







一、安装
1.上传pig包
2.解压文件

3.改名

4.赋权

5.配置环境变量
export PIG_HOME=/usr/local/pig
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$PIG_HOME/bin

6.测试
本地模式

mapreduce模式

二、使用
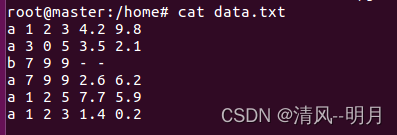
1.查看数据
a 1 2 3 4.2 9.8
a 3 0 5 3.5 2.1
b 7 9 9 - -
a 7 9 9 2.6 6.2
a 1 2 5 7.7 5.9
a 1 2 3 1.4 0.2
2.启动本地调整模式

3.计算2、3、4列所有组合中最后两列的平均值
grunt> A = LOAD 'data.txt' using PigStorage(' ') AS (col1:chararray,col2:int,col3:int,col4:int,col5:double,col6:double);
grunt> B = GROUP A BY (col2,col3,col4);
grunt> C = FOREACH B GENERATE group,AVG(A.col5),AVG(A.col6);
grunt> DUMP C;
 结果如下:
结果如下:

注:
数据类型 | |
| chararray | 字符串类型,表示文本数据 |
| int | 整数类型,表示整数数据 |
| long | 长整数类型,适用于大整数数据 |
| float | 单精度浮点数类型,表示小数数据 |
| double | 双精度浮点数类型,适用于更高精度的小数数据 |
| bytearray | 字节数组类型,表示二进制数据 |
| boolean | 布尔类型,表示逻辑值(true或false) |
| tuple | 元组类型,类似于关系数据库中的一行,可包含多个字段 |
| bag | 包类型,类似于集合,可包含多个元组 |
| map | 映射类型,用于存储键值对数据 |
| datetime | 日期和时间类型,表示日期和时间数据 |
| biginteger | 大整数类型,适用于极大整数数据 |
| bigdecimal | 大数类型,适用于高精度小数数据 |
关系运算符 | |
| LOAD | 加载数据 |
| STORE | 存储结果 |
| FILTER | 过滤和筛选 |
| DISTINCT | 去重 |
| FOREACH,GENERATE | 生成数据转换 |
| STREAM | 与外部程序交互 |
| JOIN | 连接 |
| COGROUP | 分组为多个关系 |
| GROUP | 分组 |
| CROSS | 多个关系的向量积 |
| ORDER | 排序 |
| LIMIT | 限制 |
| UNION | 合并 |
| SPLIT | 拆分 |
| DUMP | 输出 |
| DESCRIBE | 描述 |
| EXPLAIN | 分析和显示操作的执行计划 |
| ILLUSTRATE | 查看一行 |
















 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











