







多目标跟踪算法

我们也可以称之为 Multi-Target-Tracking (MTT)。
那么多目标跟踪是什么?

不难看出,跟踪算法同时会为每个目标分配一个特定的 id 。
由此得出了目标跟踪与目标检测的区别(似乎都是用方框来框出目标捏?):

从上图不难看出,目标跟踪需要在检测的基础上进一步做数据关联,也就是说,多目标跟踪需要考虑两帧之间哪两个目标属于同一个目标。
这就是和目标检测的区别。
那么为什么需要多目标检测呢?
很明显是由市场需求决定的:

接下来我们从五个方面来介绍多目标跟踪相关知识。
多目标跟踪流程
多目标跟踪算法大多由以下四步组成:

举例如下:
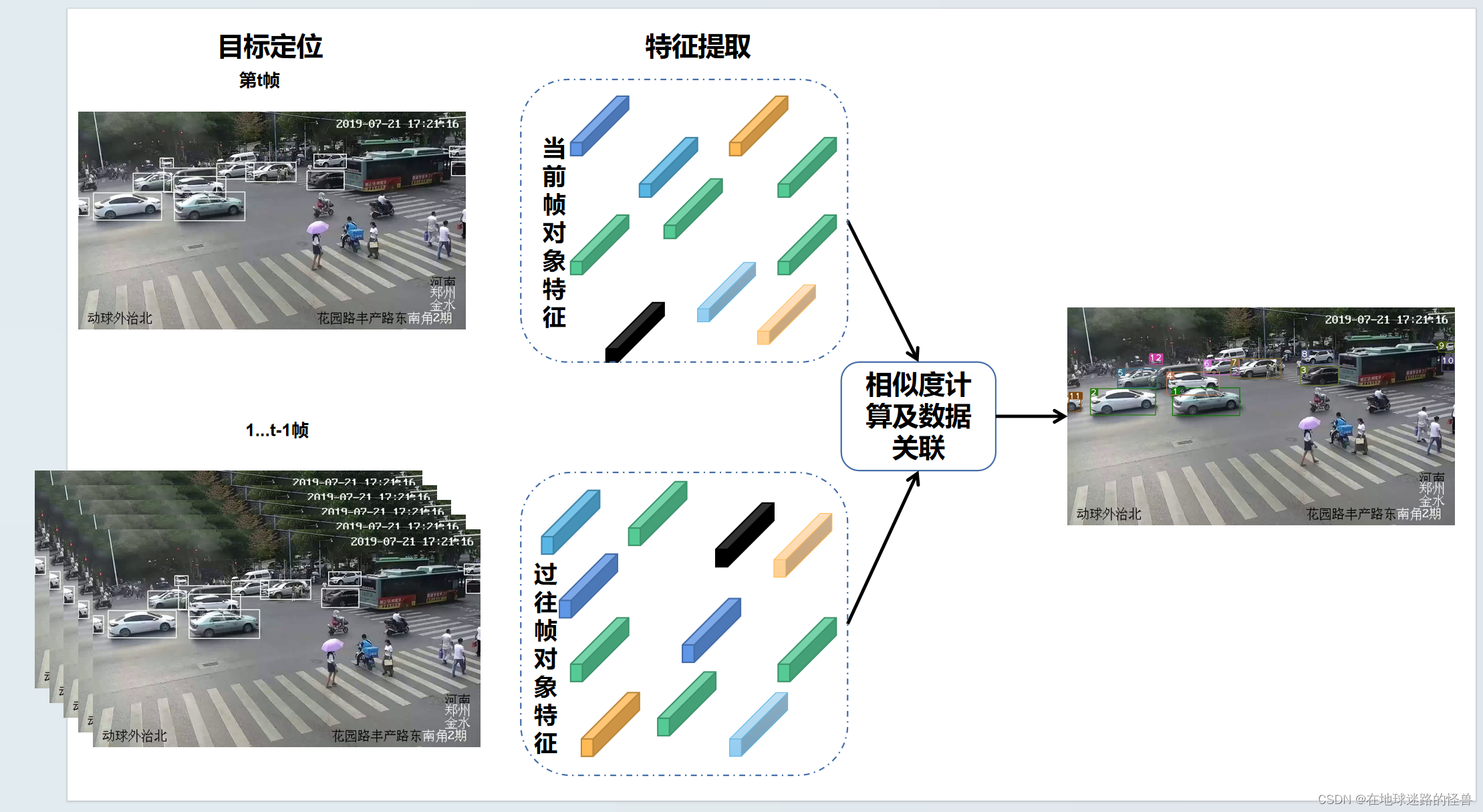
首先,我们将一段视频划分成帧并输入到多目标跟踪算法中,假设现在我们运行到了第 t 帧,通过一系列特征提取算法来获取当前帧中每个检测目标的特征。
这些特征可以是外观特征,也可以是运动特征,然后把每一个目标的特征与前 t - 1 帧中的跟踪对象特征进行相似度计算以及数据关联,得到最终的跟踪结果。
多目标跟踪算法的分类
在本节末有更加详细的各个算法的 AI 解释,这里先简单的介绍与一下。
最主要有以下三种分类方式,首先可以将多目标跟踪算法分为:Detection Based Tracking 或 Detection Free Tracking。
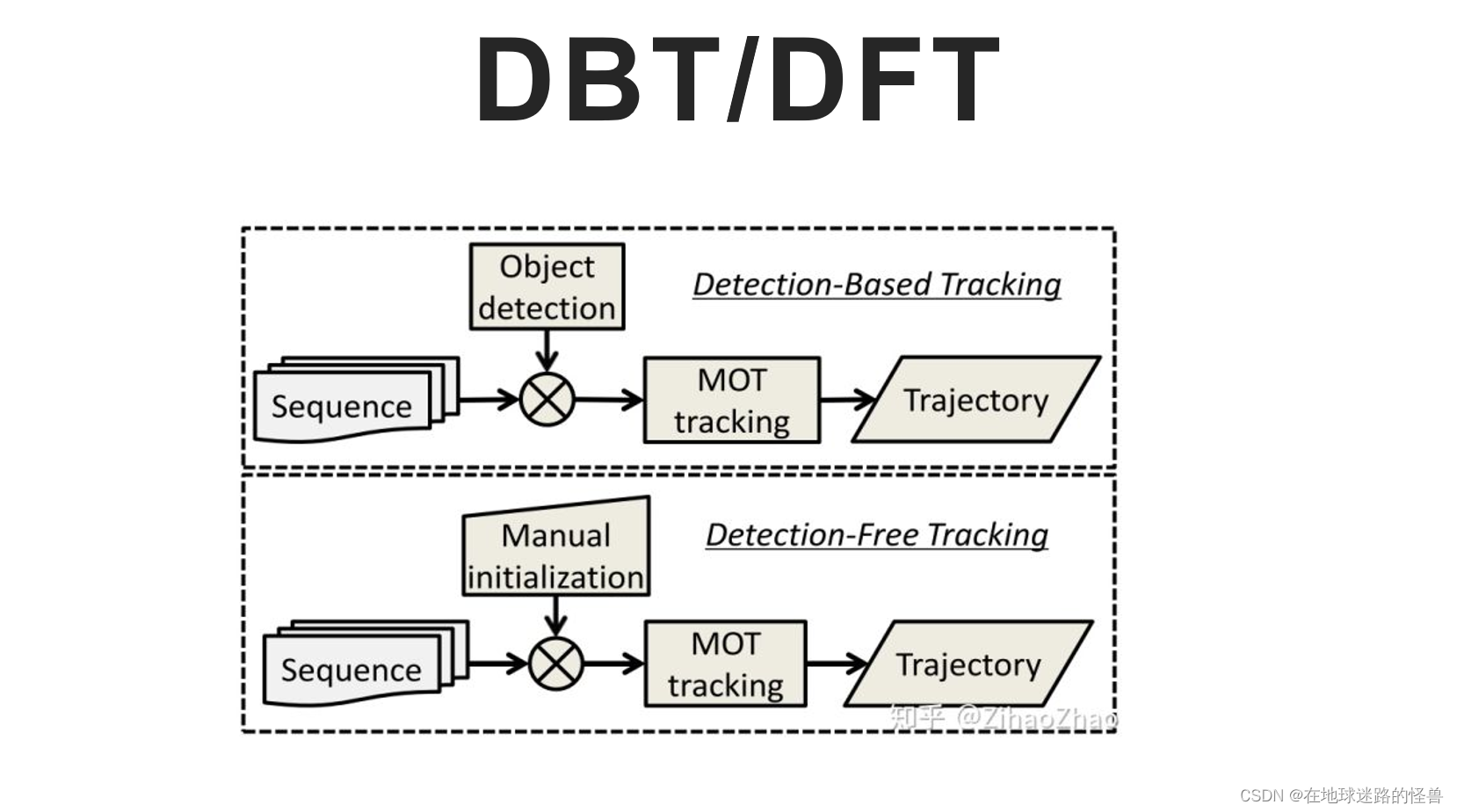
这种分类方式是从检测结果的输入角度进行的。
Detection Based Tracking(基于目标的追踪)是指采用检测器在每一帧中提取目标,然后利用数据关联方法将当前帧的检测结果和过往帧中的跟踪对象关联起来,最终获取目标运动轨迹。
而 Detection Free Tracking(目标无关的追踪)是指在初始帧通过人为初始化跟踪目标位置,再利用跟踪算法获取目标的运动轨迹。
下面这幅图展示了两类算法的区别:
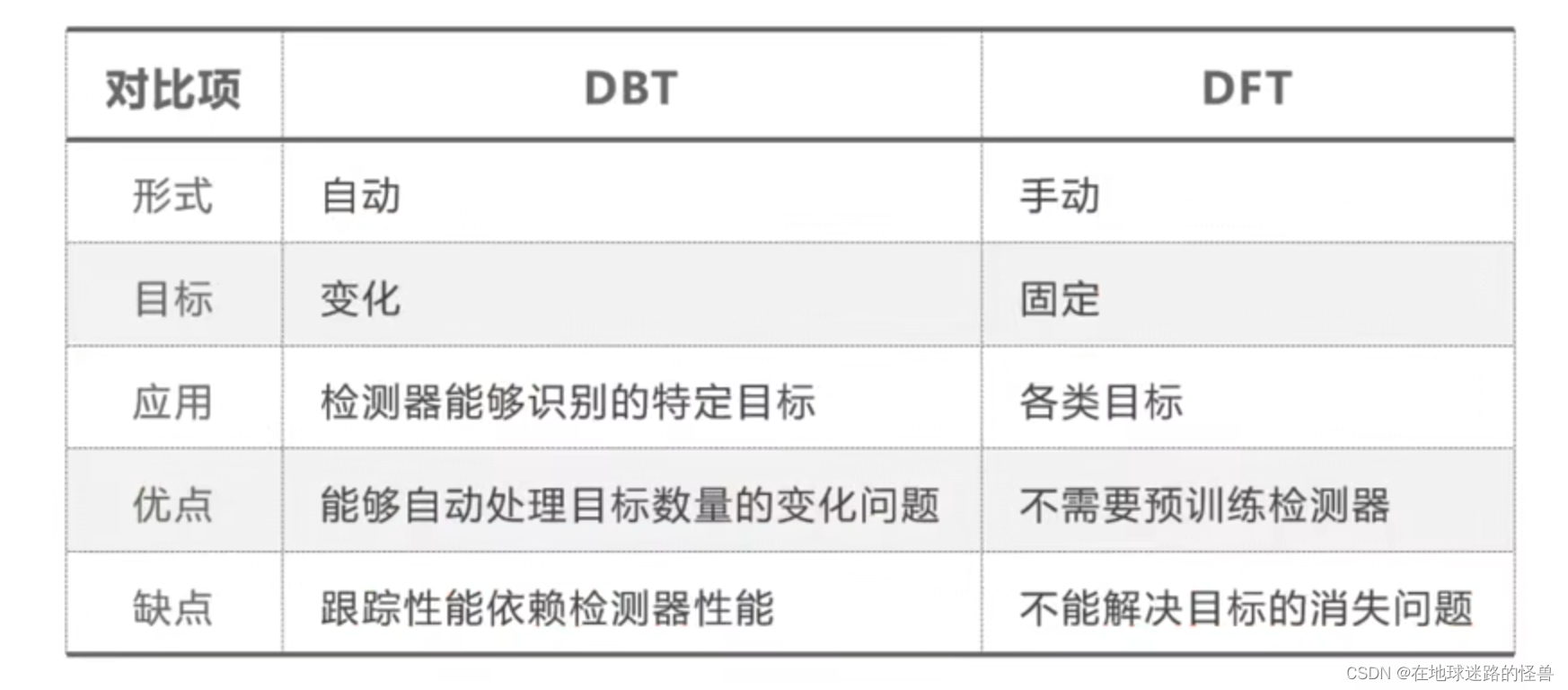
以检测为基础的跟踪是完全自动的,它不需要人工初始化目标,每一帧的目标都是通过检测器获取的,因此其跟踪目标也不是一成不变的,但是其跟踪性能非常依赖于检测器的性能。
而与检测器无关的算法需要在开始阶段人工初始化更多目标,它不需要预训练检测器,但是无法解决目标消失的问题。
第二种常见的分类形式是 online 和 offline 的算法,也就是在线和离线的两种方式。
两类算法最主要的区别在于某一帧做跟踪时,是否用到后面帧的信息,online MOT 有以下代表:

如上图所示,在 online 算法中,2017 年的 DeepSort 算法算是一个比较经典的算法,其应用一个在大规模行人重识别数据集上训练的网络,增加了对缺失和遮挡的鲁棒性,同时还保持了系统的高效和使用于在线场景。其它的介绍图上都有,不再赘述。
offline MOT有以下代表:

第三种常见的分类方式是基于深度学习和基于传统算法的分类。

全局最近邻标准滤波是最早提出并被广泛应用的在线数据关联算法,其核心思想是考虑当前帧的检测结果与已有目标轨迹,计算所有可能存在的匹配,并基于求解二元分配问题,生成最大概率分配假设,联合概率数据关联方法能够考虑所有的可能性,将候选检测结果进行匹配。
目前网络流数据关联算法为传统多目标跟踪中在视觉领域应用最多的算法。
网络流算法将整个跟踪过程建模为网络表示和目标函数,以此求解最小问题。
多假设跟踪最初被应用于雷达的目标跟踪,是一种基于延迟逻辑的方法。其核心思想是基于随时间推移对所有潜在的数据关联进行假设,并根据接下来收到的结果以处理当前帧中相对关联的歧义。
Detection Based Tracking(基于目标的追踪)
检测(detection)和跟踪(tracking)是计算机视觉领域中常见的两种任务,通常用于视频分析、目标识别和监控系统中。检测是指在图像或视频中定位和识别特定对象或物体的过程,而跟踪是指在连续的图像帧中追踪这些对象或物体的位置和运动。Detection Based Tracking(基于检测的跟踪)结合了这两种任务的特点,即首先通过检测算法找到对象,然后通过跟踪算法在连续帧中追踪这些对象。
