







前言
Yolo算法简介
YOLO (You Only Look Once) 是一种用于目标检测的深度学习算法,由 Joseph Redmon、Santosh Divvala、Ross Girshick 和 Ali Farhadi 在 2015 年提出。YOLO 是一种端到端的算法,它将目标检测任务视为一个单一的回归问题,从而显著提高了处理速度。与传统的基于滑动窗口或区域提议的目标检测算法相比,YOLO 可以在单个前向传递中直接预测多个边界框和类别概率。
以下是 YOLO 的主要特点:
速度快:YOLO 的处理速度非常快,因为它将目标检测视为一个单一的回归问题,而不需要进行复杂的后处理步骤。这使得 YOLO 能够在实时应用(如自动驾驶、视频流分析等)中表现出色。
端到端训练:YOLO 的训练是端到端的,这意味着它可以从原始像素直接预测边界框和类别概率,而不需要进行中间步骤(如特征提取或区域提议)。
全局上下文:由于 YOLO 在整个图像上运行一次卷积网络,它能够捕获全局上下文信息,这有助于在复杂场景中准确检测目标。
泛化能力强:YOLO 在各种数据集上都具有较好的泛化能力,包括那些具有不同尺度和长宽比的目标。
然而,YOLO 也存在一些局限性,例如:
定位精度相对较低:与某些基于区域提议的算法相比,YOLO 的定位精度可能较低,尤其是在处理小目标或紧密排列的目标时。
对背景的误检率较高:由于 YOLO 预测了大量的边界框,其中一些可能会错误地检测到背景区域。
为了改进这些局限性,研究人员已经提出了许多 YOLO 的变种,如 YOLOv2、YOLOv3、YOLOv4 和 YOLOv5 等。这些变种在保持快速处理速度的同时,通过引入更复杂的网络结构、更精细的边界框预测和更强大的训练策略来提高检测精度和泛化能力。
Yolo V5算法简介
Yolo V5是一种先进的单阶段目标检测算法,它在 Yolo V4 的基础上添加了一些新的改进思路,使得速度与精度都得到了极大的性能提升。以下是关于 YOLOv5 的详细介绍:
网络架构:
YOLOv5的目标检测算法可以划分为四个通用的模块,包括输入端、基准网络、Neck网络与Head输出端。输入端负责接收图片,该网络的输入图像大小通常为608*608,会经过图像预处理阶段,如缩放和归一化。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度,并提出了一种自适应锚框计算与自适应图片缩放方法。
性能特点:
精度:YOLOv5在目标检测任务中具有很高的精度,其在COCO数据集测试集上的mAP(mean Average Precision)可以达到50%左右。
速度:YOLOv5是一种快速的目标检测模型,可以在CPU上实现实时处理,GPU上能够获得更高的性能。在Tesla V100 GPU上,YOLOv5可以达到140 FPS的处理速度。
小型化:YOLOv5在网络结构设计和模型压缩方面做了很多优化,使得其模型参数量和模型大小都比较小,适合在嵌入式设备等场景中使用。
多任务处理:YOLOv5可以同时处理多种任务,包括目标检测、人脸检测、姿态估计等,具有很好的通用性和灵活性。
优点:
轻量级:与YOLOv4相比,YOLOv5使用更小的模型,在保证高精度的同时,减少了计算资源和存储空间的消耗。
更快速:YOLOv5的速度比YOLOv4更快,可以处理更高分辨率的图像,同时保持精度。
更准确:与YOLOv4相比,YOLOv5在多个物体检测指标上都有一定的提升,具有更高的准确性。
更易于使用:YOLOv5使得物体检测任务的部署和使用变得更加简单,支持多种语言和平台,易于集成到AI应用中。
需要注意的是,虽然YOLOv5在目标检测任务中表现出色,但它对小目标的识别可能不太稳定,并且需要大量的训练数据才能达到较高的准确率。此外,YOLOv5的变种,如YOLOv5-Multibackbone-Compression,通过引入多骨干网络和模型压缩技术,旨在提升模型的推理速度并减小内存占用,同时保持良好的检测性能。这些变种可以适应各种资源受限的环境,如边缘设备或低功耗平台。
Yolo V5 的小版本选择
因为 YoLo V5 的代码直到现在依然在不停的更新,因此我们选择其中一个版本进行讲解,相信弄明白了其中一个版本,那么后面不断更新的内容也会比较好理解和上手。
如上图所示,我们选择的是 v7.0 这个小版本进行讲解。
注意:这里的 v7.0 指的是 YoloV5 不断更新的小版本,而不是 Yolo 这个模型的大版本嗷,注意辨析。
YoloV5 环境配置
我们下载其压缩文件:
将压缩包下载下来后解压,使用 PyCharm 编辑器打开等待加载,然后点击左上角,其内有一个 settings:
点击进去配置我们的 PyTorch 环境:
点击应用后关闭,此时我们就将 Anaconda 中我们一开始配置好的 PyTorch 环境配置到我们的项目中了,还差一步我们的项目就应该能正常运行了,那就是安装这个项目所需要的一些库。
在优秀的开源项目中,作者都会将这些库罗列成一个脚本文件以展示给用户,即这个项目中的 requirements.txt 文件:
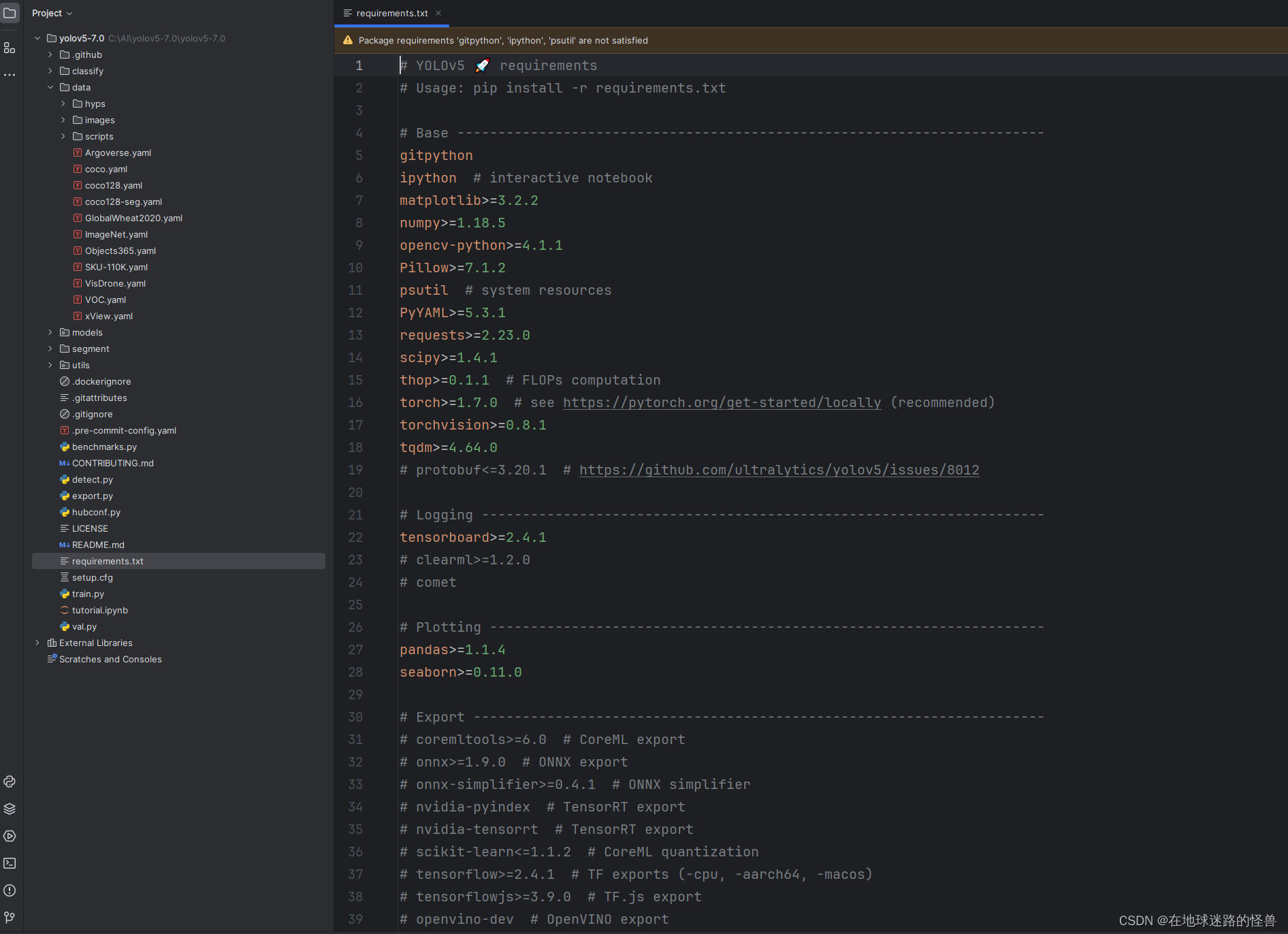
接下来我们打开控制台,输入脚本指令即可(注意要进入我们所配置的 conda 环境中嗷,我这里是环境名字就叫 pytorch):
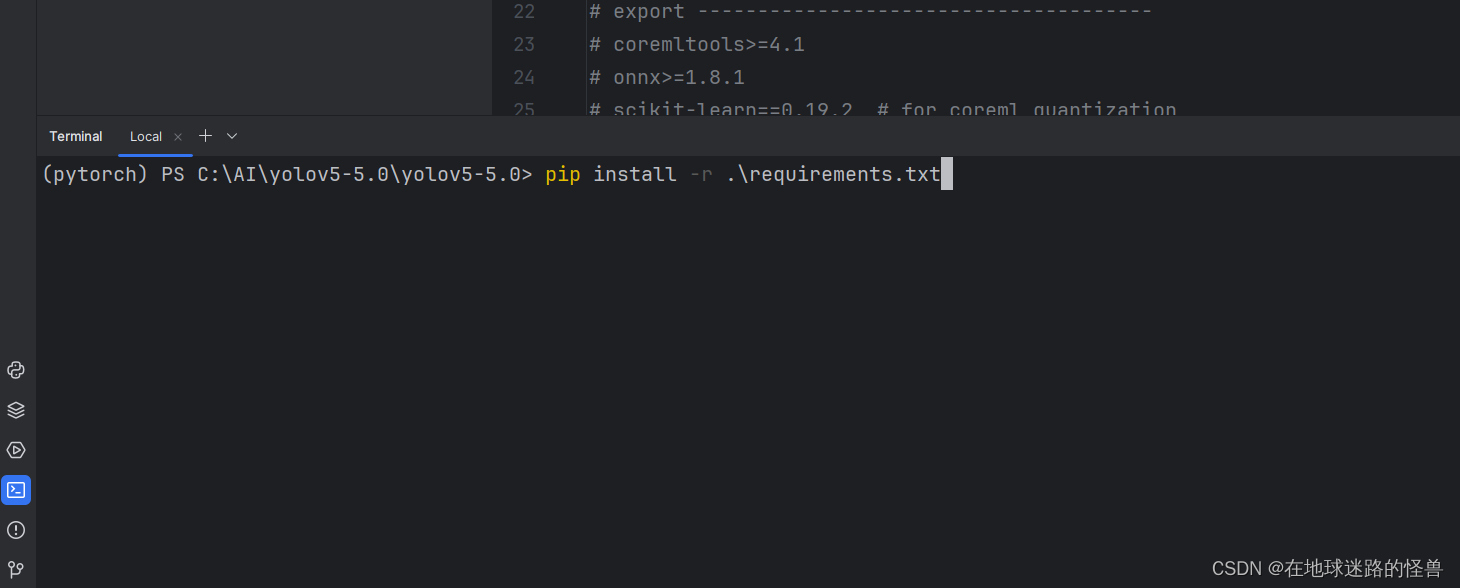
回车之后开始下载即可。
如果下载过慢,可以指定一下下载源,直接输入下面的命令进行下载即可:
pip install -r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
一般情况下这样就能成功,如果出现错误了那么可以接着往下看,下面是可能会出现的一些可能出现的问题。
比如出现了下面的问题捏:

这里是我们缺少了 C++ 相关的一些工具,那么我们按照给的链接去下载就可以了:
下载完成之后双击运行安装即可,来到下面的页面时:
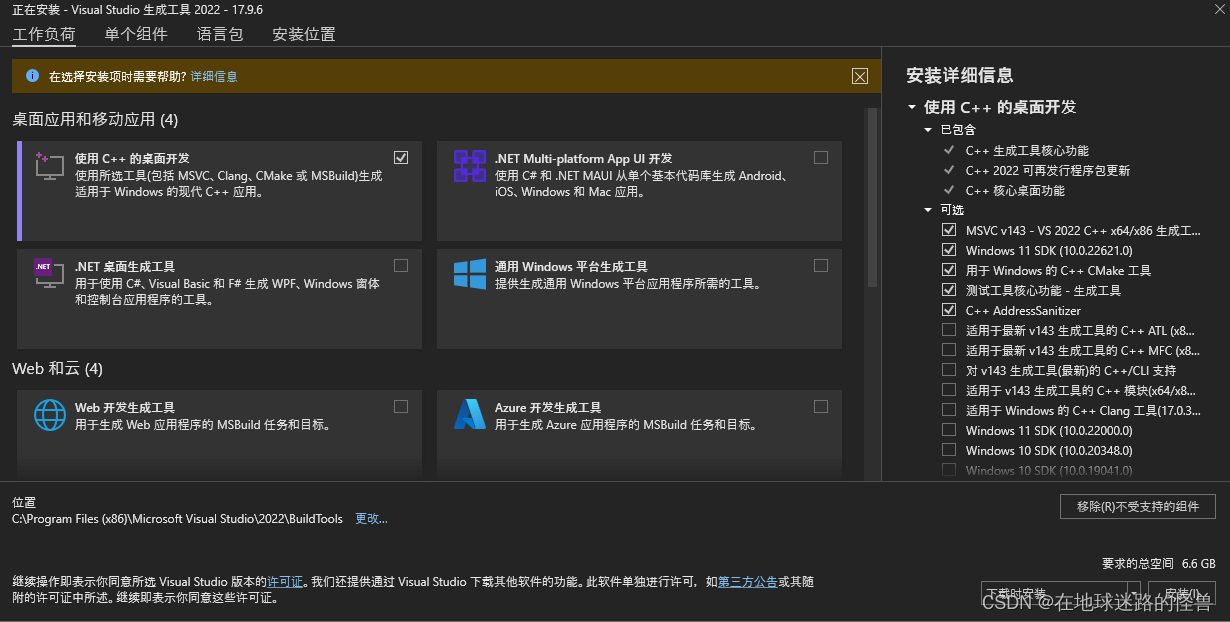
先勾选上左上角的 “ 使用C++的桌面开发”,然后点击左上角的 “单个组件”,搜索 “build”,然后勾选上下图中的组件(“编译器、生成工具和运行时”下的 clang-cl 组件):
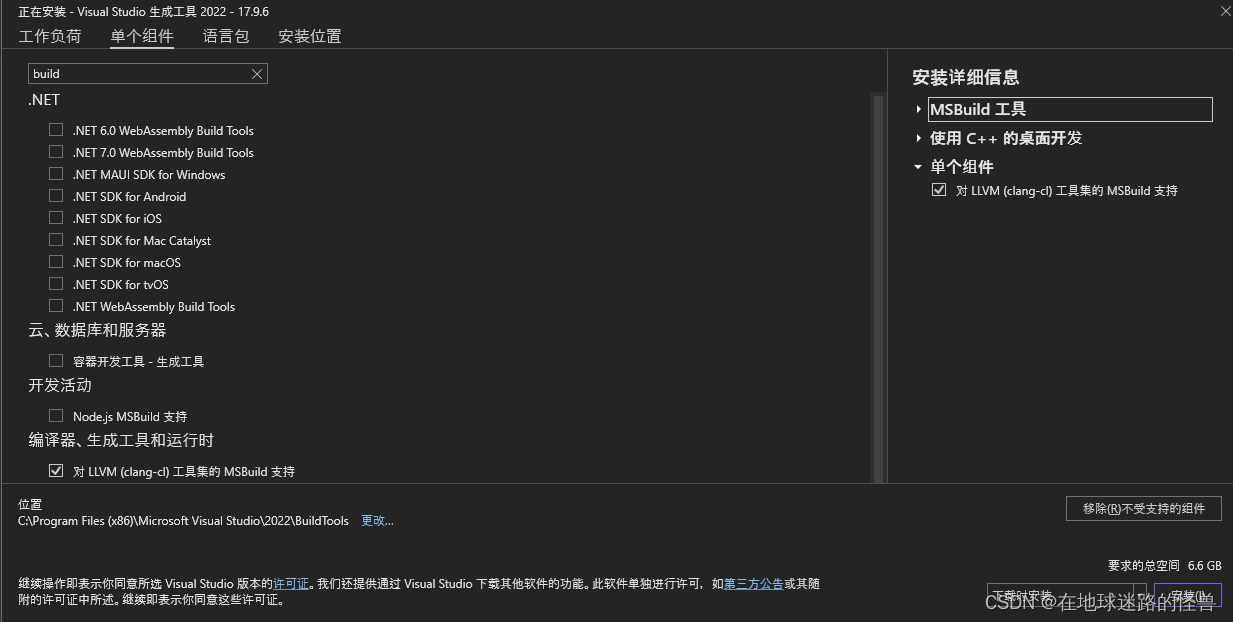
然后点击右下角进行安装即可,安装完毕后重启 PyCharm 再运行 PyCharm 运行上述的下载指令(pip install -r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple)即可解决问题。
但是又出现了下面的问题:

其实就是 python 和 opencv 版本不匹配的问题,因为我用的 python 是 3.6 的版本,而 python3.6 适配的 opencv 版本是 opencv-python 4.5.4.60,因此我们下载这个版本的 opencv 即可:
pip install opencv-python==4.5.4.60
然后重新执行下载命令(pip install -r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple)即可。
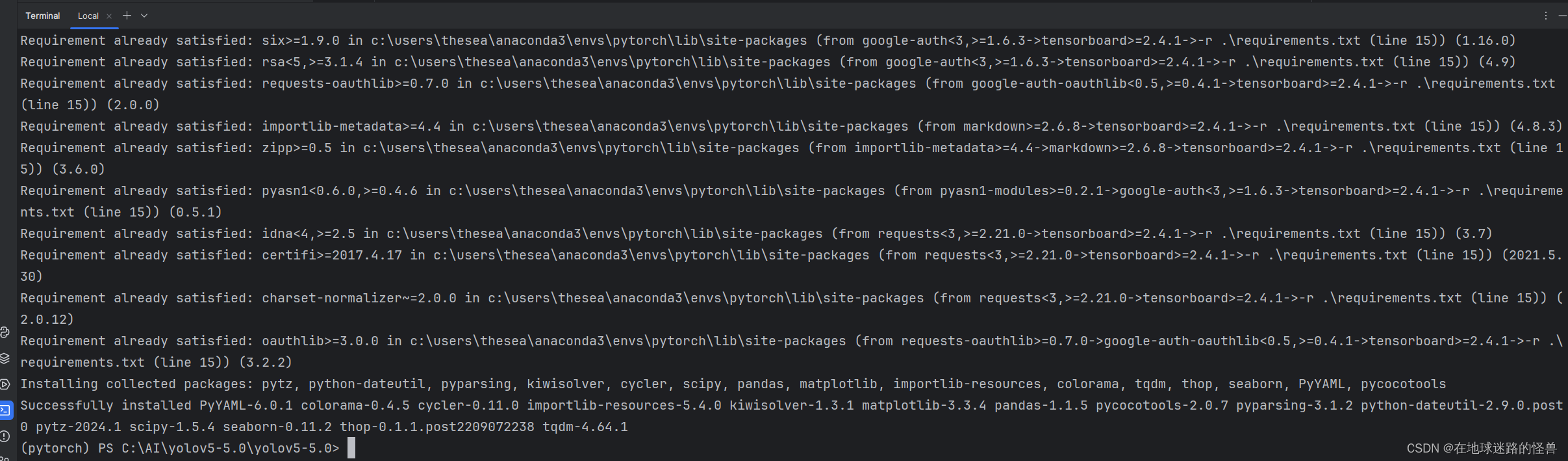
安装结束没有爆红,说明全部正常,那么 Yolo V5 的环境配置就算是大功告成啦。
利用 YoloV5 的成熟模型进行预测
这里要先声明一点:整个Yolo V5 的话是被划分为了四个模型,yolov5s 是最小的模型,然后 yolov5m 是中等模型,yolov5l 是大模型,yolov5x 是超大模型。
测试程序
观察项目的文件目录中,不难发现存在一个 detect.py 文件。从 readme.md 文件中可以知道,这个文件已经写好给出了我们如何利用其已经训练好的一些网络模型进行预测的代码。
在这个 Python 文件当中我们可以下载不同的模型,同时这个模型的结果会被保存到 runs/detect 文件夹中。
那么我们就可以先用这个文件来简单的测试一下 Yolo V5 。
下面是 GPT 给出的这个文件的解释:
detect.py文件的主要作用是提供一个简单的命令行界面,允许用户使用预训练的YOLOv5模型对图像、视频或目录中的图像进行目标检测。
以下是detect.py文件通常包含的一些功能:
命令行参数解析:detect.py会解析从命令行传入的参数,这些参数包括输入文件的路径(可以是图像、视频或目录)、预训练模型的路径、输出文件的路径、置信度阈值等。
加载预训练模型:使用PyTorch加载预训练的YOLOv5模型。这通常包括加载模型的权重(.pt或.pth文件)和模型结构(.yaml文件)。
数据预处理:对输入的图像或视频帧进行必要的预处理,如调整大小、归一化等。
目标检测:使用加载的模型对输入数据进行推理,生成边界框、类别标签和置信度分数。
后处理:对模型输出的结果进行后处理,如非极大值抑制(NMS)以去除冗余的边界框,根据置信度阈值过滤结果等。
结果可视化:将检测到的目标在原始图像上用边界框、类别标签和置信度分数进行标注,并显示或保存到输出文件。
性能评估(可选):如果提供了标注的验证集,detect.py还可以计算并输出一些性能指标,如mAP(平均精度均值)等。但请注意,这不是detect.py的主要功能,主要用于val.py或test.py等评估脚本中。
总之,detect.py是YOLOv5中一个非常实用的工具,它允许用户轻松地使用预训练的模型进行目标检测,并将结果可视化。
使用这个文件可以使用命令行的方式,但我们这里使用 PyCharm 的可视化的方式,关于命令行的方式在 readme.md 文档中都有详细介绍。
查看 detect.py 文件,下拉到下面可以发现主函数:
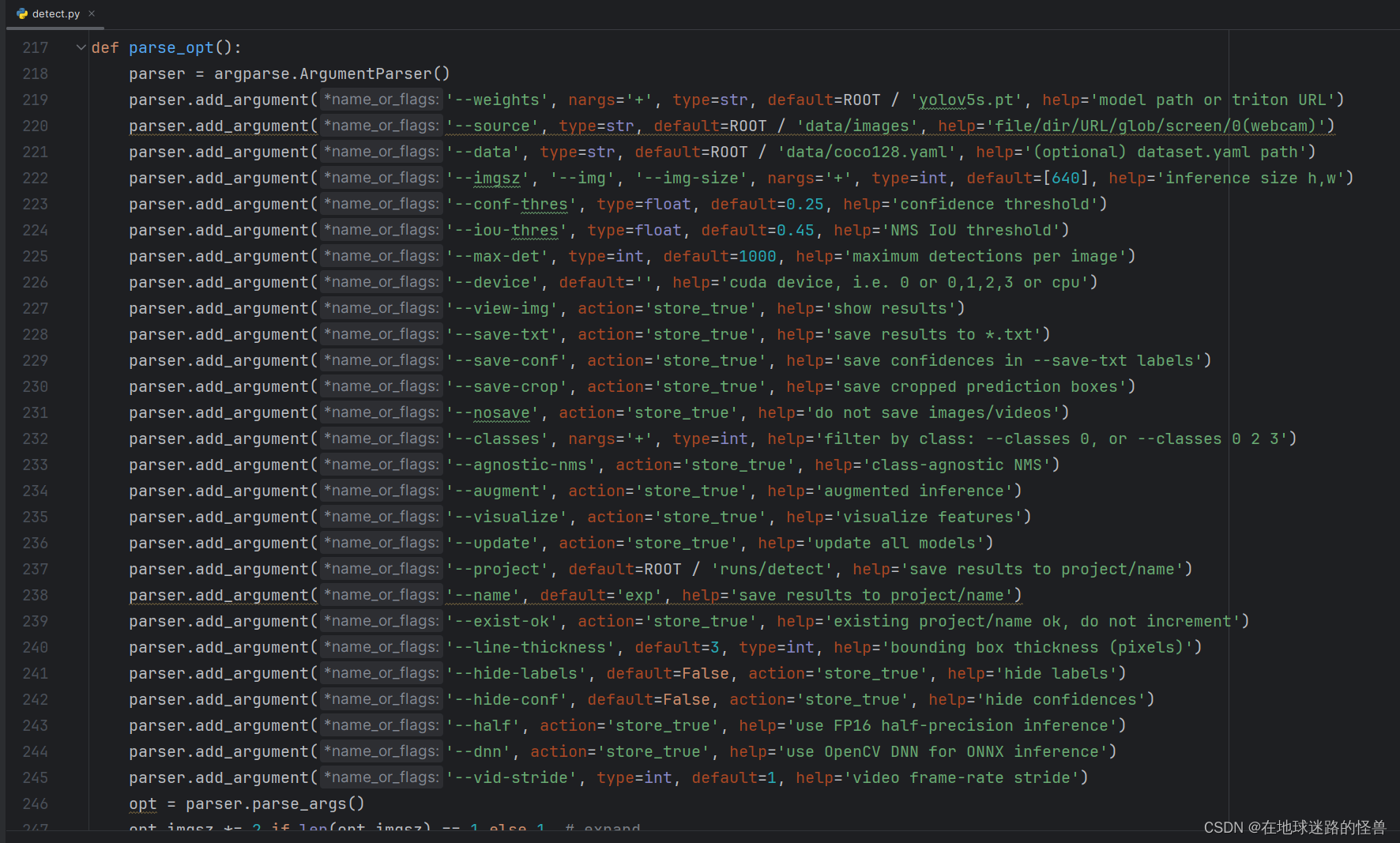
从这里就可以知道我们其实是可以通过命令行的方式来在启动程序时创建所需参数的。
以其中一个参数为例:
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
不难想到这应该是权重参数 weights,可以看到其类型 type 为 str 字符串型,然后其有一个 default 默认值为 “yolov5s.pt”,也就是默认加载的是 5s 这个小模型的权重参数值。而后面的 help 参数基本就是注释了,通过该信息我们可以知道某个参数是干嘛的如何使用就足够了。
其他的就以此类推。
往下翻,可以找到 main 函数所在的地方,我们从main函数启动这个程序,参数全部采用默认值:
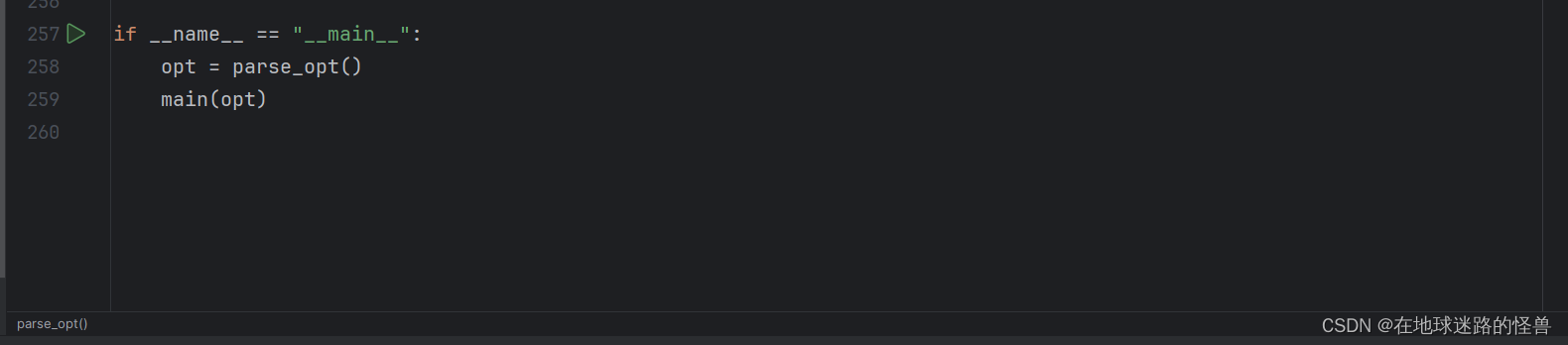
启动 main 后会报错:
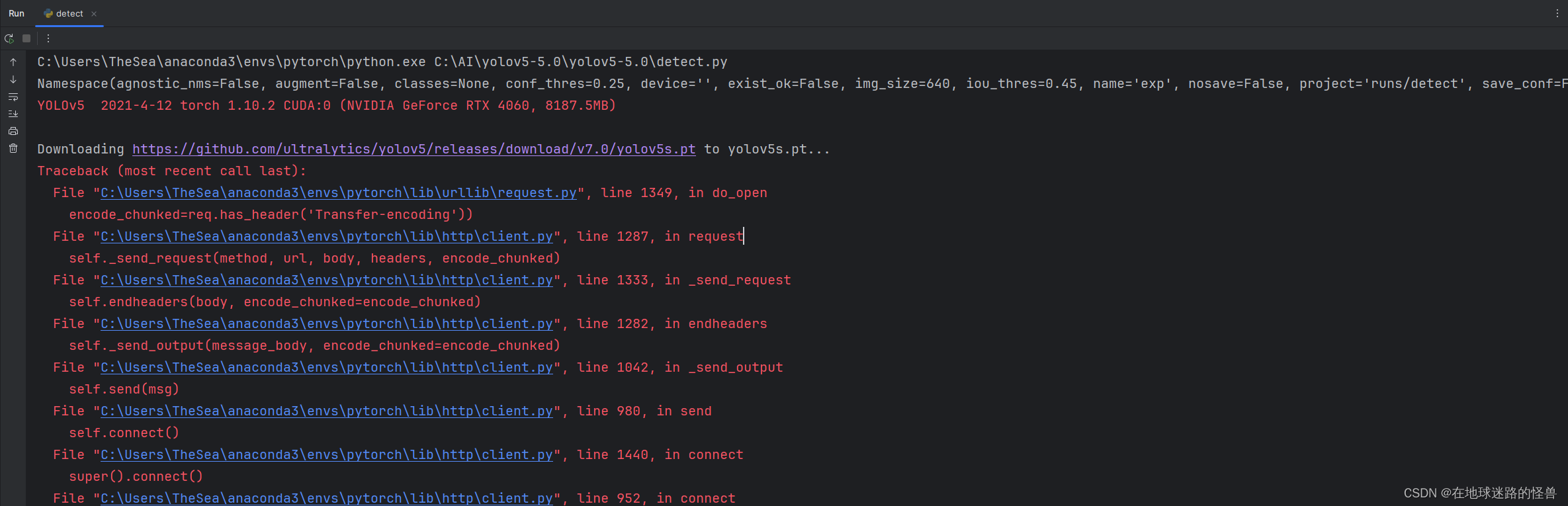
这一步是我们的项目正在从 github 上下载我们所需要的 Yolo 已经训练好的模型程序(也就是默认的 yolov5s.pt),而出现这样的问题就是本地和 github 外网的连接不稳定,我的解决办法是直接复制这个链接然后去 github 官网用浏览器下载,下载完之后手动添加到这个项目文件夹下即可:
然后再重新运行 main 方法即可。
运行效果如下:
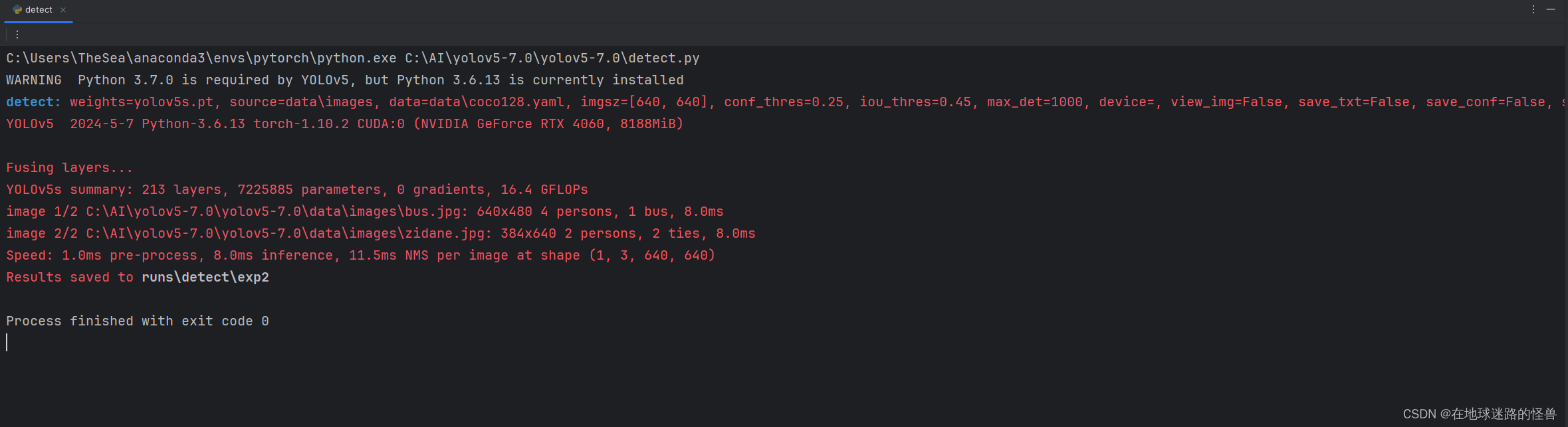
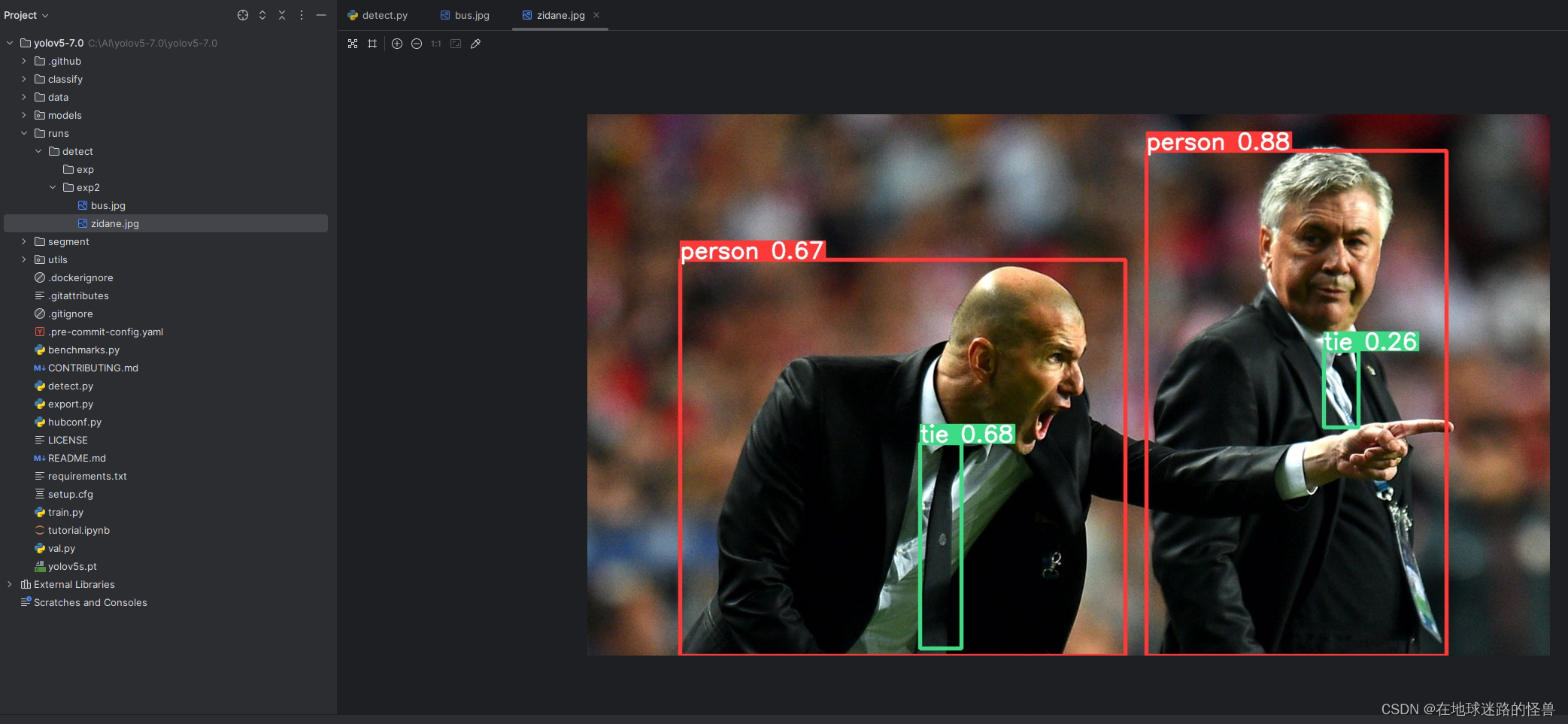
从上图我们可以看到预测的结果已经拿到,存放在 runs\detect\exp2 文件夹中:
Yolo V5 的参数介绍
接下来我们介绍 Yolo V5 中测试程序里所涉及到的各个参数,掌握了这些参数我们应该可以做一些定制化开发了捏。
–weights
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
weights就是我们的模型参数,默认是 yolov5s.pt,如果使用这个则会调用这个训练好的模型参数来对我们的测试数据进行预测。
我们也可以将其改成 yolov5m.pt,有很多个类型,在 github 仓库的右下角的 Releases 一栏,有各个版本的介绍:
点进上图右下角的 Releases,可以发现诸多版本:
–source
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
source则是指定我们的数据来源,其也有默认值,在上面的测试程序中,我们可以根据这个路径去找到我们的测试图片:
因此我们将自己的图片数据放入其中也一样可以进行预测嗷,另外看官方文档我们也可以知道,Yolo除了可以检测图片,视频也是可以检测的,只要将数据源换成视频即可。甚至可以实现实时检测,只要连接到 rtsp 等常见流媒体传输协议的链接作为数据源即可。
–data
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
参数 --data 允许用户在运行 YOLOv5 的命令行脚本时指定数据集配置文件的路径,默认是 coco128 数据集。
coco128.yaml 是一个数据集配置文件,它包含了数据集的相关信息,如数据路径、类别信息等。具体来说,在 YOLOv5 等目标检测模型中,该文件用于指定训练时所使用的数据集路径、类别数量、类别名称等关键信息。这样,模型就可以根据这些信息来加载和处理数据集,从而进行训练和预测等操作。
在YOLOv5的示例中,coco128.yaml可能指向一个由COCOtrain2017数据集中的前128个图像组成的小型教程数据集,用于演示和测试模型的训练过程。通过修改coco128.yaml文件中的配置信息,用户可以轻松地切换到其他数据集进行训练和测试。
–imgsz
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
imgsz 参数是用来在网络计算过程中将我们的输入数据的大小给 Resize 成 640*640 大小以贴合 Yolo 网络计算的,但是最后输出的数据依然会被转换回原来的大小。
–conf-thres
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
conf-thres 参数用于设置模型在检测时所使用的置信度阈值。
在目标检测中,模型会为每个检测到的对象分配一个置信度得分,这个得分反映了模型对该对象存在的确信程度。置信度阈值用于过滤掉那些模型认为不太可能存在(即置信度得分低于阈值)的对象。设置较高的阈值通常会导致更少的误检(即将背景或其他非目标对象误识别为目标对象),但也可能导致漏检(即未能识别出真正的目标对象)。因此,选择合适的置信度阈值对于平衡误检和漏检是非常重要的。
形象的说:如果置信度过低,比如为0,那么可能检测结果会是满屏幕都是可疑目标对象;而置信度过高,那么可能检测结果满屏幕只会有极少几个被确定为是正确的目标对象。
–iou-thres
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
iou-thres 参数用于设置非极大值抑制(Non-Maximum Suppression, NMS)算法中的交并比(Intersection over Union, IoU)阈值。
在目标检测中,NMS是一个常用的后处理步骤,用于去除重叠的检测框,保留最佳的一个。NMS的基本思想是,对于同一个目标,只保留置信度最高的检测框,同时去除那些与其重叠程度超过一定阈值(即IoU阈值)的其他检测框。
IoU阈值是一个介于0到1之间的浮点数,用于衡量两个检测框的重叠程度。IoU值越高,表示两个检测框的重叠程度越高。在NMS中,如果两个检测框的IoU值超过了设定的阈值,那么IoU值较小的那个检测框就会被认为是冗余的,从而被去除。
通过调整 --iou-thres 参数的值,用户可以控制NMS算法去除冗余检测框的严格程度。较低的IoU阈值会导致NMS更加宽松,保留更多的检测框;而较高的IoU阈值则会导致NMS更加严格,只保留更加确信的检测框。因此,选择合适的IoU阈值对于平衡检测框的数量和检测精度是非常重要的。
举一个例子 NMS 非极大值抑制的例子:

从上图中不难发现,左边三个和右边三个检测框都高度重叠,然而很明显只有一个是最佳选择。此时就需要根据 iou 参数值来进行选择了。
那么 iou 究竟是什么呢?
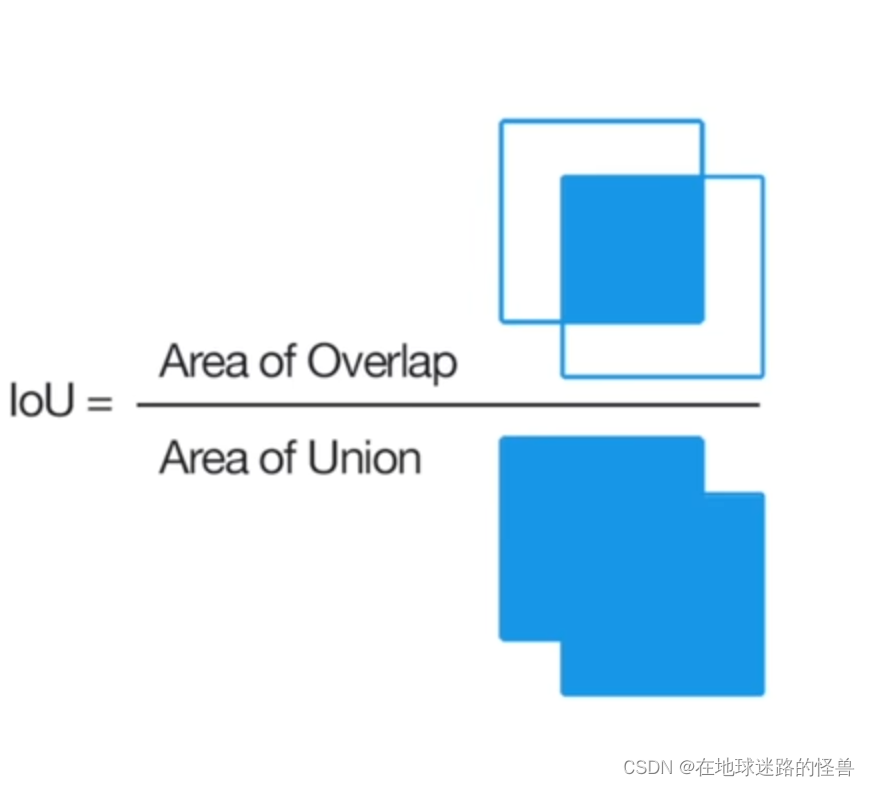
上图给出了 iou 的计算公式,两个检测框的交集部分除以两个检测框的并集部分得到的值就是 iou 值。
再举一个小例子来形象的说明一下 iou 值大小对于检测的影响:
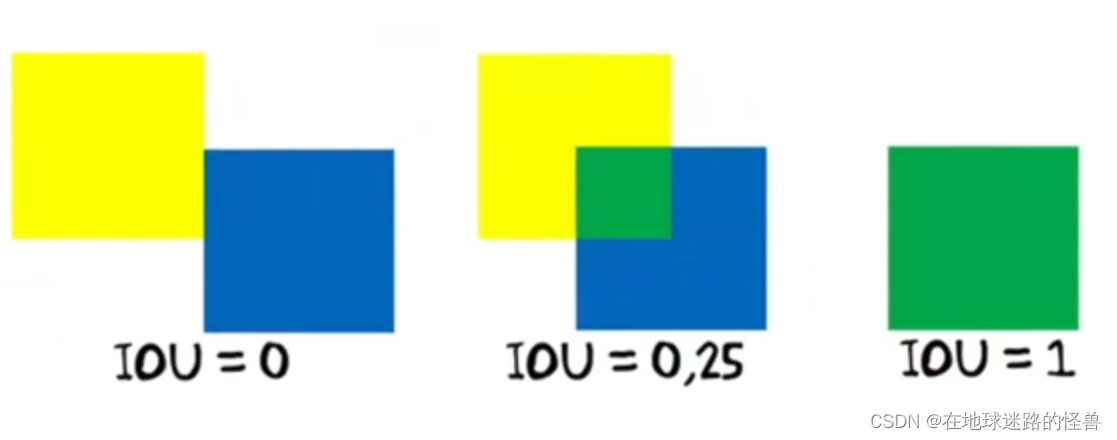
还是比较形象吧?iou 值越高则两个框重叠的概率会越高捏。
–max-det
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
这个参数是用来设置“每幅图像的最大检测数量”的。
在 YOLOv5 的上下文中,这个参数可能用于限制模型每幅图像输出的最大检测框(或预测对象)数量。例如,如果你设置 --max-det=10,那么无论模型检测到多少对象,它都只会输出前 10 个最自信的预测。这有助于在需要限制输出数量(例如,在实时应用中)时提高性能。
在目标检测任务中,模型会对输入图像进行预测,并输出多个边界框(bounding boxes),每个边界框都表示一个检测到的对象,并附有该对象的类别分数和位置信息。这些检测到的对象可能是模型识别到的图像中的实际物体,但也可能包含一些误检(false positives)。
“每幅图像的最大检测数量”指的是在模型对一幅图像进行预测后,会选择置信度最高的前N个检测框作为最终的输出结果,其中N就是–max-det参数所指定的值。例如,如果–max-det设置为100,那么无论模型实际上检测到了多少个对象,它都只会返回置信度最高的前100个检测框。
这个参数在多种场景下都很有用。在实时检测应用中,限制输出数量可以提高处理速度,因为不需要处理或显示所有的检测框。此外,在一些应用中,用户可能只对置信度最高的几个检测感兴趣,因此限制输出数量也可以帮助过滤掉一些误检。
–device参数
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
这个就比较明显了,device 参数就是用来确定用 GPU 跑还是 CPU 跑程序了。
可以看到其默认为空,说明在程序内部其实会自动判断的,我们不需要管。
–view-img
parser.add_argument('--view-img', action='store_true', help='show results')
view-img 参数用于控制是否在训练或测试过程中显示图像结果。
当用户在命令行中指定了 --view-img 参数(即运行命令时包含了 --view-img 而不必带任何值),它会将args.view_img(args是argparse.ArgumentParser().parse_args()返回的命名空间对象)设置为True,这样 YOLOv5 将在训练或测试过程中显示处理后的图像结果,如:

如果–view-img没有被指定,则args.view_img的默认值将为False,如:

那么在训练或测试过程中被处理后的图像结果就不会被显示。
这对于调试和可视化非常有用,因为用户可以直观地看到模型对每个输入图像的预测结果。
我们如果使用 PyCharm 编辑器的话,是可以在编辑器中手动加上这个参数的,在项目右上角有一个启动编辑:
点击上图中的 Edit Configuration:
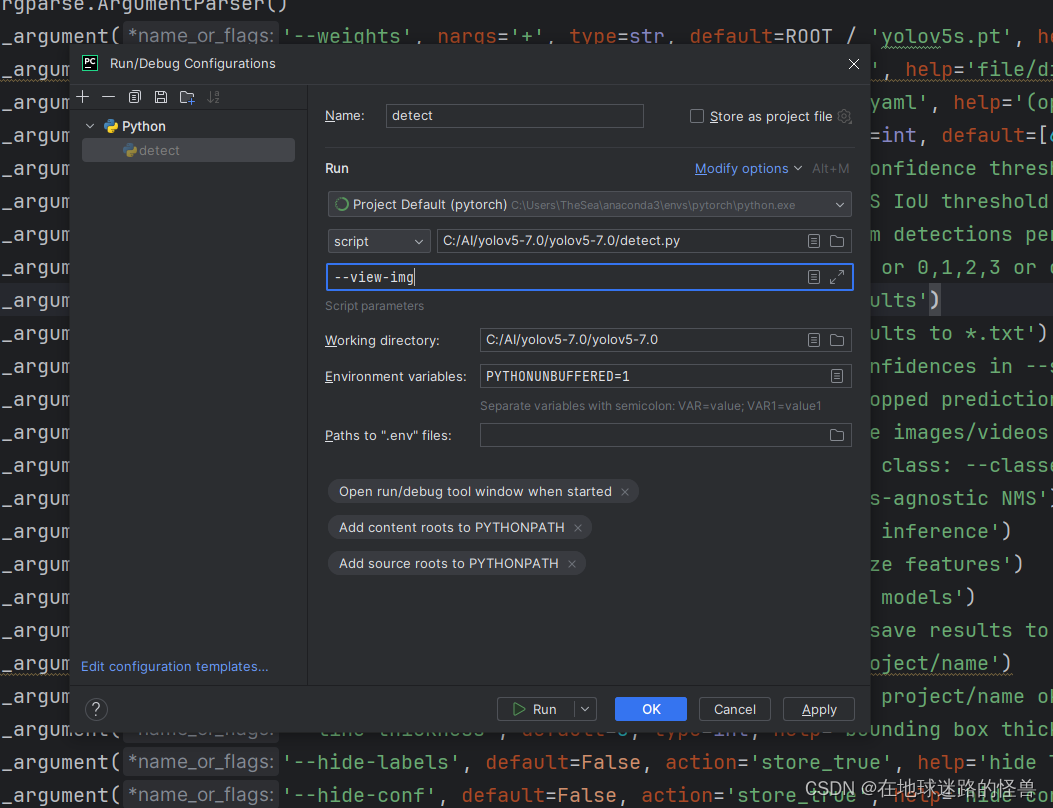
将我们的参数写入 Script parameters 中,点击 Apply 运行即可完成这样的效果,这样就会训练一部分就会弹出一部分效果图显示。
这还蛮有用的其实,想想如果我们使用的视频数据的话,那么就可以实时查看数据了,大概像这样:
这里放的图片无法动态展示,各位可以自己尝试一下。
–save-txt 参数
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
–save-txt 参数是询问是否将训练结果保存为 txt 文件(就是一些计算结果的值),方式为 action,因此效果同 device 参数。
如果想知道加上有什么效果,那么可以将该参数追加在 PyCharm 中,注意多参数之间使用空格进行分隔:
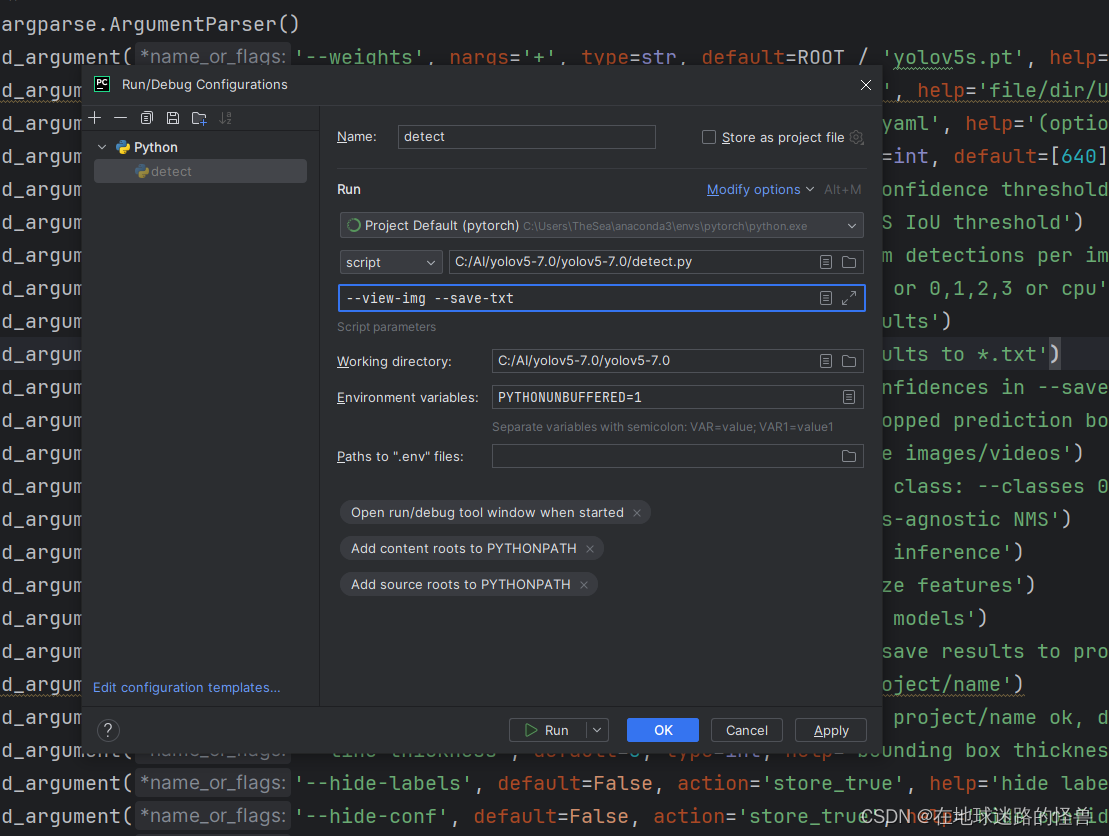
然后再启动程序即可。
–save-conf
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
–save-conf 参数用于决定是否在保存的文本标签(可能是边界框的标签)中包含置信度分数。如果–save-conf被指定,那么在生成的文本文件中,每个边界框的旁边可能会包含一个表示模型对该边界框的置信度的分数。
–save-crop
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
–save-crop 参数的作用是允许用户选择是否保存那些与检测到的目标边界框(prediction boxes)相对应的裁剪后的图像。这通常用于进一步分析或可视化检测到的目标,因为它只显示每个目标及其周围的上下文,而不是整个原始图像。
–nosave
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
顾名思义,就是不保存图片或者视频数据。
–classes
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
这个参数表示可以给 --class 指定多个赋值,比如可以指定参数 --classes 0 或者 --classes 0 2 3;
这个参数的作用则是用于过滤,在检测过程中我们对于每个目标都会有一个标记,比如汽车是class[0],人是class[1],狗是class[2]等等。
而如果我们指定了 --class 0 1 2 的话,那么意思就是只保留 class 0 2 3 的结果,然后其它的结果都不保存了。
–agnostic-nms
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
指定了这个参数的话那么就会使用一个更加强大的 NMS 机制。
–augment
parser.add_argument('--augment', action='store_true', help='augmented inference')
–augment 参数是用来增强模型的推理能力的。
增强推理(augmented inference)通常指的是在推理(或验证)阶段使用数据增强技术来生成多个输入图像版本,并对每个版本进行预测,然后将这些预测结果合并起来以获得更鲁棒和准确的预测结果。这种技术可以模拟训练时使用的数据增强,以在推理时提高模型的性能。然而,它也会增加推理时间和计算资源的使用量。
–visualize
parser.add_argument('--visualize', action='store_true', help='visualize features')
–visualize 参数用于启用特征可视化功能,即允许在训练、验证或推理过程中查看或保存中间层的特征图(feature maps)。
–visualize 参数被指定后程序会在训练或验证过程中将某些层的特征图保存到磁盘上,或者直接在屏幕上显示它们。具体实现细节可能因YOLOv5的版本和配置而异。
–update
parser.add_argument('--update', action='store_true', help='update all models')
该参数会把一些网络模型当中的一些不必要的部分去掉,因为源码在定义网络模型时不光光只定义了网络模型的参数,还定义了一些其他的比如一些优化器之类的东西。设置了该参数之后会把这些其他的给去掉,就只保留预测需要的一些参数和部分。
这个参数基本不用管,用不到,要用到的时候可以仔细查看官方文档给的解释。
–project
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
该参数表示设置我们模型的训练结果给保存到什么位置。
–name
parser.add_argument('--name', default='exp', help='save results to project/name')
该参数设置保存模型训练结果的文件夹叫什么名字。
–exist-ok
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
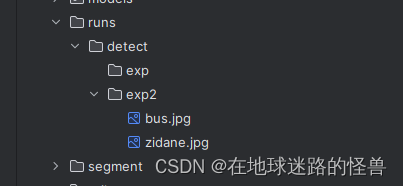
该参数表示如果我们没有指定该参数,那么我们会发现在每次执行完训练后 Yolo 都会给我们创建一个新的文件夹叫 expN,如果指定了该参数的话那么 Yolo 就会只在 exp 文件夹下追加训练结果了:
–line-thickness
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
该参数用来指定绘制边界框(bounding box)时所使用的线条粗细。
在深度学习或计算机视觉项目中,边界框通常用于在图像上标注出检测到的目标对象的位置。线条粗细决定了这些边界框在图像上显示的清晰度,较粗的线条可能更容易被用户注意到,但也可能遮挡图像中的更多细节;较细的线条则可能不够显眼,但能够减少遮挡。因此,通过调整 --line-thickness 参数的值,用户可以根据需要自定义边界框的显示样式。
–hide-labels
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
这个参数用来决定是否隐藏检测结果的标签(labels)。
在深度学习或计算机视觉项目中,标签通常用于在图像上标注出检测到的目标对象的类别或名称。通过调整 --hide-labels 参数的值,用户可以选择是否显示这些标签。如果用户想要简化输出或仅关注目标对象的位置,他们可以选择隐藏标签。这样,在显示结果时,只会显示边界框,而不会显示目标对象的类别或名称。
–hide-conf
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
这个参数用来决定是否隐藏检测结果的置信度(confidences)。
在目标检测任务中,每个检测到的目标对象通常都会有一个与之关联的置信度值,表示模型对该检测结果的自信程度。这个置信度值通常是一个介于0和1之间的浮点数,其中1表示模型完全确定其检测结果是正确的,而0表示模型完全不确定。
通过调整 --hide-conf 参数的值,用户可以选择是否在显示结果时包含这些置信度值。如果用户想要简化输出或仅关注目标对象的位置和类别,他们可以选择隐藏置信度值。这样,在显示结果时,只会显示边界框和相应的类别标签,而不会显示置信度值。
–half
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
这个参数用来决定是否使用半精度(FP16)浮点数进行推理(inference)。
在深度学习或计算机视觉项目中,推理通常指的是使用训练好的模型对新的、未见过的数据进行预测。使用半精度浮点数(FP16)而不是全精度浮点数(FP32)进行推理可以显著减少计算量和内存占用,从而加速推理过程并提高硬件的利用率。然而,这可能会以牺牲一定的精度为代价,因为FP16的表示范围和精度都低于FP32。
通过调整 --half 参数的值,用户可以在速度和精度之间进行权衡。如果用户更关注推理速度,并且可以接受一定的精度损失,他们可以选择使用 --half 参数来启用FP16推理。否则,他们可以选择不指定该参数,以保持使用FP32进行推理。
–dnn
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
这个参数来决定是否使用OpenCV的DNN(深度神经网络)模块来进行ONNX模型的推理。
ONNX(Open Neural Network Exchange)是一个用于表示深度学习模型的开放格式。它使得不同深度学习框架(如TensorFlow、PyTorch、Caffe2等)之间可以共享和部署模型。OpenCV是一个广泛使用的计算机视觉库,它包含一个DNN模块,用于加载和运行各种深度学习模型,包括ONNX模型。
通过调整 --dnn 参数的值,用户可以选择是否使用OpenCV的DNN模块来进行ONNX模型的推理。如果用户指定了 --dnn 参数,那么脚本将使用OpenCV的DNN模块来加载和运行ONNX模型。否则,脚本可能会使用其他方法(如直接调用ONNX运行时或其他深度学习框架)来进行推理。
使用OpenCV的DNN模块进行ONNX推理可以简化部署过程,因为OpenCV是一个广泛使用的库,并且它通常与各种计算机视觉任务紧密集成。然而,这也可能限制了可用的优化和定制选项,因为OpenCV的DNN模块可能不如专门的深度学习框架那样灵活。因此,用户需要根据自己的具体需求和环境来选择是否使用 --dnn 参数。
–vid-stride
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
–vid-stride: 这是命令行参数的名称。当处理视频数据时,用户可以通过这个参数来指定视频帧率的步长(stride)。
在视频处理或视频目标检测等任务中,处理每一帧可能既耗时又没有必要,因为相邻帧之间通常包含大量重复或相似的信息。通过设置 --vid-stride 参数,用户可以指定跳过一定数量的帧来减少计算量。例如,如果 --vid-stride 设置为2,那么脚本将只处理视频中的偶数帧(或每隔一帧处理一次)。
注意,这里的“帧率步长”并不直接改变视频的原始帧率,而是决定了脚本在处理视频时访问帧的频率。原始视频的帧率保持不变,但脚本将按照指定的步长选择性地处理其中的帧。
本地自定义训练 YoloV5
测试训练程序
在这个项目中,训练文件都集中放在了 train.py 内:
因此我们要训练自己的内容的话,看这个文件即可。
点开这个文件后往下拉,继续找到我们的 main 函数位置:
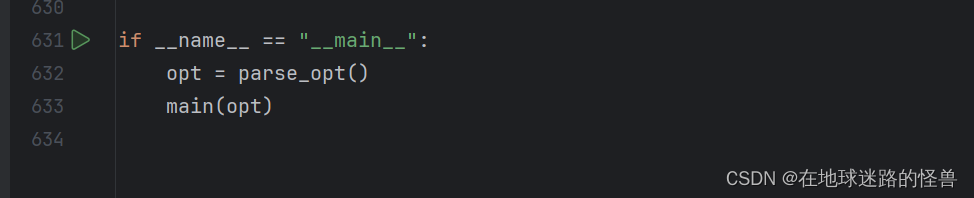
可以看见 main 函数主要做了两件事情,一个是解析参数,一个是调用其内部定义的 main 函数以启动程序。
那么我们可以按住 ctrl + p 进入 parse_opt() 函数中查看其都做了些什么:
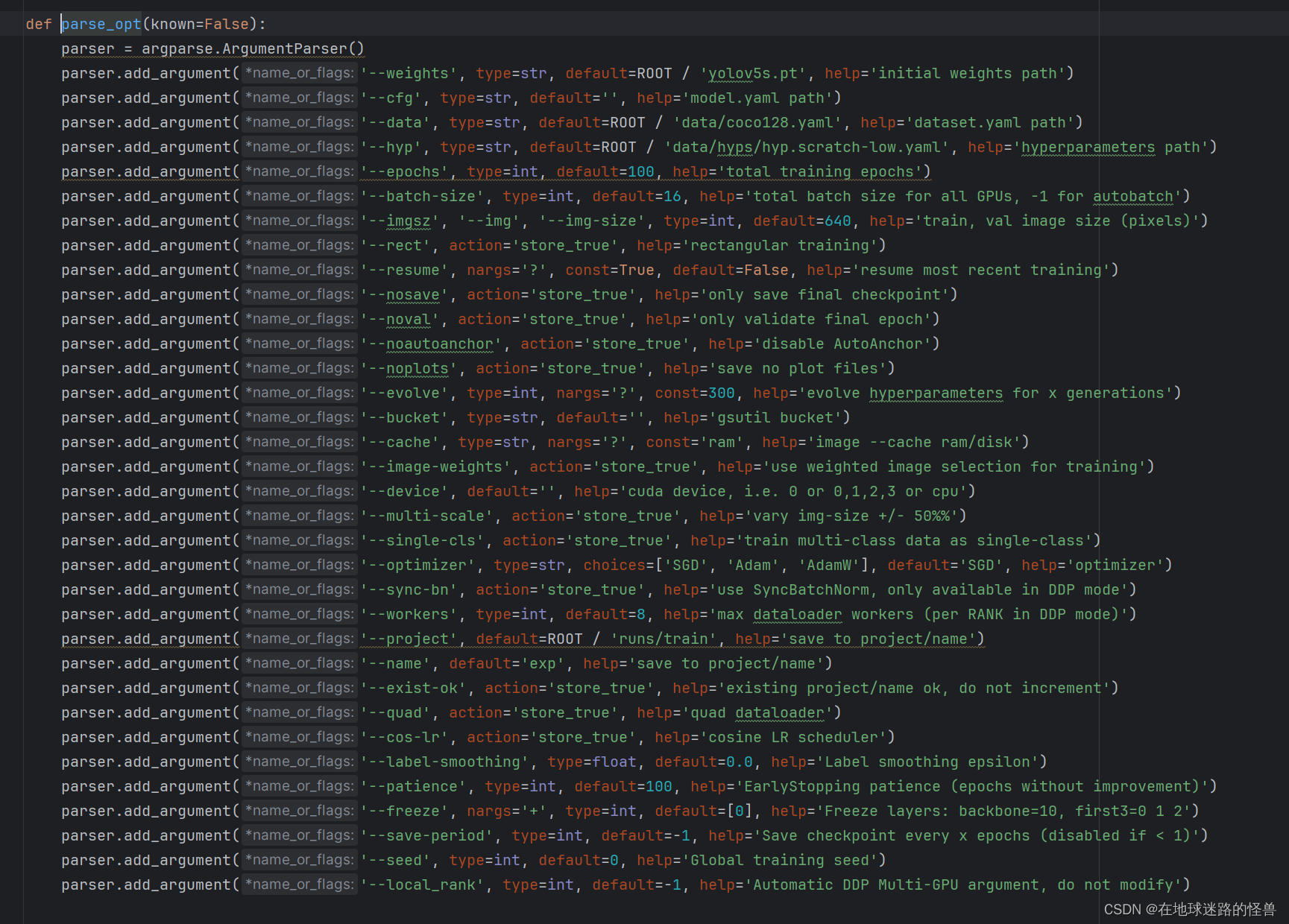
可以看见和我们的 detect.py 文件一样,启动训练程序一样需要有诸多参数的设置。
在启动程序之前,强烈建议将其中的 --workers 参数设置为 0,因为不同机器下这个功能可能会出问题,设置为 0 最多就是训练慢一点(其含义是使用多进程多线程来进行数据的加载),因此强烈建议设置为 0,如果设置为 0 后没有问题则可以逐步调大,看个人喜恶即可。
然后我们启动训练程序体验一下:
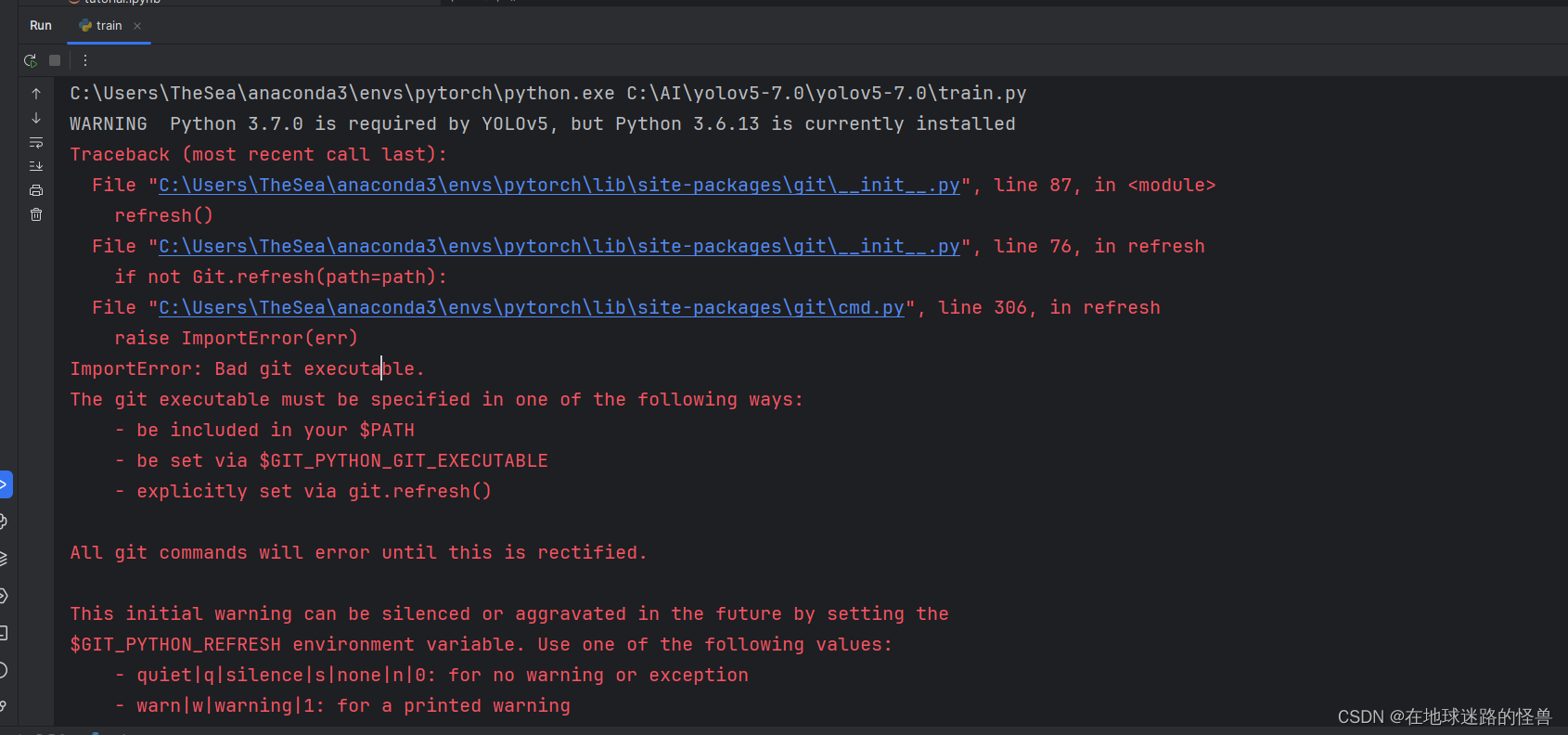
发现报错了,粗看原因貌似是缺乏 git ,因此我们安装 git 即可,安装步骤网上很多,这里不再赘述。
安装完成后再次启动则正常:
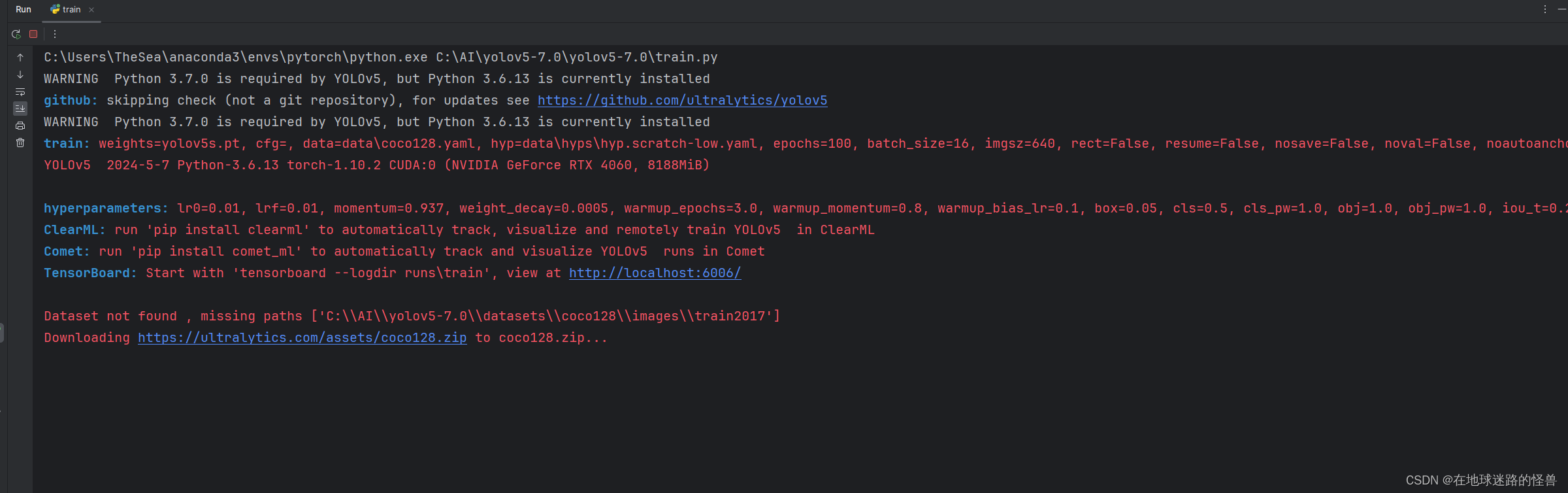
可以发现它会开始下载 coco128 这个数据集,但是大概率会报错捏,没错又是之前的连接超时异常:

老办法,直接 cv 这个链接去 web 下载即可,下载完之后将其放到 Yolo V5 所需要存放该数据集的位置,从启动日志中可以看出:

那么这个数据的存放位置就应该是 yolov5-7.0 这个文件夹下的 datasets 下的 coco128 下的 images 的 train2017:
此时再启动程序,发现就以及开始训练了:
另外因为我们上面没有放到指定文件目录下,程序启动时自动搜索到我们的 coco128 文件然后将其给放到程序指定的目录下了:
然后就可以正常启动运行了。
因为我们短暂的启动了一会儿,因此有些训练结果已经出来了:
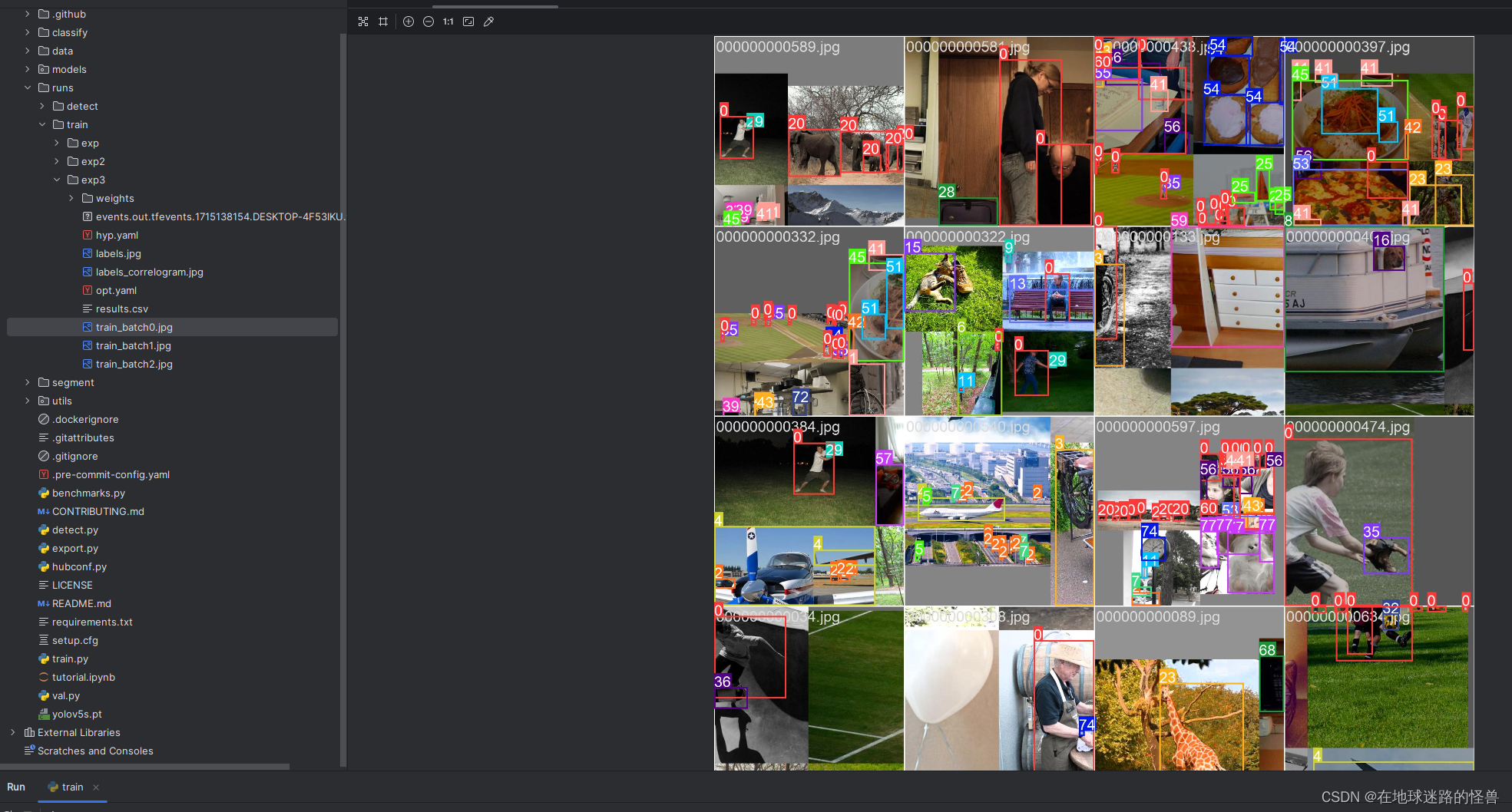
训练结果文件中的各个文件解释
在训练结果中,点开 weights 文件夹:
其中的 best.pt 就是在这次所有训练轮数中训练效果最好的一次的网络模型的训练参数,而 last.pt 则是最后一次训练的模型训练参数。
hyp.yaml 文件是训练过程中对模型设置的一些超参数。
labels.jpg 文件是标注的一些分布。
labels_correlogram.jpg 则是标注的一些相关矩阵信息。
opt.yaml 是在训练过程中一些参数的设置。
results.csv 是训练结果的一些记录。
train_batch0-2 则是训练完的图片的样子。
参数解释
–weights
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
这个和前面的一样,如果是默认的话则此次训练将使用 yolov5s.pt 这个模型的参数进行设置本次训练的参数,也就是设置初始权重参数的路径,但如果我们要从头开始训练的话可以直接将其删除,让其默认为空,从头开始训练我们自己的参数。
–cfg
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
这个参数用来设置模型需要的一些配置文件,这些配置文件声明了模型的结构和一些必要的参数,比如我们之前用的模型 yolov5s,这个可以在 models 文件夹下看见各个模型的 yaml 配置文件:
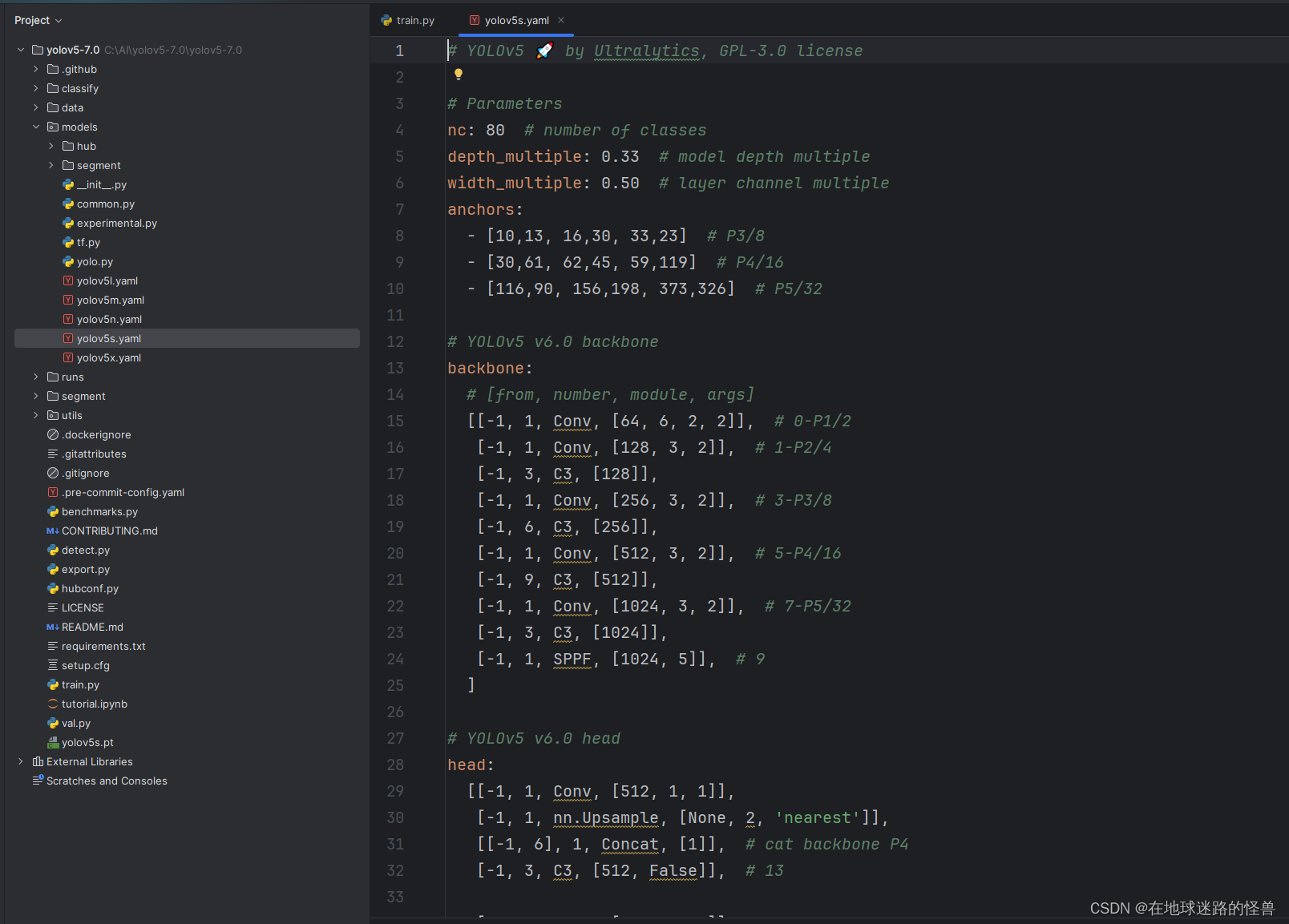
不难发现可以配置比如预测的类别数,模型的深度、模型的宽度等等。
因此这里我们如果不自定义的话,就可以直接 cv 这里现有的模型结构的路径填入该参数即可,这样我们就可以直接用现有的模型结构进行我们自己的训练。
–data
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
data 参数则是指定我们要训练的数据集的相关的一些配置,我们可以在这个文件目录中查看一下:
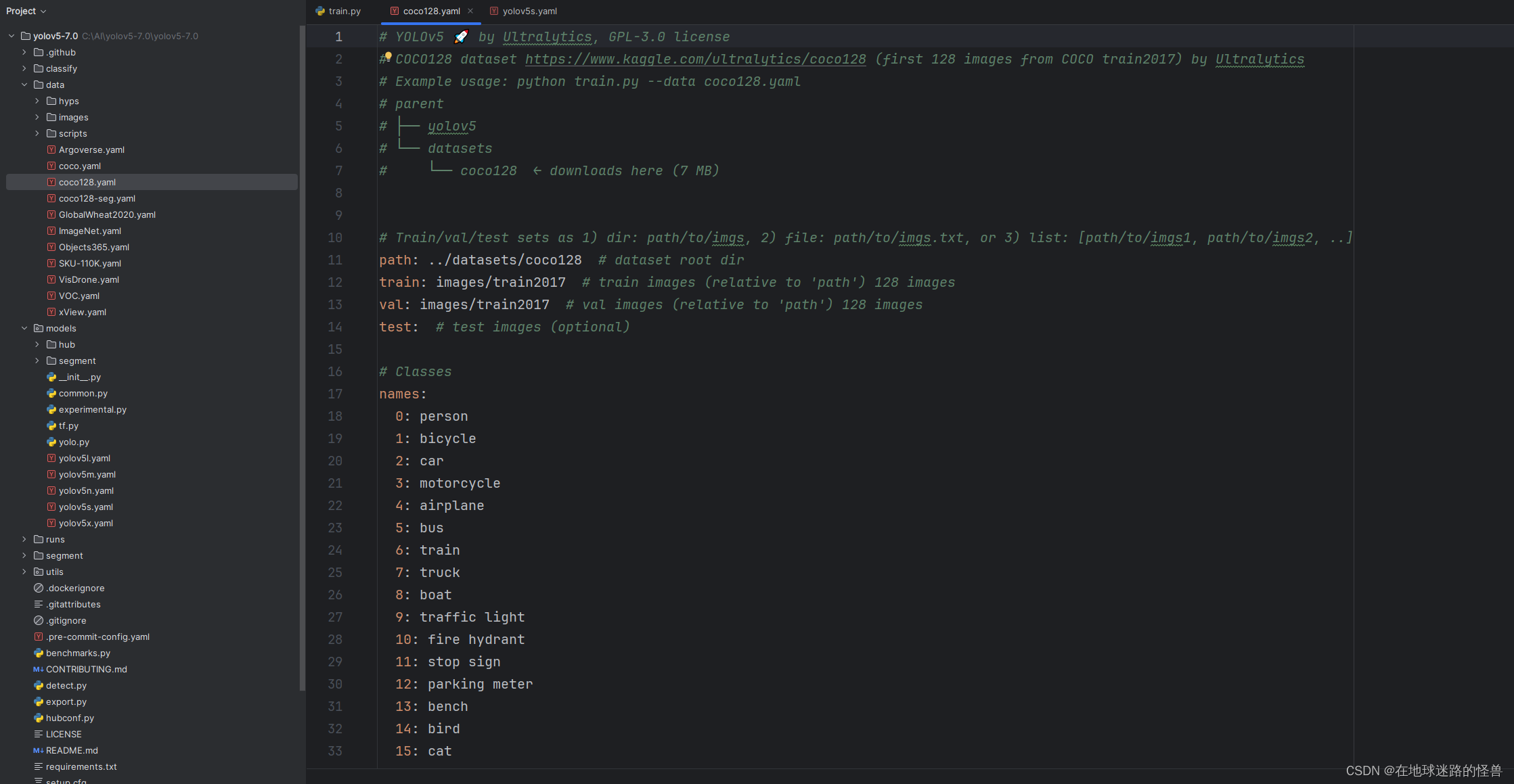
可以看见配置了比如数据集的路径,数据要预测的类别还有数据集的下载路径等。
–hyp
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
设置超参数相关的配置文件用的(超参数用来对模型进行微调),scratch是从头开始的意思,大概含义就是这是一个从头开始训练所需要的配置文件:
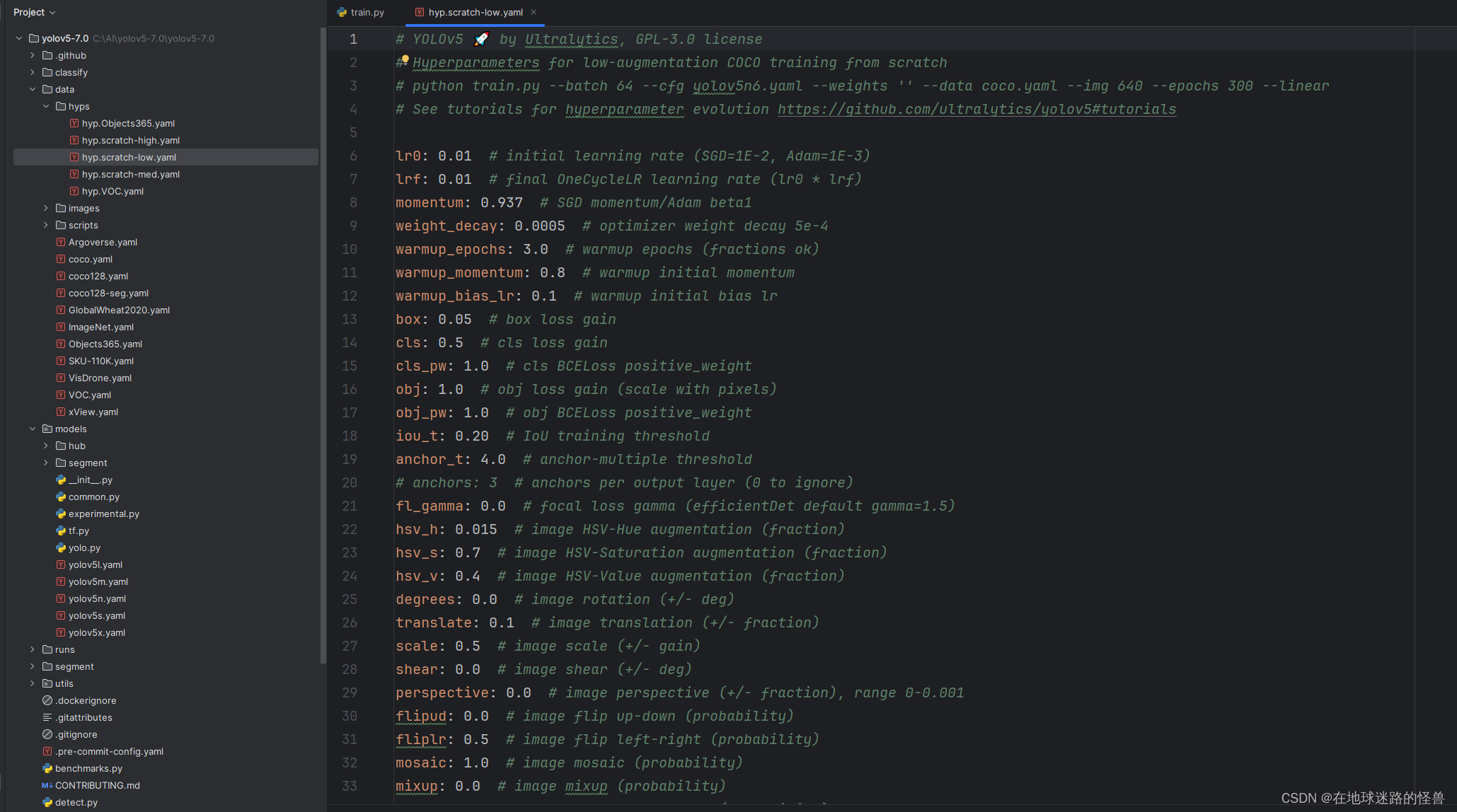
其他的不认识的话,那么 lr 总认识吧,学习率就是一个超参数捏。
–epochs
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
指定训练轮数。
–batch-size
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
指定每一次将多少个数据打包成一个 batch 送入网络当中训练。
–imgsz
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
imgsz 参数是用来在网络计算过程中将我们的输入数据的大小给 Resize 成 640*640 大小以贴合 Yolo 网络计算的,但是最后输出的数据依然会被转换回原来的大小。
–rect
parser.add_argument('--rect', action='store_true', help='rectangular training')
将训练方式设置成矩阵的训练方式。
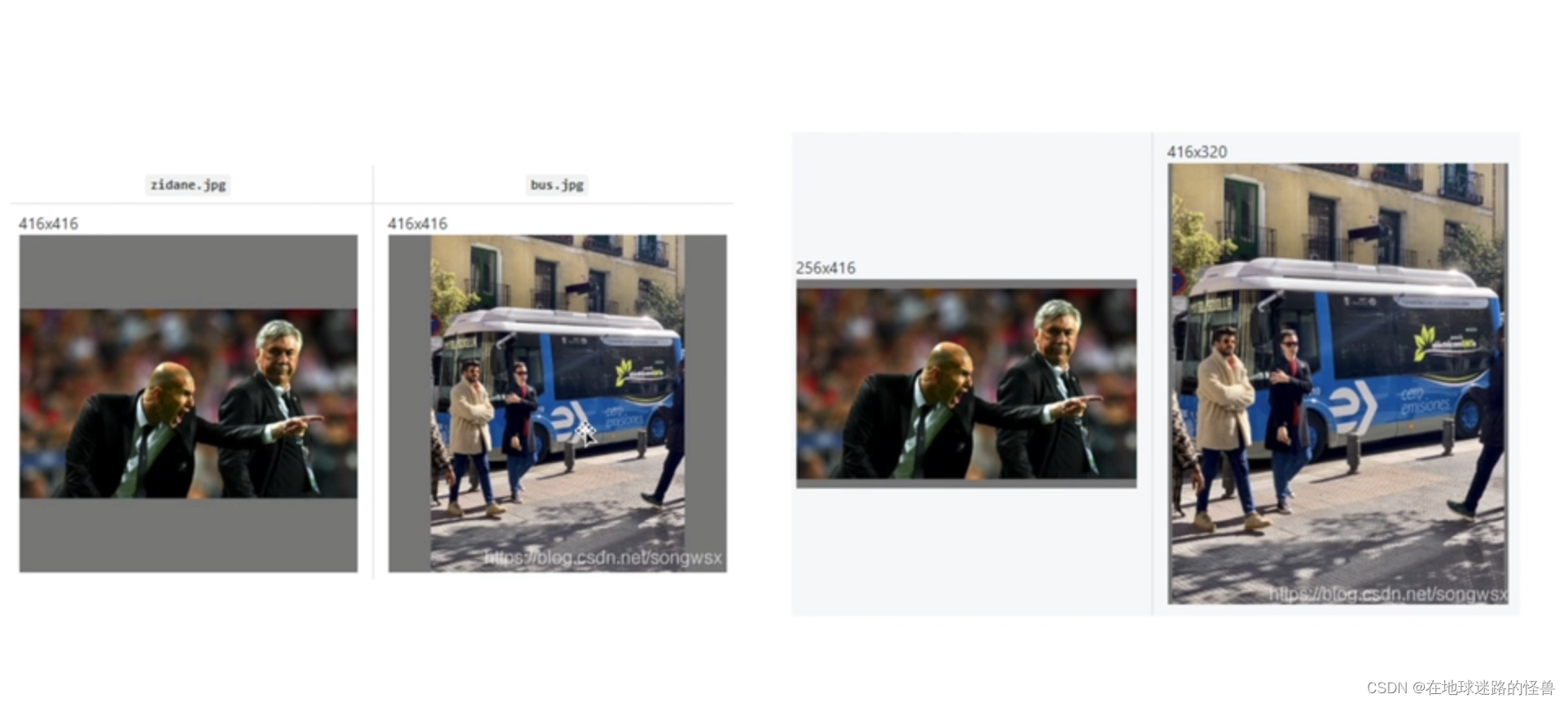
设置成矩阵的训练方式那么从上图可以明显看出,未设置(上图左侧)之前为了让图片大小合适会进行一个方形的填充,这样会添加很多不必要的信息,而设置成矩阵的训练方式之后(上图右侧)可以看见填充的部分少了非常多。
–resume
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
这个参数是询问是否选择从当前最近的一个训练模型结果当中在其基础上再进行训练。
默认情况下是 False,但是如果我们要使用的话并非是指定为 True 即可,而是必须要指定一下我们想选择的最近的一个训练模型结果(注意是之前训练过程中的,不是 Yolo 已经给我们训练好的嗷)的路径,例如:
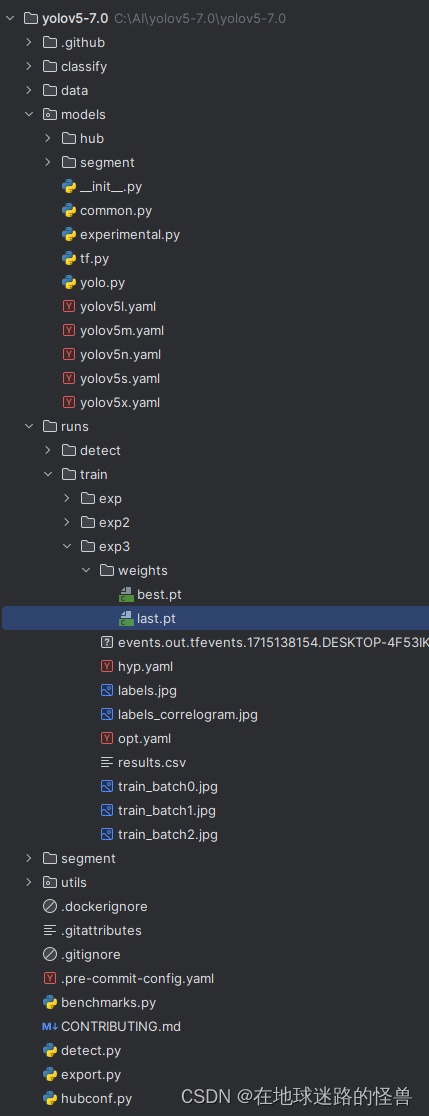
如上图中的 last.pt 就可以设置进这个参数当中,这样其开始训练时就会从这个模型中开始训练(那么原来的训练的参数就会被替换掉,就访问不到了嗷)。
–nosave
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
在模型训练中会有很多的 epoch,如果设置该参数生效,则表示训练过程中只会保留最后一次 epoch 训练的模型结果,也就是权重数据(即 pt 文件)。
–noval
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
是否只在最后一次 epoch 进行测试评估。
–noautoanchor
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
是否采用具有锚点的模型。
在以前,如果要从图片当中选取检测一个目标的话,我们需要在图片上进行遍历,比较耗时费力(比如滑动窗口),而现在较多都采用锚点或者锚框的方式,这样就可以少遍历一些会更快。
这个参数可以看到是默认开启的,所以不用动它。
–noplots
parser.add_argument('--noplots', action='store_true', help='save no plot files')
这个参数用于控制是否在训练或验证过程中保存绘图文件。
在YOLOv5的训练或验证脚本中,通常会有一些代码块用于生成并保存各种绘图文件,例如损失函数曲线图、预测结果可视化等。通过检查 --noplots 参数的值(True 或 False),脚本可以决定是否执行这些绘图相关的代码块。
–evolve
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
这个参数用来进行对超参数调优,也就是增强的意思。
–bucket
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
没用,不管。
–cache
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
选择图片缓存的位置,默认是内存 ram 中,也可以换成磁盘 disk 中。

