






、### 功能及代码结构
该部分代码实现词法分析功能,识别源代码中的合法词素(略过空格、注释等),生成词法单元序列(包括Token-Name和attribute),词法单元序列作为语法分析器的输入。该部分还可以对部分词法错误进行汇报。
仓库:编译器前端代码
文件目录
- Token.h 词素结构头文件
- Token.cpp 词素结构源文件
- lexer.h lexer.cpp 词法分析模块
- sourceCode 测试代码
- sourceCode0.txt 词法单元定义源代码
- sourceCode1.txt 分支语句
- sourceCode2.txt 表达式语句
- sourceCode3.txt while循环
- sourceCode4.txt 符合语句(if while嵌套)
- sourceCode5.txt 错误情况测试
- out
- TokenX.txt 对于sourceCodeX的词法单元序列
1 合法词素定义
- ①算术运算符:’+’ ‘-’ ‘*’ ‘/’
- ②比较运算符: ‘<=’ ‘<’ ‘>=’ ‘>’ ‘==’
- ③逻辑运算符:’&&’ ‘||’
- ④逗号运算符(连接多个表达式):’,’
- ⑤标识符:以字母开头的字母数字串
- ⑥字符: 所有的ASCII码,用两个单引号包括,可以像C一样直接用字符输入,也可以使用转义符。可见博客 C语言字符常量
- ⑦整型: integer = [0-9]+
- ⑧关键字:keyword = ‘while’|’if’|’else’|’int’|’char’ ;
- ⑨特殊字符:’{‘ ‘}’ ‘(‘ ‘)’ ‘;’
对于绝大多数的词素单元可以用ASCII码进行表示,由于在C++中char类型与int类型是兼容的,所以所有的由单个符号组成的词素直接用ASCII码对应的编码表示,这些符号包括了上文中提及的①、④、⑨以及字符串终结符’\0’。
对于由多个符号组成的词素无法直接用ASCII编码表示,为了延续表示的一致性,这里参考了《编译原理》附录A中的方法:用一个枚举类型代替了Tag类,下标从257开始(避开ASCII码范围),用以标识多个字符组成的词素。具体内容可见Token.h第10行,需要注意的是:INTEGER和CHARACTER表示整型和字符型的常量,而INT和CHAR为表示这两种类型的关键字。
2 词法单元表示
词法单元需要记录其名称和属性信息,并由一定的结构关系,此处采用类的结构表示,类间关系如下图所示。
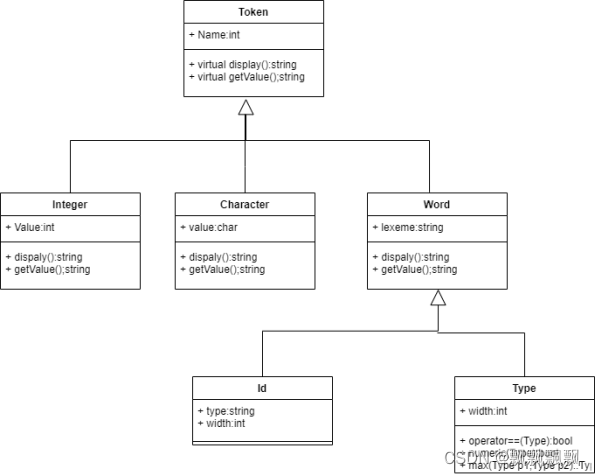
Token类是所有单元的父类,其Name属性表示了词法单元的类型;Interger和Character类型需要保存值属性;Word记录了关键字与标识符,需要保存其名称。由于最终实现时并没有实现符号表和存储分配,所以实际上没有用到Id类和Type类,这两个类与赋值语句和表达式中的类型判断有关。
这里其实有一个问题,就是虽然每个词法单元已经用整型表示其类型了,但由于文法处理模块和语法分析模块均使用的字符串表示(如”if”,”while”),所以在真正使用时需要调用一个转换函数再将int转为对应的文法符号名称。
最终词法单元序列用一个Token类的指针列表记录,这样做的目的是为了通过虚函数重载获取不同类型的词法单元的属性值。
Token.h
#pragma once
#include<iostream>
#include<string>
#include<list>
#include<unordered_map>
using namespace std;
// 注意小括号、大括号以及单字符运算符不需要加入enum 因为ASCII对其有定义
// INTEGER表示整型常量 CHARACTER为字符常量 CHAR和INT为类型关键字
enum Tag { INTEGER = 257, CHAR, ID, IF, ELSE, DO, WHILE, AND, OR, EQ, GE, LE, NEQ, INT, CHARACTER};
//这四个类用于管理不同的词法单元
class Token
{
public:
int Name; //词法单元表示,从枚举Tag获取值
Token(int t);
Token() ;
//重载toString输出信息
virtual string display();
virtual string getValue();
};
//整型常量
class Integer :public Token
{
public:
int value;
Integer(int value);
string display();
string getValue();
};
//字符常量
class Character :public Token
{
public:
char value;
Character(char value);
string display();
string getValue();
};
//保留字:变量类型TYPE应当为Word的子类,应为TYPE都是保留字
class Word :public Token
{
public:
// 词法单元名称
string lexeme = "";
Word(string s, int tag);
Word();
string display();
string getValue();
};
//标识符类没有用到
class Id :Word
{
public:
string type;
int width;
Id() :Word()
{}
Id(string le) :Word(le, Tag::ID)
{
lexeme = le;
}
};
//用于记录标识符环境没有用到
class Env
{
public:
unordered_map<string, class Id> Table;
Env* parent = NULL;
Env()
{
parent = NULL;
}
Env(Env& v)
{
parent = &v;
}
bool put(string key, Id i)
{
