







建立数据库
建立数据库:CREATE DATABASE my_database;
删除数据库:DROP DATABASE my_database;
使用数据库:USE my_database;
创建表
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT,
grade CHAR(1)
);
插入数据:INSERT INTO students (name, age, grade) VALUES ('张三', 20, 'A');
更新数据:UPDATE students SET name=“小明” where id = 9;
删除数据:DELETE FROM students where name = “夏明”;
注意:delete p1 from person p1, person p2 where p1.id > p2.id and p1.email = p2.email (删除重复的email)
查询数据:SELECT * FROM students WHERE id = 9;
索引
创建索引:CREATE INDEX idx_age ON students(age);
删除索引:DROP INDEX idx_age ON students;
修改索引:ALTER INDEX idx_age RENAME TO idx_age_new;
查看索引:SHOW INDEX FROM students
创建联合索引:CREATE INDEX idx_students_pro_age_sta ON students(profession,age,status);
视图
创建视图:CREATE OR REPLACE VIEW stu_view AS select id,name from students WHERE id > 9 WITH CHECK OPTION
查询是一样的
删除视图:DROP VIEW stu_view
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插入,更新,删除,以使其符合视图的定义。MySOL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项:CASCADED 和 LOCAL,默认值为 CASCADED
系统变量
查看系统变量:show session variables ;
show session variables like "auto%';
show global variables like 'auto%';
select @aglobal.autocommit;
设置系统变量
set session autocommit = 0 ;
用户自定义变量:
赋值:set @myname = itcast'; set @myage := 10;
使用:select @myname , @myage , @mygender , @myhobby;
查询结果赋值给变量:select count(*) into @mycount from tb_user;
局部变量
声明 - declare
create procedure begin declare stu_count int default 0; //声明 selectI count(*) into stu_count from student; //赋值 select stu_count; end:
存储过程
存储过程传参:
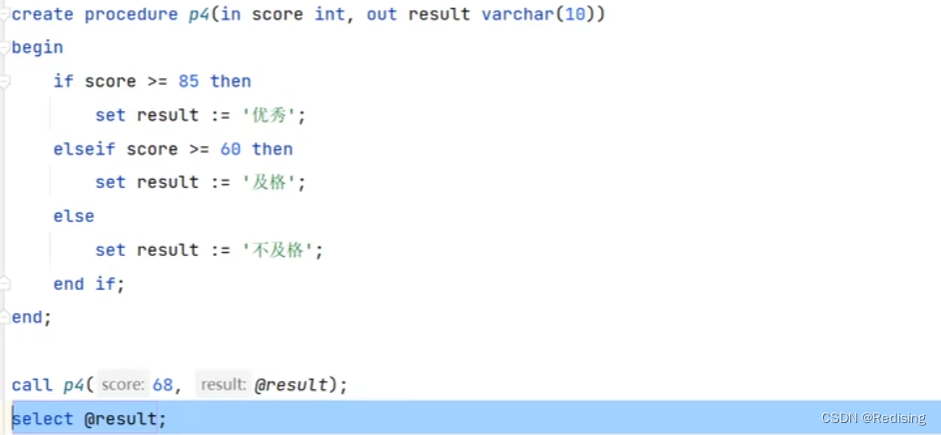
while循环:
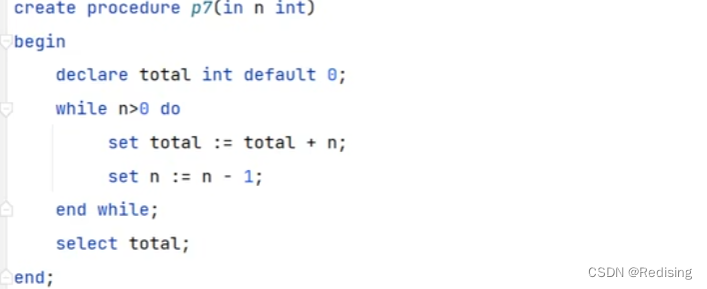
存储函数
create function fun1(n int) return int deterministic begin declare total int default 0; while n>0 do set total := total + n; set n := n - 1; end while; return total; end;
触发器创建:当指定的操作“insert"在tb_user表中执行时触发(行级触发器) ,主体是触发后的执行语句
create trigger tb_user_insert_trigger after insert on tb_user for each row begin insert into user_logs(id, operation, operate_time, operate_id, operate_params) VALUES (nuLl,'insert',now(),new.id,concat('入的数据内容为: id=',new.id,'name=',new.name)); end;