以下是 Detection Based Tracking 的基本步骤:
1、检测(Detection):首先,利用检测算法(如基于深度学习的目标检测算法,例如Faster R-CNN、YOLO、SSD等)在图像或视频帧中定位和识别对象。这些算法能够在图像中找到对象的位置,并用边界框(bounding box)来表示对象的位置和大小。
初始化(Initialization):一旦检测到对象,就需要初始化跟踪器,以便在后续帧中追踪该对象。初始化通常包括确定对象的初始状态(位置、速度等)以及选择合适的跟踪算法。
2、跟踪(Tracking):在对象被检测到后,跟踪算法开始在连续的图像帧中追踪对象的位置和运动。这通常涉及更新对象的状态(例如位置和速度)以适应图像帧之间的变化,如对象的运动、变形或遮挡。
3、重新检测(Re-detection):在跟踪过程中,如果对象由于遮挡、光照变化或其他因素而丢失,则需要重新进行检测以重新定位对象。重新检测通常定期执行,以确保跟踪的准确性和鲁棒性。
4、更新(Update):随着时间的推移,对象的外观和运动可能会发生变化。因此,跟踪器可能需要定期更新对象的模型或特征表示,以适应这些变化并维持准确的跟踪。
Detection Based Tracking 结合了检测和跟踪的优势,能够在复杂的场景中有效地追踪对象,并且相对于单独的检测或跟踪方法,能够提供更高的准确性和鲁棒性。
Detection Free Tracking(检测无关的跟踪)
检测无关的跟踪(Detection Free Tracking)是一种目标跟踪方法,与检测依赖的跟踪相反。在这种方法中,不需要先进行目标检测,而是直接对目标进行跟踪。这意味着跟踪算法不依赖于在每个图像帧中对目标进行显式的检测和识别。
以下是 Detection Free Tracking 的基本原理和步骤:
1、初始化(Initialization):与检测依赖的跟踪类似,Detection Free Tracking 也需要在初始时对目标进行初始化。这可能包括手动选择目标或使用一些自动初始化技术。
2、特征提取(Feature Extraction):在每个图像帧中,从目标周围提取特征,这些特征可以描述目标的外观和运动特性。常见的特征包括颜色直方图、纹理特征、光流等。
3、相似度计算(Similarity Calculation):使用提取的特征来计算当前图像帧中目标与上一帧中目标的相似度。这可以通过比较特征向量之间的距离或相似性度量来完成。
4、跟踪(Tracking):根据相似度计算的结果,更新目标的位置和状态。通常使用运动模型来预测目标的位置,并根据实际观测值(提取的特征)进行校正和更新。
5、遮挡处理(Occlusion Handling):当目标被遮挡时,跟踪器可能会失效。在 Detection Free Tracking 中,通常使用一些技术来处理遮挡,例如目标外观模型的更新或使用上下文信息来推断被遮挡目标的位置。
6、持续更新(Continuous Update):持续地重复上述步骤,以在连续的图像帧中跟踪目标,并根据需要更新目标的状态和特征表示。
Detection Free Tracking 通常适用于目标外观和运动变化不剧烈、背景复杂或目标尺寸较小的情况。由于不需要显式的目标检测步骤,因此可以更快地实现目标跟踪,并且在某些情况下,可能具有更好的实时性能。然而,它也可能面临由于目标外观变化或遮挡而导致的跟踪失败的挑战。
Online MOT
在线多目标追踪(Online Multi-Object Tracking)是指在视频流中实时追踪多个目标的过程,而不需要事先知道目标数量或类别。在线方式意味着跟踪算法在处理视频时只能访问当前和过去的信息,并且不能使用未来帧的信息。
以下是在线多目标追踪的一般步骤和方法:
1、目标检测(Object Detection):在每一帧中,使用目标检测算法检测出图像中的目标。常用的检测算法包括 Faster R-CNN、YOLO、SSD 等。检测器会输出目标的位置信息,通常表示为边界框。
