







目录
前言
本期将介绍大模型微调的各种方法,传统的全量微调对于普通硬件环境来说,十分困难,对此本期将介绍一些高效微调的方法。
主流的高效微调方法介绍
我们将高效微调方法粗略分为三类,Additive(增加额外参数),Selective(选取一部分参数更新)、Reparametrization-based(引入重参数化)。
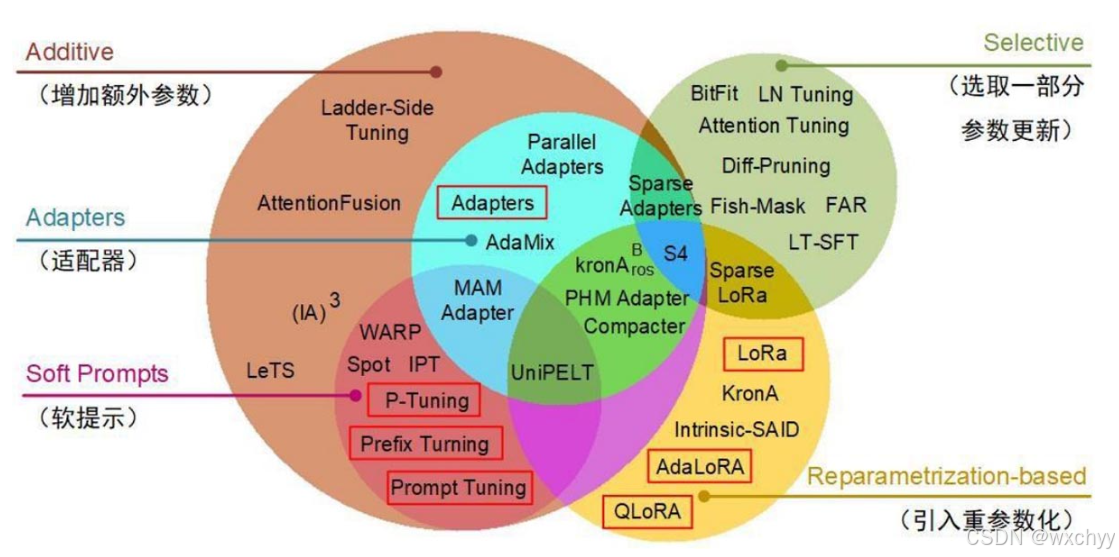
(1) Additive
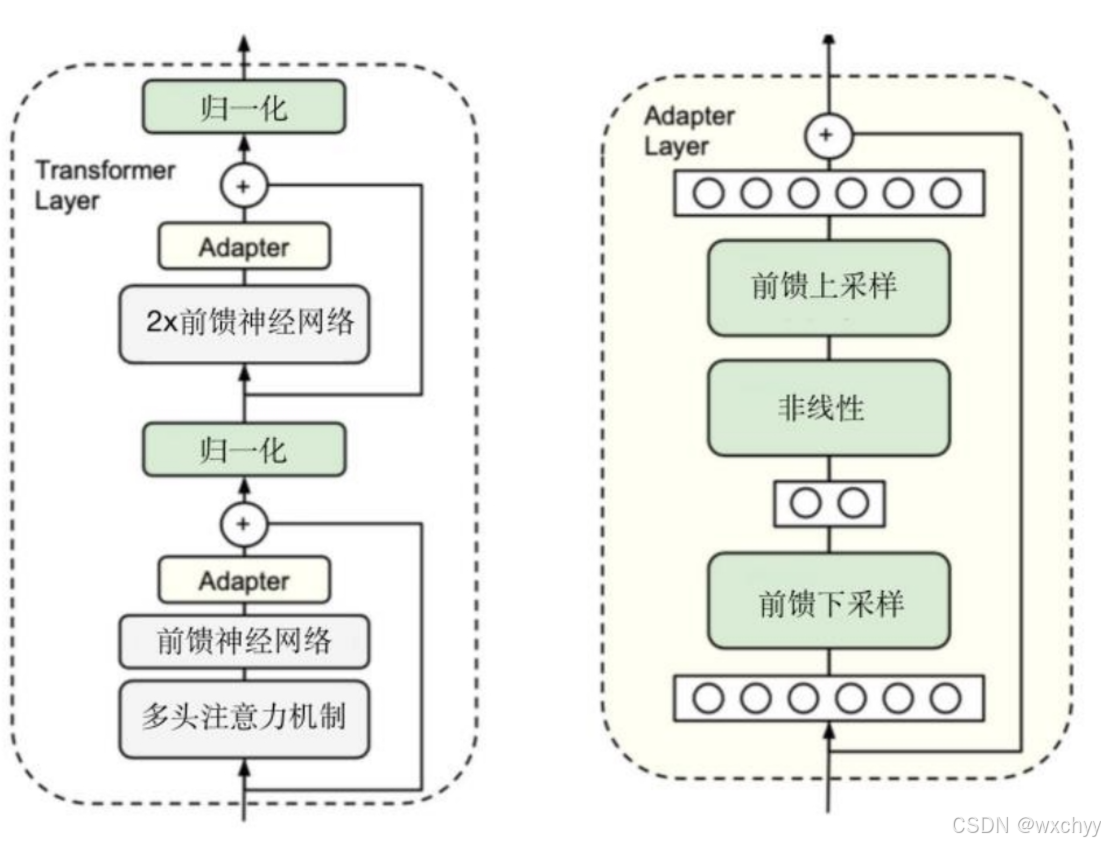
- Additive即引入额外参数,主要分为Adapters(适配器)和Soft Prompts(软提示)两个小类。适配器设计在前馈神经网络模块的内部额外增加一个辅助模块。以此实现模型的针对性增强。
- Soft Prompts包括Prompt Tuning、Prefix Tuning以及P-Turning等。Soft Prompt的特点是绕过庞大的预训练模型权重的直接调整,转而关注于优化模型的响应机制,仅通过对提示的精心设计和调整引导大模型产生期望的输出变化。
(2)Selective
Selective聚焦于有选择性地对模型现有参数集合进行细微的调整。调整依据可涉及模型层次的深度、不同类型的功能层,乃至具体参数的重要性进行选择性调参。
(3)Reparametrization-based
其中,LoRA是这一类中的一个典型代表。通过变化预训练模型的参数配置,乃至对网络架构本身进行适度改造,力求较小规模的模型或参数逼近并复制大模型的性能表现。
Prompt策略
(1)Hard Prompt (硬提示):又称为离散Prompt,Hard Prompt体现了直观且直接的干预方式,它是由研究者手动精心构造的一系列具有明确语义的文本标记。然而,这一过程也伴随着显著的局限—创造一个既高效又能精准引导模型输出的Hard Prompt,往往需要深厚的专业洞察力与大量的试错工作,是一个劳动密集且可能效果不确定的任务。
