







 本文详细介绍了多种字符串匹配算法,包括朴素匹配、hashRabin-Karp、KMP、Sunday、SHIFT-AND以及AC自动机。AC自动机是一种高效处理多模式匹配问题的算法,它结合了字典树和失败指针的概念,能够实现线性时间复杂度的匹配。文章还探讨了AC自动机的优化,如路径压缩,以及如何应用在实际的字符串统计问题中。
本文详细介绍了多种字符串匹配算法,包括朴素匹配、hashRabin-Karp、KMP、Sunday、SHIFT-AND以及AC自动机。AC自动机是一种高效处理多模式匹配问题的算法,它结合了字典树和失败指针的概念,能够实现线性时间复杂度的匹配。文章还探讨了AC自动机的优化,如路径压缩,以及如何应用在实际的字符串统计问题中。
字符串匹配算法
文章目录
朴素匹配算法Brute-Force
时间复杂度O(N*M)
#include <stdio.h>
#include <string.h>
int brute_force(const char *s, const char *t) {
for (int i = 0; s[i]; i++) {
int flag = 0;
for (int j = 0; t[j]; j++) {
if (s[i + j] == t[j]) continue;
flag = 1;
break;
}
if (flag == 0) return i;
}
return -1;
}
int main() {
char s[100], t[100];
scanf("%s%s", s, t);
printf("%d\n", brute_force(s, t));
return 0;
}
hash Rabin-Karp匹配法
对母串的每一个字串进行hash n-m+1次hash hash(A) = hash(B) A=B
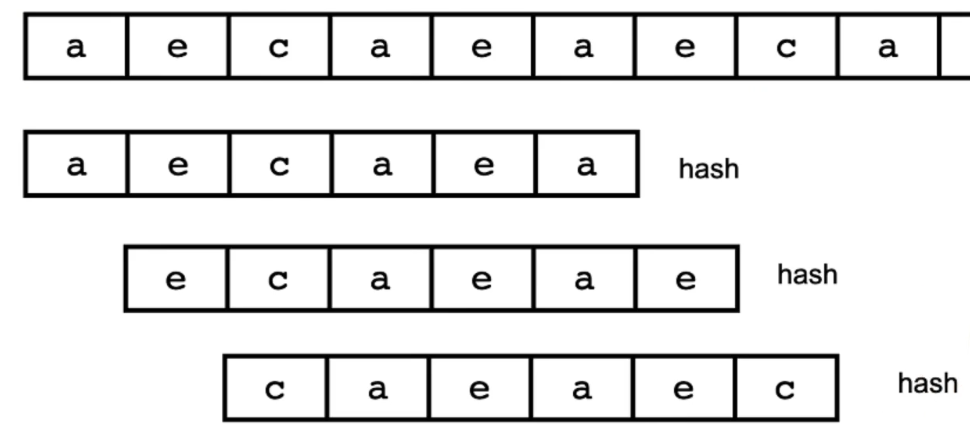
hash 的方法 abc = a * 26 * 26 + b * 26 + c
前一个:aeca hash(A) 后一个:ecae hash(B) hash(B) = hash(A) - (a * 26 * 26 * 26) + e
推导公式 h[i] = (h[i - 1] - 26 ^ (m - 1) * s[i - 1]) * 26 + s[i + m - 1]
问题:
1、hash值超过了int范围?
