






MVT简介
概述
MVT是华睿的一款集标定、训练、测试于一体的生成模型工具,生成的模型一般用于MVP算法平台中的深度学习模块,目前支持任务类型有分类、分割、检测、OCR识别。
运行环境
| 推荐配置 | |
| 操作系统 | Windows7/10(64位中、英文操作系统) |
| CPU | 建议配置为i7-6700或以上,6核12线程以上 |
| 内存 | 8GB以上 |
| 显卡 | 显存6G以上,英伟达显卡,推荐RTX2080、RTX2080Ti、RTX3070、RTX3080Ti、RTX3090、RTX3090Ti等,GTX1660、GTX1660Ti、GTX1080、GTX1080Ti也同样支持。 显卡驱动:需安装对应的显卡驱动,建议显卡驱动程序版本不低于31.0.15.1659 |
| 屏幕分辨率 | 1280*1024以上,推荐1920*1080 |
| 加密狗 | 支持硬加密狗和软加密狗 |
当然,如果要训练的模型比较小,对算力的要求比较低,显卡也可用4G显存的。具体还是要结合自己的需求来配置。
工程管理界面
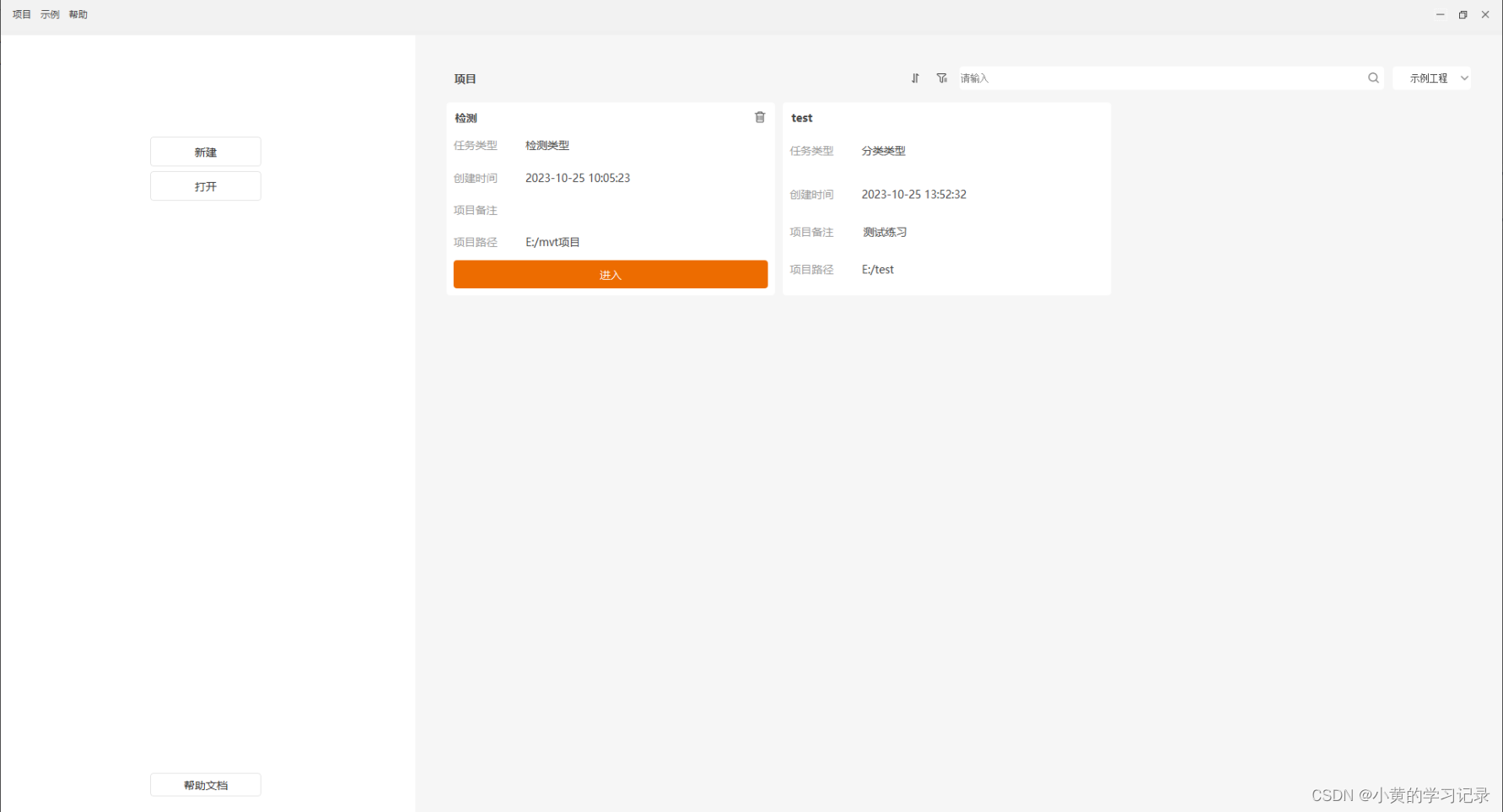
此界面可管理当前所有工程,主要包括项目的一些基础增删改查等操作。项目修改的需要进入具体项目中才能修改。
创建项目:点击“新建”-> “选择项目类型”,可根据需要自行选择分类、检测、OCR识别、分割四种类型其中之一。-> “填写项目信息”,包括项目名称、项目存储路径、备注等信息,备注信息如果不需要可以不写。