(2)Soft Prompt (软提示):Soft Prompt常被称为连续Prompt,Soft Prompt实质上是一种可学习的向量表示,即一系列在向量空间中通过算法优化得到的张量,它们与模型的输入嵌入层紧密相连,能够随训练数据集的具体需求动态调整。尽管Soft Prompt在适应性和性能上展现出显著优势,但其不足之处在于缺乏直观的人类可读性。
接下来将介绍一些软提示的具体微调方法。
Prefix Tuning
Prefix Tuning作为一种增量调整策略,通过在模型输入前附加一系列专为特定任务设计的连续向量来实现其独特性。在此机制中,仅对这些被称为“前缀”的参数进行优化,并将其融入模型每一层级的隐藏状态之中,而模型的其余部分保持不变。尽管Prefix Tuning技术大幅度减少了模型参数量(约减少至原参数量的千分之一),其模型性能仍能与全量微调模型相媲美,尤其是在数据资源有限的场景下,展现出了超越常规微调方法的卓越性能,为高效模型调优开辟了新的途径。
Prompt Tuning
之前介绍的Prefix Tuning 在实际应用中也有若干局限性。
1)其运行机制基于在原有输入Prompt之前附加前缀,这会占用模型的输入容量。
2)Prefix Tuning 的前缀长度(L)、插入位置(如编码器 / 解码器)等超参数需人工设定。这种人工预设类似于离散模板的设计过程(如模板长度、占位符位置),若超参数选择不当,可能导致模型性能下降。
在此背景下,Prompt Tuning仅在模型输入嵌入层集成提示参数,而非遍历所有模型层插入Prefix参数。这一调整极大简化了模型结构调整的复杂度,规避了MLP训练的调整,转而依赖于在输入层面精心设计的Prompt Token来驱动模型针对特定任务的响应能力。
