







爬虫解析
前言
当获取到内容后,如何获取更详细的类容如下所示:
1. Xpath
Xpath解析页面数据,能够解析本地和直接的数据
1.1 安装Xpath
-
打开 chrome浏览器
-
打开扩展( 点击右上角小圆点 =》 更多工具 =》 扩展程序 )
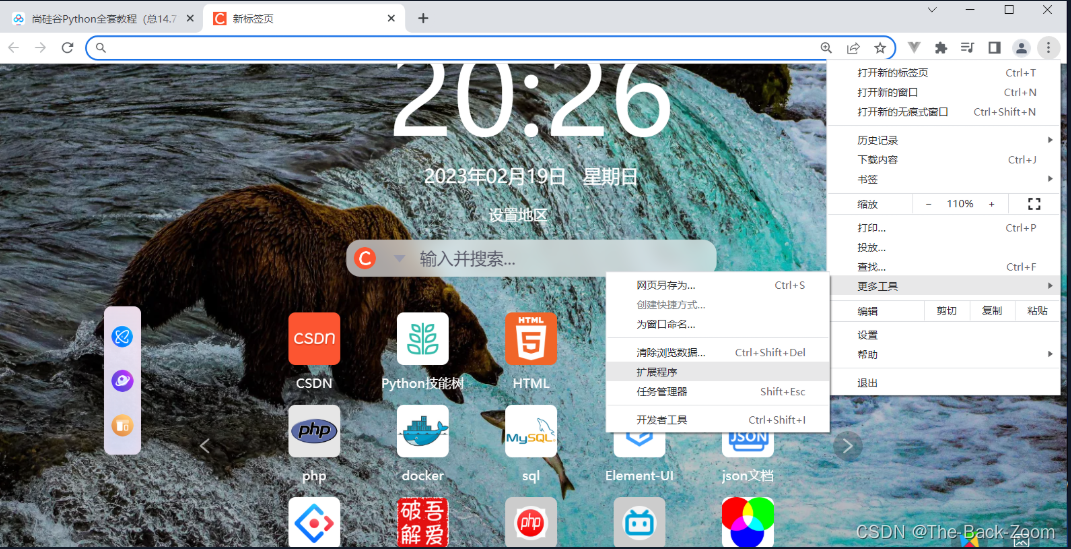
-
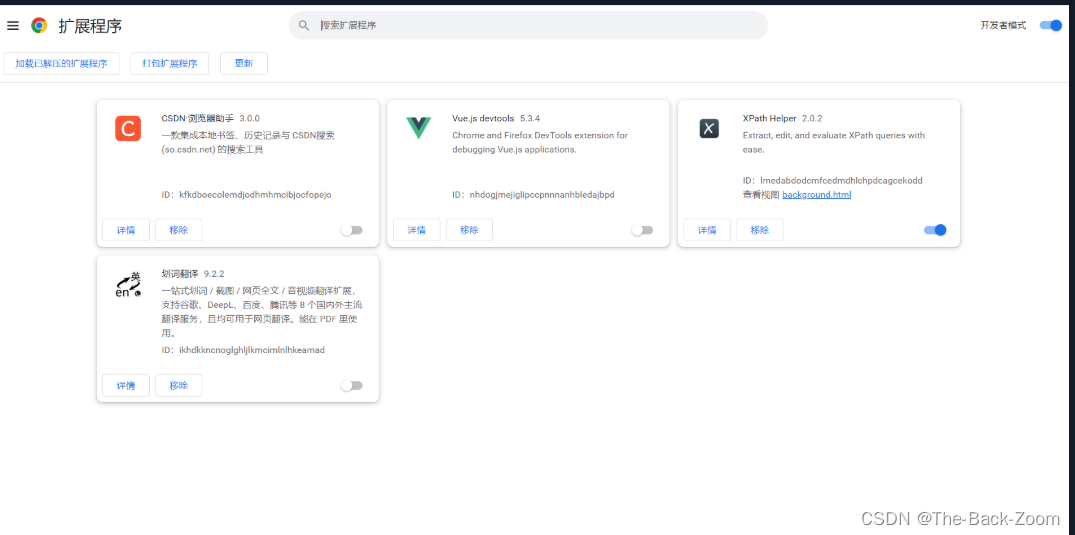
把文件拖到如下的界面,就是扩展程序的页面
-
关闭浏览器,然后重新打开浏览器,按下
ctrl + shift + x, 出现小黑框 就表明安装成功 -
下载lxml库,
pip install lxml
1.2 etree库的基本使用
- parse():解析本地文件
- HTML():解析服务器响应的数据 response.read().decode(‘utf-8’)
from lxml import etree
import urllib.request
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url)
tree1 = etree.HTML(response.read().decode('utf-8'))
tree2 = etree.parse('Xpath.html')
print(tree2)
print(tree1)
1.3 Xpath的基本语法
- xpath():tree.xpath(‘xpath路径’)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/> <!--lxml.etree.XMLSyntaxError: Opening and ending tag mismatch:没有/就会出现这个错误-->
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li >武汉</li>
</ul>
<table>
<caption>作业</caption>
<tr>
<th colspan="2">111</th>
<th>222</th>
<th>333</th>
</tr>
</table>
</body>
</html>
xpath路径语法:
-
路径查询
-
//:查找所有子孙节点,不考虑层级关系
-
/ :找直接子节点
from lxml import etree # 如下两条语句解析数据 tree = etree.parse('Xpath.html') li_list = tree.xpath('//ul/li') print(li_list, " ", len(li_list))
-
-
谓词查询
@属性,不单指id和class
-
//div[@id]
-
//div[@class]
-
/div[@id=“maincontent”]
from lxml import etree tree = etree.parse('Xpath.html') li_list = tree.xpath('//ul/li[@id="l2"]') print(li_list, " ", len(li_list))
-
-
模糊查询
-
//div[contains(@id, “he”)]
-
//div[starts‐with(@id, “he”)]
