







本文借鉴了数学建模清风老师的课件与思路,可以点击查看链接查看清风老师视频讲解:清风数学建模:https://www.bilibili.com/video/BV1DW411s7wi
注: 因为要用到机器学习工具箱,所以至少需要安装MATLAB2017a的版本,版本越高越好,最好是2021版本的。此篇文章旨在介绍机器学习的实际应用,所以对算法的原理介绍可能会不是很清楚,想了解清楚的可以看看B 站吴恩达(稍简单一点)、李宏毅老师的视频,也可以看周志华老师的西瓜书《机器学习》(B站有配套视频),注重实用的话就看B 站的菜菜的机器学习sklearn、唐宇迪的机器学习视频。
目录
一、 概念
通过一个问题引入:夏天你是怎么买到一个好的西瓜的?你是通过自己的经验来购买西瓜的吧,经验又是通过自身长期以来对西瓜知识的累积来的把。比如:好西瓜有三个指标:色泽青绿、根蒂蜷缩、敲声浑浊,你就通过这三个指标来判断好西瓜,这是靠人类自己就能够完成的。而机器学习就是这样一个过程,它通过对以往数据(这里可以指上面的经验)的训练,在面对新的情况时,做出判断(这里可以指上面的判断瓜的好坏)。
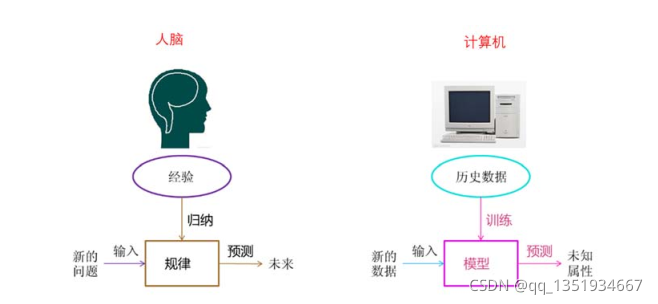
二、 机器学习的划分
机器学习包括监督学习,无监督学习,强化学习,半监督学习,主动学习。
2.1 监督学习
定义:既有x也有y。
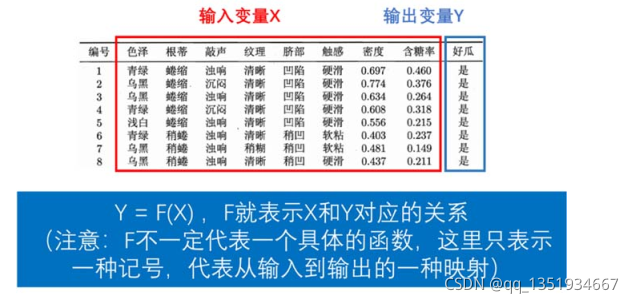
监督学习根据y的不同,可以分为分类问题和回归问题(预测问题)。
①分类问题:将西瓜分为好瓜和坏瓜、将肿瘤分为良性和恶行。
②回归问题(预测问题):预测股票涨跌、预测房价。
2.2 无监督学习
定义:只有x 没有y。我们需要得到数据之间隐藏的规律。
无监督学习常用于聚类和降维。
①聚类:根据数据将这些数据划分成几类(类似于我之前写的聚类模型文章)。
注:这里说明一下聚类和分类的区别,分类是事先就知道要将这些数据分成几类,而聚类是不知道要划分成几类,聚类划分的类别需要我们通过聚类的最终结果自己来定义。
②降维:给定的数据的指标太多了,处理起来不方便,通过对数据进行降维,得到了几个指标,这几个指标能够反映之前全部指标的大部分信息。
2.3 强化学习

2.4 半监督学习
定义:有x也有y,但y有一部分没有。
三、 模型评估指标
从现在开始,只介绍监督学习,即回归问题和分类问题
3.1 回归问题(预测问题)的评估指标

这些指标都有优缺点,到时候网上搜索就行。
3.2 分类问题的评估指标
我们定义下面这四个指标:
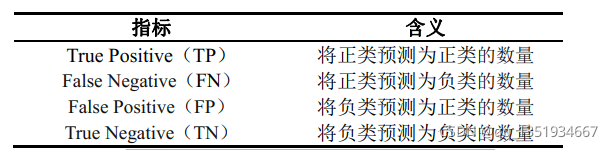
在机器学习中,通常将更关注的事件定义为正类(生活中我们通常将关注那些结果不好的情况定义为正类,比如:肿瘤的恶性、股票的下跌),负类则相反。
当然,这种定义也不是绝对的,你若更加关注股票的上涨,也可将上涨定义为正类,也比如将猫和狗的照片进行分类,你也无法定义,此时你就可以随便定义一个就好。
将这四个指标构成一个混淆矩阵:

由这个矩阵可以看出,预测对了TP+TN=6个,预测错了FP=FN=4个。
现在就定义下面这些指标:

四、 模型的泛化能力
将模型对于未知数据的预测能力定义为模型的泛化能力。
通过下面这些方法可以知道模型的泛化能力到底好不好。
4.1 留出法
将已知的数据(这里指既知道x 又知道y的数据)分成两部分,一部分通过训练可以得到一个模型,再将另一部分数据的x 放入到这个模型中进行测试,然后预测y,这时候再将预测出来的y与真实的y 进行对比,这时候我们就可以知道这个模型的好坏。这里我们将训练的数据定义为训练集,被测试的数据定义为测试集。这种对泛化能力进行评估的能力称为留出法。

留出法的缺点:当训练集过少时,我们得到的模型并不准确,同时,我们会损失作为测试集的这一部分数据。
4.2 交叉验证
交叉验证的主要思想就是下面这个图:
 我对于这个的理解:将所有知道x,y的数据拿出k-1个数据来作训练集,剩下的一个拿来作测试集,就这样,进行K次测试和训练,选取最优的一次,在上面这张图中,K取的是10(通常K都是取10),我们就称之为10折交叉验证。
我对于这个的理解:将所有知道x,y的数据拿出k-1个数据来作训练集,剩下的一个拿来作测试集,就这样,进行K次测试和训练,选取最优的一次,在上面这张图中,K取的是10(通常K都是取10),我们就称之为10折交叉验证。

4.3 选择最好的模型

4.4 欠拟合和过拟合
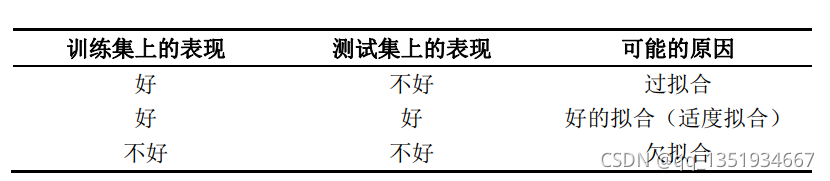
可能产生过拟合的常见原因:
(1) 模型中参数设置的过多导致模型过于复杂
(2) 训练集的样本量不够
(3) 输入了某些完全错误的的特征
解决过拟合的方法:
(1) 通过前面介绍的交叉验证的方法来选择合适的模型,并对参数进行调节。
(2) 扩大样本数量、训练更多的数据
(3) 对模型中的参数增加正则化(即增加惩罚项,参数越多惩罚越大)
欠拟合则和过拟合刚好相反,我们可以增加模型的参数、或者选择更加复杂的模
型; 也可以从数据中挖掘更多的特征来增加输入的变量, 还可以使用一些集成算法(如
装袋法(Bagging),提升法(Boosting))。
(注意:有可能模型的输入和输出一点关系都没有,举个极端的例子,你买的西
瓜好坏和你的个人特征没任何关系,例如你的性别身高体重等)














 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