–image-weights
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
大概意思是该参数被设置的话,会从上一轮的测试过程中对于哪些测试图片比如对于哪些部分测试效果不是很好,那么就会在下一轮的训练过程中对这些图片部分再加上一些相关权重。
–device
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
指定训练的设备,不用管。
–multi-scale
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
是否对图片尺寸进行变换。
–single-cls
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
设置数据集是单类别的还是多类别的。
–optimizer
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
用于指定训练过程中使用的优化器。
choices=[‘SGD’, ‘Adam’, ‘AdamW’]:这是一个列表,指定了 --optimizer 参数可以接受的值。用户只能从这三个选项中选择一个作为优化器的类型。如果用户尝试指定不在这个列表中的值,argparse 将抛出一个错误。
default=‘SGD’:如果用户没有在命令行中明确指定 --optimizer 参数的值,那么默认值将被设置为 ‘SGD’。
–sync-bn
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
该参数用于控制是否使用同步批量归一化(SyncBatchNorm)。
但需要注意的是,SyncBatchNorm 仅在分布式数据并行(DistributedDataParallel,简称 DDP)模式下可用。
SyncBatchNorm 是一种在分布式训练中使用的批量归一化技术,它可以在多个 GPU 之间同步批次统计信息(均值和方差),以确保在分布式训练过程中批量归一化的效果与在单个 GPU 上训练时相同。这对于提高分布式训练的稳定性和收敛性非常重要。
在 YOLOv5 中,如果用户希望在分布式训练中使用 SyncBatchNorm,他们可以在命令行中指定 --sync-bn 参数。然而,需要注意的是,只有在 YOLOv5 的配置和代码支持 DDP 模式时,这个参数才有效。如果用户在不支持 DDP 的情况下尝试使用 --sync-bn,可能会导致错误或不可预测的行为。
–workers
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
之前提过,是否采用多线程多进程来加快数据加载的过程,建议是设置为 0 。
–project
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
设置保存训练结果的文件路径。
–name
parser.add_argument('--name', default='exp', help='save to project/name')
设置保存训练结果的文件名称。
–exist-ok
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
该参数表示如果我们没有指定该参数,那么我们会发现在每次执行完训练后 Yolo 都会给我们创建一个新的文件夹叫 expN,如果指定了该参数的话那么 Yolo 就会只在 exp 文件夹下追加训练结果了:
–quad
parser.add_argument('--quad', action='store_true', help='quad dataloader')
这个参数不知道有什么用,跳!
–cos-lr
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
这个参数是用于启用余弦学习率调度器(cosine learning rate scheduler)的。
余弦学习率调度器是一种优化技术,用于在训练神经网络时调整学习率。它基于余弦函数来平滑地减少学习率,从而在训练后期提高模型的稳定性和性能。在训练过程中,随着迭代次数的增加,学习率会按照余弦函数的形状逐渐减小,这有助于模型在训练后期更好地收敛到最优解。
在 YOLOv5 中,–cos-lr 参数允许用户选择是否使用余弦学习率调度器来训练模型。如果用户指定了 --cos-lr 参数,那么 YOLOv5 将使用余弦学习率调度器来调整学习率;否则,它将使用默认的学习率调度策略(如果有的话)。
–label-smoothing
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
这个参数用于控制标签平滑(label smoothing)的强度。
在标签平滑中,epsilon 是一个介于 0 和 1 之间的值,用于控制标签的平滑程度。当 epsilon 为 0 时,不使用标签平滑;当 epsilon 接近 1 时,标签将被平滑得更严重。
标签平滑是一种正则化技术,用于防止模型在训练过程中过度自信地预测类别标签。在标准的分类任务中,模型的目标通常是学习一个将输入映射到 one-hot 编码的输出的函数。然而,one-hot 编码可能会导致模型在训练时过于自信,从而过拟合训练数据。通过标签平滑,我们将真实的标签分布替换为一个稍微平滑的分布,其中真实标签的概率被降低,而其他标签的概率被增加(但通常仍然很小)。这有助于模型在训练时保持一定的不确定性,从而提高其在测试数据上的泛化能力。
–patience
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
这个参数与早期停止(Early Stopping)策略相关,用于设置早期停止的“耐心值”(patience)。
在早期停止策略中,模型会在连续若干个 epoch(这里由 --patience 参数指定)的验证损失(或其他评估指标)没有改善时停止训练,以避免过拟合。
在训练深度学习模型时,早期停止是一种常用的正则化技术,用于防止模型在训练数据上过拟合。通过设置 --patience 参数,用户可以控制模型在多少个 epoch 内没有看到性能提升时停止训练。这有助于节省计算资源,并可能提高模型在测试集上的性能。
例如,如果 --patience 设置为 10,并且模型在连续 10 个 epoch 的验证损失都没有降低,那么训练就会提前停止。这可以防止模型在训练数据上过度拟合,从而提高其泛化能力。
–freeze
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
用于指定在训练过程中应该冻结(即不更新权重)的层。
在帮助信息中可以看到,它给出了两个示例:backbone=10 表示冻结 backbone 的前 10 层,first3=0 1 2 表示冻结前三个层(索引为 0、1、2 的层)。

–save-period
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
该参数用于指定每隔多少个 epoch 保存一次模型的检查点(checkpoint)。
如果设置的值小于 1,那么保存检查点的功能将被禁用。
在训练深度学习模型时,保存检查点是一个很重要的功能。它允许用户在训练过程中间断后(比如由于电源中断、硬件故障等原因)恢复训练,而不需要从头开始。此外,如果在训练过程中模型在某个 epoch 达到了最好的性能,用户也可以加载这个检查点来评估模型或进行后续处理。
通过 --save-period 参数,用户可以灵活地控制保存检查点的频率。例如,如果用户设置 --save-period=10,那么训练脚本将在每 10 个 epoch 后保存一次检查点。如果设置 --save-period=-1(默认值),那么保存检查点的功能将被禁用。如果设置 --save-period=1,那么训练脚本将在每个 epoch 后都保存检查点,但这可能会占用大量的磁盘空间,并且可能导致训练速度变慢(因为写磁盘操作通常比内存操作要慢)。
–seed
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
该参数用于设置全局的训练随机种子。
在深度学习和机器学习中,设置随机种子是非常重要的,因为它可以确保实验的可重复性。随机性通常存在于多个地方,如权重初始化、数据打乱、正则化操作等。通过设置一个固定的随机种子,用户可以确保在相同的实验条件下得到相同的结果,从而方便进行模型的比较和调试。
需要注意的是,即使设置了随机种子,由于硬件、操作系统、库版本等因素的差异,仍然可能存在一些不可控的随机性。但是,通过设置随机种子,用户可以大大减少这种随机性,提高实验的可重复性。
在训练深度学习模型时,使用 --seed 参数来设置随机种子是一个常见的做法。这有助于确保在不同的实验或不同的研究人员之间得到一致的结果。
–local_rank
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
看见 DDP 分布式相关的字样就可以略过了,我们用不到。
日志相关的参数

剩下的像上图这些都是日志相关的参数设置了,默认即可,我们一般用不到。
要用到的话查阅官方文档即可。
一个简单的训练模板

就修改了一下上图中的几个参数,当然你也可以调成别的,我就这么用了。
如何制作和训练自己的数据集
官方文档的方法
制作自己的数据集,主要有下面几种方式。
1、有数据集的情况下,先对数据集进行标注
2、没数据集的情况下,人工手动收集数据集-人工标注
3、没数据集的情况下,人工手动收集数据集-半人工标注
4、仿真数据集(使用 GAN 网络或者数字图像处理的方式)
我们这里主要讲如何采用人工手动标注的方式来制作和训练自己的数据集(其他的感兴趣可以自己去了解)。
手工标注其实在 Yolo 的官方文档中都是有说怎么进行操作的:
点击上图中的 Train Custom Data:
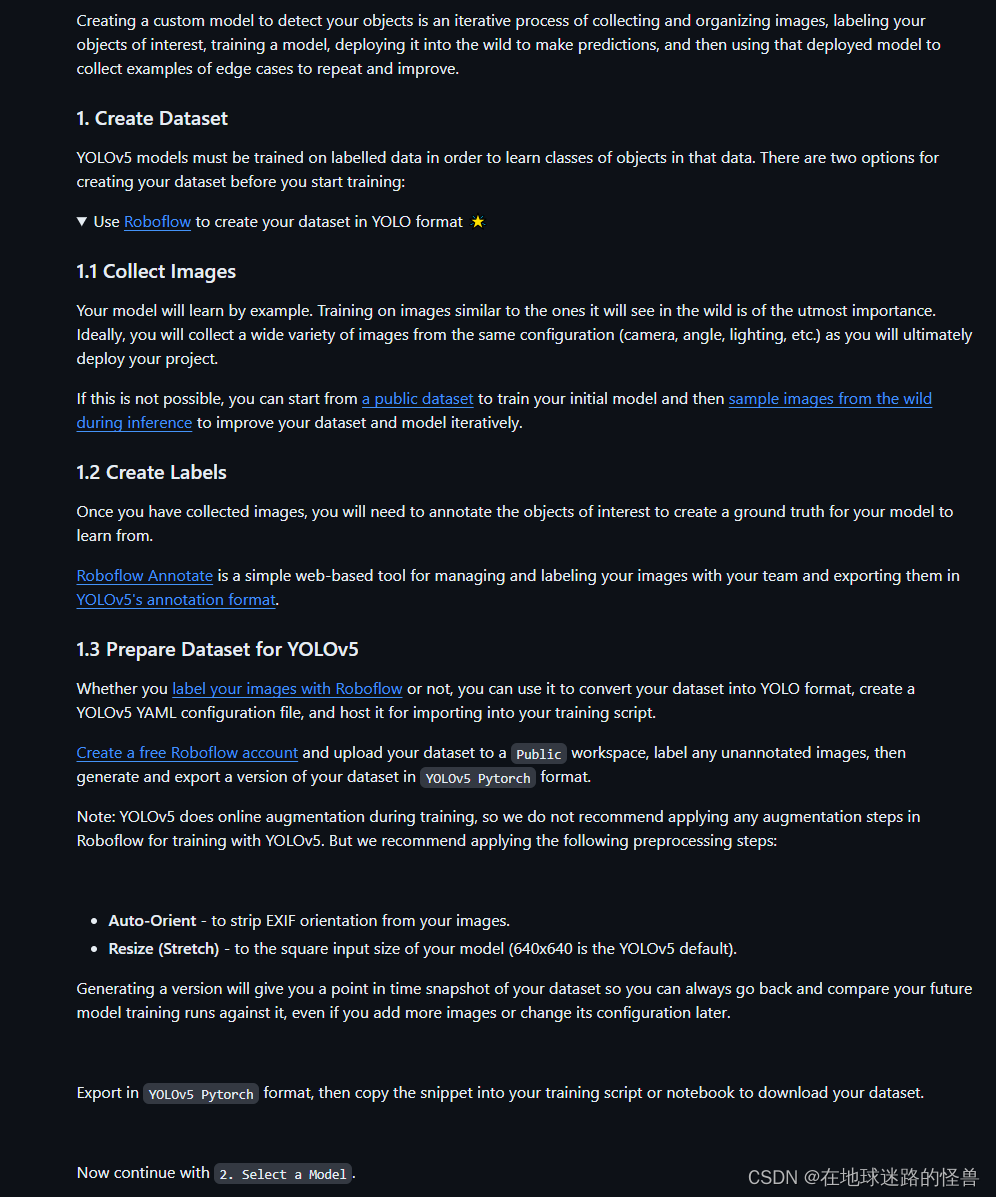
可以看见步骤写的是蛮清楚的。
我们来实现一下。
1、创建一个数据集的根目录。
2、然后分别创建训练集测试集的文件夹的相对路径。
3、然后指定一下我们训练当中有多少个类别。
4、 最后还有个 list 列表来指定这些类分别带有什么含义。
将这些内容全部放在一个 yaml 配置文件中即可。
这个过程我们可以从之前的 Coco128.yaml 文件中了解一二:
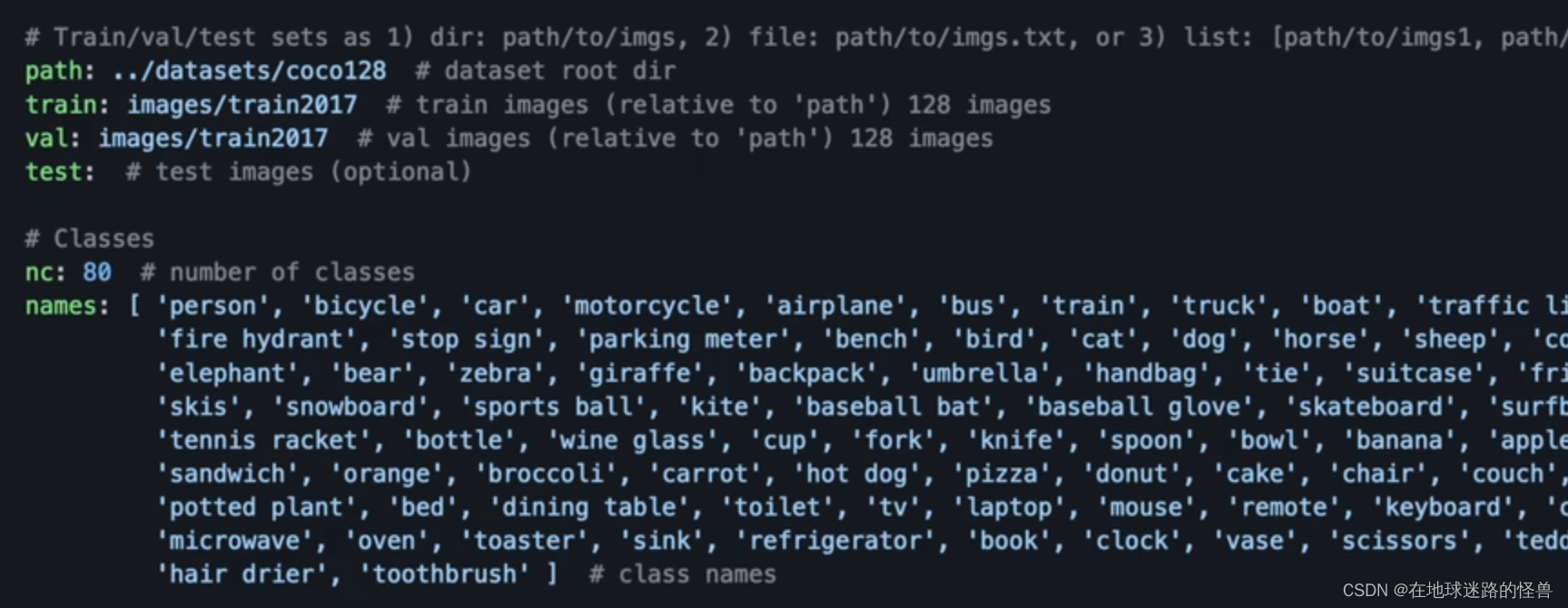
仿照着它写即可。
1、实操:收集数据集
这里我们就在网上搜几张关于车的图片吧:
2、实操:打标签
然后现在要打标签,可以用一个在线工具来完成这个事情,链接是: Make Sense
进入官网:
点击右下角,选则 get started:
点击中间的位置,上传图片:

上传完之后如下:
此时是在询问用于目标检测(Object Detection) 还是图像识别(Image recognition)。
我们选目标检测:
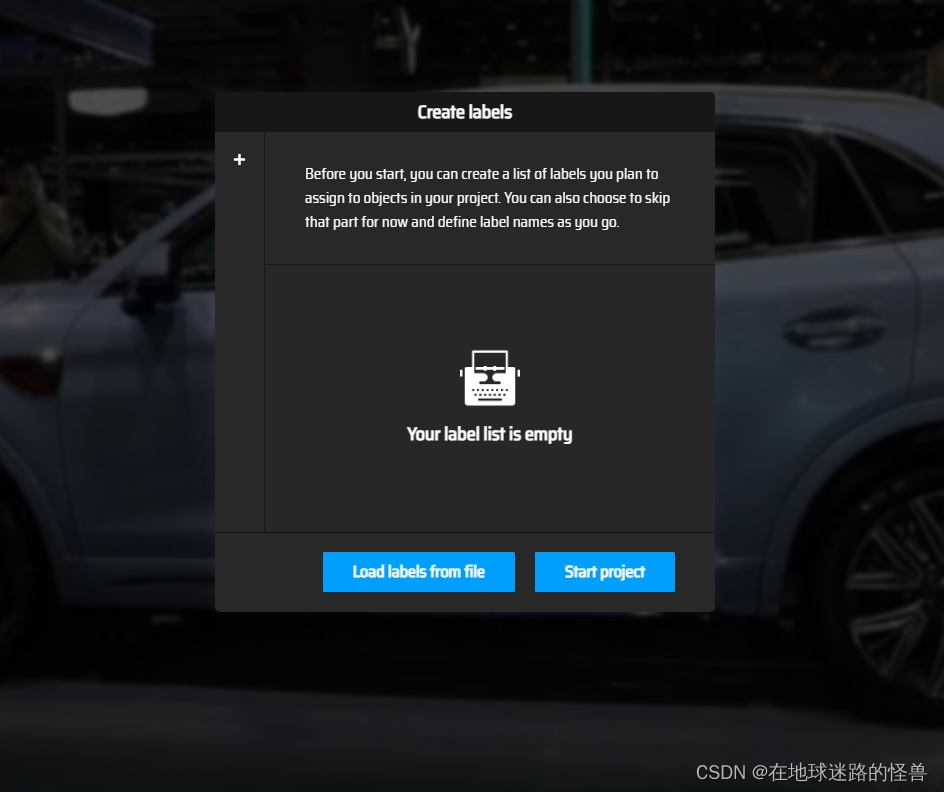
这里是选择进行标签创建的方式,我们可以选择 Load labels from file,也就是先写一个标签列表的 txt 文件然后上传上去自动识别即可。
准备一个 txt 文件,注意每个类别写在一行里面:

这里我们只写了两个类别。
然后我们选择上传这个 txt 文件:
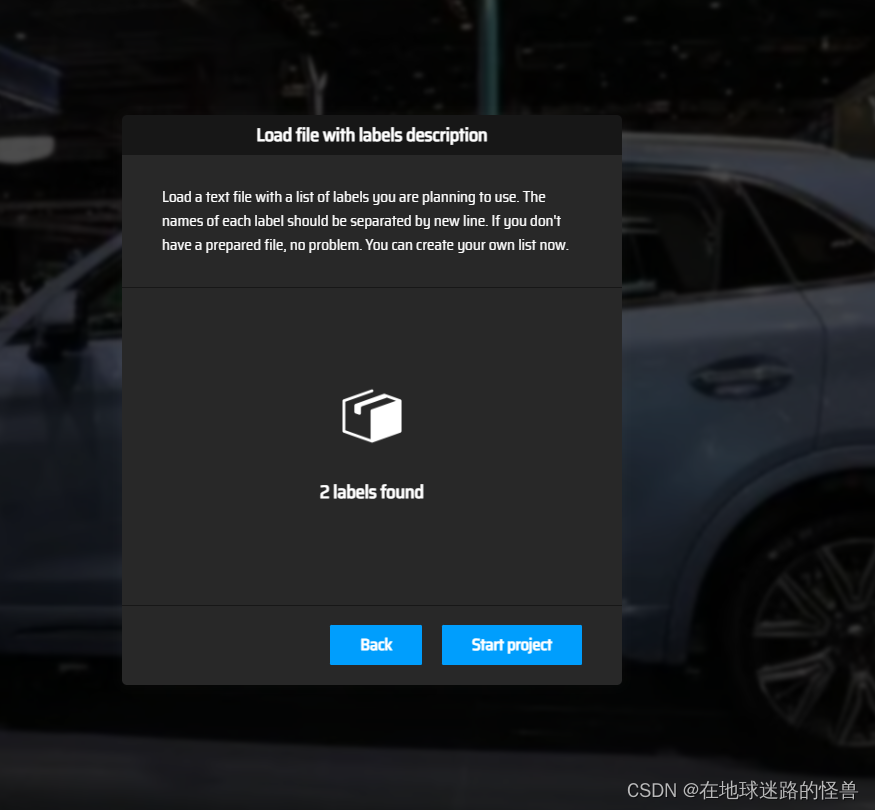
然后点击 Start project 即可。
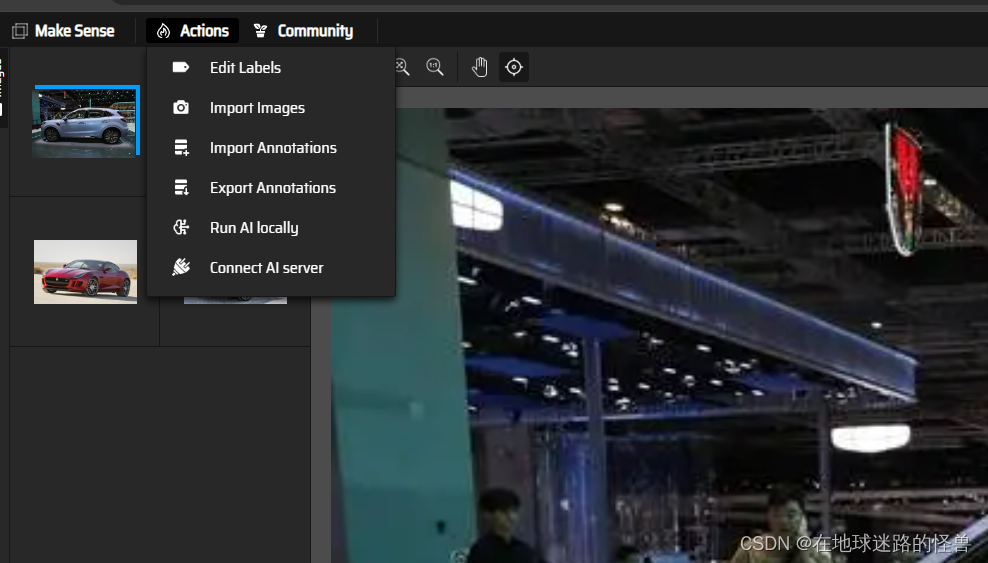
左上角的 Actions 下可以有多种操作执行,比如编辑标签,导入图片、导入标注导出标注等等:
在页面右侧是我们标注的方式:
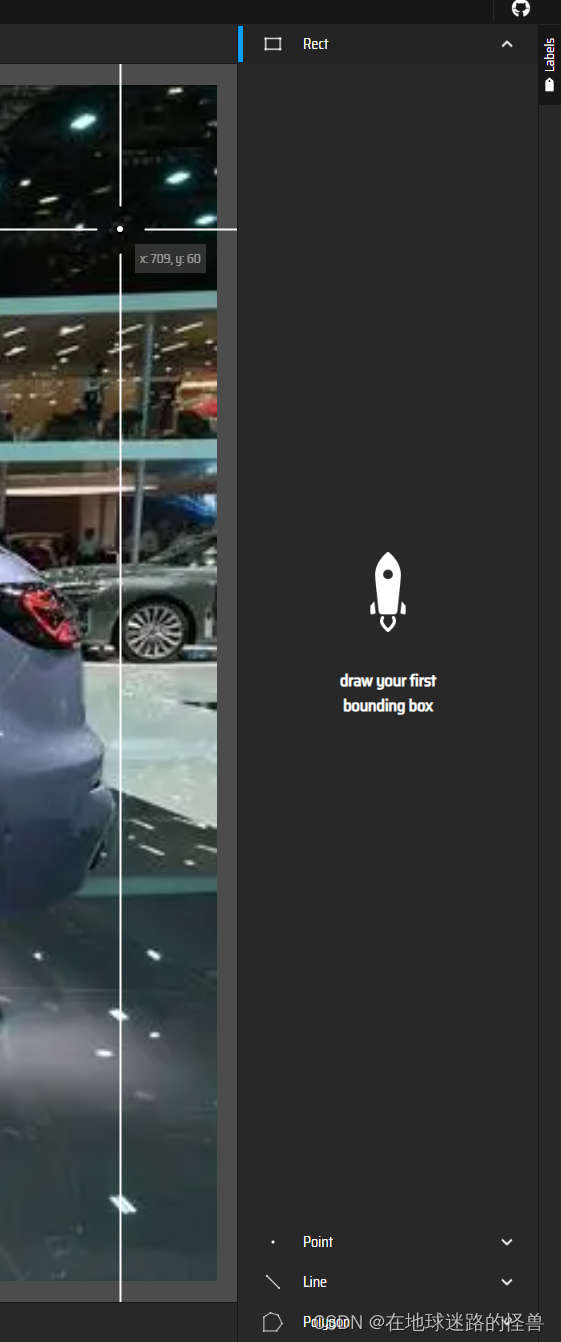
可以使用矩阵标注、点标注、线标注以及多边形标注。
我们一般用矩阵标注,也就是选择上图的 Rect 工具,然后去图中将我们的检测物体进行框选起来:

此时在右侧就会出现一个 Select label 字样,我们选择 Car:
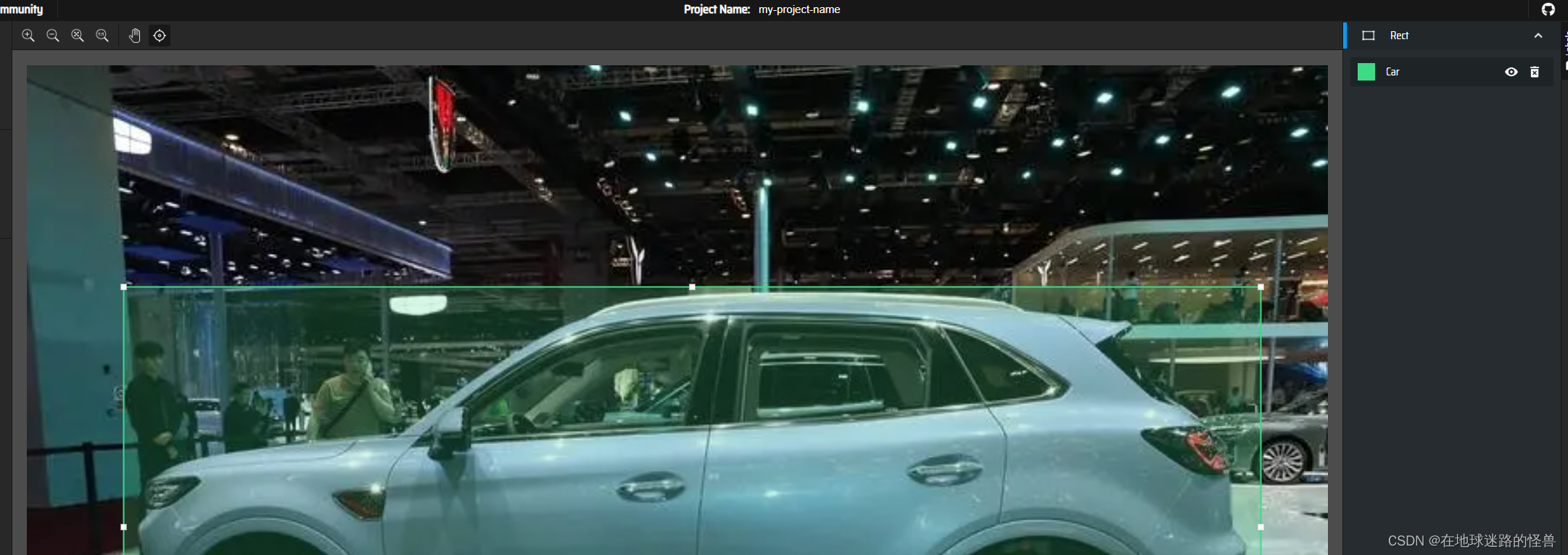
其他的依次类推,每个图框选出一个标签嗷:
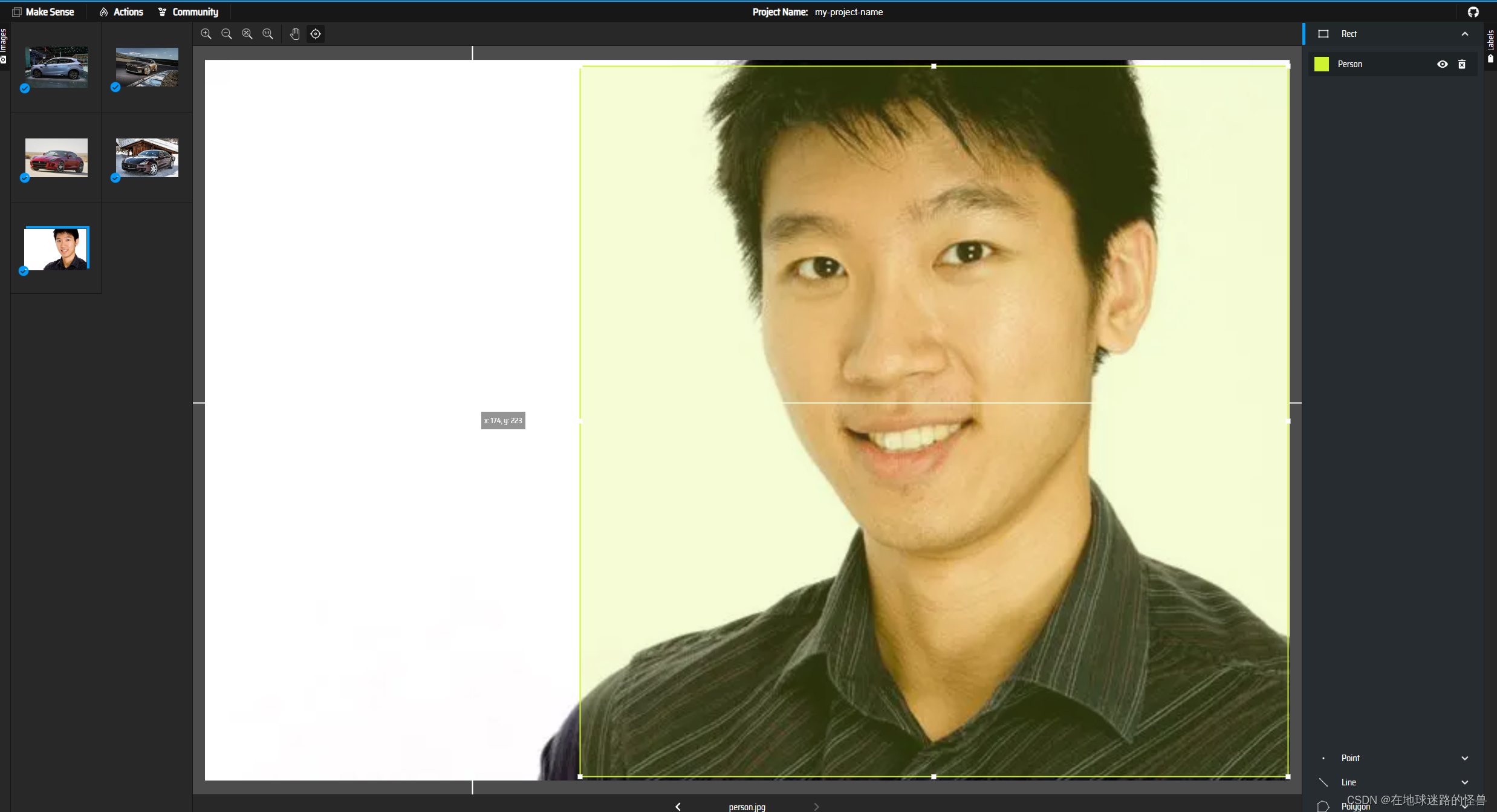
刚刚图弄少了,这里再加上一个人的图片吧,然后其预测为人即可,也就是共有五张图片。
这就是手动标注的过程,现在全部标注好之后,我们可以从 Action 选项下面的 Export Annotations 来导出我们标注好的数据:
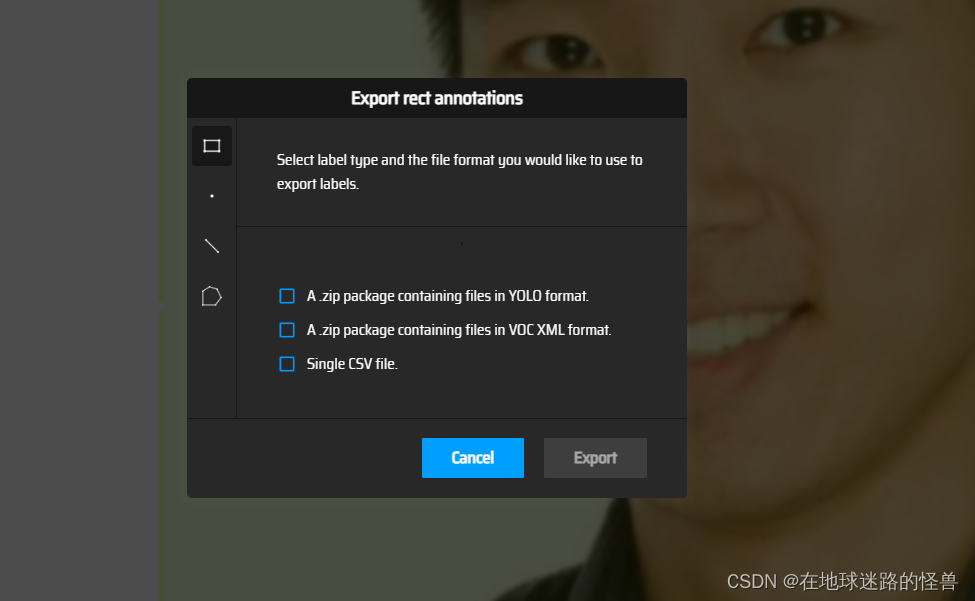
这里我们肯定选用 YOLO 格式的进行导出啦,选中 YOLO 处勾上,然后 Export 导出即可。
将下载下来的压缩包解压完成之后,得到下面的东西:
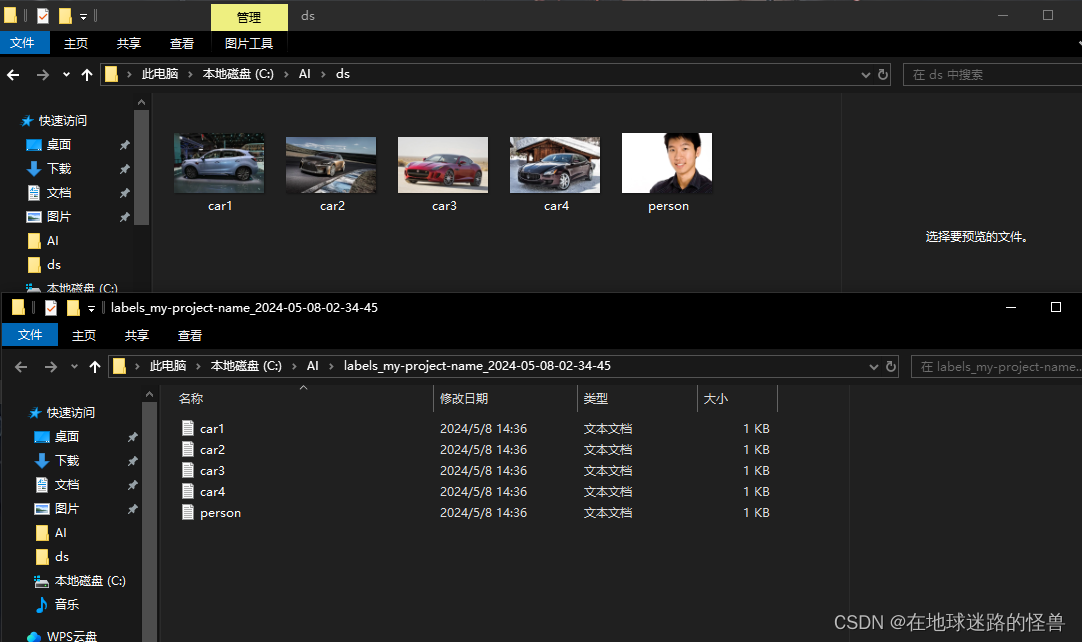
可以看见和我们的图片数据是一一对应的。
现在我们的数据集和标注都已经准备完了,点开一个 txt 文件可以看到:

从左往右第一个 0 表示其为类别 0,也就是 Car。
我们也可以打开 person 的那个进行查看:

可以看见 person 的类别就是 1,后面的数据则是一些图片的特征数据。
3、实操:归一化操作
从官网上面的示例可以看见 txt 文件内部的那些数值都表示什么意思,如果是自己纯手动打标注的话,那就还需要进行下面这一步归一化的过程(就得自己纯算了,必须要变化到 0 到 1 的区间范围内),我们这里因为导出的时候就是按照 Yolo 格式的,因此省了计算归一化的这个过程:
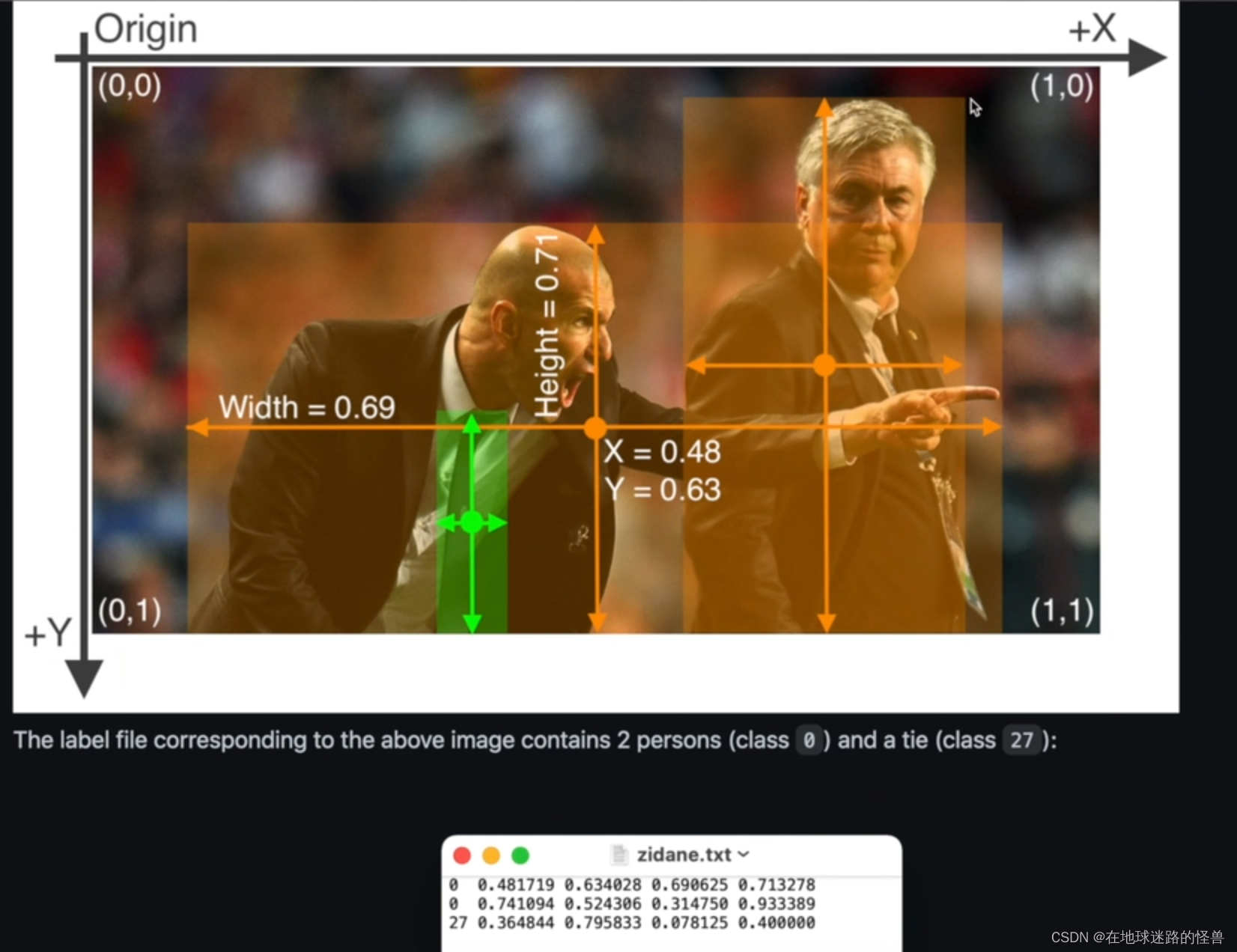
4、实操:设置数据文件夹
这一步对于不同的 YoloV5 版本设置方法不一样(但其实都是共通的),我这里介绍官方更推荐的方式,其实就是仿照 Yolo 跑官方数据集的方式,如之前的 coco128 数据集,不难发现其位于与 yolov5 工程目录同级目录下的 datasets 下:
因此为了模仿它的写法,我们也将我们自己的数据集放到这里,命名为 mydata(这个名字可以随便写嗷)。
mydata 内也模仿 coco128 的形式,设置两个文件夹:

但这里的名字就不可以随便写了,记得一定要叫 images 和 labels。
分别在images和labels目录下创建一个 train 文件夹(这个名字也不能乱取),在 /images/train 目录中放上我们的训练数据集:
在 /labels/train 目录中放上我们数据所对应的标注集:
至此文件目录就创建完毕啦,如果还有测试数据集和验证数据集的话再各自往 images 和 labels 文件夹中创建对应的 val 文件夹和 test 文件夹即可,必要时可以查阅官方文档。
5、编写 yaml 配置文件
我们在之前的学习中知道,如果要进行训练的话,我们是通过设置参数 --data 来进行的,而该参数会用到一个 yaml 配置文件,因此我们来编写这个东西。
直接复制 coco128.yaml 进行更改即可:
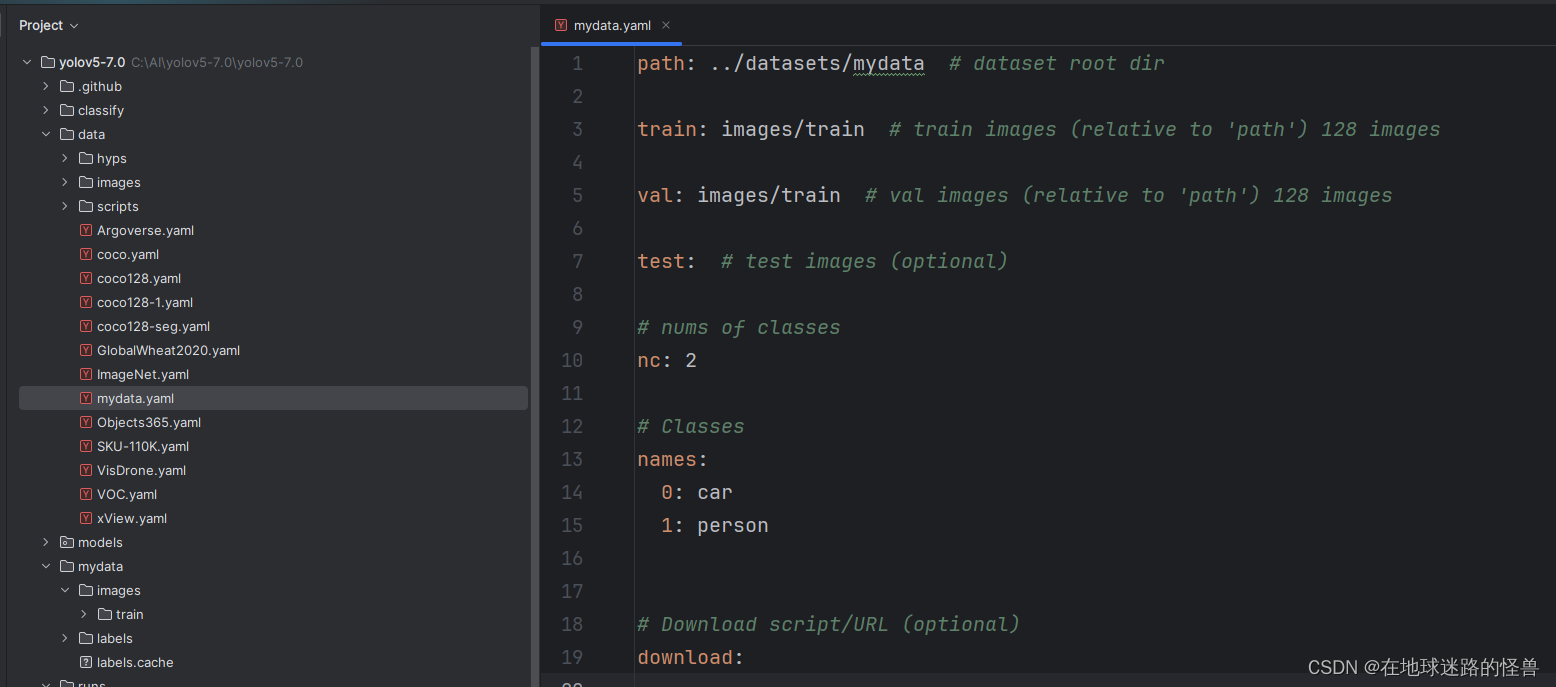
更改内容如下:
6、改变参数启动训练
启动参数设置如下:
这里主要就是改一下 --data 参数,让其索引到我们自己的数据集文件目录下即可。
启动:
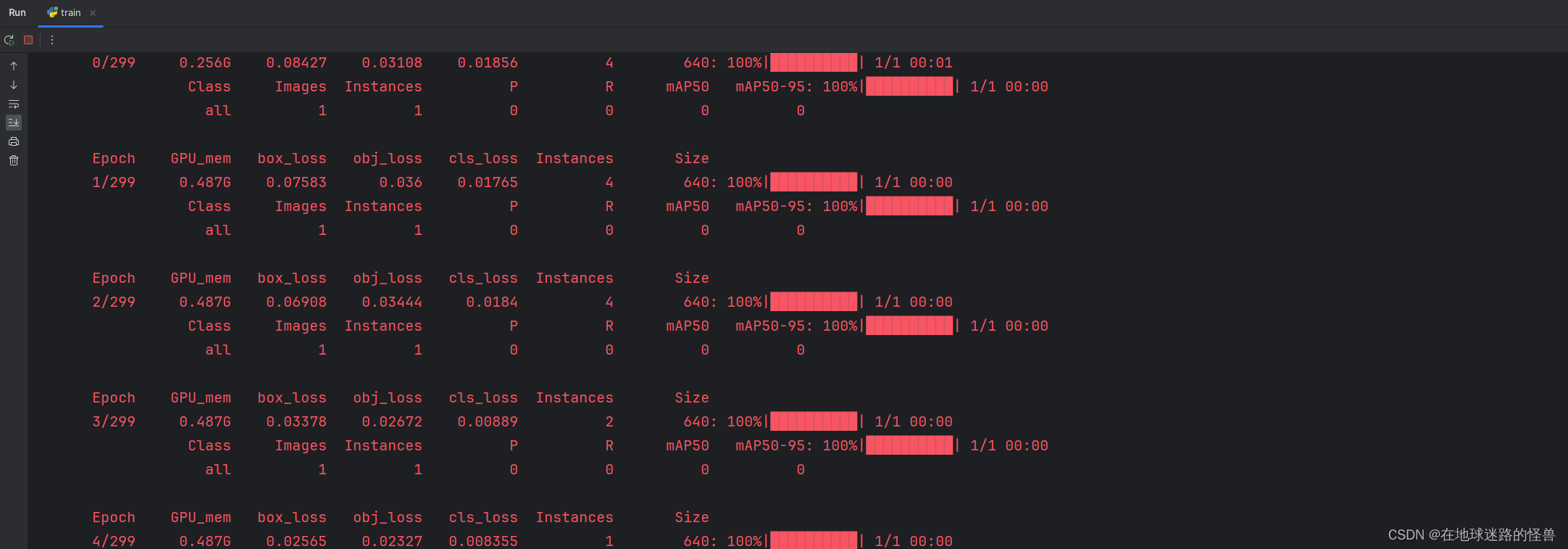
然后 Yolo V5 的学习与使用模块就结束啦!
一个非常坑爹的错误
我在自定义数据集进行模型训练时出现过一个错误:
No labels found in C:\AI\yolov5-7.0\datasets\mydata\labels\train.cache, can not start training.
我被这个问题折磨了很久,最后终于靠着一点点警觉以及经典的控制变量法找出了问题所在,是我在百度上找的图片有问题,也就是我的训练数据集有问题才导致了这个问题。
因为我是直接在网页上点击右键保存的,而其格式如下:
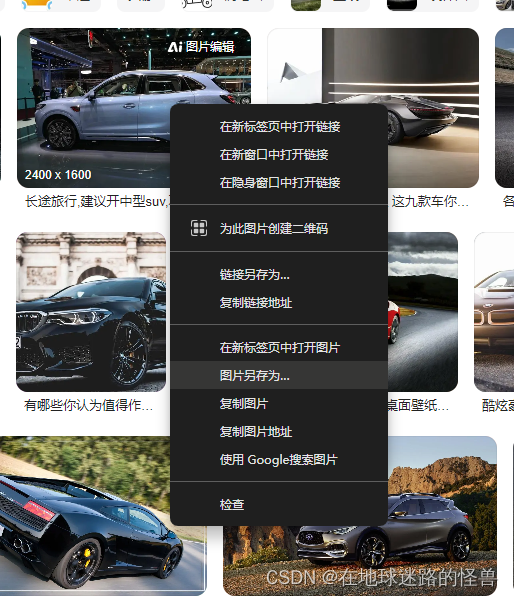
保存时可以看到其是以 .webp 结尾的:
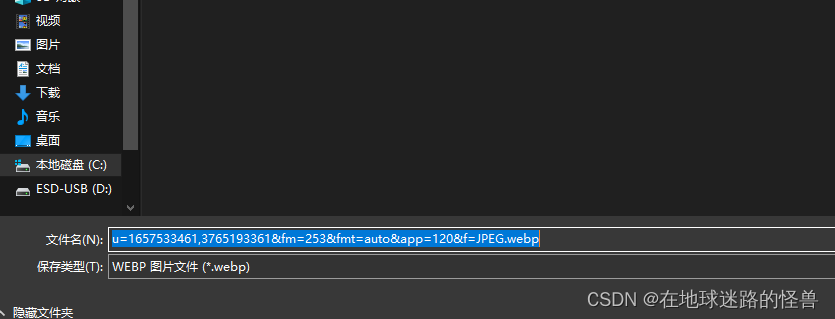
虽然我已经将其改成了 .jpg 结尾的图片格式,但是依然对我跑模型产生了上述错误的影响,因此应该直接点击正常的下载:
或者是直接截图亦或是其他的什么方式获得图片,至于为什么 .webp 格式的图片会有问题我也不清楚,我就是这么做然后就解决了。
科普一下 .webp 的图片格式吧:

















 3478
3478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











