






主要记录一些自己学习中觉得比较重要和容易出错的地方,鸽了好久都没学完的一门武林秘籍。
参考的王爽老师的汇编语言这本书,大部分指令是分散在各个章节中的,在记录中也额外设置了小标题,可以快速索引到。
Debug
Debug的一些配置
配置参考师傅博客:https://blog.csdn.net/lcr_happy/article/details/52491107
下载好DOSBox和debug.exe link.exe masm.exe
将上述EXE文件放到一个名字短路径段的文件夹中,比如F:\tmp
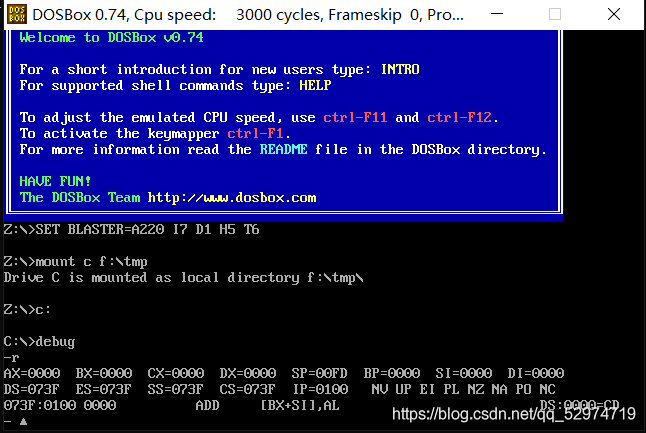
输入mount c f:\tmp (自己定义的文件夹)
出现非报错语句后输入 c:
接着便可使用debug、masm、link了
debug 可用于调试EXE 看各个寄存器的变化状态
masm 是用于编译汇编源程序
link 是进行连接
连接干了什么:
连接源程序分开写的目标文件
源程序中调用了一些外部库
将OBJ文件中的机器指令转为可执行
简单的进行编译和连接,不考虑中间文件:
编译: masm 1.asm;
连接: link 1.OBJ
调试:debug 1.EXE 可用Tab不全,文件应同在F:\tmp目录下,即存放3个EXE的目录
Debug的一些指令
r 指令 查看或改变寄存器的值
r是查看全部寄存器
r + 寄存器的名 是查看某一指定寄存器
r + 寄存器 在 : 后输入即为改变寄存器的值 空格不处理 回车直接不改变
d指令 查看内存中的值 d + 地址(段地址:偏移地址格式)
d 1000:0 查看10000H处内存值,默认输出128B单元
d 段地址: 偏移地址1 偏移地址2 类似python切片 查看地址1~地址2间的内容
e指令 修改内存值,可用来写入数据或指令的机器码
e + 段地址:偏移地址 a b c d ...用来写入数据
e + 地址 会出现XX. 在.之后可输入自己要把XX改为的值 ,空格不处理 ,回车结束。
a指令 直接向某一地址中写入汇编指令
a + 段地址:偏移地址
t指令 执行当前CS:IP所指向的指令(一般是一条),涉及对ss的修改可能连带对sp的赋值一起修改。类似单步步入
p指令 用来执行int 21H 或 执行loop s (执行到cx=0 循环结束的下一条指令)
g指令 g + 段地址:偏移地址 可以直接将该地址之前的指令执行完 要u指令看仔细了 并不是的连着的 指令长度不一样
q指令 退出debug
源程序注意事项
1、要指明段开头和段结尾 XXsegment 和 XX ends
2、数据不能以字母开头,如 ffffH 必须写成 mov ax,0ffffH,指令不分大小写!!!
3、要指明程序结尾 end
4、源程序会将mov ax,[0] 识别为 mov ax,0 所以 如果是内存赋值的话要加上ds:前缀。
或者mov bx,0 通过mov ax [bx]来间接访问。
5、end指令也可以用来标明程序入口,end start ,start指向第一条汇编指令,start的本质也是地址(偏移地址,相对于代码段)
6、如果只用了ss而没给sp赋值的话,sp默认为0,用法就类似一个ds寄存器。
1、开辟空间
dw为定义字型数据 word 2个字节
db为定义字节型数据 byte 1个字节
dd用来定义双字 dword 4个字节
dup 操作符 结合 dd dw db来开辟空间,多进行数据的复用
可理解为开辟空间,如果跟dw 0123h 就可以理解为开辟一个字的空间,内容为0123h(可能不等价于段的大小)
对dw数据操作 每次add bx 2 对db操作每次inc bx
定义字符串
db 'hello' 没有高级语言的'\0',本质还是这5个字节的ASCII码
dup 举例
如 db 3 dup(0) 即开辟3个字节空间,值都为0
而db 3 dup(0,1,2) 则是开辟9个字节空间,值分别为0,1,2,0,1,2,0,1,2…
总结 :dx(db,dw,dd) 重复的次数 dup(重复的x型数据)
nop指令 的机器指令只占一个字节的空间
6、标号的本质都可理解为段地址
第五章、LOOP和[bx]
1、基础
loop 和 cx结合来控制循环,在loop指令前设计一个标号s,每次执行loop会自动将cx减1,如果cx=0就继续执行loop下面的指令,否则就跳转到s继续执行。
