






网络作为生成器
将x(可以是文字)以及一个简单的分布作为输入,生成一个y(可以是图片),随着z的输入不同,y的输出不同。这是一个输出分布的network。
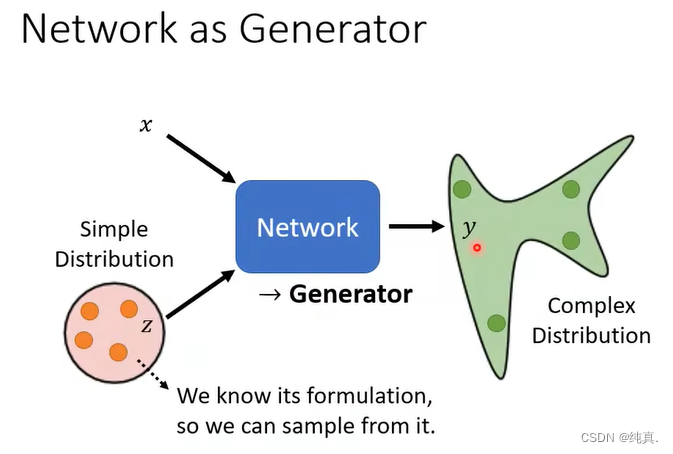
那么我们为什么输出一个分布呢?这是因为我们希望我们的输出更具有“创造性”,也就是说我们希望输出不固定的东西,比如在数据集中没有的东西。

我们的输入是一个低维的向量,而输出是一个高维的向量。因此实际上是一个低纬的分布到高维的分布的一个映射。
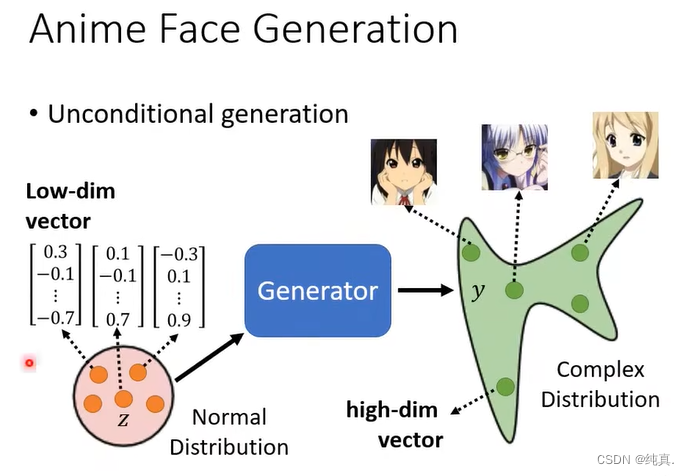
图像生成
生成器
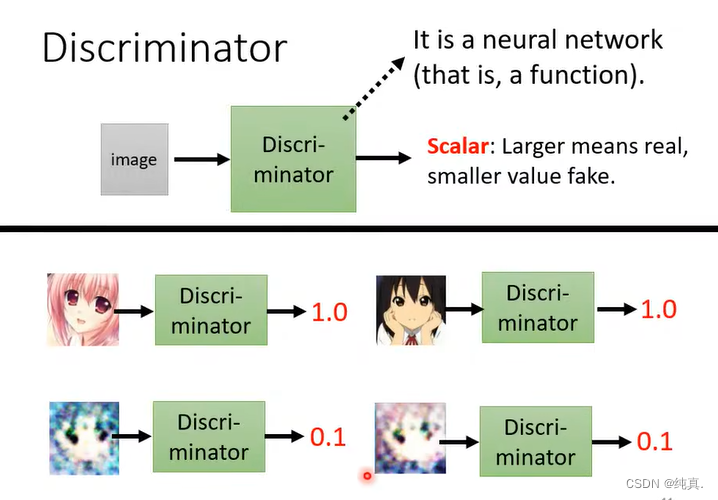
判别器
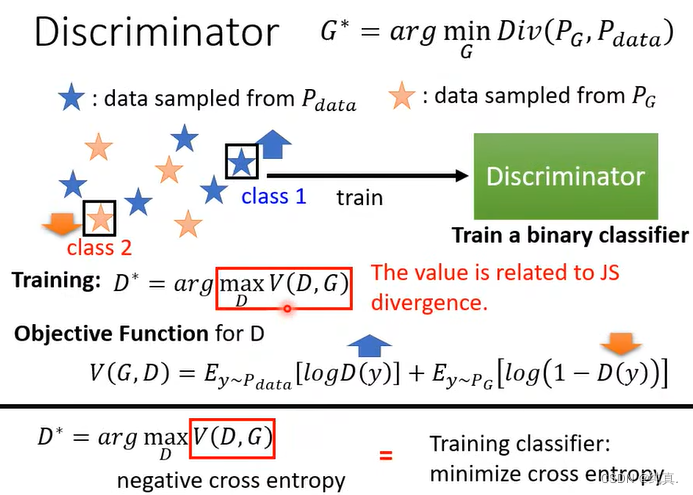
判别器的输出是一个分数,越真实的图片给出的分数越高。他是一个CNN的架构。
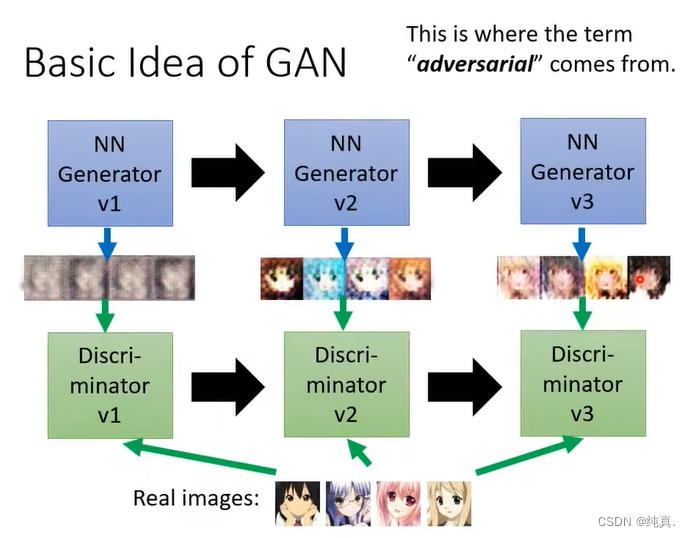
GAN
GAN基础的概念
