







今天我们继续学习各个激活函数层的实现过程。
目录
5.2 Sigmoid层
sigmoid函数的表达式如下:
用计算图表示的话如下:
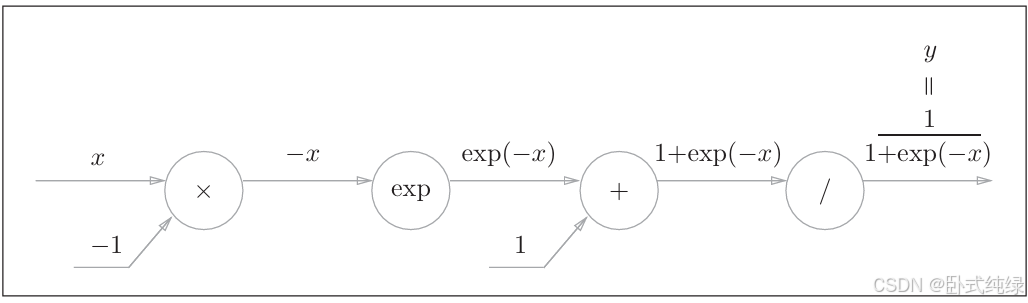
计算过程稍微有些复杂,且这里除了乘法和加法还出现了新的运算符号 exp以及除法“/”,exp节点会进行y=exp(x)的计算,“/”节点会进行的计算。
下面我们按照流程求出计算图的反向传播。
1、节点/:表示的是,则导数可以用高等数学的方法求解得到为:
,那么我们就知道了,在反向传播的时候,上游的值乘以-y2(正向传播的输出平方后取相反数)传给下游。则,除法的反向传播结果为:
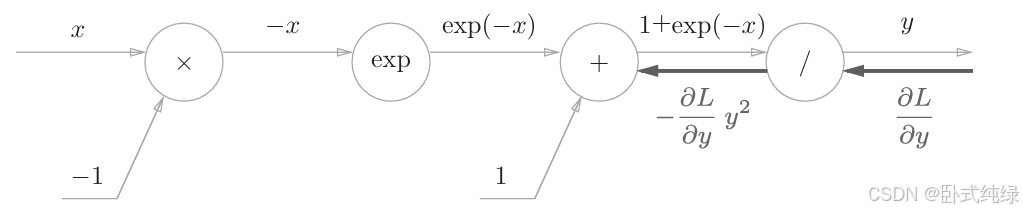
2、节点+:这个之前已经讨论过,直接将上游导数原封不动传给下游,不再赘述:
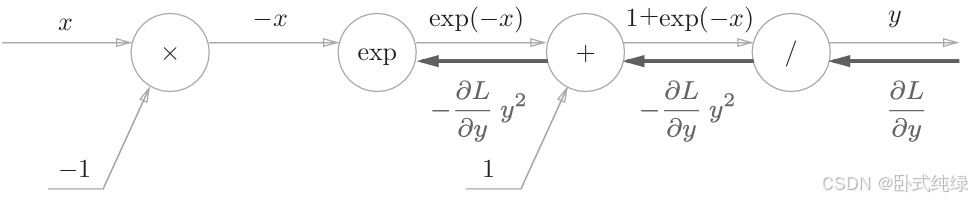
3、节点exp:表示的是,其解析式的导数与原式相同,故将上游导数乘以
(正向传播时的输出)传至下游。在我们这个例子中是
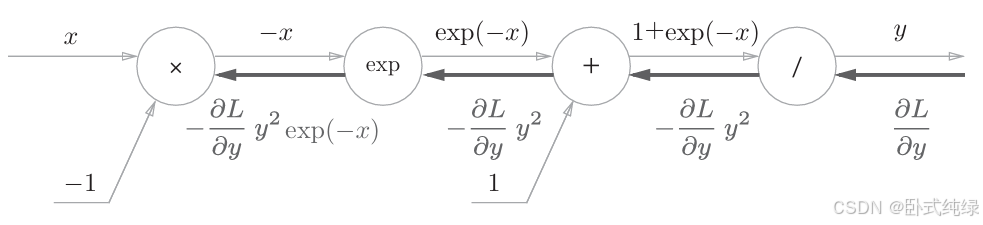
4、节点×:这里我们之前也讨论过,将上游的导数乘以输入值的翻转值后传至下游即可:
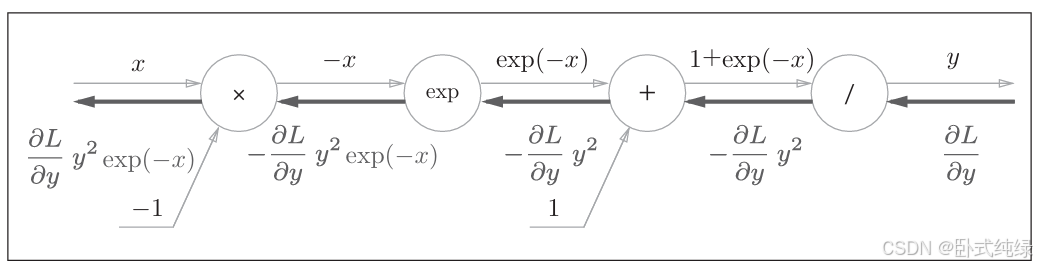
这样我们就得到了最终的反向传播计算图。
最后得到的这个结果中我们只用到了正向传播中的输入x和输出y,故我们可以在反向传播时简化中间的过程,直接得到最后的结果:
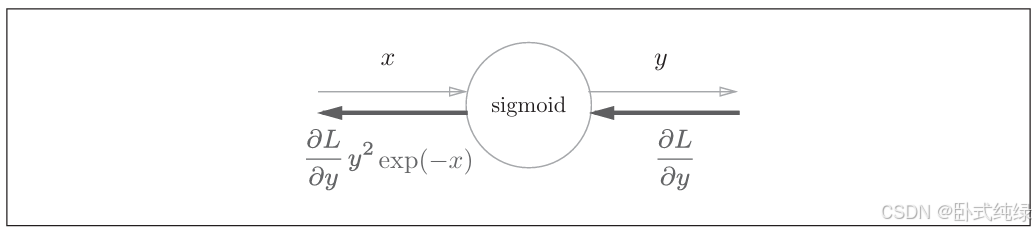