s本质上是个偏移地址,在debug调试中可明显看出loop后跟了一个偏移地址,也算是改变IP的一个方式。
[bx]本质上也是内存中的数据,地址为(DSx16 + bx),还是逃不出基地址+ 偏移地址的圈子
在载入程序时,CX中存放的是程序的长度(多少字节)
2、实验(3)
写一段汇编程序,将"mov ax,4c00H"之前的指令复制到0:200之处。
在写程序之前我们要思考,从哪里开始复制,复制少长度,可能一上来有点懵,所以先通过debug打开一个EXE看一下初始状态。
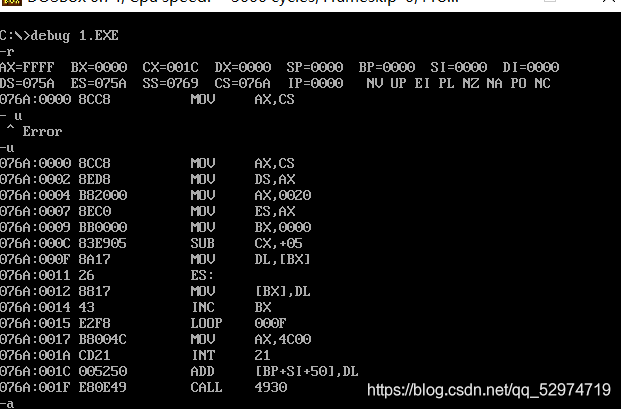
在载入程序时,CX中存放的是程序的长度(多少字节),通过u指令也可已看出在0017H到001C前存放的是返回的指令,一共五个字节。
所以mov前的指令一共是CX-5个字节,所以完成拷贝循环CX-5次,所以在程序中直接对CX 进行
SUB CX 5即可,一个一个字节copy
故源程序:
assume cs:code
code segment
mov ax,cs
mov ds,ax //不能mov 段寄存器 和 段寄存器 不能用立即数给段寄存器赋值
mov ax,0020H
mov es,ax
mov bx,0
sub cx,5
s: mov dl,[bx] //不能mov 内存到内存,在debug中会出错
mov es:[bx],dl
inc bx
loop s
mov ax,4C00H //源程序可加H来标明16进制
int 21H
code ends
end
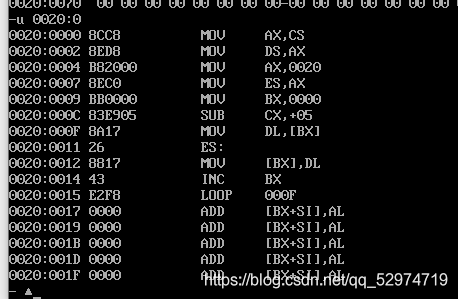
debug调试,查看功能是否实现。
第六章 包含多个段的程序
理解本章要有一个大局意识,即我们不能随意更改一片内存(可能存放有关程序的重要值),所以为了内存合法,需要在源程序中定义出段来讨内存,这样在加载程序时系统会给我们分配内存,这些内存是合法的,修改不会出现错误。
另一种方法是在程序执行时,向系统申请,不过没深入讨论。
1、 栈、数据、代码公用一个段
本质是使用end start来标明入口点,start应该是表示入口地址的偏移地址部分。
从一个混合实例中学习:
利用栈将程序中定义的数据逆序
assume cs:code
code segment
dw 0123h,0456h,0678h,0abch,0defh,0fedh,0cbah,0987h
dw 0,0,0,0,0,0,0,0
logo: mov ax,cs
mov ds,ax
mov ss,ax
mov sp,20h
mov bx,0
mov cx,8
s: push [bx]
add bx,2
loop s
mov bx,0
mov cx,8
s0: pop [bx]
add bx,2
loop s0
mov ax,4c00h
int 21h
code ends
end logo
上述log即start,也说明这种标号的名称是可变的,但尽量有意义,为了增加代码的可读性。
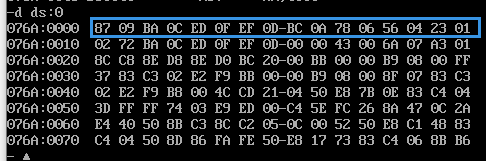
可知上述程序代码段,一开始定义了8个字型数据,接着开辟了8个字的空间作为栈来进行逆序操作。
ds和ss中的值都为CS的值,IP的值因为start标号而改变为0020H

在这个内存分配中0010~001F的内存为栈空间,所以设置sp的值为0020H,要根据实际情况来判断sp的值。
2、多个段编写源程序
1、定义了多个段,代码操作就普通入栈和出栈,主要debug运行后查看cs,ss,ds寄存器的值
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,10h
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
mov ax,stack,stack是栈段段名,是标号,直接理解为一个地址就行了。
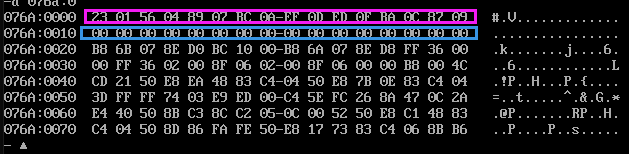
刚进入debug时各个寄存器的值

运行到返回前各个寄存器的值

可见最后DS=076A,SS=076B,CS=076C,不难发现DS、SS和CS值在内存中是连续的,DS和SS相差10H个字节,SS和CS相差10H个字节,仔细看源程序便知,ds和ss都是8个字的大小,即16个字节(这是能被16整除下,详见段的大小),如图。
3、各个段的位置和执行
为什么DS最终是076A开始,而刚刚进入时DS是075A呢?
