






Stable Diffusion
架构
主要分为三个模块,对于text encoder模块是输入一段文字,而后输出一串向量。第二个部分是Generation Model,这里使用的大多是DM,吃一个噪声以及文字的encoder产生一个中间产物,中间产物是一个图片被压缩后的版本。最后是套一个Decoder,把中间产物decode而后产生图片。三个模块是分别练好的,然后再组合起来的。
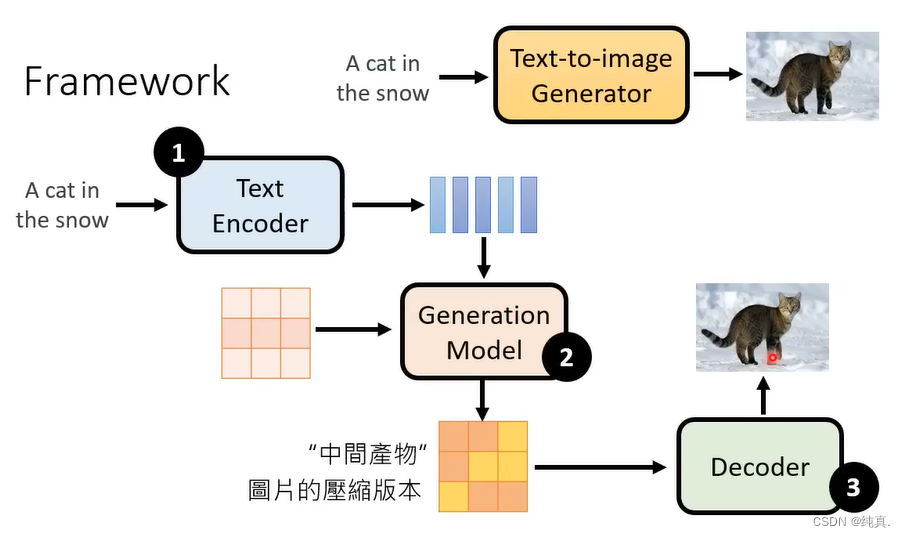