优化hash函数, 把字符与素数做映射, 而不是简单的a->1, b->2
优化hash函数, 更改hash策略, 直接把对应位置想加, 不做乘法法
2、hash冲突? 发送冲突,则直接对比 (子字符串)
时间复杂度:
最好:O(N)
最坏:O(N*M) (发送哈希冲突次数过多)
KMP算法
母串S
模式串T
一、关键点:求模式串 的每一个前缀的子前缀的相等的最长前缀和后缀
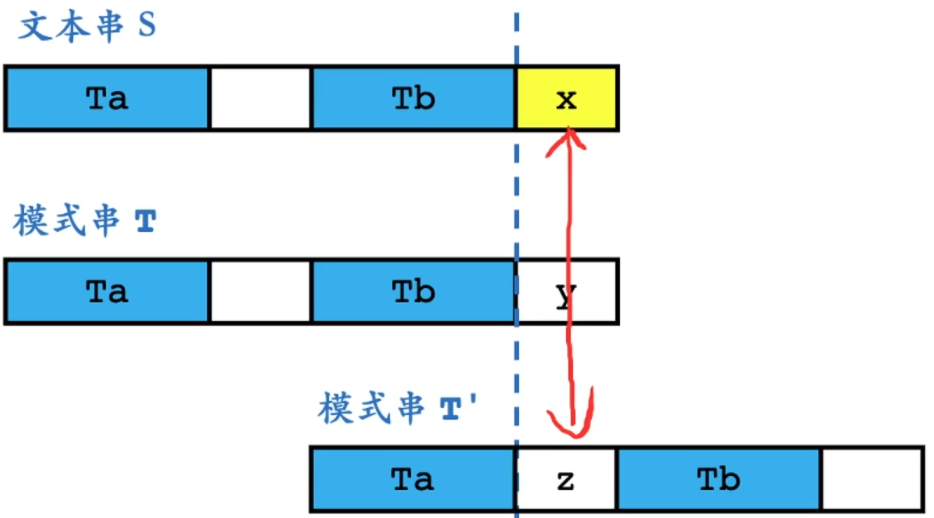
x!=y: 对比x和z
abcdab
| 子前缀 | 其相等的最长前缀和后缀 |
|---|---|
| a | a |
| ab | 无 |
| abc | 无 |
| abcd | 无 |
| abcda | a |
| abcdab | ab |
二、最长前缀后缀预处理

i = j 扩大 Sa 和 Sb,
i != j 利用sa和sb的最长前缀和后缀,再对比 i 和 j
如:模式串T abcxabcab
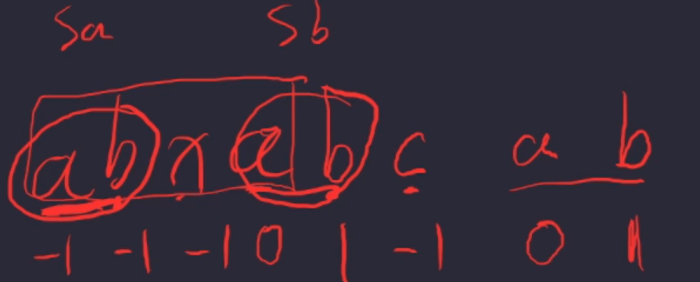
#include <stdio.h>
#include <string.h>
int next[100];
int kmp(const char *s, const char *t) { //s为母串, t为子串
//init next
next[0] = -1; //第一个字符的前后缀无意义
for(int i = 0, j = -1; t[i]; i++) { //最长前缀后缀预处理
while(j != -1 && t[j + 1] != t[i]) { //j!= -1 跳过第一个 t[j + 1] != t[i]第二种情况
j = next[j]; //利用sa和sb的最长前缀和后缀,再对比 i 和 j + 1
}
if (t[j + 1] == t[i]) { // t[j + 1] == t[i] 扩大 Sa 和 Sb
j++;
}
next[i] = j; //存 当前最长值
}
/*
for (int i = 0; i < 20; i++) { //next[i] 默认-1,加一即为真实值
printf("%d ", next[i]);
}
printf("\n");
*/
//match string
for(int i = 0, j = -1; s[i]; i++) {
while(j != -1 && s[i] != t[j + 1]) {
j = next[j];
}
if (s[i] == t[j + 1]) j++;
if (t[j + 1] == '\0') return i - j; //返回位置
}
return -1;
}
int main() {
char s[100], t[100];
scanf("%s%s", s, t);
kmp(s, t);
printf("%d\n", kmp(s, t));
return 0;
}
无注释版
int next[100];
int kmp(const char *s, const char *t) {
// init next
next[0] = -1;
for(int i = 1, j = -1; t[i]; i++) {
while(j != -1 && t[j + 1] != t[i]) { j = next[j]; }
if(t[j + 1] == t[i]) { j++; }
next[i] = j;
}
// match string
for(int i = 0, j = -1; s[i]; i++) {
while(j != -1 && s[i] != t[j + 1]) { j = next[j]; }
if(s[i] == t[j + 1]) j++;
if(t[j + 1] == '\0') return i - j;
}
return -1;
}
kmp 流式算法
a.out < input 512MB的内存处理10GB
hash算法
BM算法
Sunday算法
Sunday算法
- SUNDAY 算法理解的核心,在于理解对齐点位
- 是文本串的匹配尾部,一定会出现在模式串中的字符
- 文本串应该和模式串中最后一位(从后往前找的第一位)出现该字符的位置对齐
- 第一步:预处理**每一个字符(所有)**在模式串中最后一次出现的位置
- 第二步:模拟暴力匹配算法过程,失配的时候,文本串指针根据预处理信息向后移动若干位
int sunday(const char *s, const char *t) {
int len_s = strlen(s), len_t = strlen(t);
int ind[256];
//第一步:预处理每一个字符(所有 256个字符)在模式串中最后一次出现的位置
for (int i = 0; i < 256; i++) ind[i] = len_t + 1;
for (int i = 0; t[i]; i++) {
ind[t[i]] = len _t - i;
}
int i = 0;
while (i + len_t <= len_s) {