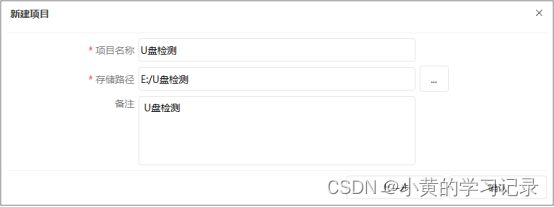
这样我们的一个项目就建立好了。
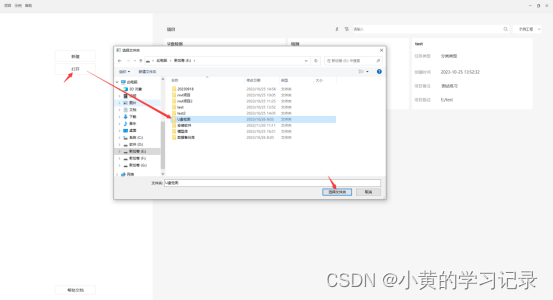
打开项目,“打开”功能可以打开原有的项目,主要是用来切换项目或者导入其他项目。只需要找到项目的根目录,选择该文件夹即可。
工程管理:
| 1排序 | 对项目进行排序,排序选项【创建时间、打开时间】 |
| 2筛选 | 按任务类型筛选项目,筛选选项【所有、分类、分割、识别、字符检测】 |
| 3搜索 | 通过搜索任务名称搜索任务 |
| 4示例工程 | 进入示例工程 |
| 5查看 | 查看工程路径 |
| 6进入 | 进入工程 |

标定界面
标定界面分为5大模块:样本管理、绘图标定、预标定模型、标签管理、标签属性
| 样本管理 | 管理图片,包括样本集、训练集、测试集图片 |
| 绘图标定 | 标定区域上部分为标定工具,下部分为图片绘制标定 |
| 预标定模型 | 通过已有模型对图片进行自动粗略的标定,提高标定效率 |
| 标签管理 | 管理标签,支持增删改查、导入、导出操作 |
| 标签属性 | 标定数据管理,支持删、改、查删操作 |
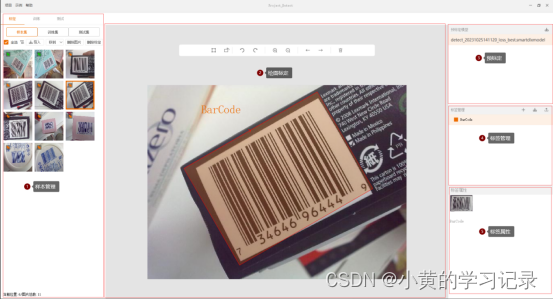
样本管理模块

样本管理有3个子页面:样本集、训练集、测试集,3个页面相互独立。
| 样本集 | 可以从外部导入图片进入样本集; 一般在样本集中对图片进行标定,然后将标定好的图片移动至训练集、测试集 |
| 训练集 | 已标定的图片可被移动至训练集,训练用的数据全部来自训练集; 训练集中的图片,若被删除标定数据变成未标定状态,会被自动移动到样本集。 |
| 测试集 | 已标定的图片可被移动至测试集,测试用的数据全部来自测试集; 测试集中的图片,若被删除标定数据变成未标定状态,会被自动移动到样本集。 |
工具条功能:
![]()
| 导入 | 从外部导入图片 |
| 移到 | 移动图片至其它集 |
| 批量管理 | 支持批量删除图片、移动、删除标定; |
| 搜索 | 根据图片名称进行搜索 |
| 筛选 | 根据标定状态进行筛选 手动标定:已标定图片,图片左上方有绿色图钉标志 智能标定:已标定图片,图片左上方有橙色图钉标志 未标定:暂未标定的图片 |
图片操作:
| 鼠标左击 | 选中,同时可配合Ctrl+A、Ctrl、Shift键使用,实现图片的快速批量选中,与windows文件选中操作习惯一致。 |
| 鼠标右击 | 可支持单张图片的移动、删除图片、删除标定、排除图片、打开图片文件夹 |
绘图标定模块