游标
CURSOR)是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标
的声明、OPEN、FETCH 和 CLOSE,其语法分别如下:
create procedure p11(in uage int)
begin
declare uname varchar(100);
declare upro varchar(100);
declare u_cursor cursor for select name,profession from tb_user where age <= uage; #通过游标保存结果集
declare exit handler for not found close u_cursor; #条件处理程序
drop table if exists tb_user_pro;
create table if not exists tb_user_pro(
id int primary key auto_increment,
name varchar(100)
profession varchar(100)
);
open u_cursor; #开启游标
while true do
fetch u_cursor into uname,upro;
insert into tb_user_pro values (null, uname, upro);
end while;
close u_cursor;
end1.表合并
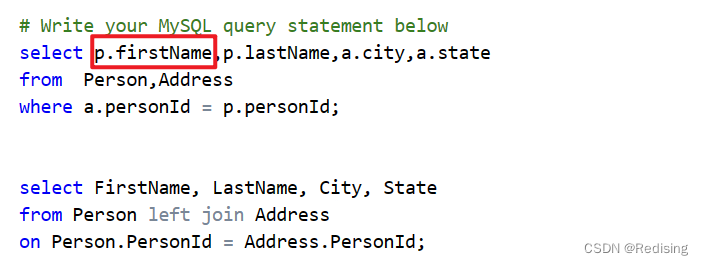
- 首先错误原因在语法出错误---表别名的写法
正确的如下:
SELECT p.firstName, p.lastName, a.city, a.state FROM Person AS p, Address AS a WHERE p.personId = a.personId;
- 其次是逻辑错误---使用左外连接
不使用左外连接会导致只有当两个表同时存在时才会出现按,因此allen这个条目丢失了

正确结果:
select P.FirstName, P.LastName, A.City, A.State from Person AS P left join Address AS A on P.PersonId = A.PersonId;

其余几种连接方式
除了左连接(LEFT JOIN),还有几种常见的连接方式,这些连接方式可以根据业务需求和数据关系选择合适的一种。以下是几种连接方式:
- 内连接(INNER JOIN):
-
- 内连接是最常见的连接方式。它只返回两个表中满足连接条件的行。如果某行在其中一个表中没有匹配的行,则不会包含在结果集中。
SELECT P.FirstName, P.LastName, A.City, A.State FROM Person AS P INNER JOIN Address AS A ON P.PersonId = A.PersonId;
- 右连接(RIGHT JOIN):
-
- 右连接与左连接相反,它返回右边表的所有行,以及与左边表匹配的行。如果左边表中没有匹配的行,右边表的列将会用 NULL 填充。
SELECT P.FirstName, P.LastName, A.City, A.State FROM Person AS P RIGHT JOIN Address AS A ON P.PersonId = A.PersonId;
- 全外连接(FULL OUTER JOIN):
-
- 全外连接返回左右两个表中所有的行,如果某一行在一个表中没有匹配的行,则用 NULL 填充。在一些数据库系统中,也可以使用
LEFT JOIN和UNION 或者 RIGHT JOIN和UNION 的组合来模拟全外连接。
SELECT P.FirstName, P.LastName, A.City, A.State FROM Person AS P FULL OUTER JOIN Address AS A ON P.PersonId = A.PersonId;
- 自连接(INNER JOIN):
-
- 自连接是指在同一个表中进行连接操作。这种情况下,通常会使用表别名来区分两次引用同一个表。
SELECT E1.EmployeeName, E2.EmployeeName FROM Employee AS E1 INNER JOIN Employee AS E2 ON E1.ManagerId = E2.EmployeeId;
2.排名问题
将Scores表的分数按照从高到低排名,相同分数一样,排名序号连续。
方法一:DENSE_RANK() 窗口函数
DENSE_RANK() 窗口函数:返回当前行在其分区中的排名,没有间隙。对等项被视为并列并获得相同的排名。此函数为对等组分配连续的排名;结果是大于一的组不产生不连续的排名号码。