与Prefix Tuning局限于在Transformer架构内部增添前缀模块不同,Prompt Tuning采取了一种更为高效的外部模型架构,该架构与基础预训练模型相隔离,形成一个独立的外挂系统。尤其值得注意的是,Prompt Tuning进一步提出了Prompt Ensembling策略,在单个训练批次中集成多个针对同一任务的不同形式的Prompt,这实质上模拟了多个模型的集成学习效应,却大幅降低了实际集成多个模型的高昂成本。通过这种策略,每个Batch内的多样化Prompt促进了模型对任务理解的深度与广度,增强了模型的健壮性和灵活性。
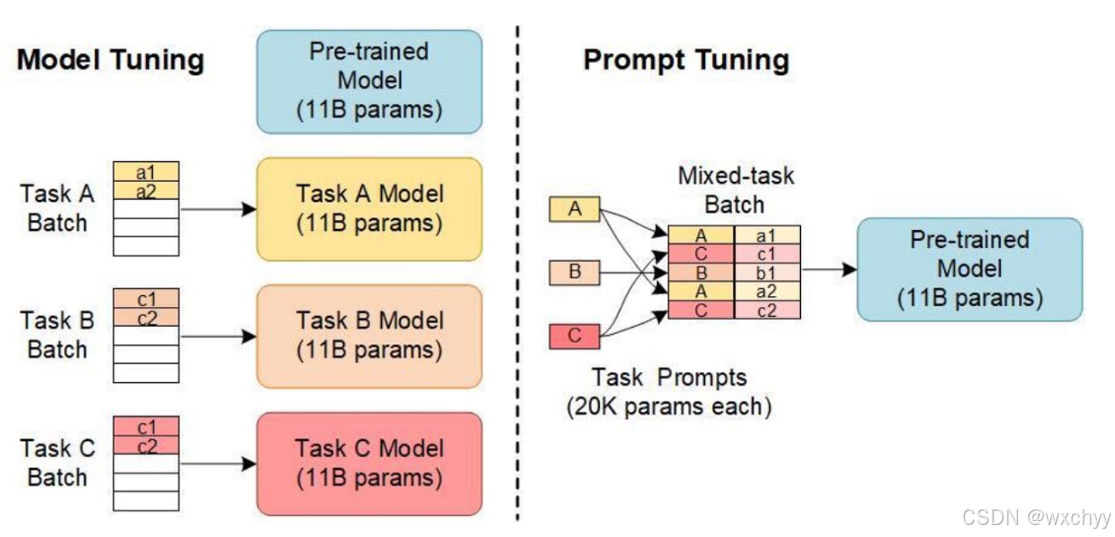
左图是传统的全量微调,每一个任务训练一个模型,右边是Prompt Tuning,可以同时处理不同任务,进而提高模型的泛化能力。
实验研究表明,尽管Prompt Tuning未必能在所有指标上全面超越Fine Tuning,但其实现的性能已十分接近,表明其能以较低的开发成本达成与高成本方法相近的成果。
P-Tuning V1
P-Tuning V1是由中国研究团队引领的调优技术,属于软提示方式的一种创新演变,旨在连续空间中自动探索并优化提示序列,以替代传统的人工设计。相对于上面讲述的Prompt tuning的Prompt是纯连续软提示和模型冻结的方案,P-Tuning则采用了一种人为设计离散模板、连续虚拟token和部分模型调优的混合方案。具体来讲:
1 P-Tuning 首先将下游任务转化为自然语言填空问题,即构造一个包含 “输入文本(X)”、“模式(Pattern)” 和 “答案(Answer)” 的三元组。
如:情感分类任务:
输入文本 X = “这部电影情节紧凑,演员演技在线”,
模式 P = “[X],这句话的情感是 [MASK]”,
答案 A = “积极”(填充到 [MASK] 位置)。
2 为了增强模式对任务的适应性,P-Tuning 在模式的关键位置,通常是输入文本 X 和 [MASK] 之间插入 k 个可训练的连续向量(虚拟 token),记为
v
1
,
v
2
,
.
.
.