from lxml import etree tree = etree.parse('Xpath.html') li_list = tree.xpath('//ul/li[contains(@id, "l")]') print(li_list, " ", len(li_list))
-
-
逻辑运算
-
//div[@id=“head” and @class=“s_down”]
-
//title | //price
from lxml import etree tree = etree.parse('Xpath.html') li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]') print(li_list, " ", len(li_list))
-
以上四个都是指元素,后面两个都是指值
-
属性查询
不单指class属性值,指各种属性值
-
//@class
from lxml import etree tree = etree.parse('Xpath.html') li_list = tree.xpath('//ul/li[contains(@id, "l")]/@id') print(li_list, " ", len(li_list))
-
-
内容查询
-
//div/h1/text()
from lxml import etree tree = etree.parse('Xpath.html') li_list = tree.xpath('//ul/li[contains(@id, "l")]/text()') print(li_list, " ", len(li_list))
-
1.4 获取百度网站的百度一下
- 获取网页的源码(https://www.baidu.com)
- 解析的服务器响应的文件 etree.HTML
- 打印
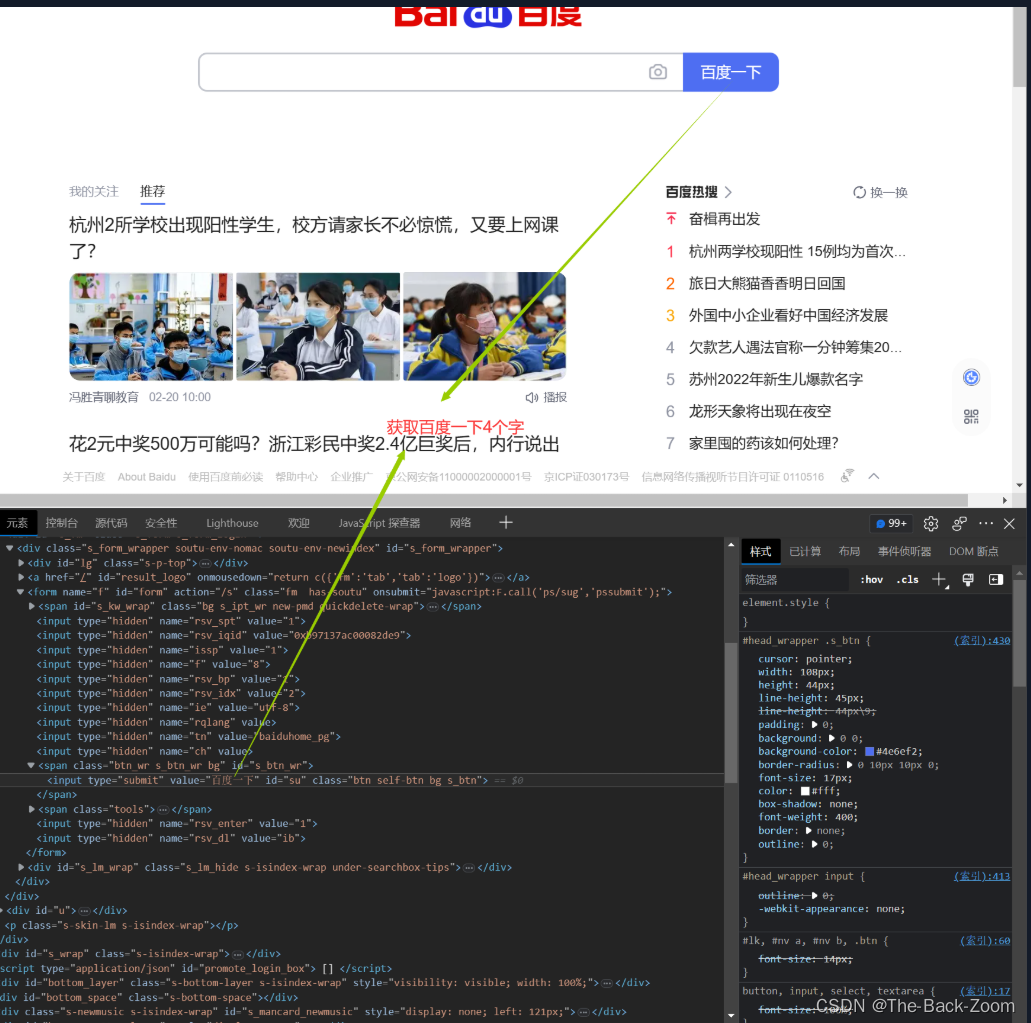
import urllib.request
from lxml import etree
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/110.0.0.0 Mobile Safari/537.36 '
} # ctrl +t
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
li_list = tree.xpath('//button[@id="index-bn"]/text()')
print(li_list[0])
1.5 站长素材下载
-
获取整个网站源码
-
对网站源码进行解析
-
下载图片
import urllib.request from pathlib import Path # Path模块,创建目录的模块 from lxml import etree def get_response(item): if item == 1: url = 'https://m.sc.chinaz.com/tupian/qinglvtupian.html' else: url = f"https://m.sc.chinaz.com/tupian/qinglvtupian.html?page={item}" headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/110.0.0.0 Mobile Safari/537.36 ' } request = urllib.request.Request(url=url, headers=headers) return