if (Table.find(key) == Table.end())
{
Table[key] = i;
}
else
{
return false;
}
}
Id* find(string key)
{
for (Env* e = this; e != NULL; e = e->parent)
{
if (e->Table.find(key) != Table.end())
{
Id* f = &e->Table.at(key);
return f;
}
else
{
return NULL;
}
}
}
};
//基本数据类型:int 和 char,不做存储分配和数组访问 不需要知道大小,也没有使用
class Type :public Word
{
public:
int width = 0;
Type(string s, int tag, int w) :Word(s, tag)
{
this->width = w;
}
bool operator==(const Type t)
{
return(width == t.width && Name == t.Name && lexeme == t.lexeme);
}
//类型转换
static bool numeric(Type p)
{
Type Int = Type("int", INT, 4);
Type Char = Type("char", CHAR, 1);
if (p == Int || p == Char)
return true;
else
return false;
}
static Type max(Type p1, Type p2)
{
if (!numeric(p1) || !numeric(p2)) return Type("error",0, 4);
else if (p1.Name == INT || p2.Name == CHAR)
return Type("int", INT, 4);
else
return Type("char", CHAR, 1);
}
};
//使name能和其他部分匹配,转为字符串
string convertName(int name);
Token.cpp
#include"Token.h"
//定义了各种词法单元
using namespace std;
Token::Token(int t)
{
Name = t;
}
Token::Token() {}
string Token::display()
{
string a = "a";
if (Name != 0)
a[0] = char(Name);
else
a = "!EOF!";
return "<TokenName=" + a + "," + "value=Null>";
}
string Token::getValue(){
string a = "a";
if (Name != 0)
a[0] = char(Name);
else
a = "!EOF!";
return a;
};
Integer::Integer(int value):Token(Tag::INTEGER)
{
this->value = value;
}
string Integer::display()
{
return "<TokenName=INTEGER,value=" + getValue() + ">";
}
string Integer::getValue()
{return to_string(value);
}
Character::Character(char value) :Token(Tag::CHARACTER)
{
this->value = value;
}
string Character::display()
{
return "<TokenName=CHARACTER,value=" + getValue() + ">";
}
string Character::getValue()
{
string a = "a";
a[0] = value;
return "'" + a + "'";
}
Word::Word(string s, int tag) :Token(tag)
{
this->lexeme = s;
}
Word::Word() {}
string Word::display()
{
string TokenName = "";
switch (Name)
{
case 257:TokenName = "INTEGER"; break;
case 258:TokenName = "CHAR"; break;
case 259:TokenName = "ID"; break;
case 260:TokenName = "IF"; break;
case 261:TokenName = "ELSE"; break;
case 262:TokenName = "DO"; break;
case 263:TokenName = "WHILE"; break;
case 264:TokenName = "AND"; break;
case 265:TokenName = "OR"; break;
case 266:TokenName = "EQ"; break;
case 267:TokenName = "GE"; break;
case 268:TokenName = "LE"; break;
case 269:TokenName = "NEQ"; break;
case 270:TokenName = "INT"; break;
case 271:TokenName = "CHARACTER"; break;
}
return "<TokenName=" + TokenName + "," + "value=" + lexeme + ">";
}
string Word::getValue()
{
return lexeme;
}
//转换函数,将enum下标转化为字符串
string convertName(int name)
{
if (name == 0)
{
return "!EOF!";