select S.score,DENSE_RANK() OVER( order by S.score desc ) as 'rank' from Scores S;
方法二:使用 COUNT(DISTINCT ...) 的相关子查询
如果我们能够计算每个分数 S1.score 的不同分数 S2.score 的数量,而这些分数大于或等于此分数,那么这将有效地给我们提供 S1.score 的排名。然后我们可以按照 S1.score 对结果集进行排序,以符合问题的排名规则。
select S1.score,( select COUNT(DISTINCT S2.score) from Scores S2 where S2.score>=S1.score ) as 'rank' from Scores S1 order by S1.score DESC;
方法三:
通过自连接,将T表中大于等于S表某一行 i 的所有数据连接到 i 行,这些数据利用count函数统计其数量(去掉相同的行),得到rank,因为i行对应了多条数据,又S有多行,利用count统计需要分组,只统计i行对应连接的T表行数
SELECT S.score, COUNT(DISTINCT T.score) AS 'rank' FROM Scores S INNER JOIN Scores T ON S.score <= T.score group by S.id order by S.score DESC;
3.树形表查询
课程分类表是一个树型结构,其中parentid字段为父结点ID,它是树型结构的标志字段。如果树的层级固定可以使用表的自链接去查询,比如:我们只查询两级课程分类,可以用下边的SQL
select
one.id one_id,
one.name one_name,
one.parentid one_parentid,
one.orderby one_orderby,
one.label one_label,
two.id two_id,
two.name two_name,
two.parentid two_parentid,
two.orderby two_orderby,
two.label two_label
from course_category one
inner join course_category two on one.id = two.parentid
where one.parentid = 1
and one.is_show = 1
and two.is_show = 1
order by one.orderby,
two.orderby 如果树的层级不确定,此时可以使用MySQL递归实现,使用with语法,如下:
WITH [RECURSIVE] cte_name [(col_name [, col_name] ...)] AS (subquery) [, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...
cte_name :公共表达式的名称,可以理解为表名,用来表示as后面跟着的子查询
col_name :公共表达式包含的列名,可以写也可以不写
下边是一个递归的简单例子:
with RECURSIVE t1 AS ( SELECT 1 as n UNION ALL SELECT n + 1 FROM t1 WHERE n < 5 ) SELECT * FROM t1;
输出:
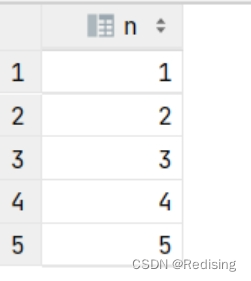
说明:
t1 相当于一个表名
select 1 相当于这个表的初始值,这里使用UNION ALL 不断将每次递归得到的数据加入到表中。
n=5时结束递归调用。
下边我们使用递归实现课程分类的查询
with recursive t1 as ( select * from course_category p where id= '1' union all select t.* from course_category t inner join t1 on t1.id = t.parentid ) select * from t1 order by t1.id, t1.orderby
查询结果如下:
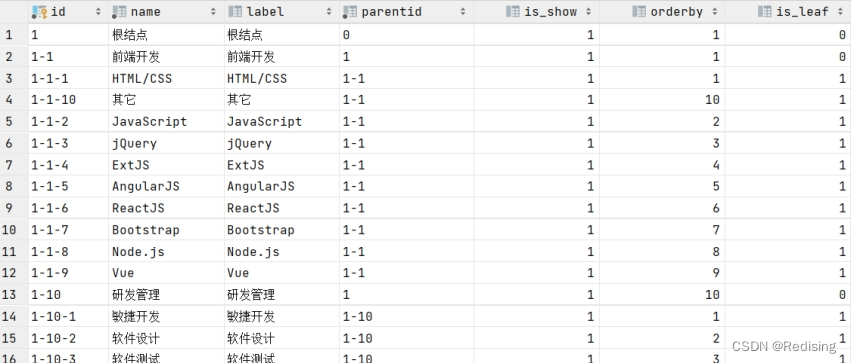
t1表中初始的数据是id等于1的记录,即根结点。
通过inner join t1 t2 on t2.id = t.parentid 找到id='1'的下级节点 。通过这种方法就找到了id='1'的所有下级节点,下级节点包括了所有层级的节点。上边这种方法是向下递归,即找到初始节点的所有下级节点。
如何向上递归?下边的sql实现了向上递归:
with recursive t1 as ( select * from course_category p where id= '1-1-1' union all select t.* from course_category t inner join t1 on t1.parentid = t.id ) select * from t1 order by t1.id, t1.orderby
初始节点为1-1-1,通过递归找到它的父级节点,父级节点包括所有级别的节点。
以上是我们研究了树型表的查询方法,通过递归的方式查询课程分类比较灵活,因为它可以不限制层级。
mysql为了避免无限递归默认递归次数为1000,可以通过设置cte_max_recursion_depth参数增加递归深度,还可以通过max_execution_time限制执行时间,超过此时间也会终止递归操作。mysql递归相当于在存储过程中执行若干次sql语句,java程序仅与数据库建立一次链接执行递归操作,所以只要控制好递归深度,控制好数据量性能就没有问题。
思考:如果java程序在递归操作中连接数据库去查询数据组装数据,这个性能高吗?
4.课本章节计划
首先是课程信息的查询,找到 where one.parentid = 0 and one.course_id=#{value} 符合这个条件的课程的一级目录,然后通过自连接拿到对应的课程二级目录信息,再寻找二级目录对应的媒体信息;我们还通过map映射,直接可以得到封装好的结果list,list中保存每一个一级目录,一级目录的孩子列表保存它的二级子菜单
<!-- 课程分类树型结构查询映射结果 -->
<resultMap id="treeNodeResultMap" type="com.xuecheng.content.model.dto.TeachplanDto">
<!-- 一级数据映射 -->
<id column="one_id" property="id" />
<result column="one_pname" property="pname" />
<result column="one_parentid" property="parentid" />
<result column="one_grade" property="grade" />
<result column="one_mediaType" property="mediaType" />
<result column="one_stratTime" property="startTime" />
<result column="one_endTime" property="endTime" />
<result column="one_orderby" property="orderby" />
<result column="one_courseId" property="courseId" />
<result column="one_coursePubId" property="coursePubId" />
<!-- 一级中包含多个二级数据 -->
<collection property="teachPlanTreeNodes" ofType="com.xuecheng.content.model.dto.TeachplanDto">
<!-- 二级数据映射 -->
<id column="two_id" property="id" />
<result column="two_pname" property="pname" />
<result column="two_parentid" property="parentid" />
<result column="two_grade" property="grade" />
<result column="two_mediaType" property="mediaType" />
<result column="two_stratTime" property="startTime" />
<result column="two_endTime" property="endTime" />
<result column="two_orderby" property="orderby" />
<result column="two_courseId" property="courseId" />
<result column="two_coursePubId" property="coursePubId" />
<!-- 一个二级目录中包含一条媒体数据 -->
<association property="teachplanMedia" javaType="com.xuecheng.content.model.po.TeachplanMedia">
<result column="teachplanMeidaId" property="id" />