,
v
k
\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_k
v1,v2,...,vk。这些虚拟 token 的初始值随机初始化,训练时通过反向传播优化。
3 与 Prompt Tuning不同,P-Tuning 不仅训练虚拟 token,还会微调预训练模型的部分底层参数。主要底层参数对输入的语义理解更敏感,微调后能更好地将虚拟 token 与原始输入的语义融合,例如Embedding 层以及前1-3层Transformer层。
4 P-Tuning 的训练目标与 MLM(Masked Language Mode)任务一致:最大化模型预测 [MASK] 位置答案的概率。
P-Tuning少样本效果接近全参数微调,通过离散模式的显式任务引导 + 虚拟 token 的动态调整,P-Tuning 在少样本下的效果显著优于纯软提示,接近全参数微调。不过P-Tuning仍需人工设计初始模板,虽然虚拟 token 能优化模式,但初始模板的结构仍需人工设计,对非结构化任务的适配性较弱。同时还需要微调部分底层参数来增加学习任务模式,这也增大了微调的参数量。
P-Tuning V2
P-Tuning V2在P-Tuning V1的基础上应运而生,旨在克服前者存在的若干局限性,并进一步拓展了该技术的应用边界。回顾P-Tuning V1,其效果显著受到模型规模(Scale)的制约,这一点与Prompt Tuning领域普遍观察到的现象相呼应。从逻辑上讲,当依托于一个强大的大模型时,丰富的预训练知识基础使得模型能更深刻地理解并利用精心设计的Prompt模板,进而在特定任务上实现卓越性能。反之,如果模型规模较小,其内在知识储备和理解能力的局限性将直接影响Prompt调优的效果,从而限制了P-Tuning V1在小模型上的表现潜力。P-Tuning V2该版本不仅融合了P-Tuning和Prefix Tuning的核心思想,更重要的是,它创新性地纳入了深度Prompt编码(Deep Prompt Encoding)和多任务学习(Multi-task Learning)等先进策略,以此为核心优化机制。通过深度Prompt编码机制深化了模型对Prompt的处理能力,还凭借多任务学习策略的集成,进一步拓宽了其在复杂任务和模型泛化方面的应用范围。
1)原始 P-Tuning 的虚拟 token 仅插入到输入层,而 P-Tuning v2 将提示扩展到模型的多个 Transformer 层,以强化模型对Prompt的响应能力。具体来说,为每一层的注意力模块添加可训练的提示向量(Key/Value 前缀),直接干预模型的中间计算过程,增强对长程依赖和复杂任务的建模能力,同时P-TuningV2不对模型的底层参数进行微调。
2)P-Tuning v2 通过统一的 “输入 + 提示” 结构替代任务特定模板,避免了人工设计模板的需求,适用于分类、生成、抽取等多种任务类型。