此模块负责完成图片的数据标定。
标定工具:不同的任务类型标定工具数量和类型有差异。
![]()
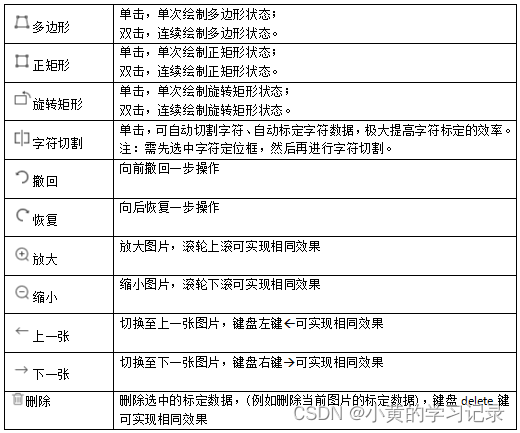
图片绘制标定:
| 绘制状态 | |
| 多边形 | 多边形绘制状态,鼠标左键绘制轮廓,右键结束。 绘制过程中快捷键F3可以回退单个点。 |
| 正矩形 | 正矩形绘制状态,拖拽式绘制正矩形 |
| 旋转矩形 | 旋转矩形绘制状态,通过3点式绘制,F3可以回退单个点。 |
标定快捷键
| F1 | 切换标签; |
| F2 | 修改标签; 先选中标定框,然后再选中目的标签,按F2将该标定框改为目的标签。结合F1使用体验效果更好。 |
| F3 | 回退,用于多边形、旋转矩形绘制过程中;绘制完成之后的话使用不了该功能了。 |
| F4 | 标定当前; 对当前选中的图片进行预标定,预标定模型中的“标定当前”,需先在预标定模块中选中1个模型; |
| F5 | 按下F5临时隐藏所有标定框,松开恢复显示 |
| F6 | 在绘制状态下,按下F6临时切换至非绘制状态,松开恢复成绘制状态,这个主要在连续绘制,并且需要调整绘制框的时候比较好用。 |
| F7 | 排除当前图像,可排除一些不想要的图片。即删除图片。 |
| Ctrl+S | 保存并下一张 |
| Ctrl+C | 拷贝选中的标定数据 |
| Ctrl+V | 粘贴标定数据 |
| Delete | 删除选中的标定数据 |
预标定模块
预标定功能:通过已训练好的模型,来推理预测结果,并将该结果作为自动标定的结果,从而提高标定效率。(预标定提高标定效率,需建立在模型较好的前提下)
预标定模型,使用前需要导入合适的模型。
| 导入 | 导入预标定模型,最多可导入5个。 注:导入模型时,会将模型自带的标签追加至“标签管理” |
| 标定当前 | 自动标定当前选中的图片 |
| 标定全部 | 自动标定样本集中所有非手动标定的图片(智能标定的图片的标定数据会被覆盖) |
| 删除模型 | 删除该模型 |
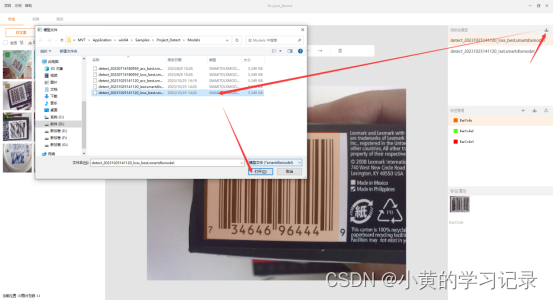
模型导入如下图所示
标签管理模块

管理标签,支持增删改查、导入、导出操作
标签管理头部:
| 新建 | 新建标签 |
| 导入 | 导入标签文件; 导入过程中执行的是追加; |
| 导出 | 导出标签文件 |
单个标签操作:不同类型工程支持的操作略有不同
| 线宽 | 标定框的线宽,范围[1,100] |
| 颜色 | 标定框和标定数据的颜色 |
| 设置 | 仅OCR工程有。 设置char标签的字符集;开启或关闭定位标签 |
| 显示 隐藏 | 显示或隐藏标定数据 |
| 左键单击 | 单击选中标签 |
| 左键双击 | 双击可修改标签名称(OCR工程的char标签除外) |
| 右键单击 | 鼠标右键单击可删除标签(OCR工程的char标签除外) |
标签属性模块

