







第五章 对象构造语义学
文章目录
继承体系下的对象构造步骤
递归调用 C ——> B ——> A(编译器的) ——> 初始化列表 + A(自己的) ——>初始化列表 + B —— >初始化列表 + C
虚函数表指针被覆盖了三次
-
一:对象的构造顺序
-
二:虚函数的继续观察
大家千万不要在构造函数中你自己的代码中使用诸如memcpy或者直接操作等手段,来修改虚函数表指针的值,否则,调用虚函数时就可能造成系统崩溃; -
三:构造函数中对虚函数的调用
某个类的构造函数 中 调用一个虚函数,那么走的不是虚函数表,而是直接调用。
(也可以用虚函数表调用,也是安全的) -
C cobj; C::C() //末端类 调用 B::B() A::A() //根源类 vptr = A::vftable; //编译器插入的代码 34 9b 2f 01 cout << "A::A()" << endl; //我们自己的代码 vptr = B::vftable; //编译器插入的代码 54 9b 2f 01 cout << "B::B()" << endl; //我们自己的代码 vptr = C::vftable; //编译器插入的代码 3c 9b 2f 01 //....不要在这里动虚函数表指针 //memset(this,0,sizeof(C)); m_c = 11; //初始化列表中基本类型变量m_c的赋值时机 cout << "C::C()" << endl; //我们自己的代码
#include <iostream>
#include <vector>
#include <ctime>
#include<algorithm>
using namespace std;
namespace _nmsp1 //命名空间
{
//一:对象的构造顺序
//二:虚函数的继续观察
//大家千万不要在构造函数中你自己的代码中使用诸如memcpy或者直接操作等手段,来修改虚函数表指针的值,否则,调用虚函数时就可能造成系统崩溃;
//三:构造函数中对虚函数的调用
//某个类的构造函数 中 调用一个虚函数,那么走的不是虚函数表,而是直接调用。
//四:举一反三
class A
{
public:
A()
{
printf("A this = %p\n", this);
cout << "A::A()" << endl;
}
virtual ~A() {}
virtual void myvirfunc() {}
virtual void myvirfunc2() {}
};
class B:public A
{
public:
B()
{
printf("B this = %p\n", this);
cout << "B::B()" << endl;
}
virtual ~B() {}
virtual void myvirfunc() {}
virtual void myvirfunc2() {}
};
class C:public B
{
public:
C():m_c(11)
{
//memcpy(this,)
myvirfunc(); //构造函数中,这里没有走虚函数表,而是直接通过虚函数地址,直接调用这个虚函数(静态方式调用)
printf("C this = %p\n", this);
cout << "C::C()" << endl;
}
virtual ~C() {}
virtual void myvirfunc() { myvirfunc2(); }
virtual void myvirfunc2() {}
int m_c;
};
//---------------------
void func()
{
//C cobj;
C *mycobj = new C();
mycobj->myvirfunc(); //代码实现上的多态,五章四节
}
}
int main()
{
_nmsp1::func();
return 1;
}
对象复制语义学、析构函数语义学
point pt1(2,3);
point pt2=pt1;
后一个语句也可写成:
point pt2( pt1);
上述语句用pt1初始化pt2,相当于将pt1中每个数据成员的值复制到pt2中,这是表面现象。实际上,系统调用了一个复制构造函数。如果类定义中没有显式定义该复制构造函数时,编译器会隐式定义一个缺省的复制构造函数,它是一个inline、public的成员函数,其原型形式为: 类名::类名(const 类名 &) 如:
point:: point (const point &);
注意:当我们自己定义了有参构造函数时,系统不再提供默认构造函数。这是容易忽略的一点。
如果我们以这种方式创建对象:
SubClass* pObj = new SubClass();
delete pObj;
不管析构函数是否是虚函数(即是否加virtual关键词),delete时基类和子类都会被释放;如果我们以这种方式创建对象:
BaseClass* pObj = new SubClass();
delete pObj;
若析构函数是虚函数(即加上virtual关键词),delete时基类和子类都会被释放;
若析构函数不是虚函数(即不加virtual关键词),delete时只释放基类,不释放子类;
-
一:对象的默认复制行为
如果我们不写自己的拷贝构造函数和拷贝赋值运算符,编译器也会有默认的对象拷贝和对象赋值行为; -
二:拷贝赋值运算符,拷贝构造函数
当我们提供自己的拷贝赋值运算符和拷贝构造函数时,我们就接管了系统默认的拷贝行为,此时,我们有责任在拷贝赋值运算符和拷贝构造函数中写适当的代码,来完成对象的拷贝或者赋值的任务; -
三:如何禁止对象的拷贝构造和赋值:把拷贝构造函数和拷贝赋值运算符私有起来,只声明,不需要些函数体;
-
四:析构函数语义
(4.1)析构函数被合成
什么情况下编译器会给我们生成一个析构函数?
a)如果继承一个基类,基类中带析构函数,那么编译器就会给咱们A合成出一个析构函数来调用基类JI中的析构函数
b)如果类成员是一个类类型成员,并且这个成员带析构函数,编译器也会合成出一个析构函数,这个析构函数存在的意义是要调用m_j这个类类型成员所在类的析构函数; (4.2)析构函数被扩展
如果我们有自己的析构函数,那么编译器就会在适当的情况下扩展我们的析构函数代码;
a)如果类成员m_j是一个类类型 JI 成员,并且这个成员m_j带析构函数 ~JI() ,编译器扩展类A的析构函数~A()代码
先执行了 类A的析构函数(子类) 代码,再执行 JI 的析构函数(父类) 代码
b)如果继承一个基类,基类中带析构函数,那么编译器就会扩展咱们类A的析构函数来调用基类JI中的析构函数 虚基类:留给大家探索;虚基类会带来更多的复杂性,也会程序执行效率有一定的影响;
#include "pch.h"
#include <iostream>
#include <vector>
#include <ctime>
#include<algorithm>
using namespace std;
namespace _nmsp1 //命名空间
{
//一:对象的默认复制行为
//如果我们不写自己的拷贝构造函数和拷贝赋值运算符,编译器也会有默认的对象拷贝和对象赋值行为;
//二:拷贝赋值运算符,拷贝构造函数
//当我们提供自己的拷贝赋值运算符和拷贝构造函数时,我们就接管了系统默认的拷贝行为,此时,我们有责任在拷贝赋值运算符和拷贝构造函数中写适当的代码,来完成对象的拷贝或者赋值的任务;
//三:如何禁止对象的拷贝构造和赋值:把拷贝构造函数和拷贝赋值运算符私有起来,只声明,不需要些函数体;
class A
{
public:
int m_i, m_j;
A() {} //缺省构造函数
private:
A & operator=(const A &tmp); //拷贝赋值运算符
/*{
m_i = tmp.m_i;
m_j = tmp.m_j;
return *this;
}*/
A(const A& tmp); //拷贝构造函数
/*{
m_i = tmp.m_i;
m_j = tmp.m_j;
}*/
};
void func()
{
A aobj;
aobj.m_i = 15;
aobj.m_j = 20;
//A aobj2 = aobj; //执行拷贝构造函数(如果你写了拷贝构造函数)
A aobj2;
A aobj3;
aobj3.m_i = 13;
aobj3.m_j = 16;
//aobj2 = aobj3; //执行拷贝赋值运算符(如果你写了拷贝赋值运算符)
}
}
namespace _nmsp2
{
//四:析构函数语义
//(4.1)析构函数被合成
//什么情况下编译器会给我们生成一个析构函数?
