







目录
1 计算机视觉
受益于深度学习,计算机视觉是飞速发展的领域之一。深度学习的计算机视觉能帮助自动驾驶汽车,判断它周围的其他汽车和行人的位置来躲避他们;面部识别也比从前任何时候都要好。
这里列出几个计算机视觉问题的例子:
(1)图像分类:输入一个图像,然后试着判断它是不是猫;
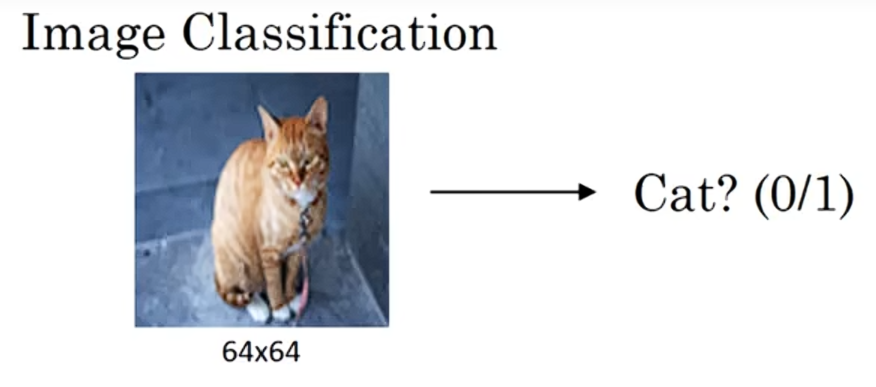
(2)目标检测:如果你正在制造一辆自动驾驶汽车,也许你不仅需要知道图像中还有没有其他汽车,而且还需要确定这些其他汽车在图像中的位置,以便你的汽车避开它们。在目标检测项目中,我们不仅要找出图片中的其他物体,而且要圈出他们。

(3)神经风格转换:你有一张内容图像和一张风格图像,用神经网络把它们放在一起,用右边的风格图像去重绘左边的内容图像。

计算机视觉问题的一个挑战是:数据的输入可能会非常大。对于尺寸为64*64的图片,实际上,它的数据量是64*64*3(因为每张图片都有三个颜色的通道),也就是数据量为12288,所以输入特征向量x的维度是12288。
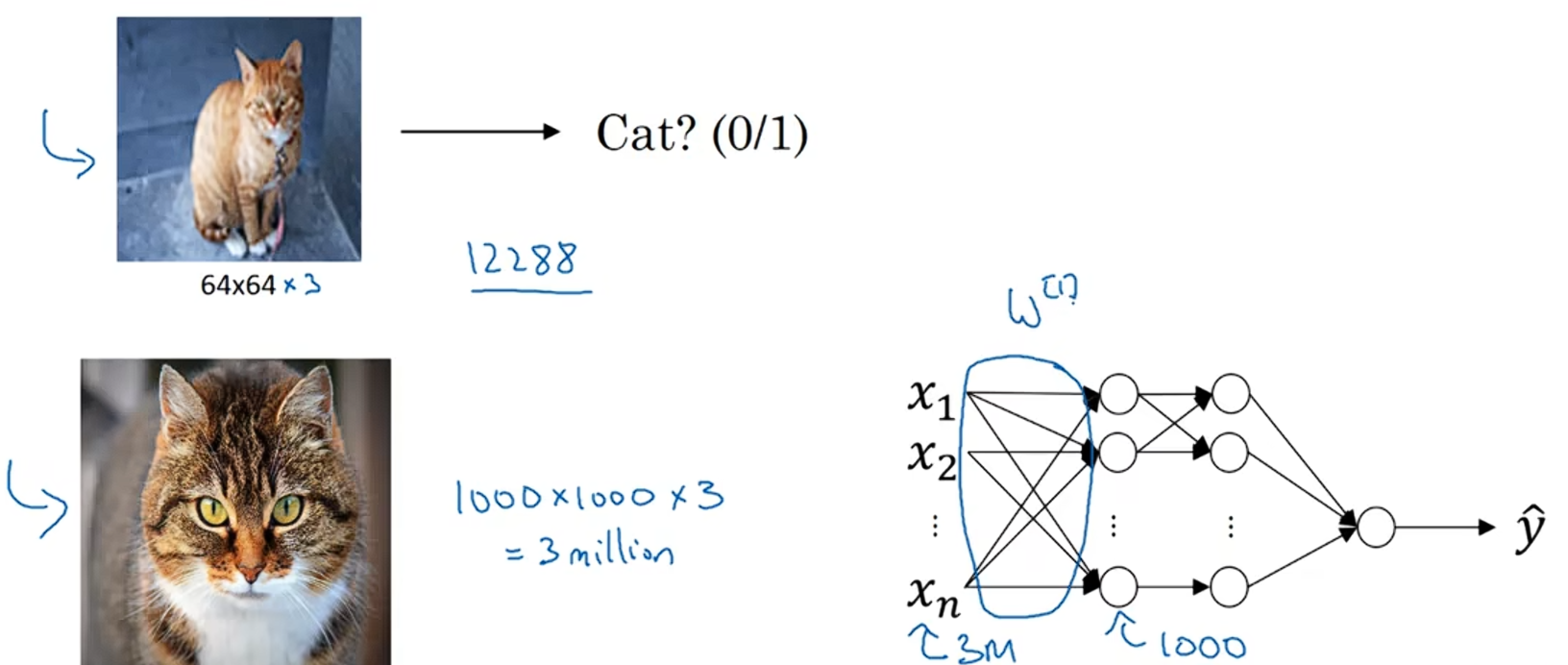
但如果对于尺寸是1000*1000的图片来说,数据量就是三百万输入特征x就是三百万维,如果第一个隐藏层只有1000个神经单元,而所有的权值组成矩阵,如果你使用标准的全连接网络,这个矩阵
的维度是(1000,3百万),意味着矩阵
有30亿个参数,在这么多参数的情况下,很难获取足够的数据来防止神经网络来发生过拟合;同时训练一个有这么多参数的神经网络,需要很大的计算量和内存需求。
2 边缘检测示例
卷积运算是卷积神经网络的基础组成单元之一,在这里我们使用边缘检测作为入门样例,你会看到卷积是怎么进行运算的?
给出一张这样的图片让电脑算出在这张图片中的物体是什么?你做的第一件事可能是检测图片中的垂直边缘,比如说在这张图片中的栏杆就对应垂直线,与此同时,这些行人的轮廓线,某种程度上也是垂线,所以在这个垂直边缘检测结果中,他们被检测出来了;也许想要检测水平边缘,栏杆扶手就是很明显的水平线,它们被检测出来了。
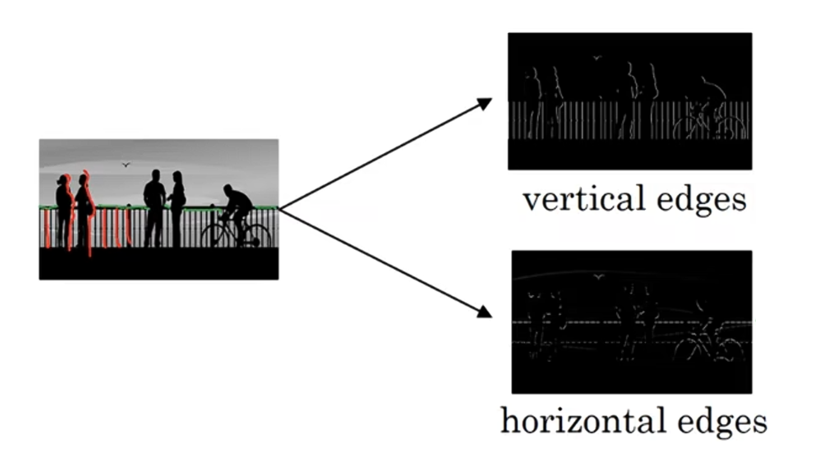
所以怎样才能在像这样的图像中检测边缘呢?我们来看一个例子。
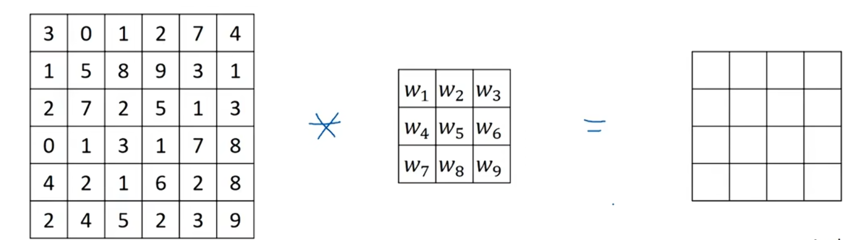
这是一个6x6的灰度图像,是6x6x1的矩阵,为了检测边缘图像中的垂直边缘,你可以构造一个3×3的矩阵,在池化过程中,用卷积神经网络中的专业术语来说,这会被称为过滤器。在论文中,它有时候会被称为核而不是过滤器。
用3×3的过滤器对6×6的图像进行卷积运算,卷积运算的输出是一个4×4的矩阵。
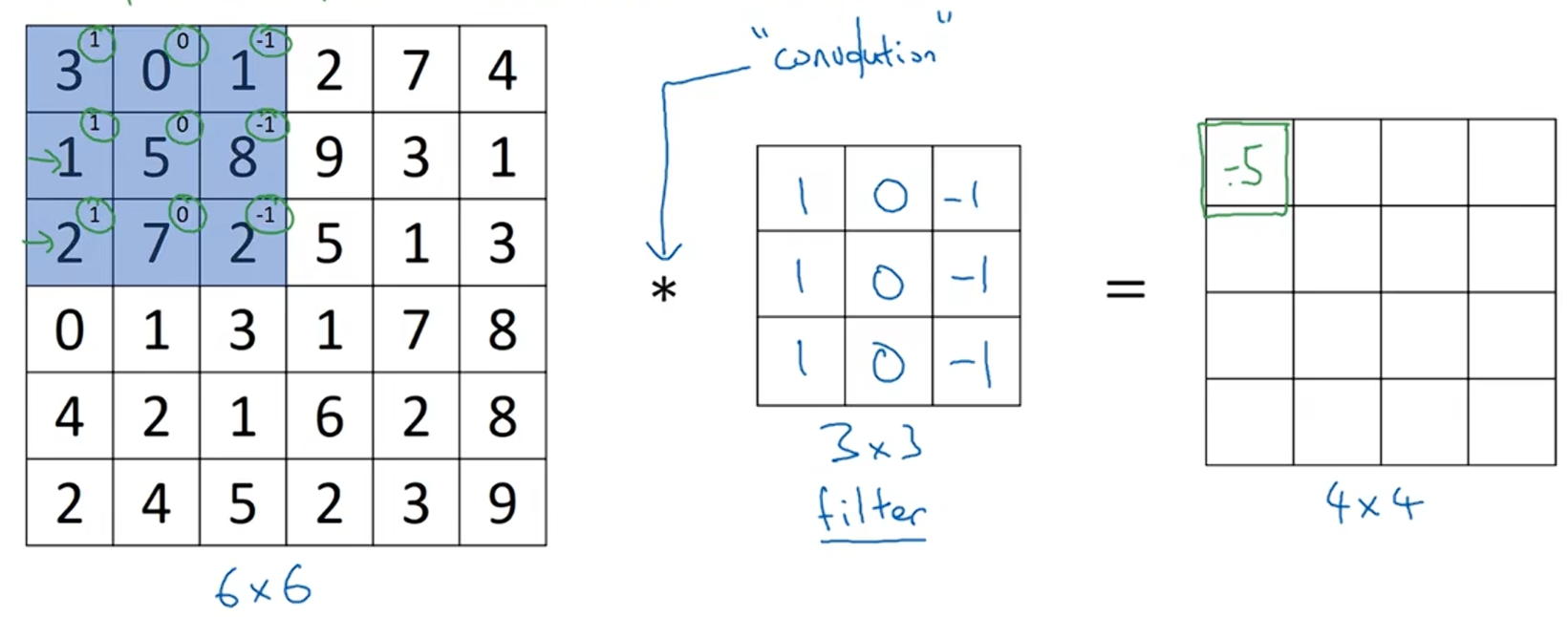
6x6图像中的蓝色区域矩阵与过滤器进行按元素相成后相加得到一个值,即:3*1+0*0+1*(-1)+1*1+5*0+8*(-1)+2*1+7*0+2*(-1)=-5
6x6图像中的蓝色区域矩阵往右移一格,与过滤器进行按元素相成后相加得到一个值,即:0*1+1*0+2*(-1)+5*1+8*0+9*(-1)+7*1+2*0+5*(-1)=-4