主要是基于一种对抗的思想,生成器需要将自己生成的图片骗过判别器,而判别器需要能够不断地识别生成器生成的伪造的图片。
算法描述
首先需要初始化生成器以及判别器,第一步是定住生成器G,更新判别器D。通过高斯分布,生成一堆vector,随后利用G生成图片p1。而后在数据集中采样几组图片p2,利用p1和p2训练D分别p1和p2,其实就是把p2标为1,p1标为0,这就变成了一个分类的问题或者回归的问题。
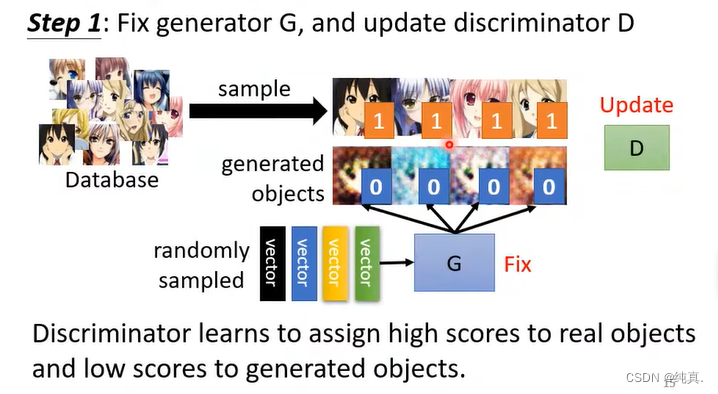 第二步与第一步相反,定住D来更新G,就是让G生成的图片欺骗D。实际的操作是,将G与D相连,吃一个向量作为向量,以一个分数作为输出,我们希望让输出越大越好。再细节一点说,将网络相连后,固定D的参数,只更新G的参数,而后通过梯度上升的方法让输出越大越好。
第二步与第一步相反,定住D来更新G,就是让G生成的图片欺骗D。实际的操作是,将G与D相连,吃一个向量作为向量,以一个分数作为输出,我们希望让输出越大越好。再细节一点说,将网络相连后,固定D的参数,只更新G的参数,而后通过梯度上升的方法让输出越大越好。
