







 本文介绍了一种结合EfficientNet_b3与UNet的网络结构,利用EfficientNet_b3强大的特征提取能力替换UNet的下采样部分,提高了整体模型性能。通过详细展示网络构建代码,为读者提供了实现参考。
本文介绍了一种结合EfficientNet_b3与UNet的网络结构,利用EfficientNet_b3强大的特征提取能力替换UNet的下采样部分,提高了整体模型性能。通过详细展示网络构建代码,为读者提供了实现参考。
本文采用Efficientnet_b3作为主干网络替换unet的下采样部分,使网络提取特征更强大
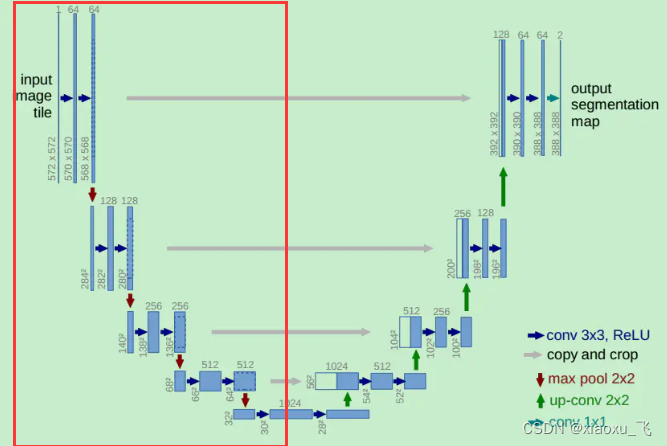
将红色框的信息替换修改
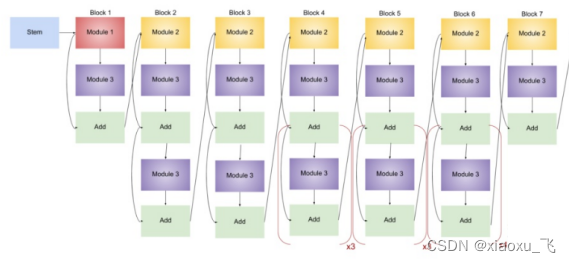
搭建上采样block
import torch
import torch.nn as nn
import torchvision.models as models
from torchsummary import summary
#基本的block
class DecoderBlock(nn.Module):
def __init__(self,
in_channels=512,
n_filters=256,
kernel_size=3,
is_deconv=False,
):
super().__init__()
if kernel_size == 3:
conv_padding = 1
elif kernel_size == 1:
conv_padding = 0
# B, C, H, W -> B, C/4, H, W
self.conv1 = nn.Conv2d(in_channels,
in_channels // 4,
kernel_size,
padding=1,bias=False)
self.norm1 = nn.BatchNorm2d(in_channels // 4)
self.relu1 = nn.ReLU(inplace=True)
# B, C/4, H, W -> B, C/4, H, W
if is_deconv == True:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