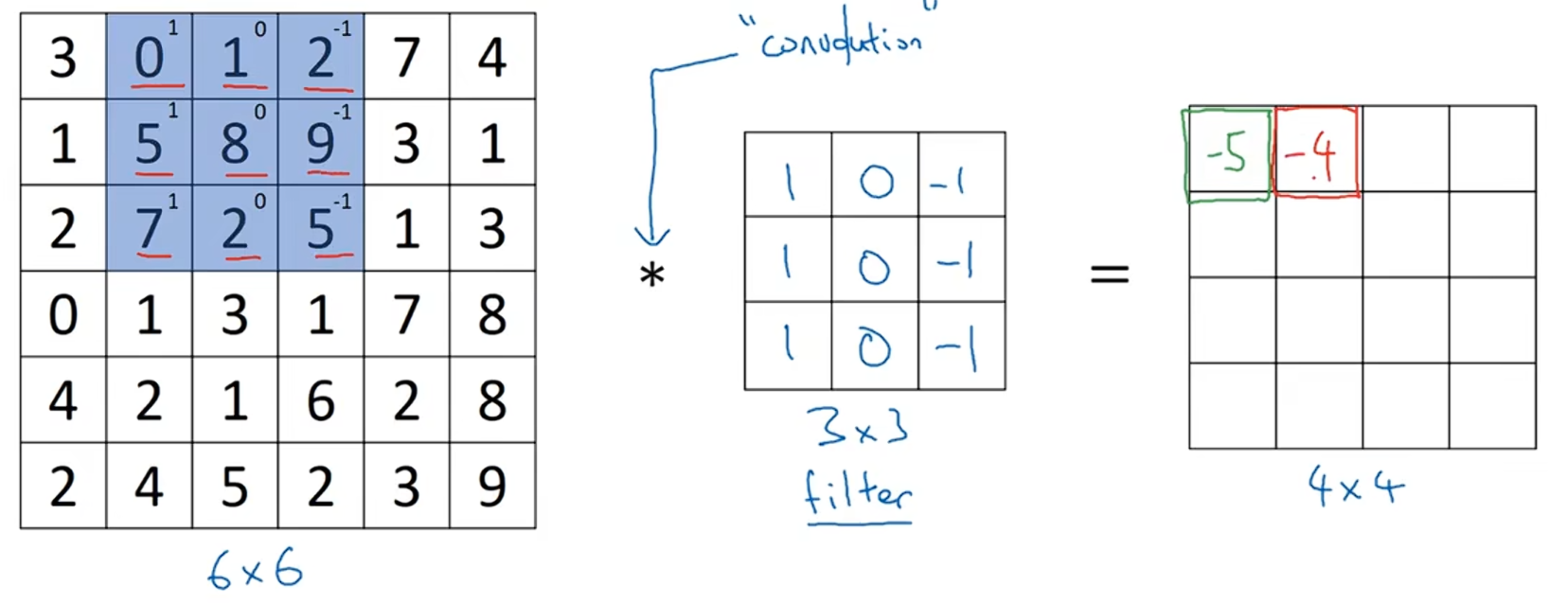
计算完第一行后,6x6图像中的蓝色区域矩阵在第二行位置开始计算,即:1*1+5*0+8*(-1)+2*1+7*0+2*(-1)+0*1+1*0+3*(-1)=-10
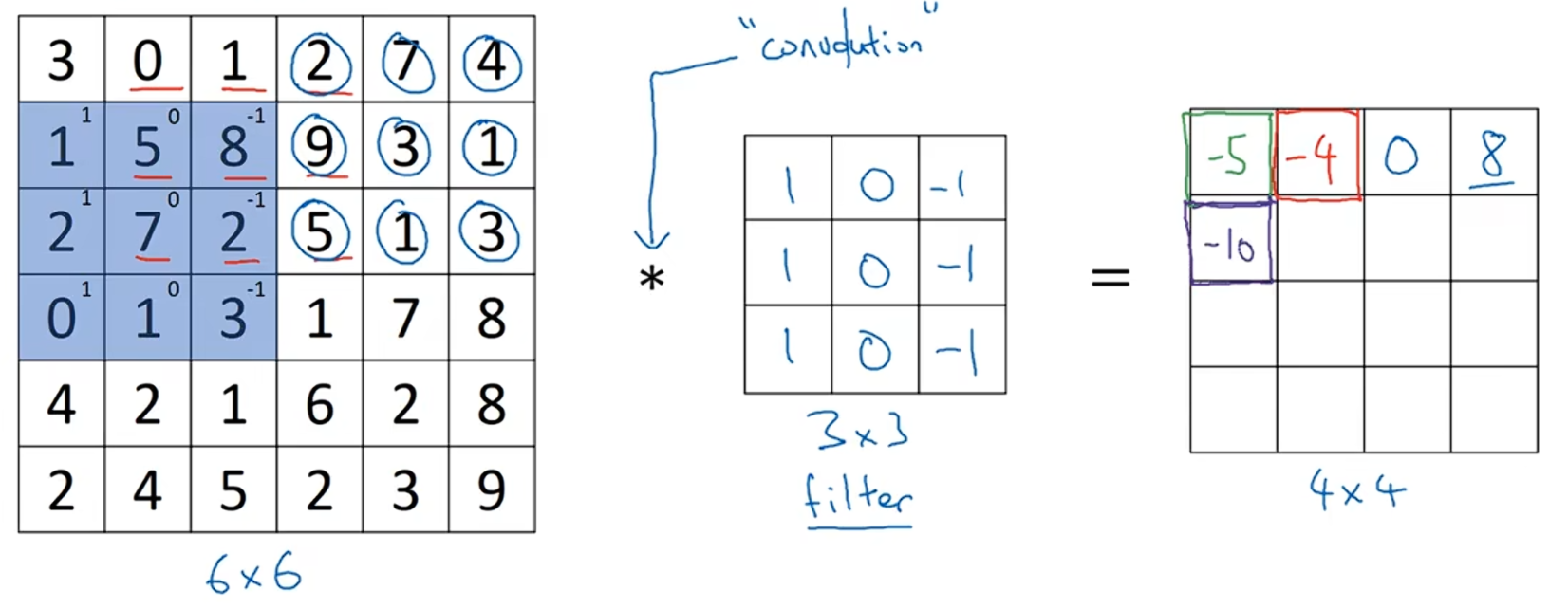
按照这样的方法计算出所有的值,得到一个4x4的矩阵。
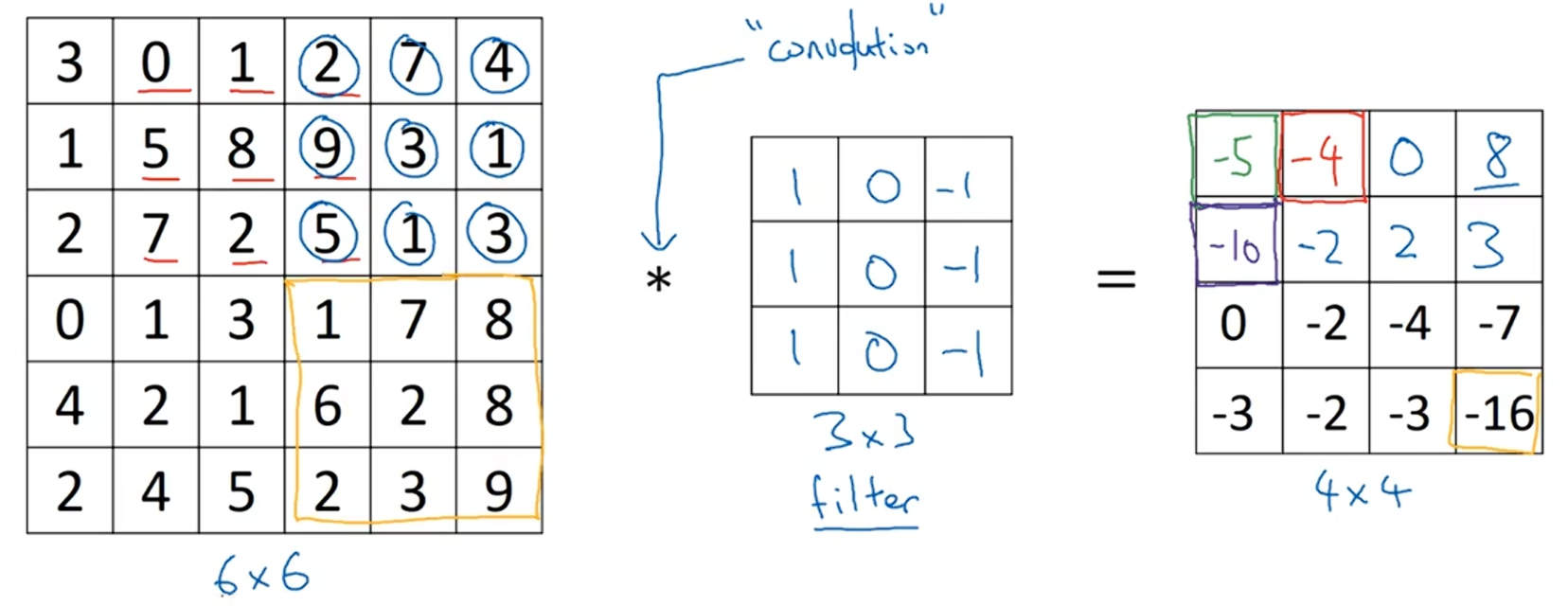
这些图片和过滤器是不同维度的矩阵,左边的矩阵可以理解成一张图片,中间矩阵理解为过滤器,右边的矩阵可以理解为另一张图片。这个就是垂直边缘检测器。
为什么这个可以做垂直边缘检测呢?我们来看一个例子。
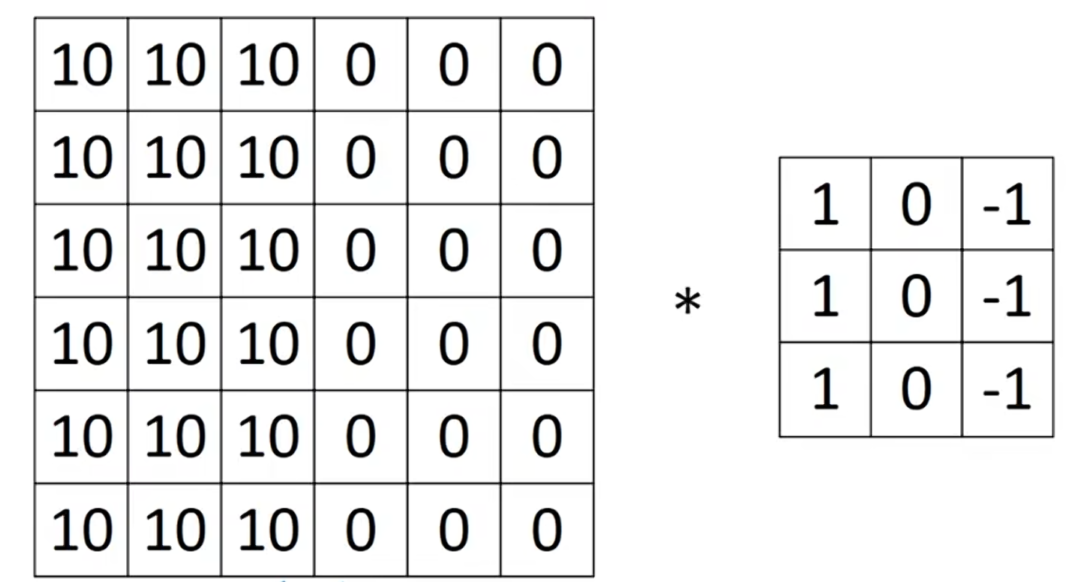
这有一个简单的6×6图像,图像的左半边是10,右半边是0,如果你以图片的形式绘制它,它是这样子的:![]() 。左半边的10,得到更亮的像素强度值;右半边的0,得到比较暗的像素强度值,但是在这个图像的正中间有一个明显的垂直边缘,当你用这个3×3的过滤器做卷积运算,这个3×3的过滤器可以被可视化成
。左半边的10,得到更亮的像素强度值;右半边的0,得到比较暗的像素强度值,但是在这个图像的正中间有一个明显的垂直边缘,当你用这个3×3的过滤器做卷积运算,这个3×3的过滤器可以被可视化成![]() ,更亮的像素点在左边,过渡段0在中间,更暗的在右边,经过卷积运算,得到4×4的矩阵,如果把最右边的矩阵当成图像,它是这样的
,更亮的像素点在左边,过渡段0在中间,更暗的在右边,经过卷积运算,得到4×4的矩阵,如果把最右边的矩阵当成图像,它是这样的![]() ,中间有段亮区域,对应6x6矩阵中间的垂直边缘。
,中间有段亮区域,对应6x6矩阵中间的垂直边缘。
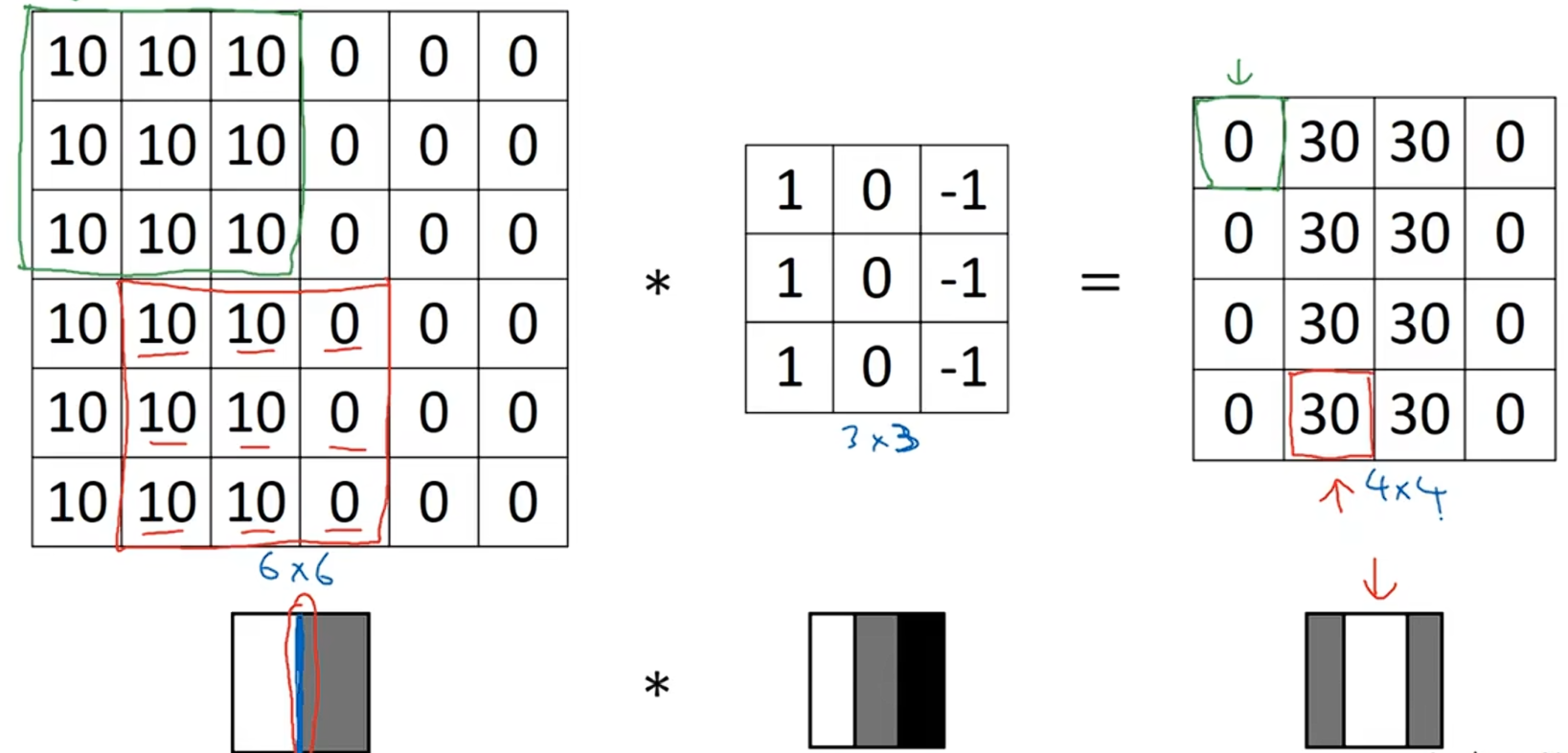
这里的维数似乎不太对,检测到的边缘太粗了。因为这个例子中,图片太小了,如果你用一个1000x1000的图像,而不是6x6的图像,你就会发现能够很好的检测出图形的垂直边缘。
从垂直边缘检测的例子中,可以得到的启发是:因为我们使用3x3的矩阵,所以垂直边缘是一个3x3的区域,左边是明亮的像素,中间的不考虑,右边是深色像素;亮像素在6x6图像的左边,暗像素在右边,中间就被视为了一个垂直边缘。
卷积运算提供了一个方便的方法,来发现图像中的垂直边缘。
3 更多边缘检测
我已经了解了如何用卷积运算实现垂直边缘检测。接下来,我们将学习正边缘和负边缘的差别,也就是由亮变暗与由暗变亮的边缘过渡;还将看到其他几种边缘检测器,以及如何让算法学习(边缘检测器)而不是手动设定边缘检测器。
在上面的例子中,我们已经知道了:这张6x6的图像,左边较亮,右边较暗,将它与垂直边缘检测器进行卷积,结果就是右边图的中间部分。
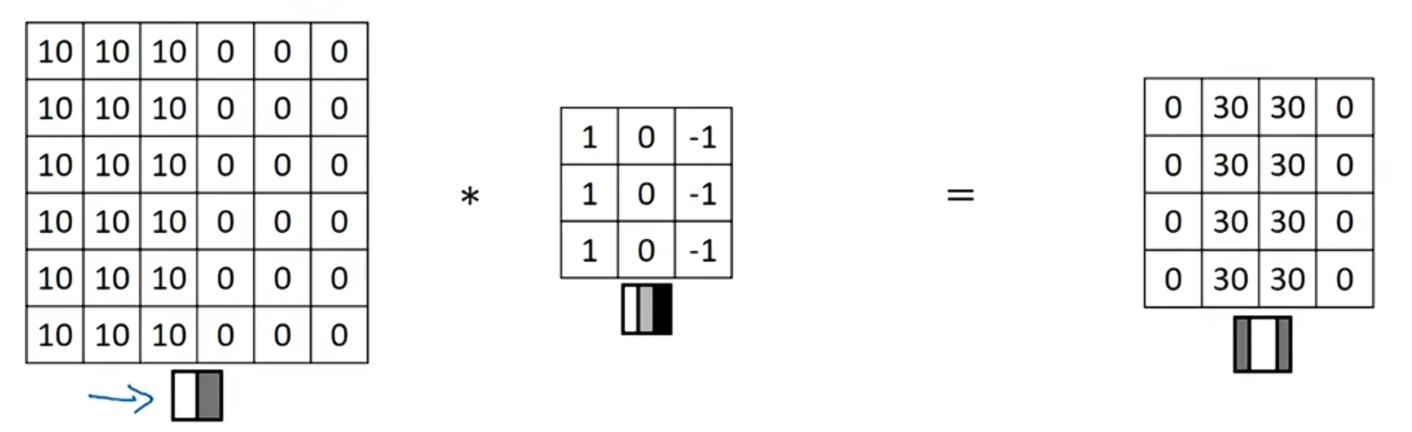
现在, 6x6的图像的左边是0,右边是10,即左边是暗部,右边是亮部,如果用它和形同的垂直边缘检测器进行卷积,最后得到的图,中间是-30,而不是30,将矩阵转换成图片就是![]() 。