下面来看Stable Diffusion的结构图,右侧部分是一个Encoder,他的输入是一些文字或图片等,内部生成器是一个DM,左侧是一个解码器。
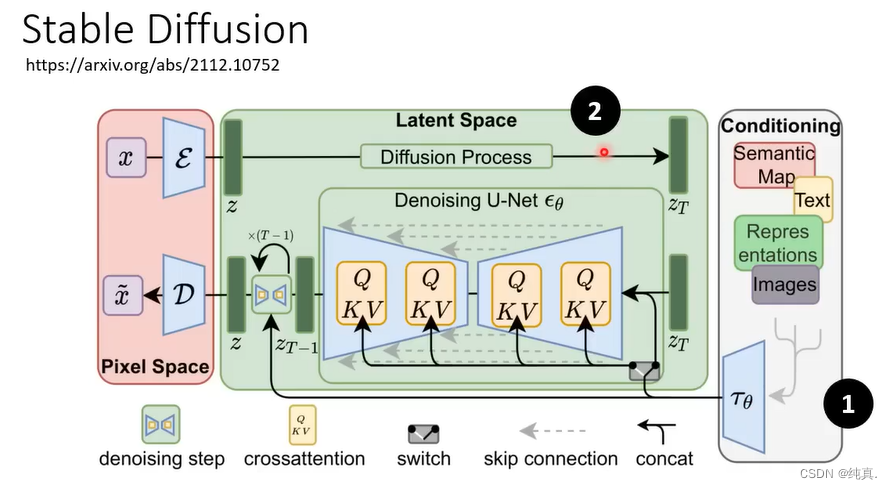 DALL-E也是一样的套路。
DALL-E也是一样的套路。
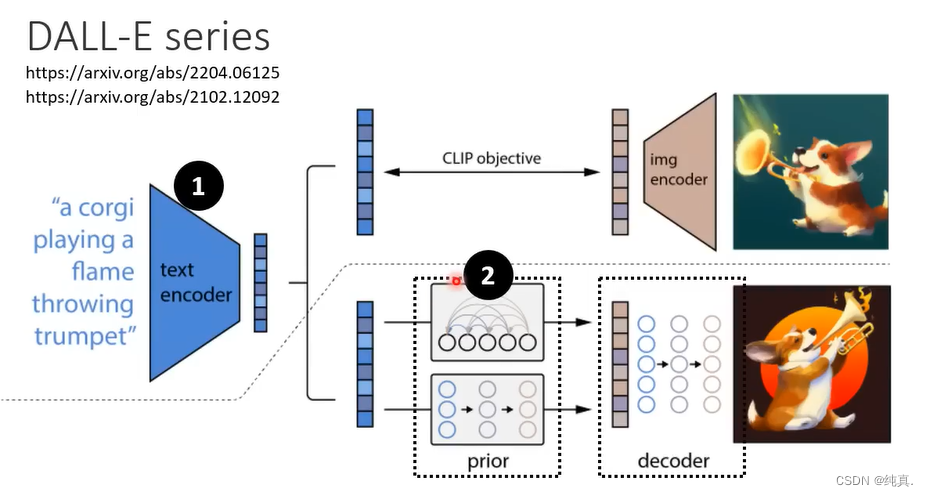
Imagen套路其实也是一样的。
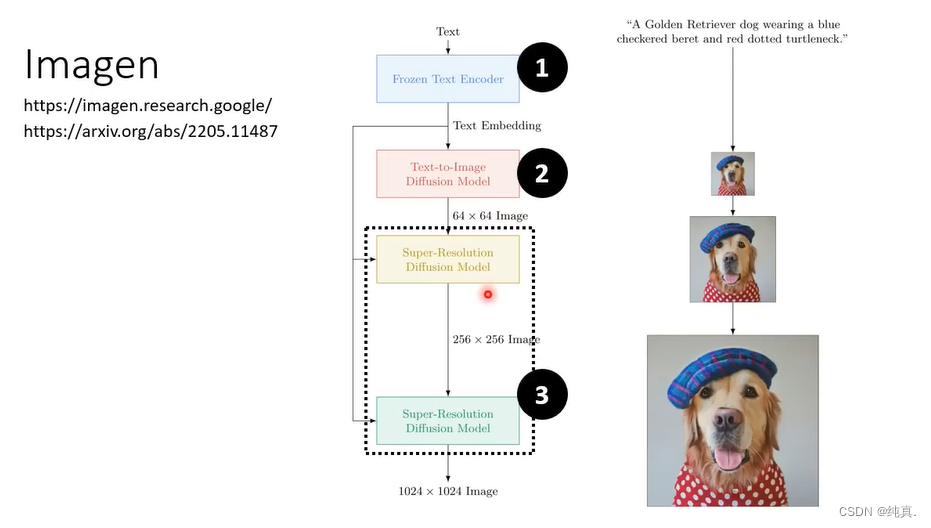
文字Encoder
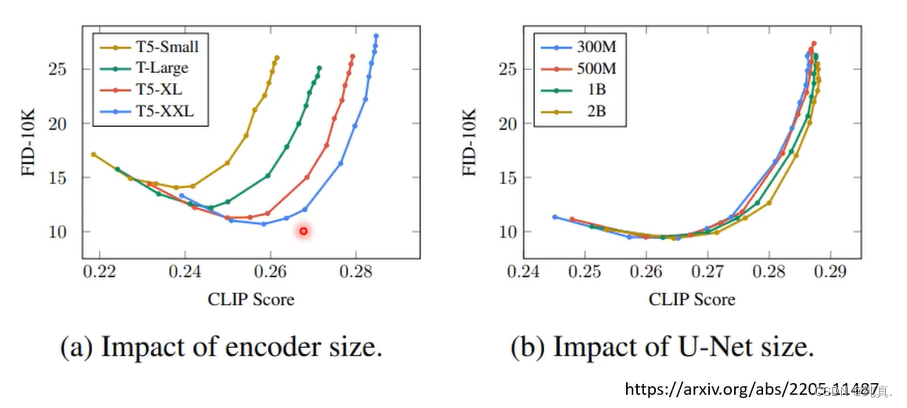