request def get_contant(request): response = urllib.request.urlopen(request) return response.read().decode('utf-8') def down_load(contant, item): tree = etree.HTML(contant) name_list = tree.xpath('//div[@class="img-box"]/img/@alt') src_list = tree.xpath('//div[@class="img-box"]/img/@src') Path('./tupian_' + str(item)).mkdir(parents=True, exist_ok=True) for i in range(len(name_list)): urllib.request.urlretrieve(url='http:' + src_list[i], filename= './tupian_' + str(item)+ '/' + name_list[i] + '.jpg') if __name__ == '__main__': # https://m.sc.chinaz.com/tupian/qinglvtupian.html # https://m.sc.chinaz.com/tupian/qinglvtupian.html?page=2 start_page = int(input('请输入开始下载页面:')) end_page = int(input('请输入下载结束页面:')) for item in range(start_page, end_page): request = get_response(item) contant = get_contant(request) down_load(contant, item)
懒加载(
一般设计图片的网站都会进行懒加载):
Path模块(
Path( '/tmp/my/new/dir' ).mkdir( parents=True, exist_ok=True ))
parents=True:如果所创建的最终的dir目录的父目录不存在,那么创建父目录exist_ok=True:如果这个目录已经存在,那么不再创建,也不会报系统错误
2. JsonPath
JsonPath用来解析JSON数据,而且只能够解析本地的JSON文件
2.1 安装 jsonpath的安装
直接在Scripts目录下面输入
pip install jsonpath
2.2 jsonpath的使用
ret = jsonpath.jsonpath(obj, 'jsonpath语法'):其中obj是我们解析的JSON数据
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
如下是对应的获取语法:
import json
import jsonpath
obj = json.load(open('073_尚硅谷_爬虫_解析_jsonpath.json','r',encoding='utf-8'))