。
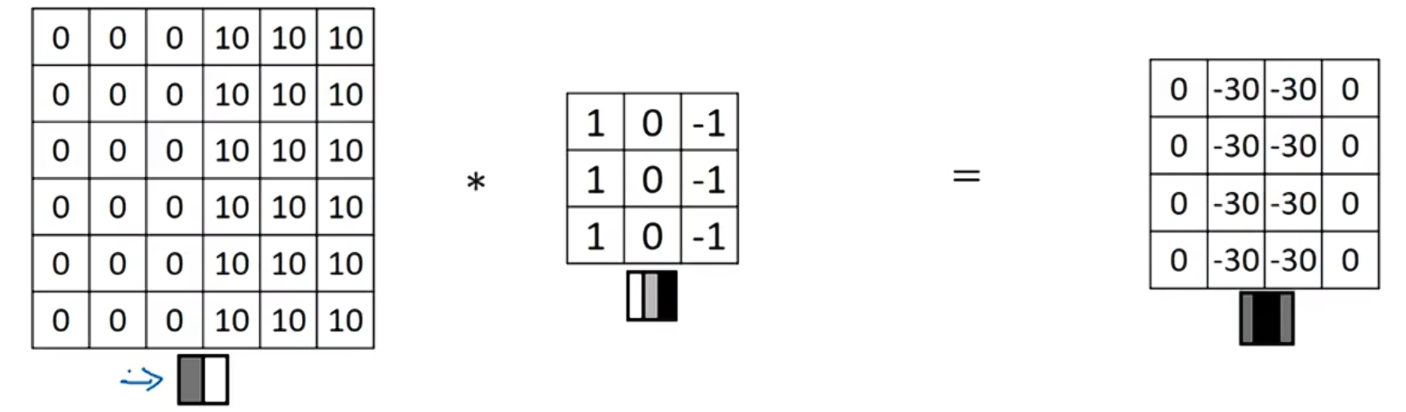
这个过滤器确实能够区亮到暗的边界和暗道亮的边界。现在看更多边缘检测的例子。
我们已经学习了能够检测垂直边缘的3×3过滤器,所以见到右边这个过滤器,你应该猜出来它能够检测出水平边缘,它的上边部分较亮,下边部分较暗。

这里有更复杂的图像,图像的左上方和右下方都是亮度为10的点,用这样的图形与水平边缘检测器卷积,就会得到一个矩阵。
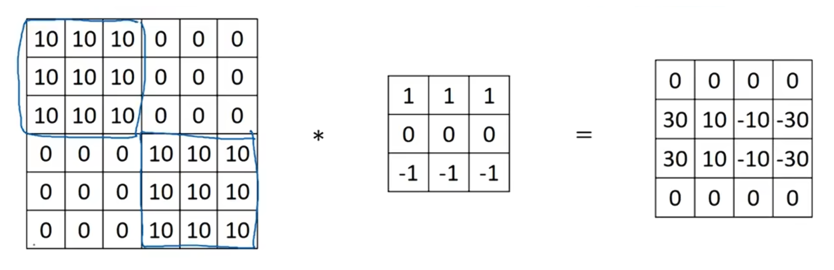
总而言之,通过使用不同的过滤器可以找到垂直或水平边界。但实际上,这些3×3的垂直边界检测器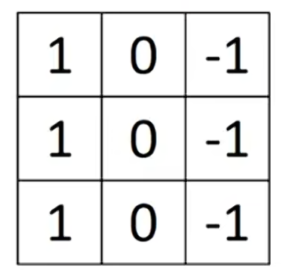 只是一个可能的选择。在计算机视觉的文献中,对于用哪些数字组合是最好的,仍然存在相当大的争议,你可以使用别的数字,
只是一个可能的选择。在计算机视觉的文献中,对于用哪些数字组合是最好的,仍然存在相当大的争议,你可以使用别的数字,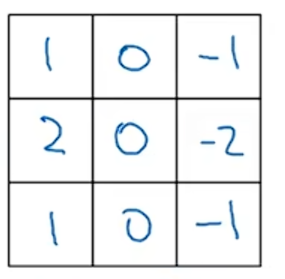 ,这是一个叫做Sobel的过滤器。这个过滤器的优点在于:它给中间行赋予了更大的权重,从而可能使它更加稳定。计算机视觉的研究人员同样会使用其他的数字组合
,这是一个叫做Sobel的过滤器。这个过滤器的优点在于:它给中间行赋予了更大的权重,从而可能使它更加稳定。计算机视觉的研究人员同样会使用其他的数字组合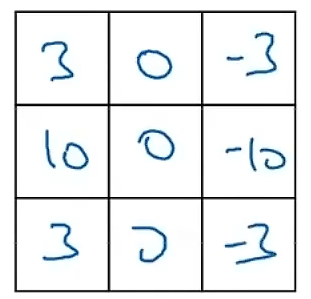 ,这叫做Scharr过滤器,它有些其他略微不同的性质。
,这叫做Scharr过滤器,它有些其他略微不同的性质。
将这一些垂直边缘检测器翻转90度,你就可以得到水平边缘检测器。
随着深度学习的发展,如果你想要检测一些复杂图片的边界,可能并不需要计算机视觉的研究人员挑选出这九个矩阵元素,你可以把矩阵里的这九个元素当做参数,通过反向传播算法来学习得到它们的数值,目标是要获得这九个参数,只要对6×6的图片,用这个3×3的过滤器进行卷积,就可以得到一个优良的边缘检测器。
通过将过滤器的每个元素设成参数,通过数据反馈,让神经网络自动学习他们,我们发现神经网络可以学习一些低级的特征(边缘的特征)。
4 填充
为了构建深层神经网络,一个你非常需要使用的,对基本的卷积操作的改进就是padding。
之前我们知道了,如果用一个3×3的过滤器卷积一个6×6的图片,最终会得到一个4×4的矩阵输出。这是因为3×3的过滤器在6×6矩阵中只可能有4×4种可能的位置。这背后的数学解释是:如果我们有一个n×n的图像,用f×f的过滤器做卷积,输出结果的维度是。
这其中有两个缺点:一个缺点是每次做卷积操作图像就会缩小,从6×6缩小到4×4,可能做了几次卷积操作之后,图像就会变得很小了。所以也许你并不希望,每次你想检测边缘或者其他特征时,都缩小你的图片。第二个缺点是,图片角落边上的像素,只会在输出中被使用一次;而图片中间的像素,会有许多3×3的过滤器在那个像素上重叠,所以图片丢失了许多靠近边界的信息。