2、数据关联(Data Association):将当前帧中检测到的目标与之前帧中的目标进行关联,以确保每个目标都能被正确地跟踪。数据关联通常涉及确定每个检测目标与已知轨迹中的哪个目标最匹配。
3、目标跟踪(Object Tracking):对于已关联的目标,使用跟踪算法来跟踪它们的运动。跟踪算法可以是基于特征的,例如卡尔曼滤波器、粒子滤波器等,也可以是深度学习方法,如 Siamese 网络、SORT(Simple Online and Realtime Tracking)等。
4、遮挡处理(Occlusion Handling):处理目标之间的遮挡是在线多目标跟踪中的一个重要挑战。一些方法包括使用外观模型来重新识别被遮挡的目标、使用运动模型来预测目标的轨迹以及使用上下文信息来推断目标的位置。
5、状态更新和删除(State Update and Deletion):根据目标的状态和跟踪性能,对目标进行状态更新和删除。如果一个目标在一段时间内无法被检测到或跟踪到,则可能会被删除。
在线多目标追踪需要高效的目标检测和关联算法,以及准确的目标跟踪算法,以确保在实时视频中能够准确地跟踪多个目标。由于在线多目标跟踪需要在实时性的限制下运行,因此通常需要在速度和准确性之间进行权衡,并根据应用场景进行调整。
Offline MOT
离线多目标追踪(Offline Multi-Object Tracking)是指在已经获得完整视频序列后,对整个视频进行分析和处理,从而实现对多个目标的跟踪。相比在线方式,离线方式允许系统在处理视频时更充分地利用全局信息,并且通常具有更高的跟踪准确性和性能。
以下是离线多目标追踪的一般步骤和方法:
1、目标检测(Object Detection):与在线方式类似,首先需要使用目标检测算法在视频的每一帧中检测目标。不同之处在于,在离线模式下,可以使用更复杂和计算密集的检测算法,因为不需要实时处理。