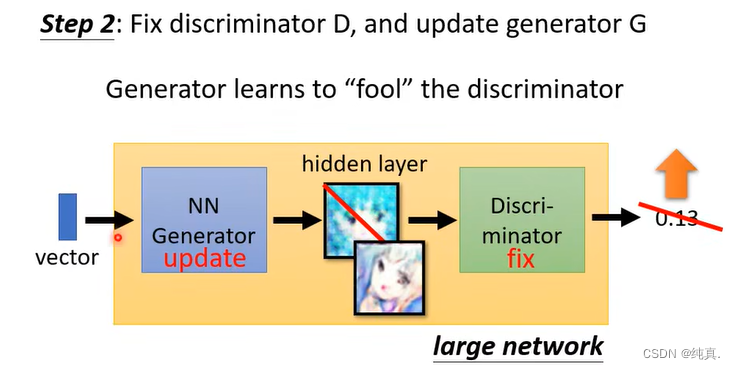
剩下的步骤就是重复1、2步。
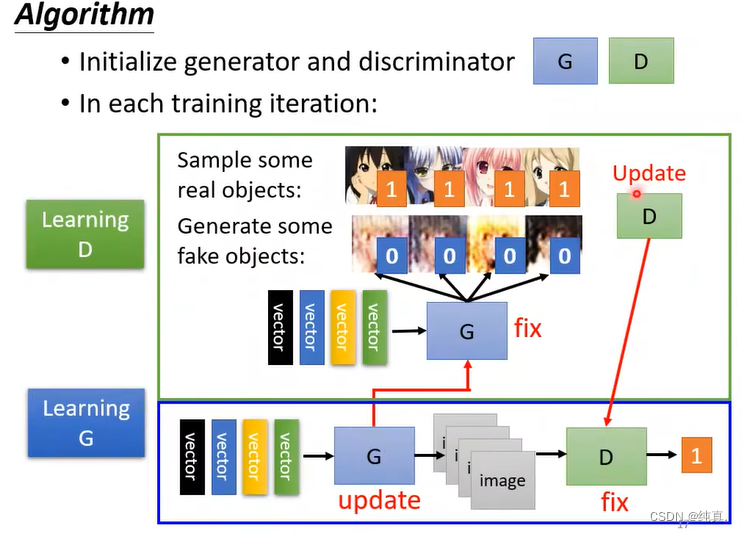
GAN背后的原理
我们的目标
生成器G
与VAE、Diffusion model类似,我们都是希望我们的网络生成的分布与真实的分布越像越好。因此生成器的训练目标就是希望两个分布之间相似度越大越好。
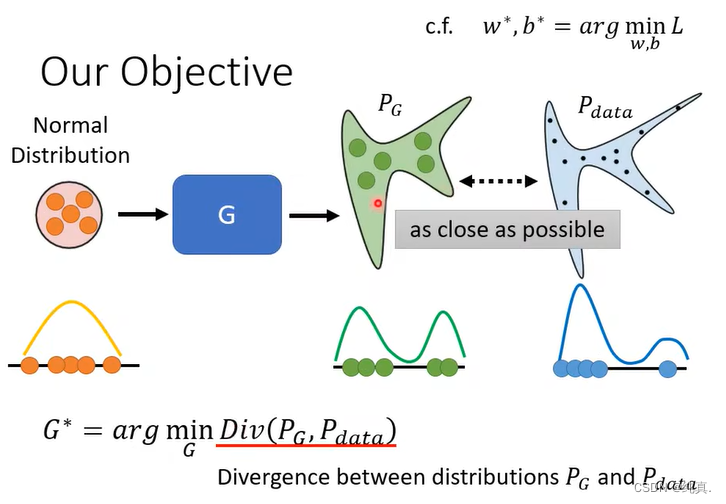
判别器D
现在我们再来看判别器的训练目标,对于分类器而言,我们想要做的就是令来自真实数据集的data得分越大越好,来自生成器G的data得分越小越好,那么我们可以借鉴交叉熵的公式对其进行描述V(G,D)。从式子中我们能够看出,对于从数据集中取样得到的y,我们希望他越大越好,而对于来自生成器G的data取样得到的y,我们希望他越小越好。
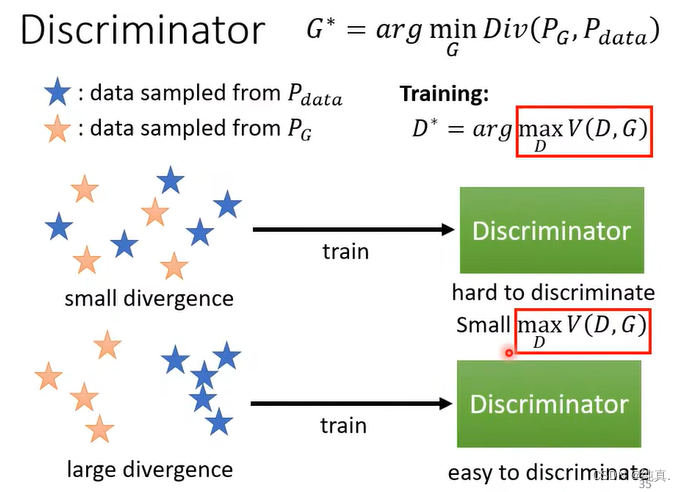
