







主要参考了《深入Linux内核架构》和《精通Linux内核网络》相关章节
文章目录
传输层
两个基于IP的主要传输协议分别是UDP和TCP,前者用于发送数据报,后者可建立安全的、面向连接的服务。尽管UDP是一个简单的、易于实现的协议,但TCP有几个隐藏良好(不为人所知)的陷阱和障碍,这使得其实现比较复杂。
套接字(概述)
用户空间
每个操作系统都必须提供网络子系统入口及API,Linux内核网络子系统提供的标准POSIX套接字API向用户提供接口。在Linux中传输层之上的一切都属于用户空间。Linux也遵循Unix范式(一切皆为文件),因此套接字也与文件相关联,使用统一的套接字API会令应用程序移植更容易,如下为套接字类型:
- SOCK_STREAM(流套接字):提供可靠的字节流通信信道。TCP套接字就属于流套接字。
- SOCK_DGRAM(数据报套接字):支持消息交换。数据报套接字提供的通信信道不可靠,因为数据包可能被丢弃、不按顺序到达或重复。UDP套接字属于数据报套接字。
- SOCK_RAW(原始套接字):直接访问IP层,支持使用协议无关的传输层格式收发数据
流。 - SOCK_RDM(可靠传输的消息):用于透明进程间通信(TIPC).
- SOCK_SEQPACKET(顺序数据包流):这种套接字类似于SOCK_STREAM,也是面向连接的。
- SOCK_DCCP套接字:数据报拥塞控制协议(DCCP)是一种传输层协议,提供不可靠数据报拥塞控制流。
net\socket.c
套接字相关的系统调用接口(提供用户使用)
/*
* System call vectors.
*
* Argument checking cleaned up. Saved 20% in size.
* This function doesn't need to set the kernel lock because
* it is set by the callees.
*/
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) {
...
}
socket():用于创建一个套接字sys_socket();
bind():将套接字与本地端口和IP地址关联sys_bind();
send():发送消息/recv():接收消息/ listen():能够让套接字接收来自其他套接字的连接请求;
accept():接受套接字连接请求,仅适用于基于连接的套接字类型SOCK_STREAM/SOCK_SEQPACKET;
connect():建立到对等套接字的连接。仅适用于基于连接的套接字类型(SOCK_STREAM/SOCK SEQPACKET)以及无连接的套接字类型(SOCK_DGRAM)。
内核空间
在内核中,有两个表示套接字的结构。
- 一个是结构socket。它向用户空间提供了一个接口,是由方法sys_socket()创建的。
- 另一个是结构sock,它向网络层(L4)提供了一个接口。结构sock位于L4之上,是一个与协议无关的结构。
struct socket
socket具体内核源码主要成员如下:
include\linux\net.h
/**
* struct socket - general BSD socket
* @state: socket state (%SS_CONNECTED, etc)
* @type: socket type (%SOCK_STREAM, etc)
* @flags: socket flags (%SOCK_NOSPACE, etc)
* @ops: protocol specific socket operations
* @file: File back pointer for gc
* @sk: internal networking protocol agnostic socket representation
* @wq: wait queue for several uses
*/
struct socket {
socket_state state;
kmemcheck_bitfield_begin(type);
short type;
kmemcheck_bitfield_end(type);
unsigned long flags;
struct socket_wq __rcu *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};
-
state:套接字可处于多种状态之一,如SS_UNCONNECTED、ss_CONNECTED等。
- 刚创建时,INET套接字的状态为SS_UNCONNECTED,请参见方法inet_create()。
- 流套接字成功连接到另一台主机后,其状态为SS_CONNECTED.
请参见include/uapi/linux/net.h中的枚举socket_state。
typedef enum { SS_FREE = 0, /* not allocated */ SS_UNCONNECTED, /* unconnected to any socket */ SS_CONNECTING, /* in process of connecting */ SS_CONNECTED, /* connected to socket */ SS_DISCONNECTING /* in process of disconnecting */ } socket_state; -
type:套接字的类型,如SOCK_STREAM或SOCK_RAW,请参见include/linux/net.h中的枚举sock_type。
-
flags:套接字标志。套接字标志是在include/linux/net.h中定义的。
- 例如,在TUN设备中分配套接字时,如果套接字不是由系统调用socket()来分配的,将设置SOCK_EXTERNALLY_ALLOCATED标志,请参见drivers/net/tun.c中的方法tun_chr_open()。
-
file:与套接字相关联的文件。
-
sk:与套接字相关联的sock对象。sock对象向网络层(L3)提供了接口。创建套接字时,将同时创建与之相关联的sk对象。
- 例如,在IPv4中,创建套接字时将调用方法inet_create(),它会分配一个sock对象(sk),并将其关联到指定的套接字。
-
ops:这个对象(一个proto_ops对象实例)包含套接字的大部分回调函数,如connect()、listen(). sendmsg()、 recvmsg()等。
这些回调函数就是向用户空间提供的接口。
- 回调函数sendmsg()实现了多个库级例程,如write()、send()、 sendto()和sendmsg()。
- 同样,回调函数recvmsg()也实现了多个库级例程,如read()、recv()、recvfrom()和recvmsg()。
- 每种协议都根据其需求定义了一个proto_ops对象,因此TCP的proto_ops对象包含listen回调函数inet_listen()和accept回调函数inet_accept()。
- 另一方面,UDP协议不使用客户-服务器模型,它将listen回调函数设置为方法sock_no_listen(),并将accept回调函数设置为方法sock_no_accept()。这两个方法所做的唯一工作是返回错误-EOPNOTSUPP。
结构proto_ops是在include/linux/net.h中定义的。
struct sock
结构sock是套接字的网络层表示,它的实现代码篇幅较长,下面列出的只是一些重要的字段。
include\net\sock.h
struct sock {
struct sk_buff_head sk_receive_queue; // 一个存储入站的数据包队列
int sk_rcvbuf; // 接收缓冲区大小
unsigned long sk_flags; // 各种标志,如SOCK_DEAD或SOCK_DBG
int sk_sndbuf; // 发送缓冲区大小
struct sk_buff_head sk_write_queue; // 存储出站数据包队列
. . .
