







前言
上期笔者介绍了Transformer架构,这个架构是之后各个大模型的基础,本期将介绍基于Transformer架构的BERT,同样会以尽可能通俗易懂的语言,让你对BERT有个真正深入的了解,话不多说,抓紧开始。
基本概念
BERT全称 Bidirectional Encoder Representations from Transformers,意思是多Transformer的双向的编码器表示,由谷歌进行开发。当然由于Transformer架构,它是基于上下文的嵌入模型,但跟Transformer不同的是,它只有编码器,我们可以把它看作只有编码器的Transformer结构,当然还有只有Transformer的解码器结构(GPT架构),以及之后的T5和BART都是结合了编码器和解码器结构。
Transformer的编码器是双向的,它可以从两个方向读取一个句子,因此BERT具备双向编码器的特征,我们将句子送入Transformer的编码器,编码器通过多头注意力层来理解句子的上下文,就可以得到句子中每个单词的特征。
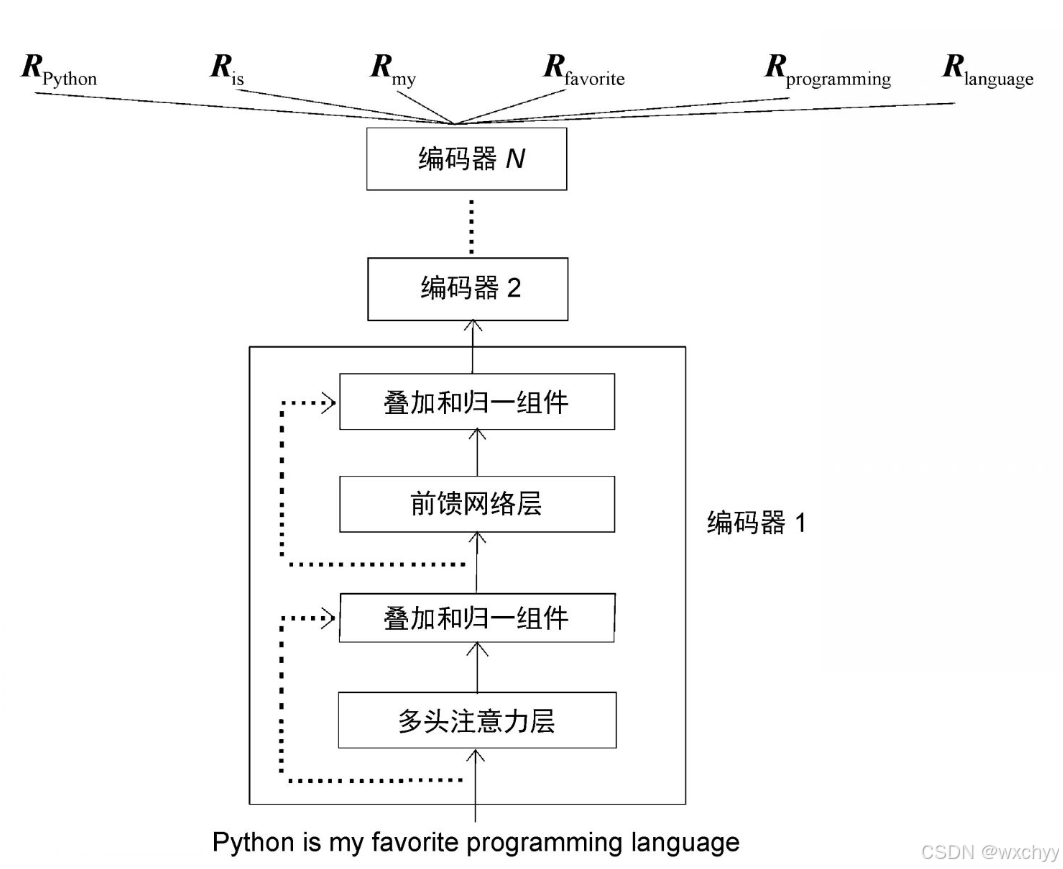
BERT的配置及预训练
BERT配置
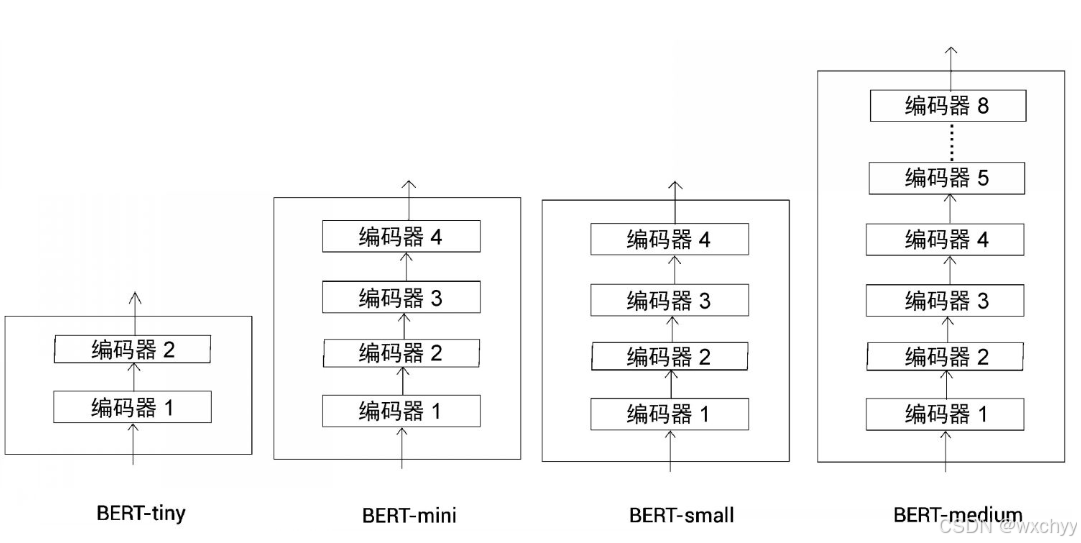
BERT有多种配置,有BERT-base,BERT-large两个标准配置还有一些小型配置。
我们用L表示编码器的层数,A表示注意力头的数量,H表示隐藏神经元的数量。
