







文章目录
- 前言
- 前期回顾
- 常用基础类
- 包装类
- Integer类
- Character类
- String类
- StringBuilder类
- Arrays类
- 数的随机
- 泛型和容器
- 泛型
- ArrayList容器
- LinkedList
- ArrayDeque
- Map
- HashSet
- TreeMap和TreeSet
- LinkedHashMap和LinkedHashSet
- 优先队列
- 抽象容器类
- Collections类
- 容器总结
- 总结
- 参考文献
- 写在文末
前言
这期是Java长文总结的中篇,主要总结Java中常用的类、泛型、容器相关知识。长文预警!!!
前期回顾
常用基础类
包装类
Java前期已经介绍过有8种基本类型,每种基本类型都有一个对应的包装类。包装类种有一个实例变量,它保存着基本类型的值。此外,类中还包括一些静态方法,静态变量和实例方法。我们看一下对应关系。
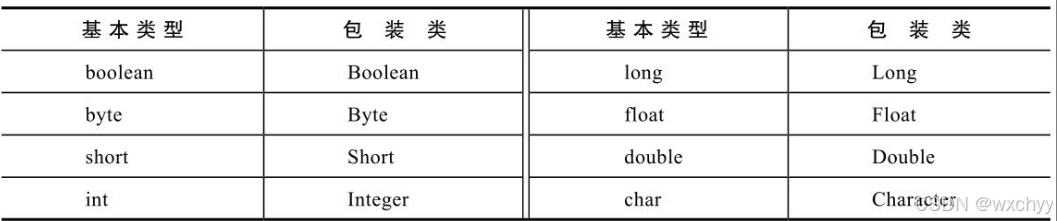
Java很多代码只能操作对象,像容器,所以我们需要对基本类型进行包装成类,可以方便对数据的操作。
1) 每个包装类都有一个静态方法valueOf()进行装包,同时也有实例方法xxxValue()进行拆包,我们通过类名进行访问,这个函数可以将基本类型转化为包装类,不过Java5以后引入了自动包装,以及拆包技术。
Integer a = Integer.valueOf(100);
int b = a.intValue();
//或者
Integer a = 100;
int b = a;
- 包装类一般会重写Object方法
boolean equals(Object obj)//判断当前对象和参数传入的对象是否相同
int hashCode()//hashCode返回一个对象的哈希值,对两个对象,如果equals方法返回true,则hashCode也必须一样,反之不要求
String toString()//返回对象的字符串表示
3)包装类一般实现Java API中的Comparable接口
public interface Comparable<T> {
public int compareTo(T o);
}
- 包装类中除了Character外,每个包装类都有一个静态的valueOf(String)方法、静态的parseXXX(String)方法以及静态toString方法。
Boolean b = Boolean.valueOf("true");
Float f = Float.valueOf("123.45f");
boolean b = Boolean.parseBoolean("true");
double d = Double.parseDouble("123.45");
System.out.println(Boolean.toString(true));
System.out.println(Double.toString(123.45));
5)包装类中定义了一些静态变量,包括所有数值类型都定义了MAⅩ_VALUE和MIN_VALUE,Float和Double还定义了一些特殊数值,比如正无穷、负无穷、非数值等等
public static final int MIN_VALUE = 0x80000000;
public static final int MAX_VALUE = 0x7fffffff;
public static final double POSITIVE_INFINITY = 1.0 / 0.0; //正无穷
public static final double NEGATIVE_INFINITY = -1.0 / 0.0; //负无穷
public static final double NaN = 0.0d / 0.0; //非数值
6)6种数值类型包装类有一个共同的父类Number。Number是一个抽象类,在其中定义了一些方法。通过这些方法,包装类实例可以返回任意的基本数值类型。
byte byteValue()
short shortValue()
int intValue()
long longValue()
float floatValue()
double doubleValue()
- 不可变性 所有的包装类都声明为了final,不能被继承,同时内部的基本类型都是私有的且声明为final,没有定义setter方法。
Integer类
- 位反转:将int当作二进制,左边的位和右边的位进行互换,reverse是按位进行互换, reverseBytes是按byte进行互换。
- 循环移位,以左移举例,最高2位移动到最低2位,其他位向左移动
- valueOf的实现是通过一种叫做享元模式的设计思路进行设计的,在Integer包装类中有私有静态内部类IntegerCache,里面有个cache变量(静态Integer数组)在静态初始化中就已经被初始化了,保存了-128~127共256个整数对应的Integer对象,当数值位于这个范围内,直接进行获取就行,只有不在范围内,才使用new创建对象,所以在创建包装类对象时,我们一般使用静态的valueOf方法。(仅做了解)
public static int reverse(int i)
public static int reverseBytes(int i)