简化后的计算图省去了sigmoid函数计算过程中的繁杂步骤,只保留了输入和输出。另外,我们还可以对反向传播结果的值进一步简化:
在上述公式的基础上,我们就可以用python实现sigmoid函数类:
Class sigmoid:
def __init__(sekf):
self.out = None # 因为反向传播需要用到输出y 所以这里记录输出值
def forward(self,x):
out = 1 / (1+np.exp(-x))
return out
def backward(self,dout):
dx = dout * self.out * (1.0 - self.out)
return dx可以看到,sigmoid函数在初始化时保存了输出值y,是因为反向传播时会用到这个输出y。
六、Affine/Softmax层实现
6.1 Affine层
神经网络的正向传播在计算加权信号的总和时,会使用到矩阵乘积,也就是Numpy中的dot点积函数,例如下面的代码片:
X = np.random.rand(2) # 输入
W = np.random.rand(2,3) #权重
B = np.random.rand(3) #偏置项
X.shape #(2,)
W.shape #(2,3)
B.shape #(3,)
Y = np.dot(X,W) + B这里XWB形状分别是(2,)、(2,3)、(3,)的多维数组。这样加权计算就可以用最后一行的表达式实现,Y再经过激活函数的转换后将结果传递给下一层,这就是神经网络的正向传播。矩阵的乘积必须保证对应维度一致如下面的例子:
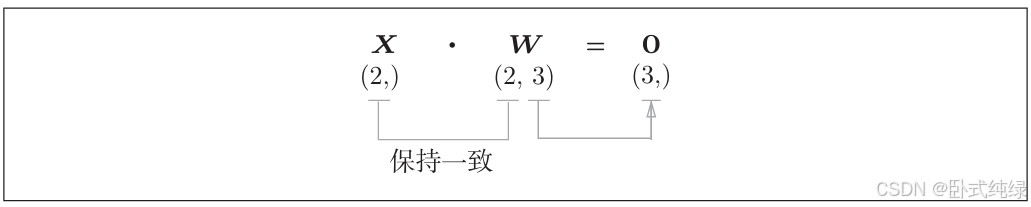
神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换”。因此,这里将进行仿射变换的处理实现为“Affine层”.(仿射变换包括一次线性变换和一次平移,分别对应神经网络的加权和运算与加偏置运算)
下面我们看一个比较简单的Affine层计算图:
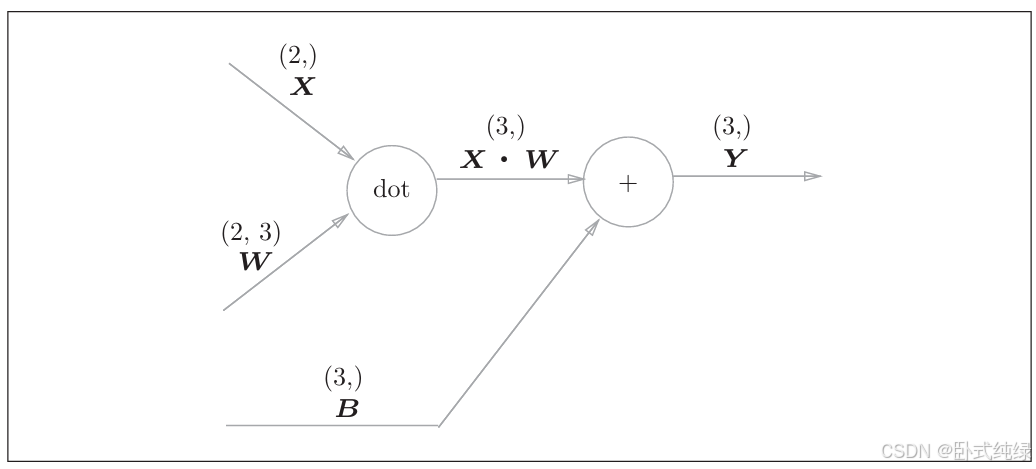
这里实现的就是上面我们代码所展示的过程,这里都是矩阵乘积和加减,之前我们学习的计算图中的各个节点都是标量,这里传播的节点都是矩阵。相当于从一维提升至二维。
现在我们考虑一下这个计算图的反向传播,步骤其实和标量的计算图一致。
首先加号,反向传播导数值不变,所以Y、X*W和B的导数值均为,L为最终输出值。
其次是点积,其实和标量中的乘法相同,所以X和W的导数值是上游导数值与反转后的输入值相乘的结果。最终得到这样的结果:
这里由于是矩阵乘法,所以要考虑维度的匹配,这里的上标T表示矩阵的转置,即行列互换。
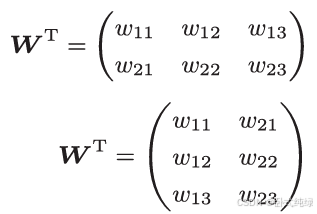
可以看到初始W矩阵为(2,3),则转置后的矩阵维度为(3,2)
计算完成之后我们尝试写出计算图的反向传播:
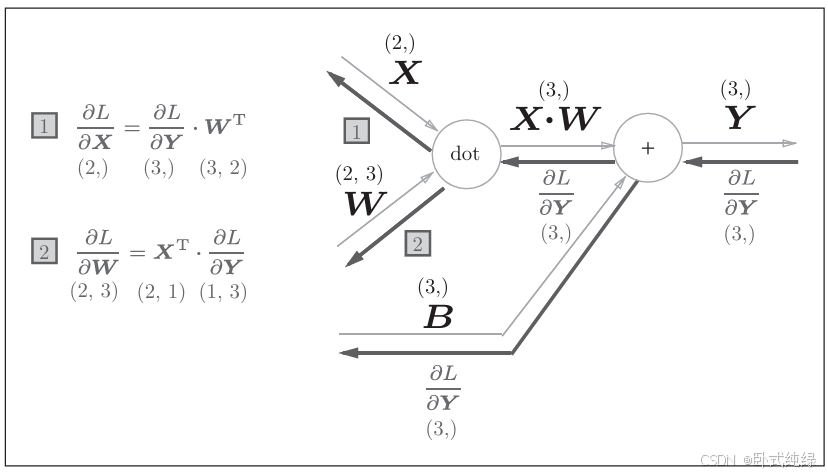
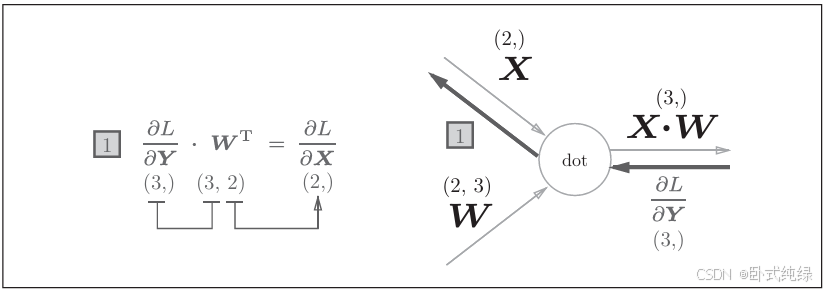
左边为我们标识了每个矩阵的维度,千万记住保证矩阵的维度匹配,否则会报错。
我们再来看看每个变量的形状:这里可以看到X和相同,W和
