






一、pnxx介绍与使用
pnnx安装与使用参考:
- https://github.com/pnnx/pnnx
- https://github.com/Tencent/ncnn/wiki/use-ncnn-with-pytorch-or-onnx
- https://github.com/Tencent/ncnn/tree/master/tools/pnnx
支持python的首选pip,否则就源码编译。
pip3 install pnnx
ncnn导出路线有以下选择,一般常选用从pt文件或者torchscrip文件导出通过pnnx导出。

1.1 pnnx指令
pnnx [model.pt] [(key=value)...]
pnnxparam=model.pnnx.param
pnnxbin=model.pnnx.bin
pnnxpy=model_pnnx.py
pnnxonnx=model.pnnx.onnx
ncnnparam=model.ncnn.param
ncnnbin=model.ncnn.bin
ncnnpy=model_ncnn.py
fp16=1
optlevel=2
device=cpu/gpu
inputshape=[1,3,224,224],...
inputshape2=[1,3,320,320],...
customop=/home/nihui/.cache/torch_extensions/fused/fused.so,...
moduleop=models.common.Focus,models.yolo.Detect,...
Sample usage: pnnx mobilenet_v2.pt inputshape=[1,3,224,224]
pnnx yolov5s.pt inputshape=[1,3,640,640]f32 inputshape2=[1,3,320,320]f32 device=gpu moduleop=models.common.Focus,models.yolo.Detect
-
pnnxparam(默认=“*.pnnx.param”,*为模型名称):PNNX 图形定义文件
-
pnnxbin(default=“*.pnnx.bin”):PNNX 模型权重
-
pnnxpy(default=“*_pnnx.py”):用于推理的PyTorch脚本,包括模型构建和权重初始化代码
pnnxonnx(default=“*.pnnx.onnx”): onnx 格式的 PNNX 模型
-
ncnnparam(default=“*.ncnn.param”): ncnn 图定义 -
ncnnbin(default=“*.ncnn.bin”):ncnn模型权重 -
ncnnpy(default=“*_ncnn.py”):用于推理的pyncnn脚本
-
fp16(默认=1):以 fp16 数据类型保存 ncnn 权重和 onnx -
optlevel(默认=2):图形优化级别
- 0:不应用优化
- 1:推理优化
- 2:优化更多用于推理
-
device(默认=“cpu”):TorchScript 模型中输入的设备类型,cpu 或 gpu
-
inputshape(可选):模型输入的形状。它用于解析模型图中的张量形状。例如,[1,3,224,224]对于只有 1 个输入的模型,[1,3,224,224],[1,3,224,224]对于有 2 个输入的模型。 -
inputshape2(可选):备选模型输入的形状,格式与 相同inputshape。通常与 一起使用inputshape以解析模型图中的动态形状 (-1)。 -
customop(可选):自定义运算符的 Torch 扩展(动态库)列表,以“,”分隔。
-
moduleop(可选):要保留为一个大运算符的模块列表,以“,”分隔。例如,`models.common.Focus,models.yolo.Detect
举例:将TorchScript转换为 PNNX
pnnx resnet18.pt inputshape=[1,3,224,224]
正常情况下,会得到七个文件
-
resnet18.pnnx.param:PNNX 图定义
-
resnet18.pnnx.bin:PNNX 模型权重
-
resnet18_pnnx.py:用于推理的 PyTorch 脚本,用于模型构建和权重初始化的 Python 代码
-
resnet18.pnnx.onnx:onnx 格式的 PNNX 模型
-
resnet18.ncnn.param:ncnn 图定义 -
resnet18.ncnn.bin:ncnn 模型权重 -
resnet18_ncnn.py:用于推理的 pyncnn 脚本
1.2 pnnx.param 格式
pnnx.param的格式如下所示:
7767517
4 3
pnnx.Input input 0 1 0
nn.Conv2d conv_0 1 1 0 1 bias=1 dilation=(1,1) groups=1 in_channels=12 kernel_size=(3,3) out_channels=16 padding=(0,0) stride=(1,1) @bias=(16)f32 @weight=(16,12,3,3)f32
nn.Conv2d conv_1 1 1 1 2 bias=1 dilation=(1,1) groups=1 in_channels=16 kernel_size=(2,2) out_channels=20 padding=(2,2) stride=(2,2) @bias=(20)f32 @weight=(20,16,2,2)f32
pnnx.Output output 1 0 2
-
magic数字:用于标识文件的格式,pnnx和ncnn的param表示都是一样的7767517。
-
[operator count] [operand count]:第二行是两个数组分别表示
Layer(算子)和Blob的个数,即模型中层(Layer)和数据块(Blob)的数量。- 4: 表示模型中的总层数。层是模型的基本组成单位,例如卷积层、池化层等。
- 3: 表示模型中数据块的总数。数据块通常包括模型参数(如权重)和中间计算结果。
-
operator line:其格式如下所示:
[type] [name] [input count] [output count] [input operands] [output operands] [operator params]- type :类型名称,例如 Conv2d ReLU 等
- name :该操作员的名称
- 输入计数:此运算符需要作为输入的操作数的数量
- 输出计数:此运算符作为输出产生的操作数的数量
- 输入操作数名字:所有输入 blob 名称的名称列表,以空格分隔
- 输出操作数名字:所有输出 blob 名称的名称列表,以空格分隔
- 运算符参数:键=值对列表,以空格分隔,运算符权重以
@符号为前缀,张量形状以符号为前缀#,输入参数键以$
1.3 pnnx.bin格式
pnnx.bin 文件是一个以“存储模式”(无压缩)创建的压缩文件。权重二进制文件的名称由算子名称和权重名称组成。例如,nn.Conv2d的参数可以表示为:
conv_0 1 1 0 1 bias=1 dilation=(1,1) groups=1 in_channels=12 kernel_size=(3,3) out_channels=16 padding=(0,0) stride=(1,1) @bias=(16) @weight=(16,12,3,3)
其中,conv_0.weight 和 conv_0.bias 会被打包到 pnnx.bin 的压缩文件中。权重二进制文件可以使用任何压缩文件工具(例如 7zip)来列出或修改。

pnnx计算图相关参考:https://blog.csdn.net/qq_53144843/article/details/141262656?spm=1001.2014.3001.5501
二、torchscript文件导出
在导出torchscript文件之前需要修改yolo.py文件Detect类中的forward函数,在老版本的export.py 中,通过添加train参数,去除模型中的后处理。但是新版本7.0中,该参数被删除了,所以需要将模型中的后处理去掉。