- BERT-base:L = 12 、A = 12 、 H = 768
- BERT-large : L = 24 、A = 16、H = 1024
- BERT-tiny:L = 2 、A = 2、H = 128
- BERT-mini:L = 4 、 A = 4、H = 256
- BERT-small:L = 4 、A = 8、H = 512
- BERT-medium:L = 8、A = 8、H = 512。
BERT预训练
BERT模型在一个巨大的语料库针对两个特定的任务进行预训练,掩码语言模型构建和下句预测。预训练好的模型BERT,我们将权重保存下来,用于一个新任务,我们只需要根据新任务进行微调即可。
输入数据
在数据输入BERT之前,会经过三个嵌入层,将输入转化为嵌入。
- 标记嵌入层
- 分段嵌入层
- 位置嵌入层
标记嵌入层
在进入标记嵌入层时,我们先需要对句子进行分词,在开头我们,添加[CLS]标记,并将它放在第一句的开头,然后在每个句子的末尾添加新的标记[SEP]标记。
#句子A:Paris is a beautiful city
#句子B:I love Paris(我爱巴黎)
tokens = [Paris, is, a, beautiful, city, I, love, Paris]
tokens = [ [CLS], Paris, is, a, beautiful, city, [SEP], I, love, Paris, [SEP]]
