






11.1 子集搜索与评价
我们将属性称为“特征”,对于当前学习任务有用的属性称为“相关特征”,没什么用的属性称为“无关特征”,“冗余特征”所包含的信息能从其他特征中推演出来,从给定的特征集合·里面选择出相关的特征子集的过程就称为“特征选择”。
特征选择的原因
选择重要的特征可以大大减轻维数灾难问题;
想要从特征集合中选取出一个包含所有重要信息·的特征子集,遍历往往会遭遇组合爆炸。可行的方案是,产生一个“候选子集”,评价其好坏,基于评价结果产生下一个候选子集,再对其进行评价,周而复始,直到无法找到更好的候选子集为止。该过程涉及两个关键问题:子集搜索解决根据评价结果获取下一个候选子集,子集评价解决评价候选特征子集的好坏问题。
第一个环节是子集搜索。给定特征集合,对这d个候选单特征子集进行评价,假定
最优,那么就将
作为第一轮的选定集;在剩下的
个候选两特征子集中
最优,并且其优于
,那么将
作为本轮的选定集;...假设第
轮时,最优候选
特征子集不如上一轮的选定集,则停止,并且将上一轮的k个特征集合作为特征选择结果。
第二个环节是子集评价。假定数据集D,且第i类样本所占比例为,假定本属性均为离散型。对于属性子集A,假设将D分成V个子集
,并且每个子集的样本在A上取值相同,则属性子集A信息增益
,
其中信息熵为
,
信息增益越大,那么特征子集A包含的有利于分类的信息越多,所以,我们往往可以用训练数据集D来计算其信息增益,并以此为评价准则。
11.2 过滤式选择
过滤式选择方法先是对数据集进行特征选择,再训练学习器,这就等价于先用特征选择过程对初始特征进行“过滤”,再用过滤后的特征来训练模型。过滤式选择的代表算法是Relief,该方法设计了一个“相关统计量”来度量特征的重要性。该统计量是一个向量,对应于每个初始特征,只需指定一个阈值,然后选择比
大的相关统计量分量所对应的特征即可。
Relief的关键是怎么确定相关统计量。假定训练集,对于每个实例
,Relief先在
的同类样本中寻找最近邻
,即为猜中近邻,再从
的异类样本中寻找其最近邻
,即为猜错近邻,则相关统计量对应于属性j的分量为
,
其中表示样本
在属性j上的取值,
,取决于属性j的类型:如果属性j为离散型,则
时
,否则为1;若属性j为连续型,则
。
从上式中可以看出,如果大于0,那么说明属性j对区分同类与异类样本是有益的,于是就增大属性j所对应的统计量分量;反之,则说明属性j起到负面作用,故减小属性j所对应的统计量分量。
Relief的时间开销随采样次数以及原始特征数线性增长,故是一个运行效率很高的过滤式特征选择算法。
11.3 包裹式选择
与过滤式特征选择不同,包裹式特征选择就是为给定学习器选择最有利于其性能的特征子集。LVW是一个典型的包裹式特征选择方法,它使用随机策略来进行子集搜索,并以最终分类器的误差为特征子集评价准则。算法描述如下

上图算法第8行使用交叉验证法来估计学习器的误差,注意该误差是特征子集
的误差,若比当前特征子集A上的误差小,则将
保留下来。需要注意的是,LVW算法若初始特征数很多、T设置较大,则算法在由运行时限的情况下可能给不出解。
下面是LVW算法的实现代码
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
def evaluate_feature_subset(X_train, y_train, X_test, y_test, feature_subset):
if len(feature_subset) == 0:
return 0 # 如果没有选择特征,准确率为0
# 选择特征子集
X_train_subset = X_train[:, feature_subset]
X_test_subset = X_test[:, feature_subset]
# 训练模型
model = RandomForestClassifier(n_estimators=10, random_state=42)
model.fit(X_train_subset, y_train)
# 预测并评估
y_pred = model.predict(X_test_subset)
accuracy = accuracy_score(y_test, y_pred)
return accuracy
def las_vegas_wrapper(X_train, y_train, X_test, y_test, max_features=None, max_iterations=100):
num_features = X_train.shape[1]
if max_features is None:
max_features = num_features
best_features = []
best_accuracy = 0
for _ in range(max_iterations):
# 随机选择特征子集
num_selected_features = np.random.randint(1, min(max_features, num_features) + 1)
feature_subset = np.random.choice(num_features, num_selected_features, replace=False)
# 评估特征子集
accuracy = evaluate_feature_subset(X_train, y_train, X_test, y_test, feature_subset)
# 更新最佳特征子集
if accuracy > best_accuracy:
best_accuracy = accuracy
best_features = feature_subset
return best_features, best_accuracy
# 示例使用
if __name__ == "__main__":
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 执行 Las Vegas Wrapper 算法
best_features, best_accuracy = las_vegas_wrapper(X_train, y_train, X_test, y_test)
print("最佳特征子集:", best_features)
print("最佳准确率:", best_accuracy)evaluate_feature_subset函数用来评估给定特征子集的模型性能,返回准确率;las_vegas_wrapper函数执行 Las Vegas Wrapper 算法。它随机选择特征子集,训练模型并评估其性能,最终返回最佳特征子集及其对应的准确率。示例中使用的是鸢尾花数据集,也可以替换为其他数据集进行测试。
11.4 嵌入式选择与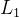 正则化
正则化
与前两种选择方法不同的是,嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成。
给定数据集,其中
。考虑线性回归模型,假定以平方误差为损失函数,那么优化目标为
.
当样本特征过多,但是样本数又相对较少时,上式很可能陷入过拟合。为缓解过拟合,可引入正则化,使用范数正则化,有
此外,我们还可以将范数替换为
,令
,即采用
范数,有
范数和
范数正则化都有助于降低过拟合风险,但前者更易于获得稀疏解,即它求得的
会有更少的非零向量。

正则化问题的求解可使用近端梯度下降,即令
表示微分算子,优化目标为
若可导,且存在常数
使得
,
则在附近可将
通过二阶泰勒展式近似为
其中const是与x无关的常数,表示内积。显然,上式的最小值在
获得
即在每一步对进行梯度下降迭代的同时考虑
范数最小化。对于上式,可先计算
,然后求解
令表示x的第i个分量,将上式按分量展开可看出,不存在
这样的项,即x的各分量互不影响,故有闭式解
其中与
分别是
与z的第i个分量。















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