将Detect类下面的forward函数修改为下面的forward函数。
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
feat = self.m[i](x[i]) # conv
# x(bs,255,20,20) -> x(bs,20,20,255)
feat = feat.permute(0, 2, 3, 1).contiguous()
z.append(feat.sigmoid())
return tuple(z)

forward函数的主要目的是对 YOLO 模型的输出进行处理,根据模型的用途(训练或推理)来调整预测结果的格式。它包括特征图的形状调整、网格和锚框的计算、坐标和尺寸的解码以及最终的预测结果拼接。
以下是整个函数的注释:
def forward(self, x):
# `x` 是一个输入张量列表,包含了来自不同尺度的特征图
z = [] # 存储推理阶段的输出结果
# 遍历每一个特征图
for i in range(self.nl):
# 对第i个特征图应用对应的卷积层self.m[i]
x[i] = self.m[i](x[i]) # 卷积操作
# 获取特征图的尺寸
bs, _, ny, nx = x[i].shape # bs: 批量大小, ny: 高度, nx: 宽度
# 调整特征图的形状为 (bs, na, no, ny, nx),并重新排列维度
# na是锚框的数量,no是每个锚框预测的输出特征(通常包括坐标、宽高、置信度和类别概率)。
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 推理阶段的处理
if not self.training: # 如果不是训练阶段
# 如果动态网格或锚框的尺寸与当前特征图的尺寸不匹配,则更新网格和锚框
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
# 如果模型是分割模型(包含掩码)
if isinstance(self, Segment):
# 分离出坐标 (xy), 宽高 (wh), 置信度 (conf) 和掩码 (mask)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
# 将坐标进行 sigmoid 激活,转换为实际的坐标位置
xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i]
# 将宽高进行 sigmoid 激活,并进行缩放
wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i]
# 将所有结果拼接成一个张量
y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
else: # 否则是目标检测模型(不包含掩码)
# 分离出坐标 (xy), 宽高 (wh) 和 置信度 (conf)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
# 将坐标进行 sigmoid 激活,转换为实际的坐标位置
xy = (xy * 2 + self.grid[i]) * self.stride[i]
# 将宽高进行 sigmoid 激活,并进行缩放
wh = (wh * 2) ** 2 * self.anchor_grid[i]
# 将所有结果拼接成一个张量
y = torch.cat((xy, wh, conf), 4)
# 将处理后的结果添加到列表 `z` 中
z.append(y.view(bs, self.na * nx * ny, self.no))
# 返回结果
# 如果是训练阶段,返回原始特征图 `x`
# 否则,如果 `self.export` 为 True,返回拼接后的预测结果
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
总体流程如下:
1.输入: x 是来自 YOLO 模型的特征图列表。
2.处理: 对每个特征图进行卷积操作,调整维度,处理推理阶段的网格和锚框,以及根据模型类型(检测或分割)处理坐标、宽高、置信度和掩码。
3.输出: 训练阶段返回原始特征图,推理阶段返回拼接后的预测结果。
def forward(self, x):
z = [] # 存储推理阶段的输出结果
for i in range(self.nl):
feat = self.m[i](x[i]) # 对第 i 个特征图应用对应的卷积层
# 将特征图的维度从 (bs, 255, 20, 20) 转换为 (bs, 20, 20, 255)
feat = feat.permute(0, 2, 3, 1).contiguous()
# 将特征图进行 sigmoid 激活,并添加到列表 `z` 中
z.append(feat.sigmoid())
# 返回处理后的特征图列表作为元组
return tuple(z)
修改之后的代码将 YOLO 模型的 forward方法进行了简化,移除了一些处理步骤,新的 forward方法只进行了卷积和激活操作,省略了之前的坐标、宽高、置信度的计算步骤,以及处理推理阶段的网格和锚框的操作。返回的是处理后的特征图列表,而不再包括原始特征图或额外的拼接操作。
补充:permute 和 contiguous 是 PyTorch 中用于操作张量(Tensor)的方法,常用于调整张量的维度顺序和内存布局。
-
permute 函数用于对张量的维度进行重新排列。
tensor.permute(*dims) # dims: 重新排列的维度顺序。需要传递一个维度索引的序列。 x = torch.randn(2, 3, 4) print(x.shape) # 输出: torch.Size([2, 3, 4]) # 重新排列维度 x_permuted = x.permute(1, 0, 2) print(x_permuted.shape) # 输出: torch.Size([3, 2, 4]) -
contiguous函数用于返回一个内存连续的张量。张量在某些操作(例如 permute)之后,可能会变得不再内存连续(non-contiguous),因此在某些情况下需要调用 contiguous函数以确保数据在内存中是连续的。
tensor.contiguous() x = torch.randn(2, 3, 4) x_permuted = x.permute(1, 0, 2) print(x_permuted.is_contiguous()) # 输出: False x_contiguous = x_permuted.contiguous() print(x_contiguous.is_contiguous()) # 输出: True -
view函数是 PyTorch 中用于改变张量形状的函数。它可以将张量重塑为不同的形状,而不改变其数据内容。
tensor.view(*shape) #shape:一个整数序列,用于指定新的张量形状。这个形状中的元素乘积必须等于原始张量的元素总数 # 创建一个形状为 (2, 3, 4) 的张量 x = torch.randn(2, 3, 4) print(x.shape) # 输出: torch.Size([2, 3, 4]) # 将张量重塑为形状 (6, 4) x_viewed = x.view(6, 4) print(x_viewed.shape) # 输出: torch.Size([6, 4])在深度学习模型中,经过 permute操作后,张量在内存中可能会变得不连续。为了确保后续操作能够正常执行,尤其是需要访问连续内存的操作(如 view),通常会在 permute 后调用 contiguous。例如,view操作需要内存连续的张量,如果张量不是内存连续的,就会导致错误。
使用如下指令导出TorchScript文件
python export.py --weights yolov5s.pt --include torchscript
会在当前工作目录下生成 yolov5s.torchscript,使用netron查看网络结构,如下图所示。
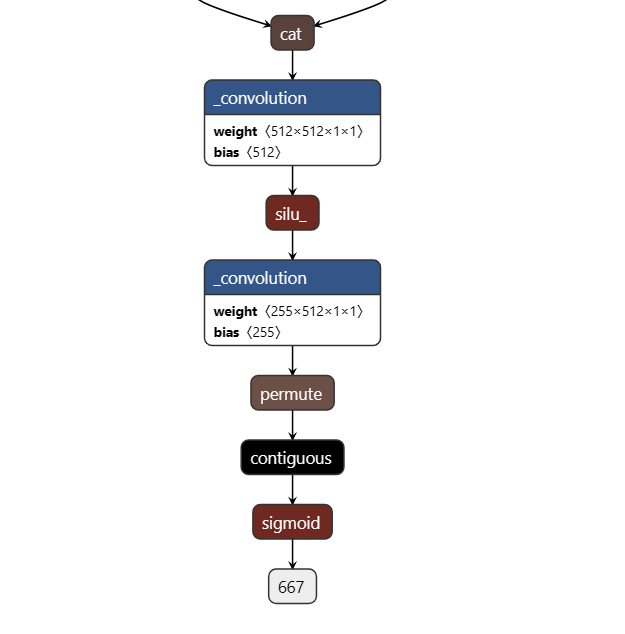