使用的技术就是GPT或者BERT,文字的Encoder对于结果影响还是比较大的。从下图可以看出,文字Encoder的大小对于结果的影响比较大,而DM的大小对于结果的影响较小。
FID
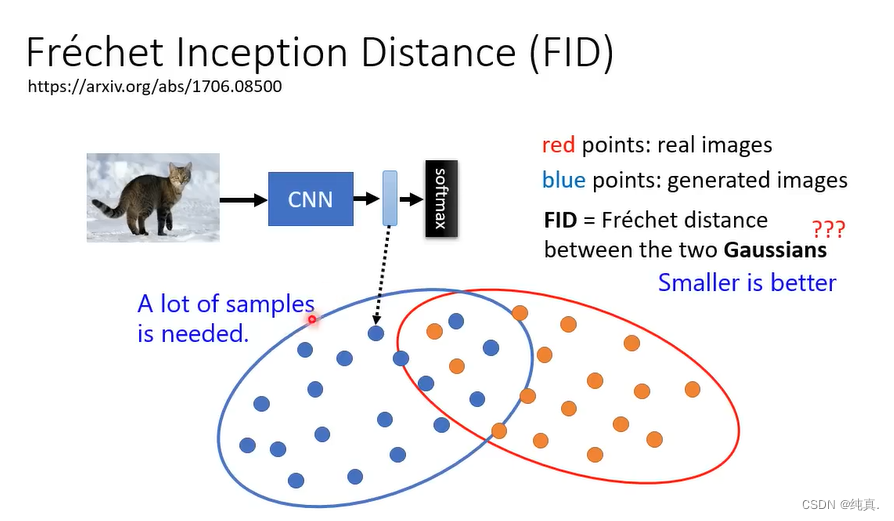
评估影像生成模型的好坏,需要一个已经训练好的CNN,比较representation的距离。
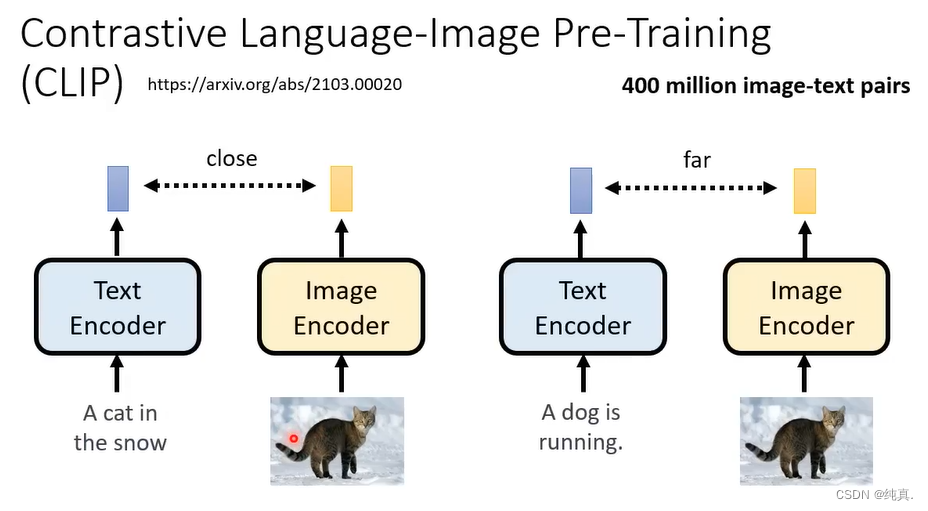
CLIP
Decoder
训练时不需要文字和影像成对的资料,只需要大量的影像的资料即可。如果中间产物是一个小图,那么就把原图压缩一下然后作为训练集。
