



机器学习概述
人工智能三大概念
人工智能AI概念
-
仿智,像人一样机器智能的综合与分析;机器模拟代替人类
-
AI系统效果
-
像人那样思考 像人那样理性思考
-
像人那样思考 像人那样理性思考
-
三者之间关系
-
机器学习是实现人工智能的一种途径
-
深度学习是机器学习的一种方法发展而来的
-
目前的人工智能技术体系(软件开发角度):
- 基于统计学的传统机器学习方法
- 基于神经网络的深度学习方法
机器学习ML
-
让机器自动学习,而不是基于规则的编程
-
机器学习识别车: 从数据中获取规律;来了一个新的数据,产生一个新的预测
深度学习DL
-
大脑仿生,设计一层一层的神经元模拟万事万物
-
浅层神经网络、深层神经网络、神经网络框架、大型预训练模型
机器学习和深度学习拓展
-
在机器学习中,程序员手工提取事物特征做数据,传递给机器学习模型做分类
-
在深度学习中,不需要要程序员手工事物提取事物特征,直接交给模型去做特征抽取和模型分类
机器学习开发常用术语
样本和数据集
-
样本(sample) :一行数据就是一个样本
-
数据集 :多行样本构成数据集
特征
-
一列数据一个特征,有时也被称为属性
-
对目标值有用的属性,叫特征
标签
-
标签/目标(label/target) :模型要预测的那一列数据。
-
注意:有些任务是需要标签,有些任务不需要标签
数据集划分
-
训练集用来训练模型、测试集用来测试评估模型
-
一般划分比例7:3 ~ 8:2
机器学习建模流程
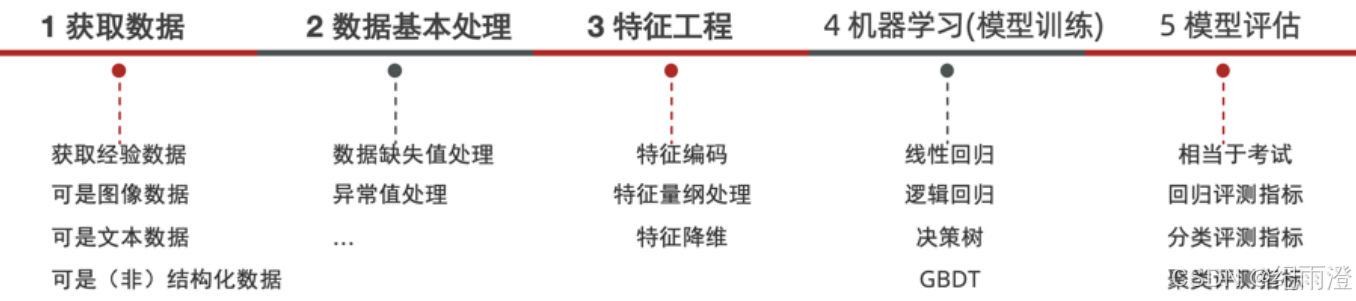
监督学习下,模型训练需要给模型提供特征值和标签;也就是需要提供标准答案。这样模型才知道从数据中学习什么,有了一个学习的标准。
机器学习helloworld编程
回归API
from sklearn.linear_model import LinearRegression
import joblib
def dm02_线性回归api_保存和加载():
# 1 准备数据 平时成绩 期末成绩 最终成绩
x = [[80, 86], [82, 80], [85, 78], [90, 90], [86, 82], [82, 90], [78, 80], [92, 94]]
y = [84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]
# 2 实例化 线性回归模型
estimator = LinearRegression()
# 3 模型训练
estimator.fit(x, y)
# 4 打印 线性回归模型参数 coef_ intercept_
print(estimator.coef_)
print(estimator.intercept_)
# 5 模型预测
y_pred = estimator.predict([[90, 80]])
print(y_pred)
# 模型保存
joblib.dump(estimator, "data/mymodel1.bin")
# 模型加载
estimator2 = joblib.load("data/mymodel1.bin")
y_pred2 = estimator2.predict([[80, 70]])
print(y_pred2)
分类API
from sklearn.neighbors import KNeighborsClassifier
def dm02_分类任务():
# 2 准备数据
# 0-喜剧片 1-动作片 2-爱情片
x = [[39, 0, 31], # 0
[3, 2, 65], # 1
[2, 3, 55], # 2
[9, 38, 2], # 2
[8, 34, 17], # 2
[5, 2, 57], # 1
[21, 17, 5], # 0
[45, 2, 9]] # 0
y = [0, 1, 2, 2, 2, 1, 0, 0]
# 3 实例化
estimator = KNeighborsClassifier(n_neighbors=3)