在计算图中会有三个上述的结构,这是我们修改的 forward 中的内容,由于 PNNX 会把最后的 reshape优化掉,所以不得已只能也把 sigmoid 导出。
三、模型转换
使用pnnx从torchscript文件中导出ncnn相关的文件,指令如下:指定 inputshape 并且额外指定 inputshape2 转换成支持动态 shape 输入的模型:
pnnx yolov5s.torchscript inputshape=[1,3,640,640] inputshape2=[1,3,320,320]
获得 yolov5s.ncnn.param和 yolov5s.ncnn.bin模型文件,如下图所示:

转换后的计算图如下:
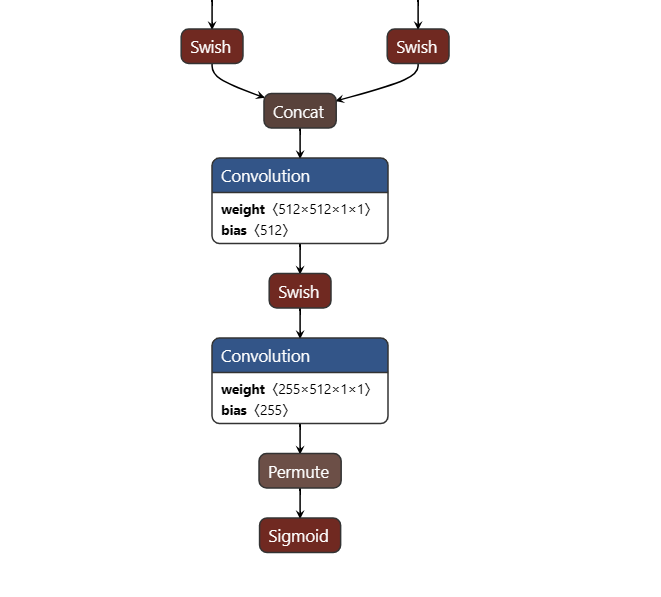
注意,本文用pnnx转换后的模型,尾巴上有permute和sigmoid层。
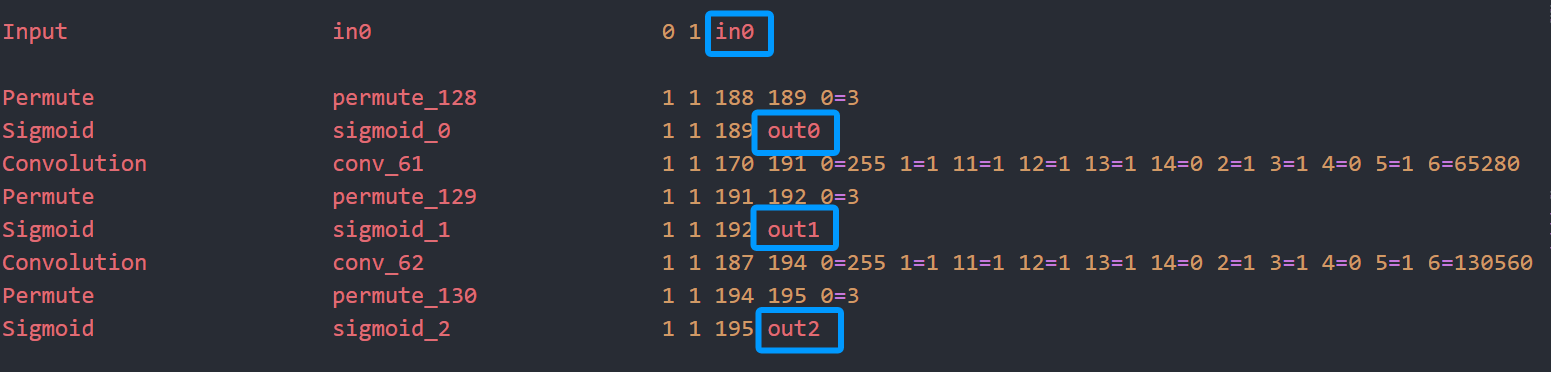
在param文件中查看输入与输出节点,如下所示:
四、模型推理
4.1 generate_proposals生成候选框
pytorch的后处理在 models/yolo.py Detect类 forward函数,也就是我们注释掉的部分,对着它改写成 cpp的推理代码。
anchor信息是在 yolov5/models/yolov5s.yaml。pnnx转换后的模型,输出blob名字总是 out0 out1 out2,分别对应于 stride 8/16/32 的输出,下面来看看其各个输出的大小:
首先说一下输入图像的尺寸调整和动态尺寸:
-
静态尺寸: 输入图像固定缩放到一个指定的尺寸(例如 640x640),并添加填充。按长边缩放到 640xH 或 Wx640,padding 到 640x640 再检测,如果 H/W 比较小,会在 padding 上浪费大量运算。
-
动态尺寸: 输入图像根据长边进行缩放,
保持纵横比不变,然后将短边填充到最接近的 64 的倍数。这种方式减少了不必要的填充,降低了计算量。按长边缩放到 640xH 或 Wx640,padding 到 640xH2 或 W2x640 再检测,其中 H2/W2 是 H/W 向上取64倍数,计算量少,速度更快。ncnn天然支持动态尺寸输入,无需reshape或重新初始化。
假设图片输入大小为640,当图片输入尺寸为1080×810×3,先把长边缩放到640,然后短边根据长边的缩放比例同步缩放,缩放完后图片的尺寸为640×480×3。最后将480上取整对齐到64的倍数,也就是512,所以图片的尺寸最后就是640×512×3。
图片经过模型的输出后会有三个尺度的输出,分别是8倍下采样,16倍下采样,32倍下采样。输出张量的形状表示了网格大小和锚框预测:
- Stride 8: ( w=640 / 8 =80, h=512/8=64 ) —> 80x64
- Stride 16: ( w=640 / 16 =40, h=512/16=32 )—>40x32
- Stride 32: ( w=640 / 32 =20, h=512/32=16 )—>20x16
每个输出张量的深度为 ((5+cls)×3= 85 * 3 )=255 ,其中 85 表示 ( 4 ) 个 bbox 坐标、( 1 ) 个置信度、( 80 ) 个类别概率,对应 3 个锚框。其分别对应的就是80×64×[(5+cls)×3],40×32×[(5+cls)×3],20×16×[(5+cls)×3]。
边界框的计算是基于网络输出的特征图和预定义的锚框(anchor)进行的

对每个位置 (i, j) 的输出张量值包含每个锚框的预测信息:
-
tx, ty: 边界框中心点相对于网格单元的偏移量。 -
tw, th: 边界框的宽度和高度。 -
objectness: 该网格单元包含物体的置信度box_confidence。 -
class_scores: 每个类别的得分。
YOLOv5 中的边界框坐标计算包括以下几个步骤:
1.解码边界框的中心点坐标 (bx, by),这里指的是在下采样后的特征图中的坐标,其中 (cx, cy)是当前网格单元的坐标,stride是下采样倍数。
$$
bx = sigmoid(tx) * 2 - 0.5 + cx \
by = sigmoid(ty) * 2 - 0.5 + cy \
bx_s = (sigmoid(tx) * 2 - 0.5 + cx) * stride = bx * stride\
by_s = (sigmoid(ty) * 2 - 0.5 + cy) * stride = by * stride\
因此,计算在原始尺寸图片大小的坐标
因此,计算在原始尺寸图片大小的坐标
因此,计算在原始尺寸图片大小的坐标(bx_s,by_S)$$需要将bx,by乘以下采样倍数stride。
2.解码边界框的宽度和高度 (bw, bh),这里指的是在下采样后的特征图中的宽和高,其中 anchor_w和 anchor_h是锚框的宽度和高度。
$$
bw = (sigmoid(tw) * 2) ^ 2 \
bh = (sigmoid(th) * 2) ^ 2 \
bw_s = (sigmoid(tw) * 2) ^ 2 * anchor_w = bw * anchor_w\
bh_s = (sigmoid(th) * 2) ^ 2 * anchor_h = bh * anchor_h
$$
同样的,bw和bh乘以anchor的宽和高就是图像原始尺度的宽高。
3.计算边界框的左上角 (x1, y1) 和右下角 (x2, y2) 坐标
x
1
=
b
x
s
−
b
w
s
/
2
y
1
=
b
y
s
−
b
h
s
/
2
x
2
=
b
x
s
+
b
w
s
/
2
y
2
=
b
y
s
+
b
h
s
/
2
x1 = bx_s - bw_s / 2 \\ y1 = by_s - bh_s / 2 \\ x2 = bx_s + bw_s / 2 \\ y2 = by_s + bh_s / 2
x1=bxs−bws/2y1=bys−bhs/2x2=bxs+bws/2y2=bys+bhs/2
在计算完边界框的实际坐标前,还需先后分别执行box_confidence和confidence阈值过滤:
box_confidence是指一个锚框(anchor)是否包含目标物体的置信度,它通常通过神经网络直接输出。box_confidence 表示模型对于这个锚框中是否存在物体的信心值,取值范围是 [0, 1],通常通过一个 sigmoid 函数计算得到。
confidence 是在 box_confidence的基础上,进一步考虑目标的类别置信度后得到的最终置信度。它不仅考虑了模型对于该锚框是否包含目标物体的信心,还综合了模型对于目标类别的信心。计算 confidence 的公式为:
c
o
n
f
i
d
e
n
c
e
=
b
o
x
_
c
o
n
f
i
d
e
n
c
e
×
c
l
a
s
s
_
s
c
o
r
e
confidence=box\_confidence \times class\_score
confidence=box_confidence×class_score
box_confidence只衡量了该锚框内是否存在物体的可能性。confidence则综合了物体存在的可能性和该物体属于某个类别的可能性,用于最终的检测结果筛选和评价。
最终的生成的候选框还需要进行非极大值抑制 (NMS), 移除相互重叠的边界框,保留置信度最高的框。
以上内容都是为了从模型的输出特征图中提取候选框,生成候选框代码如下,需要将代码中的generate_proposals方法的代码用下面的代码替换,这个函数不包括NMS操作。
/**
* @brief 通过对每个网格点和锚框组合的预测进行处理,生成可能包含对象的候选框(proposals), 将模型输出的特征图转换为实际的检测框
*
* @param anchors 锚框的尺寸信息,通常用于生成候选框
* @param stride 特征图和原始图像之间的步长
* @param in_pad 输入图像的填充信息
* @param feat_blob 特征图数据,包含了每个网格点的预测信息
* @param prob_threshold 置信度阈值,低于这个值的候选框将被忽略