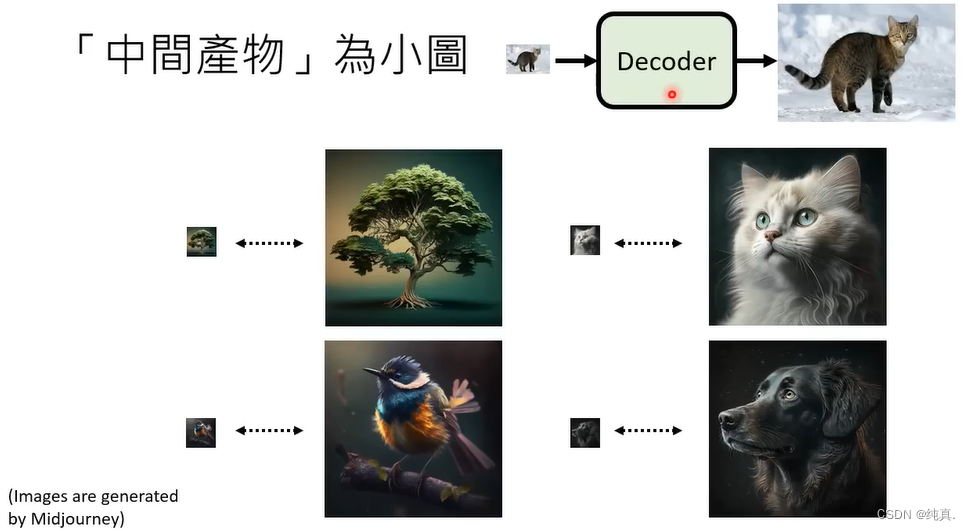
如果中间产物是Latent Representation,那就是训练一个自编码器的问题。
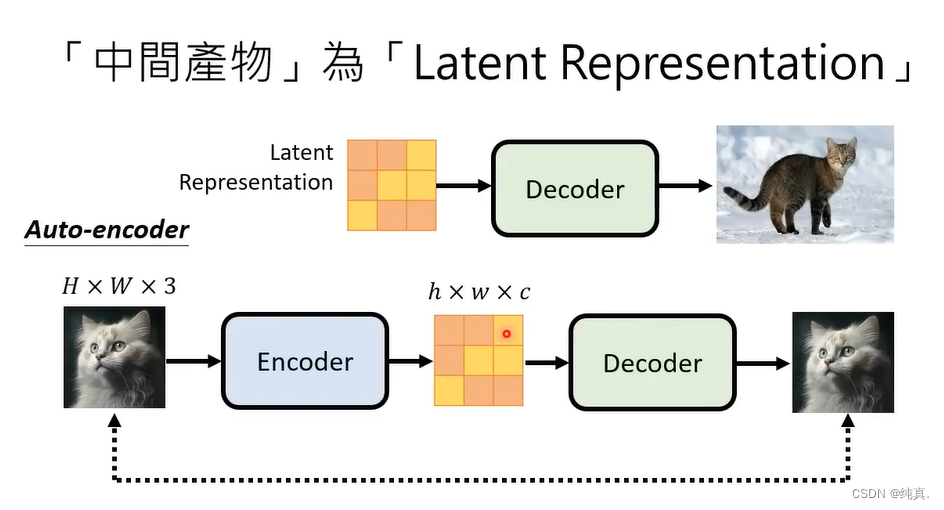
生成模型
在之前生成模型中,是把noise直接加在图片上,但是现在的输入不再是图片了而是一个Latent representation。那么现在noise要加到Latent representation上。
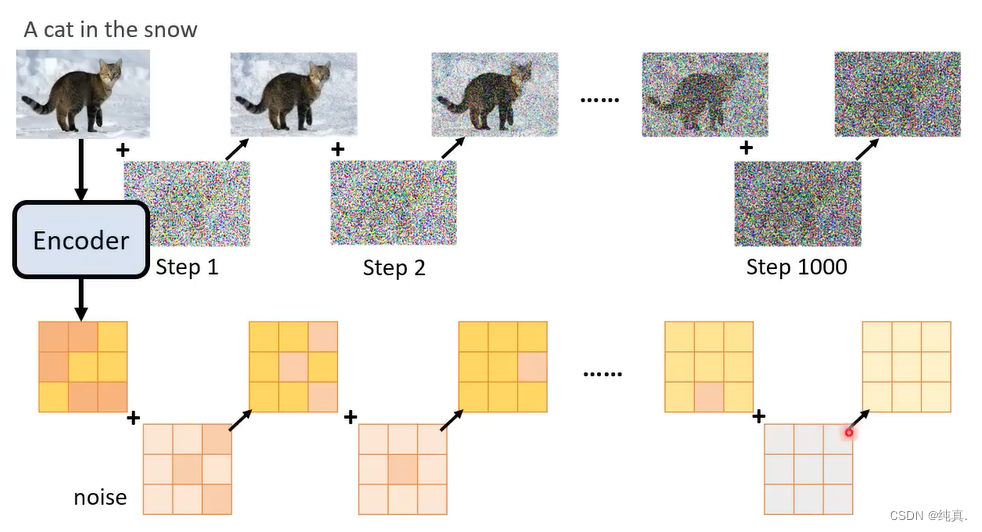