public static int rotateLeft(int i, int distance)
public static int rotateRight(int i, int distance)
Character类
Character类在Unicode字符级别(而非char级别)封装了字符的各种操作,在上期我们介绍了Unicode,每个字符都有一个编号。
在Java内部使用UTF-16进行编码,对于常用字符集(BMP),使用两字节,而对于增补字符集则需要2个char,4个字节表示,一个表示高代理项,一个表示低代理项。我们可以使用int可以表示任意一个Unicode字符,低21位表示Unicode编号,高11位表示0。整数编号在Unicode称为代码点,表示一个Unicode字符,与之相对,还有一个代码单元表示一个char,是用于存储代码点的最小单位。通俗理解两者关系,也就是说如果是常用字符集(一个代码点)一个代码单元存储,但如果是增补字符集(一个代码点),需要两个代码单元(也就是一个代理对Surrogate Pair)存储。
我们看一下Character的静态方法。
- 检查code point和char
//判断一个int是不是一个有效的代码点,小于等于0x10FFFF的为有效,大于的为无效
public static boolean isValidCodePoint(int codePoint)
//判断一个int是不是BMP字符,小于等于0xFFFF的为BMP字符,大于的不是
public static boolean isBmpCodePoint(int codePoint)
//判断一个int是不是增补字符,0x010000~0X10FFFF为增补字符
public static boolean isSupplementaryCodePoint(int codePoint)
//判断char是否是高代理项,0xD800~0xDBFF为高代理项
public static boolean isHighSurrogate(char ch)
//判断char是否为低代理项,0xDC00~0xDFFF为低代理项
public static boolean isLowSurrogate(char ch)
//判断char是否为代理项, char为低代理项或高代理项,则返回true
public static boolean isSurrogate(char ch)
//判断两个字符high和low是否分别为高代理项和低代理项
public static boolean isSurrogatePair(char high, char low)
//判断一个代码点由几个char组成,增补字符返回2, BMP字符返回1
public static int charCount(int codePoint)
- 获取字符类型(general category);检查字符是否为数字;检查是否为字母(Letter)
public static int getType(int codePoint)//获取字符类型
public static int getType(char ch)//获取字符类型
public static boolean isDigit(int codePoint)//检查字符是否为数字
public static boolean isLetter(int codePoint)//检查是否为字母
- 字符转换
public static int toLowerCase(int codePoint)
public static int toUpperCase(int codePoint)
String类
- 字符串可以通过常量、new以及运算符+和+=来创建String变量。
String name = "Hello";
String name = new String("Hello")
String name +="Hello";
- String类包括很多方法,以方便操作字符串
public boolean isEmpty() //判断字符串是否为空
public int length() //获取字符串长度
public String substring(int beginIndex) //取子字符串
public String substring(int beginIndex, int endIndex) //取子字符串
public int indexOf(int ch) //查找字符,返回第一个找到的索引位置,没找到返回-1
public int indexOf(String str) //查找子串,返回第一个找到的索引位置,没找到返回-1
public int lastIndexOf(int ch) //从后面查找字符
public int lastIndexOf(String str) //从后面查找子字符串
public boolean contains(CharSequence s) //判断字符串中是否包含指定的字符序列
public boolean startsWith(String prefix) //判断字符串是否以给定子字符串开头
public boolean endsWith(String suffix) //判断字符串是否以给定子字符串结尾
public boolean equals(Object anObject) //与其他字符串比较,看内容是否相同