在分完词后,我们将标记输入标记嵌入层,将其转化为向量,具体是每个token(如单词或子词)被分配一个唯一的ID,通过查找表(lookup table)转换为固定维度的向量。

分段嵌入层
分段嵌入层用来区分两个给定的句子。让我们通过前面所列举的两个句子来理解分段嵌入。分段嵌入层只输出嵌入
E
A
或
E
B
E_A或E_B
EA或EB。也就是说,如果输入的标记属于句子A,那么该标记将被映射到嵌入
E
A
E_A
EA;如果该标记属于句子B,那么它将被映射到嵌入
E
B
E_B
EB。

位置嵌入层
BERT本质上是Transformer的编码器,因此在直接向BERT输入词之前,需要给出单词(标记)在句子中的位置信息。位置嵌入层正是用来获得句子中每个标记的位置嵌入的。

最终三个嵌入层的输出通过逐元素相加,形成最终的输入表示,并输入给BERT:

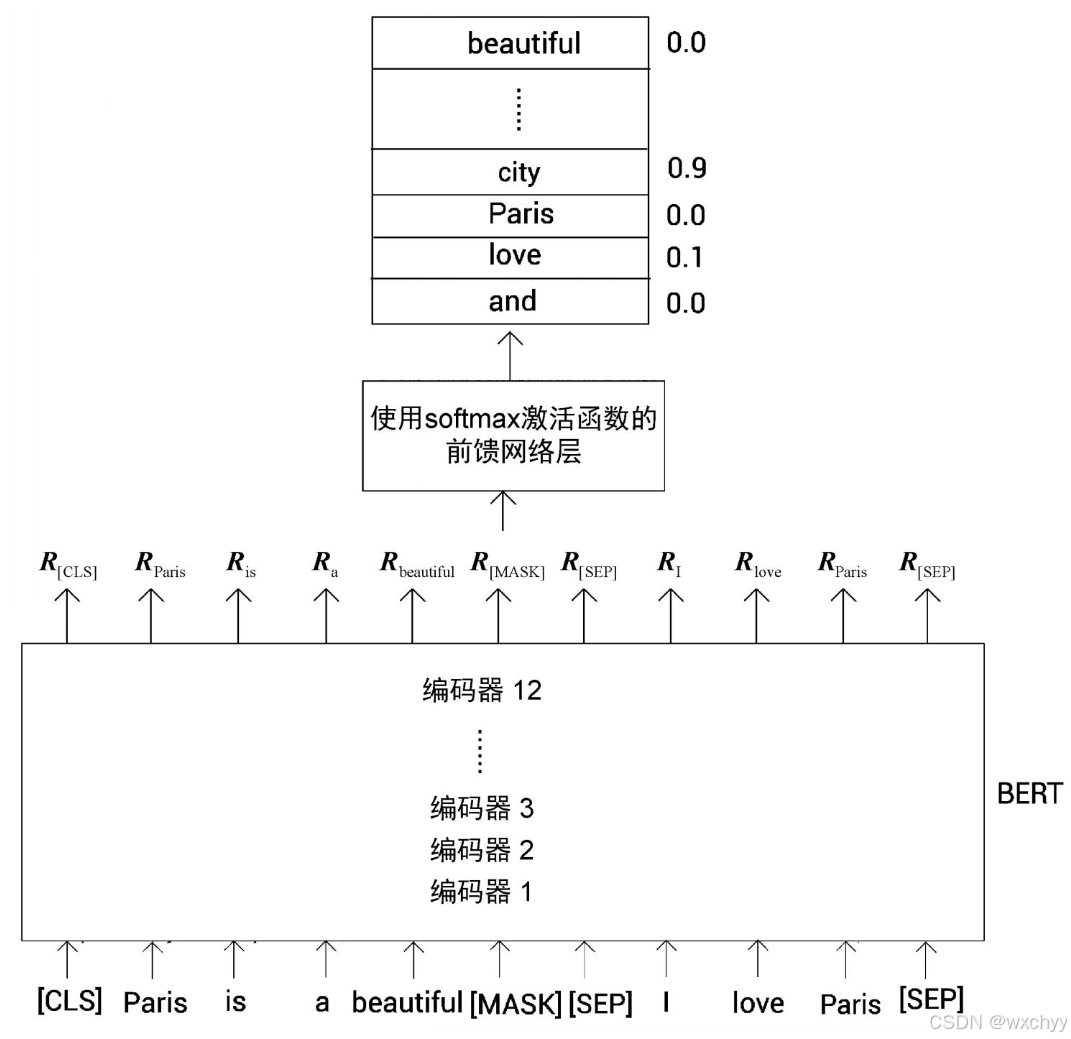
掩码语言模型构建
在掩码语言模型构建任务中,给定一个输入句,我们随机掩盖其中15%的单词,用一个[MASK]标记替换,并训练模型来预测被掩盖的单词。为了预测被掩盖的单词,模型从两个方向阅读该句并进行预测。
tokens = [Paris, is, a, beautiful, city, I, love, Paris]
tokens = [ [CLS], Paris, is, a, beautiful, [MASK], [SEP], I, love, Paris, [SEP] ]