unsigned int sk_shutdown : 2,
sk_no_check : 2, // 禁用校验和标志
sk_protocol : 8, // 协议标识符,为socket系统调用的第3个参数
sk_type : 16; // 套接字类型,如SOCK_STREAM
. . .
void (*sk_data_ready)(struct sock *sk, int bytes); // 通知套接字有新数据到达
void (*sk_write_space)(struct sock *sk); // 用于指出可用来处理数据传输的内存
};
系统调用socket
套接字是通过在用户空间中调用系统调用socket()来创建的。
sockfd = socket(int socket_family,int socket_type,int protocol);
下面描述系统调用socket()的参数。
- socket_family:可以是表示IPv4的AF_INET、表示IPv6的AF_INET6、表示UNIX域套接字的AF_UNIX等(UNIX域套接字是一种进程间通信(IPC)方式,能够让运行在同一台主机上的进程进行通信)。
- socket_type:可以是表示流套接字的SOCK_STREAM、表示数据报套接字的SOCK_DGRAM、表示原始套接字的SOCK_RAW等。
- protocol:可以是下面的任何值。
- 表示TCP套接字的0或IPPROTO_TCP。
- 表示UDP套接字的O或IPPROTO_UDP。
- 表示原始套接字的IP协议标识符(如IPPROTO_TCP或IPPROTO_ICMP ),请参见RFC
struct msghdr
**从用户空间套接字发送数据或在用户空间套接字中接收来自传输层的数据,这些工作分配是通信内核中调用方法sendmsg()/recvmsg()来处理。**它们会将一个msghdr对象作为参数,这个msghdr对象包含要发送或填充的数据块及其它参数。
struct msghdr {
void *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
struct iov_iter msg_iter; /* data */
void *msg_control; /* ancillary data */
__kernel_size_t msg_controllen; /* ancillary data buffer length */
unsigned int msg_flags; /* flags on received message */
struct kiocb *msg_iocb; /* ptr to iocb for async requests */
};
- msg_name:目标套接字地址。为获取目标套接字,通常会将不透明指针msg_name转换为指向结构sockaddr_in的指针,请参阅方法udp_sendmsg()。
- msg_namelen:地址的长度。
- msg_iter: 数据(共用体) 含iovec——数据块矢量。
- msg_control:控制信息(也叫辅助数据(ancillary data ))。
- msg_controllen:控制信息的长度。
- msg_flags:收到的消息的标志,如MSG_MORE(参见11.3.2节)。
请注意,对于每个套接字,内核可处理的最大控制缓存区长度大小为sysctl_optmem_max (/proc/sys/net/core/optmem_max)的值。
UDP
UDP提供面向消息的不可靠传输,但没有拥塞控制功能。很多协议都使用UDP,如用于IP网络传输音频和视频的实时传输协议(Real-time Transport Protocol,RTP),此类型容许一定的数据包丢弃。UDP报头长8字节,具体内核源码如下:
include\uapi\linux\udp.h
struct udphdr {
__be16 source; // 源端口
__be16 dest; // 目的端口
__be16 len; // 有效负载和udp报头总长度
__sum16 check; // 数据包的校验和
};
UDP初始化操作
定义对象==udp_protocol(net_protocol对象)==并使用方法inet_add_protocol()来添加它,这将使对象udp_protocol成为全局协议数组( inet_protos )的一个元素。
net\ipv4\af_inet.c
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
static int __init inet_init(void)
{
. . .
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
. . .
}
**接下来,定义一个udp_prot对象,并调用方法proto_register()来注册它。**这个对象包含的几乎都是回调函数,**在用户空间打开UDP套接字和使用套接字API时,将调用这些回调函数。**例如,对UDP套接字调用系统调用setsockopt()时,将调用回调函数udp_setsockopt()。
net/ipv4/udp.c
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.connect = ip4_datagram_connect,
.disconnect = udp_disconnect,
.ioctl = udp_ioctl,
. . .
.setsockopt = udp_setsockopt,
.getsockopt = udp_getsockopt,
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage,
. . .
};
int __init inet_init(void)
{
int rc = -EINVAL;
. . .
rc = proto_register(&udp_prot, 1);
. . .
}
发送数据包(到L3) udp_sendmsg
详情请见 : LINUX内核网络数据包发送(二)——UDP协议层分析
要从UDP用户空间套接字中发送数据,可使用多个系统调用: send() 、sendto()、sendmsg()和write()。这些系统调用最终都由内核中的方法udp_sendmsg()来处理。用户空间应用程序创建包含数据块的msghdr对象,并将其传递给内核。下面来看看方法udp_sendmsg()。
-
**UDP corking (阻塞)是一项优化技术,允许内核将多次数据累积成单个数据报发送。**在用户程序中有两种方法可以启用此选项:
-
使用
setsockopt系统调用设置 socket 的UDP_CORK选项 -
程序调用
send,sendto或sendmsg时,带MSG_MORE参数
udp_sendmsg代码检查up->pending以确定 socket 当前是否已被塞住(corked),如果是, 则直接跳到do_append_data进行数据追加(append)。 -
-
其次执行完整性检测,udp长度不能超过65535 —— 2^16-1
-
还需要知道目标地址和目标端口,这样才能创建使用方法udp_send_skb()或ip_append_data()发送SKB所需的flowi4对象。目标端口不能为0。这里有两种情形:在msghdr的msg_name中指定了目标端口;或者套接字已连接,其状态为TCP_ESTABLISHED。请注意,UDP不同于TCP,它是一种无状态协议。在UDP中,状态TCP_ESTABLISHED意味着套接字已经通过了一些完整性检查。