* @param objects 存储生成的候选框对象的数组
*/
static void generate_proposals(const ncnn::Mat& anchors, int stride, const ncnn::Mat& in_pad, const ncnn::Mat& feat_blob, float prob_threshold, std::vector<Object>& objects)
{
// 获取特征图的宽度、高度和通道数
const int num_w = feat_blob.w; // 特征图的宽度
const int num_grid_y = feat_blob.c; // 特征图的通道数
const int num_grid_x = feat_blob.h; // 特征图的高度
// 计算锚框的数量
const int num_anchors = anchors.w / 2;
// 计算每个锚框对应的特征图的步长
const int walk = num_w / num_anchors;
// 计算类别数量
const int num_class = walk - 5;
// 遍历特征图的每个网格点
for (int i = 0; i < num_grid_y; i++)
{
for (int j = 0; j < num_grid_x; j++)
{
// 获取当前网格点的特征
const float* matat = feat_blob.channel(i).row(j);
// 遍历所有锚框
for (int k = 0; k < num_anchors; k++)
{
// 获取当前锚框的宽度和高度
const float anchor_w = anchors[k * 2];
const float anchor_h = anchors[k * 2 + 1];
// 获取当前锚框的预测值
const float* ptr = matat + k * walk;
float box_confidence = ptr[4];
// 如果置信度高于阈值,则进行处理
if (box_confidence >= prob_threshold)
{
// 找出得分最高的类别
int class_index = 0;
float class_score = -FLT_MAX;
for (int c = 0; c < num_class; c++)
{
float score = ptr[5 + c];
if (score > class_score)
{
class_index = c;
class_score = score;
}
// 计算最终置信度
float confidence = box_confidence * class_score;
// 如果最终置信度高于阈值,则生成候选框
if (confidence >= prob_threshold)
{
float dx = ptr[0];
float dy = ptr[1];
float dw = ptr[2];
float dh = ptr[3];
// 计算候选框的中心坐标
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
// 计算候选框的宽度和高度
float pb_w = powf(dw * 2.f, 2) * anchor_w;
float pb_h = powf(dh * 2.f, 2) * anchor_h;
// 计算候选框的左上角和右下角坐标
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
// 创建对象并设置其属性
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
// 将对象添加到结果数组中
objects.push_back(obj);
}
}
}
}
}
}
}
generate_proposals方法修改:https://blog.csdn.net/qq_41726670/article/details/134766957
4.2 nms_sorted_bboxes非极大值抑制
非极大值抑制(Non-Maximum Suppression,NMS)是一种在目标检测中常用的后处理算法,主要用于去除重叠的候选框(bounding boxes),从而保留最有可能包含目标的框。
// 非极大值抑制算法,去除重叠框
static void nms_sorted_bboxes(const std::vector<Object>& faceobjects, std::vector<int>& picked, float nms_threshold, bool agnostic = false)
{
picked.clear();
const int n = faceobjects.size();
// 计算每个框的面积
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = faceobjects[i].rect.area();
}
// 遍历所有对象
for (int i = 0; i < n; i++)
{
const Object& a = faceobjects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = faceobjects[picked[j]];
// 如果标签不同且非标签无关模式,则跳过
if (!agnostic && a.label != b.label)
continue;
// 计算交并比(IoU)
float inter_area = intersection_area(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0; // 交并比超过阈值,不保留
}
if (keep)
picked.push_back(i); // 保留该框
}
}
nms_sorted_bboxes 用于对已经排序的候选框集合 faceobjects 进行非极大值抑制,从中挑选出不重叠或者重叠程度低于阈值的候选框。它将保留下来的框的索引存储在 picked 向量中。
4.3 detect_yolov5
在detect_yolov5中主要功能是使用 YOLOv5 模型对输入图像进行目标检测,并返回检测到的目标位置(bounding boxes)及相关信息。这包括了从图像预处理到候选框生成、排序、非极大值抑制以及最后的候选框位置调整等完整的目标检测流程。
原始图像经过了预处理,包括缩放和填充(padding)。检测到的候选框是在预处理后的图像上生成的,因此在输出最终的检测结果时,需要将这些候选框的坐标变换回原始图像的坐标系中。现在来看看letterbox 操作,letterbox 操作。这个操作的目的是将输入图像调整为模型所需的尺寸,同时保持图像的纵横比,并进行适当的填充,代码如下:
// letterbox操作
// 原始图像的宽度和高度
int w = img_w;
int h = img_h;
// 缩放因子初始化为1
float scale = 1.f;
// 如果宽度大于高度,按宽度缩放
if (w > h)
{
scale = (float)target_size / w; // 计算宽度的缩放因子
w = target_size; // 将宽度调整为目标大小
h = h * scale; // 按缩放因子调整高度
}
else // 如果高度大于宽度,按高度缩放
{
scale = (float)target_size / h; // 计算高度的缩放因子
h = target_size; // 将高度调整为目标大小
w = w * scale; // 按缩放因子调整宽度
}
// 将输入图像从BGR格式转换为RGB格式并调整尺寸
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, img_w, img_h, w, h);
// yolov5/utils/datasets.py letterbox
// 计算需要填充的宽度和高度,以使其变为目标尺寸的倍数
int wpad = (w + max_stride - 1) / max_stride * max_stride - w; // 计算需要填充的宽度
