






为什么要使用VAE
直观解释
这里主要是与AutoEncoder进行一个对比。简单易懂的理解变分其实就是一句话:用简单的分布q去近似复杂的分布p。
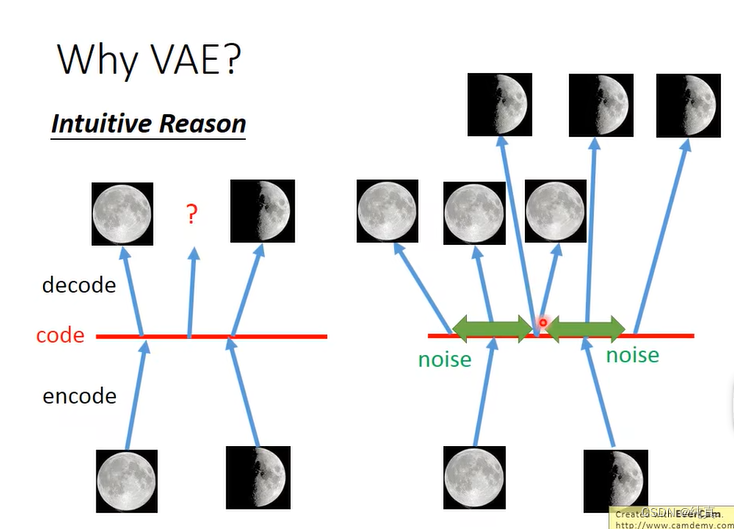 在原先的AutoEncoder当中,只能产生一一对应的图片,然而如果我们希望它能够产生两张月亮的中间结果时,他便不能够进行输出。因此,在VAE中对图像加入noise,在一定范围内都可以输出对应的月亮的图像,因此我们期望在两个范围的交界处,使得模型能够产生一个中间结果。
在原先的AutoEncoder当中,只能产生一一对应的图片,然而如果我们希望它能够产生两张月亮的中间结果时,他便不能够进行输出。因此,在VAE中对图像加入noise,在一定范围内都可以输出对应的月亮的图像,因此我们期望在两个范围的交界处,使得模型能够产生一个中间结果。
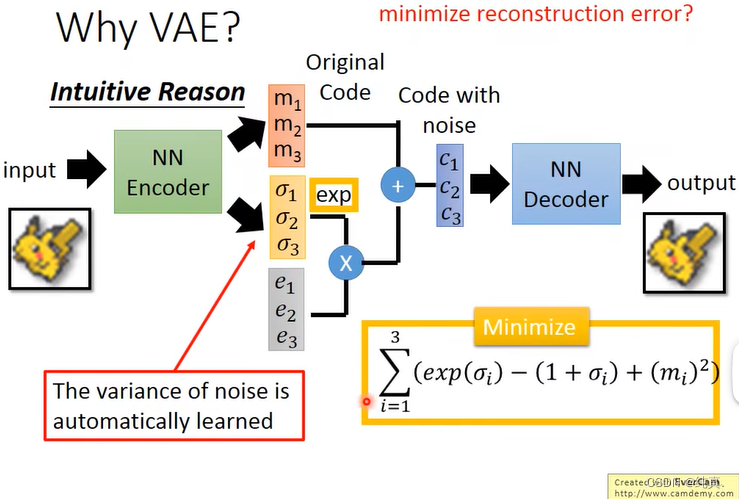
再来看一下VAE的流程,其中e1-e3是通过正态分布产生的vector。c代表的是加上了noise以后的code,decoder需要做的就是把加入noise以后的code还原成一张图像。σ1-σ3是通过学习产生的noise的方差,因为需要保证他是正数,在乘e时需要对其取exp。这样就保证了对于c1-c3的,方差的大小决定了noise的大小。
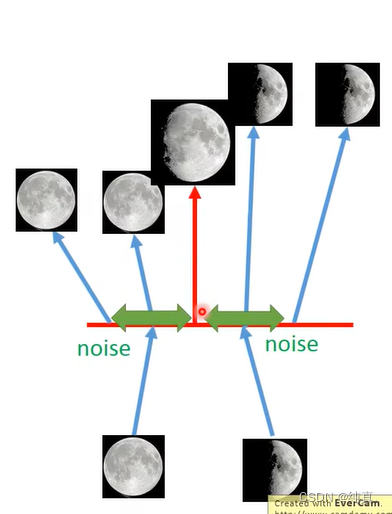
但是只通过上面的描述还是不够的,因为当把所有的σ都取0时,模型自然是训练的最好的。为了避免这种情况,我们需要对方差添加右下角的约束,也就是让variance不能太小。在下图中绿色曲线代表该式的函数图像,可以看出当σ取0时函数值是取1的,也就是不要让他太小。