-
现在开始路由,UDP 层中处理路由的代码以快速路径(fast path)开始。如果 socket 已连接,则直接尝试获取路由。
如果 socket 未连接,或者虽然已连接,但路由辅助函数
sk_dst_check认定路由已过期,则代码将进入慢速路径(slow path)以生成一条路由记录。 -
如果调用
send,sendto或sendmsg的时候指定了MSG_CONFIRM参数(阻止 ARP 缓存过期)
UDP 协议层将会 goto do_confirm; 该标志提示系统去确认一下 ARP 缓存条目是否仍然有效,防止其被垃圾回收。- 其在相应的缓存条目上设置一个标记位,稍后当查询邻居缓存并找到 条目时将检查该标志,我们后面一些会看到。此功能通常用于 UDP 网络应用程序,以减少不必要的 ARP 流量。此代码确认缓存条目然后跳回
back_from_confirm标签。一旦do_confirm代码跳回到back_from_confirm(或者之前就没有执行到do_confirm),代码接下来将处理 UDP cork 和 uncorked 情况。
- 其在相应的缓存条目上设置一个标记位,稍后当查询邻居缓存并找到 条目时将检查该标志,我们后面一些会看到。此功能通常用于 UDP 网络应用程序,以减少不必要的 ARP 流量。此代码确认缓存条目然后跳回
-
uncorked UDP sockets 快速路径
如果不需要 corking,数据就可以封装到一个
struct sk_buff实例中并传递给udp_send_skb,离 IP 协议层更进了一步。这是通过调用ip_make_skb来完成的。 -
没有被 cork 的数据时的慢路径
如果使用了 UDP corking,但之前没有数据被塞住(corked),则慢路径开始:
- 对 socket 加锁
- 检查应用程序是否有 bug:已经被 cork 的 socket 是否再次被 cork
- 设置该 UDP flow 的一些参数,为 corking 做准备
- 分配一个新缓冲区来存储传入的数据
接收数据包 udp_rcv
UDP数据包接收过程
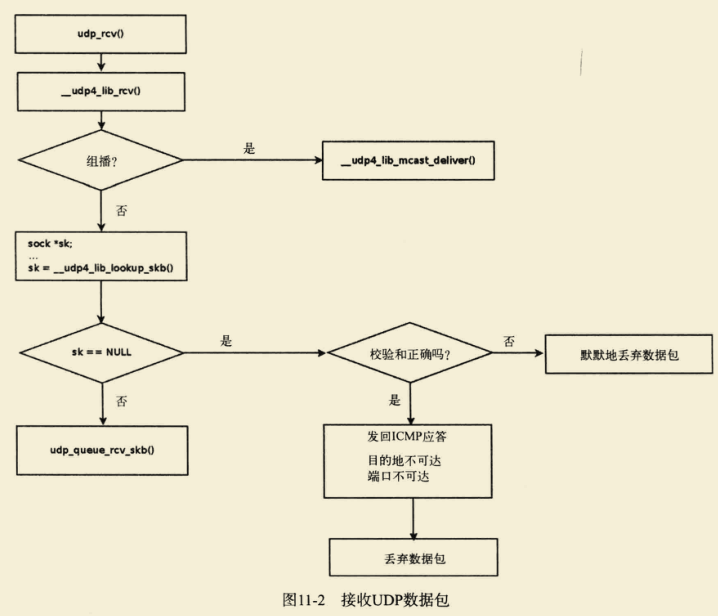
方法udp_rcv()是负责接收来自网络层(L3)的UDP数据包的主处理程序。它所做的唯一工作就是调用方法_udp4_lib_rcv() (net/ipv4/udp.c)。
UDP有两条处理路径:
1)放到sk的接收队列,通知等待进程;
2)调用udp_sock的encap_rcv函数,类似vxlan的实现,可以直接在内核中进行处理。
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto)
{
struct sock *sk;
struct udphdr *uh;
unsigned short ulen;
struct rtable *rt = skb_rtable(skb); //得到路由表项信息
__be32 saddr, daddr;
struct net *net = dev_net(skb->dev);
/*
* Validate the packet.
*/
if (!pskb_may_pull(skb, sizeof(struct udphdr))) //检测报文长度
goto drop; /* No space for header. */
// 从SKB中取回UDP报头、报头长度以及源地址和目标地址。
uh = udp_hdr(skb);
ulen = ntohs(uh->len);
saddr = ip_hdr(skb)->saddr;
daddr = ip_hdr(skb)->daddr;
if (ulen > skb->len) //skb报文长度必须UDP头设定的长度,skb可能存在pad
goto short_packet;
if (proto == IPPROTO_UDP) {
/* UDP validates ulen. */
if (ulen < sizeof(*uh) || pskb_trim_rcsum(skb, ulen)) //裁剪skb报文
goto short_packet;
uh = udp_hdr(skb);
}
if (udp4_csum_init(skb, uh, proto)) //csum值校验,如果非零则表示csum错误
goto csum_error;
sk = skb_steal_sock(skb); //IP层调用UDP的early_demux函数设置的sk
if (sk) {
struct dst_entry *dst = skb_dst(skb);
int ret;
if (unlikely(sk->sk_rx_dst != dst))
udp_sk_rx_dst_set(sk, dst);
ret = udp_queue_rcv_skb(sk, skb); //sock处理skb报文
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
return __udp4_lib_mcast_deliver(net, skb, uh, // 组播报文上送
saddr, daddr, udptable, proto);
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable); // 全量检索sock
if (sk) {
int ret;
if (inet_get_convert_csum(sk) && uh->check && !IS_UDPLITE(sk))
skb_checksum_try_convert(skb, IPPROTO_UDP, uh->check, // 如果skb->ip_summed == CHECKSUM_NONE,重置csum
inet_compute_pseudo);
ret = udp_queue_rcv_skb(sk, skb); // sock处理skb报文
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) // ipset安全检测
goto drop;
nf_reset(skb);
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb)) // 没有socket,如果checksum出错则直接丢弃
goto csum_error;
UDP_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0); // 发送icmp,通知发送方目的不可达
/*
* Hmm. We got an UDP packet to a port to which we
* don't wanna listen. Ignore it.
*/
kfree_skb(skb);
return 0;
short_packet:
net_dbg_ratelimited("UDP%s: short packet: From %pI4:%u %d/%d to %pI4:%u\n",
proto == IPPROTO_UDPLITE ? "Lite" : "",
&saddr, ntohs(uh->source),
ulen, skb->len,
&daddr, ntohs(uh->dest));
goto drop;
csum_error:
/*
* RFC1122: OK. Discards the bad packet silently (as far as
* the network is concerned, anyway) as per 4.1.3.4 (MUST).