我们衡量两个分布的相似度一般是用divergence来衡量的,而argmaxV(D,G)刚好与JS divergence有关。满足我们的目标
从直观上对这个式子进行解释,如果两个分布足够像,那么他们的数据在高维中可能是混在一起的,因此判别器比较难分辨出他们,因此maxV的值就会比较小。而如果divergence比较大,那么判别器是可以很简单的区分出他们的。
训练目标
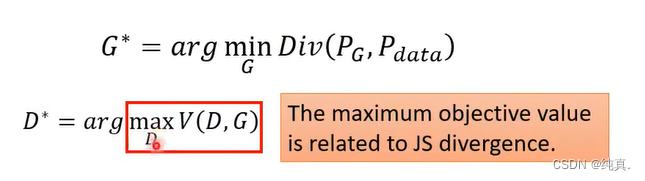
原先我们求Div是比较难的,但经过我们的分析后,我们发现D的操作与Div是有相关性的,那么我们可以对其进行一个替换。而这其实就是我们之前在训练中所提到的第一步与第二步。

训练GAN的技巧
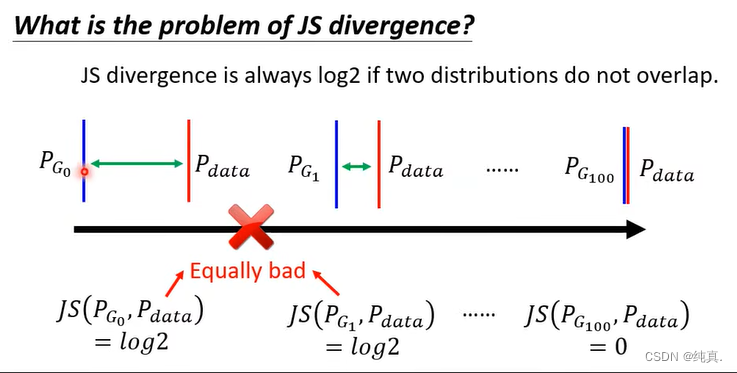
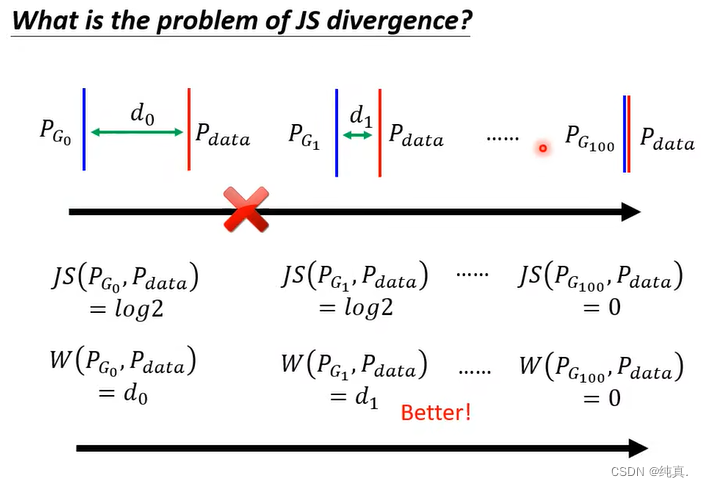
JS divergence有局限性
上面我们说的GAN用的是JS divergence,但他有局限性。这里给出了两种解释,第一种解释是P_data和P_G是高维空间在低维空间的一个mainfold,他们之间的重叠部分可能被忽略。
