







Linux 内核活动专题
主要参考了《深入linux内核》和《Linux内核深度解析》,简单浅析了一下相关内容
硬件中断及软中断
需要区分两种类型的中断(广义)。
-
硬件中断(hardware interrupt):由系统自身和与之连接的外设自动产生。它们用于支持更高效地实现设备驱动程序,也用于引起处理器自身对异常或错误的关注,这些是需要与内核代码进行交互的。
-
软中断(SoftIRQ soft interrupt request):用于有效实现内核中的延期操作。
与内核的其他部分相比,用于处理中断和系统调用相关部分的代码中,汇编和C代码交织在一起,以解决C语言无法独立处理的一些微妙问题。
硬件中断(CPU或外部设备产生)
通常,各种类型的中断可分为如下两个类别
- **同步中断和异常。这些由CPU自身产生,针对当前执行的程序。**异常可能因种种原因触发:由于运行时发生的程序设计错误(典型的例子是除0),或由于出现了异常的情况或条件,致使处理器需要“外部”的帮助才能处理。
- 在前一种情况下,内核必须通知应用程序出现了异常。举例来说,内核可以使用第5章描述的信号机制。这使得应用程序有机会改正错误、输出适当的错误消息或直接结束。
- 异常情况不见得是由进程直接导致的,但必须借助于内核才能修复。一个可能的例子是缺页异常,在进程试图访问虚拟地址空间的一页,而该页不在物理内存中时,才会发生此类异常。
- 此时,内核必须与CPU交互,确保将预期的数据取入物理内存。接下来,进程可以在发生异常的位置恢复执行。由于内核自动恢复了这种情况,进程甚至不会注意到缺页异常的存在。
- 异步中断。这是经典的中断类型,由外部设备产生,可能发生在任意时间。
- **不同于同步中断,异步中断并不与特定进程关联。它们可能发生在任何时间,而不牵涉系统当前执行的活动。**网卡通过发出一个相关的中断来报告新分组的到达。因为数据可能在任意时刻到达系统,所以当前执行的很可能是与数据无关的某个进程或其他东西。为避免损害该进程,内核必须确保中断能够尽快处理完毕(通过缓冲数据),使得CPU时间能够返还给当前进程。这也是内核需要延期操作机制的原因,该机制也在本章讨论。
两类中断的共同特性是什么?如果CPU当前不处于核心态,则发起从用户态到核心态的切换。接下来,在内核中执行一个专门的例程,称为中断服务例程(interrupt service routine,简称ISR)或中断处理程序(interrupt handler)。
该例程的作用是处理异常条件或情况,毕竟,中断的作用就在于引起内核对此类改变的关注。
禁用中断
同步和异步中断之间的简单区别,并不足以描述这两类类型中断的特性。还需要考虑另一方面。许多中断可以禁用,但有些不行。举例来说,后一类就包括了因硬件故障或其他系统关键事件而发出的中断。
在可能的情况下,内核试图避免禁用中断,因为这显然会损害系统性能。但有些场合禁用中断是必要的,这是为防止内核遇到一些严重的麻烦。在仔细考察中断处理程序时,读者会看到,在处理第一个中断时,如果发生第二个中断,内核中可能发生严重的问题。如果内核在处理关键代码时发生了中断,那么可能会发生第5章讨论的同步问题。在最坏情况下,这可能引起内核死锁,致使整个系统变得不可用。
如果内核容许在禁用中断的情况下,花费过多时间处理一个ISR,那么可能(也必将)会丢失一些对系统正确运作必不可少的中断。 内核为解决该问题,将中断处理程序划分为两个部分,性能关键的前一部分在禁用中断时执行,而不那么重要的后一部分延期执行,进行所有次要的操作。早期的内核版本也包含了一种同名机制,用于将操作延期一段时间执行。但该机制已经被更高效的机制取代,将在下文讨论。
每个中断都有一个编号。如果中断号n分配给一个网卡而m(≠n)分配给SCSI控制器,那么内核即可区分两个设备,并在中断发生时调用对应的ISR来执行特定于设备的操作。当然,同样的原则也适应于异常,不同的异常指派了不同的编号。
遗憾的是,由于特别设计(通常是历史上的)的“特性”(IA-32体系结构就是一个恰当的特例),情况并不总是像描述的那样简单。**因为只有很少的编号可用于硬件中断,所以必须由几个设备共享一个编号。**在IA-32处理器上,硬件中断的最大数目通常是15,这个值可不怎么大,还有考虑到有些中断编号已经永久性地分配给了标准的系统组件(键盘、定时器,等等),因而限制了可用于其他外部设备的中断编号数目。
这个过程称为中断共享(interrupt sharing)。但必须硬件和内核同时支持才能使用该技术,因为必须要识别出中断来源于哪个设备。本章将更详细地阐述该机制。
硬件IRQ(外部设备发出)与中断控制器
以前,中断这个名词使用得很不谨慎,用来表示由CPU和外部硬件发出的中断。明白的读者当然会注意到这陈述得不大准确。中断不能由处理器外部的外设直接产生,而必须借助于一个称为中断控制器(interrupt controller)的标准组件来请求,该组件存在于每个系统中。
外部设备(或其槽位),会有电路连接到用于向中断控制器发送中断请求的组件。控制器在执行了各种电工任务(我们对此没有更多兴趣)之后,将中断请求转发到CPU的中断输入。因为外部设备不能直接发出中断,而必须通过上述组件请求中断,所以这种请求更正确的叫法是IRQ,或中断请求(interrupt request)。
因为就软件而言,IRQ和中断之间的差别不是那么大,这两个术语通常可替换使用。在所指的语义清楚的情况下,这不成问题。
但这里的一个要点涉及IRQ和中断的数目,我们绝不能忽视这一点,因为它会影响到软件。对大多数CPU来说,都只是从可用于处理硬件中断的整个中断号范围抽取一小部分使用。抽取出的范围通常位于所有中断号序列的中部,例如,IA-32 CPU总共提供了16个中断号,从32到47。
如果读者曾经在IA-32系统上配置过I/O扩展卡,或研究过/proc/interrupts的内容,那么就会了解到,扩展卡的IRQ编号从0开始,到15结束,当然,前提是使用了典型的中断控制器8256A。这意味着这里同样有16个不同的选项,但数值不同。
中断控制器除了负责IRQ信号的电工处理之外,还会对IRQ编号和中断号进行一个“转换”。 在IA-32系统上,加32即可。如果设备发出IRQ 9,CPU将产生中断41,在安装中断处理程序时必须考虑到这一点。其他体系结构在中断号和IRQ编号之间采用其他映射方式,这里不会详细阐述。
处理中断(概述)
在CPU得知发生中断后,它将进一步的处理委托给一个软件例程,该例程可能会修复故障、提供专门的处理或将外部事件通知用户进程。由于每个中断和异常都有唯一的编号,内核使用一个数组,数组项是指向处理程序函数的指针。相关的中断号根据数组项在数组中的位置判断,如图14-1所示。

进入和退出任务
如图14-2所示,中断处理划分为3部分。首先,必须建立一个适当的环境,使得处理程序函数能够在其中执行,接下来调用处理程序自身,最后将系统复原(在当前程序看来)到中断之前的状态。调用中断处理程序前后的两部分,分别称为进入路径(entry path)和退出路径(exit path)。
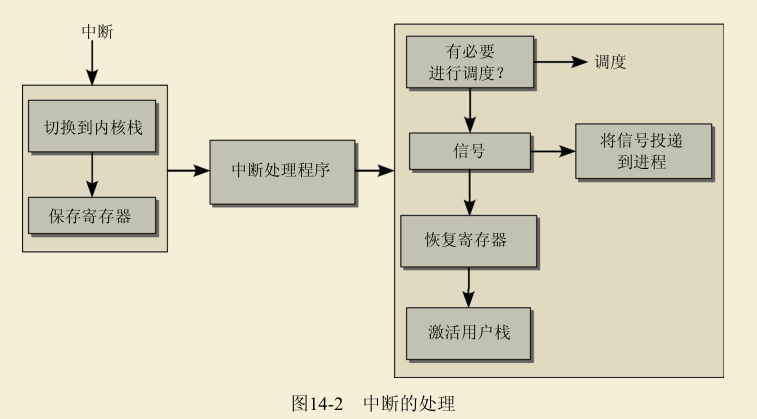
进入和退出任务还负责确保处理器从用户态切换到核心态。进入路径的一个关键任务是,从用户态栈切换到核心态栈。但是,只有这一点还不够。因为内核还要使用CPU资源执行其代码,进入路径必须保存用户应用程序当前的寄存器状态,以便在中断活动结束后恢复。这与调度期间用于上下文切换的机制是相同的。在进入核心态时,只保存整个寄存器集合的一部分。内核并不使用全部寄存器。