public boolean equalsIgnoreCase(String anotherString) //忽略大小写比较是否相同
public int compareTo(String anotherString) //比较字符串大小
public int compareToIgnoreCase(String str) //忽略大小写比较
public String toUpperCase() //所有字符转换为大写字符,返回新字符串,原字符串不变
public String toLowerCase() //所有字符转换为小写字符,返回新字符串,原字符串不变
public String concat(String str) //字符串连接,返回当前字符串和参数字符串合并结果
public String replace(char oldChar, char newChar) //字符串替换,替换单个字符
public String replace(CharSequence target, CharSequence replacement)//字符串替换,替换字符序列,返回新字符串,原字符串不变
public String trim() //删掉开头和结尾的空格,返回新字符串,原字符串不变
public String[] split(String regex) //分隔字符串,返回分隔后的子字符串数组
public char charAt(int index) //返回指定索引位置的char
//返回字符串对应的char数组, 注意,返回的是一个复制后的数组,而不是原数组
public char[] toCharArray()
//将char数组中指定范围的字符复制入目标数组指定位置
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin)
- String类跟包装类类似,被声明位final,是不可变类,不能被继承。所以String的concat()方法原来的String对象不会被修改,而是新创建了一个对象。
- Java中的字符串常量,可以直接调用String的各种方法,本质上,这些常量就是String类型的对象,被放在一个共享的地方(字符串常量池),它保存所有的常量字符串,每个常量只会保存一份,被所有使用者共享。**当通过常量的形式使用一个字符串的时候,使用的就是常量池中的那个对应的String类型的对象。**我们可以做个对比,
# 1
String name1 = "Hello";
String name2 = "Hello";
System.out.println(name1==name2);
# 2
String name1 = new String("Hello");
String name2 = new String("Hellp")
System.out.println(name1==name2);
第1种为True,第2种为False。
StringBuilder类
- 如果对字符串修改操作比较频繁的话,我们会使用StringBuilder和StringBuffer,因为String是不可变的,每次修改都需要new一个新的对象,而StringBuilder维护的是一个可变的字符数组,可以直接修改。StringBuilder和StringBuffer区别在于StringBuilder是非线程安全的,如果在单线程情况下我们使用StringBuilder。
- 使用方法,通过append方法添加字符串,通过toString方法获取构建后的字符串。
StringBuilder sb = new StringBuilder();
sb.append("Hello");
sb.append(" World");
String result = sb.toString();
System.out.println(result);
- 常用函数:
public StringBuilder insert(int offset, String str)//在指定索引offset处插入字符串str
Arrays类
- toString
Arrays的toString()方法可以将数组直接输出字符串形式。如果不使用这个方法,直接输出数组本身,将会输出内存地址等信息,难以阅读。
public static String toString(int[] a)
public static String toString(Object[] a)
2)排序sort,sort可以排序基本类型,还可以排序对象类型,除了基本类型,但对象需要实现Comparable接口。
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
}
public static void sort(int[] a)
public static void sort(double[] a)
如果需要从大到小排序,对应对象类型,可以指定一个不同的Comparator,可以使用匿名内部类来实现。
String[] arr = {"hello", "world", "Break", "abc"};
Arrays.sort(arr, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareToIgnoreCase(o1);
}
});
System.out.println(Arrays.toString(arr));
- 查找
