







由于原论文中作者只给出了基于测试集的数据结果分析(结果如下),在自己花了一天的时间训练之后与官网中作者给出的验证集结果进行对比。
pointpillar官方链接:https://github.com/zhulf0804/PointPillars?tab=readme-ov-file
论文链接:https://arxiv.org/abs/1812.05784
代码:GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
算法复现:基于kitti数据集的3D目标检测算法的训练流程_mini kitti 数据集-CSDN博客
目录
一、测试集结果分析
(一)定量分析
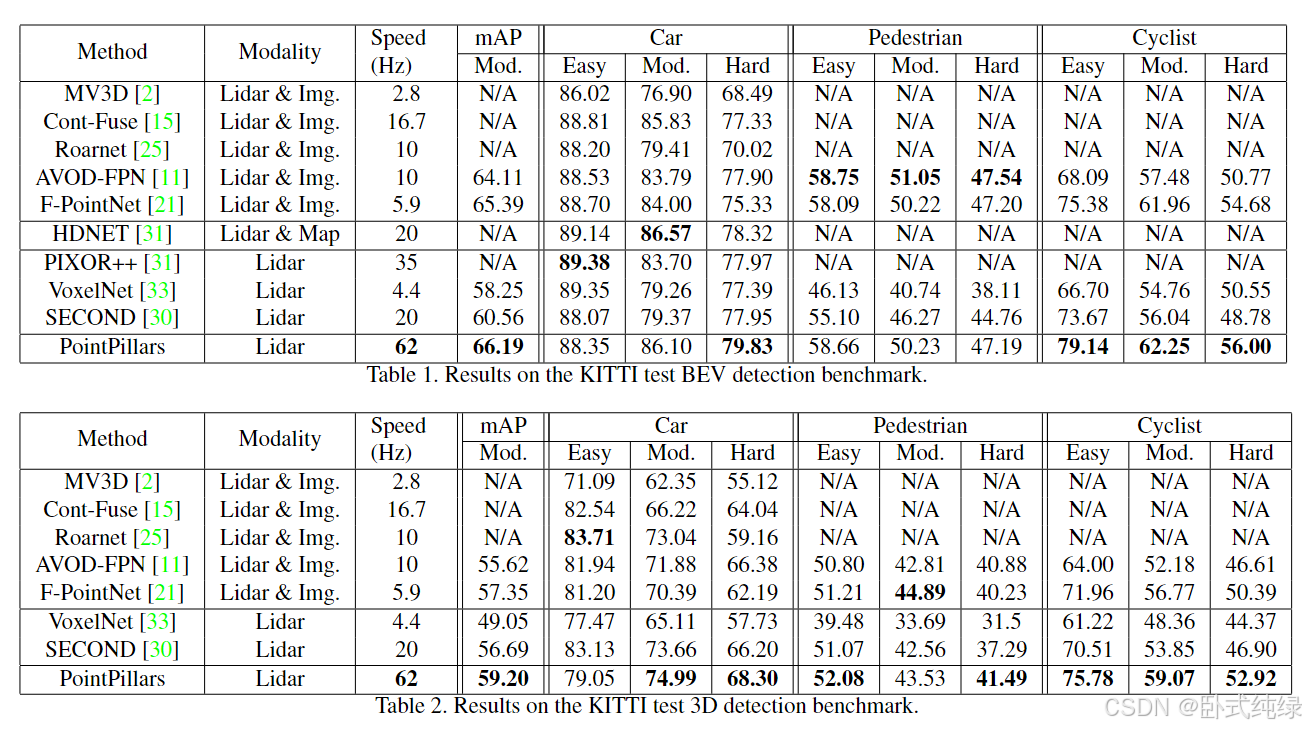
上表是KITTI测试BEV检测基准的结果,下表是KITTI测试3D检测基准的结果。所有检测结果均使
用官方KITTI评估指标进行测量,即:鸟瞰图(BEV)、3D、2D和平均方向相似度(AOS)。2D检测在图像平面上完成,平均方向相似度评估二维检测的平均方向(以BEV为单位测量)。KITTI 数据集分为简单、中等和困难的困难,官方 KITTI 排行榜按中等性能排名。如上表 所示,PointPillars 在平均精度 (mAP)方面优于所有已发布的方法。与仅激光雷达的方法相比,PointPillars 在所有类和难度层上都取得了更好的结果,除了简单的汽车层。它还优于基于汽车和骑自行车的人的融合方法。
虽然 PointPillars 预测 3D 定向框,但 BEV 和 3D 指标没有考虑方向。使用 AOS评估方向,这需要将 3D 框投影到图像中,执行 2D 检测匹配,然后评估这些匹配的方向。与仅预测定向框的两种 3D 检测方法相比,PointPillars 在 AOS 上的性能在所有层中显着超过。一般来说,只有图像的方法在2D检测上表现最好,因为盒子在图像中的三维投影可以导致松散的盒子,这取决于3D姿势。尽管如此,PointPillars中度自行车AOS为68.16优于最好的基于图像的方法。