这与可执行文件的结构有关,可执行文件由描述信息和程序构成,在内存中真正程序开始处之上还有256字节的PSP程序前缀(用于通信,保存一些相关信息),所以DS一开始保存地址 和 真正的程序部分还相差0010H。
同时,按照我们之前的学习,一般是CS和DS(开始时的075A)相差0010H才对,而上图中CS为076C,不符合常规,其实之前我们的源程序,只有代码段,根据程序和机器码位置一 一对应,程序入口处即代码段的汇编指令。而上述多个段的程序刚开始是定义了DS和SS段,程序刚一入口并不是汇编指令,而是开辟了内存空间,这也是为什么修改后的DS和一开始的DS相差了0010H。
而至于CS为什么是076C则是end start指令指明了真正的程序入口,会在加载程序时改变CS:IP的值,使它指向代码段的第一条汇编指令。
当然如果我们改变源程序的顺序,比如:
assume cs:code,ds:data,ss:stack
code segment
mov ax,stack
mov ss,ax
mov sp,10h
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
end
编译、连接后debug的载入情况
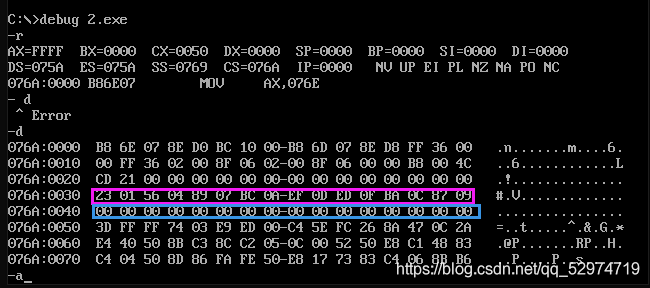
发现改变了源程序的顺序,可执行文件中的指令顺序也做出了同步的改变,把代码段放在源程序首部(并且代码段第一句话就是有效指令)则不需要end start标明。如图CS:IP指向也是第一条汇编,并且CS和DS的初始差又变为了0010H,之后内存依次是ds和ss。
起初以为stack的定义在mov stack之后会报错,实际发现并没有发生报错并且第一个指令mov ax,076E准确指明了栈段,感觉应该是在加载程序时内存已经同时分配好了,(不像是高级语言的编译器,从上往下摸,在上面找不到定义就报错)。
再参考第四章p79的图4.2,如下
这也表明了源程序的顺序和内存中机器指令的顺序有个一 一映射的关系,各段在内存中的顺序取决于在远程序中的定义,所以如果源程序中第一个不是代码段则需要end start标明程序入口
如果不指明入口位置,则程序从所分配的空间开始执行
4、段的大小
如果段的数据占N个字节,则程序加载后,段的空间为((N+15)/16) x 16
首先要知道,一个段的大小,最小为16字节最大为(2^16) 64KB,为什么最小为16个字节呢,因为段的起始地址必须为16的倍数,如00010H,段地址为0001H而00011H当然不行,因为00011H的段地址还是0001H,只不过偏移地址是0001H,所以下一个段地址为0002H(最小段的情况下),所以一个段最小为16B,而最大为64KB因为8086的寄存器为16位,最大也就能偏移0~FFFFH为64KB。
所以如果N为16的整数倍,则段的大小就为(N/16) x 16
否则 为 (N/16 + 1) x 16 (N/16)只取整数部分
合成一个式子 变为 [(N+15) /16 ] x 16
例如,在开辟段时,数据段和栈段个占2个字,分配的内存大小仍为16B。
data segment
dw 0123h,0456h
data ends
stack segment
dw 0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,10h
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
在设置栈顶时便能发现是 mov,sp,10h 是按照16字节的大小来的

debug查看到压栈完成后的内存,栈后两位为0123h 和 0456h
由于栈的中断机制,栈中压入了一些cpu的状态,隐约看到CS的值076CH目前不是太懂,等待后续解决。
5、实验5
上述操作已完成实验的前部分,下面主要是实验(5)(6)
1、 实验(5):
编写程序实现将a段和b段中的数据依次相加,结果保存到c段
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
code segment
start: mov ax,c
mov es,ax //c段的段地址用es来存放
mov bx,0
mov cx,8
s: mov dx,a
mov ds,dx
mov al,[bx]
mov dx,b
mov ds,dx
add al,[bx] //用ds寄存器来实现a段和b段内数据相加
mov es:[bx],al
inc bx
loop s
mov ax,4c00h
int 21h
code ends
end start
注意:不能直接mov ds,a等,a,b,c标号即代表着在内存中的段地址。
另:用到三个寄存器,ds,ss,es,如果程序没有其他栈操作ss可直接当做ds来用。
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
code segment
start: mov ax,c
mov es,ax
mov ax,a
mov ds,ax
mov ax,b
mov ss,ax //不设置sp sp默认为0
mov bx,0
mov cx,8
s: mov dl,[bx]
add dl,ss:[bx]
mov es:[bx],dl
inc bx
loop s
mov ax,4c00h
int 21h
code ends
end start
2、 实验(6)
编写code代码,用push指令将a段中的前八个字型数据逆序存到b段中。
因为是逆序存到b段中,所以考虑把b段当成栈段来用,可以assume ss:b来说明一下
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 0,0,0,0,0,0,0,0
b ends
code segment
start: mov ax,a
mov ds,ax
mov ax,b
mov ss,ax
mov sp,10h
mov bx,0
mov cx,8
s: push [bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
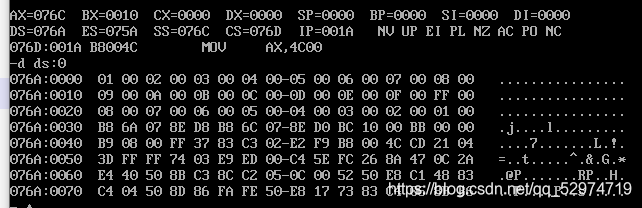 debug查看结果,可知076a到076c之前的32个字节为a段,076c这16个字节为b段,下面接代码段的机器码。
debug查看结果,可知076a到076c之前的32个字节为a段,076c这16个字节为b段,下面接代码段的机器码。
第七章 灵活的寻址方法
1、基础内容
and 和 or指令
and 指令 进行与运算 对应python的 & 和离散的合取
or 指令 进行或运算 对应python的 | 和离散的析取
and 用来讲某一位设置成0 ,or 用来讲某一位设置成 1
例如:
mov al ,10000111B
如果将al的第1位置0(从0开始,第0位,对应第n位十进制为2^n)
and al,11111101B 将第一位(第二个设置为0) 设置后 al = 10000101B
同理,若将第三位设置为1,则
or al,00000100B 即可 设置后 al = 10001111B
tip:有关大小写用位运算的转换
对于大写字母和小写字母,我们知道他们的ASCII码相差32如(A:65)、(a:97),而32正好对应二进制