二分查找既可以针对基本类型数组,也可以针对对象数组,对于对象数组,需要传递Comparator。
public static int binarySearch(int[] a, int key)
public static int binarySearch(int[] a, int fromIndex, int toIndex, int key)
public static int binarySearch(Object[] a, Object key)//对象数组
- 判断两个数组是否相同
public static boolean equals(boolean[] a, boolean[] a2)
public static boolean equals(Object[] a, Object[] a2)
- 复制一个新数组
public static long[] copyOf(long[] original, int newLength)
public static <T> T[] copyOf(T[] original, int newLength)
- 给数组每个元素设置相同的值
public static void fill(int[] a, int val)
public static void fill(int[] a, int fromIndex, int toIndex, int val)
- 如果是多维数组,我们需要在方法前面加上deep。
int[][] arr = new int[][]{{0,1}, {2,3,4}, {5,6,7,8}};
System.out.println(Arrays.deepToString(arr));
数的随机
- Math.random输出的是0 ~ 1之间的随机数,类型为double
System.out.println(Math.random());
2)Random类
需要创建出一个对象,有以下方法:
Random rnd = new Random();
System.out.println(rnd.nextInt());//产生一个随机的int
System.out.println(rnd.nextInt(100));//产生一个随机int,范围是0~100
public long nextLong() //随机生成一个long
public boolean nextBoolean() //随机生成一个boolean
public void nextBytes(byte[] bytes) //产生随机字节, 字节个数就是bytes的长度
public float nextFloat() //随机浮点数,从0到1,包括0不包括1
public double nextDouble() //随机浮点数,从0到1,包括0不包括1
泛型和容器
泛型
- 泛型,通俗来讲,就是广泛的类型,同一套代码可以支持不同的数据类型。在类名后面加上,T表示类型参数,可以支持不同类型,使用方法,在创建对象的时候加上具体类型如
public class Pair<T> {
T first;
T second;
public Pair(T first, T second){
this.first = first;
this.second = second;
}
public T getFirst() {
return first;
}
public T getSecond() {
return second;
}
}
Pair<Integer> minmax = new Pair<Integer>(1,100);
Integer min = minmax.getFirst();
Integer max = minmax.getSecond();
- 泛型也可以支持不同类型,<U,V>,泛型的本质是Java编译器和JVM将其全部转化为Object类型,再进行强制类型转化,这种称为类型擦除。
- 通过泛型,我们可以实现各种容器类。
- 泛型不仅可以支持类,也可以支持方法的泛型,在返回值前面放参数T。同样也支持多个类型。
public static <T> int indexOf(T[] arr, T elm){
for(int i=0; i<arr.length; i++){
if(arr[i].equals(elm)){
return i;
}
}
return -1;
}
- 泛型接口,接口也是可以泛型的,在实现接口时,指定具体的类型。
public interface Comparable<T> {
public int compareTo(T o);
}
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
}
6)如果我们需要对类型参数进行限界,就是传递的类型参数必须为给定的上界类型或子类型,这个限定我们可以通过extends实现。下面例子限定两个类型参数必须为Number。
7) 限定我们也可以通过通配符来实现。
无限定通配符(?):表示未知类型。
上界通配符(? extends T):表示类型必须是 T 或者 T 的子类。
下界通配符(? super T):表示类型必须是 T 或者 T 的父类。
public class NumberPair<U extends Number, V extends Number>
extends Pair<U, V> {
public NumberPair(U first, V second) {