举例来说,内核代码中不使用浮点操作(只有整数计算),因而并不保存浮点寄存器。浮点寄存器的值在执行内核代码时不会改变。平台相关的数据结构pt_regs列出了核心态可能修改的所有寄存器,它的定义考虑到了不同的CPU之间的差别(14.1.7节将仔细考察该结构)。在汇编语言编写的底层例
程负责填充该结构。
在退出路径中,内核会检查下列事项。
- 调度器是否应该选择一个新进程代替旧的进程。
- 是否有信号必须投递到原进程。
从中断返回之后,只有确认了这两个问题,内核才能完成其常规任务,即还原寄存器集合、切换到用户态栈、切换到适用于用户应用程序的适当的处理器状态,或切换到一个不同的保护环。因为需要C语言代码和汇编语言代码之间的交互,所以必须特别小心,才能正确设计在汇编语言层次和C语言层次上的数据交换。对应的代码位于arch/arch/kernel/entry.S中,彻底利用了各个处理器的具体特性。为此,该文件的内容应该尽可能少修改,即使修改也必须极其小心。
在中断到达时,处理器可能处于用户态或核心态,这使得中断的进入和退出路径中的工作更为困难。这需要另外几个技术上的修改,为确保图示简明,没有在图14-2中给出。(有可能无须切换核心态栈和用户态栈,也有可能无须检查是否要调用调度器或投递信号。)
术语中断处理程序(interrupt handler)的使用是可能引起岐义的。它用于指代CPU对ISR(中断服务程序)的调用,包括了进入/退出路径和ISR本身。当然,如果只指代在进入路径和退出路径之间执行、由C语言实现的例程,将更为准确。
中断处理程序
中断处理程序可能会遇到困难,特别是,在处理程序执行期间,发生了其他中断。尽管可以通过在处理程序执行期间禁用中断来防止,但这会引起其他问题,如遗漏重要的中断。屏蔽(Masking,这个术语用于表示选择性地禁用一个或多个中断)因而只能短时间使用。
因此ISR必须满足如下两个要求。
- (1) 实现(特别是在禁用其他中断时)必须包含尽可能少的代码,以支持快速处理。
- (2) 可以在其他ISR执行期间调用的中断处理程序例程,不能彼此干扰。
尽管后一个要求可以通过高超的编程和精巧的ISR设计来满足,然而前一个要求更难满足。根据具体的中断,必须运行某个程序,来满足中断处理的最低要求。因而代码长度无法任意缩减。
内核如何解决这种两难问题呢?并非ISR的每个部分都同等重要。通常,每个处理程序例程都可以划分为3个部分,具有不同的意义。
- 关键操作必须在中断发生后立即执行。 否则,无法维持系统的稳定性,或计算机的正确运作。在执行此类操作期间,必须禁用其他中断。
- 非关键操作也应该尽快执行,但允许启用中断(因而可能被其他系统事件中断)。
- 可延期操作不是特别重要,不必在中断处理程序中实现。 内核可以延迟这些操作,在时间充裕时进行。内核提供了tasklet,用于在稍后执行可延期操作。14.3节将更详细地阐述tasklet。
数据结构
中断技术上的实现有两方面:汇编语言代码,与处理器高度相关,用于处理特定平台上相关的底层细节;抽象接口,是设备驱动程序及其他内核代码安装和管理IRQ处理程序所需的。本节主要关注第二方面。描述汇编语言部分的功能会涉及无数细节,可以参考处理器体系结构方面的书籍或手册。
为响应外部设备的IRQ,内核必须为每个潜在的IRQ提供一个函数。该函数必须能够动态注册和注销。静态表组织方式是不够的,因为可能为设备编写模块,而且设备可能与系统的其他部分通过中断进行交互。
IRQ相关信息管理的关键点是一个全局数组,每个数组项对应一个IRQ编号。因为数组位置和中断号是相同的,很容易定位与特定的IRQ相关的数组项:IRQ 0在位置0,IRQ 15在位置15,等等。IRQ最终映射到哪个处理器中断,在这里是不相关的。
kernel\irq\irqdesc.c
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
[0 ... NR_IRQS-1] = {
.handle_irq = handle_bad_irq,
.depth = 1,
.lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
}
};
中断处理子系统的各部分及交互方式
内核在2.6之前的版本包含了大量平台相关代码来处理IRQ,在许多地方是相同的。因而,在内核版本2.6开发期间,引入了一个新的通用的IRQ子系统。**它能够以统一的方式处理不同的中断控制器和不同类型的中断。**基本上,它由3个抽象层组成,如图14-3所示。
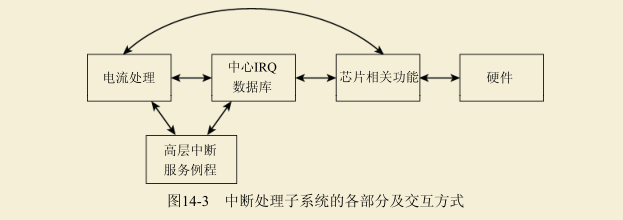
**(1) 高层ISR(high-level interrupt service routines,高层中断服服务例程)针对设备驱动程序端(或其他内核组件)的中断,执行由此引起的所有必要的工作。**例如,如果设备使用中断通知一些数据已经到达,那么高层ISR的工作应该是将数据复制到适当的位置。
(2) 中断电流处理(interrupt flow handling):处理不同的中断电流类型之间的各种差别,如边沿触发(edge-triggering)和电平触发(level-triggering)。
边沿触发意味着硬件通过感知线路上的电位差来检测中断。在电平触发系统中,根据特定的电势值检测中断,与电势是否改变无关。
从内核的角度来看,电平触发更为复杂,因为在每个中断后,都需要将线路明确设置为一个特定的电势,表示“没有中断”。
(3) 芯片级硬件封装(chip-level hardware encapsulation):需要与在电子学层次上产生中断的底层硬件直接通信。该抽象层可以视为中断控制器的某种“设备驱动程序”。
irq_desc 中断描述符
用于表示IRQ描述符的结构定义如下(稍有简化):
struct irq_desc {
struct irq_common_data irq_common_data;
struct irq_data irq_data; // 含irq_chip
unsigned int __percpu *kstat_irqs;
irq_flow_handler_t handle_irq;
#ifdef CONFIG_IRQ_PREFLOW_FASTEOI
irq_preflow_handler_t preflow_handler;
#endif
struct irqaction *action; /* IRQ操作列表 */
unsigned int status_use_accessors;
unsigned int core_internal_state__do_not_mess_with_it;
unsigned int depth; /* 嵌套停用irq */
unsigned int wake_depth; /* nested wake enables */
unsigned int irq_count; /* 用于检测错误的中断 */
unsigned long last_unhandled; /* Aging timer for unhandled count */
unsigned int irqs_unhandled;
atomic_t threads_handled;
int threads_handled_last;
raw_spinlock_t lock;
struct cpumask *percpu_enabled;
const struct cpumask *percpu_affinity;
...