论文中常见的解释
问题描述
例如下图所示的宝可梦图像生成,可以把每一只宝可梦看成高维空间中的一个点,我们想要做的就是估计这个几率分布。输入x是一个vector。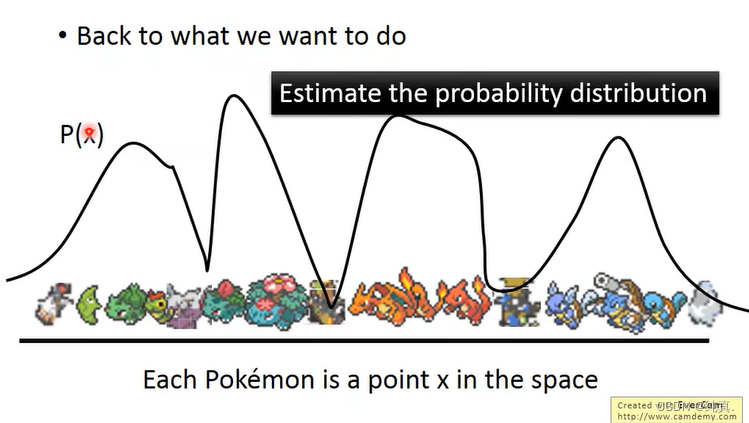
高斯混合模型
对于一个复杂的分布,他可以是由多组正态分布混合构成的,因此它可以表示为如下的形式。那么我们就可以计算x究竟属于哪一个正态分布当中,而后对分布进行描述。但是这样其实是不够的,更好的描述方式是使用Distributed Representations的方案进行描述。Distributed Representation是什么意思呢?在 distributed representation 中,强调的重点是每个词并非采用离散的表征方式(例如 one-hot encoding),而是被表征为一个低维,稠密的向量。
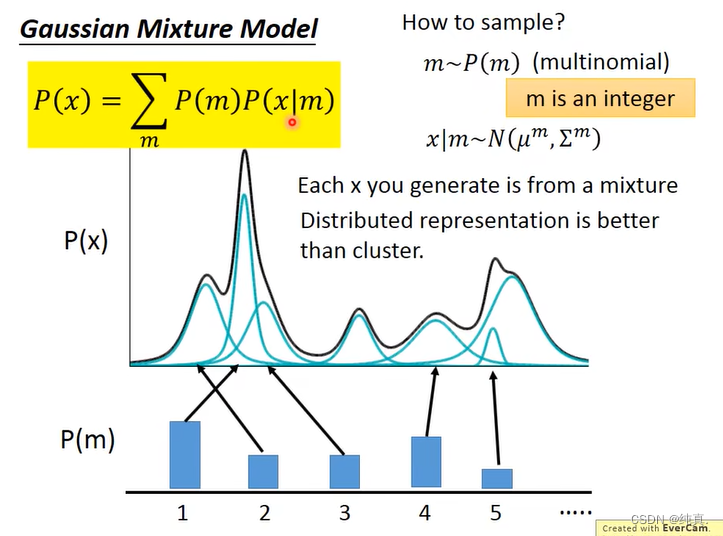
VAE其实就是可以看作是Distributed Representation的版本。
VAE
z是从正态分布中取样的一个向量,z的每一维都代表了一个图像的特征。我们通过一个正态分布来产生Gaussian,z中的每一个点都代表了一个Gaussian,所以我们有无穷多的Gaussian,z的均值与方差都是可以通过函数来计算的(通过NN)。隐变量z的作用除了让生成网络尽可能还原原来的数据 X,同时也能生成原来数据中不存在的数据。
 那么现在我们就可以用积分的形式来表示P(x),这个类比前面离散的时候是累加,但是由于这里的Gaussian是无穷多的,因此需要变成积分的形式。
那么现在我们就可以用积分的形式来表示P(x),这个类比前面离散的时候是累加,但是由于这里的Gaussian是无穷多的,因此需要变成积分的形式。
 现在可以回想在训练Diffusion model的时候,我们通过最大似然估计来考量两个分布之间的相似度。在VAE中用的也是这样一个思路,这里需要训练的值就是z的均值与方差,其实也就是更能够凸显x的特征。
现在可以回想在训练Diffusion model的时候,我们通过最大似然估计来考量两个分布之间的相似度。在VAE中用的也是这样一个思路,这里需要训练的值就是z的均值与方差,其实也就是更能够凸显x的特征。
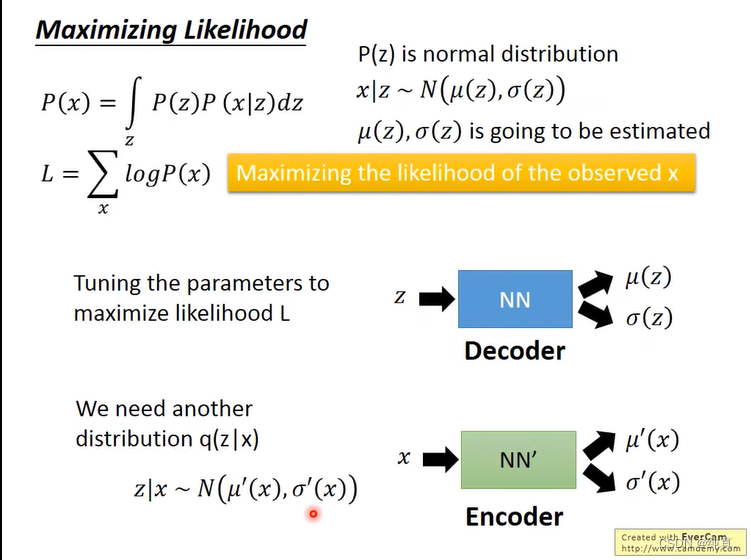
下面给一个推导过程,其实也就是计算的是他的下界,这个在之前Diffusion model中有提到过。