super(first, second);
}
}
- 不能创建泛型数组。
ArrayList容器
1)ArrayList是一个泛型容器。主要使用方法:
ArrayList<Integer> intList = new ArrayList<Integer>();
ArrayList<String> strList = new ArrayList<String>();
public boolean add(E e) //添加元素到末尾
public boolean isEmpty() //判断是否为空
public int size() //获取长度
public E get(int index) //访问指定位置的元素
public int indexOf(Object o) //查找元素, 如果找到,返回索引位置,否则返回-1
public int lastIndexOf(Object o) //从后往前找
public boolean contains(Object o) //是否包含指定元素,依据是equals方法的返回值
public E remove(int index) //删除指定位置的元素, 返回值为被删对象
public boolean remove(Object o)//删除指定对象,只删除第一个相同的对象,返回值表示是否删除了元素//如果o为null,则删除值为null的元素
public void clear() //删除所有元素
public void add(int index, E element)//在指定位置插入元素,index为0表示插入最前面,index为ArrayList的长度表示插到最后面
public E set(int index, E element) //修改指定位置的元素内容
我们可以通过foreach进行访问。
原理实现:通过实现Iterable接口,接口内实现iterator方法。
ArrayList<Integer> intList = new ArrayList<Integer>();
intList.add(123);
intList.add(456);
intList.add(789);
for(Integer a : intList){
System.out.println(a);
}
特点:插入和删除元素的效率比较低,因为需要移动元素,具体为O(N)。
LinkedList
ArrayList随机访问效率很高,但插入和删除性能比较低;LinkedList与ArrayList用法类似,支持List接口,只是,LinkedList增加了一个接口Deque,我们可以把它看作队列、栈、双端队列,方便地在两端进行操作。LinkedList的本质是使用了双向链表。
//初始构造方法
public LinkedList()
public LinkedList(Collection<? extends E> c)
List<String> list = new LinkedList<String>();
//插入元素
list.add("a");
list.add("b");
//根据索引访问元素get
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//删除元素
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//实现队列接口Queue
public interface Queue<E> extends Collection<E> {
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E element();
E peek();
}
//把LinkedList当作Queue使用
Queue<String> queue = new LinkedList<>();
queue.offer("a");
queue.offer("b");
queue.offer("c");
while(queue.peek()! =null){
System.out.println(queue.poll());
}
//把LinkedList当作栈使用
Deque<String> stack = new LinkedList<>();
stack.push("a");
stack.push("b");
stack.push("c");
while(stack.peek()! =null){
System.out.println(stack.pop());
}
//把LinkedList当作双端队列使用
Deque<String> deque = new LinkedList<>(
Arrays.asList(new String[]{"a", "b", "c"}));
Iterator<String> it = deque.descendingIterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
ArrayDeque
ArrayDeque实现了双端队列,内部使用循环数组实现。
1)在两端添加、删除元素的效率很高
2)根据元素内容查找和删除的效率比较低,为O(N)
3) 与ArrayList和LinkedList不同,没有索引位置的概念,不能根据索引位置进行操作
//构造方法
public ArrayDeque()
public ArrayDeque(int numElements)