(二)定性分析

上图是KITTI的定性分析。作者展示了激光雷达点云(上)的鸟瞰图,以及投影到图像中的3D边界框,以便更清晰的可视化。请注意,作者仅使用激光雷达。展示了汽车(橙色)、自行车(红色)和行人(蓝色)的基本事实(灰色)和预测框。框方向由从底部中心到框前面的直线显示。下图是KITTI上的失败案例。与上图中的相同可视化设置,但专注于几种常见的故障模式。
作者在两张图中提供了定性结果。虽然只在激光雷达点云上进行训练,为了便于解释,作者从 BEV 和图像的角度可视化 3D 边界框预测。图 3 显示了检测结果,具有紧密方向的 3D 边界框。汽车的预测特别准确,常见的故障模式包括困难样本(部分遮挡或远处的物体)上的假阴性或相似类(vans或trams)上的假阳性。检测行人和骑自行车的人更具挑战性,导致一些有趣的故障模式。行人和骑自行车的人通常相互错误分类(有关标准示例,请参见图 4a,图 4d 用于将行人和桌子组合分类为骑自行车者)。此外,行人很容易与极点或树干等环境的狭窄垂直特征混淆(见图4b)。在某些情况下,可以正确地检测到地面实况注释中缺少的对象(参见图 4c)。
二、验证集结果分析
(一)官方验证集结果
根据以下路径找到pointpillar文件夹: mmdetection3d/configs/pointpillars
点进去之后会出现文献,往下翻就能找到各种数据集的结果,这里我们找到kitti数据集、3 class的日志文件进去查看。
直接查看日志文件会有点乱(但没有办法),这里我们直接翻到文件最下面看到AP40的结果:

(二)复现结果
AP11结果
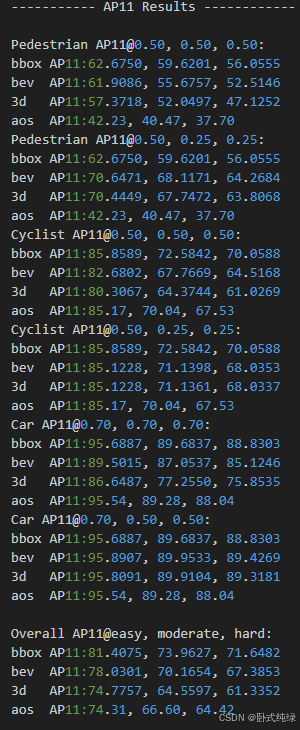
AP40结果:
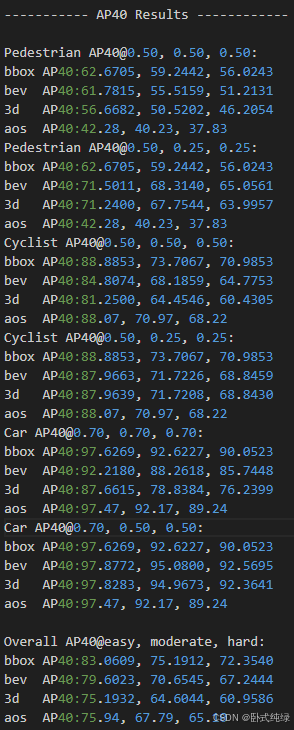
其中
- bbox:2D检测框的准确率
- bev:bird'eye view 鸟瞰图下的准确率
- 3d: 3D检测框的准确率
- aos:检测目标旋转角的检测率(Average Orientation Similarity 平均方向相似度)
- 三列代表的事不同困难程度下的结果,依次是easy(简单)、moderate(中等)和hard(困难)
- @0.7……代表的事bbox/bev/3d评估时的IoU的阈值
- AP_R40代表的是基于40个召回位置计算的AP
AP(Average Precision)指的是平均精度,AP11使用并不常见,现在大多采用的是AP40,它在计算精确率时使用了40个等间距的召回率值作为分类器的工作点。我们在对比结果时,主要看精度稳定的一项,对应图6即为每一类检测对象的第一块结果。
经过整体比较,本人复现结果较官方验证集数据更好,准确度方面都较高,复现结果整体较好(本人于4090服务器上训练,仅用了半天时间跑完80轮结)。

















 8728
8728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