//a)如果继承一个基类,基类中带析构函数,那么编译器就会给咱们A合成出一个析构函数来调用基类JI中的析构函数
//b)如果类成员是一个类类型成员,并且这个成员带析构函数,编译器也会合成出一个析构函数,这个析构函数存在的意义是要调用m_j这个类类型成员所在类的析构函数;
//(4.2)析构函数被扩展
//如果我们有自己的析构函数,那么编译器就会在适当的情况下扩展我们的析构函数代码;
//a)如果类成员m_j是一个类类型JI成员,并且这个成员m_j带析构函数~JI(),编译器扩展类A的析构函数~A()代码
//先执行了类A的析构函数代码,再执行JI的析构函数代码
//b)如果继承一个基类,基类中带析构函数,那么编译器就会扩展咱们类A的析构函数来调用基类JI中的析构函数
//虚基类:留给大家探索;虚基类会带来更多的复杂性,也会程序执行效率有一定的影响;
class JI
{
public:
JI()
{
cout << "JI::JI()" << endl;
}
virtual ~JI()
{
cout << "JI::~JI()" << endl;
}
};
class A :public JI
{
public:
//JI m_j; //类类型成员变量
A()
{
cout << "A::A()" << endl;
}
virtual ~A()
{
cout << "A::~A()" << endl;
}
};
void func()
{
A aobj;
}
}
int main()
{
//_nmsp1::func();
_nmsp2::func();
return 1;
}
局部对象、全局对象的构造和析构
-
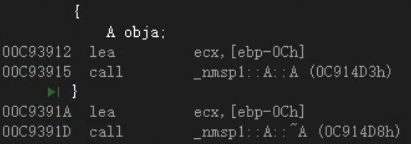
一:局部对象的构造和析构
主要出了对象的作用于,编译器总会在适当的地方插入调用对象析构函数的代码;现用现定义 ,对于局部对象,里边的m_i是随机值; —— 无默认构造函数,构造函数未初始化 …
class A { public: A() { cout << "A::A()" << endl; } ~A() { cout << "A::~A()" << endl; } int m_i; }; void func() { A obja; }
- 二:全局对象的构造和析构
全局变量是放在数据段 or BSS里的
全局对象,在不给初值的情况下,编译器默认会 把全局对象所在内存全部清0;
全局变量在编译阶段就会把空间分配出来(全局变量的地址在编译期间就确定好的)。
全局对象构造和析构的步骤:- a)全局对象g_aobj获得地址(编译时确定好的,内存也是编译时分配好的,内存时运行期间一直存在)
- b)把全局对象g_aobj的内存内容清0的能力(也叫静态初始化)
- c)调用全局对象g_aobj所对应的类A的构造函数
… - d)main()
{
…
}
… - e)调用全局对象g_aobj所对应类A的析构函数
#include <iostream>
#include <vector>
#include <ctime>
#include<algorithm>
using namespace std;
namespace _nmsp1 //命名空间
{
//一:局部对象的构造和析构
//主要出了对象的作用于,编译器总会在适当的地方插入调用对象析构函数的代码;
class A
{
public:
A()
{
cout << "A::A()" << endl;
}
~A()
{
cout << "A::~A()" << endl;
}
int m_i;
};
void func()
{
int i;
int j;
//......
/*if (1)
{
return;
}*/
//.......
//....
A obja;//现用现定义 ,对于局部对象,里边的m_i是随机值;
obja.m_i = 10;
int mytest = 1;
if (mytest == 0) //swtich case return;
{
return;
}
int b = 0;
b = 10;
return;
}
}
namespace _nmsp2
{
//二:全局对象的构造和析构
//全局变量是放在数据段里的
//全局对象,在不给初值的情况下,编译器默认会 把全局对象所在内存全部清0;
//全局变量在编译阶段就会把空间分配出来(全局变量的地址在编译期间就确定好的)。
//全局对象构造和析构的步骤:
//a)全局对象g_aobj获得地址(编译时确定好的,内存也是编译时分配好的,内存时运行期间一直存在)
//b)把全局对象g_aobj的内存内容清0的能力(也叫静态初始化)
//c)调用全局对象g_aobj所对应的类A的构造函数
//.....
//d)main()
//{
// //......
//}
//....
//e)调用全局对象g_aobj所对应类A的析构函数
class A
{
public:
A()
{
cout << "A::A()" << endl;
}
~A()
{
cout << "A::~A()" << endl;
}
int m_i;
};
A g_aobj; //全局对象,该全局对象在main函数执行之前就被构造完毕,可以在main函数中直接使用了
//在main函数执行完毕后,才被析构掉的
void func()
{
printf("g_aobj全局对象的地址=%p\n", &g_aobj);
}
}
//main函数开始之前要干很多事
int main()
{
_nmsp2::g_aobj.m_i = 6;
//_nmsp1::func();
_nmsp2::func();
return 1;
}
//main函数结束之后要干很多事
局部静态对象、对象数组构造析构和内存分配
const A &myfunc()
{
//局部静态对象
static A s_aobj1; //不管myfunc()函数被调用几次,s_aobj1这种静态局部对象只会被构造1次(只调用一次构造函数)
//static A s_aobj2;
printf("s_aobj1的地址是%p\n", &s_aobj1);
//printf("s_aobj2的地址是%p\n", &s_aobj2);
return s_aobj1;
}
void func()
{
myfunc();
myfunc();
}
-
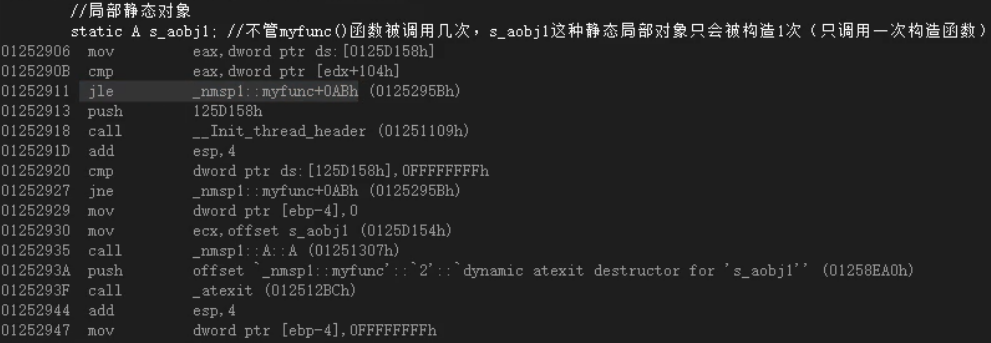
一:局部静态对象的构造和析构
- a)如果我们不调用myfunc()函数,那么根本不会触发A的构造函数;
- b)局部静态对象,内存地址是在编译期间就确定好的;
- c)静态局部量刚开始也被初始化为0; —— 未初始化数据区 BBS
- d)局部静态对象的析构,是在main函数执行结束后才被调用的。(前提是这个静态局部对象被构造过)
局部静态对象只会被构造一次,在调用的时候构造;在main函数执行完毕后析构
通过标记的方式,if 语句 —— jne —— 跳转指令
nm命令是linux下自带的特定文件分析工具,一般用来检查分析二进制文件、库文件、可执行文件中的符号表,返回二进制文件中各段的信息。