为了解决输出缩小、图像边缘大部分信息丢失这两个问题。你可以在卷积操作之前,在图像的边缘再填充一层像素,这样就把6×6的图像填充成了一个8×8的图像,这时候如果你用3×3的图像对这个8×8的图像卷积,得到的输出就不是4×4,而是6×6的图像,这样你就得到了和原始图像一样大小的尺寸。
通常,你可以用0来填充。如果p是填充的数量,在这个例子中,p=1,因为我们在边缘都填充了一个像素点,输出变成了:,也就是:
这个绿色的像素,实际上影响了输出中的这些格子,这样的效果是大大降低了之前角落信息被忽略的情况。
上面展示的是用一个像素点来填充边缘的情况,如果你想的话也可以用两个或多个像素点来填充边缘。
至于需要填充多少,我们有两个常见的选择:Valid卷积和Same卷积。Valid意味着不填充,这样的话,如果你有一个n×n的图像,用一个f×f的过滤器卷积,得到一个维的输出。Same卷积:意味着你填充后,输出大小个输入大小是一样的,因此如果你有一个n×n的图像,用p个像素填充边缘,输出就是
。如果你希望n+2p-f+1等于n,即输出和输入大小一致,
,所以当p是一个奇数的时候,只要选择相应的填充尺寸,就能确保输入和输出的尺寸一样。这也是为什么在前一个例子中,当过滤器是3×3时候,使得输出和输入的尺寸一致时,需要填充一像素。
另一个例子,当你的过滤器是5×5,就会发现需要两层填充,才能够使得输出和输出尺寸一样大。
通常在计算机视觉领域,f基本上是奇数。这有两个原因:
(1)如果f是一个偶数,那么你需要一些不对称的填充;当f是奇数时,Same卷积才会有自然的填充,可以以同样的数量填充四周,而不是左边填充多一点,右边填充少一点,这样的不对称填充。
(2)当你有一个奇数维的过滤器,比如3×3或者是5×5,它就有一个中心点,有时在计算机视觉里,有一个中心像素点会很方便,能便于指出过滤器的位置。
5 卷积步长
卷积中的步长是另一个构建卷积神经网络的基本操作。
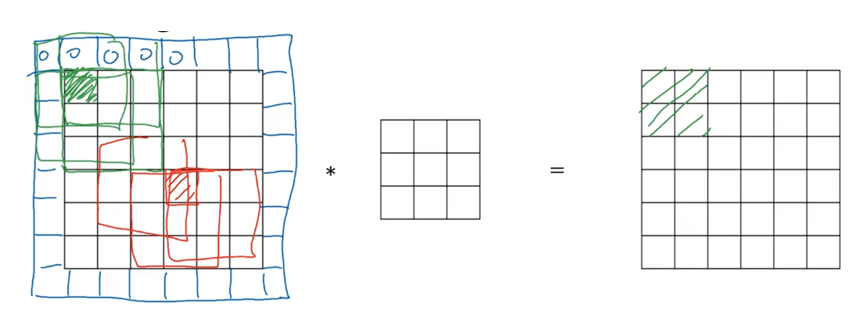
如果你想用3×3的过滤器和7×7的图像进行卷积,和之前不同的是,我们把步长(stride)设置成二。
7x7图像中的蓝色区域矩阵与过滤器进行按元素相成后相加得到一个值,即:2*3+3*4+7*4+6*1+6*0+9*2+3*(-1)+4*0+8*3=91
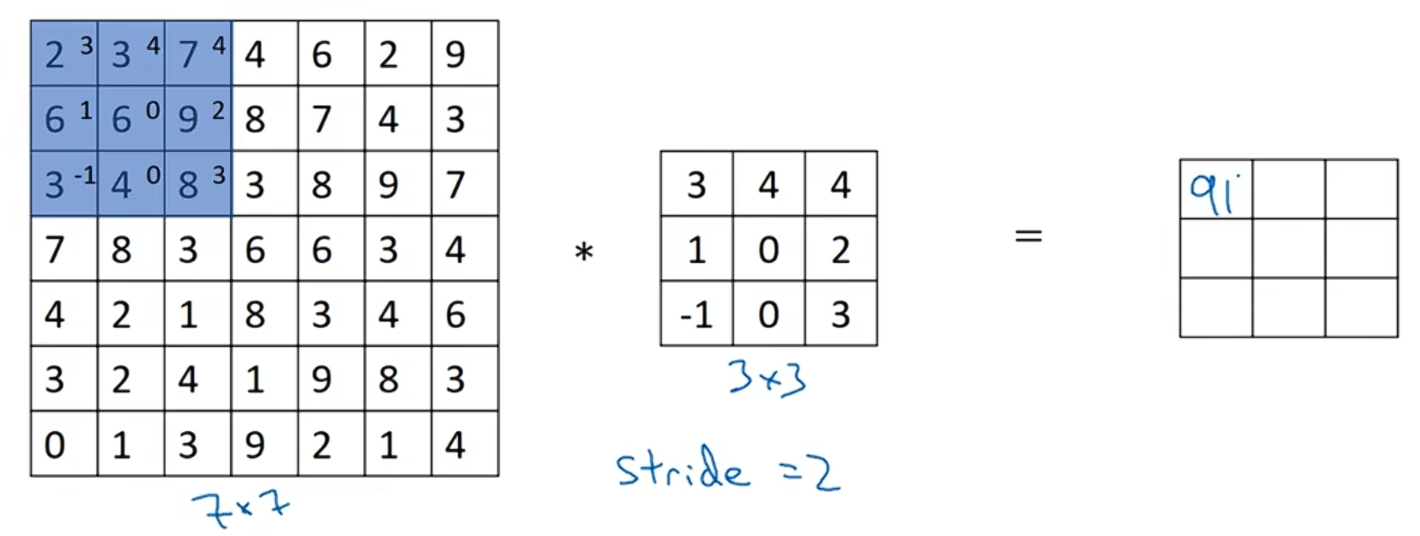
之前我们移动篮框的步长是1,现在移动的步长是2,所以我们让过滤器走过两个步长。7x7图像中的蓝色区域矩阵与过滤器进行按元素相成后相加得到结果是100
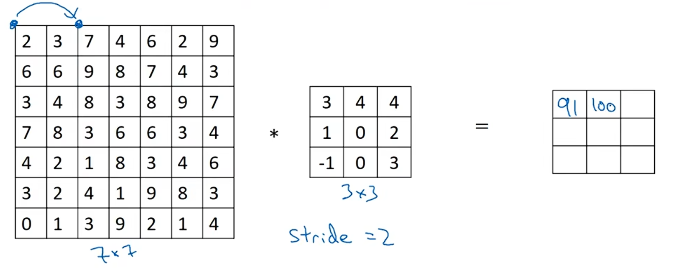
继续讲蓝框往右边移动两个步长,并计算,可以得到结果是83。
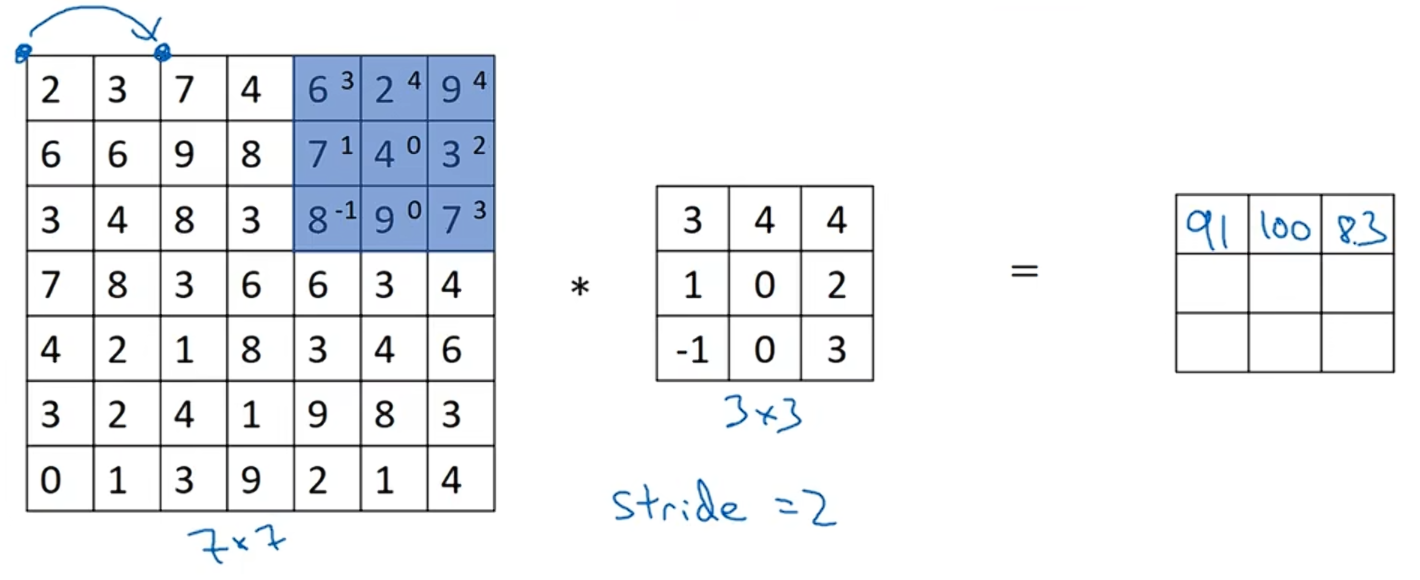
当移动到下一行时,使用的步长也是2,而不是步长1,所以把篮框移动到下面的位置,再进行卷积运算,得到结果69。
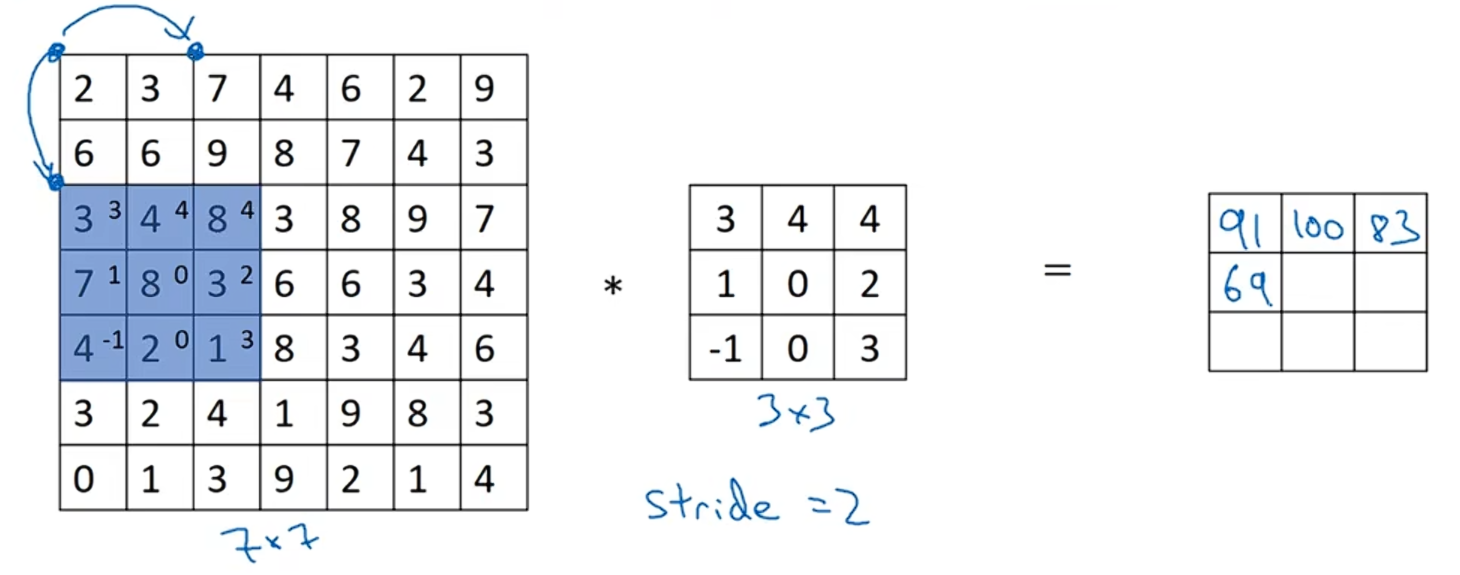
最后,用3x3的过滤器与7x7的矩阵卷积运算得到了3x3的矩阵。
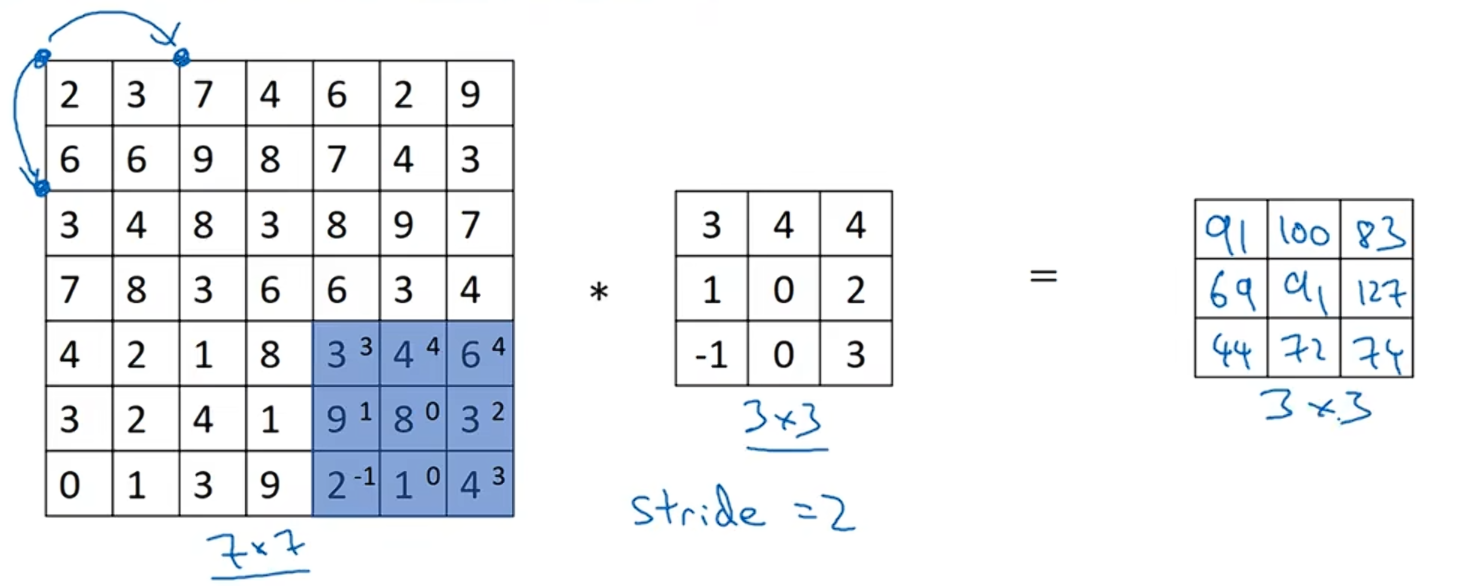