标定数据管理,支持删、改、查删操作。
训练界面
类别比例:展示训练集数据的总览。
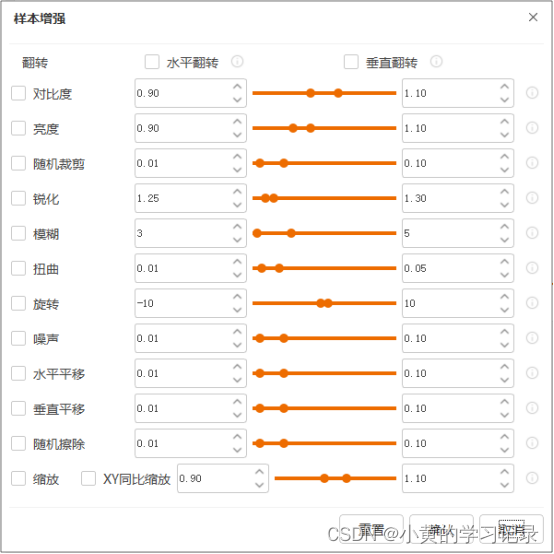
样本增强:主要是通过图像算法对原图进行变换,增加训练样本的数量,从而提高最终迭代模型的泛化性能,主要针对原训练样本数量不足的情况。
模型信息:设置训练参数,不同类型的工程可设置的参数略有不同。
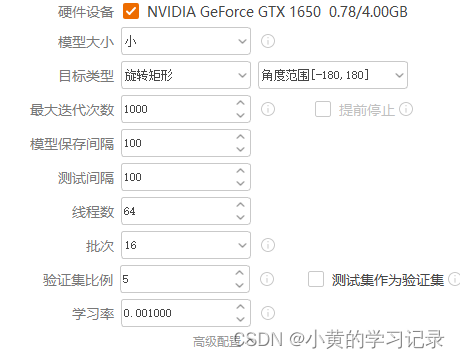
| 硬件设备 | 选择指定GPU卡训练,无GPU时不支持训练 |
| 模型大小 | 分为小、中、大三个模型可选; |
| 最大迭代次数 | 最大迭代多少个批次停止训练;范围[1,100000] 迭代次数越大,训练时间越长,一般训练出的模型越好。 |
| 提前停止 | 开启提前停止:在训练过程中,模型已经较好时,自动提前停止训练。 开启条件:最大迭代次数需大于1000次,否则置灰不让开启。 |
| 高级配置 | 高级参数包括模型保存间隔、测试间隔、线程数、吞吐量等参数。 |
不同类型工程的训练参数会有所差异,根据界面信息和自己想要的效果设置即可。
开始训练/结束训练:
点击“开始训练”,有[重新训练,自定义训练]两个选项。(选择一个选项后训练才真正开始)
重新训练:以MVT自带的模型为基础,进行训练。
自定义训练:以用户指定的模型为基础,进行训练(一般用于继续训练)
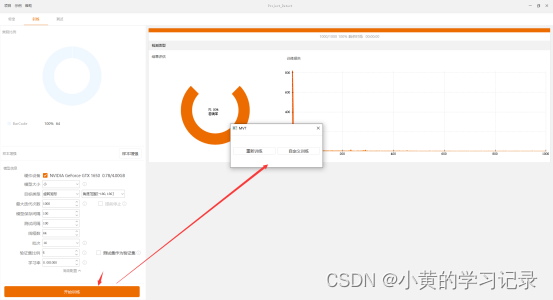
训练开始后,训练界面会显示训练进度、准确率、训练损失曲线。
训练一段时间后,如果准确率、训练损失都已经达到需求,可点击“结束训练”提前结束训练。
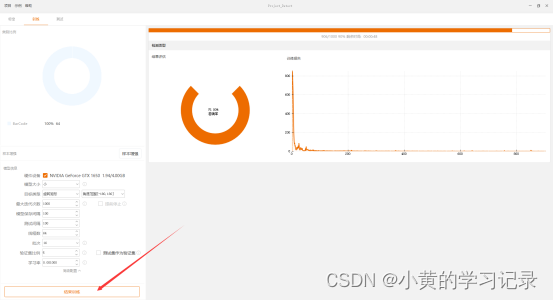
测试界面
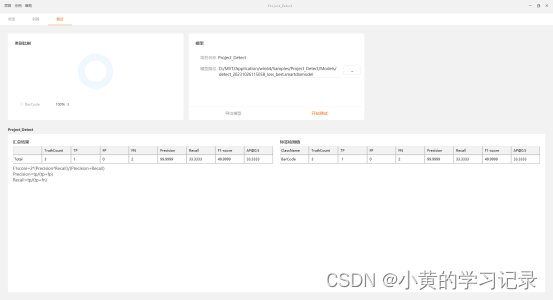
类别比例:展示测试集数据的总览。
支持选中指定模型进行测试与导出。
显示模型测试的结果,不同任务结果有差异.
分类
深度学习分类,对不同类型图像、包含不同物体图像进行归纳、分类处理。多用于整图类别或级别的划分,如包裹分类,缺陷分类。
分类工程操作步骤如下:
新建工程
新建工程,选择“分类类型”
填写项目信息,包括项目名称、存储路径和备注,备注若不需要可不写。