}
else if (name <= 256)
{
string a = "0";
a[0] = char(name);
return a;
}
else
{
string result;
switch (name)
{
case 257:result = "integer"; break;
case 258:result = "char"; break;
case 259:result = "ID"; break;
case 260:result = "if"; break;
case 261:result = "else"; break;
case 262:result = "do"; break;
case 263:result = "while"; break;
case 264:result = "&&"; break;
case 265:result = "||"; break;
case 266:result = "=="; break;
case 267:result = ">="; break;
case 268:result = "<="; break;
case 269:result = "!="; break;
case 270:result = "int"; break;
case 271:result = "character"; break;
}
return result;
}
}
3 词法单元的生成
源程序中的Lexer类负责:从文件中读入字符流,识别有意义的词素并生成词法单元序列,涉及文件lexer.h和lexer.cpp。lexer类的结果与识别算法参考了《编译原理》的附录A.3,总体思路近似,但增添了对于字符常量的识别。具体的数据结构和实现函数可以查看源文件,这里只描述关键部分。除了识别2.1中的合法词素外,词法分析器还要有略过空格符、制表符、换行符、注释的功能。词法分析器的DFA如下图所示。
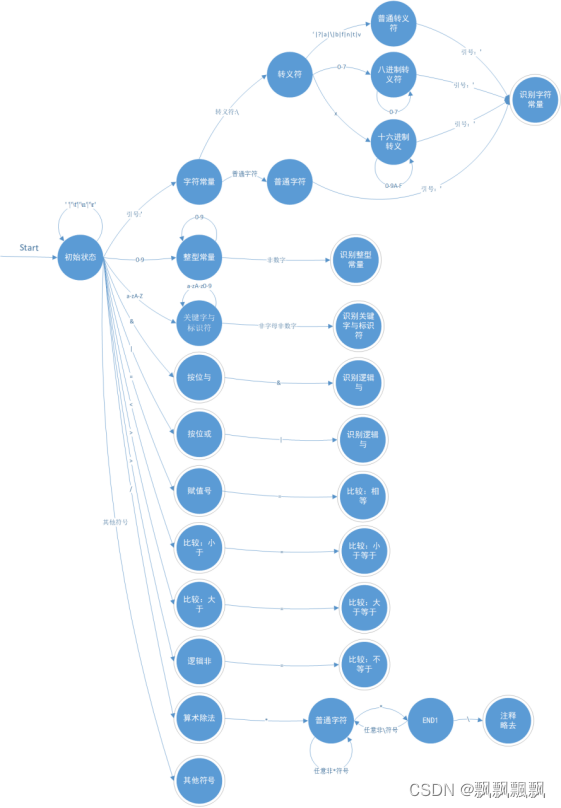
词法分析单元并没有实现双缓存结构,而是直接将文件所有内容一次读入到input字符串中,在识别过程中用peek存放下一个输入字符,用index存放其下标。函数readch()用以读入下一个字符,并有重载readch(char c)可以读入下一个字符并进行判断。该类的关键模块是sacn()函数,作用是从输入中获得下一个词法单元(Token类的指针)。词法分析器是根据DFA构建的,本词法分析器的有穷状态机如图2.2所示。主要困难点在于字符常量的识别,因为字符串常量有以下要求:有匹配的单引号,可以使用转义符且使用转义符时长度会发生改变,使用十进制或八进制转义符时不能超过ASCII码编码最大值。
为了实现字符识别,查阅了C语言的标准字符表示(C语言核心技术第二版),主要参考了其中关于转义符(如下图所示)的部分,如图2.3所示。最终实现时没有考虑通用字符转义的情况。

lexer.h
#pragma once
#include<iostream>
#include<cstdio>
#include<fstream>
#include<string>
#include<unordered_map>
#include<list>
#include<fstream>
#include<vector>
#include<ctype.h>
#include "Token.h"
/// <summary>
/// 本类进行词法分析,生成词法单元序列:Token类指针的List
/// 可以识别关键字、特殊符号、标识符、整型常量和字符型常量
/// </summary>
class Lexer
{
public:
//记录行号
int line = 1;
//存放下一个输入字符,要么为空要么指向下一个字符(为空时可以略过,自动读入下一个)
char peek = ' ';
//字符下标
int index = -1;
//词法分析是否成功的标记
bool flag = true;
string sourceCodePath = "";
string tokenOutPath = "token.txt";
string input; //文件输入内容
vector <class Token*> TokenList; //词法单元序列
unordered_map<string, Word>Words = {}; //记录已有关键字和标识符
//将所有关键字和运算符加入Word
Lexer();
//初始化peek line等变量
void init();
//填Word表
void reserve(Word w);
//读入下一个字符
void readch();
//读入下一个字符并判断
bool readch(char c);
//扫描输入,获取下一个词法单元
Token* scan();
//输出词法单元序列
void showTokenList();
//获取文件输入
void getInput();
//调用sacn函数扫描完整文件获取词法单元序列
bool scanAll();
};
lexer.cpp
#include"lexer.h"
Lexer::Lexer()
{
reserve(Word("if", Tag::IF));
reserve(Word("else", Tag::ELSE));
reserve(Word("do", Tag::DO));
reserve(Word("while", Tag::WHILE));
reserve(Word("&&", Tag::AND));
reserve(Word("||", Tag::OR));
reserve(Word("==", Tag::EQ));
reserve(Word(">=", Tag::GE));
reserve(Word("<=", Tag::LE));
reserve(Word("!=", Tag::NEQ));
reserve(Type("int", Tag::INT, 4));
reserve(Type("char", Tag::CHAR, 1));
}
void Lexer::init()