# 书店所有书的作者
# author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
# print(author_list)
# 所有的作者
# author_list = jsonpath.jsonpath(obj,'$..author')
# print(author_list)
# store下面的所有的元素
# tag_list = jsonpath.jsonpath(obj,'$.store.*')
# print(tag_list)
# store里面所有东西的price
# price_list = jsonpath.jsonpath(obj,'$.store..price')
# print(price_list)
# 第三个书
# book = jsonpath.jsonpath(obj,'$..book[2]')
# print(book)
# 最后一本书
# book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
# print(book)
# 前面的两本书
# book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# print(book_list)
# 条件过滤需要在()的前面添加一个?
# 过滤出所有的包含isbn的书。
# book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
# print(book_list)
# 哪本书超过了10块钱
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
print(book_list)
2.3 jsonPath解析淘票票网站
爬取淘票票网站
https://dianying.taobao.com/所有的城市信息
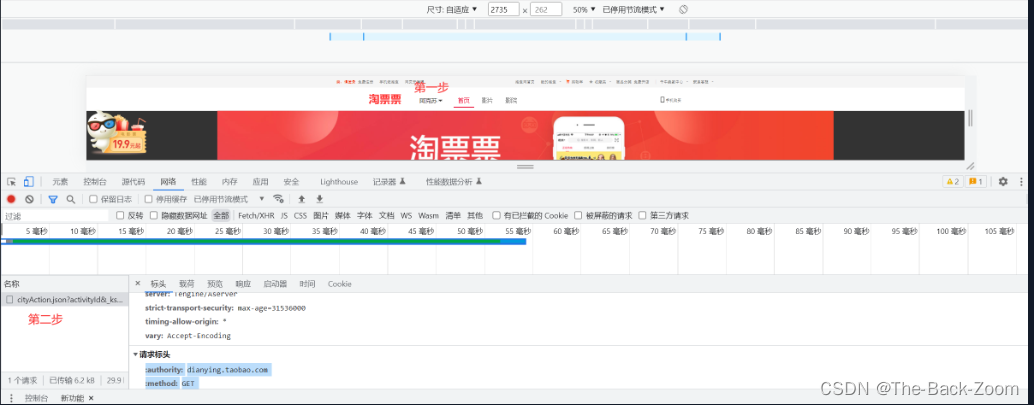
import json
import urllib.request
from jsonpath import jsonpath
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1676900027775_105&jsoncallback=jsonp106&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'accept-language': 'zh,zh-CN;q=0.9',
'bx-v': '2.2.3',
'cookie': 'v=0; cna=K64NHKgXbisBASQOBF1koLyy; xlly_s=1; _samesite_flag_=true; '
'cookie2=12f38131b83a5bb5076f63f2ee72cc5e; t=9acb43ec279f654721371416169913b9; _tb_token_=e43e05156173; '
'tb_city=652900; tb_cityName="sKK/y8vV"; '
'l=fBN8VWeqTdqDw7EXBOfZEurza779tIRcguPzaNbMi9fPO_5p509OW68cN489CnGNesIXJ3ub1k7yB'
'-Y5zyCVVcYON7h1Wn2qeFGyN3pR.; tfstk=cMhGB0ccIAy_nAOxAcN6ZDiMrIpdZcXa2jkrTeg8cOKnM8lFiqBFUWZv-rKWbt1..; '
'isg=BCoqguZRPRamNLF6l-_osHPue5DMm6717GdvPLTjl30I58ihnS_SBSBRcxt7FyaN',
'referer': 'https://dianying.taobao.com/',