P-Tuning V2不论在何种模型规模下,均展现出了与传统微调(Fine-Tuning)相当的优越性能。这一成就尤为重要,因为它颠覆了以往认为调优效果与模型参数规模紧密相关的普遍认知,成功打破了模型尺寸对调优效果的限制,不论是在资源受限的小模型上,还是在计算能力强大的大模型中,都能够稳定地输出与全量微调相媲美的高质量结果。
小结
最早的Prompt Tuning,是直接在模型外部进行操作,而不修改Transformer。而Prefix Tuning只在Transformer的不同Layer层前面新增加了一些神经网络模块MLP。P-Tuning也类似,在Embedding层增加了一些新的神经网络参数。P-TuningV2则还会有更深层次的前缀增加。
Reparametrization-based (引入重参数化)
Reparametrization-based(引入重参数化)是一类在机器学习和深度学习中广泛应用的优化技术,主要用于解决随机梯度估计和模型训练中的问题。这类方法的核心思想是通过对随机变量进行数学变换,将原本难以直接优化的随机过程转化为可微分的确定性过程,从而简化梯度计算并提高训练效率。在微调中,我们将其分为LoRA、AdaLoRA以及QLoRA,下面分别进行介绍。
LoRA
低秩适配(LoRA)方法,通过设计特定结构,在涉及矩阵乘法的模块中引入两个低秩矩阵A和B,以模拟全量微调过程,从而只对语言模型中起关键作用的低秩本质维度进行更新。尽管大模型参数规模巨大,但其中的关键作用通常是由低秩本质维度发挥的。
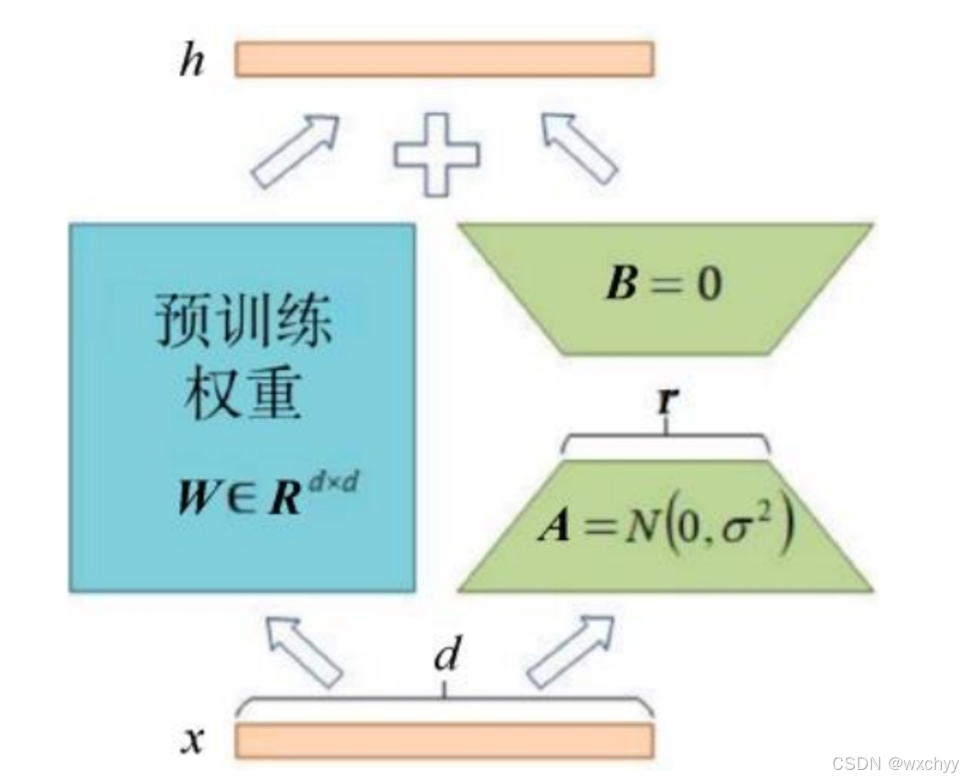
LoRA的思路是,我先不管左边这条网络路,只管右边这个我们需要新训练的外挂网络通路小模型,其名称为更新矩阵(Update Matrix)。矩阵A和B的初始化方式也不一样,其中B是零矩阵,A是正态分布矩阵(随机初始化,均值为0,方差为σ2),二者的维度分别为d×r和r×d。外挂通路的核心就是小矩阵模拟大矩阵。公式如下:
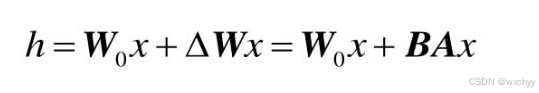
LoRA的核心思想是把公式中的ΔW改为BAx,将大矩阵从一个d×d维的高维空间变成了相对较小的AB。LoRA直接作用于域模型结构。把大模型变成小模型并不意味着大模型完全被替换了,LoRA只是在矩阵层面的替换,只能替换特定层,LoRA微调要做的就是用矩阵BA的乘积把矩阵W替换掉。
接下来介绍一下PEFT库里LoRA微调的一些参数:
- r(int): LoRA低秩矩阵的维数,影响LoRA矩阵的大小。
- lora_alpha(int): LoRA缩放的alpha参数,LoRA适应的比例因子。
- target_modules(Optional[List[str],str]):适配模块,指定LoRA应用到的模型模块,通常是attention和全连接层的投影。如果指定了此项,则仅替换具有指定名称的模块。传递字符串时,将执行正则表达式匹配。传递字符串列表时,将执行完全匹配,或者检查模块名称是否以任何传递的字符串结尾。如果指定为“all-linear”,则选择所有线性/Conv1D模块,不包括输出层。如果未指定,则根据模型架构选择模块。如果体系结构未知,则引发错误—在这种情况下,应该手动指定目标模块。