{
line = 1;
peek = ' ';
index = -1;
input = "";
TokenList.clear();
}
//填Word表
void Lexer::reserve(Word w)
{
Words.emplace(w.lexeme, w);
}
//获取文件输入
void Lexer::getInput()
{
ifstream inputFile(sourceCodePath);
input = "";
int datalen = 0;
string temp;
while (getline(inputFile, temp))
{
input += temp;
input += '\n';
}
}
//读入下一个字符
void Lexer::readch()
{
index++;
peek = input[index];
}
//读入下一个字符并判断
bool Lexer::readch(char c)
{
readch();
if (peek != c)
return false; //无需回退,识别下一个词素还停留在当前位置
peek = ' '; //设置为空,下次扫描自动度下一个字符
return true;
}
//扫描输入,返回下一个词法单元
Token* Lexer::scan()
{
//略过空白符和注释,先进循环再读,所以每次应指向待识别部分第一个字符
for (;; readch())
{
if (peek == ' ' || peek == '\t' || peek == '\r')continue;
else if (peek == '\n') line = line + 1;
else if (peek == '/') //略过注释
{
if (readch('*'))
{
while (1)
{
readch();
if (peek == '*')
{
readch();
if (peek == '/')
{
break;
}
}
}
}
//应该为除号
else
{
index -= 2;
readch();
break;
}
}
else break;
}
//整型
if (isdigit(peek))
{
int v = 0;
do
{
v = 10 * v + peek - '0';
readch();
} while (isdigit(peek));
Integer* t = new Integer(v);
return t;
}
//标识符与关键字
if (isalpha(peek))
{
string s = "";
do
{
s = s + peek;
readch();
} while (isalpha(peek)||isdigit(peek));
//检查表项中是否有该关键字
if (Words.find(s) != Words.end())
{
return &Words.at(s);
}
else //必然不是标识符
{
Word* w = new Word(s, Tag::ID);
reserve(*w);
return w;
}
}
//字符常量: 'x',其中只允许出现一个字符,注意考虑转义符的情况 \" \'等
if (peek == '\'')
{
char c;
readch();
// 非转义符
if (peek != '\\' and peek != '\'')
{
c = peek;
readch();
}
else if (peek == '\'')
{
printf("line:%d,带引号的字符至少包含一个符号", line);
readch();
}
else //转义符识别
{
//当前状态: 识别了一个 反斜杠
//读入下一个字符
readch();
//数字,读入1、2、3位八进制字符
if (isdigit(peek))
{
int tempX = 0;
do
{
if (peek - '0' > 7)
{
cout << peek << "非八进制符号,line:" << line << endl;
return NULL;
}
tempX = tempX * 8 + peek - '0';
readch();
} while (isdigit(peek));
// 应当回退一个
if (tempX > 255)
{
cout << tempX << "对字符类型太大,line:" << line << endl;
return NULL;
}
else
c = char(tempX);
}
else if (peek == 'x')// \xh \xhh 形式
{
readch();
int tempX = 0;
do
{
if (isdigit(peek))
tempX = tempX * 16 + peek - '0';
else
tempX = tempX * 16 + peek - 'A' + 10;
readch();
} while (isdigit(peek) || peek >= 'A' && peek <= 'F');
if (tempX > 255)
{
cout << tempX << "对字符类型太大,line:" << line << endl;
return NULL;
}
else
c = char(tempX);
}
else
{
//后续定义了defalut 所以先进行数字的识别
switch (peek)
{
case '\'':
c = '\'';
break;
case '\"':
c = '\"';
break;
case '\?':
c = '\?';
break;
case '\\':
c = '\\';
break;
case 'a':
c = '\a';
break;
case 'b':
c = '\b';
break;
case 'f':
c = '\f';
break;
case 'n':
c = '\n';
break;
case 'r':
c = '\r';
break;
case 't':
c = '\t';
break;
case 'v':
c = '\v';
break;