'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"',
'sec-ch-ua-mobile': '?1',
'sec-ch-ua-platform': '"Android"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/110.0.0.0 Mobile Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
value = response.read().decode('utf-8').split('(')[1].split(')')[0]
with open('tpp.json', 'w', encoding='utf-8') as fp:
fp.write(value)
with open('tpp.json', 'r', encoding='utf-8') as fp:
value = fp.read()
obj = json.loads(value)
print(jsonpath(obj, '$..regionName'))
3. Beauifulsoup
3.1 Beauifulsoup安装
直接在终端输入
pip install bs4 -i https://pypi.douban.com/simple,然后导入(from bs4 import BeautifulSoup)就可以使用了
如下是bs4.html类容的信息:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<span id="first">sdf</span>
</ul>
<a href="" title="a2" class="a1">百度</a>
<a href="" class="a1">百度</a>
<div id="d1">
<span>
哈哈哈
</span>
</div>
<p id="p1" class="p1">呵呵呵</p>
</body>
</html>
3.2 创建Beautifulsoup对象
- BeautifulSoup( obj, ‘lxml’)
- obj为 服务器响应的文件生成对象 或者 本地文件生成对象
from bs4 import BeautifulSoup
# r是open函数的默认打开模式
soup = BeautifulSoup(open('bs4.html', 'r', encoding='utf-8'), 'lxml') # 打开文件最好携带encoding='utf-8',怕是有中文
print(soup.a) # DOM节点
print(soup.a.attrs, soup.a.name)
# soup.a.attrs:a标签的属性
# soup.a.name:a标签的名字
3.3 BeautifulSoup对象的方法
-
find():返回一个对象
-
find_all():返回一个对象列表
-
select(选择器):根据选择器得到节点对象,选择器和css的语法一模一样,返回的是DOM类型的对象列表