int hpad = (h + max_stride - 1) / max_stride * max_stride - h; // 计算需要填充的高度
// 使用常数114进行边框填充
// 上下填充:hpad / 2 (上) 和 hpad - hpad / 2 (下)
// 左右填充:wpad / 2 (左) 和 wpad - wpad / 2 (右)
ncnn::Mat in_pad; // 创建填充后的图像
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
前面都好理解,主要是后面计算填充的宽度和高度wpad和hpad:
- (w + max_stride - 1) / max_stride,这是为了计算图像宽度加上步幅后,向上取整的步幅块数。加上max_stride - 1 是为了确保即使宽度不是 max_stride的整数倍也能正确向上取整。
- *max_stride是将计算结果乘以步幅,得到填充后的宽度(这个宽度是步幅的倍数)。
- -w:减去原始宽度,得到需要填充的宽度。
同样的计算方法应用于高度 hpad的计算。
比如w=640,h=480, max_stride=64, 那么wpad=(640+64-1)/64×64-640=0。hapd=(480+64-1)/64×64-640=543/64×64-640=8*64-480=32。注意这里是整数的除法,小数会被截断,为了上取整所以加了max_stride- 1。
最后在得到候选框后,需要将它们的坐标从预处理后的图像(即缩放和填充后的图像)转换回原始图像的坐标系。
int count = picked.size();
objects.resize(count); // 调整 objects 向量的大小以存储最终检测到的目标
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]]; // 将非极大值抑制后保留下来的候选框复制到 objects 向量中
// 调整回原始图像中的位置
// 计算原始图像中的坐标,将填充后的坐标转换回原始图像坐标
float x0 = (objects[i].rect.x - (wpad / 2)) / scale; // 左上角
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale; // 右下角
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// 边界检查,确保调整后的坐标不超出原始图像的边界
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f); // x0 必须在 [0, img_w - 1] 范围内
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f); // y0 必须在 [0, img_h - 1] 范围内
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f); // x1 必须在 [0, img_w - 1] 范围内
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f); // y1 必须在 [0, img_h - 1] 范围内
// 更新候选框的位置和尺寸
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0; // 计算框的宽度
objects[i].rect.height = y1 - y0; // 计算框的高度
}
上面的代码就是将经过模型预测的候选框从填充后的图像坐标系统转换回原始图像的坐标系统。
首先去除填充的影响,填充会在图像的四周增加边框,因此在将候选框转换回原始图像坐标时,首先需要去除填充的影响。假设 wpad 和 hpad 分别是图像宽度和高度上的填充量,则:
- 对候选框的
x坐标:去除填充后的坐标为x' = (x - wpad / 2) / scale - 对候选框的
y坐标:去除填充后的坐标为y' = (y - hpad / 2) / scale
其中:x 和 y是在填充后的图像上的坐标。wpad / 2 和 hpad / 2是在宽度和高度方向上的填充偏移量。scale是缩放比例,用于将坐标从缩放后的图像调整回原始图像。
x0:计算填充前的左上角 x坐标。由于图像在左边和右边可能有填充,需要减去填充的左边部分 (wpad / 2)。然后,用 scale除以原始尺寸上的比例因子以还原到原始图像坐标。
x1:计算填充前的右下角 x坐标。objects[i].rect.x + objects[i].rect.width 是右下角的 x 坐标,在此基础上减去填充的左边部分 (wpad / 2),然后用 scale除以原始尺寸上的比例因子以还原到原始图像坐标。
转换后的候选框坐标需要进行边界检查,确保它们在原始图像的范围内。候选框的坐标会被限制在 [0, img_w-1] 和 [0, img_h-1] 之间。整个变换过程包括去除填充的影响和缩放回原始图像尺寸,最终得到的候选框坐标是在原始图像上的真实位置。
由于YOLOv5 模型有三个输出,每个输出对应不同的下采样率(stride 8、stride 16、stride 32),用于检测不同尺度的目标。generate_proposals 函数根据给定的 anchor 和 stride 值生成候选框,并将其存储在 proposals 向量中,然后进行NMS。保留下来的候选框会调整回原始输入图像的坐标空间(原图进行预处理了,需要变换回原图中)中,并进行边界检查,确保其在图像范围内。最后调用draw_objects绘制检测到的目标即可,大致的推理流程就是这样的。
参考官方代码:https://github.com/Tencent/ncnn/tree/master/examples
五、编译与运行
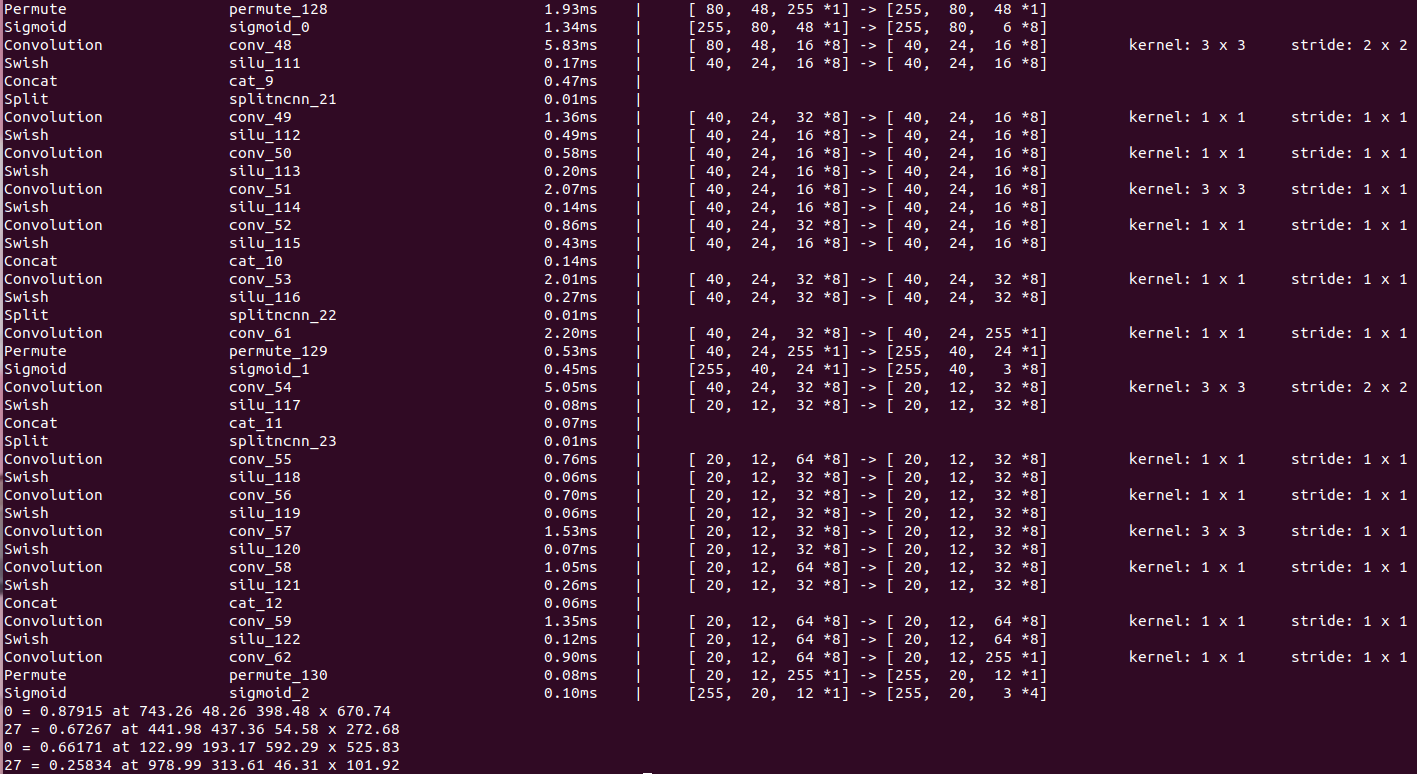
程序编译运行后如下所示:

日志输出信息
参考:
- https://zhuanlan.zhihu.com/p/471357671 针对6.1版本 pnnx导出
- https://zhuanlan.zhihu.com/p/606440867
- https://blog.csdn.net/qq_41726670/article/details/134766957 针对7.0版本 pnnx导出
六、源程序
#include "layer.h" // ncnn相关
#include "net.h"
// 如果定义了 USE_NCNN_SIMPLEOCV,则使用 simpleocv 库 ,否则使用 OpenCV
#if defined(USE_NCNN_SIMPLEOCV)
#include "simpleocv.h"
#else
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#endif
#include <float.h>
#include <stdio.h>
#include <vector>
// Object用于存储检测到的物体信息,包含矩形区域、标签和概率
struct Object
{
cv::Rect_<float> rect; // 目标框的位置和大小
int label; // 分类标签
float prob; // 分类概率
};
// 计算两个目标框的交集面积
static inline float intersection_area(const Object& a, const Object& b)
{
cv::Rect_<float> inter = a.rect & b.rect;
return inter.area();
}
// 对对象数组进行快速排序(降序排列)
static void qsort_descent_inplace(std::vector<Object>& faceobjects, int left, int right)
{
int i = left;
int j = right;
float p = faceobjects[(left + right) / 2].prob; // 基准值