default: //对于未定义的转义符,忽略转义符
c = peek;
break;
}
readch();
}
}
// 所有的情况都必须再读入一个单引号才能进行
if (peek == '\'')
{
readch();//在识别下一个词素之前应当前进
Character* t = new Character(c);
return t;
}
else
{
cout << "缺失单引号或引号内有多个字符,line:" << line << endl;
return NULL;
}
}
Token* t = NULL;
//其他情况
switch (peek)
{
case '&':
if (readch('&')) return &Words.at("&&"); //逻辑与符号
else // 按位与
{
t = new Token('&');
return t;
}
case '|':
if (readch('|')) return &Words.at("||"); //逻辑或
else //按位或
{
t = new Token('|');
return t;
}
case '=':
if (readch('=')) return &Words.at("=="); //比较运算:EQ
else //赋值号
{
t = new Token('=');
return t;
}
case '<':
if (readch('=')) return &Words.at("<="); //比较:LEQ
else //比较:L
{
t = new Token('<');
return t;
}
case '>':
if (readch('=')) return &Words.at(">="); //比较:GEQ
else //比较:G
{
t = new Token('>');
return t;
}
case '!':
if (readch('=')) return &Words.at("!="); //比较:NEQ
else //取反
{
t = new Token('!');
return t;
}
//其他单目符号
case '\0':
t = new Token(peek);
return t;
default:
t = new Token(peek);
readch();
return t;
}
}
//扫描所有词法单元
bool Lexer::scanAll()
{
bool flag = true;
//写的lexer.scan() 实际上是每次获得一个词法单元
while (flag)
{
Token* temp = scan();
if (temp != NULL)
TokenList.push_back(temp);
else
{
cout << "词法分析失败,错误位置line:"<<line << endl;
return false;
}
if (temp->Name == 0) //获取到了文件结束符
flag = false;
}
return true;
}
//显示词法单元序列
void Lexer::showTokenList()
{
ofstream outFile(tokenOutPath);
for (auto t : TokenList)
{
if (t != NULL)
{
string out = t->display();
if (t->Name == ';')
out += "\n";
cout << out;
outFile << out;
}
else
{
cout << "<未识别词素>";
outFile << "未识别词素";
}
}
cout << endl;
}
4 其他问题
4.1 关键字与标识符的记录
为词法分析单元添加一个成员,Words表,类型为unordered_map<string,Word>,在初始化中将所有的关键字添加进去,识别到标识符应当先检查Words表中是否已有该标识符,若有则返回原标识符信息,若没有则再返回词法单元前需要将新的标识符添加到Words表中。这样可以方便符号表的构建,但最终没有起到作用。
4.2 错误的发现与报告
为了能够定位错误,增添了一个line记录当前所在行号,词法分析器每次扫描到换行符就使line加1。在scan()过程中,大多数词法单元的识别在遇到错误时会直接返回NULL,导致分析失败,这时只会报告错误位置不会报告具体的错误原因。
字符类型的识别实现了错误的详细报告,具体的错误类型有以下几种:①连续两个单引号,提示行号与“带引号的字符至少包含一个符号” ②八进制转义符状态(见图2.2)识别到非八进制字符,提示错误 ③八进制和十六进制转义符识别到过大的数字 ④字符读取结束后,在读取到单引号之前出现了其他字符,报告“确实单引号或单引号有多个字符”与错误行号。当然这些错误情况还不够完备,还有很多完善的空间。
4.3 词法单元属性值的获取问题
为了能用统一的数据结构表示词法单元序列,使用Token类型的指针列表进行存储,因为只有父类指针指向子类对象才能实现子类对父类函数的重载,这样可以再Token类定义虚函数getValue,由各个类型的词法单元实现该虚函数返回其属性值。
这涉及到一个问题,子类对父类函数的重载要求有相同的参数类型、函数名、返回值类型,但显然Word类型、整型常量、字符常量具有不同的属性值。最终解决办法是全都返回String类型,在需要时进行解析。通过查阅资料,发现可以使用union结构或 std::variant(C++17标注),可以尝试用这两个方式进行改进。
4.4 负整数问题
在词法分析器设计时并未考虑到负整数的情况,但最终可以通过语法分析和语义分析解决。在文法中定义了unaryExp表示单目运算的情况,其中包括产生式unaryExp -> ‘-’primaryExp,其中primaryExp可以是整型常量,这样就实现了负整数的表示问题,即负整数是通过计算获得的,而词法分析器只是获得了一个无符号数字串。















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