public ArrayDeque(Collection<? extends E> c)
//尾部添加
public boolean add(E e) {
addLast(e);
return true;
}
//头部添加
public void addFirst(E e) {
if(e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if(head == tail)
doubleCapacity();
}
//从头部删除
public E removeFirst() {
E x = pollFirst();
if(x == null)
throw new NoSuchElementException();
return x;
}
//查看长度
public int size() {
return (tail - head) & (elements.length - 1);
}
//检查给定元素是否存在
public boolean contains(Object o) {
if(o == null)
return false;
int mask = elements.length - 1;
int i = head;
E x;
while( (x = elements[i]) ! = null) {
if(o.equals(x))
return true;
i = (i + 1) & mask;
}
return false;
}
//toArray方法
public Object[] toArray() {
return copyElements(new Object[size()]);
}
Map
HashMap由Hash和Map两个单词组成,这里Map不是地图的意思,而是表示映射关系,是一个接口,实现Map接口有多种方式,HashMap实现的方式利用了哈希(Hash)。我们看一下Map接口的API
public interface Map<K, V> { //K和V是类型参数,分别表示键(Key)和值(Value)的类型
V put(K key, V value); //保存键值对,如果原来有key,覆盖,返回原来的值
V get(Object key); //根据键获取值, 没找到,返回null
V remove(Object key); //根据键删除键值对, 返回key原来的值,如果不存在,返回null
int size(); //查看Map中键值对的个数
boolean isEmpty(); //是否为空
boolean containsKey(Object key); //查看是否包含某个键
boolean containsValue(Object value); //查看是否包含某个值
void putAll(Map<? extends K, ? extends V> m); //保存m中的所有键值对到当前Map
void clear(); //清空Map中所有键值对
Set<K> keySet(); //获取Map中键的集合
Collection<V> values(); //获取Map中所有值的集合
Set<Map.Entry<K, V>> entrySet(); //获取Map中的所有键值对
interface Entry<K, V> { //嵌套接口,表示一条键值对
K getKey(); //键值对的键
V getValue(); //键值对的值
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
boolean equals(Object o);
int hashCode();
}
boolean containsValue(Object value);
Set<K> keySet();
我们看一下常见用例:
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// 创建一个 HashMap 对象
HashMap<String, Integer> map = new HashMap<>();
// 插入键值对
map.put("apple", 1);
map.put("banana", 2);
map.put("cherry", 3);
// 获取指定键对应的值
int value = map.get("banana");
System.out.println("Value of banana: " + value);
// 检查是否包含指定的键
boolean containsKey = map.containsKey("apple");
System.out.println("Contains key 'apple': " + containsKey);
// 检查是否包含指定的值
boolean containsValue = map.containsValue(3);
System.out.println("Contains value 3: " + containsValue);
// 获取键值对的数量
int size = map.size();
System.out.println("Size of the map: " + size);
// 遍历 HashMap
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 删除指定键的键值对