00100000B,所以大写字母和小写字母的区别主要是二进制第5位(从0开始)是否为1,为1为小写,否则为大写。
如 A 转为 a
A:(01000001B)| (00100000B) = (01100001B):a 通过 or 00100000B来实现
而小写a 转为大写A只需要,把第五位置0即可,通过 & 11011111B来实现
现学现用,大小写转换
源程序: 目的是将data段中第一个字符全转为大写,第二个字符全转为小写
assume cs:code
data segment
db 'BaSic'
db 'iNdOrMaTiOn'
data ends
code segment
start: mov ax,data
mov ds,ax
mov bx,0
mov cx,5
s: mov al,[bx]
and al,11011111B //转小写 and DFh
mov [bx],al
inc bx
loop s
mov cx,11
s0: mov al,[bx]
or al,00100000B //转大写 or 20H
mov [bx],al
inc bx
loop s0
mov ax,4c00h
int 21h
code ends
end start
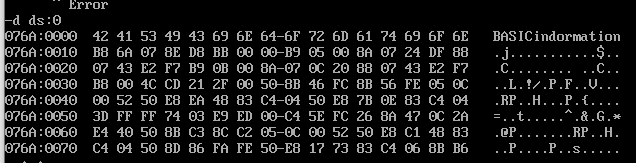
功能实现后,同时也能看出在原程序中定义的 两个字符串在内存中是连续储存的,与源程序中的换行无关。
各种寻址方式
段地址 ds(默认)
[idata] 用常量来定位一个内存单元 如 [0] [1]等等
[bx] 用一个变量来表示 如 mov bx,0 [bx] 即 dsx16 + 0
[bx+idata] 一个变量和常量的组合
表示 idata[bx] [bx].idata [bx+idata] 如200h处的一个内存 bx=0 为 200[bx] [bx].200
200[bx] 就像高级语言的a[i]一样
[bx+si] 两个变量表示 也可写成 [bx][si]
[bx+si+idata] 两个变量 + 一个常量
idata[bx][si] [bx].200[si] [bx][si].200 这里的 . 直接理解成 + 没问题
上述方法灵活使用即可。
TIP:si 和 di这两个寄存器只能当16位来使用,不能分割成两个8位来用,功能和bx差不多,[bx] 、[si]
2、双重循环的使用,及栈缓存
上题目: 将所有字母都改为大写
data segment
db 'lib '
db 'dec '
db 'dos '
db 'vax '
data ends
最简单的思路是单层循环,每层循环将0[bx]、1[bx] 、2[bx]的值依次and DFh,最后再bx+10h,反复四次就可以实现。这样可以实现是因为数据太小了,才4x3 加入是100 x 100 或者更大,这就不行了,所以要想着双层循环。
双层循环和单层循环本质上一样,需要标清楚不同循环对应的标号,同时还有一个问题是解决CX的保存问题,因为loop循环只认CX,即内存循环后还能找回外层的CX,故需要一种方式保存外层的CX,下面由两种解决方案,一是通过 再找一个寄存器来保存CX,另外则是通过栈来缓存。
①额外借助寄存器存放CX
用到bx来指向行,si来指向列,dx来存放cx
assume cs:code,ds:data
data segment
db 'lib '
db 'dec '
db 'dos '
db 'vax '
data ends
code segment
start: mov ax,data
mov ds,ax
mov bx,0
mov cx,4
s0: mov dx,cx //先保存cx
mov si,0
mov cx,3
s: mov al,[bx+si]
and al,0DFH
mov [bx+si],al
inc si
loop s
mov cx,dx //内层循环结束后复原cx
add bx,16
loop s0
mov ax,4c00h
int 21h
code ends
end start
为了容易区分两层循环,标号特意有了缩进,不过用额外寄存器存cx的方法也有局限,因为8086CPU一共就14个寄存器,并且有的寄存器有特定的功能,如果所有寄存器都在程序用到的话,那么谁还能再存cx呢,或则循环嵌套次数多呢。

②借助栈来缓存CX
既然寄存器少,但是内存可用啊。其实在单词之前开辟16字节的空间置为0,用来存放cx也可以,但不如栈方便,并且bx的值也要调整不能是0了。 为啥要选16的倍数可以想一下。
一般来说,在需要缓存数据时,都应该使用栈,因为栈的LIOF(后进先出)的特点,使栈能很好的保存当前状态,用上栈,多少层循环都不用怕了。
assume cs:code,ds:data,ss:stack
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
data segment
db 'lib '
db 'dec '
db 'dos '
db 'vax '
data ends
code segment
start: mov ax,data
mov ds,ax
mov ax,stack
mov ss,ax
mov sp,10h
mov bx,0
mov cx,4
s0: push cx
mov si,0
mov cx,3
s: mov al,[bx+si]
and al,0DFH
mov [bx+si],al
inc si
loop s
pop cx
add bx,16
loop s0
mov ax,4c00h
int 21h
code ends
end start
就是添加了一个栈段,对ss盒sp进行初始化,接着把mov dx,cx改成push … 即可。
3、实验题目:
将如下data段中每个单词的前四个字母改为大写字母
几乎和上面的例题一模一样,改成4x4的循环即可
data segment
db '1. display '
db '2. brows '
db '3. replace '
db '4. lulu '
data ends
原程序如下:
assume cs:code , ds:data , ss:stack
stack segment
dw 0,0,0,0,0,0,0,0 //用栈来缓存cx的值,实现双层循环
stack ends
data segment
db '1. display '
db '2. brows '
db '3. replace '
db '4. lulu '
data ends
code segment
start: mov ax,data
mov ds,ax
mov ax,stack
mov ss,ax
mov sp,10h
mov bx,0
mov cx,4
s0: push cx //压栈 保存当前外层循环的cx
mov si,3
mov cx,4
s: mov al,[bx+si]
and al,11011111B
mov [bx+si],al
inc si
loop s
pop cx //内层循环结束,复原外层的cx
add bx,10h
loop s0
mov ax,4c00h
int 21h
code ends
end start
通过bx来控制行,si来定位列实现寻址。
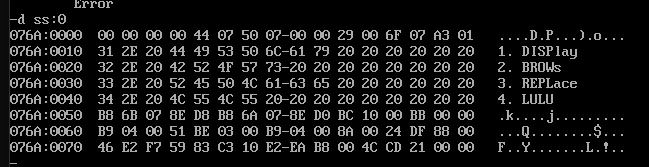
第八章 数据处理的两个基本问题
章节内容
围绕两个重要问题进行解决。
1、处理的数据在什么地方?