- lora_dropout(int):在LoRA模型中使用的dropout率。
- bias(str): LoRA的偏移类型。可以是“none”“all”或“lora_only”。如果是“all”或“lora_only”,则在训练期间更新相应的偏差。注意,这意味着,即使禁用适配器,模型也不会产生与没有自适应的基本模型相同的输出。
- modules_to_save(List[str]):除了适配器层,还要设置为可训练并保存在最终检查点中的模块列表。
注意:实验结果表明,权重矩阵的种类和rank值r的选择对训练结果具有很大的影响。
AdaLoRA
1)在LoRA中,超参数中增量矩阵的r是无法自适应调整的,它是我们在一开始训练LoRA时就需要设置的值。
2)权重矩阵的种类和不同层的权重矩阵的选择对结果影响非常大。
3)只微调了大模型中的部分模块,如Q、K、V,以及最终的输出,而并没有微调前馈网络(FFN)模块。Transformer架构中最重要的就是一个Attention接了一个FFN, LoRA只训练了Attention而忽视了FFN,事实上,FFN更重要。
ADAPTIVE BUDGET ALLOCATION FOR PARAMETER-EFFICIENTFINE-TUNING论文提出了一个针对性的解决方案,以解决原来的LoRA论文中未解决的问题。也就是AdaLoRA。
1)第一,AdaLoRA 提出了 “预算”(Budget) 的概念,将总参数预算(如总秩
(
R
total
(R_{\text{total}}
(Rtotal)动态分配给不同的权重矩阵,而非为所有矩阵设置相同的 r。
2)第二、AdaLoRA 通过敏感度评估自动确定需要训练的权重矩阵,而非人工选择。
3)第三、AdaLoRA 将 FFN 纳入低秩分解,动态分配预算。
1)第一,既然降维中用B×A替代矩阵,那么如何做降维替代更好呢?本质上就是更好地找出一个B×A。对此有很多经典的方案,如机器学习时代有一个SVD(Singular Value Decomposition,奇异值分解)方法。事实上,AdaLoRA的核心其实就是把SVD用到了极致,用SVD提升矩阵低秩分解的性能。
2)第二、对模型进行剪枝。在整个大模型中并非每个参数都是有用的,其实我们只需要那些最有用的参数,而那些不相关的参数可以不用。那么,如何找出那些最有用的参数呢?这其实是对大模型进行建模,把模型参数的每个单独的参数都当成我们要去建模的对象,每个参数都有自己的重要性,我们需要对这个重要性进行评分,这就是在AdaLoRA中做的另一件很重要的事。
3)第三,既然r不能自适应地调整,也不能靠我们决定哪个r能够在特定训练集上表现更好,那就让它动态、自适应地调整r。AdaLoRA的核心理念和技术手段就是用SVD的三元组去替代原来LoRA的BA二元组。LoRA在指定rank值之后,它的BA矩阵的维度就不会发生变化;而AdaLoRA在迭代过程中,一直在做奇异值分解,调整奇异值数量和对角矩阵的维度。