如果你用一个f×f的过滤器,卷积一个n×n的图像,padding=p,步长为s,你得到的输出为:。这个例子中步长s=2,
。
如果商不是一个整数怎么办?这种情况下,我们可以向下取整。这个原则实现的方式是:你只在篮框完全包括在图像或填充完的图像内部时,才对它进行运算;如果篮框移动到了外面,那么就不对它进行卷积操作。
6 三维卷积
我们来看看如何对三维图像进行卷积操作。
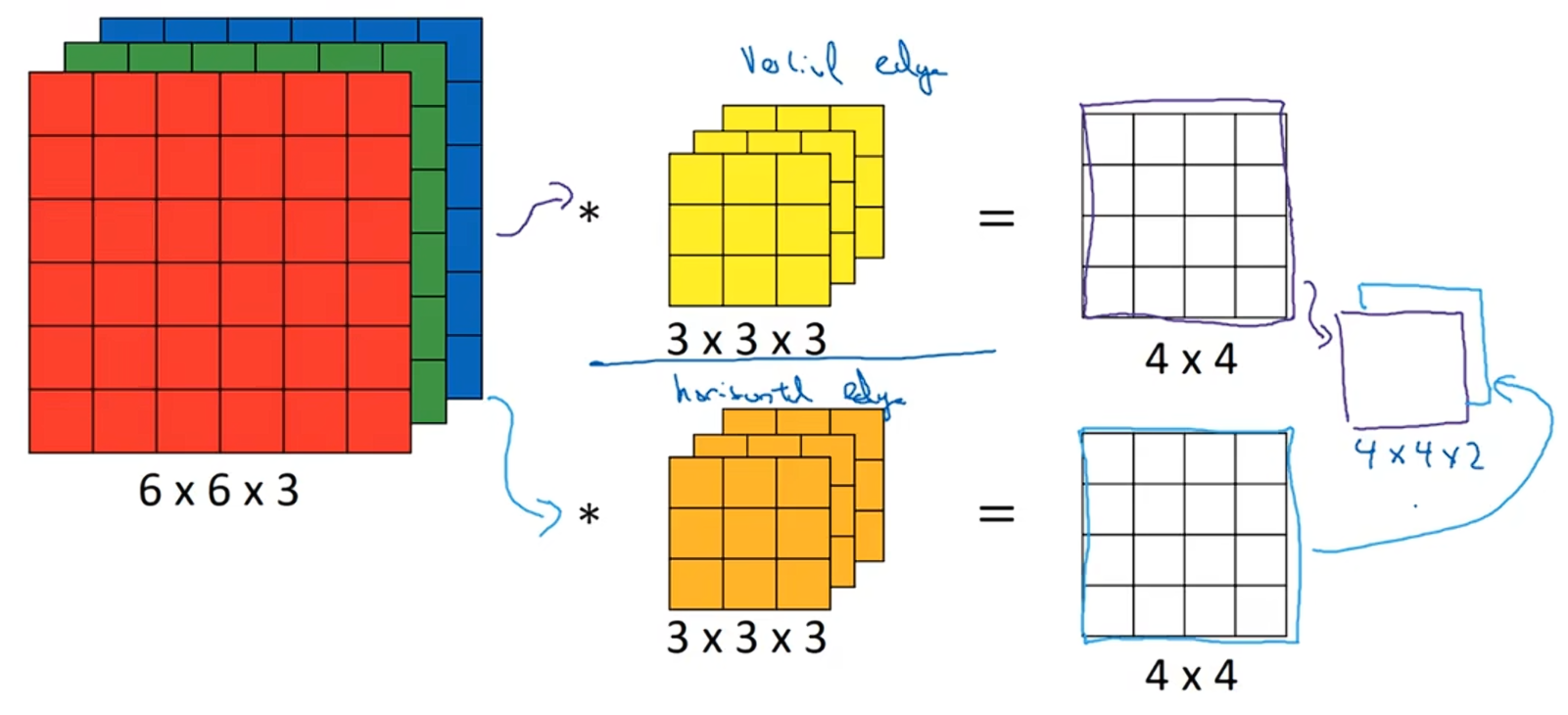
假设你不仅想检测灰度图像的特征,也想检测RGB彩色图像的特征。彩色图像大小是6×6,那么它就是6×6×3,这里的3指的是3个颜色通道,你可以把它想象成三个6×6图像的堆叠。为了检测图像的边缘或者一些其他特征,不是把它跟原来的3×3过滤器做卷积,而是跟一个三维过滤器卷积,这个过滤器也有三层,是3×3×3。
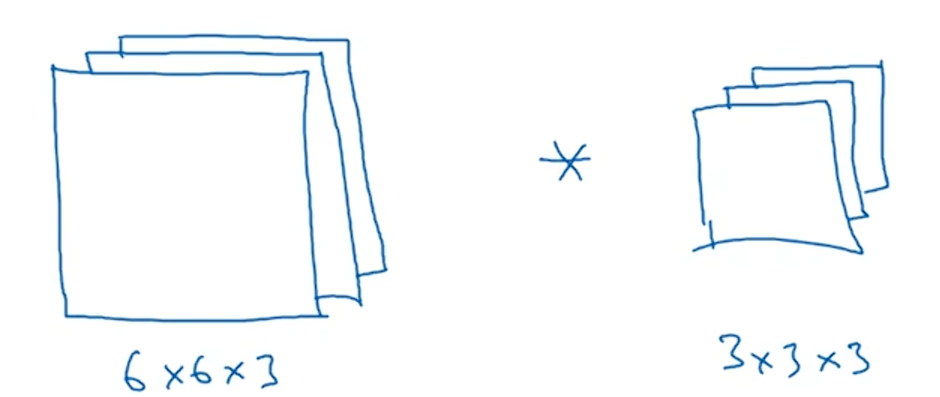
对于6×6×3,第一个6代表图像的高度,第二个6是图像的宽度,3表示的是通道数目;同样,过滤器的大小也表示高、宽和通道数,并且图像的通道数必须和过滤器的通道数匹配。它们进行卷积的结果是4×4×1。
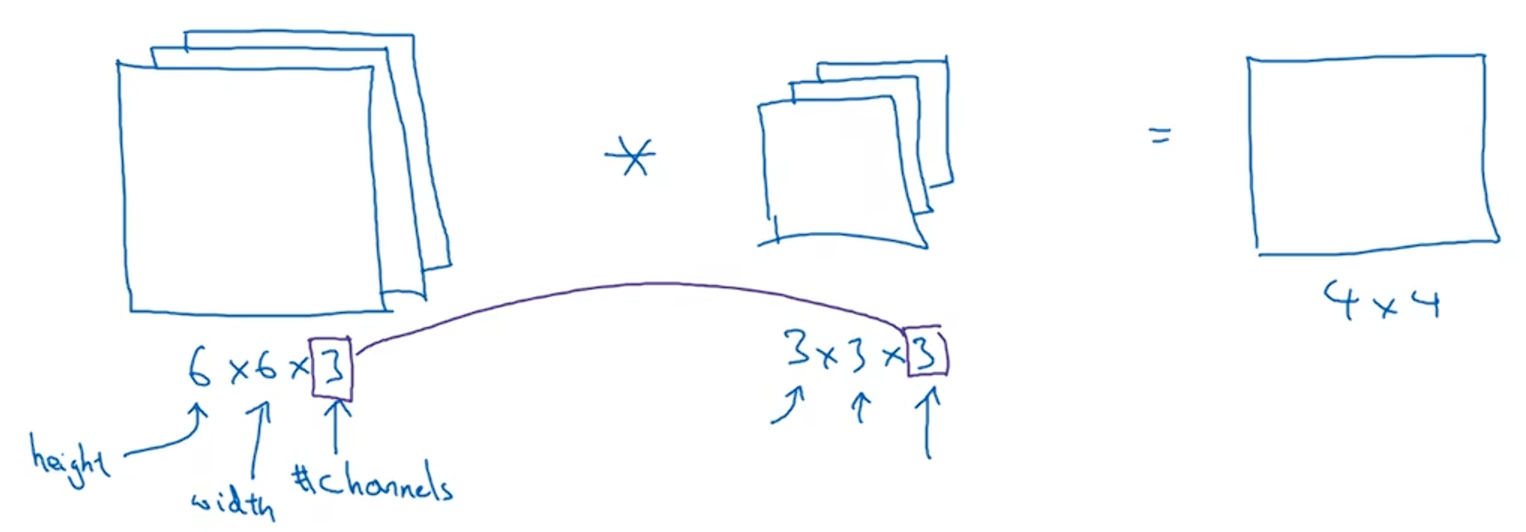
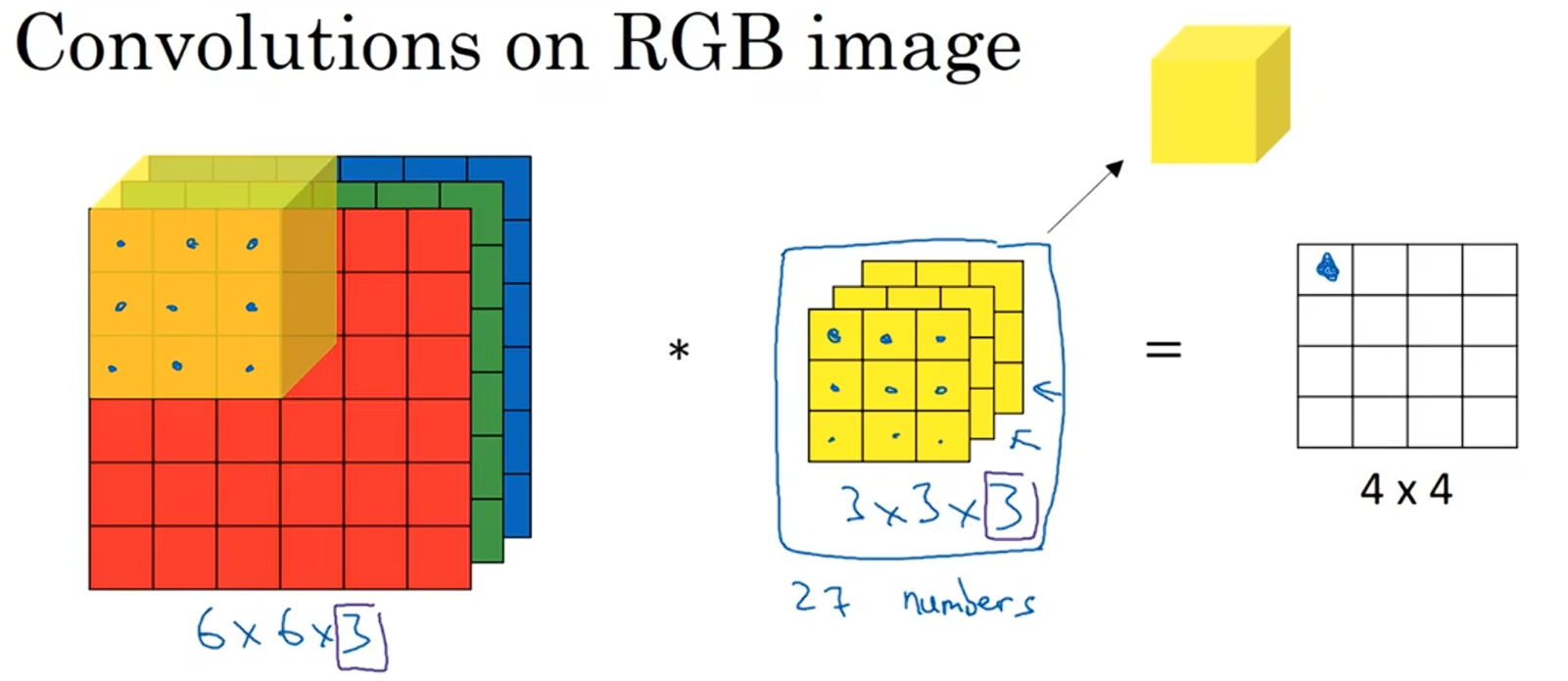
我们来研究一下这背后的细节。
为了计算这个卷积操作的输出,要做的就是把这个3×3×3的过滤器,先放到最左上角的位置,这个3×3×3的过滤器有27个数,依次取这27个数,然后乘以相应的红绿蓝通道中的数字,然后把这些数都加起来,就得到了输出的第一个数字。
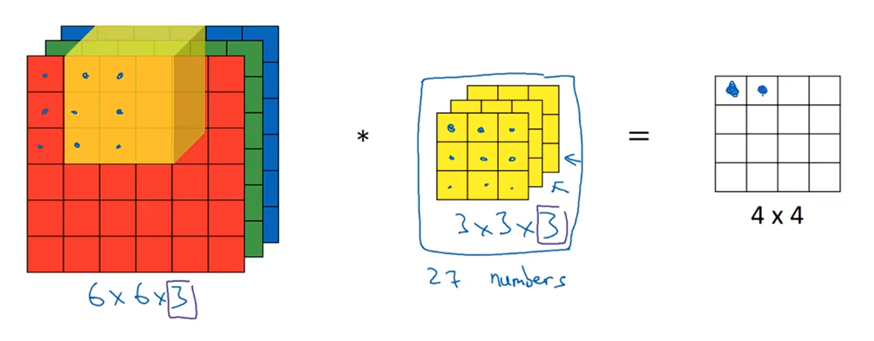
如果要计算下一个输出,就把这个立方体向右滑动一个单位,在与这27个数相乘之后把他们的值都加起来。
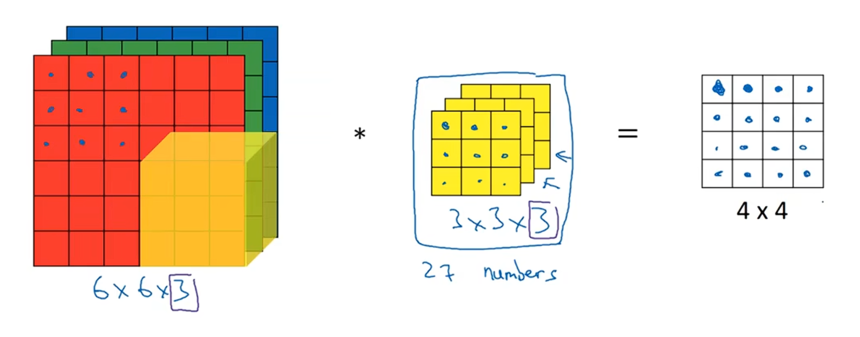
依次做这样的操作,就得到了一个4×4的输出矩阵。
那么这个能干什么呢?举个例子,这个过滤器是3×3×3的,如果你想检测图像中红色通道的边缘,你可以把这个三个通道的过滤器数值设为下图这样,那么这就是一个检测红色通道,垂直边界的过滤器。
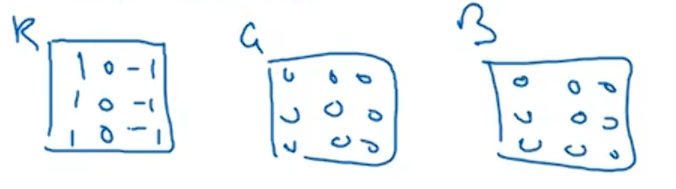
如果你不关心垂直边界在哪个颜色通道里?那么你可以用一个这样的过滤器:通过设置第二个过滤器参数,你就有了一个边界检测器,用来检测任意颜色通道里的边界。
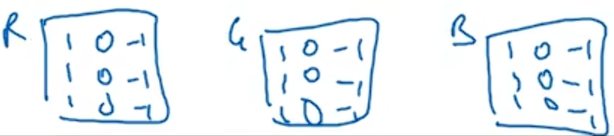
通过使用不同的参数,你可以从这个3×3×3的过滤器中得到不同特征的检测器。
通常,在计算机视觉领域,当你的输入图片有固定的高度、宽度、通道数,你的过滤器可以有不同的高、宽,但是通道数必须一样。理论上说,我们可以有一个只负责红色通道的过滤器,或者一个只负责绿色通道或蓝色通道的过滤器。用一个3×3×3的过滤器来卷积6×6×3的图像,会得到一个4×4的结果。
最后还有一个对于建立卷积神经网络非常重要的概念:如果我们不仅想要检测垂直边缘、如果我们想同时检测垂直边缘和水平边缘或者是45度边缘或者70度边缘。换句话说,如果你想要同时应用多个过滤器呢?