-
void myfunc() { static A s_aobj[1000'0000]; //数组内存应该是连续的 //for (int i = 0; i < 10000000; i++) //让编译器的分配内存优化能力失效 //{ // s_aobj[i].m_i = i; //} printf("s_aobj数组的首地址是%p\n", s_aobj); }这里用到是 运行时 分配内存技术
#include <iostream>
#include <vector>
#include <ctime>
#include<algorithm>
using namespace std;
namespace _nmsp1
{
//一:局部静态对象的构造和析构
//a)如果我们不调用myfunc()函数,那么根本不会触发A的构造函数;
//b)局部静态对象,内存地址是在编译期间就确定好的;
//c)静态局部量刚开始也被初始化为0;
//d)局部静态对象的析构,是在main函数执行结束后才被调用的。(前提是这个静态局部对象被构造过)
//局部静态对象只会被构造一次,在调用的时候构造;在main函数执行完毕后析构
class A
{
public:
A()
{
cout << "A::A()" << endl;
}
~A()
{
cout << "A::~A()" << endl;
}
int m_i;
};
//void myfunc()
const A &myfunc()
{
//局部静态对象
static A s_aobj1; //不管myfunc()函数被调用几次,s_aobj1这种静态局部对象只会被构造1次(只调用一次构造函数)
//static A s_aobj2;
printf("s_aobj1的地址是%p\n", &s_aobj1);
//printf("s_aobj2的地址是%p\n", &s_aobj2);
return s_aobj1;
}
void func()
{
myfunc();
myfunc();
}
}
namespace _nmsp2
{
//二:局部静态对象数组的内存分配
class A
{
public:
A()
{
//cout << "A::A()" << endl;
}
~A()
{
//cout << "A::~A()" << endl;
}
int m_i;
};
void myfunc()
{
static A s_aobj[1000'0000]; //数组内存应该是连续的
//for (int i = 0; i < 10000000; i++) //让编译器的分配内存优化能力失效
//{
// s_aobj[i].m_i = i;
//}
printf("s_aobj数组的首地址是%p\n", s_aobj);
}
void func()
{
myfunc();
myfunc();
}
}
int main()
{
//_nmsp1::func();
_nmsp2::func();
while (1)
{
}
return 1;
}
new、delete运算符,内存高级话题
#include "pch.h"
#include <iostream>
#include <vector>
#include <ctime>
#include<algorithm>
using namespace std;
namespace _nmsp1
{
//一:malloc来分配0个字节
//老手程序员和新手程序员最大区别:老手程序员对于不会或者没闹明白的东西可以不去用,但是一般不会用错;
//新手程序员正好相反,他发现系统没有报什么异常他就觉得这种用法是正确的;
//即便malloc(0)返回的是一个有效的内存地址,你也不要去动这个内存,不要修改内容,也不要去读;
// 所以不应该这样用
void func()
{
void *p = malloc(100); // 返回的是一个有效指针
//char *p = new char[0];
char *q = (char *)p;
//strcpy_s(q, 100, "这里是一个测试"); // 这行导致程序出现暗疾和隐患;
free(p); // strcpy_s 导致释放内存会崩溃
int abc;
abc = 1;
}
}
int main()
{
_nmsp1::func();
return 1;
}
new细节探秘,重载类内operator new、delete
-
一:总述与回顾:二章四节,五章二节
二:从new说起
(2.1)new类对象时加不加括号的差别
(2.1.1)如果是个空类,那么如下两种写法没有区别,现实中,你不可能光写一个空类
(2.1.2)类A中有成员变量则:( 内置类型or 无构造函数 )
带括号的初始化会把一些和成员变量有关的内存清0,但不是整个对象的内存全部清0;
(2.1.3)当类A有构造函数 ,下面两种写法得到的结果一样了;
(2.1.4)不同的看上去的感觉(2.2)new干了啥
new 可以叫 关键字/操作符
new 干了两个事:一个是调用operator new(),一个是调用了类A的构造函数A *pa = new A0;
operator new (011014FBh)//函数
_malloc (011013F2h)//c语言中的malloc
A::A(); // 有构造函数就调用delete干了两个事:一个是调用了类A的析构函数,一个是调用operator delete(free)
delete pa;
A::~A();//析构函数
operator delete();
free() //c语言中的free()函数(2.3)malloc干了啥
每个操作系统 实现 都 不同
#include <iostream>
#include <vector>
using namespace std;
namespace _nmsp1 //命名空间
{
class A
{
public:
int m_i; //成员变量
A()
{
}
~A()
{
}
//virtual void func() {}
};
void func()
{
//一:总述与回顾:二章四节,五章二节
//二:从new说起
//(2.1)new类对象时加不加括号的差别
//(2.1.1)如果是个空类,那么如下两种写法没有区别,现实中,你不可能光写一个空类
//(2.1.2)类A中有成员变量则:
//带括号的初始化会把一些和成员变量有关的内存清0,但不是整个对象的内存全部清0;
//(2.1.3)当类A有构造函数 ,下面两种写法得到的结果一样了;
//(2.1.4)不同的看上去的感觉
//(2.2)new干了啥
//new 可以叫 关键字/操作符
//new 干了两个事:一个是调用operator new(malloc),一个是调用了类A的构造函数
//delete干了两个事:一个是调用了类A的析构函数,一个是调用operator delete(free)
//(2.3)malloc干了啥
//(2.4)总结
A *pa = new A(); //函数调用
//....