const char *name;
} ____cacheline_internodealigned_in_smp;
从内核中高层代码的角度来看,每个IRQ都可以由该结构完全描述。上面介绍的3个抽象层在该结构中表示如下。
- 电流层ISR由handle_irq提供 (中断电流处理)。 handler_data可以指向任意数据,该数据可以是特定于IRQ或处理程序的。
- **每当发生中断时,特定于体系结构的代码都会调用handle_irq。该函数负责使用chip中提供的特定于控制器的方法,进行处理中断所必需的一些底层操作。**用于不同中断类型的默认函数由内核提供。14.1.5节将讨论此类处理程序函数的例子。
- action提供了一个操作链 (高层ISR),需要在中断发生时执行。由中断通知的设备驱动程序,可以将与之相关的处理程序函数放置在此处。 有一个专门的数据结构用于表示这些操作,在14.1.4节讨论。
- 电流处理和芯片相关操作被封装在chip中 (芯片级硬件封装)。 为此引入了一个专门的数据结构,稍后讲述。chip_data指向可能与chip相关的任意数据。
name指定了电流层处理程序的名称,将显示在/proc/interrupts中。对边沿触发中断,通常是“edge”,对电平触发中断,通常是“level”。
结构中还有一些成员需要描述。 **depth有两个任务。它可用于确定IRQ电路是启用的还是禁用的。正值表示禁用,而0表示启用。**为什么用正值表示禁用的IRQ呢?因为这使得内核能够区分启用和禁用的IRQ电路,以及重复禁用同一中断的情形。这个值相当于一个计数器,内核其余部分的代码每次禁用某个中断,则将对应的计数器加1;每次中断被再次启用,则将计数器减1。在depth归0时,硬件才能再次使用对应的IRQ。这种方法能够支持对嵌套禁用中断的正确处理。
IRQ不仅可以在处理程序安装期间改变其状态,而且可以在运行时改变:status描述了IRQ的当前状态。<irq.h>文件定义了各种常数,可用于描述IRQ电路当前的状态。每个常数表示位串中一个置位的标志位,只要不相互冲突,几个标志可以同时设置。
irq_chip 硬件中断芯片描述符
handler是一个hw_irq_controller数据类型的实例,该类型抽象出了一个IRQ控制器的具体特征,可用于内核的体系结构无关部分。它提供的函数用于改变IRQ的状态,这也是它们还负责设置flag的原因:
struct irq_chip {
struct device *parent_device;
const char *name;
unsigned int (*startup)(unsigned int irq);
void (*shutdown)(unsigned int irq);
void (*enable)(unsigned int irq);
void (*disable)(unsigned int irq);
void (*ack)(unsigned int irq);
void (*mask)(unsigned int irq);
void (*mask_ack)(unsigned int irq);
void (*unmask)(unsigned int irq);
void (*eoi)(unsigned int irq);
void (*end)(unsigned int irq);
void (*set_affinity)(unsigned int irq, cpumask_t dest);
...
int (*set_type)(unsigned int irq, unsigned int flow_type);
...
该结构需要考虑内核中出现的各个IRQ实现的所有特性。因而,一个该结构的特定实例,通常只定义所有可能方法的一个子集。
name包含一个短的字符串,用于标识硬件控制器。在IA-32系统上可能的值是“XTPIC”和“IO-APIC”,在AMD64系统上大多数情况下也会使用后者。在其他系统上有各种各样的值,因为有许多不同的控制器类型,其中很多类型都得到了广泛应用。
各个函数指针的语义如下。
-
startup指向一个函数,用于第一次初始化一个IRQ。大多数情况下,初始化工作仅限于启用该IRQ。因而,startup函数实际上就是将工作转给enable。
-
enable激活一个IRQ。换句话说,它执行IRQ由禁用状态到启用状态的转换。为此,必须向I/O内存或I/O端口中硬件相关的位置写入特定于硬件的数值。
-
disable与enable的相对应,用于禁用IRQ。而shutdown完全关闭一个中断源。如果不支持该特性,那么这个函数实际上是disable的别名。
-
ack与中断控制器的硬件密切相关。在某些模型中,IRQ请求的到达(以及在处理器的对应中断)必须显式确认,后续的请求才能进行处理。如果芯片组没有这样的要求,该指针可以指向一个空函数,或NULL指针。ack_and_mask确认一个中断,并在接下来屏蔽该中断。
-
调用end标记中断处理在电流层次的结束。如果一个中断在中断处理期间被禁用,那么该函数负责重新启用此类中断。
-
现代的中断控制器不需要内核进行太多的电流控制,控制器几乎可以管理所有事务。在处理中断时需要一个到硬件的回调,由eoi提供,eoi表示end of interrupt,即中断结束。
-
在多处理器系统中,可使用set_affinity指定CPU来处理特定的IRQ。这使得可以将IRQ分配给某些CPU(通常,SMP系统上的IRQ是平均发布到所有处理器的)。该方法在单处理器系统上没用,可以设置为NULL指针。
-
set_type设置IRQ的电流类型。该方法主要使用在ARM、PowerPC和SuperH机器上,其他系统不需要该方法,可以将set_type设置为NULL。
irqaction - 每个中断的动作描述符
struct irqaction {
irq_handler_t handler; // 中断处理程序
void *dev_id; // 指向设备
void __percpu *percpu_dev_id;
struct irqaction *next; // 指向下一个成员,实现共享中断
irq_handler_t thread_fn;
struct task_struct *thread;
struct irqaction *secondary;
unsigned int irq; // 中断号
unsigned int flags; // 中断标志
unsigned long thread_flags;
unsigned long thread_mask;
const char *name;
struct proc_dir_entry *dir;
} ____cacheline_internodealigned_in_smp;
**该结构中最重要的成员是处理程序函数本身,即handler成员,这是一个函数指针,位于结构的起始处。在设备请求一个系统中断,而中断控制器通过引发中断将该请求转发到处理器的时候,内核将调用该处理程序函数。**在考虑如何注册处理程序函数时,我们再仔细考察其参数的语义。但请注意,处理程序的类型为irq_handler_t,与电流处理程序的类型irq_flow_handler_t显然是不同的。
**name和dev_id唯一地标识一个中断处理程序。name是一个短字符串,用于标识设备(例如,“e100”、“ncr53c8xx”,等等),而dev_id是一个指针,指向在所有内核数据结构中唯一标识了该设备的数据结构实例,例如网卡的net_device实例。**如果几个设备共享一个IRQ,那么IRQ编号自身不能标识该设备,此时,在删除处理程序函数时,将需要上述信息。
flags是一个标志变量,通过位图描述了IRQ(和相关的中断)的一些特性,位图中的各个标志位照例可通过预定义的常数访问。<interrupt.h>中定义了下列常数。
- 对共享的IRQ设置IRQF_SHARED,表示有多于一个设备使用该IRQ电路。
- 如果IRQ对内核熵池(entropy pool)有贡献,将设置IRQF_SAMPLE_RANDOM。①
- IRQF_DISABLED表示IRQ的处理程序必须在禁用中断的情况下执行。
- IRQF_TIMER表示时钟中断。
next用于实现共享的IRQ处理程序。几个irqaction实例聚集到一个链表中。链表的所有元素都必须处理同一IRQ编号(处理不同编号的实例,位于irq_desc数组中不同的位置)。在14.1.7节讨论过,在发生一个共享中断时,内核扫描该链表找出中断实际上的来源设备。特别是在单芯片(只有一个中断)上集成了许多不同的设备(网络、USB、FireWire、声卡等)的笔记本电脑中,此类处理程序链表可能包含大约5个元素。
但我们预期的情况是,每个IRQ下只都注册一个设备。
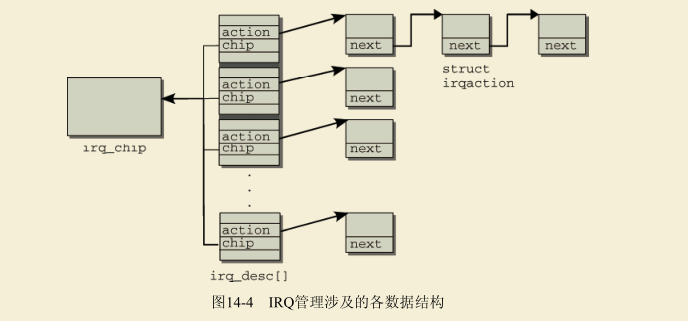