以这种方式掩盖标记会造成预训练和微调之间的差异。也就是说,我们通过预测[MASK]来训练BERT。经过训练后,可以对预训练的BERT模型进行微调,用于执行下游任务,比如情感分析。但在微调期间,我们的输入中不会有任何[MASK]标记。因此,这将导致BERT的预训练方式和用于微调的方式不匹配。为了解决这个问题,我们可以使用80-10-10规则。我们已经随机掩盖了句子中15%的标记。现在,对于这些标记,我们做以下处理。
- 在80%的情况下,使用[MASK]标记来替换该标记(实际词)。
- 对于10%的数据,使用一个随机标记(随机词)来替换该标记(实际词)。
- 对于剩余10%的数据,不做任何改变。
在分词和掩码后,将标记列表送入标记嵌入层、分段嵌入层和位置嵌入层,得到嵌入向量。然后,将嵌入向量送入BERT。BERT将输出每个标记的特征向量。 R [ C L S ] R_{[CLS]} R[CLS]表示[CLS]的特征向量, R P a r i s R_{Paris} RParis表示Paris的特征向量,以此类推。

为了预测被掩盖的词,我们将BERT计算的被掩盖的词的特征向量送入使用softmax激活函数的前馈网络层。然后,前馈网络层将
R
[
M
A
S
K
]
R_{[MASK]}
R[MASK]作为输入,并返回词表中所有单词为被掩盖单词的概率。掩码语言模型构建任务也被称为完形填空任务。
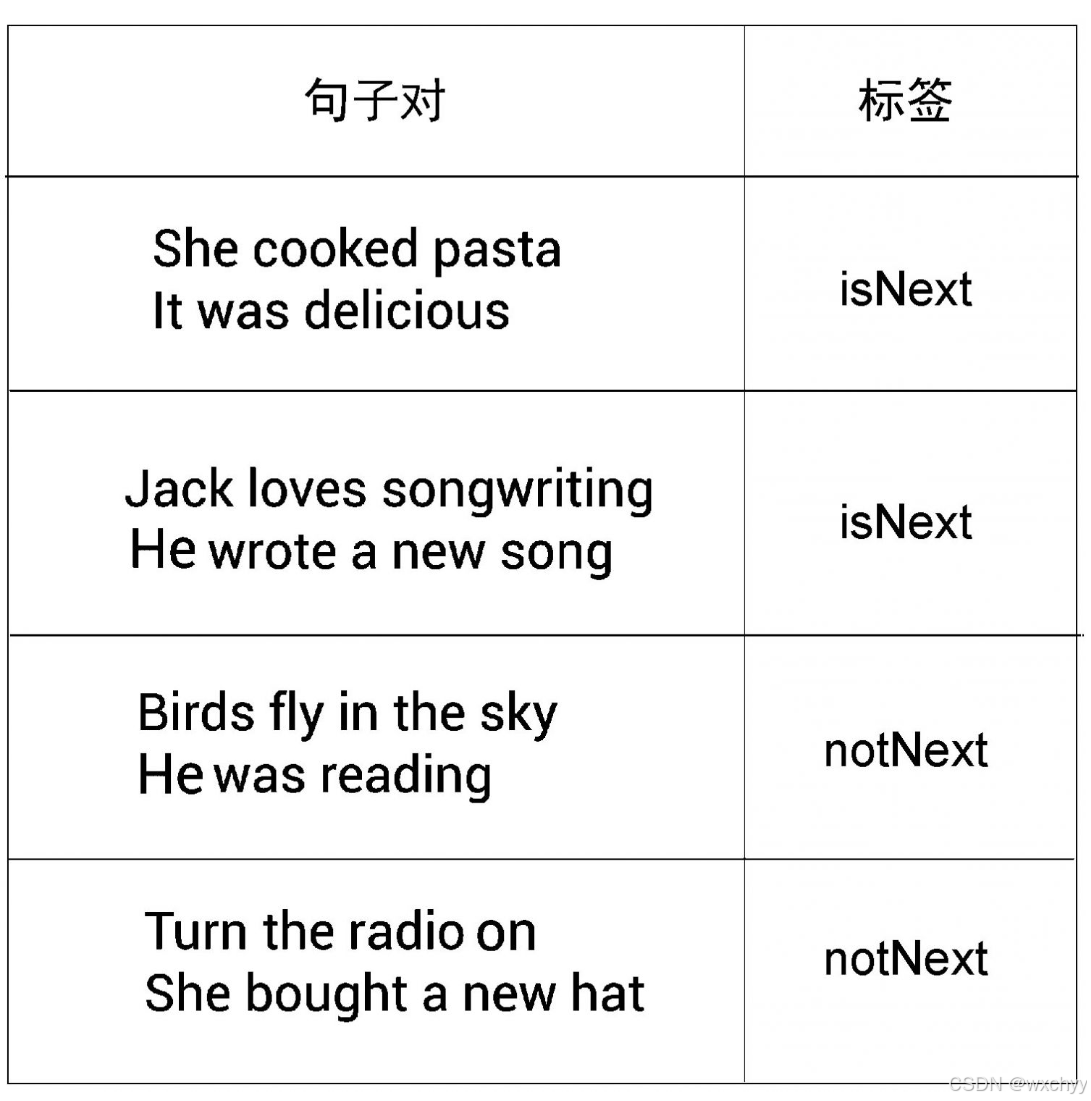
下句预测
