






0x00 正则表达式的概述
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
首先介绍正则的测试平台,小编用的比较多的两个
菜鸟在线:
https://c.runoob.com/codedemo/6230/
oschina在线:
https://tool.oschina.net/regex
另附一张简洁的说明图:
下面开始详细分析说明:

0x01 正则的几种标识符
下面开始介绍基本的入门使用:
(一)限定符
> abc?:代表?前一个对象也就是c出现0次或者多次,c可有可无
> ab*c:代表*前一个对象也就是b出现多次也可以没有
> ab+c:代表+前一个对象也就死b出现一次或者多次,不可以不出现
> ab{2,6}:代表{}前的对象也就是b出现2到6次,根据{}内的数值可以测试多种不同的结果
> (ab)+:代表()内的对象ab出现一次或多次
(二)运算符号
> 1.或运算:a(b|c):a匹配ab或者ac
> 2.[a-zA-Z0-9]:表示所有的大小写字符包括数字
> 3.[^0-9]:表示选出非后的字符,就是代表所有的非数字字符(包括换行符),但是一般^放在开头表示从某个对象开始匹配,且一定在最前面才能匹配到
(三)元字符
\d:0-9
\w:所有的英文字符加上下划线数字
\s:代表换行符包括tab,以及换行
\D:非数字字符
\W:非单词字符
\S:非空字符
. :代表任意字符,不包括换行符
^a:只会匹配行首的a
a$:只会匹配行末的a
(四)贪婪匹配与懒惰匹配
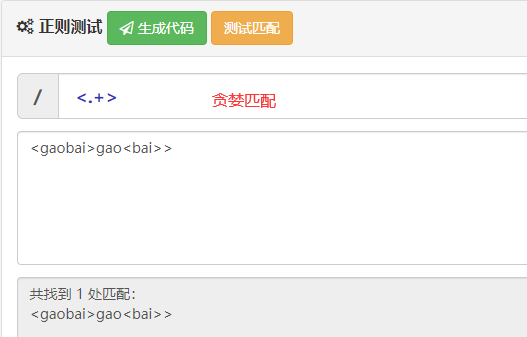
贪婪匹配:<.+>表示匹配从第一个到所有的<>
举个栗子:
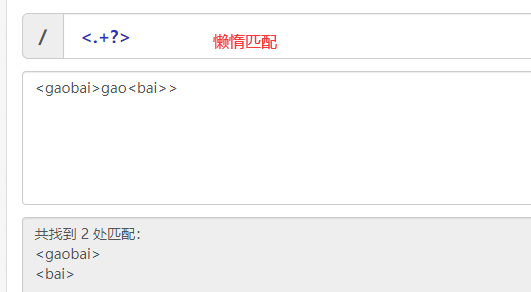
懒惰匹配:<.+?>表示匹配没一个<>,遇到闭合即完成
其他懒惰匹配规则:
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
(五)捕获
1.常规分组
正常捕获组:
学习捕获前需要了解分组的概念,常常将()作为一个分组,
那么当涉及到多个的分组的时候应该如何划分分组呢
举个栗子:(a(b))(c)
组1输出:ab
组2输出:b
组3输出:c
也就是说从左往右计算满足第一个()的分组为第一组,
非捕获组:
当我们不想给某个组加入到分组时候,可以不用捕获
举个栗子:(a(?:b))(c)
组1输出:ab
组2输出:c
?:表示不被捕获到
2命令分组
举个栗子:(a(?<gb>b))(c)
组1:ab
组2:c
组3(gb):b #组名为gb
结论:当混合在一起的时候,分组按照正常的123分完去继续排列命名分组,
(六)断言
常见五个用法:举几个栗子
(?:X) :非捕获
赋值str=1234.56¥
正则取值:(\d+)(?:\.?)(?:\d+)([¥$])
组1输出:1234
组2输出:$
这里的中间两个不参与捕获分组
(?=X):向前取值查找
举个栗子:
赋值str=sabb2135bb21aa
正则取值:[0-9]{2}(?=bb)
输出:35
结论:这里取两个数字切后面必须跟着bb也就是35满足条件
(?<=X):向后取值查找
举个栗子:
赋值str=sabb2135bb22aa
正则取值:(?<=bb)[0-9]{2}
输出:21
输出:22
结论:取值满足两个数字一起且前面是bb则取出
(?<!X):向后取非值查找
显而易见这两个与前面的前后取值将=换做了!在这里!也是表示非得意思,
举个栗子:
赋值str=sabb2135bb22aa33
正则取值:(?<!bb)[0-9]{2}
输出:13
输出:33
结论:从左往右第一个两位数字且前面不等于bb的就是13,但是将13取完后13就不参与选取,故后面取值为33不为35
(?!X):向前取非值查找
再举个栗子:
赋值str=sabb2135bb22aa
正则取值:[0-9]{2}(?!bb)
输出:21
输出:22
(七)递归与平衡组
通过递归引用,可以大幅提升正则的简洁诚度,在正则中直接引用之前的表达式,而不用复制。
学习平衡组需要有一定的正则基础,需要弄明白正则是如何将内容匹配,并且按照特定的内容匹配的中间过程,不然学习起来尚有些许吃力,这里暂时不作研究
这里的递归与平衡组后面再作研究,需要有一定的正则基础
0x02 常见的正则表达式
常用正则表达式
[\u4e00-\u9fa5]匹配中文字符
[^\x00-\xff]匹配双字节字符(包括汉字在内)
\n\s*\r匹配空白行
[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?匹配Email地址
[a-zA-z]+://[^\s]*匹配网址URL
\d{3}-\d{8}|\d{4}-\{7,8}匹配国内电话号码
[1-9][0-9]{4,}匹配腾讯QQ号
[1-9]\d{5}(?!\d)匹配中国邮政编码
^(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)$匹配18位身份证号
([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8])))匹配(年-月-日)格式日期
^[1-9]\d*$匹配正整数
^-[1-9]\d*$匹配负整数
^-?[1-9]\d*$匹配整数
^[1-9]\d*|0$匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$匹配正浮点数
^-[1-9]\d*\.\d*|-0\.\d*[1-9]\d*$匹配负浮点数
正则的学习要多在实践中探索,注意字符的大小写中英文,细心的探索研究。
















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