map.remove("cherry");
System.out.println("After removing 'cherry': " + map);
}
}
PS: 1 HashMap不是线程安全的 2 HashMap中的键值对没有顺序,因为hash值是随机的
HashSet
HashMap与HashMap类似,字面上看,HashSet由两个单词组成:Hash和Set。其中,Set表示接口,实现Set接口也有多种方式,各有特点,Hash-Set实现的方式利用了Hash。Set表示的是没有重复元素、且不保证顺序的容器接口,它扩展了Collection,但没有定义任何新的方法,不过,对于其中的一些方法,它有自己的规范。
HashSet 内部使用 HashMap 来存储元素,HashSet 中的元素被作为 HashMap 的键,而 HashMap 的值则是一个固定的静态对象 PRESENT。当向 HashSet 中添加元素时,实际上是将该元素作为键存储到 HashMap 中,值为 PRESENT。通过 HashMap 的哈希机制,HashSet 可以快速判断元素是否已经存在于集合中。
Set接口的完整定义如下:
public interface Set<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
//迭代遍历时,不要求元素之间有特别的顺序
//HashSet的实现就是没有顺序,但有的Set实现可能会有特定的顺序,比如TreeSet
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
//添加元素, 如果集合中已经存在相同元素了,则不会改变集合,直接返回false,
//只有不存在时,才会添加,并返回true
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<? > c);
//重复的元素不添加,不重复的添加,如果集合有变化,返回true,没变化返回false
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<? > c);
boolean removeAll(Collection<? > c);
void clear();
boolean equals(Object o);
int hashCode();
}
与HashMap类似,HashSet要求元素重写hashCode和equals方法,且对于两个对象,如果equals相同,则hashCode也必须相同。我们看一下它的一些示例:
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
// 创建一个 HashSet 对象
HashSet<String> set = new HashSet<>();
// 添加元素
set.add("apple");
set.add("banana");
set.add("cherry");
// 检查集合是否包含指定元素
boolean contains = set.contains("banana");
System.out.println("Set contains 'banana': " + contains);
// 获取集合的大小
int size = set.size();
System.out.println("Size of the set: " + size);
// 遍历 HashSet
for (String element : set) {
System.out.println(element);
}
// 删除指定元素
set.remove("cherry");
System.out.println("After removing 'cherry': " + set);
// 检查集合是否为空
boolean isEmpty = set.isEmpty();
System.out.println("Is the set empty? " + isEmpty);
}
}
特点:
1)没有重复元素;
2)可以高效地添加、删除元素、判断元素是否存在,效率都为O(1)
3)没有顺序
HashSet可以方便高效地实现去重、集合运算等功能。
TreeMap和TreeSet
相较于HashMap和HashSet通过哈希实现,TreeMap和TreeSet通过排序二叉树(红黑树)实现,键值对之间按键有序。TreeMap是按键有序的,默认从小到大,可以通过传比较器对象进行修改。举例:
Map<String, String> map = new TreeMap<>(new Comparator<String>(){
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
//或者Collections类有一个静态方法reverseOrder()可以返回一个逆序比较器
Map<String, String> map = new TreeMap<>(Collections.reverseOrder());
其他我就不多累述了,跟HashMap主要区别就是键值是否有序。
LinkedHashMap和LinkedHashSet
LinkedHashMap是HashMap的子类,但可以保持元素按插入或访问有序(内部有一个双向链表以维护节点的顺序),这与TreeMap按键排序不同。LinkedHashSet是HashSet的子类,它内部的Map的实现类是LinkedHashMap,所以它也可以保持插入顺序,这里我们只看LinkedHashMap。