8086中,只有bx、bp、si、di能用在 […]中进行寻址,可以单独出现即 [si]、 [bx]等,也可以组合出现,但只有四种组合,必须是[bx+si]、[bx+di]、[bp+si]、[bp+di]
注:如果用[…]用到bp,如果段地址没有显示给出(即前缀),段地址默认在 ss
如[bp] 、[bp+si]、[bp+si+idata]都是默认以ss中数据为段地址
汇编语言用三个概念来表示数据的位置
1、立即数
直接包含在机器指令中的数据(执行前在cpu的指令缓冲区) 可参考第二章中指令执行的过程
如 mov ax,1 mov bx,'a' 等
2、寄存器
数据在寄存器中,在操作时给出相应的寄存器名称
如 mov ax,bx sub ax,bx
3、数据在内存中
通过 段地址(SA)+ 偏移地址(EA)来访问
可以显示给出如 ds:[0] ds:[bx]
也可以默认 如[bx] 默认ds [bp] 默认ss
寻址方式,详细可参考上一章
结合高级语言,理解一些常见的表述方式,怎么直观怎么来用。
2、指令要处理的数据有多长?
1、通过寄存器来标明数据尺寸
这也解释了为什么前边 mov ax,1就是一个字的大小,mov ah,1就是一个字节的大小,并且要求两个对象应该是同一种(大小对应 如 ax 对bx ah对al)
2、用操作符X ptr 指明长度
如 mov word ptr ds:[0],1
word ptr指明访问的内存单元是一个字,注意是指向内存单元。
mov byte ptr ds:[0],1
byte ptr 指明访问内存单元是一个字节大小,没有寄存器参与时,一定要显示指明。
div指令
div是除法指令,除数和被除数存放情况。
除数: 有8位和16位两种,存放在一个寄存器 或 内存单元中(需要用 X ptr指明大小)
被除数:有16位和32位,16为默认存在ax中,如果是32位则低16位在AX中 高16位在dx中
除数为8位则被除数为16位 除数为16位则被除数为32位
如果被除数为16位 则 商存在al中 ah中存余数 ,如果为32位 则ax存商,dx存余数,即低位存商,高位存余数
dd伪指令 和 dup操作符在源程序 开辟空间下解释
实验7:
assume cs:code
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
code segment
start: mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov bx,0
mov si,0
mov cx,21
s1: mov ax,[bx] //进行1975的数据复制
mov dx,[bx+2]
mov es:[si],ax
mov es:[si+2],dx
mov ax,84[bx] //进行snum数据的复制 注意多了偏移84 即 bx+84开始 84类似数组的首地址 bx表示偏移
mov dx,84[bx+2]
mov es:5[si],ax
mov es:5[si+2],dx
add bx,4
add si,16
loop s1
mov cx,21
mov bx,168
mov di,0
s2: mov ax,[bx]
mov es:[di+10],ax
add di,16
add bx,2
loop s2
mov cx,21
mov bx,84
mov si,0
mov di,0
s3: mov ax,[bx]
mov dx,[bx+2]
div word ptr [si+168]
mov es:[di+13],ax
add bx,4
add si,2
add di,16
loop s3
mov ax,4c00h
int 21h
code ends
end start
最开始我的实现方式,其实用4次循环会更加的可读,但鉴于第一个是字节型,并且题目中一个’1975’内为双字,并且接下来的21个数也为双字,所以可以放在一起进行处理。
程序运行前table段:
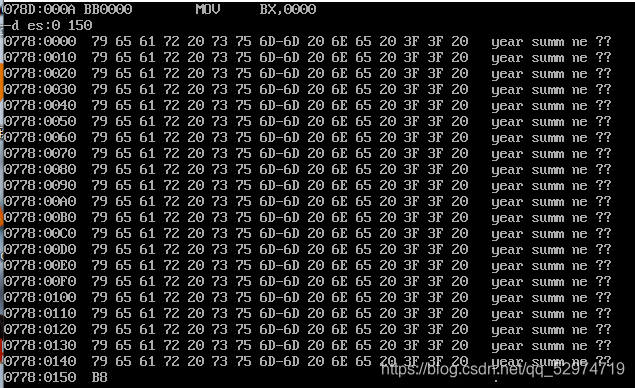 debug后table段:
debug后table段:

用一重循环来实现:
assume cs:code
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
code segment
start: mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov bx,0
mov si,0
mov di,0
mov cx,21