int flag = 1;
for (int j = 0; t[j]; j++) {
if (s[i + j] == t[j]) continue;
flag = 0;
break;
}
if (flag == 1) return i; // 找到了匹配, 直接返回位置
i += ind[s[i + len_t]]; // 匹配不成功, 找对齐点位, 出现在第几位, 就往后移动多少位置
}
return -1;
}
SHIFT-AND算法
模式串T转换为二维数组
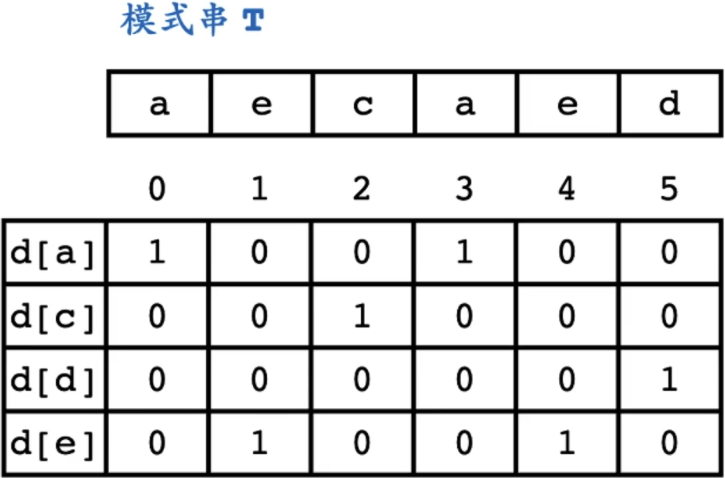
d[a] = int(001001) 反过来

P = (P << 1 | 1) & d[s[i]]
P & (1 << (n - 1))
SHIFT-AND算法
-
第一步对模式串做特殊处理,把每一种字符出现的位置,转换成相应的二进制编码
-
后续匹配的过程中跟模式串一毛钱关系都没有
-
P的结构定义:
相应的位置为1,意味着当前文本串后缀能匹配到模式串的第几位前缀 -
P的结构操作:
文本串进来一个,对于每个p为1的地方,都有可能移动1位(都有可能多匹配一个字符),并且第一位O也有可能变成1,我们先假设,所有的1都能匹配得到假设完之后,开始验证我们的假设
时间复杂度 O(n+m)
#include <stdio.h>
#include <string.h>
int shift_and(const char *s, const char *t) {
int code[256] = {0};
int n = 0;
for(int i = 0; t[i]; i++, n++) {
code[t[i]] |= (1 << i); //t[i] 位置 加上 第i位的1
}
int p = 0;
for(int i = 0; s[i]; i++) {
p = (p << 1 | 1) & code[s[i]];
if(p & (1 << (n - 1))) return i - n + 1; // 和t的n个前缀相等则完成字符串匹配
}
return -1;
}
int main() {
char s[100], t[100];
scanf("%s%s", s, t);
printf("%d\n", shift_and(s, t));
return 0;
}
AC 自动机
(https://www.bilibili.com/video/BV14v4y1Z7fu?from=search&seid=6238726824937823313)
kmp的基础上做的多模式匹配
多模匹配问题
- 有多个模式串的匹配问题,就是多模匹配问题
- Step1:多个模式串,建立成一棵字典树
- Step2:和文本串的每一位对齐匹配,模拟暴力匹配算法的过程
AC 自动机的思想
- 当匹配成功文本串中的 she 时,也就意味着后续一定会匹配成功 he
- she 对应了字典树中的节点 P,he 对应了字典树中的节点Q
- P 和 Q 就是等价匹配节点,如果从 P 引出一条边指向 Q,就可以加速匹配过程
- 在 P 下面查找节点的操作,等价于在 Q 下面查找节点的操作
- 这条等价关系边,通常在 AC 自动机上叫做 【Fail 指针】
- AC 自动机 = Trie + Fail 指针
- 子节点的 Fail 指针是需要参照父节点的 Fail指针信息的,最简单的建立方式,就是采用【层序遍历】
- 没做优化的 AC 自动机,本质上是一个 NFA(非确定型有穷状态自动机)
- 通俗理解:根据当前状态 p,以及输入字符 c,无法通过一步操作确定状态
- 第二种理解:当前状态,并不代表唯一状态。
#include <cstdio>
#include <cstring>
#include <sstream>
#include <ctime>
#define base 26
typedef struct Node {
const char *str;
struct Node *next[base], *fail;
} Node;
typedef struct Queue {
Node **data;
int head, tail;
} Queue;
Queue *initQueue(int n) {
Queue *q = (Queue *)malloc(sizeof(Queue));
q->data = (Node **)malloc(sizeof(Node *) * n);
q->head = q->tail = 0;
return q;
}
int empty(Queue *q) {
return q->tail - q->head == 0;
}
Node *front(Queue *q) {
return q->data[q->head];
}
void push(Queue *q, Node *node) {
q->data[q->tail++] = node;
}
void pop(Queue *q) {
if(empty(q)) return ;
q->head++;