Map<String, Integer> seqMap = new LinkedHashMap<>();
seqMap.put("c", 100);
seqMap.put("d", 200);
seqMap.put("a", 500);
seqMap.put("d", 300);
for(Entry<String, Integer> entry : seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
//输出
c 100
d 300
a 500
我们可以看到按照插入顺序输出。
优先队列
PriorityQueue。顾名思义,PriorityQueue是优先级队列,它首先实现了队列接口(Queue),与LinkedList类似,它的队列长度也没有限制,与一般队列的区别是,它有优先级的概念,每个元素都有优先级,队头的元素永远都是优先级最高的。PriorityQueue内部是用堆实现的,内部元素不是完全有序的,不过,逐个出队会得到有序的输出。
//实现Queue接口
public interface Queue<E> extends Collection<E> {
boolean add(E e); //在尾部添加元素,队列满时抛异常
boolean offer(E e); //在尾部添加元素,队列满时返回false
E remove(); //删除头部元素,队列空时抛异常
E poll(); //删除头部元素,队列空时返回null
E element(); //查看头部元素,队列空时抛异常
E peek(); //查看头部元素,队列空时返回null
}
//基础示例
Queue<Integer> pq = new PriorityQueue<>();
pq.offer(10);
pq.add(22);
pq.addAll(Arrays.asList(new Integer[]{11, 12, 34, 2, 7, 4, 15, 12, 8, 6, 19, 13 }));
while(pq.peek()! =null){
System.out.print(pq.poll() + " ");
}
//输出
2 4 6 7 8 10 11 12 12 13 15 19 22 34
抽象容器类
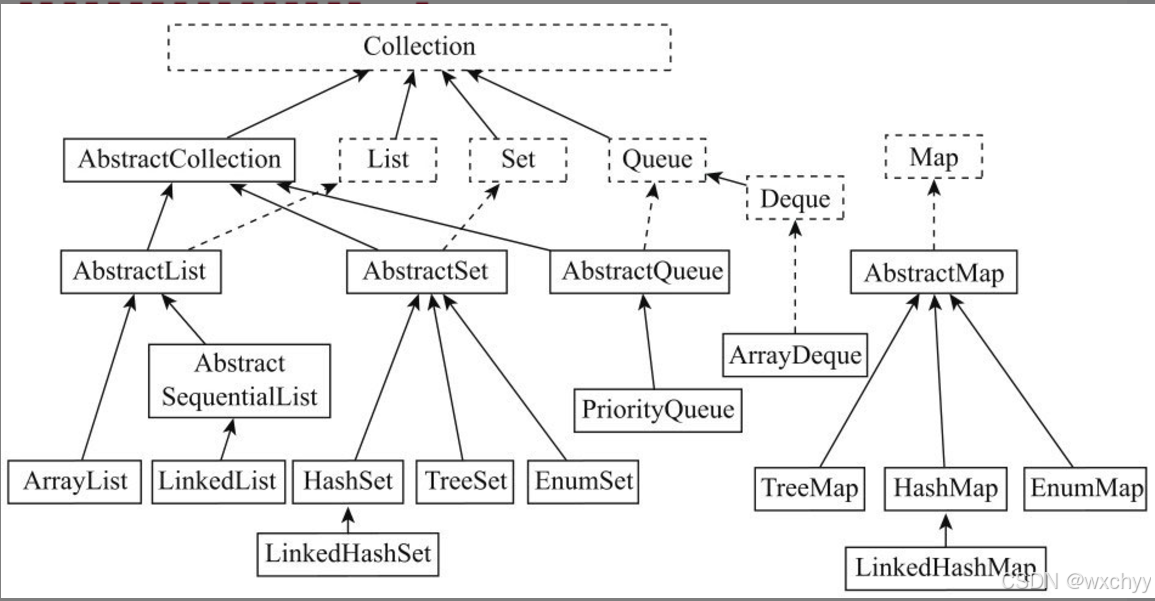
虚线框表示接口,有Collection、List、Set、Queue、Deque和Map。
有6个抽象容器类。
1)AbstractCollection:实现了Collection接口,被抽象类AbstractList、AbstractSet、AbstractQueue继承。
2)AbstractList:实现了List接口,被ArrayList、Abstract-SequentialList继承。
3)AbstractSequentialList:父类是AbstractList,被LinkedList继承。
4)AbstractMap:实现了Map接口,被TreeMap、HashMap、EnumMap继承。
5)AbstractSet:父类是AbstractCollection,实现了Set接口,被HashSet、TreeSet和EnumSet继承。
6)AbstractQueue:父类是AbstractCollection,实现了Queue接口,被PriorityQueue继承。
Collections类
类Collections以静态方法的方式提供了很多通用算法和功能。第一类操作是一些通用算法,包括查找、替换、排序、调整顺序、添加、修改等,这些算法操作的都是容器接口对象,这是面向接口编程的一种体现,只要对象实现了这些接口,就可以使用这些算法。第二类操作都返回一个容器接口对象,这些方法代表两种设计模式,一种是适配器,另一种是装饰器。
1)二分查找
2)查找最大值/最小值
3)排序、交换位置与翻转
4)随机化重排
5)循环移位
6)添加和修改
7)适配器
8)装饰器
容器总结
容器类有两个根接口,分别是Collection和Map, Collection表示单个元素的集合,Map表示键值对的集合。Collection表示的数据集合有基本的增、删、查、遍历等方法,但没有定义元素间的顺序或位置,也没有规定是否有重复元素。List是Collection的子接口,表示有顺序或位置的数据集合,增加了根据索引位置进行操作的方法。Set也是Collection的子接口,它没有增加新的方法,但保证不含重复元素。Queue是Collection的子接口,表示先进先出的队列,在尾部添加,从头部查看或删除。Map接口表示键值对集合,经常根据键进行操作,它有两个主要的实现类:HashMap和TreeMap。HashMap还有一个子类LinkedHashMap,它可以按插入或访问有序。
总结
本篇文章总结了类、泛型、容器内容,下篇继续总结。
参考文献
Java编程的逻辑 马俊昌
写在文末
如果想要更深入学习Java的友友,关注我,下期更精彩
请大家一定一定要关注!!!
请大家一定一定要关注!!!
请大家一定一定要关注!!!
友友们,你们的支持是我持续更新的动力~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











