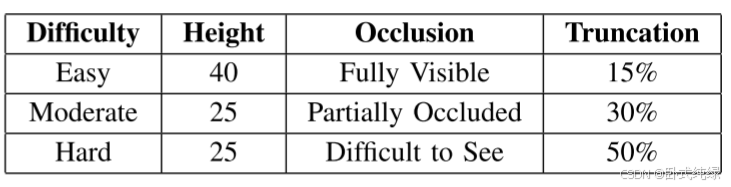
我们在KITTI目标检测基准[13]上评估了我们的方法,用于汽车检测任务。数据集按照[18]的建议分为训练和验证。训练集和验证集分别有3682张和3799张图像。我们通过包括图像的水平翻转版本来增强训练集。KITTI目标检测基准在表1中根据约束条件区分的3种不同难度设置下评估检测器的性能。我们在中等难度设置下进行训练和测试。硬真实值箱在训练和测试中都被认为是不关心箱。我们评估精确度召回曲线(AUC)下的面积作为检测器性能的衡量标准。如果某个真实值的IoU重叠大于0,则认为该检测边界框为真阳性,实验中固定为0.7。
我们在KITTI训练分割上使用ZF网络训练RefineNet模型(M1)。训练和测试在尺度s ={375, 750}上进行,分别是图像大小的{1x, 2x}。我们在3种不同的尺度(8,16和32)和3种不同的长宽比(1:1,1:2和2:1)下使用默认的9个锚。对于迭代1,我们将K1 = 6000和K2 = 300盒子(在第三节中定义)使用到Fast R-CNN网络中。在表2中,我们将AUC报告为细化迭代次数的函数,重叠为0.7。在这种严格的重叠要求下,我们演示了细化步骤仅通过1或2次迭代就能提高定位精度的能力。当N = 3时,M1最大AUC为81.58%。在K2 = 200时,运行时间从0.29秒减少到0.22秒,AUC减少不到0.4%。作为最后的实验,我们研究了锚箱数量的影响。具体来说,我们只训练了一个锚边界框(边长为67像素,居中为0,0的正方形)的RefineNet模型(M2)。同样,训练和测试按s ={375,750}的比例尺进行。根据我们之前的实验,我们设K1 = 1000。在K2 = 200时,运行时间减少到0.20秒,AUC减少不到0.9%。虽然运行时间的减少并不显著,但AUC从74.54%提高到80.69%,提高幅度超过6%。通过将锚盒的数量从M1中的9个减少到M2中的1个,我们减少了模型参数的数量。直观地说,这导致第一次迭代时AUC降低了4% (78.79% vs 74.54%),但是,RefineNet仅在另外两次迭代中就提高了检测质量。

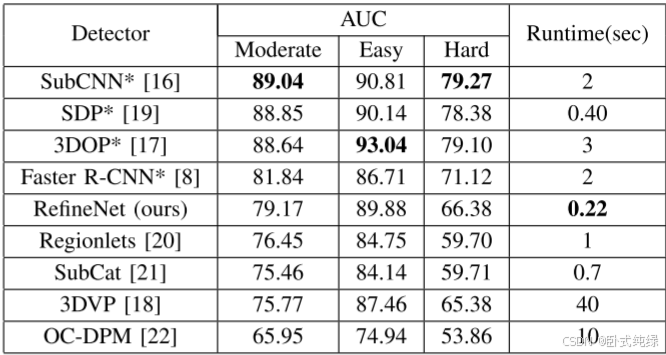
对KITTI目标检测基准的评估:我们用取自M1的参数训练一个RefineNet模型,并在整个训练集上训练它。该模型在KITTI基准上达到79.17%。在表III中,我们比较了不同难度设置下的AUC。SubCNN[16]和3DOP[17]在不同难度设置下共享最大AUC。然而,这带来了计算成本的显著增加。SubCNN在上采样输入图像上使用VGG16[3]高达4倍,而3DOP在上采样输入图像上使用VGG16[4]为3.5倍。SDP通过在VGG16的不同转换层使用级联分类器来解决小目标的检测问题。在使用ZF Net[14]来研究对检测器精度和运行时间的影响的同时,将这个想法与RefineNet结合起来会很有趣。
结果可视化:图3展示了以不同颜色可视化的RefineNet迭代示例图像。RefineNet被证明可以改善各种具有挑战性的情况下的边界框定位,包括小物体、部分截断和部分遮挡。我们在分析的低阈值处绘制检测结果,导致一些假阳性,但请注意,这些假阳性的得分通常低于可视化的真阳性。图展示了RefineNet的一些具有挑战性的情况,主要是由于严重遮挡。例如,图4描述了RefineNet在基线上有所改进,但仍然不能完全定位被遮挡车辆的情况(中图)。另一个例子是许多停在附近的车辆,在迭代改进步骤之后导致较少的局部化边界框。


五、总结贡献
在本文中,我们引入了一种名为RefineNet的新策略来提高车辆检测的定位精度,并在AUC下获得了高达6%的增益。我们的方法依赖于使用已经计算的特征,使检测器非常快。具体来说,RefineNet在每张图像上运行大约0.22秒。在KITTI目标检测基准测试中,在中等难度设置下达到79.19%。它是最快的检测器,达到70%以上的AUC。在简单的难度设置下,它达到了90%的AUC,接近最先进的结果。结果表明,采用ZF结构,该方法大大提高了检测性能。使用更深层的网络(如VGG)来提高性能,将在未来进行研究。
六、致谢
作者要感谢我们的相关行业合作伙伴的支持,审稿人的建设性意见,以及我们在智能和安全汽车实验室的同事的有益讨论和帮助。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