<result column="mediaFilename" property="mediaFilename" />
<result column="mediaId" property="mediaId" />
<result column="two_id" property="teachplanId" />
<result column="two_courseId" property="courseId" />
<result column="two_coursePubId" property="coursePubId" />
</association>
</collection>
</resultMap>
<!--课程计划树型结构查询-->
<select id="selectTreeNodes" resultMap="treeNodeResultMap" parameterType="long" >
select
one.id one_id,
one.pname one_pname,
one.parentid one_parentid,
one.grade one_grade,
one.media_type one_mediaType,
one.start_time one_stratTime,
one.end_time one_endTime,
one.orderby one_orderby,
one.course_id one_courseId,
one.course_pub_id one_coursePubId,
two.id two_id,
two.pname two_pname,
two.parentid two_parentid,
two.grade two_grade,
two.media_type two_mediaType,
two.start_time two_stratTime,
two.end_time two_endTime,
two.orderby two_orderby,
two.course_id two_courseId,
two.course_pub_id two_coursePubId,
m1.media_fileName mediaFilename,
m1.id teachplanMeidaId,
m1.media_id mediaId
from teachplan one
left JOIN teachplan two on one.id = two.parentid
LEFT JOIN teachplan_media m1 on m1.teachplan_id = two.id
where one.parentid = 0 and one.course_id=#{value}
order by one.orderby,
two.orderby
</select>对应的结果封装在如下对象中
public class TeachplanDto extends Teachplan { //课程计划关联的媒资信息 TeachplanMedia teachplanMedia; //子结点 List<TeachplanDto> teachPlanTreeNodes; }
复杂技巧题
1.查找第N高数据(查找薪水第二高的表项)
朴素思路:先找最大,再找比最大小的第二大,再找...
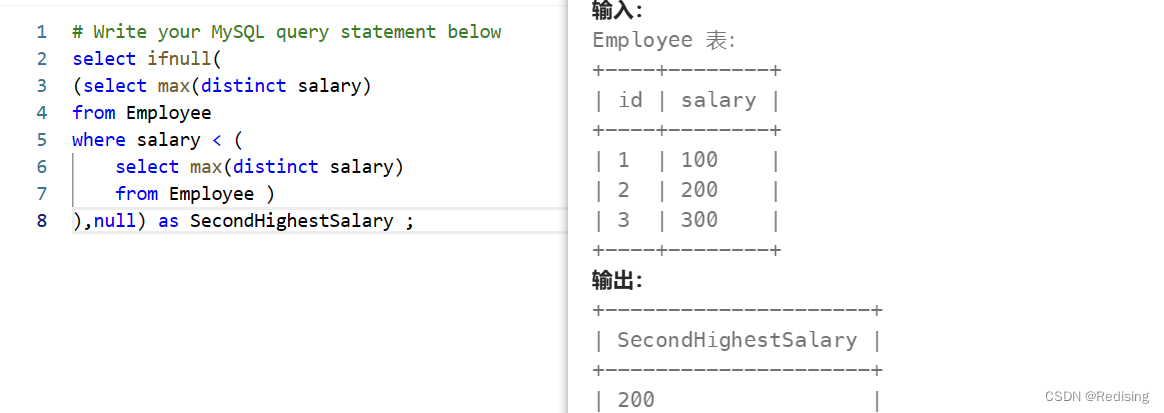
select ifnull( (select max(distinct salary) from Employee where salary < ( select max(distinct salary) from Employee ) ),null) as SecondHighestSalary ;
精炼思路:
select ifnull( (select distinct salary from Employee order by salary desc limit 1 offset 1 ),null) as SecondHighestSalary ;
- 如果没有第二高的salary,返回空值,所以这里用判断空值的函数(ifnull)函数来处理特殊情况。ifnull(a,b)函数解释:如果a不是空,结果返回a,如果a是空,结果返回b
- 使用 limit 和 offset
limit n子句表示查询结果返回前n条数据 ,offset n表示跳过x条语句
limit y offset x 分句表示查询结果跳过 x 条数据,读取前 y 条数据
使用limit和offset,降序排列再返回第二条记录可以得到第二大的值。















 8943
8943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