2、轨迹初始化(Trajectory Initialization):在整个视频序列中,对检测到的目标进行轨迹初始化。这可以通过为每个目标分配唯一的标识符并将其视为单独的轨迹来实现。
3、数据关联(Data Association):通过匹配不同帧中的目标检测结果,建立目标轨迹。这通常涉及在帧之间匹配相同目标的位置、外观或其他特征。数据关联可以采用各种算法,包括基于最小成本匹配的方法、图匹配方法等。
4、目标跟踪(Object Tracking):一旦建立了目标轨迹,就可以对轨迹进行跟踪。在离线模式下,可以利用整个轨迹历史信息来更准确地估计目标的运动和状态。
5、轨迹后处理(Trajectory Post-processing):在跟踪阶段之后,可以对跟踪结果进行后处理,以改善轨迹的连续性、准确性和稳定性。这可能涉及消除轨迹中的错误匹配、光滑轨迹以减少噪声等。
离线多目标追踪通常用于对视频进行深入分析、行为理解、视频摘要生成等应用。由于不受实时性的限制,可以使用更复杂和精细的算法来提高跟踪的准确性和性能。然而,离线多目标追踪的主要缺点是需要大量的计算资源和时间,并且不能用于需要实时响应的应用场景。
经典算法介绍
近些年来随着深度学习的蓬勃发展,基于深度学习的多目标跟踪算法如雨后春笋般涌现出来,这里主要介绍上图中的三个。

首先是 Sort 算法,该算法只包含特征提取和数据关联部分,需要额外的检测器提供目标位置信息,它可以与任意的检测器进行组合,对照上述图片对该算法的流程来进行介绍。
首先假设当前在第 t 帧,左图表示 t - 1 帧的跟踪结果,首先通过检测器来检测第 t 帧中的所有检测对象。如中间图片中黑色实线框所示,使用卡尔曼滤波预测,第 t - 1 帧中的跟踪对象在第 t 帧中的位置,如图中黑色虚线框所示。
然后我们计算所有的跟踪对象的预测 bounding box 和检测对象的 bounding box 之间的 Iou 相似度矩阵,最后使用匈牙利算法求出最优匹配,然后对结果进行卡尔曼更新,得到最终的跟踪结果。
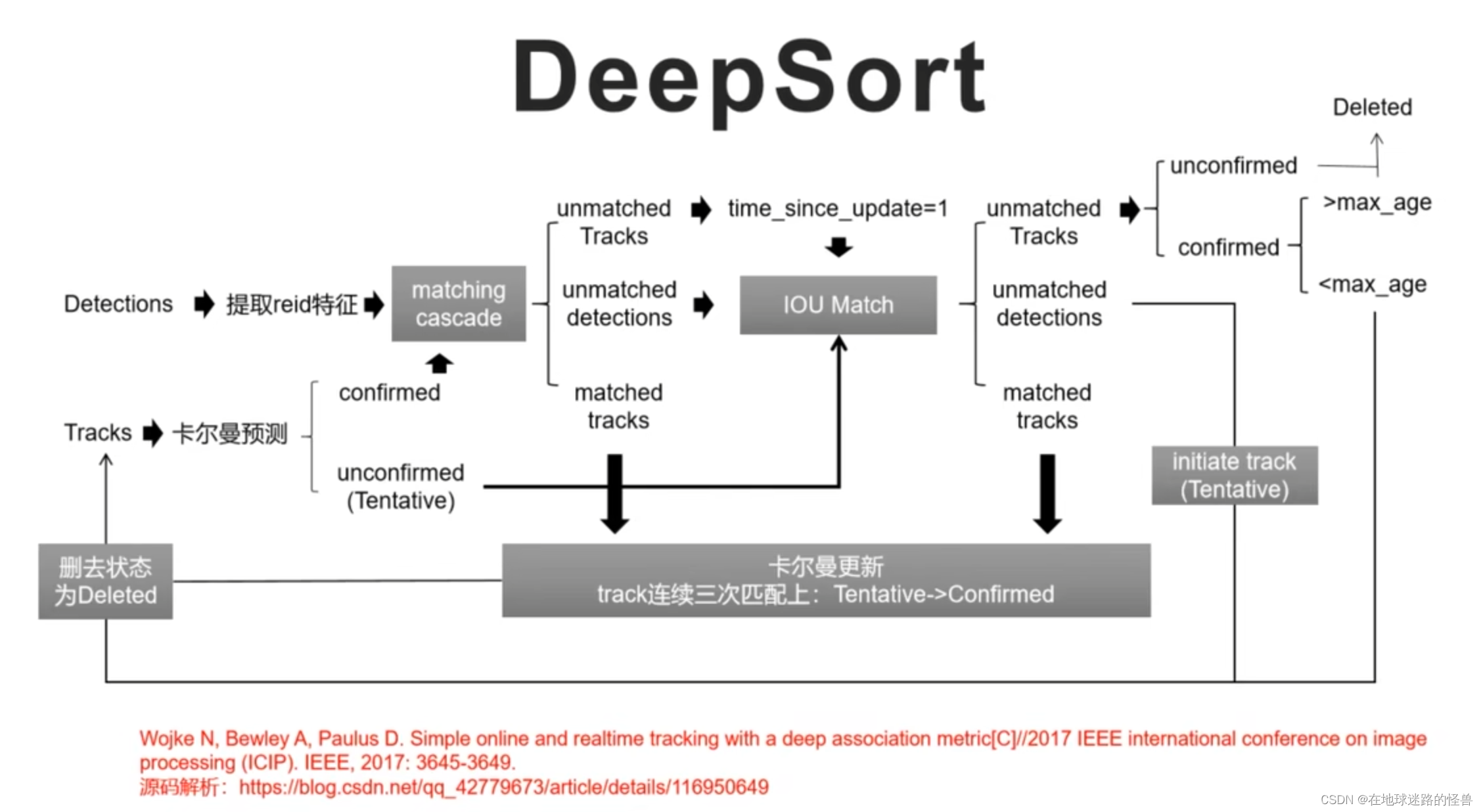
