







神经网络学习笔记——神经网络基础(二)
四、参数初始化
在构建网络之后,网络参数需要初始化,主要就是权重和偏置。偏重一般初始化为 0 即可,而对权重的初始化则会更加重要。
常见的初始化方法有随机初始化、全0初始化、全1初始化、Kaiming 初始化、Xavier 初始化等。
import torch
import torch.nn.functional as F
import torch.nn as nn
# 1. 均匀分布随机初始化
def test01():
linear = nn.Linear(5, 3)
# 从0-1均匀分布产生参数
nn.init.uniform_(linear.weight)
print(linear.weight.data)
# 2. 固定初始化
def test02():
linear = nn.Linear(5, 3)
nn.init.constant_(linear.weight, 5)
print(linear.weight.data)
# 3. 全0初始化
def test03():
linear = nn.Linear(5, 3)
nn.init.zeros_(linear.weight)
print(linear.weight.data)
# 4. 全1初始化
def test04():
linear = nn.Linear(5, 3)
nn.init.ones_(linear.weight)
print(linear.weight.data)
# 5. 正态分布随机初始化
def test05():
linear = nn.Linear(5, 3)
nn.init.normal_(linear.weight, mean=0, std=1)
print(linear.weight.data)
# 6. kaiming 初始化
def test06():
# kaiming 正态分布初始化
linear = nn.Linear(5, 3)
nn.init.kaiming_normal_(linear.weight)
print(linear.weight.data)
# kaiming 均匀分布初始化
linear = nn.Linear(5, 3)
nn.init.kaiming_uniform_(linear.weight)
print(linear.weight.data)
# 7. xavier 初始化
def test07():
# xavier 正态分布初始化
linear = nn.Linear(5, 3)
nn.init.xavier_normal_(linear.weight)
print(linear.weight.data)
# xavier 均匀分布初始化
linear = nn.Linear(5, 3)
nn.init.xavier_uniform_(linear.weight)
print(linear.weight.data)
if __name__ == '__main__':
test07()
五、优化方法(Optimizer)
机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣,同时利用损失函数来提升算法模型.这个提升的过程就叫做优化(Optimizer)
1.指数加权平均
我们最常见的算数平均指的是将所有数加起来除以数的个数,每个数的权重是相同的。加权平均指的是给每个数赋予不同的权重求得平均数。移动平均数,指的是计算最近邻的 N 个数来获得平均数。
指数移动加权平均则是参考各数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近则对平均数的计算贡献就越大(权重越大)。
表示的是之前情况对现有情况的影响

2.Momentum
当梯度下降碰到 “峡谷” 、”平缓”、”鞍点” 区域时, 参数更新速度变慢. Momentum 通过指数加权平均法,累计历史梯度值,进行参数更新,越近的梯度值对当前参数更新的重要性越大。
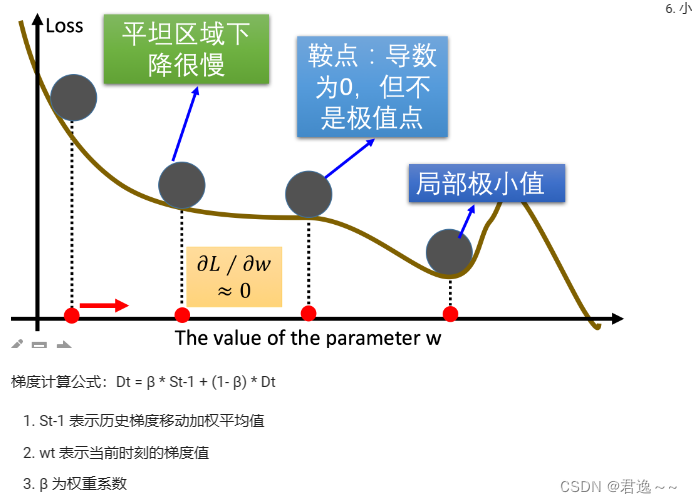
当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。一定程度上有利于降低 “峡谷” 问题的影响。峡谷问题:就是会使得参数更新出现剧烈震荡.
利用历史梯度值,克服一些优化情况中的特殊点。
3.AdaGrad(自适应梯度算法)
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小,开始离最优目标较远,可使用大一点的学习率加快训练速度,但是随着训练次数增加,需要将学习率不断降低,防止跳过最优目标。
- 初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
- 初始化梯度累积变量 s = 0
- 从训练集中采样 m 个样本的小批量,计算梯度 g
- 累积平方梯度 s = s + g ⊙ g,⊙ 表示各个分量相乘

AdaGrad 缺点是可能会使得学习率前期下降太多,导致模型训练后期学习率太小,训练过程较长,导致较难找到最优解。
4.RMSProp(自适应学习率方法)
RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数移动加权平均梯度替换历史梯度J加当前梯度的平方和。其计算过程如下:
- 初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
- 初始化参数 θ
- 初始化梯度累计变量 s
- 从训练集中采样 m 个样本的小批量,计算梯度 g
- 使用指数移动平均累积历史梯度,公式如下:

RMSProp 与 AdaGrad 最大的区别是对梯度的累积方式不同,RMSProp 通过引入衰减系数 β,控制历史梯度对历史梯度信息获取的多少. 被证明在神经网络非凸条件下的优化更好,学习率衰减更加合理一些。
AdaGrad 和 RMSProp 都是对于不同的参数分量使用不同的学习率,如果某个参数分量的梯度值较大,则对应的学习率就会较小,如果某个参数分量的梯度较小,则对应的学习率就会较大一些
5.Adam
Momentum 使用指数加权平均计算当前的梯度值、AdaGrad、RMSProp 使用自适应的学习率,**Adam 结合了 Momentum、RMSProp 的优点,使用:移动加权平均的梯度和移动加权平均的学习率。**使得能够自适应学习率的同时,也能够使用 Momentum 的优点。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