delete pa;
A *pa2 = new A;
int *p3 = new int; //初值随机
int *p4 = new int(); //初值 0
int *p5 = new int(100); //初值100
//operator new(120);
//operator delete();
//malloc()
//free();
int abc;
abc = 6;
}
}
int main()
{
_nmsp1::func();
return 1;
}
new细节探秘,重载类内operator new、 delete
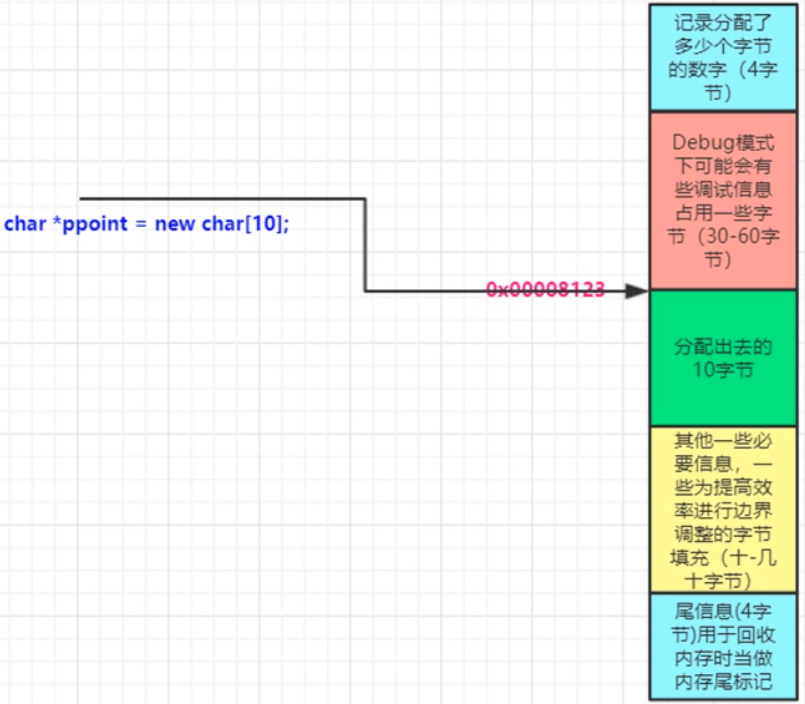
用 visual studio 内存功能 观察到
-
分配内存这个事,绝不是简单的分配出去4个字节,而是在这4个字节周围,编译器做了很多处理,比如记录分配出去的字节数等等;
分配内存时,为了记录和管理分配出去的内存,额外多分配了不少内存,造成了浪费;尤其是你频繁的申请小块内存时,造成的浪费更明显,更严重 -
-
重载的operator new / operator delete 指接管了 new / delete 的 operator部分,构造函数和析构函数均正常执行
-
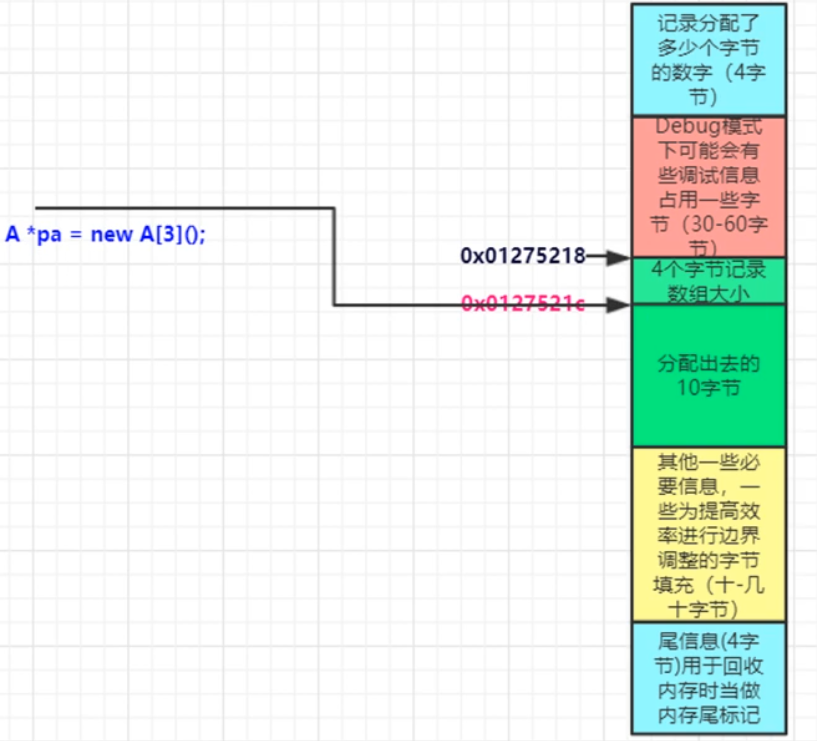
数组版本
-
A *pa = new A[3]();
构造和析构函数被调用3次,但是operator new[]和operator delete[]仅仅被调用一次;
传了7个字节 —— 多要了4个字节 记录数组大小
#include <iostream>
#include <vector>
using namespace std;
namespace _nmsp1 //命名空间
{
//一:new内存分配细节探秘
//我们注意到,一块内存的回收,影响范围很广,远远不是10个字节,而是一大片。
//分配内存这个事,绝不是简单的分配出去4个字节,而是在这4个字节周围,编译器做了很多处理,比如记录分配出去的字节数等等;
//分配内存时,为了记录和管理分配出去的内存,额外多分配了不少内存,造成了浪费;尤其是你频繁的申请小块内存时,造成的浪费更明显,更严重
//new, delete, (malloc,free)内存没有看上去那么简单,他们的工作内部是很复杂的;
void func()
{
char *ppoint = new char[10];
memset(ppoint, 0, 10);
delete[] ppoint;
/*int *ppointint = new int(10);
*ppointint = 2000000000;
delete ppointint;*/
}
}
namespace _nmsp2 //命名空间
{
//二:重载类中的operator new和operator delete操作符
/*void *temp = operator new(sizeof(A));
A *pa = static_cast<A*>(temp);
pa->A::A();*/
/*pa->A::~A();
operator delete(pa);*/
class A
{
public:
static void *operator new(size_t size); // 静态成员函数跟着类走到
static void operator delete(void *phead);
//int m_i = 0;
A()
{
int abc;
abc = 10;
}
~A()
{
int abc;
abc = 1;
}
};
void *A::operator new(size_t size)
{
//.....
A *ppoint = (A *)malloc(size);
return ppoint;
}
void A::operator delete(void *phead)
{
//...
free(phead);
}
void func()
{
/*A *pa = new A();
delete pa;*/
A *pa = ::new A(); //::全局操作符
::delete pa;
}
}
namespace _nmsp3
{
//三:重载类中的operator new[]和operator delete[]操作符
class A
{
public:
//static void *operator new(size_t size);
//static void operator delete(void *phead);
//int m_i = 0;
static void *operator new[](size_t size);
static void operator delete[](void *phead);
A()
{
int abc;
abc = 10;
}
~A()
{
int abc;
abc = 1;
}
};
void *A::operator new[](size_t size)
{
//.....
A *ppoint = (A *)malloc(size);
return ppoint;
}
void A::operator delete[](void *phead)
{
//...