6×6×3的图像和两个过滤器进行卷积,得到两个4×4的输出,把它们堆叠在一起,形成一个4×4×2的立方体,这里的2来源于用了两个不同的过滤器。
7 单层卷积网络
我们来看看如何构建卷积神经网络的卷积层,现在来看看一个例子。
我们已经知道了如何通过两个过滤器卷积处理一个三维图像,并输出两个不同的4×4矩阵。最终,我们需要把这些输出变成单层卷积神经网络,然后对每一个输出增加一个偏差,我们可以添加一些非线性Relu函数,最终,通过添加偏差和非线性转换,得到了一个4×4矩阵输出。我们把输出的这两个矩阵放在一起,得到一个4×4×2的矩阵。
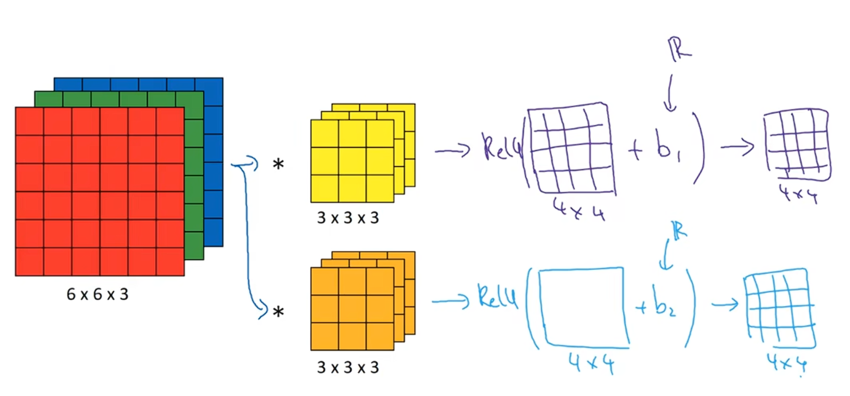
这个例子中,对于6×6×3的输入,我们通过计算得到一个4×4×2的输出,这就是卷积神经网络的一层。
现在我们把这个例子和普通的非卷积单层前向传播神经网络对应起来,在神经网络传播之前,我们需要做:,执行非线性函数,得到
,输入图片就是x,过滤器就是
。
在卷积过程中,我们对这27个数进行操作,其实是27×2,因为我们用了两个过滤器。我们取这些数做乘法,实际上执行了一个线性函数得到一个4×4的矩阵。
在这个例子中,我们有两个过滤器,也就是两个特征。因此,我们得到输出是4×4×2,如果我们有十个过滤器,那么我们得到的输出就是4×4×10,因为这里需要有十个这样的操作,然后把结果放在一起。
为了进一步理解这里所说的,我们来做一个练习。
假如你的单层神经网络中有十个3×3×3的过滤器,那么,这层网络中有多少参数呢?我们来计算一下。
每个过滤器是3×3×3的三维矩阵,因此,每个过滤器有27个参数,然后加上一个参数b,也就是总共有28个参数。十个这样的过滤器,也就是说总共有280个参数。
需要注意的一点是,不论输入的图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个,这就是卷积神经网络的一个特征,叫做避免过拟合。因此,如果你训练学习得到十个特征检测器,你可以把它们应用到非常大的图像(特征检测)中,参数还是不变的。
现在我们来总结一下,用来在卷积神经网络描述一层网络的符号标记。
如果层L是一个卷积层,表示过滤器的大小;
表示padding,填充的大小也可以通过不同的卷积名称来定义,比如Valid填充、Same填充;
表示步长;
表示过滤器的数量;这一层的输入是一个多维矩阵,也就是
×
×
,输出是
×
×
8 卷积网络的简单示例
假设我们有一张图像。并且你想做图像分类或图像识别。把这张图片定义为输入x,判别图片中有没有猫,用0或者1表示。
我们来构建适用于这项任务的卷积网络。
针对这个事例用了一张比较小的图片,大小是39×39×39。这样设定可以使其中一些数字效果更好。所以,,即高度和宽度都等于39;
,表示第0层的通道数量是3。假设第1层用一个3×3的过滤器来提取特征。那么,
,如果有10个过滤器,神经网络下一层的激活值为37×37×10,第1层的标记为:
,
。
假设还有另外一个卷积层,这次采用的过滤器是5×5的矩阵,在标记法中神经网络下一层的f=5,即:;步长为2,即:
;padding为0,即:
;有20个过滤器,输出结果是一个17×17×20的新图像。因此,
,
。
我们来构建最后一个卷积层:假设过滤器还是5×5,步长为2,Padding为0,有40个过滤器,即,最后结果为7×7×40。
到此,这张39×39×3的输入图像就处理完毕了,为图片提取了7×7×40个特征,计算出来就是1960个特征。然后对该卷积层进行处理,可以将其展开成1960个单元,扁平化成一个向量,然后将其输入到一个逻辑回归或sofrmax单元,这取决于是想识别图片上有没有猫还是想识别是k种猫的哪一种猫?用表示最终神经网络的预测输出。