*/
net_dbg_ratelimited("UDP%s: bad checksum. From %pI4:%u to %pI4:%u ulen %d\n",
proto == IPPROTO_UDPLITE ? "Lite" : "",
&saddr, ntohs(uh->source), &daddr, ntohs(uh->dest),
ulen);
UDP_INC_STATS_BH(net, UDP_MIB_CSUMERRORS, proto == IPPROTO_UDPLITE); // UDP csum错误统计
drop:
UDP_INC_STATS_BH(net, UDP_MIB_INERRORS, proto == IPPROTO_UDPLITE); // UDP丢包统计
kfree_skb(skb);
return 0;
}
TCP
TCP非常复杂,本章不讨论TCP实现的所有细节、优化和微秒之处,因为这些足够写一部专著。TCP功能由两部分组成:连接管理和数据收发。本节重点介绍TCP的初始化和TCP连接的建立(它们属于连接管理部分)以及数据包的接收和发送(它们属于数据收发部分)。这些是重要的基础知识,能够让你更深入地探索TCP的实现。需要指出的是,TCP通过拥塞控制来对字节流进行自我管控。拥塞控制算法很多,Linux提供了一个可插拔、可配置的架构,以支持各种拥塞控制算法。深入探讨各种拥塞控制算法的细节不在本书的范围之内。每个TCP数据包的开头都是一个TCP报头。要理解TCP的工作原理,必须了解TCP报头。下面就来描述IPv4TCP报头。
doff表示数据偏移量(data offset)并指定了TCP首部结构的长度,标识该tcp头部有多少个32bit字(4字节)因为4位最大能表示15,所以tcp头部最长是60字节。

TCP初始化
定义对象tcp_protocol ( net_protocol对象),并使用方法inet_add_protocol()来添加它。
// 此结构net_protocol定义了传输层协议,其中包含了传输层协议(icmp/igmp协议)
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static int __init inet_init(void)
{
. . .
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
. . .
}
接下来,像UDP一样,定义一个tcp_prot对象并调用方法proto_register()来注册它**(随后 执行系统调用sys_socket,会初始化socket里sock的结构)**。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
. . .
};
static int __init inet_init(void)
{
int rc;
. . .
rc = proto_register(&tcp_prot, 1);
. . .
}
请注意,在tcp_prot的定义中,函数指针init被设置为回调函数tcp_v4_init_sock(),它用于执行各种初始化工作,如调用方法tcp_init_xmit_timers()来设置定时器、设置套接字状态等。在相对简单得多的协议UDP中,根本就没有设置函数指针init,因为UDP不需要执行特殊的初始化。回调函数tcp_v4_init_sock()将在本节后面讨论。
TCP定时器
TCP定时器是在net/ipv4/tcp_timer.c中处理的。TCP使用的定时器有4个。
- **重传定时器:负责重传在指定时间内未得到确认的数据包。**数据包丢失或受损时就会出现这种情况。这个定时器在每个数据段发送后都会启动。如果定时器到期后未收到确认,将取消该定时器。
- **延迟确认定时器:推迟发送确认数据包。**在TCP收到必须确认但无需马上确认的数据时得到设置。
- **存活定时器:检查连接是否断开。**在有些情况下,会话会空闲很长时间,此时一方可能会断开连接。存活定时器会检测这样的情形,并调用方法tcp_send_active_reset()来重置连接。
- **零窗口探测定时器(也叫持续定时器):缓冲区满后,接收方会通告零窗口,发送方将停止发送数据。**接下来,如果发送方发送包含新窗口大小的数据段,但该数据段在传输过程中丢失了,发送方将永远地等待下去。这种问题的解决方案如下。发送方获悉接收方的窗口大小为零后,使用持续定时器来探测接收方的窗口大小。如果获悉窗口大小不为零,就将停止持续定时器。
TCP套接字的初始化
要使用TCP套接字,用户空间应用程序必须创建一个SOCK_STREAM套接字,并调用系统调用socket()。这在内核中是由回调函数tcp_v4_init_sock()来处理的。**它将调用方法tcp_init_sock()来完成实际工作。**请注意,方法tcp_init_sock()用于执行随地址簇而异的初始化。方法tcp_v6_init_sock()也可调用它。方法tcp_init_sock()执行的重要任务如下。
- 将套接字的状态设置为TCP_CLOSE。
- 调用方法tcp_init_xmit_timers()来初始化TCP定时器。
- 初始化套接字的发送缓冲区( sk_sndbuf)和接收缓冲区( sk_rcvbuf )。sk_sndbuf被设置为sysctl_tcp_wmem[1](默认为16384字节),而sk_rcvbuf被设置为sysctl_tcp_rmem1。这些默认值是在方法tcp_init()中设置的。要覆盖数组sysctl_tcp_wmem和sysctl_tcp_rmem的默认值,可分别设置/proc/sys/net/ipv4/tcp_wmem和/proc/sys/net/ipv4/tcp_rmem。请参阅Documentation/networking/ ip-sysctl.txt的“TCP变量”一节。
- 初始化无序队列和预备队列( prequeue ).