# 4 模型训练 .fit()
estimator.fit(x, y)
# 5 模型预测 .predict() 搞笑镜头23 拥抱镜头3 打动镜头17
y_pred = estimator.predict([[23, 3, 17]])
print(y_pred)
聚类API
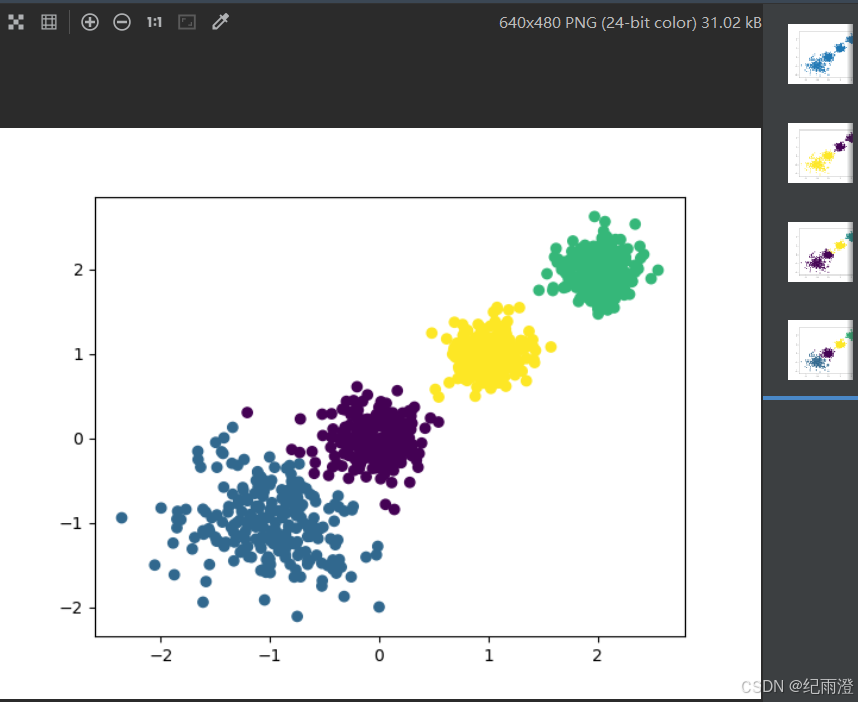
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score
def dm03_无监督聚类问题():
# 2 创建数据集 1000个样本,每个样本2个特征 4个质心蔟数据标准差[0.4, 0.2, 0.2, 0.2]
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
plt.figure()
plt.scatter(x[:, 0], x[:, 1], marker='o')
plt.show()
# 3 使用k-means进行聚类, 并使用CH方法评估
# 3-1 n_clusters=2
y_pred = KMeans(n_clusters=2).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
print('2-->', calinski_harabasz_score(x, y_pred))
# 3-2 n_clusters=3
y_pred = KMeans(n_clusters=3).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
print('3-->', calinski_harabasz_score(x, y_pred))
# 3-3 n_clusters=4
y_pred = KMeans(n_clusters=4).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
print('4-->', calinski_harabasz_score(x, y_pred))
-
分类回归聚类求解
-
每一类问题都会有不同的算法来求解
-
算法没有好坏:要根据应用场景(数据要求、性能要求等)来选择不同的算法
-
每一类算法都有不同的评估指标来评测模型的效果如何。
-
特征工程
特征Feature
- 对模型训练有用的属性信息
特征工程
- 专业背景知识和技巧处理数据,让模型效果更好
特征处理作为一项工程来做,是非常重要的
特征提取 feature extraction
- 从无到有的产生行列数据 产生向量数据
特征预处理 feature preprocessing
- 不同特征对模型影响一致性
对输入的数据提前预处理 量化一致 标准化、归一化等
特征降维 Feature decomposition
- 保证数据的主要信息要保留下来
会改变原来数据的值,不需要了解数据本身是什么含义
特征选择 feature selection
- 从特征中选择出一些重要特征训练模型
不会改变原来数据的值,数据本身意义不变
特征组合 feature crosses:
- 把具有相关性的特征合并组合成一个特征
模型效果-过拟合和欠拟合
为什么引入此概念?
- 为了描述模型在测试集上的泛化能力(在测试集上的表现效果)
拟合概念
- 用来表示模型对样本分布点的模拟情况
欠拟合概念
- 模型在训练集上表现很差、在测试集表现也很差
过拟合概念
- 模型在训练集上表现很好、在测试集表现很差
欠拟合产生的原因
- 模型过于简单
过拟合产生的原因
- 模型太过于复杂、数据不纯、训练数据太少等造成
泛化 Generalization :
-
具体的、个别的扩大为一般的能力
-
希望得到泛化能力好的模型

















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