第二种解释是虽然也有重叠,但是如果我们取样的样本不够多那么很可能导致重叠部分被忽略。
 也就是说除非有重合才是0,这就会无法判断不重合的程度如何。
也就是说除非有重合才是0,这就会无法判断不重合的程度如何。
Wasserstein distance
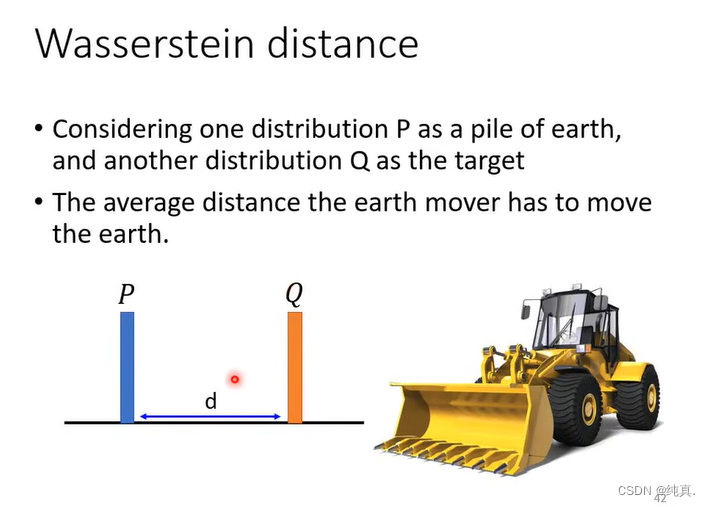
对于简单分布的wasserstein distance比较简单,但是对于复杂的情况其实是很难计算的,因为不同move方式有很多可能。根据他的定义,要遍历全部方式计算一个最好的方式。
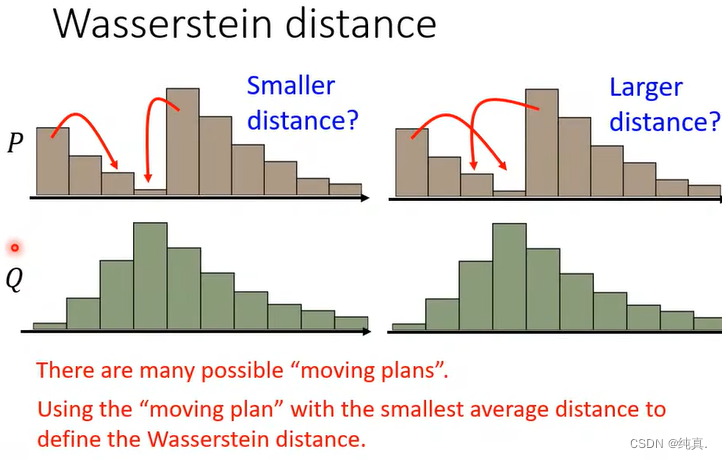
Wasserstein distance的优点
从他的定义我们能够看出,它能够解决JS divergence所不能解决的问题。
WGAN
这里直接给出如何计算Wasserstein distance,可以看出是找到一个足够平滑的作为判别函数。如果x是从真实分布中取样得到的,那么我们希望他越大越好,如果x是由生成器G生成的,那么我们希望他越小越好。那么为什么要让他足够平滑呢?具体看下图解释。