return ;
}
void clearQueue(Queue *q) {
if(q == NULL) return ;
free(q->data);
free(q);
return ;
}
int node_cnt = 0;
Node *getNewNode() {
Node *p = (Node*)malloc(sizeof(Node));
p->str = NULL;
p->fail = NULL;
node_cnt++;
memset(p->next, 0, sizeof(Node *) * base);
return p;
}
void clear(Node *root) {
if(root == NULL) return ;
for(int i = 0; i < base; i++) {
clear(root->next[i]);
}
if(root->str) free((char *)root->str);
free(root);
return ;
}
const char *copyStr(const char *s) {
int n = strlen(s);
char *buff = (char *)malloc(n + 1);
strcpy(buff, s);
return buff;
}
void insert(Node *root, const char *s) {
Node *p = root;
for(int i = 0; s[i]; i++) {
if(p->next[s[i] - 'a'] == NULL) {
p->next[s[i] - 'a'] = getNewNode();
}
p = p->next[s[i] - 'a'];
}
p->str = copyStr(s);
return ;
}
void initBuildFaildQueue(Node *root, Queue *q) { //队列 root->next[i]先进先出
root->fail = NULL;
for(int i = 0; i < base; i++) {
if(root->next[i] == NULL) continue;
root->next[i]->fail = root;
push(q, root->next[i]);
}
return ;
}
void build_fail(Node *root) {
Queue *q = initQueue(node_cnt);
initBuildFaildQueue(root, q);
while(!empty(q)) {
Node *p = front(q);
for(int i = 0; i < base; i++) {
if(p->next[i] == NULL) continue;
Node *k = p->fail;
while(k != root && k->next[i] == NULL) {
k = k->fail;
}
if(k->next[i] != NULL) k = k->next[i];
p->next[i]->fail = k;
push(q, p->next[i]);
}
pop(q);
}
clearQueue(q);
return ;
}
void match_ac(Node *root, const char *s) {
Node *p = root, *q;
for(int i = 0; s[i]; i++) {
while(p != root && p->next[s[i] - 'a'] == NULL) {
p = p->fail;
}
if(p->next[s[i] - 'a']) p = p->next[s[i] - 'a'];
q = p;
while(q) {
if(q->str != NULL) printf("find %s\n", q->str);
q = q->fail;
}
}
return ;
}
int main() {
int n;
char s[100];
Node *root = getNewNode();
scanf("%d", &n);
for(int i = 0; i < n; i++) {
scanf("%s", s);
insert(root, s);
}
build_fail(root);
scanf("%s", s);
match_ac(root, s);
return 0;
}
经验O(N)
AC自动机的优化(有点类似并查集的路径压缩)
#include <cstdio>
#include <cstring>
#include <sstream>
#include <ctime>
#define base 26
typedef struct Node {
const char *str;
struct Node *next[base], *fail;
} Node;
typedef struct Queue {
Node **data;
int head, tail;
} Queue;
Queue *initQueue(int n) {