s: mov ax,[si]
mov dx,[si].2
mov es:[bx],ax
mov es:[bx].2,dx
mov ax,84[si]
mov dx,84[si+2]
mov es:[bx].5,ax
mov es:[bx].7,dx
div word ptr ds:168[di]
mov es:[bx].13,ax
mov ax,168[di]
mov es:[bx].10,ax
add di,2 //用来进行dw数据的复制 所以+2
add si,4 //用于复制 dd 数据 所以需要+4
add bx,16 //用来表示处理的行 一行16字节
loop s
mov ax,4c00h
int 21h
code ends
end start
分析清楚偏移,程序比较好实现。
第九章 转移指令原理
前面提到过了,CS和IP寄存器不能用mov来修改,只能是jmp或者loop指令来修改,本章主要围绕修改CS和IP的不同方法来展开。
1、基础知识
8086CPU的转移指令分为以下几类:
概述
1、无条件转移指令 如 jmp
2、条件转移指令
3、循环指令
4、过程
5、中断
转移条件不同,基本原理相同
操作符offset
offset是汇编语言中由编译器处理的,功能是取得标号的偏移地址。
前面所采用的start、s这种标号,本质上是偏移地址,用offset可以将之提取出来。
如下
code segment
start:mov ax,offset start //类似于 mov ax,0
s: mov ax,offset s //类似于 mov ax,3 因为第一条mov指令占3个字节码
code ends
2、jmp指令深入
温习:jmp为无条件的跳转指令,可以单独修改IP或是修改IP和CS
jmp ax 单独修改IP
jmp xxxx(cs):xxxx(ip)
1、依据位移进行转移的jmp指令
jmp short 标号
实现段内短转移,对IP的修改为-128~127,负数是向前移动。
注:汇编指令中,指令中的立即数不论是内存单元还是偏移地址,都会在对应机器指令中出现。
而 jmp short 标号对应的机器码 为EB XX,XX表示位移。
jmp short 标号
功能为 IP=IP+8位位移 -128~127 补码
XX位移= 标号处的地址 - jmp下一条指令的地址
jmp near ptr 标号
功能为IP=IP+16位位移 -2^31 ~ 2^31-1
根据转移范围 把8位改变称为段内短转移,把16位变化称为段内近转移。
以上jmp short和 jmp near ptr都是在段内短跳,
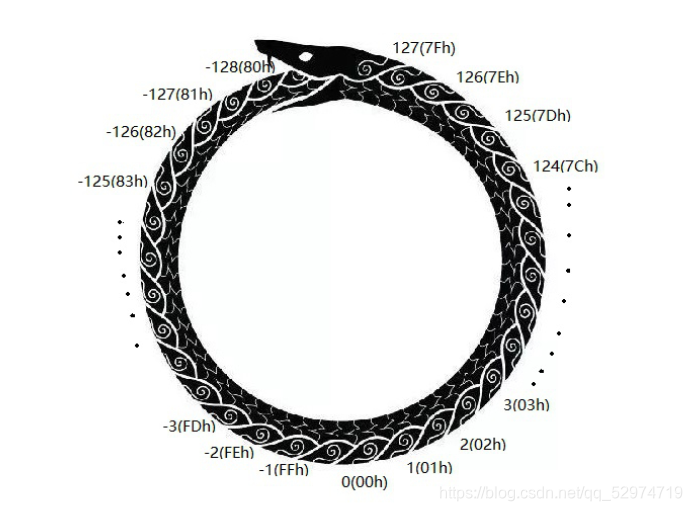
如图为,8位数据以补码形式存放蟒蛇。
2、地址在指令中的jmp指令
jmp far ptr 实现段间转移,又称为远转移。
far ptr指明了用标号的段地址和偏移地址修改CS和IP
如 jmp far ptr s
在debug载入时会变为 jmp xxxx:xxxx (s的段地址和偏移地址)
3、转移地址在寄存器中的jmp指令
jmp ax 单纯用于修改IP
4、转移地址在内存中的jmp
分为 jmp word ptr 内存 和 jmp dword ptr 内存
1、jmp word ptr 内存
用于改变 IP 在内存中取一个字用来修改IP 为什么是一个字呢 正好是一个16位寄存器的大小
段内转移
2、jmp dword ptr 内存
用于修改 IP和CS,并且IP是低2个字节,CS是高两个字节
mov ax,0123h //低位
mov [bx],ax
mov word ptr [bx+2],0 //高位
jmp dword ptr [bx]
IP=0123h CS=0
jcxz指令和loop指令
jcxz为有条件跳转,所有的条件指令都是段内短转移,通过EB +位移来实现
jcxz + 标号
如果cx等于0,就跳转到标号处
if(cx==0) jmp short s
loop指令为循环指令,所有的循环指令都是短转移。
实现过程
cx--
if(cx!=0) jmp short s
以上两种指令都是段内短转移,并且都依靠cx来进行判断。
可用多个jmp指令来实现循环,如下,实现在内存2000H的段内查找第一个只为0的字节,找到就把偏移量存在dx中。
1、依靠jcxz实现
code segment
start: mov ax,2000h //养成用标号的习惯
mov ds,ax
mov bx,0
s: mov ch,0 //因为是找第一个为0的字节 所以只用cl,故ch高位赋0