- 初始化各种参数。例如,根据2013年发布的RFC 6928 ( Increasing TCP 's Initial Window),将TCP初始拥塞窗口初始化为10 ( TCP_INIT_CWND)个数据段。
了解TCP套接字是如何初始化的后,来学习TCP连接是如何建立的。
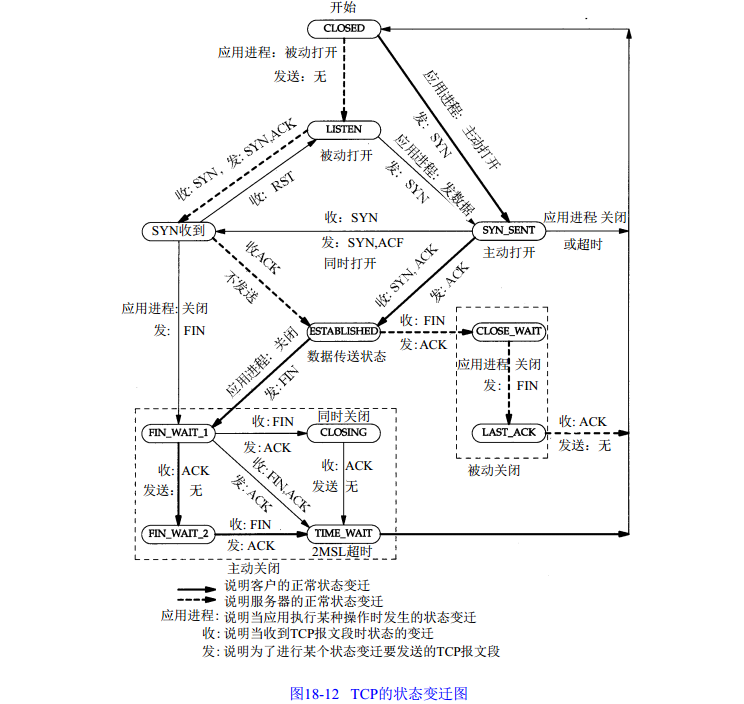
TCP的状态转移
TCP连接的建立和拆除以及TCP连接的属性都被描述为状态机的状态。在给定时点,TCP套接字将处于指定的任何一种状态。例如,调用系统调用listen()后,套接字进入TCP_LISTEN状态。sock对象的状态由其成员sk_state表示。完整的状态清单请参阅include/net/tcp_states.h。
在TCP客户端和TCP服务器之间,使用三次握手来建立TCP连接。
- 首先,客户端向服务器发送SYN请求,其状态变为TCP_SYN_SENT。
- 侦听的服务器套接字(其状态为TCP_LISTEN)创建一个处于TCP_SYN_RECV状态的请求套接字,来表示新的连接,并发回一个SYN_ACK。
- 客户端收到SYN ACK后,将其状态变为TCP_ESTABLISHED,并向服务器发送一个ACK。服务器收到ACK后,将请求套接字修改为处于TCP_ESTABLISHED状态的子套接字,因为此时连接已建立,可以发送数据。
总的状态转移图
TCP维护的socket散列表
系统中的每个TCP套接字都归入3个散列表之一,分别接受下列状态的套接字。
-
连接的套接字 —— 包括出listen外的所有套接字
- SYN_SENT(客户端第一次发送SYN时)、SYN_RECV(服务器发送SYN时)、FIN_WAIT1、FIN_WAIT2等
-
等待连接(监听状态)的套接字。
-
所有处于bind的套接字(无状态)。
struct inet_hashinfo {
// 'e' 前缀代表建立,但我们确实放置了除 LISTEN 之外的所有套接字。
struct inet_ehash_bucket *ehash; // listen之外的其他状态的tcp_sock散列表
struct inet_bind_hashbucket *bhash; // bind状态的tcp_sock散列表
unsigned int ehash_size // established状态的tcp_sock散列表长度
unsigned int bhash_size; // bind状态的tcp_sock散列表长度
struct kmem_cache *bind_bucket_cachep; // bind类型的tcp_sock的slab
struct hlist_head listening_hash[INET_LHTABLE_SIZE] // listen状态的tcp_sock散列表
rwlock_t lhash_lock ____cacheline_aligned; // 访问listening_hash的读写锁
atomic_t lhash_users; // 有进程写该结构时加1,这时其他进程会放入lhash_wait等待
wait_queue_head_t lhash_wait;
};
接收数据 tcp_v4_rcv
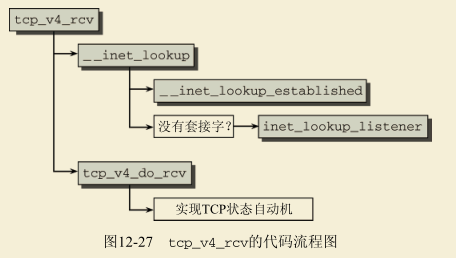
接收来自网络层(L3)的TCP数据包
方法tcp_v4_rcv() ( net/ipv4/tcp_ipv4.c)是负责接收来自网络层(L3)的TCP数据包的主处理程序,下面就来看看它。
-
首先,做一些完整性检查(例如,检查数据包类型是否为PACKET_HOST、TCP报头是否比整个数据包还长)。如果发现问题,就将数据包丢弃。
-
接下来,做一些初始化工作,并调用方法_inet_lookup_skb()查找匹配的套接字。
- 这个方法首先调用方法__inet_lookup_established(),在已建立的套接字散列表中查找。
- 如果没有找到,则调用方法_inet_lookup_listener()在侦听套接字散列表中查找。如果也没有找到,就将数据包丢弃。
-
接下来,检查套接字是否属于某个应用程序。如果套接字归某个应用程序所有,sock_owned_by_user()宏就返回1,否则返回0。
-
如果套接字不归任何应用程序所有,它便可以接收数据包。
-
在这种情况下,首先调用方法tcp_prequeue()来尝试将数据包加入**预备队列**,因为在预备队列中处理数据包的效率更高。
-
如果无法在预备队列中处理(例如,这个队列没有空间时),tcp_prequeue()将返回false。在这种情况下,将调用方法tcp_v4_do_rcv()。
tcp_v4_do_rcv是一个多路分解器,基于套接字状态将代码控制流划分为不同的分支。
- 如果套接字处于TCP_ESTABLISHED状态,就调用方法tcp_rcv_established()。
- 如果套接字处于TCP_LISTEN状态,则调用方法tcp_v4_hnd_req()。
- 如果套接字并非处于TCP_LISTEN状态,则调用方法tcp_rcv_state_process()。
-
-
当套接字归某个应用程序所有时,意味着它处于锁定状态,不能接收数据包。在这种情况下,将调用方法sk_add_backlog()将其加入**后备队列(backlog)**。
-
三个队列
TCP对输入数据包的整体处理流程可以简单的用下图表达:
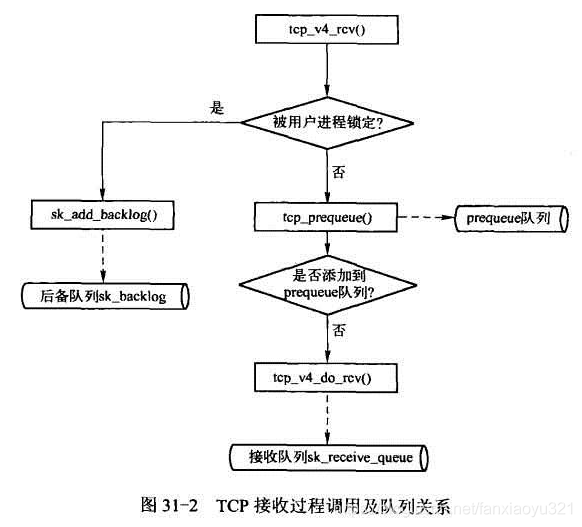
从上图中可以看到TCP的接收过程会涉及到三个队列:prequeue队列、receive队列以及backlog队列,这里首先介绍下这三个队列的作用,然后再跟踪源代码实现。
The backlog queue is special, it is always used with the per-socket spinlock held and requires low latency access. Therefore we special case it’s implementation.