from bs4 import BeautifulSoup soup = BeautifulSoup(open('bs4.html', 'r', encoding='utf-8'), 'lxml') # 打开文件最好携带encoding='utf-8',怕是有中文 print(soup.find('a')) # 找到第一个a标签DOM print(soup.find('a', class_='a1')) # 找到第一个有class_='a1'属性的a标签的DOMclass_='a1'::可以表示各种属性,id,title都可以,之所以写成class_的形式,是因为class是关键字from bs4 import BeautifulSoup soup = BeautifulSoup(open('bs4.html', 'r', encoding='utf-8'), 'lxml') # 打开文件最好携带encoding='utf-8',怕是有中文 print(soup.find_all('a')) # 找到所有a标签DOM print(soup.find_all(['a', 'li'])) # 找到所有a和li标签DOM print(soup.find_all('a', limit=1)) # 找到前两个a标签DOMfrom bs4 import BeautifulSoup soup = BeautifulSoup(open('bs4.html', 'r', encoding='utf-8'), 'lxml') print(soup.select('#first')) # print(soup.select('*')) print(soup.select('a[title]')) # 选取有title属性的a标签
3.4 获取节点信息
-
获取节点内容
-
obj.string
-
obj.get_text()【推荐】
如果标签中除了内容还有标签,obj.string获取不到数据,但是obj.get_text()都可以获取属性
from bs4 import BeautifulSoup soup = BeautifulSoup(open('bs4.html', 'r', encoding='utf-8'), 'lxml') # 打开文件最好携带encoding='utf-8',怕是有中文M obj = soup.select('li') print(obj[0].string, obj[0].get_text())
-
-
获取节点属性
-
tag.name : 获取标签名
-
tag.attrs : 将属性值作为一个字典返回
-
obj.attrs.get(‘title’) : 获取title属性的值
from bs4 import BeautifulSoup soup = BeautifulSoup(open('bs4.html', 'r', encoding='utf-8'), 'lxml') # 打开文件最好携带encoding='utf-8',怕是有中文M print(obj[0].attrs, obj[0].name) print(obj[0].attrs.get('id'))
-
3.5 爬取星巴克
ctrl + f:谷歌搜索
4. 项目爬取IP地址
爬取项目的IP地址为
https://ip.jiangxianli.com/,注意爬取前10页的IP地址
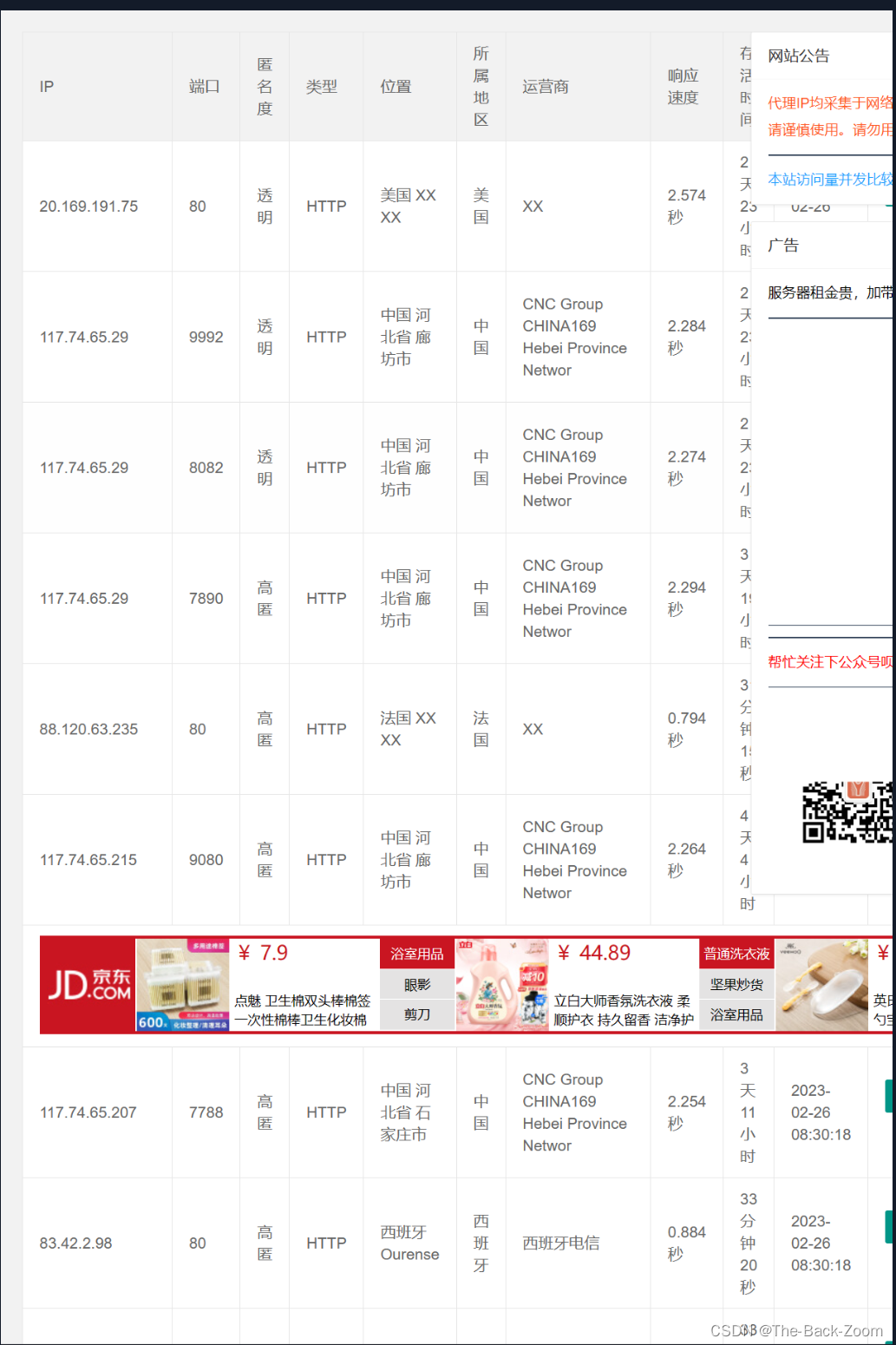
注意该IP地址强制使用https协议,你要用ssl证书验证,这也是一个反爬,如下是全部的代码:
import urllib.request
import urllib.error
from lxml import etree
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.7',