QLoRA
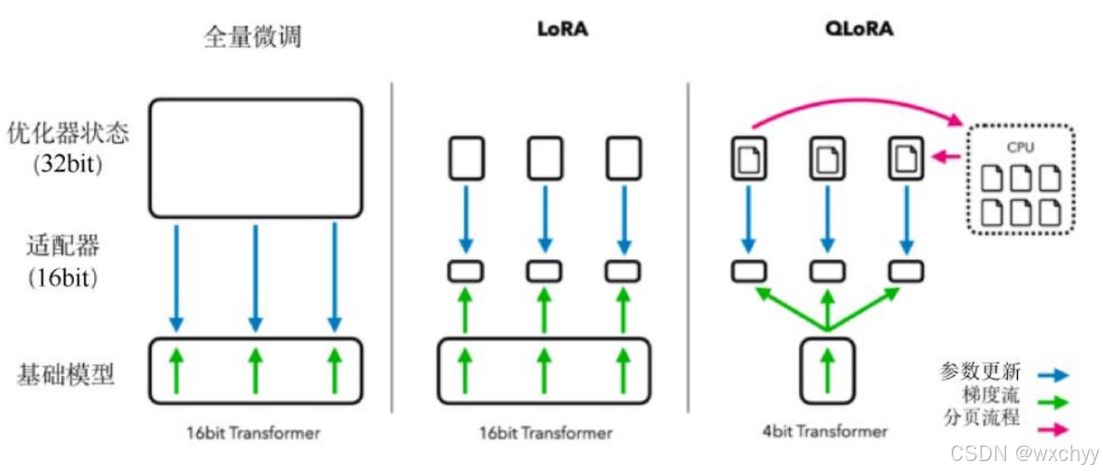
美国华盛顿大学的一篇论文QLoRA: Efficient Finetuning of Quantized LLMs提出了一个新的训练微调的方法,即QLoRA,就是去训练量化的大模型。QLoRA通过三个技术的叠加,即4bit即NF4 Normal Four Bit这个新的数据类型加上双量化的量化策略,再加上内存和显存管理的Page Optimizers,使它训练出来的大模型比16bit微调的大模型还要好。
1 NF4
NF4是信息理论上最优的量化数据类型,适用于正态分布的数据。我们的机器学习、深度学习、大模型和我们需要存储的模型参数是有特点的,模型参数本身不是随机的,且它们的数值会聚集在一块区域中。香农在信息论中提出的最优数据类型其实是指,假设你知道通过经验的积累和历史数据的拟合,知道了数据的分布情况,知道了要存在计算机中的数大概是什么样子的分布函数,你就可以进行输入张量的分位数量化。
2 双量化技术
双量化技术引入了双重量化(Double Quantization, DQ)的概念,这是一种对量化常数进行二次量化的过程,目的是进一步节省内存容量。具体来说,双重量化将第一次量化的量化常数作为第二次量化的输入。这种技术其实就是嵌套的量化。论文中的研究者使用256块大小的8bit浮点数进行第二次量化,根据Dettmers和Zettlemoyer的研究,8bit量化没有性能下降。数据虽然被NF4保存下来了,但真正计算时肯定不能那样保存,因为除它外,对其他数据还是用16bit计算。因此,QLoRA设计了存储数据类型NF4和计算数据类型BF16,并且采用了存算分离技术,这也是QLoRA的核心价值。计算机在计算时,用Float16表达的浮点数可以直接进行加减乘除矩阵运算;而NF4不能,因为它是极致地压缩了存储空间,把计算和存储分离,只有在算时才解压缩。因为QLoRA不是对每个阶段的每个参数都运算的,而是只运算部分参数,在运算的时候再回到BF16进行运算,运算完再编码保存下来。
3 分页优化器
分页优化器(Page Optimizer)的作用是防止系统崩溃。在运行过程中,在某一层可能因为中间数据量比较庞大,短时间的内存峰值导致暂时的OOM(Out Of Memory,内存不足)。分页优化器在GPU运行偶尔出现OOM时,可以通过英伟达统一内存的功能,在CPU和GPU之间自动进行页面到页面的传输,和虚拟内存技术差不多。
这就是QLoRA通过三个技术的叠加,将65B参数模型的内存需求从>780GB降低到<48GB,并保持了16bit微调任务的性能。对于个人开发者来说,如果想实现具有100亿个参数的模型,则可采用这种由可靠的技术支撑、廉价、合理的方案,否则需要买很多显卡才能使用大模型。
写在文末
有疑问的友友,欢迎在评论区交流,笔者看到会及时回复。
请大家一定一定要关注!!!
请大家一定一定要关注!!!
请大家一定一定要关注!!!