free(phead);
}
void func()
{
/*A *pa = new A();
delete pa;*/
A *pa = new A[3](); //构造和析构函数被调用3次,但是operator new[]和operator delete[]仅仅被调用一次;
delete[] pa;
}
}
int main()
{
//_nmsp1::func();
//_nmsp2::func();
_nmsp3::func();
return 1;
}
空类 一个字节
Conclusion:
其实这是C++中空类占位问题。
在C++中空类会占一个字节,这是为了让对象的实例能够相互区别。具体来说,空类同样可以被实例化,并且每个实例在内存中都有独一无二的地址,因此,编译器会给空类隐含加上一个字节,这样空类实例化之后就会拥有独一无二的内存地址。如果没有这一个字节的占位,那么空类就无所谓实例化了,因为实例化的过程就是在内存中分配一块地址。
注意:当该空白类作为基类时,该类的大小就优化为0了,这就是所谓的空白基类最优化。
内存池概念、代码实现和详细分析
-
(1)减少malloc的次数,减少malloc()调用次数就意味着减少对内存的浪费 ;
(2)减少malloc的调用次数,是否能够提高程序运行效率? 会有一些速度和效率上的提升,但是提升不明显; -
“内存池的实现原理”:
(1)用malloc申请一大块内存,当你要分配的时候,我从这一大块内存中一点一点的分配给你,当一大块内存分配的差不多的时候,我再用malloc再申请一大块内存,然后再一点一点的分配给你;减少内存浪费,提高运行效率;
-
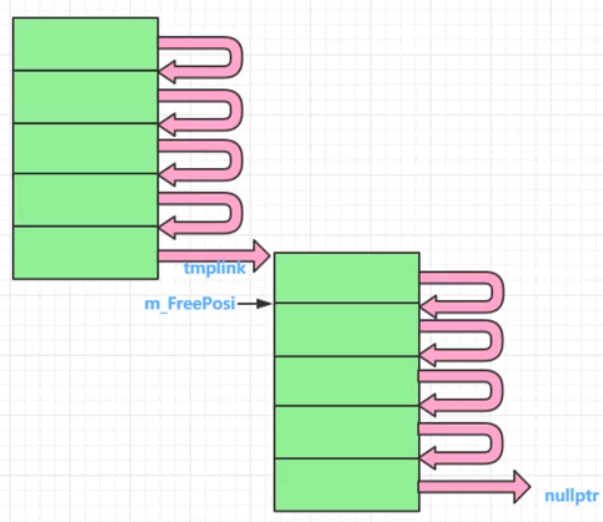
二:针对一个类的内存池实现演示代码
针对一个类的内存池 A,
A *pa = new A(), delete pa; 用内存池的手段实现new,delete一个对象; -
-
#include "pch.h"
#include <iostream>
#include <vector>
#include <ctime>
using namespace std;
namespace _nmsp1 //命名空间
{
//一:内存池的概念和实现原理概述
//malloc:内存浪费,频繁分配小块内存,则浪费更加显得明显
//“内存池”,要解决什么问题?
//(1)减少malloc的次数,减少malloc()调用次数就意味着减少对内存的浪费
//(2)减少malloc的调用次数,是否能够提高程序运行效率? 会有一些速度和效率上的提升,但是提升不明显;
//“内存池的实现原理”:
//(1)用malloc申请一大块内存,当你要分配的时候,我从这一大块内存中一点一点的分配给你,当一大块内存分配的差不多的时候,我
//再用malloc再申请一大块内存,然后再一点一点的分配给你;
//减少内存浪费,提高运行效率;
void func()
{
}
}
namespace _nmsp2
{
#define MYMEMPOOL 1
//二:针对一个类的内存池实现演示代码
//针对一个类的内存池 A,
//A *pa = new A() ,delete pa; 用内存池的手段实现new,delete一个对象;
//三:内存池代码后续说明
class A
{
public:
static void *operator new(size_t size);
static void operator delete(void *phead);
static int m_iCout; //分配计数统计,每new一次,就统计一次
static int m_iMallocCount; //每malloc一次,我统计一次
private:
A *next;
static A* m_FreePosi; //总是指向一块可以分配出去的内存的首地址
static int m_sTrunkCout; //一次分配多少倍的该类内存
};
int A::m_iCout = 0;
int A::m_iMallocCount = 0;
A *A::m_FreePosi = nullptr;
int A::m_sTrunkCout = 5; //一次分配5倍的该类内存作为内存池子的大小
void *A::operator new(size_t size)
{
#ifdef MYMEMPOOL
A *ppoint = (A*)malloc(size);
return ppoint;
#endif
A *tmplink;
if (m_FreePosi == nullptr)
{
//为空,我要申请内存,要申请一大块内存
size_t realsize = m_sTrunkCout * size; //申请m_sTrunkCout这么多倍的内存
m_FreePosi = reinterpret_cast<A*>(new char[realsize]); //传统new,调用的系统底层的malloc
tmplink = m_FreePosi;
//把分配出来的这一大块内存(5小块),彼此要链起来,供后续使用
for (; tmplink != &m_FreePosi[m_sTrunkCout - 1]; ++tmplink)
{
tmplink->next = tmplink + 1;
}
tmplink->next = nullptr;
++m_iMallocCount;
}
tmplink = m_FreePosi;
m_FreePosi = m_FreePosi->next;
++m_iCout;
return tmplink;
}
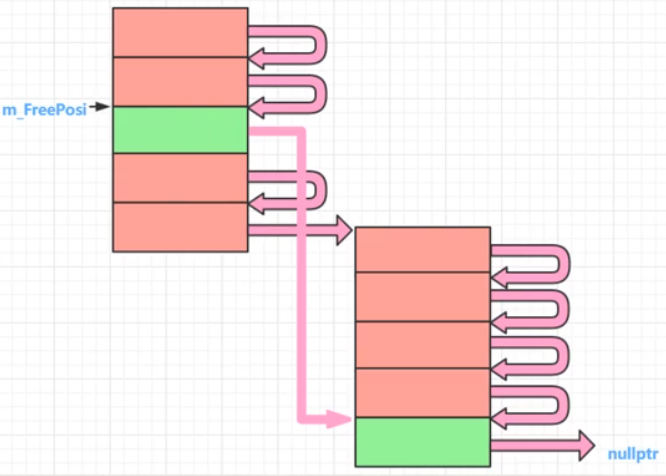
void A::operator delete(void *phead) // 这里未能真正回收内存
{
#ifdef MYMEMPOOL
free(phead);
return;
#endif
(static_cast<A*>(phead))->next = m_FreePosi;
m_FreePosi = static_cast<A*>(phead);
}
void func()
{
clock_t start, end; //包含头文件 #include <ctime>
start = clock();
//for (int i = 0; i < 500'0000; i++)
for (int i = 0; i < 15; i++)
{
A *pa = new A();
printf("%p\n", pa);
}
end = clock();
cout << "申请分配内存的次数为:" << A::m_iCout << " 实际malloc的次数为:" << A::m_iMallocCount << " 用时(毫秒): " << end - start << endl;
}
}
int main()
{
//_nmsp1::func();
_nmsp2::func();
return 1;
}
- 5块
申请分配内存的次数为: 5000000实际malloc的次数为:1000000用时(毫秒):551
500-650毫秒之间 - 50块
申请分配内存的次数为:5000000实际malloc的次数为:100000用时(毫秒):350
340-460毫秒之间 - 500块
申请分配内存的次数为:5000000实际malloc的次数为:10000用时(毫秒): 333
320-450毫秒之间 - 原装的:
申请分配内存的次数为:О实际malloc的次数为:0用时(毫秒):1234
嵌入式指针概念及范例、内存池改进版
- 一:嵌入式指针(embedded pointer) —— 把 A* next 去掉
(1.1)嵌入式指针概念
一般应用在内存池相关的代码中; 成功使用嵌入式指针有个前提条件:(类A对象的sizeof必须不小于4字节)
嵌入式指针工作原理:借用 (暂时) A对象所占用的内存空间中的前4个字节,这4个字节用来 链住这些空闲的内存块;
但是,一旦某一块被分配出去,那么这个块的 前4个字节 就不再需要,此时这4个字节可以被正常使用;
(1.2)嵌入式指针演示代码
sizeof()超过4字节的类就可以安全的使用嵌入式指针,因为,在当前的vs2017环境下,指针的sizeof值是4
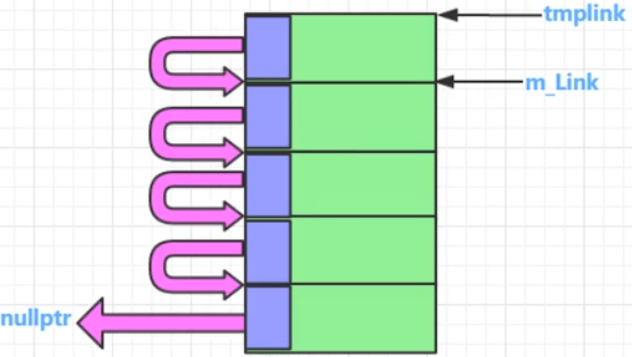
void func()
{
TestEP mytest;
cout << sizeof(mytest) << endl; //8
TestEP::obj *ptemp; //定义一个指针
ptemp = (TestEP::obj *)&mytest; //把对象mytest首地址给了这个指针ptemp,这个指针ptemp指向对象mytest首地址;
cout << sizeof(ptemp->next) << endl; //4
cout << sizeof(TestEP::obj) << endl; //4
ptemp->next = nullptr;
}
#include <iostream>
#include <vector>
#include <ctime>
using namespace std;
namespace _nmsp1 //命名空间
{
//一:内存池的概念和实现原理概述
//malloc:内存浪费,频繁分配小块内存,则浪费更加显得明显
//“内存池”,要解决什么问题?