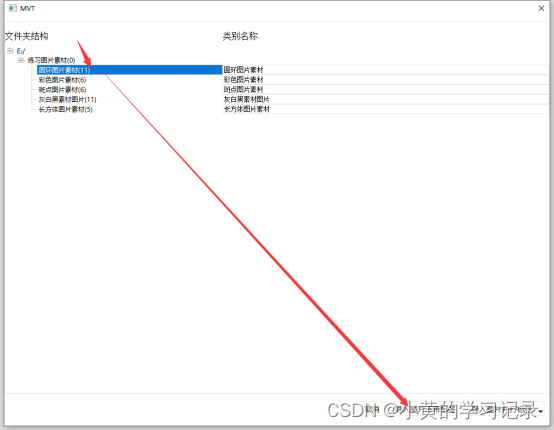
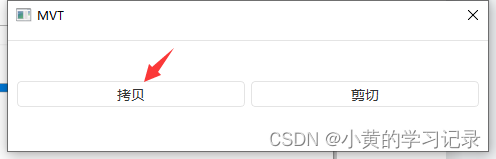
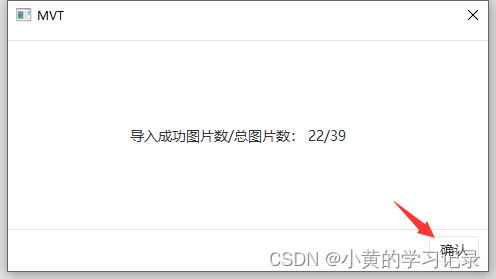
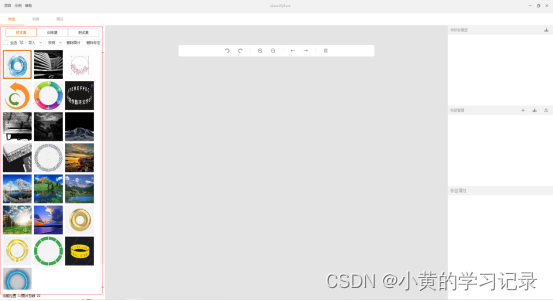
在样本集模块选择导入图片,可选择从文件夹导入,或者直接导入图片

标定数据
新建标签
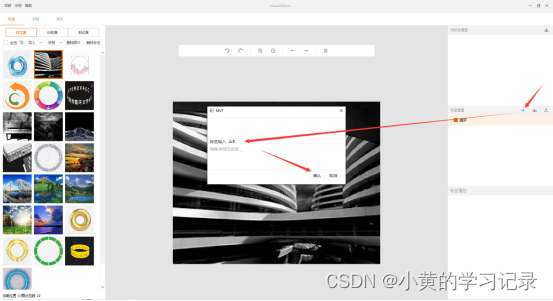
把鼠标放到标签上,点击标签上的小圆点设置标签的颜色
![]()
标签颜色可随意选择

点击小眼睛可设置标签字样是否可见。
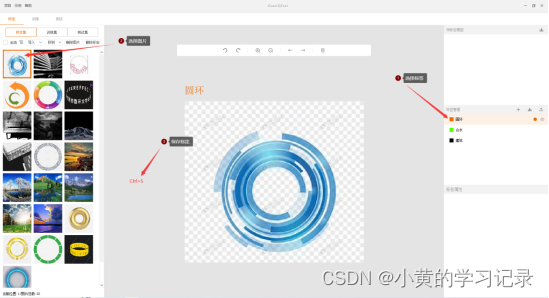
标定工具条
![]()
| 撤回 | 向前撤回一步操作 |
| 恢复 | 向后恢复一步操作 |
| 放大 | 放大图片,滚轮上滚可实现相同效果 |
| 缩小 | 缩小图片,滚轮下滚可实现相同效果 |
| 上一张 | 切换至上一张图片,键盘左键ß可实现相同效果 |
| 下一张 | 切换至下一张图片,键盘右键à可实现相同效果 |
| 删除 | 删除当前图片的标定数据(其它工程中是删除选中的标定数据),键盘delete键可实现相同效果 |
标定,选择标签和图片进行标定,并且使用Ctrl+S保存标定数据。
标定完成后图片左上角出现一个类似图钉的绿色小图标