而 DeepSort 就是对 Sort 算法的改进,主要进行了如下改进:
1、增加了 reid 模型提取目标的外观特征
2、增加了外观匹配度以及距离匹配度,而不仅仅是 sort 算法中的 iou 匹配度
3、引入matching cascade 方法来进行特征匹配
下图为 DeepSort 算法的主要流程:
Fair MOT 发表在 IJCV 2021 上,它的结构非常简单,如下图所示:
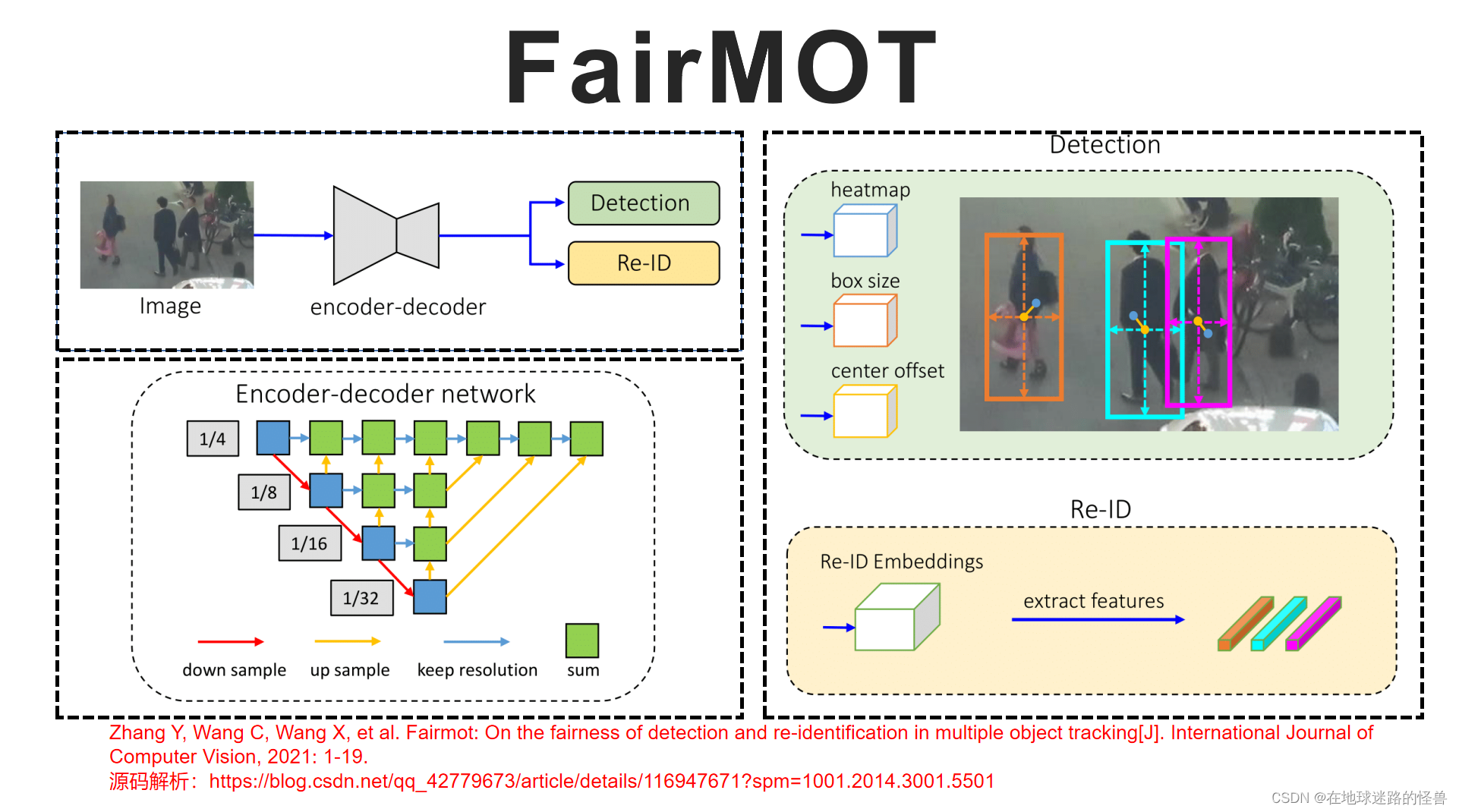
在无锚框目标检测算法 CenterNet 的网络基础之上,增加了重识别头以实现联合检测和身份嵌入,在我们得到每一个检测对象的同时会输出其对应的 reid ,其中的检测分支和 reid 分支的具体输出如右图两侧所示。
如图中的左下部分所示,文中采用多层特征聚合的方法,使得深层和浅层特征融合以平衡两种任务。
CenterTrack 发表在 ECCV 2020,该算法是 CenterNet 的作者提出:
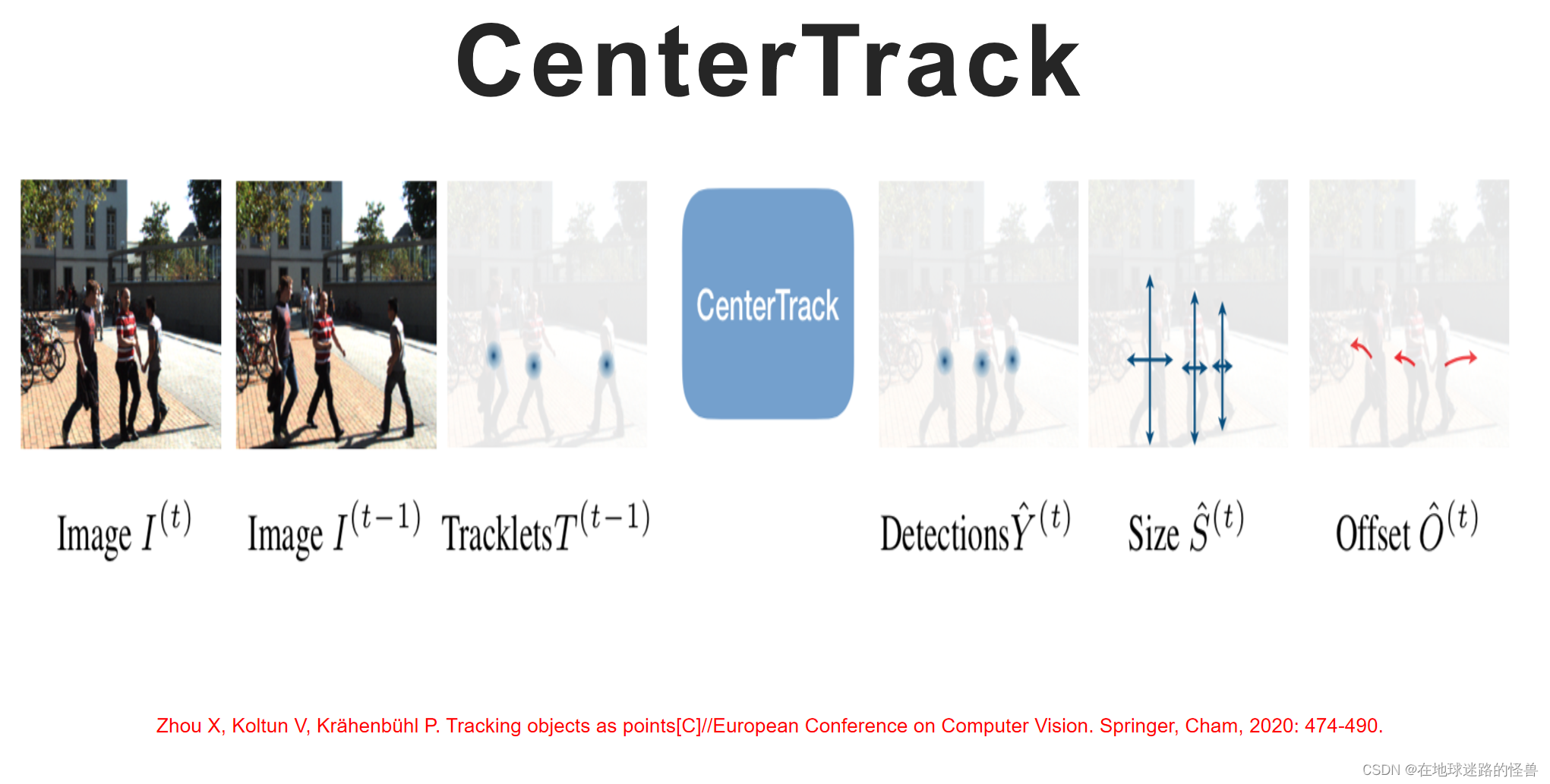
其输入为当前帧图片、上一张图片以及上一帧对应的 heatmap ,与 Fair Mot 不同的是没有使用 reid 提取网络,而是增加了中心点位移分支,在得到目标检测结果的同时输出其中心点相对于上一帧中该目标中心点的位移,然后根据距离来进行特征贪婪匹配。目标离得越近,则认为两者相似度越高。
实验证明看似简单的关联算法却得到了非常好的效果。
多目标跟踪评价指标
下面介绍一下多目标跟踪的评价指标,图中是极为常用的多目标跟踪指标:

如多目标跟踪准确度 MOTA,ID 切换次数ID Switch 以及 IDF1得分等:
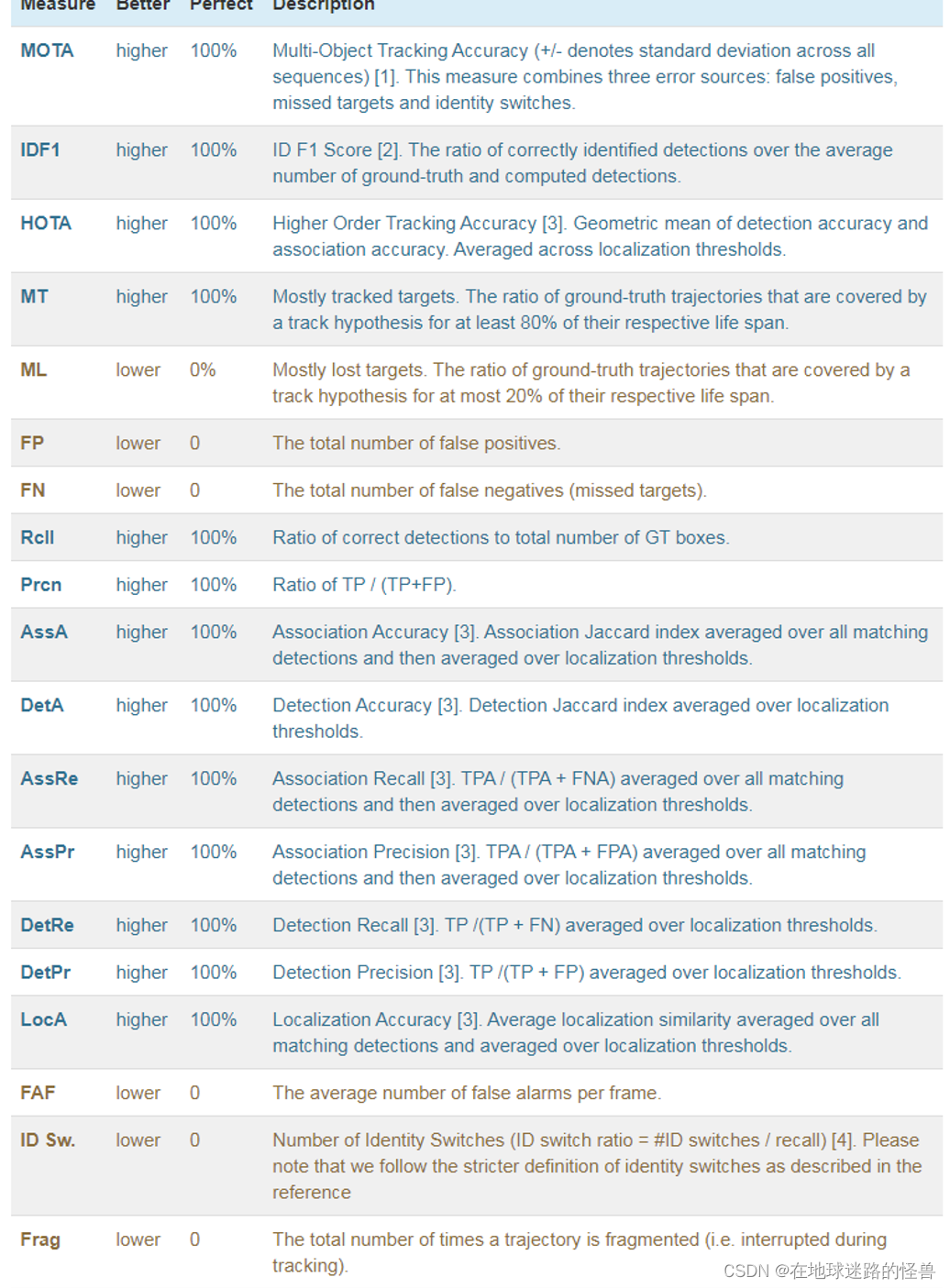
接下来重点介绍 MOTA 和 IDF1 两个指标。
MOTA 即为多目标跟踪准确度,公式如下:

FP为误报的目标个数:即跟踪算法认为其是目标,但实际上它不是一个目标。