//(1)减少malloc的次数,减少malloc()调用次数就意味着减少对内存的浪费
//(2)减少malloc的调用次数,是否能够提高程序运行效率? 会有一些速度和效率上的提升,但是提升不明显;
//“内存池的实现原理”:
//(1)用malloc申请一大块内存,当你要分配的时候,我从这一大块内存中一点一点的分配给你,当一大块内存分配的差不多的时候,我
//再用malloc再申请一大块内存,然后再一点一点的分配给你;
//减少内存浪费,提高运行效率;
void func()
{
}
}
namespace _nmsp2
{
//#define MYMEMPOOL 1
//二:针对一个类的内存池实现演示代码
//针对一个类的内存池 A,
//A *pa = new A() ,delete pa; 用内存池的手段实现new,delete一个对象;
//三:内存池代码后续说明
class A
{
public:
int m_i;
int m_j;
static void *operator new(size_t size);
static void operator delete(void *phead);
static int m_iCout; //分配计数统计,每new一次,就统计一次
static int m_iMallocCount; //每malloc一次,我统计一次
private:
A *next;
static A* m_FreePosi; //总是指向一块可以分配出去的内存的首地址
static int m_sTrunkCout; //一次分配多少倍的该类内存
};
int A::m_iCout = 0;
int A::m_iMallocCount = 0;
A *A::m_FreePosi = nullptr;
int A::m_sTrunkCout = 5; //一次分配5倍的该类内存作为内存池子的大小
void *A::operator new(size_t size)
{
#ifdef MYMEMPOOL
A *ppoint = (A*)malloc(size);
return ppoint;
#endif
A *tmplink;
if (m_FreePosi == nullptr)
{
//为空,我要申请内存,要申请一大块内存
size_t realsize = m_sTrunkCout * size; //申请m_sTrunkCout这么多倍的内存
m_FreePosi = reinterpret_cast<A*>(new char[realsize]); //传统new,调用的系统底层的malloc
tmplink = m_FreePosi;
//把分配出来的这一大块内存(5小块),彼此要链起来,供后续使用
for (; tmplink != &m_FreePosi[m_sTrunkCout - 1]; ++tmplink)
{
tmplink->next = tmplink + 1;
}
tmplink->next = nullptr;
++m_iMallocCount;
}
tmplink = m_FreePosi;
m_FreePosi = m_FreePosi->next;
++m_iCout;
return tmplink;
}
void A::operator delete(void *phead)
{
#ifdef MYMEMPOOL
free(phead);
return;
#endif
(static_cast<A*>(phead))->next = m_FreePosi;
m_FreePosi = static_cast<A*>(phead);
}
void func()
{
clock_t start, end; //包含头文件 #include <ctime>
start = clock();
//for (int i = 0; i < 500'0000; i++)
for (int i = 0; i < 15; i++)
{
A *pa = new A();
printf("%p\n", pa);
}
end = clock();
cout << "申请分配内存的次数为:" << A::m_iCout << " 实际malloc的次数为:" << A::m_iMallocCount << " 用时(毫秒): " << end - start << endl;
}
}
namespace _nmsp3
{
//一:嵌入式指针(embedded pointer)
//(1.1)嵌入式指针概念
//一般应用在内存池相关的代码中; 成功使用嵌入式指针有个前提条件:(类A对象的sizeof必须不小于4字节)
//嵌入式指针工作原理:借用A对象所占用的内存空间中的前4个字节,这4个字节用来 链住这些空闲的内存块;
//但是,一旦某一块被分配出去,那么这个块的 前4个字节 就不再需要,此时这4个字节可以被正常使用;
//(1.2)嵌入式指针演示代码
//sizeof()超过4字节的类就可以安全的使用嵌入式指针,因为,在当前的vs2017环境下,指针的sizeof值是4
class TestEP
{
public:
int m_i;
int m_j;
public:
struct obj //结构
{
//成员,是个指针
struct obj *next; //这个next就是个嵌入式指针
//自己是一个obj结构对象,那么把自己这个对象的next指针指向 另外一个obj结构对象,最终,把多个自己这种类型的对象通过链串起来;
};
};
void func()
{
TestEP mytest;
cout << sizeof(mytest) << endl; //8
TestEP::obj *ptemp; //定义一个指针
ptemp = (TestEP::obj *)&mytest; //把对象mytest首地址给了这个指针ptemp,这个指针ptemp指向对象mytest首地址;
cout << sizeof(ptemp->next) << endl; //4
cout << sizeof(TestEP::obj) << endl; //4
ptemp->next = nullptr;
}
}
namespace _nmsp4
{
//二:内存池代码的改进
//单独的为内存池技术来写一个类
//专门的内存池类
class myallocator //必须保证应用本类的类的sizeof()不少于4字节;否则会崩溃或者报错;
{
public:
//分配内存接口
void *allocate(size_t size)
{
obj *tmplink;
if (m_FreePosi == nullptr)
{
//为空,我要申请内存,要申请一大块内存
size_t realsize = m_sTrunkCout * size; //申请m_sTrunkCout这么多倍的内存
m_FreePosi = (obj *)malloc(realsize);
tmplink = m_FreePosi;
//把分配出来的这一大块内存(5小块),彼此用链起来,供后续使用
for (int i = 0; i < m_sTrunkCout - 1; ++i) //0--3
{
tmplink->next = (obj *)((char *)tmplink + size);
tmplink = tmplink->next;
} //end for
tmplink->next = nullptr;
} //end if
tmplink = m_FreePosi;
m_FreePosi = m_FreePosi->next;
return tmplink;
}
//释放内存接口
void deallocate(void *phead)
{
((obj *)phead)->next = m_FreePosi;
m_FreePosi = (obj *)phead;
}
private:
//写在类内的结构,这样只让其在类内使用
struct obj
{
struct obj *next; //这个next就是个嵌入式指针
};
int m_sTrunkCout = 5;//一次分配5倍的该类内存作为内存池子的大小
obj* m_FreePosi = nullptr;
};
//------------------------
#define DECLARE_POOL_ALLOC()\
public:\
static myallocator myalloc;\
static void *operator new(size_t size)\
{\
return myalloc.allocate(size);\
}\
static void operator delete(void *phead)\
{\
return myalloc.deallocate(phead);\
}\
//-----------
#define IMPLEMENT_POOL_ALLOC(classname)\
myallocator classname::myalloc;
//---------------
class A
{
DECLARE_POOL_ALLOC()
public:
int m_i;
int m_j; //为了保证sizeof(A)凑够4字节,老师演示时定义了两个int成员变量;
};