友友们,你们的支持是我持续更新的动力~
随便记记
1 Pytorch安装的版本要大于当前计算机的CUDA最高版本
2 PEFT库LoRa微调和量化使用的BitsAndBytes库
3 模型文件后缀是.safetensors
4 基于Gradio库的Web端对话应用
5 OpenAI风格的API调用方法
6 模型量化部署,默认是FP16(半精度浮点数),量化包括 FP16 INT8 INT4 NF4
7 transformer库包含三大自动化类别(Auto Classes)AutoConfig、AutoModel及AutoTokenizer
8 如果自定义配置与预训练模型不一致,需要手动配置忽略不匹配的权重。
9 input_ids 本质是词表(Vocabulary)的下标(整数索引)
10 Encoder Decoder Sequence-to-Sequence
11 LN层归一化,LN作用于某一层的输出之后,操作对象是单个样本,求均值和方差,同时引入了科学习参数。
12 Post-Processing,softmax之后,将id转化为label
13 模型的保存,使用model.save_pretrained(),config和.bin
14 Datasets库 和Accelerate库,混合精度训练通过结合单精度和半精度浮点运算,减少了内存占用并加速了计算过程,是当前提升训练效率的关键策略之一。
15 GLUE通用语言理解评估
16 数据集预处理 dataset.map(tokenize_function,batched = True)
17 DataCollator高级数据预处理组件,其核心功能在于将原始的训练数据集精心编排为结构化的批次数据(Batched Data)
18 TrainingArguments,集中且高效的参数管理,Trainer组件大幅度简化神经网络模型的微调与训练流程
19 load_metric 模型评估
20 准确率是正确预测的样本数占总样本的数量。精确率是仅关注预测为正例的部分,衡量这部分的正确性。召回率关注正例的部分,衡量预测正确的正例占总正例的比例。
21 QLoRA、LoRA、P-Tuning、PrefixTuning及P-Tuning V2
22 PEFT库引入了PeftModel与PeftConfig两大核心组件,
23 save_pretrained将保存增量PEFT权重,分为两个文件:adapter_config.json配置文件和adapter_model.bin权重文件。
24 model(input):前向传播,获取原始输出 model.generate():序列生成,获取最终结果
25 量化用更少的bit表示数据,这使它成为一种减少内存使用和加速推理的有用技术
26 BitsAndBytes库,对CUDA自定义函数的轻量级封装
27 LangChain应用框架
28 LLM和ChatLLM:LLM 是通用语言模型,适合单轮文本生成、总结等任务,需手动管理上下文;
ChatLLM 是对话优化的 LLM,通过 RLHF 训练,擅长多轮交互、角色感知和上下文跟踪,更适合聊天机器人、客服系统等对话场景。
29 NF4 跟 INT4 ,在 LLaMA、Mistral 等大模型上的实验表明,NF4 相比 INT4 显著降低了量化后的性能损失。
30 FP16和BF16,BF16 已逐渐成为主流选择;而 FP16 仍在推理和小模型场景中广泛应用。
31 VIT模型,将Transformer架构用于图像上
32 pass@k一种评估代码生成的方法
33 PPO算法的核心思想是,在进行策略(可以理解为模型)更新时,通过限制新策略和旧策略之间的差异来让更新更稳定。
34 稀疏专家模型 稀疏模型的特点是不会激活所有参数来处理给定的输入,而只会激活与输入相关的参数子集。人工智能不需要访问所有知识来完成任务,这是显而易见的。这是大脑的工作方式,也是人工智能应该模仿的方式
35 no-slot-prompt ,few-slot-prompt 即在提示中加入输入/输出示例、Few-Shot CoT、零样本思维链(Zero-Shot CoT)
36 GPT、InstructGPT、ChatGPT
37 只有当模型的规模至少达到620亿个参数时,AI模型才可能训练出思维链的能力。
38 模型参数训练估算,一是模型状态,包括优化器状态(例如Adam优化器的动量和方差)、模型参数和模型参数的梯度。其次,剩余的空间主要被模型训练中间激活值、临时缓冲区和不可用的内存碎片占用,它们统称为剩余状态。 以GPT2-3.5B-Chinese举例,模型参数,前向传播的激活值和梯度,优化器的动量和方差。以FP16举例,模型参数7GB,激活值和梯度 14GB 优化器的动量和方差FP32 28GB 7 + 14 +28 = 49GB
39 PyTorch分布式训练的包 torch.distributed
40 数据并行:它将模型复制到多个GPU上,并将数据集切分成多个片段,每个片段分配给一个设备。
41 模型并行:模型并行将模型分割并分布在一个设备阵列上,切分的方式分为两种:一种是水平切分,即张量并行;另一种是垂直切分,即流水线并行。张量并行是在一个操作中进行并行计算,如矩阵的分块乘法运算。流水线并行是在各层之间进行并行计算,某一层之内的计算操作不会被拆开。
42 混合并行:结合数据并行、模型并行和流水线并行的3D并行训练
43 ZERO一种去除冗余的数据并行方案,核心思想:分片存储,按需聚合,ZERO-1:优化器状态分片,ZERO-2:优化器状态 + 梯度分片,ZERO-3:参数 + 梯度 + 优化器状态分片。
44 RMSNorm归一化
45 SwiGLU激活函数
46 RoPE位置嵌入
47 分组查询注意力(GQA)机制



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