下图给出了所描述各数据结构(irq_desc)的一个概览,说明其彼此交互的方式。因为通常在一个系统上只有一种类型的中断控制器会占据支配地位(当然,并没有什么约束条件阻止多个控制器并存),所有irq_desc的handler成员都指向irq_chip的同一实例。
软中断
软中断使得内核可以延期执行任务。因为它们的运作方式与上文描述的中断类似,但完全是用软件实现的,所以称为软中断(software interrupt)或softIRQ是完全符合逻辑的。
系统调用也是靠软中断机制实现的,首先,用户程序为系统调用设置参数,其中一个编号是系统调用编号,参数设置完成后,程序执行系统调用指令,x86 上的软中断是由 int 产生的,这个指令会导致一个异常,产生一个事件,**这个事件会导致处理器跳转到内核态并跳转到一个新的地址。**并开始处理那里的异常处理程序,此时的异常处理就是系统调用程序。
再仔细审视基于中断方式的系统调用的执行过程,不难发现,前面很多处理过程都是固定的,其实很没必要,如门描述符级别检查、查找中断处理程序入口,等等。为了省去这些多余的检查,Intel 在 Pentium II CPU 中加入了新的 SYSENTER 指令,专门用来执行系统调用。该指令会跳过前面检查步骤,直接将 CPU 切换到特权模式,继而执行系统调用,同时还增加了几个专用寄存器辅助完成参数传递和上下文保存工作。另外,还相应地增加了 SYSEXIT 指令,用来返回执行结果,并切回用户模式。在 Linux 实现了 SYSENTER 方式的系统调用之后,就有人用 Pentium III 的机器对比测试了两种系统调用的效率。测试结果显示,与中断方式相比,SYSENTER 在用户模式下因省掉了级别检查类的操作,花费的时间大幅减少了 45% 左右;在核心模式下,因少了一个寄存器压栈保存动作,所花费的时间也减少了 2% 左右。目前,基于中断方式的系统调用仍然保留着,Linux 启动时会自动检测 CPU 是否支持 SYSENTER 指令,从而根据情况选择相应的系统调用方式。
内核借助于软中断来获知异常情况的发生,而该情况将在稍后由专门的处理程序例程解决。如上所述,内核在do_IRQ末尾处理所有待决软中断,因而可以确保软中断能够定期得到处理。
从一个更抽象的角度来看,可以将软中断描述为一种延迟到稍后时刻执行的内核活动。但尽管硬件和软件中断之间有明显的相似性,它们并不总是可比较的。
软中断机制的核心部分是一个表,包含32个softirq_action类型的数据项。该数据类型结构非常简单,只包含一个成员:
/* 软中断掩码和活动字段移动到 asm/hardirq.h 中的 irq_cpustat_t 以获得更好的缓存使用。 */
struct softirq_action
{
// 一个指向处理程序例程的指针,在软中断发生时由内核执行该处理程序例程
void (*action)(struct softirq_action *);
};
该数据结构的定义是体系结构无关的,而软中断机制的整个实现也是如此。除了处理的激活之外,没有利用处理器相关的功能或特性,这与普通的中断是完全相反的。
软中断必须先注册,然后内核才能执行软中断。open_softirq函数即用于该目的。它在softirq_vec表中指定的位置写入新的软中断:
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
软中断编号
各个软中断都有一个唯一的编号,这表明软中断是相对稀缺的资源,使用其必须谨慎,不能由各种设备驱动程序和内核组件随意使用。默认情况下,系统上只能使用32个软中断。但这个限制不会有太大的局限性,因为软中断充当实现其他延期执行机制的基础,而且也很适合设备驱动程序的需要。
下文将讨论相应的技术(tasklet、工作队列和内核定时器)。
只有中枢的内核代码才使用软中断。软中断只用于少数场合,这些都是相对重要的情况:
enum
{
HI_SOFTIRQ=0, // 高优先级的小任务
TIMER_SOFTIRQ, // 定时器软中断
NET_TX_SOFTIRQ, // 网络栈发送报文的软中断
NET_RX_SOFTIRQ, // 网络栈接收报文的软中断
BLOCK_SOFTIRQ, // 块设备软中断
IRQ_POLL_SOFTIRQ, // 支持I/O轮询的块设备软中断
TASKLET_SOFTIRQ, // 低优先级的小任务
SCHED_SOFTIRQ, // 调度软中断,用于在处理器之间负载均衡
HRTIMER_SOFTIRQ, /* 没有使用,但是保留,因为有些工具依赖这个编号 */
RCU_SOFTIRQ, /* RCU软中断应该总是最后一个软中断 */
NR_SOFTIRQS
};
其中两个用来实现tasklet(HI_SOFTIRQ、TASKLET_SOFTIRQ),两个用于网络的发送和接收操作(NET_TX_SOFTIRQ和NET_RX_SOFTIRQ,这是软中断机制的来源和其最重要的应用),一个用于块层,实现异步请求完成(BLOCK_SOFTIRQ),一个用于调度器(SCHED_SOFTIRQ),以实现SMP系统上周期性的负载均衡。在启用高分辨率定时器时,还需要一个软中断(HRTIMER_SOFTIRQ)。
软中断的编号形成了一个优先顺序,这并不影响各个处理程序例程执行的频率或它们相当于其他系统活动的优先级,但定义了多个软中断同时活动或待决时处理例程执行的次序。
**raise_softirq(int nr)用于引发一个软中断(类似普通中断)。**软中断的编号通过参数指定。
该函数设置各CPU变量irq_stat[smp_processor_id].__softirq_pending中的对应比特位。该函数将相应的软中断标记为执行,但这个执行是延期执行。通过使用特定于处理器的位图,内核确保几个软中断(甚至是相同的)可以同时在不同的CPU上执行。
如果不在中断上下文调用raise_softirq,则调用wakeup_softirqd来唤醒软中断守护进程,这是开启软中断处理的两个可选方法之一。14.2.2节将详细讲述该守护进程。
开启软中断处理
有几种方法可开启软中断处理,但这些都归结为调用do_softirq函数。为此,我们详细介绍该函数。图14-11给出的代码流程图,揭示了其中基本的步骤。
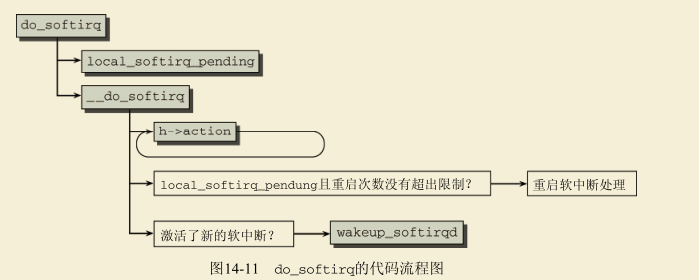
该函数首先确认当前不处于中断上下文中(当然,即不涉及硬件中断)。如果处于中断上下文,则立即结束。因为软中断用于执行ISR中非时间关键部分,所以其代码本身一定不能在中断处理程序内调用。
通过local_softirq_pending,确定当前CPU软中断位图中所有置位的比特位。如果有软中断等待处理,则调用__do_softirq。
该函数将原来的位图重置为0。换句话说,清除所有软中断。这两个操作都是在(当前处理器上)禁用中断的情况下执行,以防其他进程对位图的修改造成干扰。而后续代码是在允许中断的情况下执行。这使得在软中断处理程序执行期间的任何时刻,都可以修改原来的位图。
softirq_vec中的action函数在一个while循环中针对各个待决的软中断被调用。
在处理了所有标记出的软中断之后,内核检查在此期间是否有新的软中断标记到位图中。要求在前一轮循环中至少有一个没有处理的软中断,而重启的次数没有超过MAX_SOFTIRQ_RESTART(通常设置为10)。如果是这样,则再次按序处理标记的软中断。这操作会一直重复下去,直至在执行所有处理程序之后没有新的未处理软中断为止。
如果在MAX_SOFTIRQ_RESTART次重启处理过程之后,仍然有未处理的软中断,那么应该如何?内核将调用wakeup_softirqd唤醒软中断守护进程。
软中断守护进程
(1)在中断处理程序的后半部分执行软中断,对执行时间有限制:不能超过2毫秒,并且最多执行10次
(2)每个处理器有一个软中断线程,调度策略是SCHED_NORMAL,优先级是120。
软中断守护进程的任务是,为其余内核代码异步执行软中断。为此,系统中的每个处理器都分配了自身的守护进程,名为ksoftirqd。
内核中有两处调用wakeup_softirqd唤醒了该守护进程。
- 在do_softirq中,如前所述。
- 在raise_softirq_irqoff末尾。该函数由raise_softirq在内部调用,如果内核当前停用了中断,也可以直接使用。
**唤醒函数本身只需要几行代码。首先,借助于一些宏,从一个各CPU变量读取指向当前CPU软中断守护进程的task_struct的指针。如果该进程当前的状态不是TASK_RUNNING,则通过wake_up_ process将其放置到就绪进程的列表末尾(参见第2章)。**尽管这并不会立即开始处理所有待决软中断,
但只要调度器没有更好的选择,就会选择该守护进程来执行。
在系统启动时用initcall机制调用init不久,即创建了系统中的软中断守护进程。 在初始化之后,各个守护进程都执行以下无限循环:
static int ksoftirqd(void * __bind_cpu)
...
while (!kthread_should_stop()) {
if (!local_softirq_pending()) {
schedule();
}
__set_current_state(TASK_RUNNING);
while (local_softirq_pending()) {
do_softirq();
cond_resched();
}
set_current_state(TASK_INTERRUPTIBLE);
}
...
}
每次被唤醒时,守护进程首先检查是否有标记出的待决软中断,否则明确地调用调度器,将控制转交到其他进程。
- 如果有标记出的软中断,那么守护进程接下来将处理软中断。进程在一个while循环中重复调用两个函数do_softirq和cond_resched,直至没有标记出的软中断为止。
- cond_resched确保在对当前进程设置了TIF_NEED_RESCHED标志的情况下调用调度器(参见第2章)。这是可能的,因为所有这些函数执行时都启用了硬件中断。
下半部
下半部有3种:软中断(softirq)、小任务(tasklet)和工作队列(workqueue)。3种下半部的区别如下。
小任务(tasklet)是基于软中断执行的
3种下半部的区别如下:
(1)软中断和小任务不允许睡眠;工作队列是使用内核线程实现的,处理函数可以睡眠。
(2)软中断的种类(小任务也是一种)是编译时静态定义的,在运行时不能添加或删除;小任务可以在运行时添加或删除。
(3)同一种软中断的处理函数可以在多个处理器上同时执行,处理函数必须是可以重入的,需要使用锁保护临界区;一个小任务同一时刻只能在一个处理器上执行,不要求处理函数是可以重入的。
tasklet
软中断是将操作推迟到未来时刻执行的最有效的方法。但该延期机制处理起来非常复杂。因为多个处理器可以同时且独立地处理软中断,同一个软中断的处理程序例程可以在几个CPU上同时运行。
对软中断的效率来说,这是一个关键,多处理器系统上的网络实现显然受惠于此。但处理程序例程的设计必须是完全可重入且线程安全的。另外,临界区必须用自旋锁保护,而这需要大量审慎的考虑。
tasklet和工作队列是延期执行工作的机制,其实现基于软中断,但它们更易于使用,因而更适合于设备驱动程序(以及其他一般性的内核代码)。
在深入技术细节之前,请注意所使用的术语:由于历史原因,术语下半部(bottom half)通常指代两个不同的东西;**首先,它是指ISR代码的下半部,负责执行非时间关键操作。**遗憾的是,早期内核版本中使用的操作延期执行机制,也称为下半部,因而使用的术语经常是含糊不清的。在此期间,下半部不再作为内核机制存在。它们在内核版本2.5开发期间被废弃,被tasklet代替,这是一个好得多的替代品。
tasklet是“小进程”,执行一些迷你任务,对这些任务使用全功能进程可能比较浪费。
创建tasklet
小任务根据优先级分为两种:低优先级小任务和高优先级小任务。
struct tasklet_struct
{
struct tasklet_struct *next; // 添加到单向链表
unsigned long state; // 小任务的状态
atomic_t count; // 成员count是计数,0表示允许小任务被执行,非零值表示禁止小任务被执行。
void (*func)(unsigned long); // 成员func是处理函数,成员data是传给处理函数的参数。
unsigned long data;
};
- 成员state是小任务的状态,取值如下。
(1)0:小任务没有被调度。
(2)(1 << TASKLET_STATE_SCHED):小任务被调度,即将被执行。
(3)(1 << TASKLET_STATE_RUN):只在多处理器系统中使用,表示小任务正在执行。
每个处理器有两条单向链表:低优先级小任务链表和高优先级小任务链表。
kernel/softirq.c
struct tasklet_head {
struct tasklet_struct *head;
struct tasklet_struct **tail;
};
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
注册tasklet
tasklet_schedule将一个tasklet注册到系统中:
static inline void tasklet_schedule(struct tasklet_struct *t);
如果设置了TASKLET_STATE_SCHED标志位,则结束注册过程,因为该tasklet此前已经注册了。否则,将该tasklet置于一个链表的起始,其表头是特定于CPU的变量tasklet_vec。该链表包含了所有注册的tasklet,使用next成员作为链表元素。
在注册了一个tasklet之后,tasklet链表即标记为即将进行处理
执行tasklet
初始化的时候,把软中断TASKLET_SOFTIRQ的处理函数注册为函数tasklet_action,把软中断HI_SOFTIRQ的处理函数注册为函数
tasklet_hi_action。
tasklet的生命周期中最重要的部分就是其执行。因为tasklet基于软中断实现,它们总是在处理软中断时执行。
tasklet关联到TASKLET_SOFTIRQ软中断。因而,调用raise_softirq(TASKLET_SOFTIRQ),即可在下一个适当的时机执行当前处理器的tasklet。内核使用tasklet_action作为该软中断的action函数。
该函数首先确定特定于CPU的链表,其中保存了标记为将要执行的各个tasklet。它接下来将表头重定向到函数局部的一个数据项,相当于从外部公开的链表删除了所有表项。接下来,函数在以下循环中逐一处理各个tasklet。
在while循环中执行tasklet,类似于处理软中断使用的机制。 因为一个tasklet只能在一个处理器上执行一次,但其他的tasklet可以并行运行,所以需要特定于
tasklet 的 锁 。 state状态用作锁变量 。 在执行一 个 tasklet 的处理程序函数之前 ,内核使用tasklet_trylock检查tasklet的状态是否为TASKLET_STATE_RUN。换句话说,它是否已经在系统的另一个处理器上运行:
static inline int tasklet_trylock(struct tasklet_struct *t)
{
// 如果对应比特位尚未设置,则设置该比特位。
return !test_and_set_bit(TASKLET_STATE_RUN, &(t)->state);
}
以函数tasklet_action()为例说明,其代码如下:
static __latent_entropy void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
// 关闭本地CPU的中断
local_irq_disable();
// 把当前处理器的低优先级小任务链表中的所有小任务移到临时链表list中。
list = __this_cpu_read(tasklet_vec.head);
__this_cpu_write(tasklet_vec.head, NULL);
__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head));
// 开启本地CPU的中断
local_irq_enable();
// 循环执行tasklet链表上每个tasklet的处理函数
while (list) {
struct tasklet_struct *t = list;
list = list->next;
// 尝试锁住小任务,确保一个小任务同一时刻只在一个处理器上执行。
if (tasklet_trylock(t)) {
// 如果小任务的计数为0,表示允许小任务被执行
if (!atomic_read(&t->count)) {
// 清除小任务的调度标志位,其他处理器可以调度这个小任务,但是不能执行这个小任务
if (!test_and_clear_bit(TASKLET_STATE_SCHED,
&t->state))
BUG();
t->func(t->data); // 执行小任务的处理函数
tasklet_unlock(t); // 释放小任务的锁,其他处理器就可以执行这个小任务了
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
// 如果尝试锁住小任务失败(表示小任务正在其他处理器上执行),或者禁止小任务被执行,那么把小任务重新添加到当前处理器的低优先级小任务链表的尾部,然后触发软中断TASKLET_SOFTIRQ。