相同。
6.2 批处理版本
之前学习的Affine层输入都是一个单独的数据X,现在我们要考虑N个数据的情况,即批处理版本的Affine层。
先给出批处理版本的计算图:
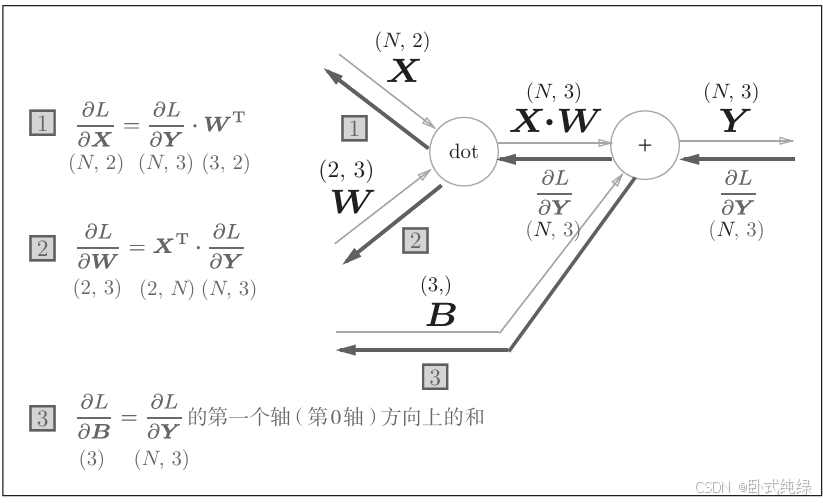
现在的输入形状为(N,2),反向传播时要注意观察矩阵的形状,这样就可以推导出X和W的导数值。
还要注意的是,偏置项B在正向传播时会加到每个数据上,例子如下:

正向传播的偏置项会给每一个元素添加,故在反向传播中,各个数据的反向传播导数值需要汇总为偏置的元素。代码表示如下:

这里sum函数中的两个参数分别是原始数组和按轴相加,axis=0则表示按照数组的第0轴(即以数据为单位的轴)的方向上进行求和。
综上所述,我们的Affine层实现如下:
Class Affine:
def __init__(self,w,b):
self.w = w
self.b = b
self.x = None
self.dw = None
self.db = None
def forward(self,x):
self.x = x
out np.dot(x,self.w) + b
return out
def backward(self,dout):
dx = np.dot(dout,self,w.T)
self.dw = np.dot(self.x.T,dout)
self.db = np.sum(dout,axis=0)
return dx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