IMPLEMENT_POOL_ALLOC(A)
void func()
{
A *mypa[100];
for (int i = 0; i < 15; ++i)
{
mypa[i] = new A();
mypa[i]->m_i = 12;
mypa[i]->m_j = 15;
printf("%p\n", mypa[i]);
}
for (int i = 0; i < 15; ++i)
{
delete mypa[i];
}
}
}
int main()
{
//_nmsp1::func();
//_nmsp2::func();
//_nmsp3::func();
_nmsp4::func();
return 1;
}
重载全局new、delete,定位new及重载等
-
二:定位new(placement new)
有placement new,但是没有对应的placement delete
功能:在已经分配的原始内存中初始化一个对象;
a)已经分配,定位new并不分配内存,你需要提前将这个定位new要使用的内存分配出来
b)初始化一个对象(初始化一个对象的内存),我们就理解成调用这个对象的构造函数;
说白了,定位new就是能够在一个预先分配好的内存地址中构造一个对象;
格式:
new (地址) 类类型() -
三:多种版本的operator new重载 —— 这个版本不会调用构造函数
可以重载很多版本的operator new,只要每个版本参数不同就行,但是第一个参数是固定的,都是size_t,表示你要new对象的sizeof值形如 —— 不会自动调用构造函数
class A { public: void *operator new(size_t size, int tvp1, int tvp2) { return NULL; } A() { int test; test = 1; } }; void func() { A *pa = new (1234, 56) A(); //自定义 new }
#include "pch.h"
#include <iostream>
#include <vector>
#include <ctime>
using namespace std;
/*
void *operator new(size_t size)
{
return malloc(size);
}
void *operator new[](size_t size) //数组版本
{
return malloc(size);
}
void operator delete(void *phead)
{
free(phead);
}
void operator delete[](void *phead)
{
free(phead);
}
*/
namespace _nmsp1 //命名空间
{
//一:重载全局operator new和operator delete函数
//重载全局operator new[]和operator delete[]函数
class A
{
public:
int m_i;
int m_j;
A()
{
cout << "A::A()" << endl;
}
~A()
{
cout << "A::~A()" << endl;
}
void *operator new(size_t size)
{
A *ppoint = (A*)malloc(size);
return ppoint;
}
void *operator new[](size_t size) //数组版本
{
A *ppoint = (A*)malloc(size);
return ppoint;
}
void operator delete(void *phead)
{
free(phead);
}
void operator delete[](void *phead)
{
free(phead);
}
};
void func()
{
/*int *pint = new int(12);
delete pint;
char *parr = new char[15];
delete[] parr;
*/
A *p = new A();
delete p;
A *pa = new A[3]();
delete[] pa;
}
}
namespace _nmsp2
{
//二:定位new(placement new)
//有placement new,但是没有对应的placement delete
//功能:在已经分配的原始内存中初始化一个对象;
//a)已经分配,定位new并不分配内存,你需要提前将这个定位new要使用的内存分配出来
//b)初始化一个对象(初始化一个对象的内存),我们就理解成调用这个对象的构造函数;
//说白了,定位new就是能够在一个预先分配好的内存地址中构造一个对象;
//格式:
//new (地址) 类类型()
class A
{
public:
int m_a;
A() :m_a(0)
{
int test;
test = 1;
}
A(int tempvalue) :m_a(tempvalue)
{
int test;
test = 1;
}
~A()
{
int abc;
abc = 1;
}
//传统new操作符重载
void *operator new(size_t size)
{
A *ppoint = (A*)malloc(size);
return ppoint;
}
//定位new操作符的重载
void *operator new(size_t size,void *phead)
{
//A *ppoint = (A*)malloc(size);
//return ppoint;
return phead; //收到内存开始地址,只需要原路返回
}
};
void func()
{
void *mymemPoint = (void *)new char[sizeof(A)]; //内存必须事先分配出来
A *pmyAobj1 = new (mymemPoint) A(); //调用无参构造函数,这里并不会额外分配内存 定位new
//A *pmyAobj3 = new A();
/*void *mymemInt = (void *)new int;
int *pmyint = new (mymemPoint) int();
*/
void *mymemPoint2 = (void *)new char[sizeof(A)];
A *pmyAobj2 = new (mymemPoint2) A(12); //调用带一个参数的构造函数,这里并不会额外分配内存
//delete pmyAobj1;
//delete pmyAobj2;
pmyAobj1->~A(); //手工调用析构函数是可以的,但手工调用构造函数一般不可以
pmyAobj2->~A();
delete[](void *)pmyAobj1;
delete[](void *)pmyAobj2;
}
}
namespace _nmsp3
{
//三:多种版本的operator new重载
//可以重载很多版本的operator new,只要每个版本参数不同就行,但是第一个参数是固定的,都是size_t,表示你要new对象的sizeof值
class A
{
public:
void *operator new(size_t size, int tvp1, int tvp2)
{
return NULL;
}
A()
{
int test;
test = 1;
}
};
void func()
{
A *pa = new (1234, 56) A(); //自定义 new
}
}
int main()
{
//_nmsp1::func();
//_nmsp2::func();
_nmsp3::func();
return 1;
}
临时性对象的详细探讨
- 一:拷贝构造函数相关的临时性对象
A operator+(const A& obj1, const A& obj2)
{
A tmpobj;
printf("tmpobj的地址为%p\n", &tmpobj);
printf("---------------------\n");
//.....
return tmpobj; //编译器产生临时对象,把tmpobj对象的内容通过调用拷贝构造函数 把tmpobj的内容拷贝构造给这个临时对象;
//然后返回的是这个临时对象;
}
void func()
{
A myobj1;
printf("myobj1的地址为%p\n", &myobj1);
A myobj2;
printf("myobj2的地址为%p\n", &myobj2);
A resultobj = myobj1 + myobj2; //这个从operator +里返回的临时对象直接构造到了resultobj里;
printf("resultobj的地址为%p\n", &resultobj);
return;
}
- 二:拷贝赋值运算符相关的临时性对象 —— 多一次默认构造函数
A operator+(const A& obj1, const A& obj2)
{
A tmpobj;
printf("tmpobj的地址为%p\n", &tmpobj);
//printf("---------------------\n");
//.....