下句预测(next sentence prediction)是一个用于训练BERT模型的策略,它是一个二分类任务。在下句预测任务中,我们向BERT模型提供两个句子,它必须预测第二个句子是否是第一个句子的下一句。如果是下一句标记为isNext,不是则标记为notNext。
因为[CLS]标记基本上汇总了所有标记的特征,所以它可以表示句子的总特征。我们可以忽略所有其他标记的特征值,只取[CLS]标记的特征值
R
[
C
L
S
]
R_{[CLS]}
R[CLS],并将其送入使用softmax激活函数的前馈网络层,以得到分类概率。
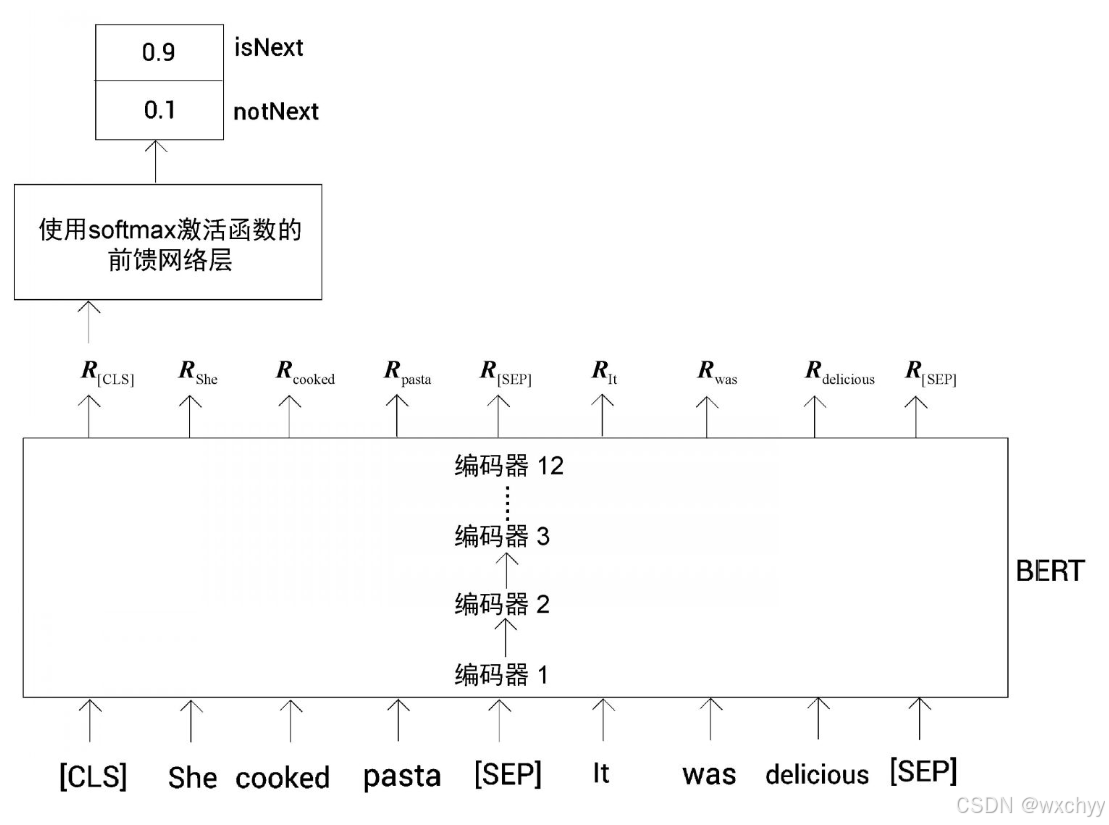
最终,BERT通过**掩码语言模型(完形填空)(MLM)和下句预测任务(NSP)**在使用多伦多图书语料库(Toronto BookCorpus)和维基百科数据集进行预训练得到预训练好的BERT模型,我们可以在huggingface网站上下载其权重,并用于我们需要的任务中。
WordPiece
最后我们在介绍一下BERT的分词器WordPiece。WordPiece是一种子词(subword)分词算法,旨在将单词拆分为更小的语义单元,解决未登录词(OOV)问题。其核心思想是通过合并高频字符对构建词表,同时平衡词表大小与分词粒度。与字节对编码BPE(Byte-Pair Encoding)类似,但合并策略不同。
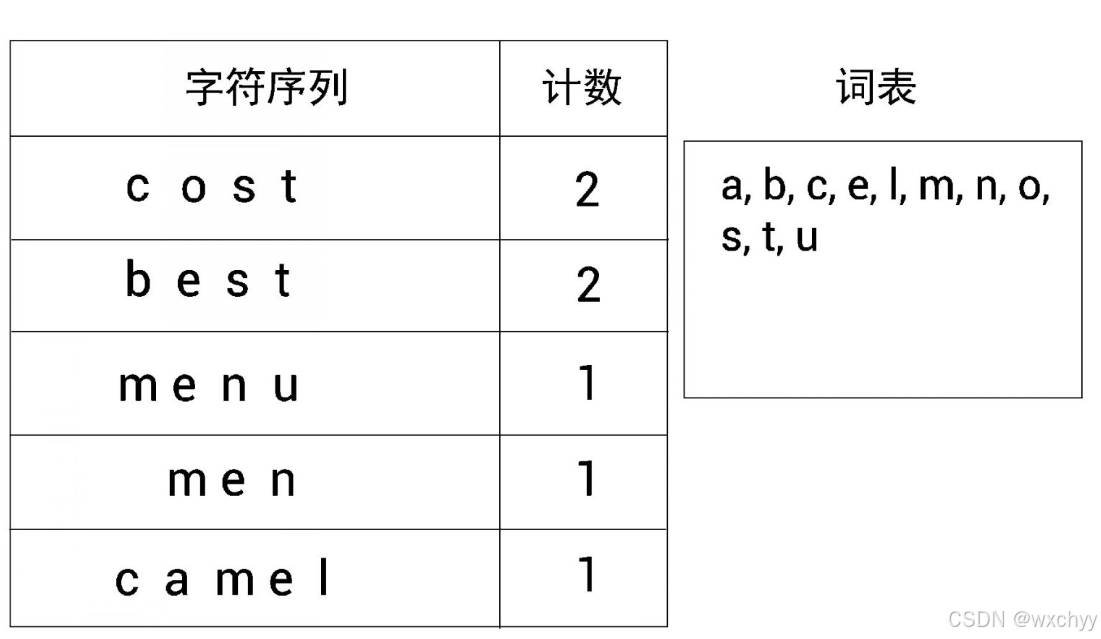
算法步骤如下。
(1) 从给定的数据集中提取单词并计算它们出现的次数。