训练模型
准备训练集图片
标定完成后 选中并移动标定好的图片至训练集,”(未标定的数据会被自动过滤,不会移动到训练集或测试集)
训练界面
类别比例:展示训练集数据的总览。
样本增强:一般用于训练集数据较少时,扩大训练集数据。可自行开启或关闭,可以根据需要设置具体参数。
模型信息:设置训练参数
| 硬件设备 | 选择指定GPU卡训练,无GPU时不支持训练 |
| 模型大小 | 分为小、中、大三个模型可选; 根据任务复杂程度及样本量选择,样本量低于10000,推荐使用小中模型,样本量>10000可以考虑使用大模型 |
| 最大迭代次数 | 最大迭代多少个批次停止训练;范围[1,100000] 样本量<2000,迭代次数5000-8000 样本量2000-5000,迭代次数8000-15000 样本量>5000,迭代次数10000-20000 |
| 提前停止 | 开启提前停止:在训练过程中,模型已经较好时,自动提前停止训练。 开启条件:最大迭代次数需大于1000次,否则置灰不让开启。 |
| 模型保存间隔 | 每迭代多少次保存一次模型;范围[1,最大迭代次数] |
| 测试间隔 | 每迭代多少次进行一次模型测试;范围[1,最大迭代次数] 每次模型测试会将准确率显示在界面上。 |
| 线程数 | 同时开启多个线程用于训练,范围:[1,cpu核数*4],默认会自适应为最大值 建议使用推荐设置 |
| 吞吐量 | 训练时同一批次的图片数量,范围:[1,最大值与剩余显卡内存相关],默认会自适应为最大值 建议使用推荐设置 |
开始训练:
点击“开始训练”,有[重新训练,自定义训练]两个选项。
重新训练:以MVT自带的模型为基础,进行训练。
自定义训练:以指定的模型为基础,进行训练(一般用于继续训练)
训练前记得勾选GPU,不然训练不了。
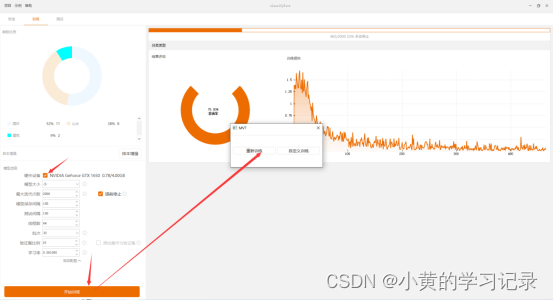
训练之后可以看到模型的训练信息
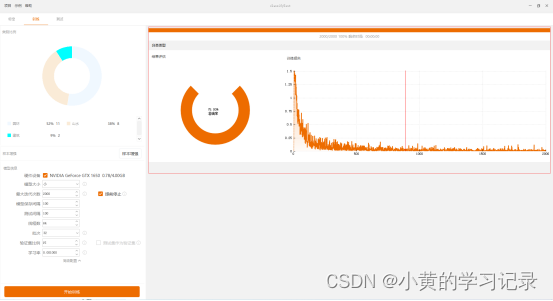
模型测试
准备测试集图片
选择部分已经标定好的图片,移动到测试集。
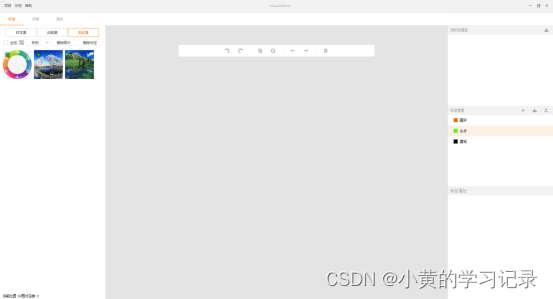
测试模型
切换至“测试”界面。
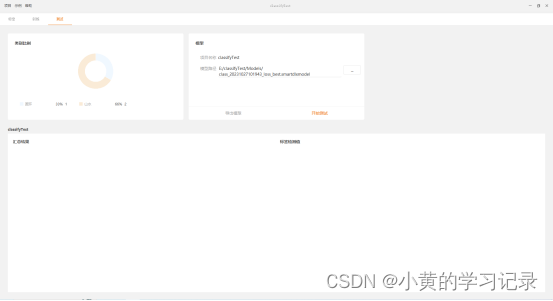
“类别比例”展示测试集数据总览。
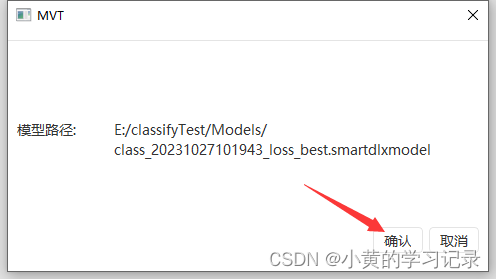
模型路径:默认会选择最新的(创建时间最晚的)xxx_loss_best.smartdlxmodel模型。
开始测试:测试完成后,会展示“汇总结果”、“标签检测值”数据。
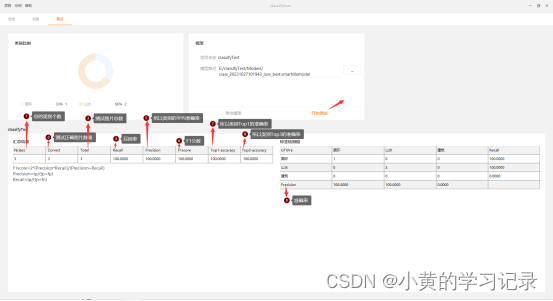
结果参数含义:
| 汇总结果 | |
| nclass | 总类别个数 |
| correct | 测试正确图片数 |
| recall | 召回率 |
| precision | 所有类别的平均准确率 |
| f1score | f1分数 |
| total | 测试图片总数 |
| top1-precision | 预测类别top1的准确率 |
| top3-precision | 预测类别top3的准确率 |
| 标签检测值 | |
| precision | 准确率 |
导出模型:当测试结果比较好时,可进行模型的导出。
预标定
预标定功能:通过已训练好的模型,来推理预测结果,并将该结果作为自动标定的结果,从而提高标定效率。(预标定提高标定效率,需建立在模型较好的前提下。如果模型不太好,需要手动修正错误的标定,提升的效率有限。分类的预标定提升的效率还是很明显的)。
导入模型
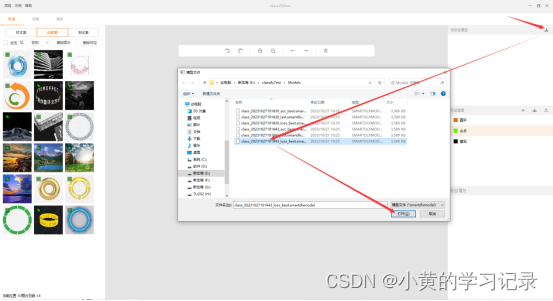
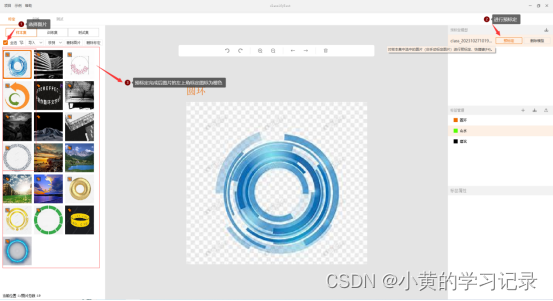
进行预标定:
选中目标图片,当图片能预标定出结果时,该图片左上角会显示“智能标定”的标记(橙色图钉)。
样本集中除手动标定状态(手动标定的图片左上角是绿色图钉)以外的所有图片都会被进行预标定(智能标定的图片也会被预标定,预标定结果将覆盖之前的数据)
分割
深度学习分割,根据某些规则将图片分成若干特定的、具有独特性质的区域,并抽取出感兴趣的目标。多用于需要提取特定区域的场景,如缺陷检测的划痕提取,斑点提取等。
分割工程操作步骤整体流程与分类任务基本一致,个别步骤有所区别:
新建工程、标定数据、训练、测试、预标定。
标定数据