这是神经网络的一个典型例子,设计卷积神经网络时确定这些超参数比较费功夫,要决定过滤器的大小、步长、padding以及使用多少个过滤器。
一个典型的卷积神经网络通常有三层:卷积层,常常用Conv来标注;池化层(Pooling)常常用POOL.来标注;全连接层(Fully connected)常常用FC来标注。虽然仅用卷积层也可能构建出很好的神经网络,但大部分神经网络架构师依然会添加池化层和全连接层。幸运的是池化层和全连接层比卷积层更容易设计。
9 池化层
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。我们先看一个池化层的例子,然后我们讨论一下为什么要这么做。
假设你有一个4×4的输入,并且你想使用一种称作Max pooling的池化类型。这个Max pooling的输出将会是2×2。实现它的做法非常简单,加4×4的输入划分为不同的区域,输出的每个元素都是其对应颜色区域中的最大元素值,如图所示:
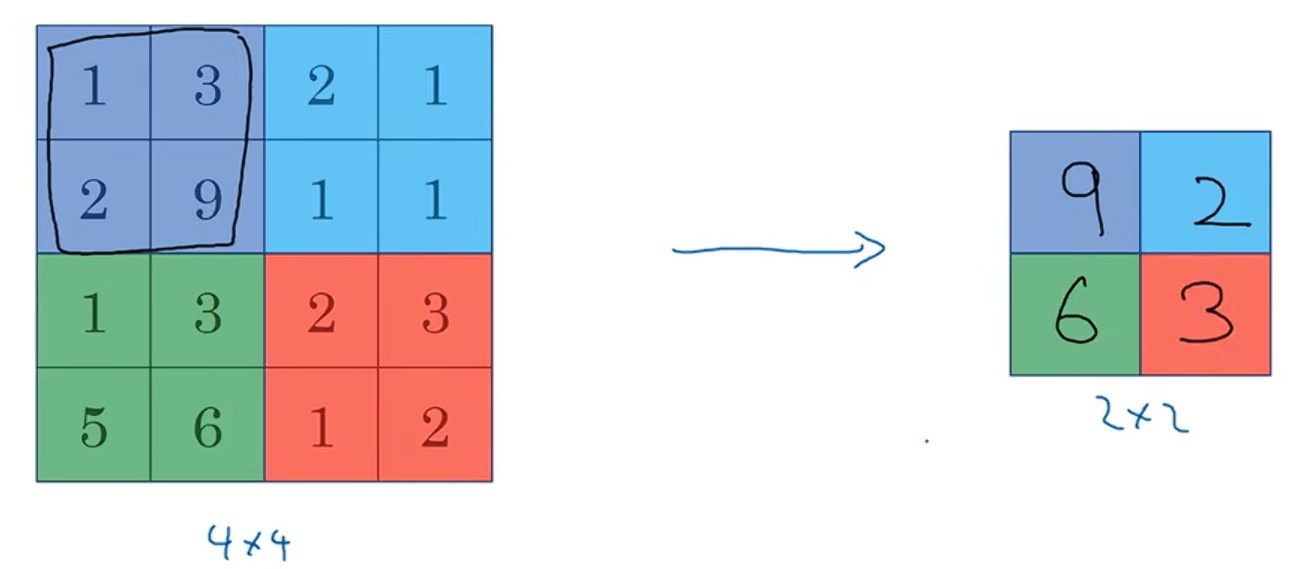
这里来说一下Max pooling背后的机制:如果你把4×4的区域看作某个特征的集合,即神经网络某个层中的激活状态,那么一个大的数字,意味着它或许检测到了一个特定特征,Max pooling做的是检测到所有地方的特征,保留数值最大的。
Max pooling的一个有趣的特性是:它有一套超参数,但是它没有任何参数需要学习,也就是说:没有任何需要梯度下降算法计算的参数。
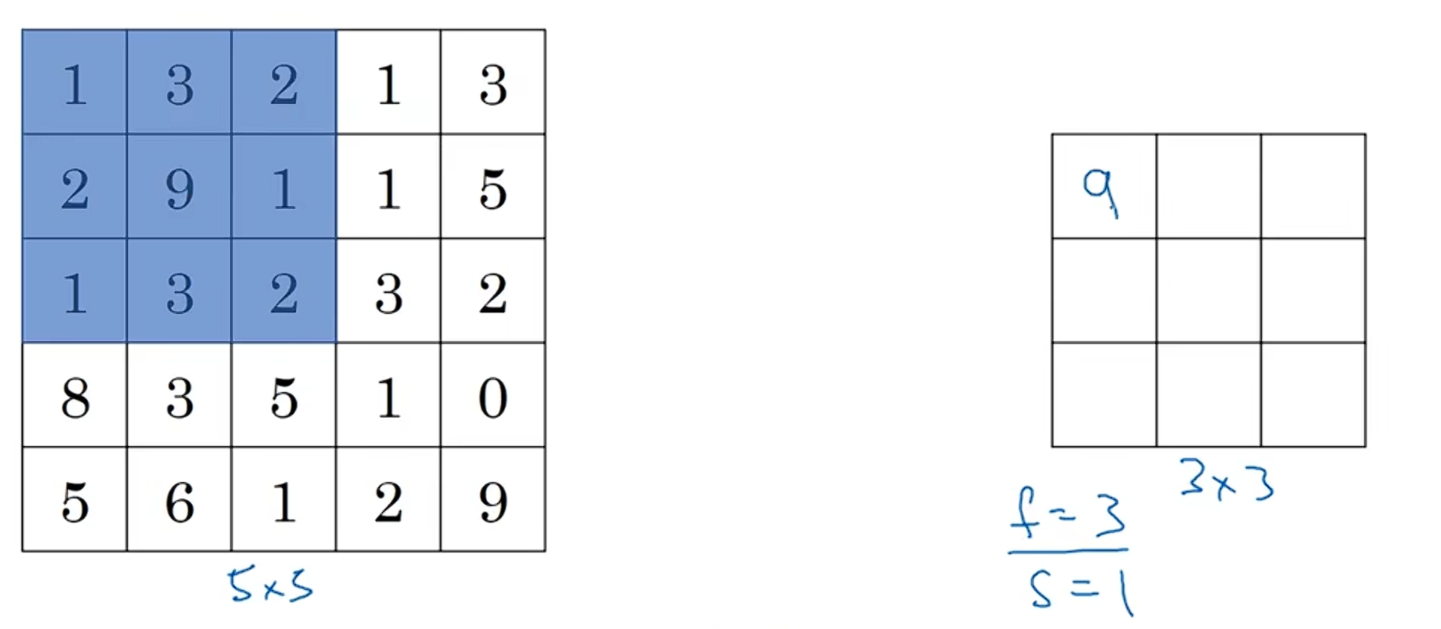
让我们来看一个有某些不同参数的例子。这里我们打算是用一个5×5的输入,并且为Max pooling应用一个大小为3×3的过滤器,于是f=3,并且我们使用的步长为一。
对第一个区域Max pooling的结果是9:
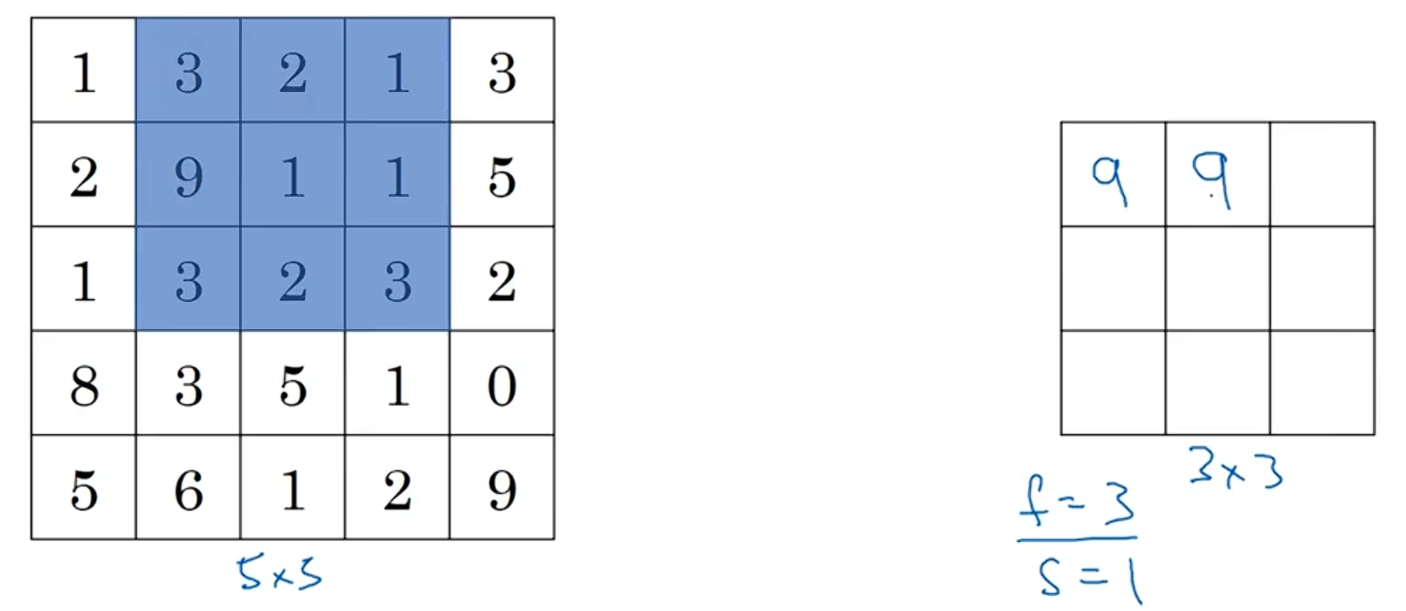
因为步长是1,向右移动一个单位,蓝色区域内的最大值是9:
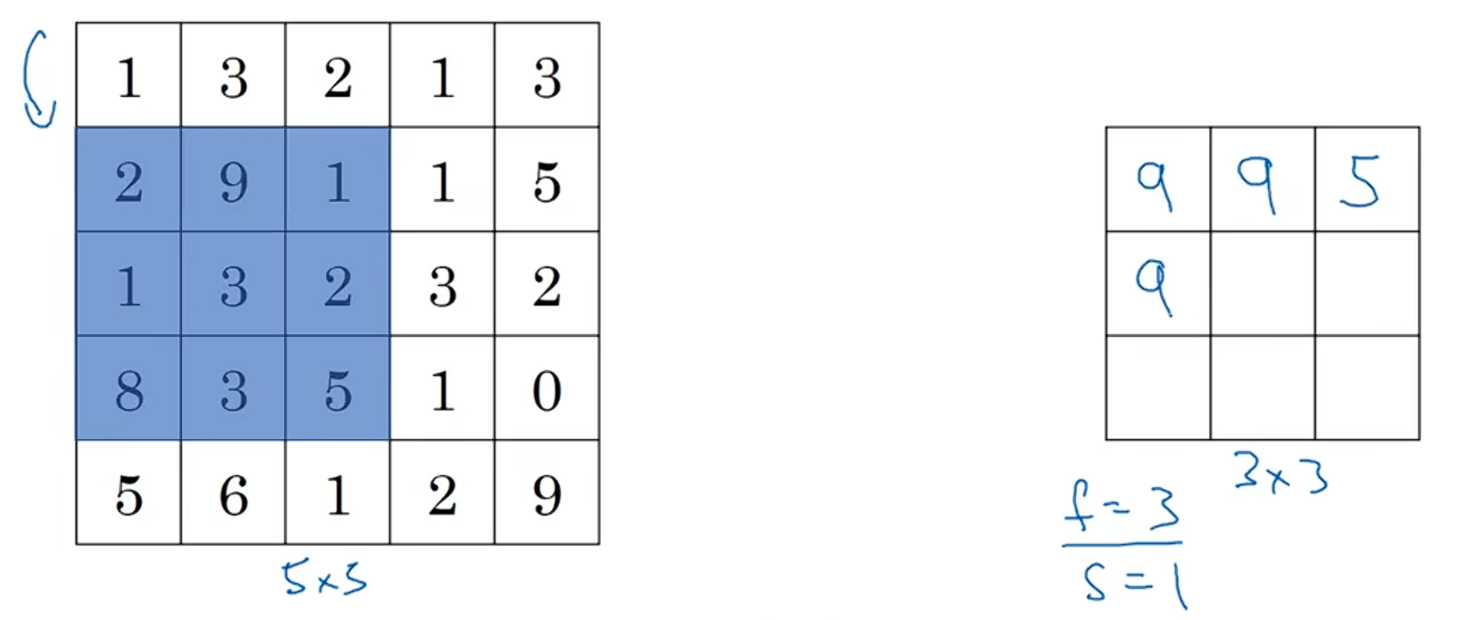
当第一行计算完,往下移动一个单位继续计算,蓝色区域内的最大值是9:
最后,通过Max pooling得到了3×3的矩阵:
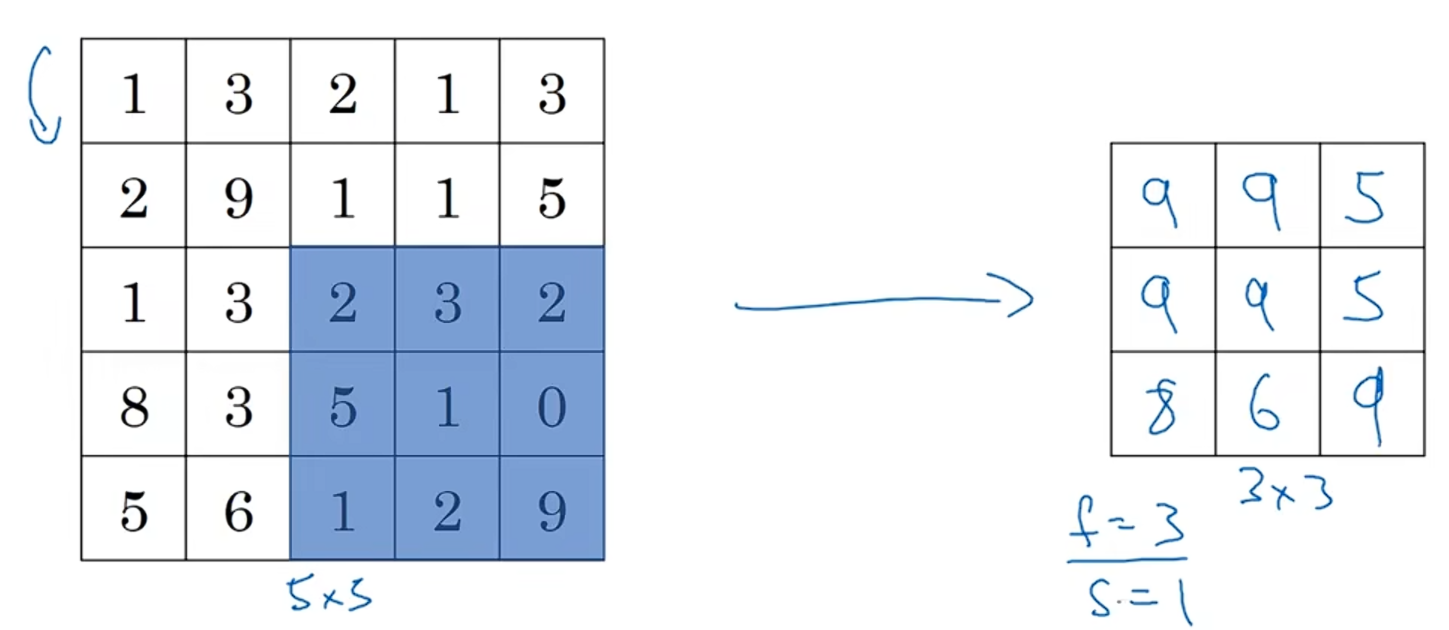
以上就是在二维输入上的Max pooling,如果有一个三维输入,则会输出同样的维度。例如有一个5×5×2的输入,输出将是3×3×2,并且计算最大值采样的方法是使用刚刚的计算过程,并且最大值采样计算是在这些通道上独立进行的。
现在我们来介绍一下均值采样:它不是取最大值,而是取平均值。
通常最大值采样比均值采样用的多一些,唯一的例外是:有时候在深度非常大的神经网络,你也许可以使用均值采样来合并表示,比如7×7×1000的输入,将它们整体取一个均值,得到1×1×1000。
10 卷积神经网络示例
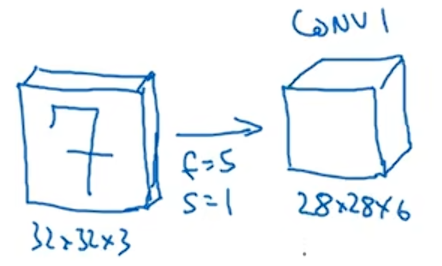
假设有一张大小为32×32×3的RGB输入图片,也许你想做手写数字识别,图片中含有某个数字,比如七,你想识别它是从0到9这十个数字中的哪一个?我们可以构建一个神经网络来实现这个功能,在这里使用的神经网络和LeNet-5非常相似。
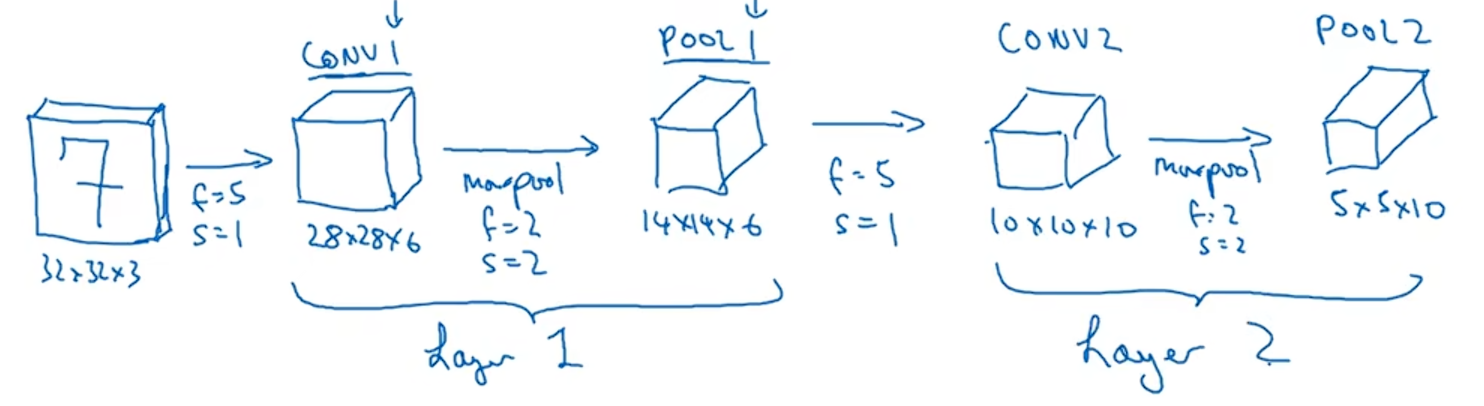
这里有一个32×32×3的输入,假设第一层使用的过滤器大小为5×5,步长是1,padding是0,过滤器个数是6,那么第一层的输出为28×28×6将这一层标记为Conv1
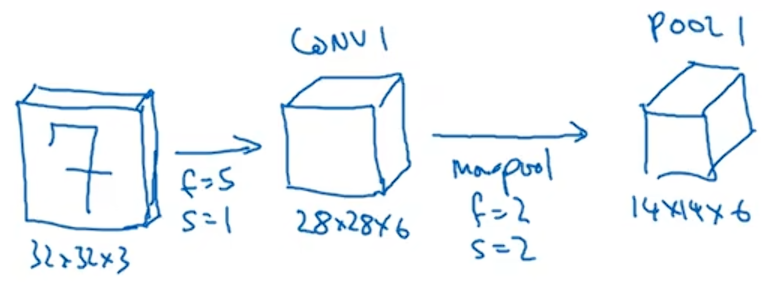