mov cl,[bx]
jcxz ok
jmp s
ok: mov dx,bx
mov ax,4c00h
int 21h
code ends
2、通过loop实现
code segment
start: mov ax,2000h
mov ds,ax
mov bx,0
s: mov ch,0
mov cl,[bx]
inc bx
loop s
ok: dec bx
mov ax,4c00h
int 21h
code ends
inc 和 dec 前面貌似忘记提到
inc 就是值+1 dec就是值-1 increase 和 decrease
位移转移的意义和越界问题
1、位移转移的意义
以loop为例,loop s 的机器指令为 E2 XX(位移),如果字节将地址写在机器指令中的话,就对程序段在内存中的偏移有了严格的限制,假如说程序运行的时候地址发生了改变,那么可能就会出现一些错误,即s所指的指令的偏移发生了变化,如果是位移的话,无论地址变成什么样,位移始终是不变的(就像保守力做功只看始末位置)
2、编译器对位移超界的检测
根据位移进行转移的指令,转移的范围受到转移位移的限制,如果出现转移范围超界的问题,在编译时编译器会报错哦。
如书本上实例:
code segment
start: jmp short s
db 128 dup(0)
s: mov ax,1
mov ax,4c00h
int 21h
code ends
可知jmp short 是段内短转移 范围为-128~127 而 db 128 dup(0) 到mov ax第一个字节为128,超范围了编译器会报错。而第二章所说的jmp 2000:1000编译器也不认识,是debug中的汇编指令,编译时也会出错。
所以jmp短跳位移要合法,或者jmp+寄存器,jmp d/word ptr 内存
惊心动魄的实验环节
实验八 分析一个奇怪的程序
assume cs:code
code segment
mov ax,4c00h
int 21h
start: mov ax,0
s: nop
nop
mov di,offset s
mov si,offset s2
mov ax,cs:[si]
mov cs:[di],ax
s0: jmp short s
s1: mov ax,0
int 21h
mov ax,0
s2: jmp short s1
nop
code ends
end start
debug 调试如图 蓝框内为对应的机器指令
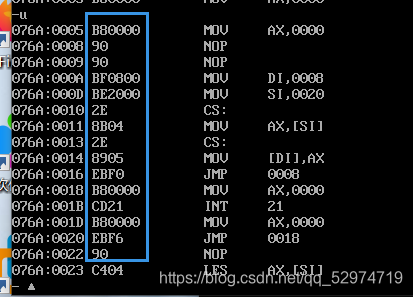
当调试完赋值语句,即把s处的两个nop处赋值时。
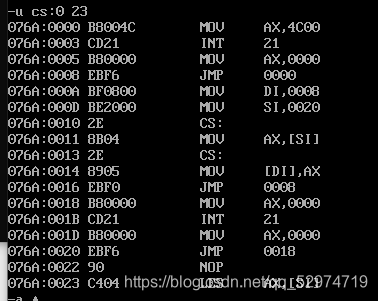
此时执行到jmp shrot s处,即图中jmp 0008h,当再次t时程序到cs:0008h处,并且再下一次要进行jmp :0000进行返回语句。
为什么是这样呢?按照汇编的理解不是jmp short s1么? 其实这种理解就是比较浅,忽略了本质,应该想,我们拷贝过去的是什么?
是机器码,也就是EB F6 而这明显是根据位移F6来跳转,F6是(-10)的补码,整数在内存中以补码方式储存。而EB F6 则是下一个指令地址000ah - 10就是目的地址为0000h,即跳转到mov ax,4c00 …程序正常的返回。
这或许也能对应上述位移的优势,如果jmp short s里面存放的只是s的偏移地址,那么程序就不能正常的返回了!!!
根据材料编程
主要提供了一个材料关于80x25彩色模式显示缓冲区,在内存中B8000H~BFFFFH共32KB的空间。主体上就是一个25行 每行80个字的一个结构,并且一个字符被分为一个字的大小,一行160个字节,也就是80个字符,其中字的低8位用来存放ASCII码,高8位村粗字符的属性(背景色、字体色、闪烁情况等)
了解完材料后,实验内容是实现在屏幕中间分别显示绿色,绿底红色、白底蓝色的字符串。
参考属性表
第7位对应BL(闪烁),第6 5 4位依次是R G B 背景色接着第3位是 I 高亮 2 1 0位是R G B字体色
所以,绿色是00000010B ,绿底红色是00100100B,白底蓝色是01110001B,也可以加闪烁耍耍。
因为涉及是正中间,所以要计算一下偏移,因为是25行80列,所以中间是12,13,14行 要输出16个字节中间是33~48列,故第一个地址为[(12-1) x 0xa0 + (33-1) x 2 = 0x720
assume cs:code
data segment
db 'welcome to masm!'