while (i <= j)
{
while (faceobjects[i].prob > p)
i++;
while (faceobjects[j].prob < p)
j--;
if (i <= j)
{
// swap
std::swap(faceobjects[i], faceobjects[j]);
i++;
j--;
}
}
#pragma omp parallel sections
{
#pragma omp section
{
if (left < j) qsort_descent_inplace(faceobjects, left, j); // 对左侧继续排序
}
#pragma omp section
{
if (i < right) qsort_descent_inplace(faceobjects, i, right); // 对右侧继续排序
}
}
}
// 对对象数组进行快速排序(入口函数)
static void qsort_descent_inplace(std::vector<Object>& faceobjects)
{
if (faceobjects.empty())
return;
qsort_descent_inplace(faceobjects, 0, faceobjects.size() - 1);
}
// 非极大值抑制算法,去除重叠框
static void nms_sorted_bboxes(const std::vector<Object>& faceobjects, std::vector<int>& picked, float nms_threshold, bool agnostic = false)
{
picked.clear();
const int n = faceobjects.size();
// 计算每个框的面积
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = faceobjects[i].rect.area();
}
// 遍历所有对象
for (int i = 0; i < n; i++)
{
const Object& a = faceobjects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = faceobjects[picked[j]];
// 如果标签不同且非标签无关模式,则跳过
if (!agnostic && a.label != b.label)
continue;
// 计算交并比(IoU)
float inter_area = intersection_area(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0; // 交并比超过阈值,不保留
}
if (keep)
picked.push_back(i); // 保留该框
}
}
// Sigmoid 函数
static inline float sigmoid(float x)
{
return static_cast<float>(1.f / (1.f + exp(-x)));
}
/**
* @brief 通过对每个网格点和锚框组合的预测进行处理,生成可能包含对象的候选框(proposals), 将模型输出的特征图转换为实际的检测框
*
* @param anchors 锚框的尺寸信息,通常用于生成候选框
* @param stride 特征图和原始图像之间的步长,即下采样倍数
* @param in_pad 输入图像的填充信息
* @param feat_blob 特征图数据,包含了每个网格点的预测信息
* @param prob_threshold 置信度阈值,低于这个值的候选框将被忽略
* @param objects 存储生成的候选框对象的数组
*/
static void generate_proposals(const ncnn::Mat& anchors, int stride, const ncnn::Mat& in_pad, const ncnn::Mat& feat_blob, float prob_threshold, std::vector<Object>& objects)
{
// 获取特征图的宽度、高度和通道数
const int num_w = feat_blob.w; // 特征图的宽度
const int num_grid_y = feat_blob.c; // 特征图的通道数
const int num_grid_x = feat_blob.h; // 特征图的高度
// 计算锚框的数量
const int num_anchors = anchors.w / 2;
// 计算每个锚框对应的特征图的步长
const int walk = num_w / num_anchors;
// 计算类别数量
const int num_class = walk - 5;
// 遍历特征图的每个网格点
for (int i = 0; i < num_grid_y; i++)
{
for (int j = 0; j < num_grid_x; j++)
{
// 获取当前网格点的特征
const float* matat = feat_blob.channel(i).row(j);
// 遍历所有锚框
for (int k = 0; k < num_anchors; k++)
{
// 获取当前锚框的宽度和高度
const float anchor_w = anchors[k * 2];
const float anchor_h = anchors[k * 2 + 1];
// 获取当前锚框的预测值
const float* ptr = matat + k * walk;
float box_confidence = ptr[4];
// 如果置信度高于阈值,则进行处理
if (box_confidence >= prob_threshold)
{
// 找出得分最高的类别
int class_index = 0;
float class_score = -FLT_MAX;
for (int c = 0; c < num_class; c++)
{
float score = ptr[5 + c];
if (score > class_score)
{
class_index = c;
class_score = score;
}
// 计算最终置信度
float confidence = box_confidence * class_score;
// 如果最终置信度高于阈值,则生成候选框
if (confidence >= prob_threshold)
{
float dx = ptr[0];
float dy = ptr[1];
float dw = ptr[2];
float dh = ptr[3];
// 计算候选框的中心坐标
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
// 计算候选框的宽度和高度
float pb_w = powf(dw * 2.f, 2) * anchor_w;
float pb_h = powf(dh * 2.f, 2) * anchor_h;
// 计算候选框的左上角和右下角坐标
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
// 创建对象并设置其属性
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
// 将对象添加到结果数组中
objects.push_back(obj);
}
}
}
}
}
}
}
// 针对6.1 版本
// static void generate_proposals(const ncnn::Mat& anchors, int stride, const ncnn::Mat& in_pad, const ncnn::Mat& feat_blob, float prob_threshold, std::vector<Object>& objects)
// {
// const int num_grid_x = feat_blob.w;