那么如何计算呢?详见下面的论文。
有条件的生成
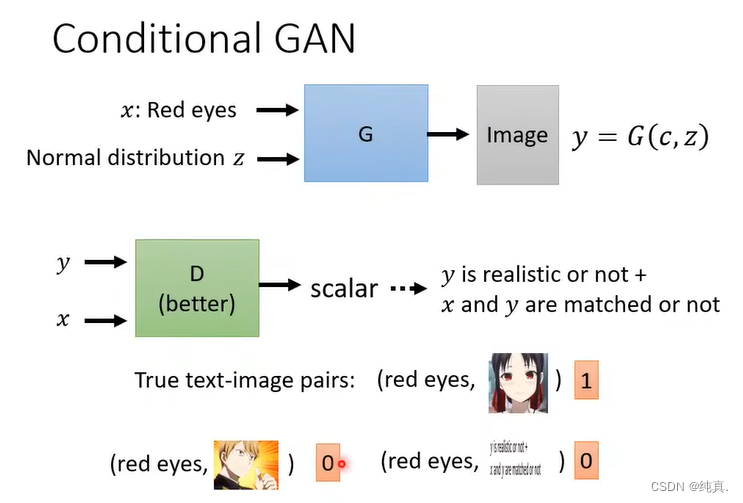
比较经典的一个任务是输入一段文字令其生成图像,这就是一个supervised learning了。
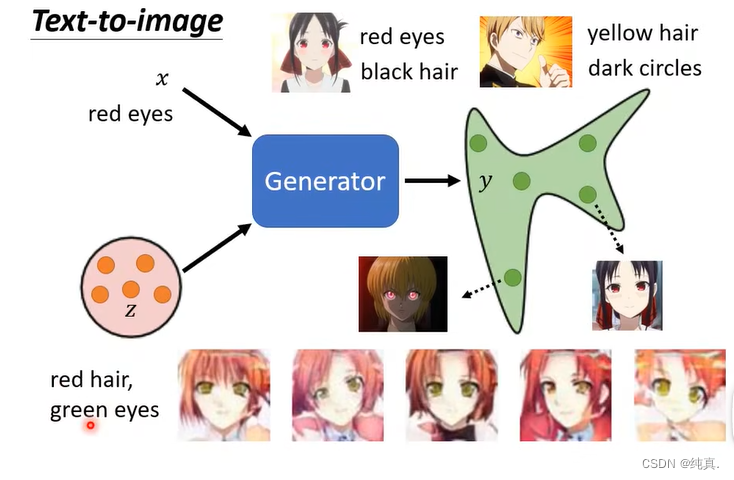 训练过程如下,其实就是要在判别器中加上我们的文字。但是这样训练得出的结果往往不太好,因此我们还需要给他一些错误示例。
训练过程如下,其实就是要在判别器中加上我们的文字。但是这样训练得出的结果往往不太好,因此我们还需要给他一些错误示例。
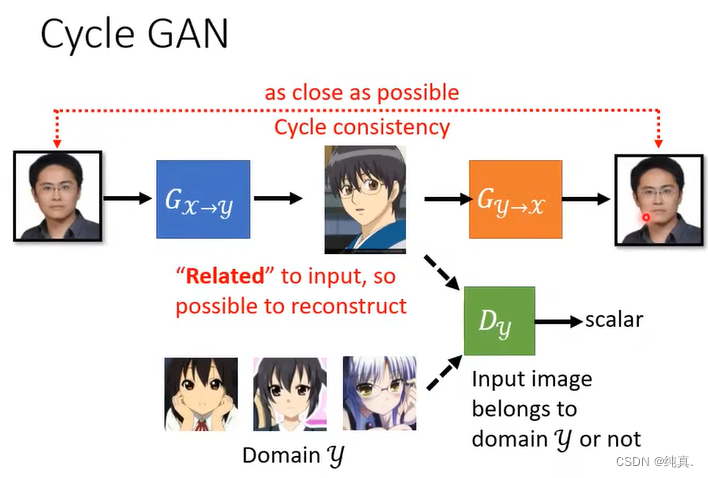
CycleGAN
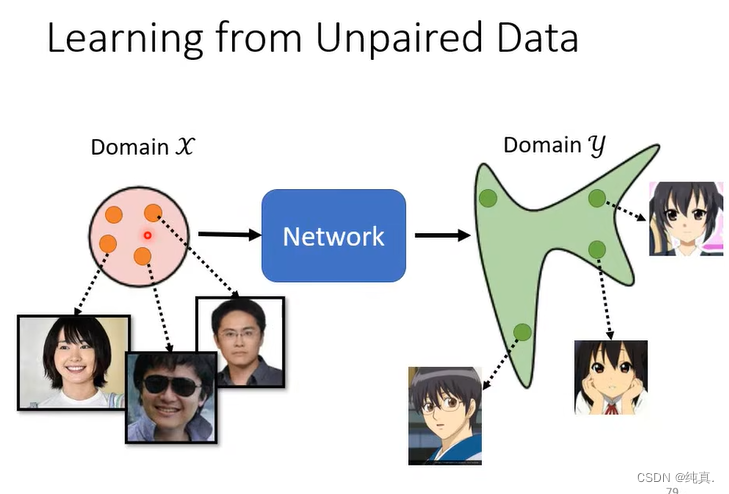
因为在训练的时候我们往往没有成对的资料,而刚才我们上面介绍的其实都是supervised learning,那么现在要介绍的CycleGAN是一种unsupervised learning的技术。