(2) 确定词表的大小。
(3) 将单词拆分成一个字符序列。
(4) 将字符序列中的所有非重复字符添加到词表中。
(5) 在给定的数据集(训练集)上构建语言模型。
(6) 选择并合并具有最大相似度(基于步骤5中的语言模型)的符号对。
(7) 重复步骤6,直到达到步骤2中所设定的词表大小。
注意:在WordPiece方法中,我们根据相似度合并它们。首先,检查每个符号对的语言模型(在给定的训练集上训练)的相似度。然后,合并相似度最大的符号对。符号对s和t的相似度可以通过下面的公式求得:
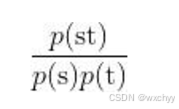
如果相似度很大,就合并符号对,并将它们添加到词表中。通过以上公式,计算出所有符号对的相似度,合并具有最大相似度的符号对,将其添加到词表中。
总结
本期的BERT实际上在理解了Transformer架构后,我们能够很轻松的理解它,它有两个预训练任务,分别为掩码语言模型构建和下句预测,以及有独特的词嵌入方式。相信看完此篇的你对其能有个大致的了解。
参考文献
BERT基础教程:Transformer大模型实战
写在文末
有疑问的友友,欢迎在评论区交流,笔者看到会及时回复。
请大家一定一定要关注!!!
请大家一定一定要关注!!!
请大家一定一定要关注!!!
友友们,你们的支持是我持续更新的动力~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