The backlog queue是特殊的,它总是与持有的每个套接字自旋锁一起使用,并且需要低延迟访问。 因此我们特例它的实现。
对应于sock中的sk_backlog结构
receive队列以及backlog队列 都是独属于一个sock
从数据接收的角度考虑,可以将TCP的传输控制块(TCB,就是sock)的状态分为如下三种:
- 用户进程正在读写数据,此时TCB是被锁定的
- 用户进程正在读写数据,但是因为没有数据可用而进入了休眠态,等待数据可用,这时TCB是不会被用户进程锁定的
- 用户进程根本就没有在读写数据,当然这时TCB也不会被用户进程锁定
再考虑一点,由于协议栈对输入数据包的处理实际上都是软中断中进行的,出于性能的考虑,我们总是期望软中断能够快速的结束。
这样,再来理解上图:
- 如果被用户进程锁定,那么处于情形一,此时由于互斥,没得选,为了能快速结束软中断处理,将数据包放入到backlog队列中,这类数据包的真正处理是在用户进程释放TCB时进行的;
- 如果没有被进程锁定,那么首先尝试将数据包放入prequeue队列,原因还是为了尽快让软中断结束,这种数据包的处理是在用户进程读数据过程中处理的;
- 如果没有被进程锁定,prequeue队列也没有接受该数据包(出于性能考虑,比如prequeue队列不能无限制增大),那么没有更好的办法了,必须在软中断中对数据包进行处理,处理完毕后将数据包加入到receive队列中。
综上,可以总结如下:
- 放入receive队列的数据包都是已经被TCP处理过的数据包,比如校验、回ACK等动作都已经完成了,这些数据包等待用户空间程序读即可;
- 相反,放入backlog队列和prequeue队列的数据包都还需要TCP处理,实际上,这些数据包也都是在合适的时机通过tcp_v4_do_rcv()处理的;
被动建立连接的流程
被动连接建立并不源于内核本身,而是在接收到一个连接请求的SYN分组后触发的。因而其起点是tcp_v4_rcv函数,如上文所述,该函数查找一个监听套接字,并将控制权转移到tcp_v4_do_rcv,其代码流程图(对此特定场景适用)在图12-28给出。
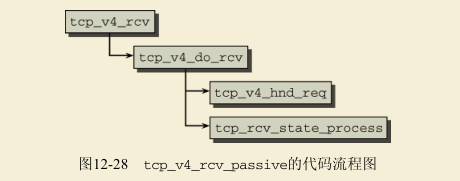
调用tcp_v4_hnd_req来执行网络层中建立新连接所需的各种初始化任务。实际的状态迁移发生在tcp_rcv_state_process中,该函数由一个长的switch/case语句组成,区分各种可能的套接字状态来调用适当的传输函数。
**如果套接字状态是TCP_LISTEN,则调用tcp_v4_conn_request。该函数处理了TCP的许多细节和微妙之处,在这里不描述了。重要的是该函数结束前发送的确认分组。其中不仅包含了设置的ACK标志和接收到的分组的序列号,还包括新生成的序列号和SYN标志,这是三次握手过程的要求。**这样就完成了连接建立的第一阶段。
**客户端的下一步是,接收通过通常的路径到达tcp_rcv_state_process的ACK分组。套接字状态现在是TCP_SYN_RECV,由一个特定的case分支处理。**内核的主要任务是将套接字状态修改为TCP_ESTABLISHED,表示连接现在已经建立。
enum {
TCP_ESTABLISHED = 1,
TCP_SYN_SENT,
TCP_SYN_RECV,
TCP_FIN_WAIT1,
TCP_FIN_WAIT2,
TCP_TIME_WAIT,
TCP_CLOSE,
TCP_CLOSE_WAIT,
TCP_LAST_ACK,
TCP_LISTEN,
TCP_CLOSING, /* 现在是有效状态 */
TCP_MAX_STATES /* 标志状态定义的结束! */
};
主动建立连接的流程
主动连接建立发起时,是通过用户空间应用程序调用open库函数,发出socketcall系统调用到达内核函数tcp_v4_connect,其代码流程图如图12-29的上半部所示。

**该函数开始于查找到目标主机的IP路由,使用的框架如上所述。在产生TCP首部并将相关的值设置到套接字缓冲区中之后,套接字状态从CLOSED改变为SYN_SENT。接下来tcp_connect将一个SYN分组发送到互联网络层,接下来到服务器端。**此外,在内核中创建一个定时器,确保如果在一定的时间内没有接收到确认,将重新发送分组。
现在客户端必须等待服务器对SYN分组的确认以及确认连接请求的一个SYN分组,这是通过普通的TCP机制接收的(图12-29的下半部)。这又通向了tcp_rcv_state_process分配器,在这种情况下,控制流又转移到tcp_rcv_synsent_state_process。套接字状态设置为ESTABLISHED,而tcp_send_ ack向服务器返回另一个ACK分组,完成连接建立。
接收分组 tcp_rcv_established
图12-30中的代码流程图给出了接收分组时所采用的代码路径,从我们熟悉的tcp_v4_rcv函数开始。
在控制传递到tcp_v4_do_rcv后,会选择一条快速路径(如果连接已经存在)而不是进入到中枢的分配器函数,这与其他套接字状态相反,但也是合乎逻辑的。因为在任何TCP连接中,分组的传输都占据了工作量的最大份额,所以应该尽快执行。在确认目标套接字的状态为TCP_ESTABLISHED之后,调用tcp_rcv_established函数,再次将控制流分裂开来。易于分析的分组在快速路径(fast path)中处理,而包含了不常见选项的分组在低速路径(slow path)处理。