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
初了普通的tasklet之外,内核还使用了另一种tasklet,它具有“较高”的优先级。除以下修改之外,其实现与普通的tasklet完全相同。
- 使用HI_SOFTIRQ作为软中断,而不是TASKLET_SOFTIRQ,相关的action函数是tasklet_hi_action。
- 注册的tasklet在CPU相关的变量tasklet_hi_vec中排队。这是使用tasklet_hi_schedule完成的。
在这里,“较高优先级”是指该软中断的处理程序HI_SOFTIRQ在所有其他处理程序之前执行,尤其是在构成了软中断活动主体的网络处理程序之前执行。
当前,大部分声卡驱动程序都利用了这一选项,因为操作延迟时间太长可能损害音频输出的音质。
而用于高速传输的网卡也可以得益于该机制。
等待队列和完成量
等待队列(wait queue)用于使进程等待某一特定事件发生,而无须频繁轮询。进程在等待期间睡眠,在事件发生时由内核自动唤醒。
完成量(completion)机制基于等待队列,内核利用该机制等待某一操作结束。这两种机制使用得都比较频繁,主要用于设备驱动程序,如第6章所示。
等待队列
数据结构
每个等待队列都有一个队列头,由以下数据结构表示:
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
因为等待队列也可以在中断时修改,在操作队列之前必须获得一个自旋锁lock(参见第5章)。
task_list是一个双链表,用于实现双链表最擅长表示的结构,即队列。
队列中的成员是以下数据结构的实例:
typedef struct __wait_queue wait_queue_t;
struct __wait_queue {
unsigned int flags;
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
- flags的值或者为WQ_FLAG_EXCLUSIVE,或者为0,当前没有定义其他标志。WQ_FLAG_EXCLUSIVE表示等待进程想要被独占地唤醒(稍后将详细讲述)。
- private是一个指针,指向等待进程的task_struct实例。该变量本质上可以指向任意的私有数据,但内核中只有很少情况下才这么用,因此这里不会详细讲述这种情形。
- 调用func,唤醒等待进程。
- task_list用作一个链表元素,用于将wait_queue_t实例放置到等待队列中。
等待队列的使用分为如下两部分。
(1) 为使当前进程在一个等待队列中睡眠,需要调用wait_event函数(或某个等价函数,在下文讨论)。进程进入睡眠,将控制权释放给调度器。
内核通常会在向块设备发出传输数据的请求后,调用该函数。因为传输不会立即发生,而在此期间又没有其他事情可做,所以进程可以睡眠,将CPU时间让给系统中的其他进程。
(2) 在内核中另一处,就我们的例子而言,是来自块设备的数据到达后,必须调用wake_up函数(或某个等价函数,将在下文讨论)来唤醒等待队列中的睡眠进程。
在使用wait_event使进程睡眠之后,必须确保在内核中另一处有一个对应的wake_up调用。
使进程睡眠
add_wait_queue函数用于将一个进程增加到等待队列,该函数在获得必要的自旋锁后,将工作委托给__add_wait_queue:
static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new)
{
list_add(&new->task_list, &head->task_list);
}
在将新进程统计到等待队列时,除了使用标准的list_add链表函数,没有其他工作需要做。
内核还提供了add_wait_queue_exclusive函数。它的工作方式与add_wait_queue相同,但将进程插入在队列尾部,并将其标志设置为WQ_EXCLUSIVE(该标志的语义在下文讨论)。
使进程在等待队列上睡眠的另一种方法是prepare_to_wait。除了add_wait_queue需要的参数之外,还需要进程的状态:
/*
* 注意:我们在等待队列添加之后使用“set_current_state()”,因为我们需要在 SMP 上设置一个内存屏障,因此任何测试等待队列是否处于活动状态的唤醒函数都可以保证看到等待队列添加_or_ 此线程中的后续测试将看到已发生唤醒。
*
* spin_unlock() 本身是半渗透性的,只保护一种方式(它只保护关键区域内的东西并阻止它们流血 - 它仍然允许后续负载移动到关键区域)。
*/
void fastcall
prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list))
__add_wait_queue(q, wait);
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
像在上文讨论的那样,调用__add_wait_queue之后,内核将进程当前的状态设置为state (传递到prepare_to_wait的状态)。
prepare_to_wait_exclusive是一个变体,它会设置WQ_FLAG_EXCLUSIVE标志并将等待队列的成员添加到队列尾部。
add_wait_queue通常不直接使用。更常用的是wait_event。这是一个宏,需要如下两个参数。
(1) 在其上进行等待的等待队列。
(2) 一个条件,以所等待事件有关的一个C表达式形式给出。 这个宏只确认条件尚未满足。如果条件已经满足,可以立即停止处理,因为没什么可等待的了。
#define wait_event(wq, condition) \
do { \
might_sleep(); \
if (condition) \
break; \
__wait_event(wq, condition); \
} while (0)
主要的工作委托给__wait_event:
#define ___wait_event(wq, condition, state, exclusive, ret, cmd) \
({ \
__label__ __out; \
wait_queue_t __wait; \
long __ret = ret; /* explicit shadow */ \
\
init_wait_entry(&__wait, exclusive ? WQ_FLAG_EXCLUSIVE : 0); \
for (;;) { \
long __int = prepare_to_wait_event(&wq, &__wait, state);\
\
if (condition) \
break; \
\
if (___wait_is_interruptible(state) && __int) { \
__ret = __int; \
goto __out; \
} \
\
cmd; \
} \
finish_wait(&wq, &__wait); \
__out: __ret; \
})
#define __wait_event(wq, condition) \
(void)___wait_event(wq, condition, TASK_UNINTERRUPTIBLE, 0, 0, \
schedule())
使用prepare_to_wait使进程在等待队列上睡眠。每次进程被唤醒时,内核都会检查指定的条件是否满足,如果条件满足则
退出无限循环。否则,将控制转交给调度器,进程再次睡眠。
在条件满足时,finish_wait将进程状态设置回TASK_RUNNING,并从等待队列的链表移除对应的项。
除了wait_event之外,内核还定义了其他几个函数,可以将当前进程置于等待队列中。其实现实际上等同于sleep_on:
#define wait_event_interruptible(wq, condition)
#define wait_event_timeout(wq, condition, timeout) { ... }
#define wait_event_interruptible_timeout(wq, condition, timeout)
- wait_event_interruptible使用的进程状态为TASK_INTERRUPTIBLE。因而睡眠进程可以通过接收信号而唤醒。
- wait_event_timeout等待满足指定的条件,但如果等待时间超过了指定的超时限制(按jiffies指定)则停止。这防止了进程永远睡眠。
- wait_event_interruptible_timeout使进程睡眠,但可以通过接收信号唤醒。它也注册了一个超时限制。从内核采用的命名方式来看,一般不会有出人意料之处!