FN为漏报个数:即跟踪算法认为这里没有目标,但是实际上这里有目标。
注意:gtID 的全称是 ground truth id:
“Ground truth ID” 是指在目标跟踪或目标识别任务中,每个目标在数据集中的唯一标识符。这个标识符通常用于评估跟踪或识别算法的性能,以便将算法检测或跟踪的目标与数据集中的真实目标进行比较。
在数据集中,每个目标通常都会被分配一个独特的标识符,这个标识符称为 ground truth ID。在目标跟踪任务中,ground truth ID 通常用于跟踪目标在时间序列中的运动,以及对跟踪算法的准确性进行评估。在目标识别任务中,ground truth ID 用于确定算法是否正确识别了数据集中的目标,并将其与真实标签进行比较。
使用 ground truth ID 可以帮助研究人员或从业者评估他们的算法在真实场景中的表现,以及与其他算法的比较。通常,一个好的目标跟踪或识别算法应该能够准确地识别或跟踪数据集中每个目标的 ground truth ID,以及跟踪目标的运动和行为。
这个可以通过图来介绍一下:
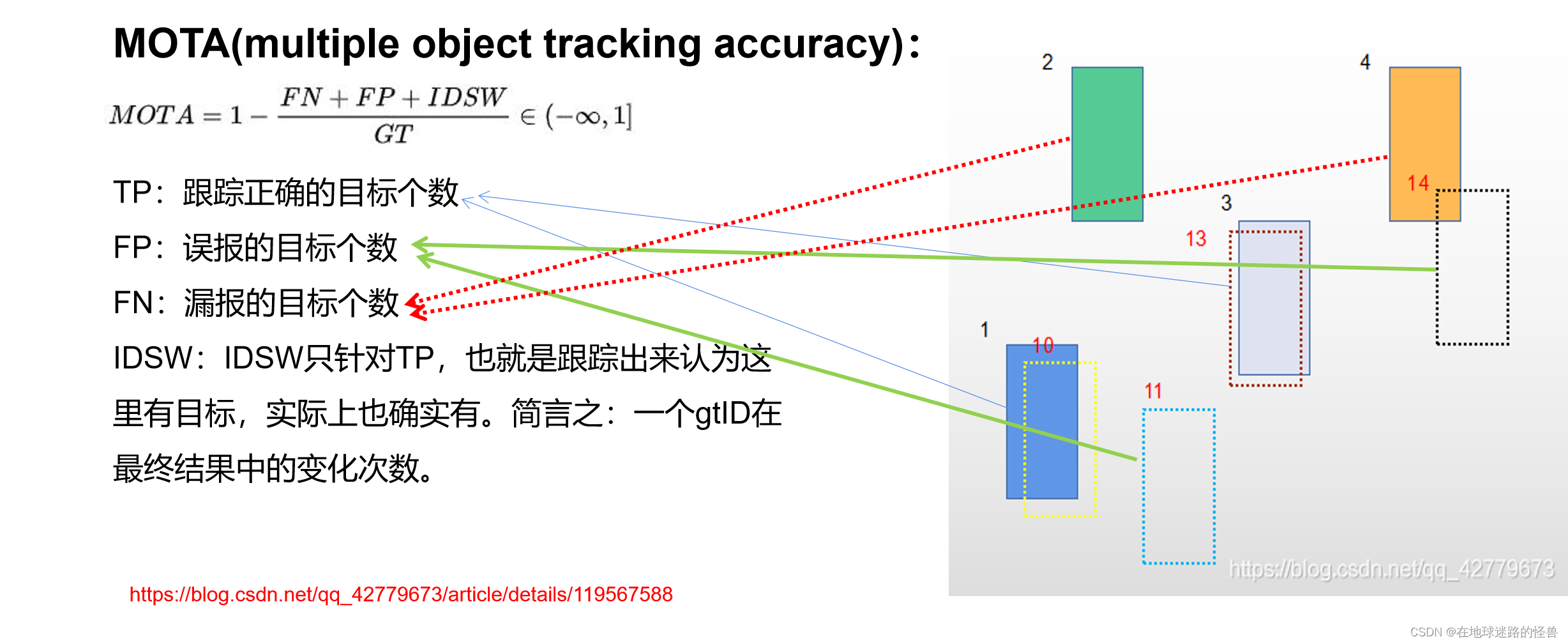
图中实线填充的矩形为 ground truth,虚线无填充的为跟踪对象。
黑色数字为 ground truth 的 id 号,红色为输出结果的 id 号,其中 10 、13 为 TP,11、14 为 FP ,2、4 为 FN,接下来看一下 id switch:
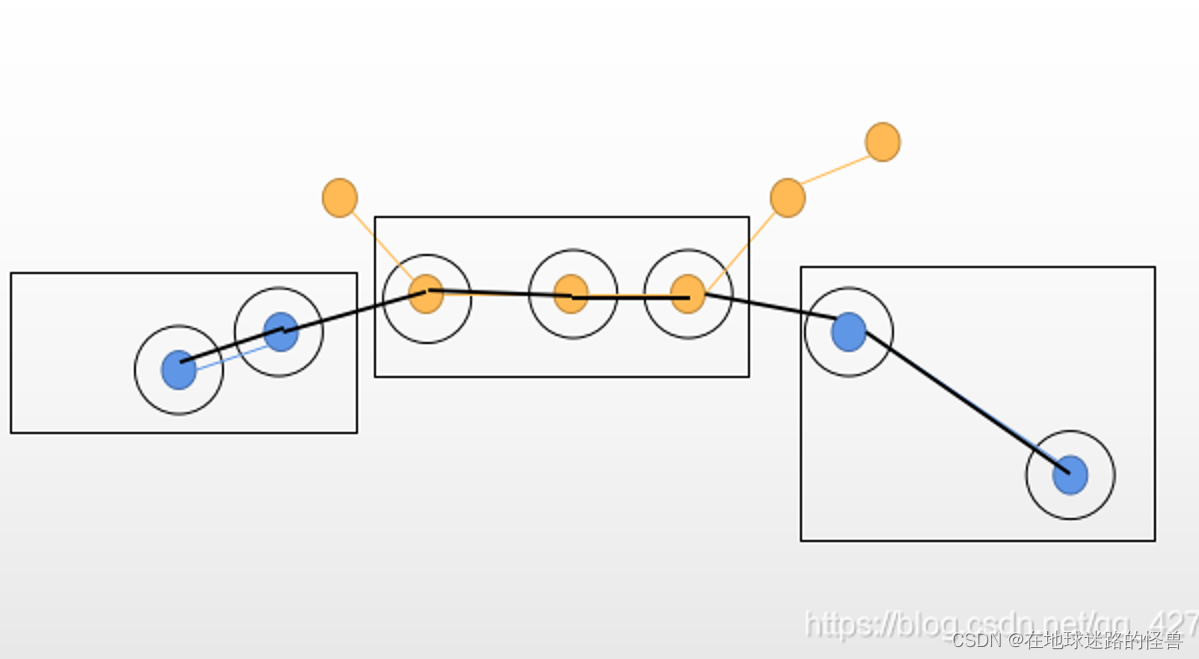
图中带填充的圆圈即为 ground truth,空心圆圈为输出结果,则蓝色对象的 id switch 即为 2 ,下面看一下 idf1:

而 IDF1 就可以通过 idtp 、idfp 以及 idfn 计算得出。
数据集介绍

各个地址链接分别如下:
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