'Connection': 'keep-alive',
'Cookie': 'Hm_lvt_b72418f3b1d81bbcf8f99e6eb5d4e0c3=1677292598; __bid_n=186866df21b7efff304207; '
'FPTOKEN=jqtAP3hxzd+lpuXPzgOoEWGO+15IPROy9UTY9Ksx523A2gaOQMC45dT222Ba'
'/zZueyxnokzsW3bVXmmLR1SIDMmPelKP0A211kb0iTlpxm8z6lhMyc3fIWVdwYLh/QN5278tdQu4E9k8z'
'+q5ephjxtSWxglAngFFwPtwwK2IEkwm/MkdI6S6Q'
'+ySag50bXJTkNTb6XGpMPg6DmJ3fINHh3BgoGxCVrn7s5c3p4IEdYKYqDtgAQl4eackpeuZbhz1pHi6yt1YnI+efmf+eSax6bl'
'/ZTnBuH8g1bdun1WcGOWQFEs+uBYMPc5dxA9al8413VZiRcvF1a6lJr1/pPgVuUCrpyhAPmWdHLADi4V9UfUGs9C6HLWl'
'+vVg2x5lxLhtKq4g0z4QyAfj0HHlKsvjWw==|YF4yavlOLDHxlUia7WtdqPp4ETkqPePhio/2jx5rMfE=|10'
'|0f7f1b34809fe5066fcf5503c009f8d6; Hm_lpvt_b72418f3b1d81bbcf8f99e6eb5d4e0c3=1677292959',
'Host': 'ip.jiangxianli.com',
'Referer': 'https://ip.jiangxianli.com/?page=2',
'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"',
'sec-ch-ua-mobile': '?1',
'sec-ch-ua-platform': '"Android"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/110.0.0.0 Mobile Safari/537.36',
}
ip = []
try:
for i in range(1, 11):
url = f"https://ip.jiangxianli.com/?page={i}"
requst = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(requst)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
ip_list = tree.xpath("//tbody//tr//td[1]/text()")
port_list = tree.xpath("//tbody//tr//td[2]/text()")
for item in range(len(ip_list)):
str = ip_list[item] +':'+ port_list[item]
ip.append(str)
print(ip)
except urllib.error.URLError as error:
print(error)

















 1713
1713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