唤醒进程
内核定义了一系列宏,可用于唤醒等待队列中的进程。它们基于同一个函数:
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
#define wake_up_nr(x, nr) __wake_up(x, TASK_NORMAL, nr, NULL)
#define wake_up_all(x) __wake_up(x, TASK_NORMAL, 0, NULL)
#define wake_up_locked(x) __wake_up_locked((x), TASK_NORMAL, 1)
#define wake_up_all_locked(x) __wake_up_locked((x), TASK_NORMAL, 0)
#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
#define wake_up_interruptible_nr(x, nr) __wake_up(x, TASK_INTERRUPTIBLE, nr, NULL)
#define wake_up_interruptible_all(x) __wake_up(x, TASK_INTERRUPTIBLE, 0, NULL)
#define wake_up_interruptible_sync(x) __wake_up_sync((x), TASK_INTERRUPTIBLE, 1)
在获得了用于保护等待队列首部的锁之后,__wake_up将工作委托给_wake_up_common。
// q用于选定等待队列,而mode指定进程的状态,用于控制唤醒进程的条件。
// nr_exclusive表示将要唤醒的设置了WQ_FLAG_EXCLUSIVE标志的进程的数目。
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
// 内核接下来遍历睡眠进程,并调用其唤醒函数func
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
这里会反复扫描链表,直至没有更多进程需要唤醒,或已经唤醒的独占进程的数目达到了nr_exclusive。该限制用于避免所谓的惊群(thundering herd)问题。如果几个进程在等待独占访问某一资源,那么同时唤醒所有等待进程是没有意义的,因为除了其中一个之外,其他进程都会再次睡眠。 nr_exclusive推广了这一限制。
最常使用的wake_up函数将nr_exclusive设置为1,确保只唤醒一个独占访问的进程。 回想上文,WQ_FLAG_EXCLUSIVE进程被添加在等待队列的尾部。这种实现确保在混合访问类型的队列中,首先唤醒所有的普通进程,然后才考虑到对独占进程的限制。
如果进程在等待数据传输的结束,那么唤醒等待队列中所有的进程是有用的。这是因为几个进程的数据可以同时读取,而互不干扰。
完成量
完成量与信号量有些相似,但是基于等待队列实现的。我们感兴趣的是完成量的接口。
场景中有两个参与者:一个在等待某操作完成,而另一个在操作完成时发出声明。
实际上,这已经被简化过了:可以有任意数目的进程等待操作完成。为表示进程等待的即将完成的“某操作”,内核使用了下述数据结构
completion.h
/*
* struct completion - structure used to maintain(维护) state for a "completion"
*
* This is the opaque(不透明) structure used to maintain the state for a "completion".
* Completions currently use a FIFO to queue threads that have to wait for
* the "completion" event.
*
* See also: complete(), wait_for_completion() (and friends _timeout,
* _interruptible, _interruptible_timeout, and _killable), init_completion(),
* reinit_completion(), and macros DECLARE_COMPLETION(),
* DECLARE_COMPLETION_ONSTACK().
*/
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
可能在某些进程开始等待之前,事件就已经完成,done用来处理这种情形。这将在下文讨论。 wait是一个标准的等待队列,等待进程在队列上睡眠。
init_completion初始化一个动态分配的completion实例,而DECLARE_COMPLETION宏用来建立该数据结构的静态实例。
进程可以用wait_for_completion添加到等待队列,进程在其中等待(以独占睡眠状态),直至请求被内核的某些部分处理。这函数需要一个completion实例作为参数:
void wait_for_completion(struct completion *);
int wait_for_completion_interruptible(struct completion *x);
unsigned long wait_for_completion_timeout(struct completion *x,
unsigned long timeout);
unsigned long wait_for_completion_interruptible_timeout(
struct completion *x, unsigned long timeout);
在请求由内核的另一部分处理之后,必须调用complete或complete_all来唤醒等待的进程。因为每次调用只能从完成量的等待队列移除一个进程,对n个等待进程来说,必须调用该函数n次。 另一方面,complete_all将唤醒所有等待该完成的进程。 complete_and_exit是一个小的包装器,首先调用complete,接下来调用do_exit结束内核线程
struct completion中done的语义是什么呢?每次调用complete时,该计数器都加1,仅当done等于0时,wait_for系列函数才会使调用进程进入睡眠。 实际上,这意味着进程无须等待已经完成的事件。complete_all的工作方式类似,但它会将计数器设置为最大可能值(UINT_MAX/2,这是无符号整数最大值的一半,因为计数器也可能取负值),这样,在事件完成后调用wait_系列函数的进程将永远不会睡眠。
工作队列
工作队列是将操作延期执行的另一种手段。因为它们是通过守护进程在用户上下文执行,函数可以睡眠任意长的时间,这与内核是无关的。在内核版本2.5开发期间,设计了工作队列,用以替换此前使用的keventd机制。
工作队列(work queue)是使用内核线程异步执行函数的通用机制。
- 工作队列是中断处理程序的一种下半部机制,中断处理程序可以把耗时比较长并且可能睡眠的函数交给工作队列执行。
工作队列不完全是中断处理程序的下半部。内核的很多模块需要异步执行函数,这些模块可以创建一个内核线程来异步执行函数。但是,如果每个模块
都创建自己的内核线程,会造成内核线程的数量过多,内存消耗比较大,影响系统性能。所以,最好的方法是提供一种通用机制,让这些模块把需要异
步执行的函数交给工作队列执行,共享内核线程,节省资源。
技术原理
- work:工作,也称为工作项。
- work_queue:工作队列,就是工作的集合,work queue和work是一对多的关系。