// const int num_grid_y = feat_blob.h;
// const int num_anchors = anchors.w / 2;
// const int num_class = feat_blob.c / num_anchors - 5;
// const int feat_offset = num_class + 5;
// for (int q = 0; q < num_anchors; q++)
// {
// const float anchor_w = anchors[q * 2];
// const float anchor_h = anchors[q * 2 + 1];
// for (int i = 0; i < num_grid_y; i++)
// {
// for (int j = 0; j < num_grid_x; j++)
// {
// // find class index with max class score
// int class_index = 0;
// float class_score = -FLT_MAX;
// for (int k = 0; k < num_class; k++)
// {
// float score = feat_blob.channel(q * feat_offset + 5 + k).row(i)[j];
// if (score > class_score)
// {
// class_index = k;
// class_score = score;
// }
// }
// float box_score = feat_blob.channel(q * feat_offset + 4).row(i)[j];
// float confidence = sigmoid(box_score) * sigmoid(class_score);
// if (confidence >= prob_threshold)
// {
// // yolov5/models/yolo.py Detect forward
// // y = x[i].sigmoid()
// // y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
// // y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
// float dx = sigmoid(feat_blob.channel(q * feat_offset + 0).row(i)[j]);
// float dy = sigmoid(feat_blob.channel(q * feat_offset + 1).row(i)[j]);
// float dw = sigmoid(feat_blob.channel(q * feat_offset + 2).row(i)[j]);
// float dh = sigmoid(feat_blob.channel(q * feat_offset + 3).row(i)[j]);
// float pb_cx = (dx * 2.f - 0.5f + j) * stride;
// float pb_cy = (dy * 2.f - 0.5f + i) * stride;
// float pb_w = pow(dw * 2.f, 2) * anchor_w;
// float pb_h = pow(dh * 2.f, 2) * anchor_h;
// float x0 = pb_cx - pb_w * 0.5f;
// float y0 = pb_cy - pb_h * 0.5f;
// float x1 = pb_cx + pb_w * 0.5f;
// float y1 = pb_cy + pb_h * 0.5f;
// Object obj;
// obj.rect.x = x0;
// obj.rect.y = y0;
// obj.rect.width = x1 - x0;
// obj.rect.height = y1 - y0;
// obj.label = class_index;
// obj.prob = confidence;
// objects.push_back(obj);
// }
// }
// }
// }
// }
// 使用 YOLOv5 模型进行目标检测
/**
* @brief 对输入图像进行预处理,提取特征,生成候选框,进行非极大值抑制,并调整候选框的坐标
*
* @param bgr 输入的BGR格式的图像,用于目标检测
* @param objects 存储经过上述处理得到的最终检测到的目标对象
* @return int
*/
static int detect_yolov5(const cv::Mat& bgr, std::vector<Object>& objects)
{
ncnn::Net yolov5;
yolov5.opt.use_vulkan_compute = true;
// yolov5.opt.use_bf16_storage = true;
// 加载模型参数和权重
if (yolov5.load_param("/home/xiaochao/Infer/NCNN/use_ncnn/yolov5/model_param/yolov5s.ncnn.param"))
exit(-1);
if (yolov5.load_model("/home/xiaochao/Infer/NCNN/use_ncnn/yolov5/model_param/yolov5s.ncnn.bin"))
exit(-1);
// 设置目标尺寸、置信度阈值、非极大值抑制阈值
const int target_size = 640;
const float prob_threshold = 0.25f;
const float nms_threshold = 0.45f;
// 输入图像宽度和高度
int img_w = bgr.cols;
int img_h = bgr.rows;
// yolov5/models/common.py DetectMultiBackend
const int max_stride = 64; // YOLOv5使用的最大步幅
// letterbox操作
// 原始图像的宽度和高度
int w = img_w;
int h = img_h;
// 缩放因子初始化为1
float scale = 1.f;
// 如果宽度大于高度,按宽度缩放
if (w > h)
{
scale = (float)target_size / w; // 计算宽度的缩放因子
w = target_size; // 将宽度调整为目标大小
h = h * scale; // 按缩放因子调整高度
}
else // 如果高度大于宽度,按高度缩放
{
scale = (float)target_size / h; // 计算高度的缩放因子
h = target_size; // 将高度调整为目标大小
w = w * scale; // 按缩放因子调整宽度
}
// 将输入图像从BGR格式转换为RGB格式并调整尺寸
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, img_w, img_h, w, h);
// yolov5/utils/datasets.py letterbox
// 计算需要填充的宽度和高度,以使其变为目标尺寸的倍数
int wpad = (w + max_stride - 1) / max_stride * max_stride - w; // 计算需要填充的宽度
int hpad = (h + max_stride - 1) / max_stride * max_stride - h; // 计算需要填充的高度
// 使用常数114进行边框填充
// 上下填充:hpad / 2 (上) 和 hpad - hpad / 2 (下)
// 左右填充:wpad / 2 (左) 和 wpad - wpad / 2 (右)
ncnn::Mat in_pad; // 创建填充后的图像
