







我们定义了一个函数
countUniqueChars(s)来统计字符串s中的唯一字符,并返回唯一字符的个数。例如:
s = "LEETCODE",则其中"L","T","C","O","D"都是唯一字符,因为它们只出现一次,所以countUniqueChars(s) = 5。本题将会给你一个字符串
s,我们需要返回countUniqueChars(t)的总和,其中t是s的子字符串。输入用例保证返回值为 32 位整数。注意,某些子字符串可能是重复的,但你统计时也必须算上这些重复的子字符串(也就是说,你必须统计
s的所有子字符串中的唯一字符)。示例 1:
输入: s = "ABC" 输出: 10 解释: 所有可能的子串为:"A","B","C","AB","BC" 和 "ABC"。其中,每一个子串都由独特字符构成。所以其长度总和为:1 + 1 + 1 + 2 + 2 + 3 = 10示例 2:
输入: s = "ABA" 输出: 8 解释: 除了 countUniqueChars("ABA") = 1 之外,其余与示例 1 相同。示例 3:
输入:s = "LEETCODE" 输出:92提示:
1 <= s.length <= 10^5s只包含大写英文字符
解题思路
本题需要统计所有字符子串中单个字符的数量,所以可以对单个字符进行分析,如果分析所有的子串,是不好处理的。因为最多就26个字符,分析每一个,然后全部加起来的可以。
分析任意一个字符ch,由题意有子串中只有单个字符出现才可以计算。所以只需考虑所有只包含单个字符ch的子串。
- 遍历字符串,开始查找字符ch,找到第一个后开始统计包含ch的子串数目,可以设置两个变量l,r来表示从起始位置到第一个ch的距离。注意由于字符串从0开始遍历,所以
l
,
r
l,r
l,r初始化为-1。在查找到第一个ch以后,将l赋值为r,r赋值为i(i是找到的ch的下标),所以此时包含第一个ch的字符子串数目为
r
−
l
r - l
r−l,i继续向后走,但是注意,i每向后走一个字符,就会多出由ch组成的
r
−
l
r-l
r−l个字符子串,所以向后寻找的过程中,循环执行
res += r - l。 - 找到第一个ch以后,需要开始统计第二个ch,但是注意的是统计第二个ch,不可以将第一个ch包含,这也就是将 r − l r-l r−l而不是 r − l + 1 r-l+ 1 r−l+1的原因,然后重复1的操作。直到遍历完字符串。
分析一个样例:对于s = “ABCDAEFG”
首先统计’A’, 初始化l,r为-1。遍历字符串,查找’A’.
1️⃣找到A,下标为0,更新l, r。执行res += r - l,此时统计的字符子串是"A", 继续向后寻找下一个’A’,在寻找的过程中,会扫描到’B’, ‘C’,‘D’,可以与’A’构成"AB", “ABC”,“ABCD”,所以在向后寻找的过程中,res += r - l循环执行。
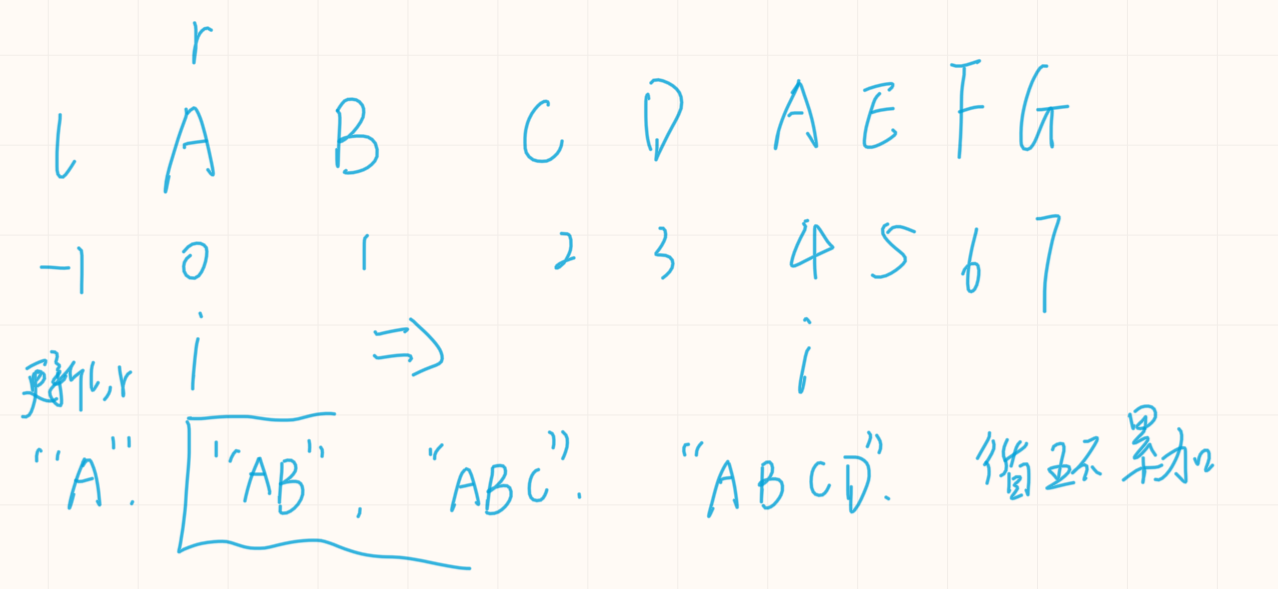
2️⃣继续寻找’A’,第二个’A’的下标为4,然后更新l,r。执行res += r - l,此时统计的子串为"BCDA",“CDA”,“DA”,“A”。
然后继续向后寻找下一个’A’,直到遍历完字符串。向上面一样,res += r- l 循环执行,向后走一步,新子串的数量就增加
r
−
l
r - l
r−l个。
例如走到’E’,新增加的包含第二个’A’的子串为"BCDAE",“CDAE”,“DAE”,“AE”。

上面的操作完成了一个字符的统计,一共可能存在26个字符,循环查找统计就可以求出所有子串的单个字符数量。
代码
class Solution {
public:
int uniqueLetterString(string s) {
int res = 0;//统计答案
//循环所有字符
for(char ch = 'A'; ch <= 'Z'; ch++)
{
//注意l, r的初始值为-1,因为需要下标是从0开始的
for(int i = 0, l = -1, r = -1; i < s.size(); i++)
{
//查找到了字符就更新l,r
if(ch == s[i])
{
l = r;
r = i;
}
//统计[l, r]的长度,不包含左边界l
res += r - l;
}
}
return res;
}
};















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