return tmpobj; //编译器产生临时对象,把tmpobj对象的内容通过调用拷贝构造函数 把tmpobj的内容拷贝构造给这个临时对象;
//然后返回的是这个临时对象;
}
void func()
{
A myobj1;
printf("myobj1的地址为%p\n", &myobj1);
A myobj2;
printf("myobj2的地址为%p\n", &myobj2);
A resultobj;
resultobj = myobj1 + myobj2; //拷贝赋值运算符
//A resultobj = myobj1 + myobj2; //拷贝构造函数
printf("resultobj的地址为%p\n", &resultobj);
return;
}
-
三:直接运算产生的临时性对象
(3.1)临时对象被摧毁const char *p = (string("123") + string("456")).c_str(); //这一行有问题,因为临时对象过了这行就被摧毁;(3.2)临时对象因绑定到引用而被保留
const string &aaa = string("123") + string("456");临时对象的析构是整行语句的最后一步,这样就能保证printf打印出来一个有效值;
void func()
{
/*A myobj1;
myobj1.m_i = 1;
A myobj2;
myobj2.m_i = 2;*/
//A resultobj = myobj1 +myobj2;
//myobj1 + myobj2; //产生了临时对象,然后该临时对象立即被析构;
//printf("(myobj1 + myobj2).m_i = %d\n", (myobj1 + myobj2).m_i); //临时对象的析构是整行语句的最后一步,这样就能保证printf打印出来一个有效值;
//A tmpobja1 = (myobj1 + myobj1); 编译器要往必要的地方,帮助我们插入代码,来产生临时对象供编译器完成我们程序开发者代码要实现的意图;
/*if ((myobj1 + myobj1).m_i > 1 || (myobj1 + myobj2).m_i > 5)
{
int abc;
abc = 4;
}*/
//const char *p = (string("123") + string("456")).c_str(); //这一行有问题,因为临时对象过了这行就被摧毁;
//string aaa = (string("123") + string("456"));
//const char *q = aaa.c_str(); //这个应该OK
//printf("p = %s\n", p);
//printf("q = %s\n", q);
const string &aaa = string("123") + string("456");
printf("aaa = %s\n", aaa.c_str());
return;
}
#include "pch.h"
#include <iostream>
#include <vector>
#include <ctime>
#include<algorithm>
using namespace std;
namespace _nmsp1
{
//一:拷贝构造函数相关的临时性对象
class A
{
public:
A()
{
cout << "A::A()构造函数被执行" << endl;
}
A(const A& tmpobj)
{
cout << "A::A()拷贝构造函数被执行" << endl;
}
~A()
{
cout << "A::~A()析构函数被执行" << endl;
}
};
A operator+(const A& obj1, const A& obj2)
{
A tmpobj;
printf("tmpobj的地址为%p\n", &tmpobj);
printf("---------------------\n");
//.....
return tmpobj; //编译器产生临时对象,把tmpobj对象的内容通过调用拷贝构造函数 把tmpobj的内容拷贝构造给这个临时对象;
//然后返回的是这个临时对象;
}
void func()
{
A myobj1;
printf("myobj1的地址为%p\n", &myobj1);
A myobj2;
printf("myobj2的地址为%p\n", &myobj2);
A resultobj = myobj1 + myobj2; //这个从operator +里返回的临时对象直接构造到了resultobj里;
printf("resultobj的地址为%p\n", &resultobj);
return;
}
}
namespace _nmsp2
{
//二:拷贝赋值运算符相关的临时性对象
class A
{
public:
A()
{
cout << "A::A()构造函数被执行" << endl;
}
A(const A& tmpobj)
{
cout << "A::A()拷贝构造函数被执行" << endl;
}
A & operator=(const A& tmpaobj)
{
cout << "A::operator()拷贝赋值运算符被执行" << endl;
printf("拷贝赋值运算符中tmpaobj的地址为%p\n", &tmpaobj);
return *this;
}
~A()
{
cout << "A::~A()析构函数被执行" << endl;
}
};
A operator+(const A& obj1, const A& obj2)
{
A tmpobj;
printf("tmpobj的地址为%p\n", &tmpobj);
//printf("---------------------\n");
//.....
return tmpobj; //编译器产生临时对象,把tmpobj对象的内容通过调用拷贝构造函数 把tmpobj的内容拷贝构造给这个临时对象;
//然后返回的是这个临时对象;
}
void func()
{
A myobj1;
printf("myobj1的地址为%p\n", &myobj1);
A myobj2;
printf("myobj2的地址为%p\n", &myobj2);
A resultobj;
resultobj = myobj1 + myobj2; //拷贝赋值运算符
//A resultobj = myobj1 + myobj2; //拷贝构造函数
printf("resultobj的地址为%p\n", &resultobj);
return;
}
}
namespace _nmsp3
{
//三:直接运算产生的临时性对象
//(3.1)临时对象被摧毁
//(3.2)临时对象因绑定到引用而被保留
class A
{
public:
A()
{
cout << "A::A()构造函数被执行" << endl;
}
A(const A& tmpobj)
{
cout << "A::A()拷贝构造函数被执行" << endl;
m_i = tmpobj.m_i;
}
A & operator=(const A& tmpaobj)
{
cout << "A::operator()拷贝赋值运算符被执行" << endl;
return *this;
}
~A()
{
cout << "A::~A()析构函数被执行" << endl;
}
int m_i;
};
A operator+(const A& obj1, const A& obj2)
{
A tmpobj;
tmpobj.m_i = obj1.m_i + obj2.m_i;
return tmpobj; //编译器产生临时对象,把tmpobj对象的内容通过调用拷贝构造函数 把tmpobj的内容拷贝构造给这个临时对象;
//然后返回的是这个临时对象;
}
void func()
{
/*A myobj1;
myobj1.m_i = 1;
A myobj2;
myobj2.m_i = 2;*/
//A resultobj = myobj1 +myobj2;
//myobj1 + myobj2; //产生了临时对象,然后该临时对象立即被析构;
//printf("(myobj1 + myobj2).m_i = %d\n", (myobj1 + myobj2).m_i); //临时对象的析构是整行语句的最后一步,这样就能保证printf打印出来一个有效值;
//A tmpobja1 = (myobj1 + myobj1); 编译器要往必要的地方,帮助我们插入代码,来产生临时对象供编译器完成我们程序开发者代码要实现的意图;
/*if ((myobj1 + myobj1).m_i > 1 || (myobj1 + myobj2).m_i > 5)
{
int abc;
abc = 4;
}*/
//const char *p = (string("123") + string("456")).c_str(); //这一行有问题,因为临时对象过了这行就被摧毁;
//string aaa = (string("123") + string("456"));
//const char *q = aaa.c_str(); //这个应该OK
//printf("p = %s\n", p);
//printf("q = %s\n", q);
const string &aaa = string("123") + string("456");
printf("aaa = %s\n", aaa.c_str());
return;
}
}
int main()
{
//_nmsp1::func();
//_nmsp2::func();
_nmsp3::func();
return 1;
}















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