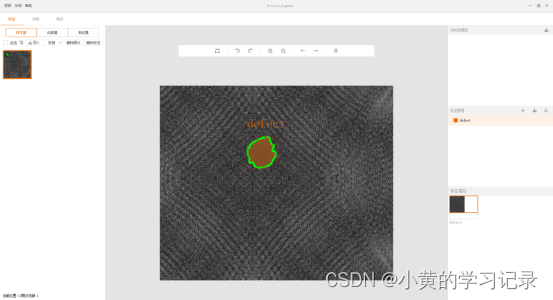
| 多边形 | 绘制分割的边缘 单击,单次绘制多边形 双击,连续绘制多边形 |
区域绘制达到自己的需求时,右键结束绘制,即可完成对缺陷区域的绘制
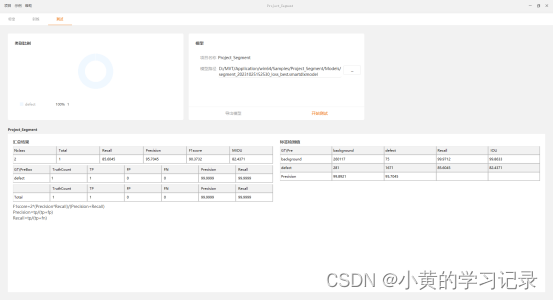
结果参数含义:
| 汇总结果 | |
| miou | 每个分割类别的交并比的平均值 |
| 标签检测值 | |
| classname | 分割类别名称(示例中有1个,defect) |
| miou | 该分割类别的真实标签与预测结果的交集与并集的比值 |
检测
检测工具:

| 正矩形 | 单击,单次绘制正矩形状态; 双击,连续绘制正矩形状态。 |
| 旋转矩形 | 单击,单次绘制旋转矩形状态; 双击,连续绘制旋转矩形状态。 |
结果参数含义:
| 汇总结果表1 | |
| conf_thresh | 检测得分阈值 |
| precision | 精确率,即模型正确预测的正样本(TP)占所有预测出的正样本(TP+FP)的比值 |
| recall | 召回率,即模型正确预测的正样本(TP)占所有正样本数据(TP+FN)的比值 |
| F1-score | F1分数 |
| TP | True-Positive,即检测结果为正样本,真实值为正样本 |
| FP | False-Positive,即检测结果为正样本,真实值为负样本 |
| FN | False-Negative,即检测结果为负样本,真实值为正样本 |
| 汇总结果表2 | |
| mean average precision (mAP@0.50) | 所有检测类别的平均AP(取IOU阈值=0.5) |
| 标签检测值 | |
| className | 类别名称 |
| AP | 该类别下的平均精度 |
| TP | True-Positive,即检测结果为正样本,真实值为正样本 |
| FP | False-Positive,即检测结果为正样本,真实值为负样本 |
OCR识别
标定数据
标签管理
char: 项目默认就有的标签,不能删除。
char标签默认包含114个字符:
62个常用字符0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
52个特殊字符-*#/\:.@$&_<>|%°?!=≠+×÷,;"()[]【】{}±∑∏αβγμξθηδλπ'^φ¥~)
新建定位标签:(若字符所占面积较小,则需要先进行定位,需要建立新标签,新建立的标签都是定位标签。若字符所占面积较大,无需定位处理,则可不新建标签,直接进行字符标定)
标定工具:

| 正矩形 | 单击,单次绘制正矩形状态; 双击,连续绘制正矩形状态。 |
| 旋转矩形 | 单击,单次绘制旋转矩形状态; 双击,连续绘制旋转矩形状态。 |
| 字符切割 | 单击,可自动切割字符、自动标定字符数据,极大提高字符标定的效率。 |
选择待标定图片
先标定字符定位框:
左键选中标签“字符定位框”,左键单击选中对应的标定工具矩形“正矩形”(若字符是倾斜方向,则选择“旋转矩形”),绘制矩形框框中所有字符。
标定字符:
标定字符有两种方法,单字符绘制、多字符切割;
方法一单字符绘制:
选中标签“char”,选择标定工具“正矩形”,绘制矩形框框中单个字符
输入标定数据(如果是多字符切割标定出来的字符标定数据会直接识别出来。)
重复单字符绘制步骤,完成剩下的的字符标定。
方法二多字符切割:
左键选中字符定位矩形框,矩形框变为高亮状态
左键单击标定工具“字符切割”,字符会被自动切割、且自动被标定数据(自动标定的数据需要我们确认一遍正确性)
“字符切割”可极大提高标定效率,默认使用软件内置的OCR识别模型,可用于常规字符的场景。若待标定字符比较特殊,可通过加载预标定模型来提高字符切割的准确率。
保存标定数据:标定好一张图片后,需要按快捷键Ctrl+S进行保存。将剩余图片按上述标定步骤标定好。
训练
移动标定好的图片至训练集。
切换至“训练”界面,可以看到两个子页面:“区域定位”、“字符识别”,因为本示例工程为OCR识别(包含定位),若不包含定位(既不新建“定位标签”)则只有“字符识别”。
“区域定位”和“字符识别”是完全独立的两个子页面,里面的“类别比例”、“样本增强”、“模型信息”、“训练结果”等全是独立的。
开始训练
当GPU显卡内存足够时,可以同时进行区域定位、字符识别的训练。
















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