data ends
code segment
start: mov ax,0b800h
mov ds,ax
mov ax,data
mov es,ax
mov bx,720h
mov si,0
mov cx,16
s: mov al,es:[si]
mov [bx],al
mov ah,2 ;绿色
mov [bx+1],ah
mov al,es:[si]
mov [bx+0a0h],al
mov ah,00100100B ;绿底红色
mov [bx+1+0a0h],ah
mov al,es:[si]
mov [bx+0a0h+0a0h],al
mov ah,01110001B ;白底蓝色
mov [bx+1+0a0h+0a0h],ah
inc si
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
在简化一点,直接给al赋值,给ah赋值,直接把ax赋给那片内存。
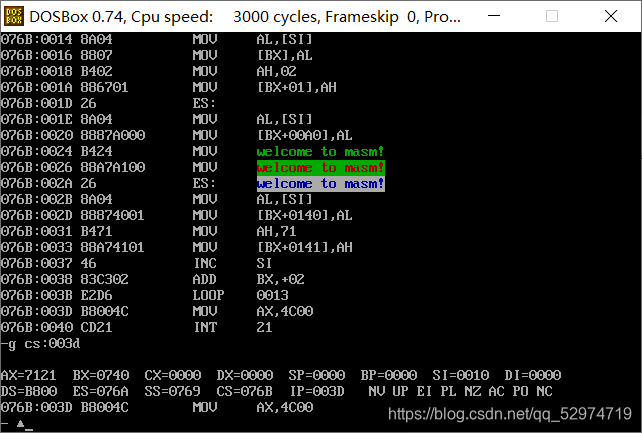
注意直接 -g cs:xxx到返回处,才能看到完整的显示。
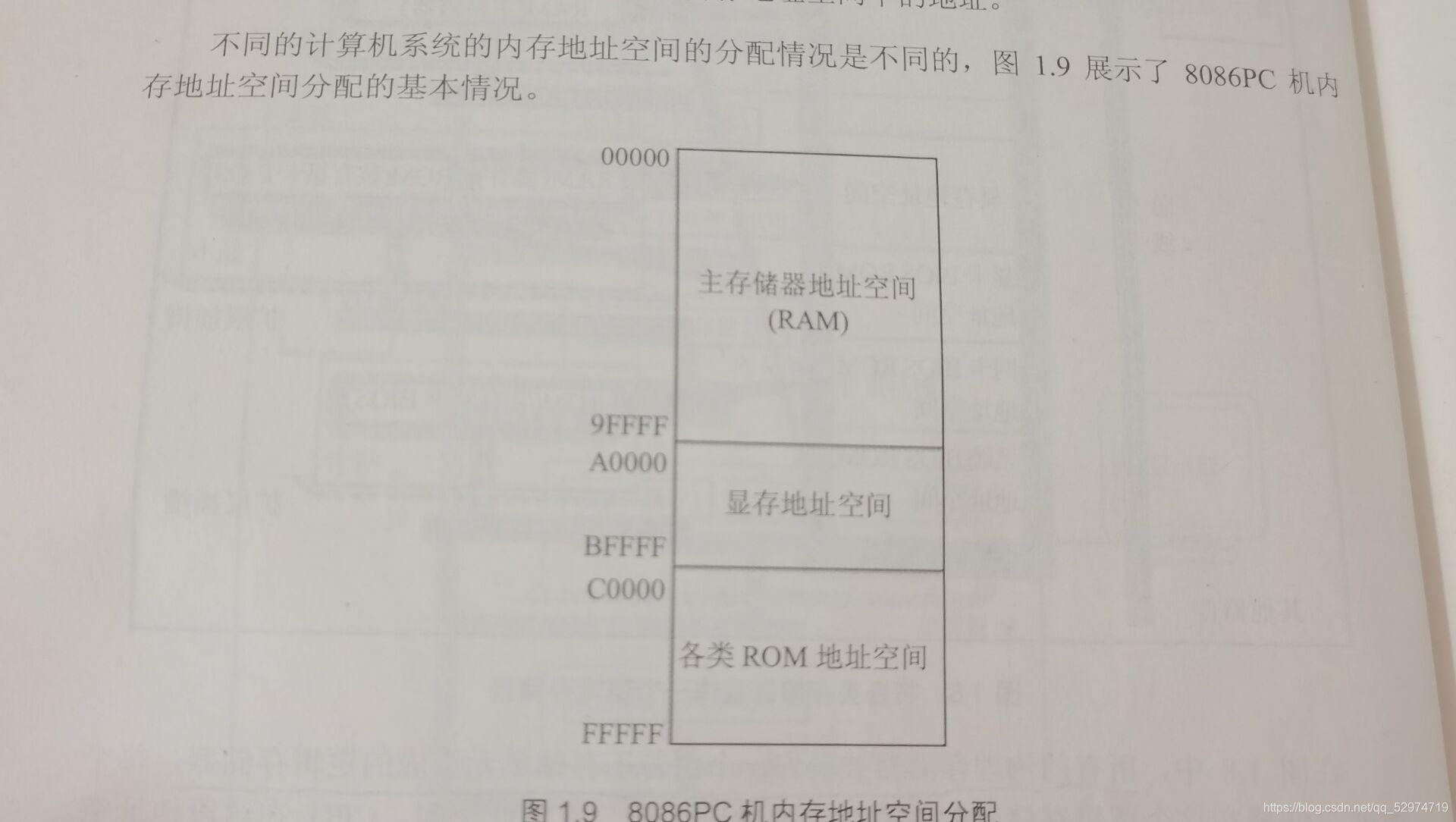
回顾第一章的图1.9,更能理解8086PC机的内存地址分布,从主存到显存再到各类不可改的ROM,显存的地址是A0000~BFFFF,以上操作便是在显存中进行,所以可以直接显示到显示器上。
总结
以上便是自己对汇编语言前九章的理解(前四章先鸽着),在学习的同时上机操作也能增添许多乐趣,但是鸽了好久了,不得不说汇编的逻辑真的好清晰,直接对线CPU编程的感觉十分的舒适,后边的部分持续更新,保存笔记方便以后查阅,如果有错误或不足还请指出。
资料链接
最后附上一个大师傅汇编第二版的答案资料和debug等,答案资料的大部题目解释的还是十分清晰的。
链接:https://pan.baidu.com/s/1mOoY4_2-0qBoBAjpKFuAVQ
提取码:cumt
附件非常小,网盘也应该会很快的。

















 3978
3978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