Queue *q = (Queue *)malloc(sizeof(Queue));
q->data = (Node **)malloc(sizeof(Node *) * n);
q->head = q->tail = 0;
return q;
}
int empty(Queue *q) {
return q->tail - q->head == 0;
}
Node *front(Queue *q) {
return q->data[q->head];
}
void push(Queue *q, Node *node) {
q->data[q->tail++] = node;
}
void pop(Queue *q) {
if(empty(q)) return ;
q->head++;
return ;
}
void clearQueue(Queue *q) {
if(q == NULL) return ;
free(q->data);
free(q);
return ;
}
int node_cnt = 0;
Node *getNewNode() {
Node *p = (Node*)malloc(sizeof(Node));
p->str = NULL;
p->fail = NULL;
node_cnt++;
memset(p->next, 0, sizeof(Node *) * base);
return p;
}
void clear(Node *root) {
if(root == NULL) return ;
for(int i = 0; i < base; i++) {
clear(root->next[i]);
}
if(root->str) free((char *)root->str);
free(root);
return ;
}
const char *copyStr(const char *s) {
int n = strlen(s);
char *buff = (char *)malloc(n + 1);
strcpy(buff, s);
return buff;
}
void insert(Node *root, const char *s) {
Node *p = root;
for(int i = 0; s[i]; i++) {
if(p->next[s[i] - 'a'] == NULL) {
p->next[s[i] - 'a'] = getNewNode();
}
p = p->next[s[i] - 'a'];
}
p->str = copyStr(s);
return ;
}
void initBuildFaildQueue(Node *root, Queue *q) {
root->fail = NULL;
for(int i = 0; i < base; i++) {
if(root->next[i] == NULL) {
root->next[i] = root;
continue;
}
root->next[i]->fail = root;
push(q, root->next[i]);
}
return ;
}
void build_fail(Node *root) {
Queue *q = initQueue(node_cnt);
initBuildFaildQueue(root, q);
while(!empty(q)) {
Node *p = front(q);
for(int i = 0; i < base; i++) {
if(p->next[i] == NULL) {
p->next[i] = p->fail->next[i];
continue;
}
Node *k = p->fail->next[i];
p->next[i]->fail = k;
push(q, p->next[i]);
}
pop(q);
}
clearQueue(q);
return ;
}
void match_ac(Node *root, const char *s) {
Node *p = root, *q;
for(int i = 0; s[i]; i++) {
p = p->next[s[i] - 'a'];
q = p;
while(q) {
if(q->str != NULL) printf("find %s\n", q->str);
q = q->fail;
}
}
return ;
}
int main() {
int n;
char s[100];
Node *root = getNewNode();
scanf("%d", &n);
for(int i = 0; i < n; i++) {
scanf("%s", s);
insert(root, s);
}
build_fail(root);
scanf("%s", s);
match_ac(root, s);
return 0;
}
字符串统计题
蒜头君某一天学习了 nn 个单词,他想看篇文章来复习下今天学习的内容,现在他想知道每个单词在这篇文章里分别出现了多少次,聪明的你能帮他解决这个问题吗?