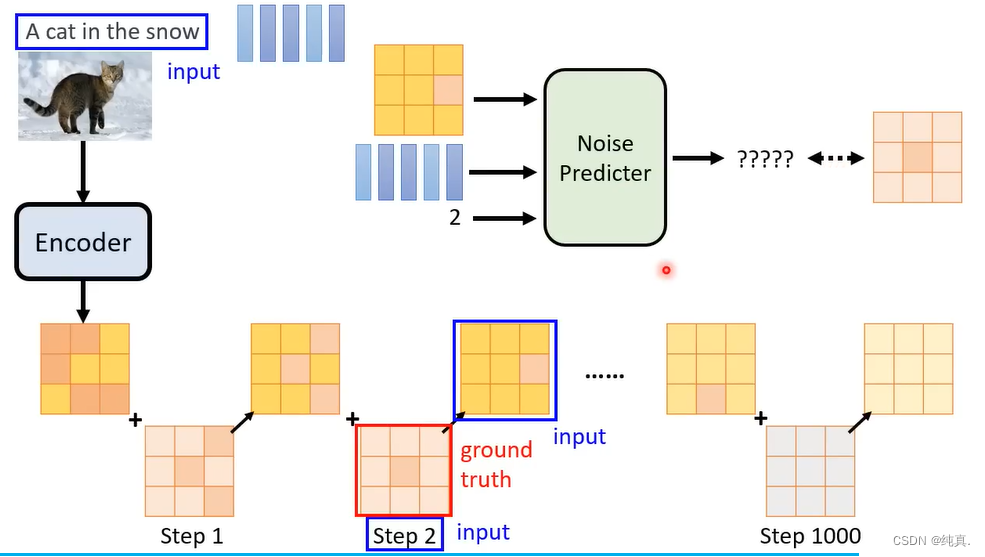
而后就是训练一个Noise Predicter,这里过程也是与DM相似的。
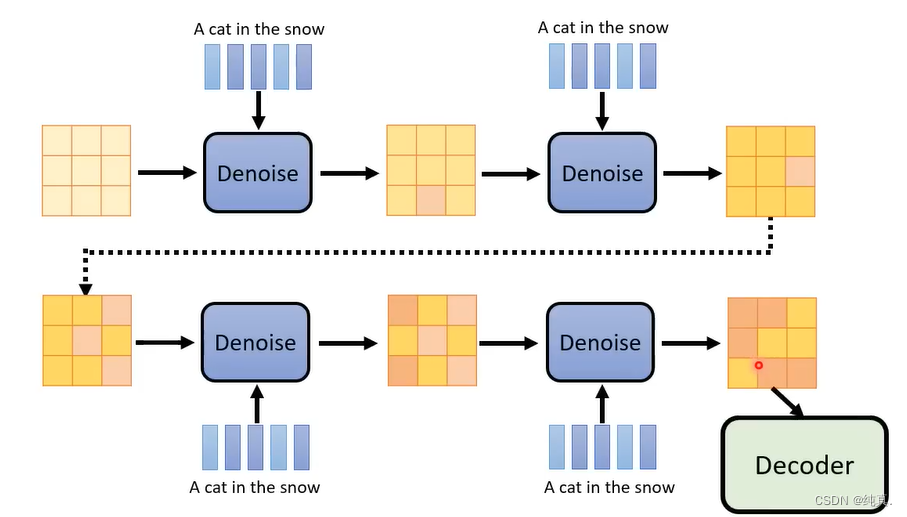
 生成的过程如下:其实与DM当输入是图像时是一样的,只是变了输入而已。
生成的过程如下:其实与DM当输入是图像时是一样的,只是变了输入而已。















 5942
5942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