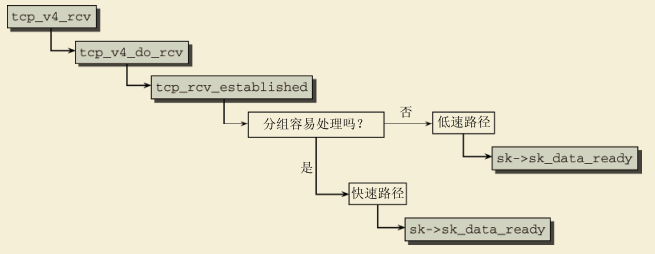
分组需要符合下列条件之一,才能归类为易于分析的。
- 分组必须只包含对上一次发送数据的确认。
- 分组必须只包含预期将接收的数据。
- 此外,下列标志都不能设置:SYN、URG、RST或FIN。
上述对“最佳场景”下分组的描述,并不是特定于Linux的,在许多其他Linux变体中也会出现。几乎所有分组都属于这些类别,这也是区分快速路径和低速路径的意义所在。
快速路径中会进行哪些操作?其中会进行一些分组的检查,找到更为复杂的分组,并将其返回到低速路径。接下来分析分组长度,确认分组的内容是数据还是确认。这没什么困难,因为ACK分组不包含数据,与TCP首部长度是相同的。
快速路径的代码并不处理ACK部分,该任务委托给tcp_ack。在这里,过时的分组以及由于接收方的TCP实现缺陷或传输错误和超时等造成的发送过早的分组,都被过滤出去。**该函数最重要的任务不仅包括分析有关连接的新信息(例如,接收窗口信息)和其他TCP协议的微妙之处,还需要从重传队列中删除确认数据(在下文讨论)。**该队列包含了所有发送的分组,如果在一定的时间限制内没有收到ACK确认,则需要重传。
因为在选择通过快速路径来处理该分组时,已经确认接收到的这部分数据是紧接着前一部分的,数据可以通过一个ACK分组向发送方确认,无须进一步检查。最后,调用保存在套接字中的sk_data_ready函数指针,通知用户进程有新数据可用。
**在低速路径和快速路径之间有什么差别呢?由于要处理许多TCP选项,低速路径中的代码要牵涉到更广泛的内容。**因此,这里不会深入阐述可能出现的许多具体情况,因为在很大程度上,这些不是内核的问题,而是TCP连接的一般性问题(详细的描述,可以参考[Ste94]和[WPR+01])。
在低速路径中,数据不能直接转发到套接字,因为必须对分组选项进行复杂的检查,而后可以是TCP子系统的响应。不按序到达的数据放置到一个专门的等待队列上,直至形成一个连续的数据段,才会被处理。只有到那时,才能将完整的数据传递到套接字。
发送分组(到L3) tcp_sendmsg
与UDP一样,要从用户空间中创建的TCP套接字发送数据包,可使用多个系统调用,包括:send() . sendto( ) . sendmsg()和write()。这些系统调用最终都由方法tcp_sendmsg()( netipv4/tcp.c )来处理。它将来自用户空间的有效负载复制到内核,并将其作为TCP数据段进行发送。这个方法比方法udp_sendmsg()要复杂得多。

很自然,在数据传输可以开始之前,所用套接字的状态必须是 TCP_ESTABLISHED or CLOSE_WAIT。如果不是这样,内核将等待(借助于sk_stream_wait_connect),直到连接已经建立。数据接下来从用户空间进程的地址空间复制到内核空间,用于建立一个TCP分组。这里不打算讨论这个复杂的操作,因为其中涉及大量过程,所有这些的目的都是满足TCP协议的复杂需求。
发送TCP分组的工作,并不仅仅限于构建一个首部并转入互联网络层。还必须遵守下列需求(这绝不是完备的列表)。
- 接收方等待队列上必须有足够的空间可用于该数据。
- 必须实现防止连接拥塞的ECN(基于显示反馈的协议)机制。
- 必须检测某一方出现失效的情况,以免通信出现停顿。
- TCP慢启动(slow-start)机制要求在通信开始时,逐渐增大分组长度。
- 发送但未得到确认的分组,必须在一定的超时时间间隔之后反复重传,直至接收方最终确认。
由于重传队列是通过TCP连接进行可靠数据传输的关键要素,所以这里详细讲述一下它的工作机制。在分组装配完毕之后,内核到达tcp_push_one (调用方法tcp_write_xmit()),该函数执行下列3个任务。
- tcp_snd_test检查目前是否可以发送数据。接收方过载导致的分组积压,可能使得现在无法发送数据。
- tcp_transmit_skb使 用 地 址 族 相 关 的 af_specific->queue_xmit函 数 ( IPv4 使 用 的 是ip_queue_xmit),将数据转发到互联网络层。
- icsk_af_ops ( INET连接套接字选项)是一个随地址簇而异的对象。对于IPv4 TCP,方法tcp_v4_init_sock()将其设置为一个名为ipv4_specific的inet_connection_sock_af_ops对象。queue_xmit回调函数被设置为通用方法ip_queue_xmit()。请参见net/ipv4/tcp_ipv4.c。
- update_send_head处理对统计量的更新。更重要的是,它会初始化所发送TCP信息段(TCP segment)的重传定时器。不必对每个TCP分组都这样做,该机制只用于已经确认的数据区之后的第一个分组。
inet_csk_reset_xmit_timer负责重置重传定时器。该定时器是未确认分组重发的基础,是TCP传输的一种保证。如果接收方在一定的时间内没有确认收到数据,则重传数据。所用的内核计时器在第15章描述。与特定套接字关联的sock实例中包含了一个重传计时器的链表,用于发送的每个分组。内核使用的超时函数是tcp_write_timer,如果没有收到ACK,该函数会调用tcp_retransmit_timer函数。在重传数据时,必须注意下列问题。
-
连接在此期间可能已经关闭。在这种情况下,保存的分组和定时器将从内核内存中删除。