对于我们的网络来说,输入是X域的分布,我们希望输出是Y域的分布。解释一下与之前的想法有什么不同,之前的想法是输入是一个正态分布,而在这里是一堆具体的数据集的分布。
其实我们在之前Cycle GAN训练的时候,第一点就是把之前的正态分布改成X域中进行取样。但是如此生成出来的图片不一定与原来的图像有很强的联系,因此我们需要借助Cycle GAN的想法。 其实就是在上面的基础上是还需要再训练一个生成器,希望第一个G生成的图片能够再恢复原先的输入。上面看起来就很像是一个编码器。
其实就是在上面的基础上是还需要再训练一个生成器,希望第一个G生成的图片能够再恢复原先的输入。上面看起来就很像是一个编码器。
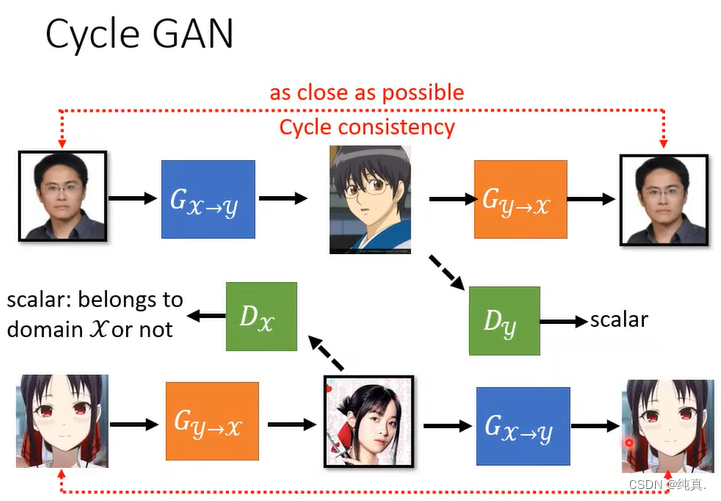
 反过来做也是一样的。
反过来做也是一样的。















 4756
4756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