为什么要引入q这一项呢?其实也就是让KL占比越来越小,其实也就是让q(z|x)与p(z|x)越来越接近,回归到在说Diffusion model中想讲的故事,其实就是让两个分布越接近越好。
 我们对Lb进行一些变形,可以看到前一项其实就是一个负的KL divergence。回忆一下q是什么,q其实就是一个NN,其实就是encoder,他吃一个x,输出z的均值与方差。
我们对Lb进行一些变形,可以看到前一项其实就是一个负的KL divergence。回忆一下q是什么,q其实就是一个NN,其实就是encoder,他吃一个x,输出z的均值与方差。

那么现在的目的就变成了训练一个NN,使得KL divergence越小越好。那也就是让q与P(z),P(z)是一个正态分布越像越好。
 再来看另外一项,另外一项的目标是max。也就是从q中sample data,要让logP(x|z)越大越好,其实这就是autoencoder在做的事情。所以目的就变成了如下所示这样的形式,其实就是让一个神经网络吃一个输入x,而后产生两个向量,分别代表均值和方差,而后根据均值和方差sample出一个z。再将这个z作为下一个神经网络的输入,产生两个向量,分别代表均值和方差。因为这里通常不考虑方差,所以就是要让两个均值越接近越好。
再来看另外一项,另外一项的目标是max。也就是从q中sample data,要让logP(x|z)越大越好,其实这就是autoencoder在做的事情。所以目的就变成了如下所示这样的形式,其实就是让一个神经网络吃一个输入x,而后产生两个向量,分别代表均值和方差,而后根据均值和方差sample出一个z。再将这个z作为下一个神经网络的输入,产生两个向量,分别代表均值和方差。因为这里通常不考虑方差,所以就是要让两个均值越接近越好。
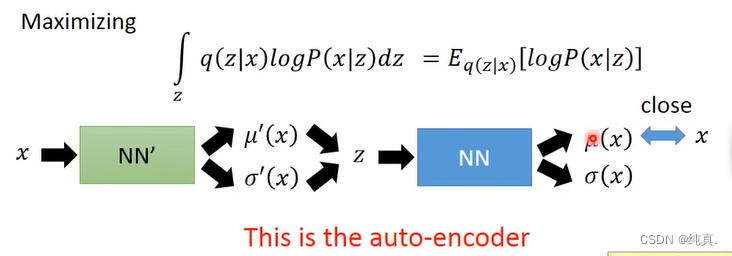
两项合并,其实就是我们之前看到的呢个VAE的损失函数。

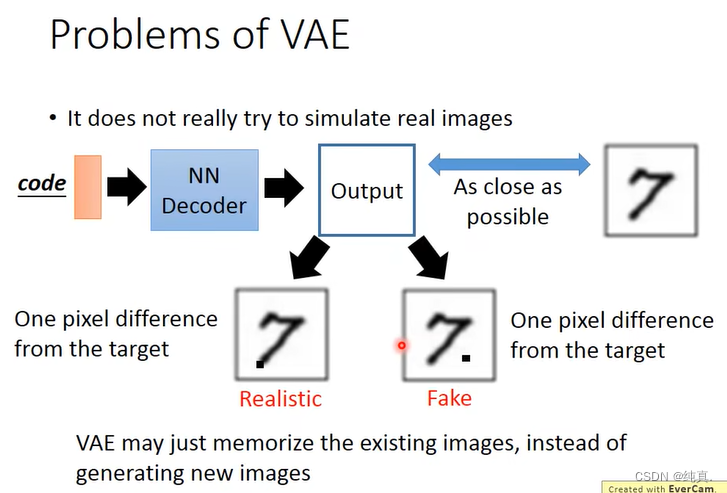
VAE的问题
VAE只是产生数据集中已经有的图片,而不是产生新的图片,因此就有了后续的GAN等技术的研究。















 8396
8396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