输入格式
第一行输入一个整数 nn(1 \leq n \leq 10001≤n≤1000),表示蒜头君学习的 nn 个单词。
接下来 nn 行,每行输入一个字符串,仅由小写字母组成,长度不超过 2020。
最后输入一个字符串 SS,仅由小写字母组成,长度不超过 10^5105,表示蒜头君看的文章。
输出格式
依次输出 nn 行,每行输出格式为i: num,ii 表示单词的编号(从 00 开始编号),numnum 为一个整数,表示第 ii 个单词在母串 SS 中出现了 numnum 次。
样例输入复制
2
ab
bca
abcabc
样例输出复制
0: 2
1: 1
#include <stdio.h>
#include <stdlib.h>
#define base 26
const int maxn = 1e5 + 10;
struct Node {
int flag, *cnt;
int next[base], fail;
} tree[maxn];
int *ans[maxn];
int que[maxn], head, tail;
int root = 1, cnt = 2;
char s[maxn + 10];
int n;
int getNewNode() {
return cnt++;
}
int *insert(const char *s) {
int p = root;
for(int i = 0; s[i]; i++) {
int ind = s[i] - 'a';
if(tree[p].next[ind] == 0) tree[p].next[ind] = getNewNode();
p = tree[p].next[ind];
}
tree[p].flag = 1;
if(tree[p].cnt == NULL) {
tree[p].cnt = (int *)malloc(sizeof(int));
tree[p].cnt[0] = 0;
}
return tree[p].cnt;
}
void build_ac() {
head = tail = 0;
tree[root].fail = 0;
for(int i = 0; i < base; i++) {
if(tree[root].next[i] == 0) {
tree[root].next[i] = root;
continue;
}
tree[tree[root].next[i]].fail = root;
que[tail++] = tree[root].next[i];
}
while(head < tail) {
int p = que[head++];
for(int i = 0; i < base; i++) {
int c = tree[p].next[i], k = tree[p].fail;
if(c == 0) {
tree[p].next[i] = tree[k].next[i];
continue;
}
k = tree[k].next[i];
tree[c].fail = k;
que[tail++] = c;
}
}
return ;
}
void match_ac(const char *s) {
int p = root;
for(int i = 0; s[i]; i++) {
int ind = s[i] - 'a';
p = tree[p].next[ind];
int q = p;
while(q) {
if(tree[q].flag) {
tree[q].cnt[0]++;
}
q = tree[q].fail;
}
}
return ;
}
int main() {
scanf("%d", &n);
for(int i = 0; i < n; i++) {
scanf("%s", s);
ans[i] = insert(s);
}
build_ac();
scanf("%s", s);
match_ac(s);
for(int i = 0; i < n; i++) {
printf("%d: %d\n", i, *ans[i]);
}
return 0;
}















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