-
如果重传尝试的次数超过了sysctl_tcp_retries2变量指定的限制,则放弃重传。
该变量的默认值是15,但可以使用/proc/sys/net/ipv4/tcp_retries2修改。
如上所述,在收到ACK之后,删除相应分组的重传定时器。
连接终止
类似于连接建立,TCP连接的关闭也是通过一系列分组交换完成的,如图12-25所示。连接可以采用下列两种方法关闭。
-
在参与传输的某一方(偶尔也会两个系统同时发出请求的情况)显式请求关闭连接时,连接会以优雅关闭(graceful close)的方式终止。
-
高层协议有可能导致连接终止或异常中止(例如,可能因为程序崩溃)。
幸运的是,因为第一种情况通常更为常见,这里只讨论这种情况并忽略第二种情况。为了优雅地关闭连接,TCP连接的参与方必须交换4个分组。各个步骤的顺序描述如下。
- 计算机A调用标准库函数close,发出一个TCP分组,首部中的FIN标志置位。A的套接字切换到FIN_WAIT_1状态。
(2) B收到FIN分组并返回一个ACK分组。其套接字状态从ESTABLISHED改变为CLOSE_WAIT。收到FIN后,以“文件结束”的方式通知套接字。
(3) 在收到ACK分组之后,计算机A的套接字状态从FIN_WAIT_1变为FIN_WAIT_2。
(4) 计算机B上与对应套接字相关的应用程序也执行close,从B向A发送FIN分组。计算机B的套接字状态变为LAST_ACK。
(5) 计算机A用一个ACK分组确认B发送的FIN,然后首先进入TIME_WAIT状态,接下来在一定时间后自动切换到CLOSED状态。
(6) 计算机B收到ACK分组,其套接字也切换到CLOSED状态。
状态迁移在中枢的分配器函数(tcp_rcv_state_process)中进行,可能的代码路径包括处理现存连接的tcp_rcv_established,以及尚未讨论的tcp_close函数。
在用户进程决定调用库函数close关闭连接时,会调用tcp_close。
-
如果套接字的状态为LISTEN(即没有到另一台计算机的连接),因为不需要通知其他参与方连接的结束。在过程开始时会检查这种情况,如果确实如此,则将套接字的状态改为CLOSED。
-
否则,在通过tcp_close_state并tcp_set_state调用链将套接字状态设置为FIN_WAIT_1之后,tcp_send_fin向另一方发送一个FIN分组。
- 从FIN_WAIT_1到FIN_WAIT_2状态的迁移通过中枢的分配器函数tcp_rcv_state_process进行,因为不再需要采取快速路径处理现存连接。
我们熟悉的一种情况是,收到的带有ACK标志的分组触发到FIN_WAIT_2状态的迁移,具体的状态迁移通过tcp_set_state进行。现在只需要从另一方发送过来的一个FIN分组,即可将TCP连接置为TIME_WAIT状态(然后会自动切换到CLOSED状态)。
- 从FIN_WAIT_1到FIN_WAIT_2状态的迁移通过中枢的分配器函数tcp_rcv_state_process进行,因为不再需要采取快速路径处理现存连接。
在收到第一个FIN分组因而需要被动关闭连接的另一方,状态迁移的过程是类似的。
-
因为收到第一个FIN分组是套接字状态为ESTABLISHED,处理由tcp_rcv_established的低速路径进行,涉及向另一方发送一个ACK分组,并将套接字状态改为TCP_CLOSING。
-
下一个状态转移(到LAST_ACK)是通过调用close库函数(进而调用了内核的tcp_close_state函数)进行的。此时,只需要另一方再发送一个ACK分组,即可终止连接。该分组也是通过tcp_rcv_state_process函数处理,该函数将套接字状态改为CLOSED(通过tcp_done),释放套接字占用的内存空间,并最终终止连接。
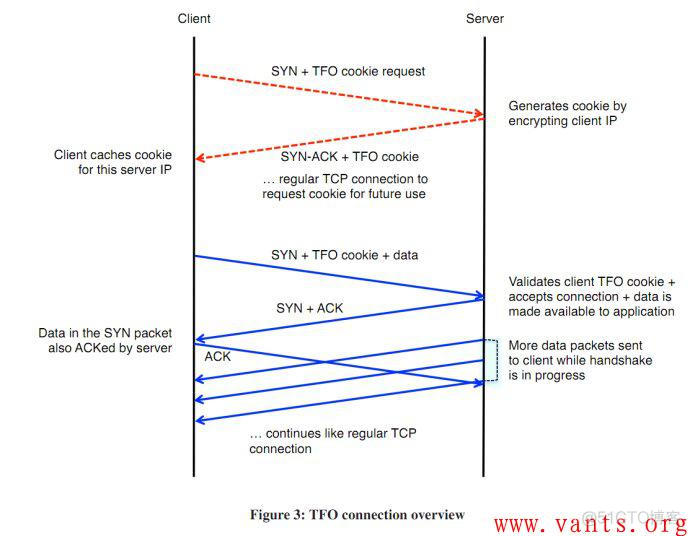
TFO(TCP FAST OPEN)
为了改善web应用相应时延方面的一个工作,google通过修改TCP协议利用三次握手时进行数据交换的TFO。和TCP相比TFO在3次握手期间也会传输数据。TFO是GOOGLE发布的。目前chrome已经支持TFO,但默认是关闭的,因为它有一些特定的使用场景。
TFO 系统开关配置
#3的意思是开启TFO客户端和服务器端
#1表示开启客户端,2表示开启服务器端
echo 3 > /proc/sys/net/ipv4/tcp_fastopen
- 客户端发送SYN包,包尾加一个TFO请求,只有4个字节。
- 服务端受到TFO请求,验证后根据来源ip地址声称cookie(8个字节),将这个COOKIE加载SYN+ACK包的末尾发送回去。
- 客户端缓存住获取到的Cookie 可以给下一次使用。
- 下一次请求开始,客户端发送SYN包,这时候后面带上缓存的COOKIE,然后就是正式发送的数据。
- 服务器端验证COOKIE正确,将数据交给上层应用处理得到相应结果,然后在发送SYN+ACK时,不再等待客户端的ACK确认,即开始发送相应数据。
目前互联网上页面平均大小为300KB,单个object平均大小及中值大小分别为7.3KB及2.4KB。所以在这种情况下,多一次RTT无疑会造成很大延迟。















 5078
5078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