- worker:工人,一个工人对应一个内核线程,我们把工人对应的内核线程称为工人线程。
- worker_pool:工人池,就是工人的集合,工人池和工人是一对多的关系。
- pool_workqueue:中介,负责建立工作队列和工人池之间的关系。工作队列和pool_workqueue是一对多的关系,pool_workqueue和工人
池是一对一的关系。
工作队列分为两种。
1)绑定处理器的工作队列:默认创建绑定处理器的工作队列,每个工人线程绑定到一个处理器。
2)不绑定处理器的工作队列:创建工作队列的时候需要指定标志位WQ_UNBOUND,工人线程不绑定到某个处理器,可以在处理器之间迁移。
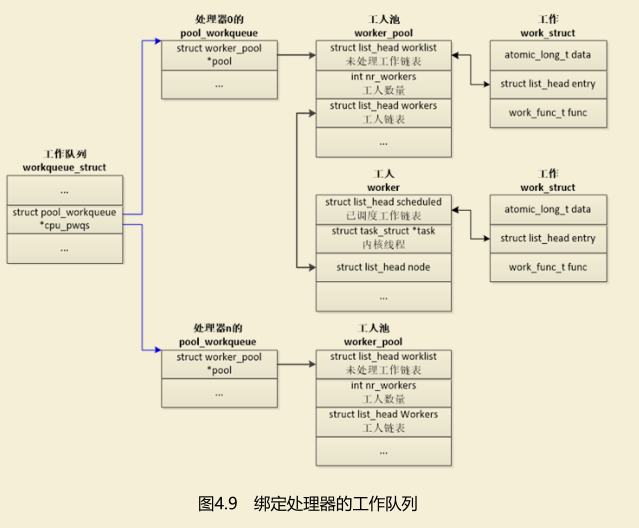
**绑定处理器的工作队列**的数据结构如图4.9所示,工作队列在每个处理器上有一个pool_workqueue实例,一个pool_workqueue实例对应一个工人
池,一个工人池有一条工人链表,每个工人对应一个内核线程。
向工作队列中添加工作项的时候,选择当前处理器的pool_workqueue实例、工人池和工人线程。
==不绑定处理器的工作队列==的数据结构如图4.10所示,工作队列在每个内存节点上有一个pool_workqueue实例,一个pool_workqueue实例对应一个工
人池,一个工人池有一条工人链表,每个工人对应一个内核线程。
向工作队列中添加工作项的时候,选择当前处理器所属的内存节点的pool_workqueue实例、工人池和工人线程。
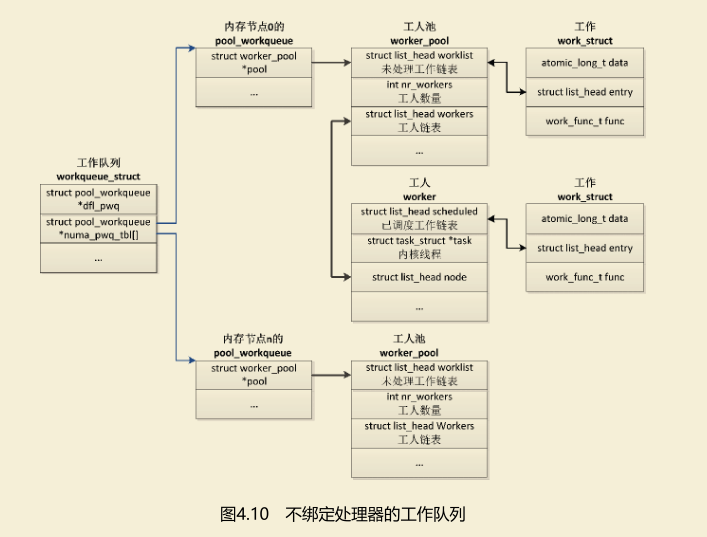
不绑定处理器的工作队列还有一个默认的pool_workqueue实例(workqueue_struct.dfl_pwq),当某个处理器下线的时候,使用默认的pool_workqueue实例。
工作队列
绑定处理器的工作队列的数据结构如图4.9所示,工作队列在每个处理器上有一个pool_workqueue实例,一个pool_workqueue实例对应一个工人
池,一个工人池有一条工人链表,每个工人对应一个内核线程。向工作队列中添加工作项的时候,选择当前处理器的pool_workqueue实例、工人池和
工人线程。
__create_workqueue_key 创建守护线程
每个工作队列都有一个数组,数组项的数目与系统中处理器的数目相同。每个数组项都列出了将延期执行的任务。
对每个工作队列来说,内核都会创建一个新的内核守护进程,延期任务使用上文描述的等待队列机制,在该守护进程的上下文中执行。
新的工作队列通过调用create_workqueue或create_workqueue_singlethread函数来创建。**前一个函数在所有CPU上都创建一个工作线程,而后者只在系统的第一个CPU上创建一个线程。**两个函数在内部都使用了__create_workqueue_key:
kernel/workqueue.c
struct workqueue_struct *__create_workqueue(const char *name, int singlethread)
name参数表示创建的守护进程在进程列表中显示的名称。如果singlethread设置为0,则在系统的每个CPU上都创建一个线程,否则只在第一个CPU上创建线程。
work_struct
所有推送到工作队列上的任务,都必须打包为work_struct结构的实例,从工作队列用户的角度来看,该结构的下述成员是比较重要的:
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
- entry照例用作链表元素,用于将几个work_struct实例群集到一个链表中。
- func是一个指针,指向将延期执行的函数。
- **该函数有一个参数,是一个指针,指向用于提交该工作的work_struct实例。**这使得工作函数可以获得work_struct的data成员,该成员可以指向与work_struct相关的任意数据。
*为什么内核使用atomic_long_t作为指向任意数据的指针的数据类型,而不是通常的void ?实际上,此前的内核版本定义的work_struct如下
struct work_struct {
...
void (*func)(void *);
void *data;
...
};
正如所料,data是用指针表示的。但内核使用了一点小技巧,显然有点近乎于“肮脏”,以便将更多信息放入该结构,而又不付出更多代价。因为指针在所有支持的体系结构上都对齐到4字节边界,而前两个比特位保证为0。因而可以“滥用”这两个比特位,将其用作标志位。
剩余的比特位照旧保存指针的信息。以下的宏用于屏蔽标志位:
WORK_STRUCT_FLAG_MASK = (1UL << WORK_STRUCT_FLAG_BITS) - 1,
WORK_STRUCT_WQ_DATA_MASK = ~WORK_STRUCT_FLAG_MASK,
当前只定义了一个标志:WORK_STRUCT_PENDING用来查找当前是否有待决(该标志位置位)的可延迟工作项。辅助宏work_pending(work)用来检查该标志位。请注意,将data设置为原子数据类型,确保对该比特位的修改不会带来并发问题。
为简化声明和填充该结构的静态实例所需的工作,内核提供了INIT_WORK(work, func)宏,它向一个现存的work_struct实例提供一个延期执行函数。
queue_work 向工作队列加入work_struct
如果需要data成员,则需要稍后设置。 有两种方法可以向一个工作队列添加work_struct实例,分别是queue_work和queue_work_ delayed。第一个函数的原型如下:
int fastcall queue_work(struct workqueue_struct *wq, struct work_struct *work)
它将work添加到工作队列wq,work本身所指定的工作,其执行时间待定(在调度器选择该守护进程时执行)。
为确保排队的工作项将在提交后指定的一段时间内执行,需要扩展work_struct,添加一个定时器。显然的解决方案如下:
struct delayed_work {
struct work_struct work;
struct timer_list timer;
};
queue_delayed_work
queue_delayed_work用于向工作队列提交delayed_work实例。它确保在延期工作执行之前,至少会经过由delay指定的一段时间(以jiffies为单位)。
int fastcall queue_delayed_work(struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay)
该函数首先创建一个内核定时器,它将在delayed jiffies之内超时。相关的处理程序接下来使用queue_work,按通常的方式将工作添加到工作队列。
内核创建了一个标准的工作队列,称为events。内核的各个部分中,凡是没有必要创建独立的工作队列者,均可使用该队列。
内核提供了以下两个函数,可用于将新的工作添加该标准队列。
int schedule_work(struct work_struct *work)
int schedule_delayed_work(struct delay_work *dwork, unsigned long delay)















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