接下来我们使用最大池化,参数f=2,s=1,原有的高度和宽度会减少一半,因此变成14×14×6,将这层标记为POOL1输出。
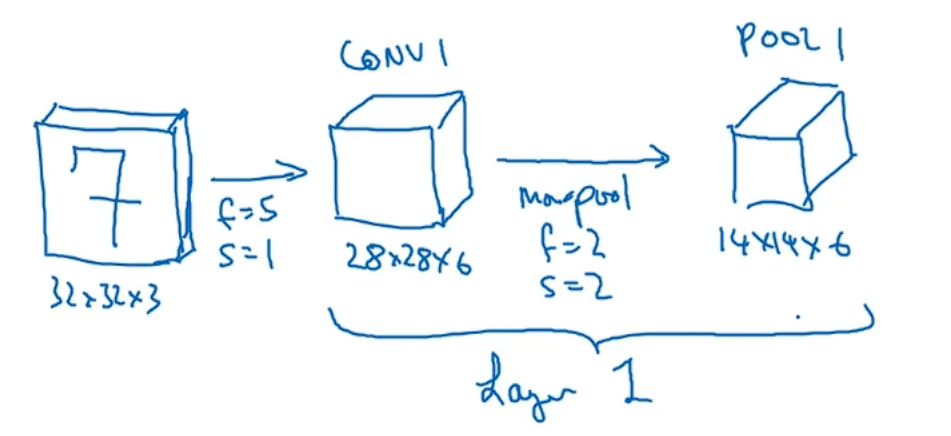
事实上,在卷积网络的文献中有两种关于层的说法,二者有细微的差别。一种是把卷积和池化称为一层;另一种说法是卷积层称为一层,池化层单独称为一层。神经网络中,当人们说到网络层数的时候,通常指那些有权重、有参数的网络层数量,因为池化层没有权重、没有参数,只有一些超参数,这里我们把Conv1和POOL1共同作为一个卷积层,并标记为Layer1。
我们再构建一个卷积层,过滤器大小为5×5,步长为1,这次使用十个过滤器,最后输出一个10×10×10的矩阵,标记为Conv2,然后做最大池化,超参数f=2,s=2,最后输出为5×5×10,标记为POOL2,这就是神经网络的第二个卷积层,即Layer2。
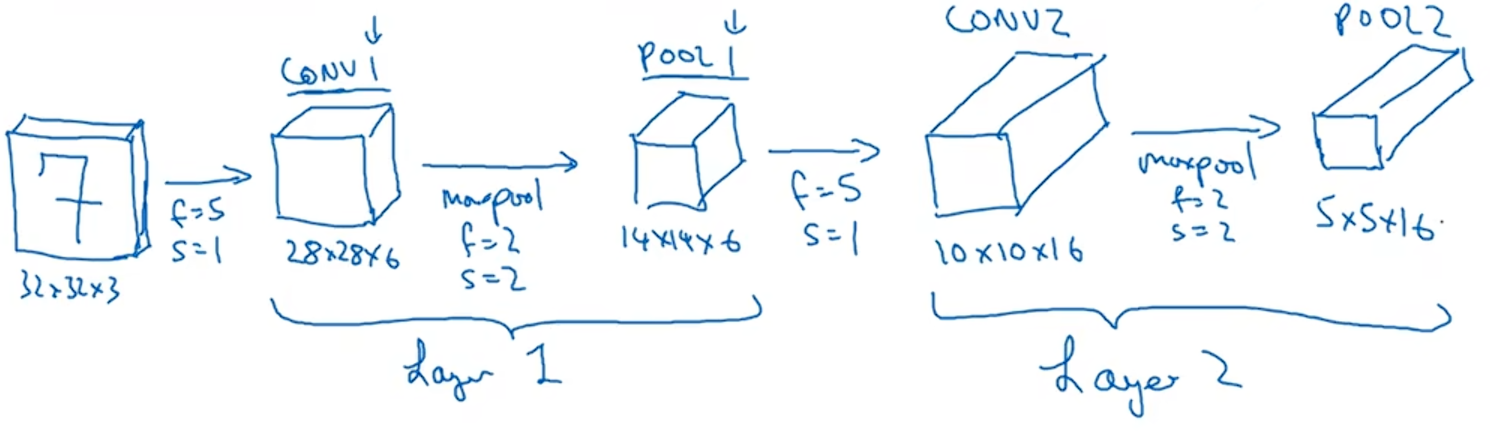
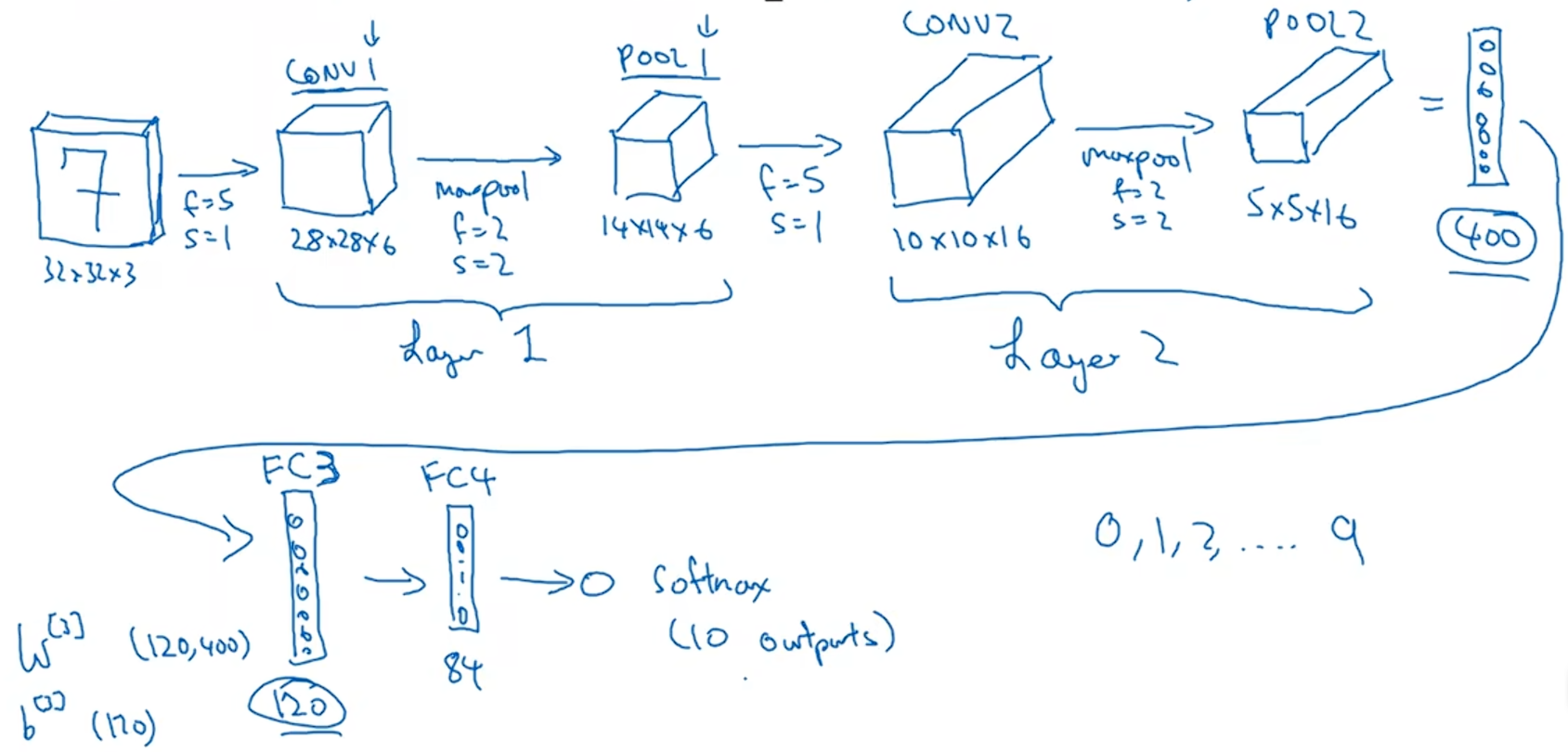
如果对Layer1应用另一个卷积层,过滤器为5×5,即f=5,步长为1,padding=0,过滤器为5×5,即f=5,步长为1,padding=0,这次使用16个过滤器,这样Conv2的输出就是10×10×16;接下来做最大池化,参数f=2,s=2,结果为5×5×16,矩阵包含400个参数。
现在我们把POOL2展开成一个400×1的向量,接下来我们要做的是用这400个单元做输入,构建一个有120个单元的下一层,这实际上是我们的第一个全连接网络层,标记为FC3。权重矩阵大小为120×400,因为400个单元与这120个单元中的每一个相连接,所以被称为全连接网络,并且还有个偏差参数,大小也是120维,因为有120个输出。
然后我们对这120个单元再添加一个全连接层。这一层比较小,假设它含有84个单元,标记为FC4。最后,我们获得了可以用于Softmax层的84个单元,如果我们想识别手写的0到9这十个数字,这将是一个有着十个输出的Softmax层。
这个例子中的卷积神经网络很经典,看上去有很多超参数,常规的操作是尽量不要自己设置超参数,而是查看文献中别人使用的超参数,选一个在别人任务中效果很好的架构,有可能它也适用于你的应用 。
11 为什么使用卷积网络
我们来谈谈为什么把卷积放在神经网络中会这么有用?
假如你有一张32×32×3的图片,6个大小为5×5的过滤器,输出维度为28×28×6。32×32×3=3072,28×28×6=4704,如果你是构建一个一层有3072个单元的神经网络,下一层是4704个单元,两层中的每个神经元彼此相连,然后计算权重矩阵,参数总和是3072×4704,结果大约是1400万个,所以要训练的参数很多。虽然以现在的技术,我们可以训练比1400万更多参数的神经网络,但是考虑到这仅仅是一个很小的图像,却要训练如此多的参数。如果有一个1000×1000的图像,那么权重矩阵将会变得非常大。但是你看这个卷积层的参数总数,每一个过滤器都是5×5的,因此一个过滤器有25个参数,再加上偏差参数,那么,每个过滤器就有26个参数,一共有六个过滤器,所以参数总共有156个,参数数量较少。
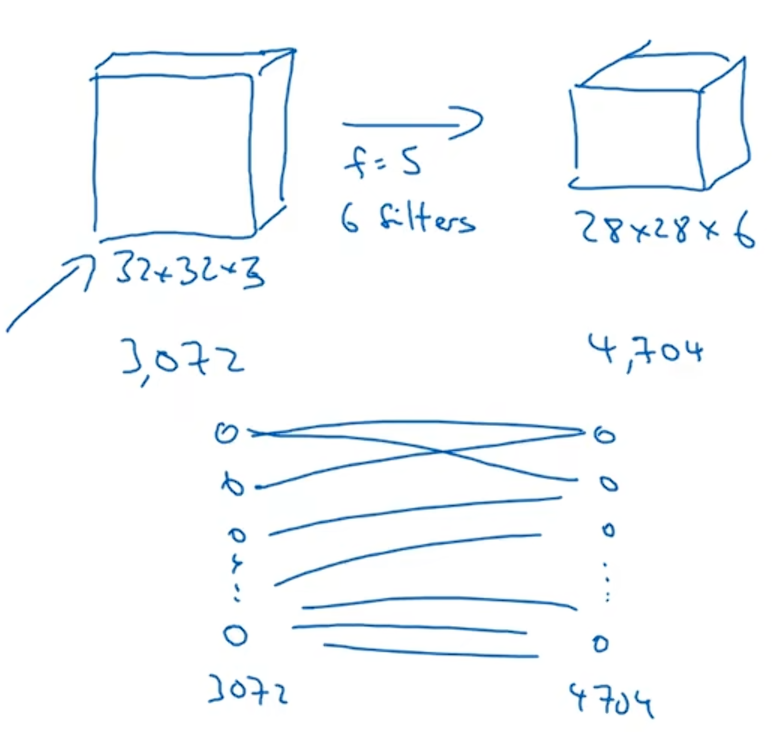
卷积层和只用完全连接的神经层比起来有两个优势:参数共享和稀疏连接。参数共享:使用相同的卷积核。稀疏连接:每个元素只与过滤器的参数有关,减少了很多没有关系的映射。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