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
// 归一化
const float norm_vals[3] = {1 / 255.f, 1 / 255.f, 1 / 255.f};
in_pad.substract_mean_normalize(0, norm_vals);
// 创建模型提取器
ncnn::Extractor ex = yolov5.create_extractor();
// 输入图像数据
ex.input("in0", in_pad);
// 存储三个检测头的目标候选框
std::vector<Object> proposals;
// anchor setting from yolov5/models/yolov5s.yaml
// 使用不同的 stride 生成候选框
// stride 8
{
ncnn::Mat out;
ex.extract("out0", out);
ncnn::Mat anchors(6);
anchors[0] = 10.f;
anchors[1] = 13.f;
anchors[2] = 16.f;
anchors[3] = 30.f;
anchors[4] = 33.f;
anchors[5] = 23.f;
std::vector<Object> objects8;
generate_proposals(anchors, 8, in_pad, out, prob_threshold, objects8);
// 将objects8中的所有目标对象添加到proposals中
proposals.insert(proposals.end(), objects8.begin(), objects8.end());
}
// stride 16
{
ncnn::Mat out;
ex.extract("out1", out);
ncnn::Mat anchors(6);
anchors[0] = 30.f;
anchors[1] = 61.f;
anchors[2] = 62.f;
anchors[3] = 45.f;
anchors[4] = 59.f;
anchors[5] = 119.f;
std::vector<Object> objects16;
generate_proposals(anchors, 16, in_pad, out, prob_threshold, objects16);
proposals.insert(proposals.end(), objects16.begin(), objects16.end());
}
// stride 32
{
ncnn::Mat out;
ex.extract("out2", out);
ncnn::Mat anchors(6);
anchors[0] = 116.f;
anchors[1] = 90.f;
anchors[2] = 156.f;
anchors[3] = 198.f;
anchors[4] = 373.f;
anchors[5] = 326.f;
std::vector<Object> objects32;
generate_proposals(anchors, 32, in_pad, out, prob_threshold, objects32);
proposals.insert(proposals.end(), objects32.begin(), objects32.end());
}
// 根据得分从高到低排序候选框
qsort_descent_inplace(proposals);
// 对候选框进行非极大值抑制
std::vector<int> picked;
nms_sorted_bboxes(proposals, picked, nms_threshold);
int count = picked.size();
// 调整候选框到原始图像中的位置
objects.resize(count);
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]]; // 将非极大值抑制后保留下来的候选框复制到 objects 向量中
// adjust offset to original unpadded
// 计算原始图像中的坐标,将填充后的坐标转换回原始图像坐标
float x0 = (objects[i].rect.x - (wpad / 2)) / scale; // 左上角
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale; // 右下角
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
// 边界检查
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
return 0;
}
/**
* @brief 绘制检测到的目标
*
* @param bgr 原始的图像数据,用于在其上绘制检测到的目标
* @param objects 检测到的最终目标集合
*/
static void draw_objects(const cv::Mat& bgr, const std::vector<Object>& objects)
{
// 分类标签
static const char* class_names[] = {
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush"
};
// 克隆输入图像,以避免直接修改原图像
cv::Mat image = bgr.clone();
// 遍历所有检测到的目标
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
// 打印目标的信息(类别、置信度和位置
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.prob,
obj.rect.x, obj.rect.y, obj.rect.width, obj.rect.height);
// 在图像上绘制目标的边界框
cv::rectangle(image, obj.rect, cv::Scalar(0, 255, 0),2);
// 准备显示的文本:类别名称和置信度
char text[256];
sprintf(text, "%s %.1f%%", class_names[obj.label], obj.prob * 100);
// 计算文本的大小和基线
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > image.cols)
x = image.cols - label_size.width;
// 在目标的边界框上方绘制背景矩形
cv::rectangle(image, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
// 在背景矩形上绘制文本
cv::putText(image, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
cv::imshow("image", image);
cv::waitKey(0);
}
int main(int argc, char** argv)
{
if (argc != 2)
{
fprintf(stderr, "Usage: %s [imagepath]\n", argv[0]);
return -1;
}
const char* imagepath = argv[1];
cv::Mat m = cv::imread(imagepath, 1);
if (m.empty())
{
fprintf(stderr, "cv::imread %s failed\n", imagepath);
return -1;
}
std::vector<Object> objects;
detect_yolov5(m, objects);
draw_objects(m, objects);
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











