







研究背景:在自动驾驶领域,多模态大语言模型的应用多限于理解复杂环境或生成高级指令,而少有涉及端到端路径规划,主要因缺乏包含视觉、语言和行动的大规模注释数据集。为解决此问题,本文提出了CoVLA数据集,含80小时真实驾驶视频,通过自动数据处理技术,匹配精确轨迹与自然语言描述,超越了现有数据集。研究利用CoVLA数据集,探索了多模态大语言模型在自动驾驶中的视觉、语言和动作处理能力,证实了模型在生成连贯输出方面的强大性能,展现了视觉-语言-动作模型在自动驾驶领域的应用潜力。
主要贡献:
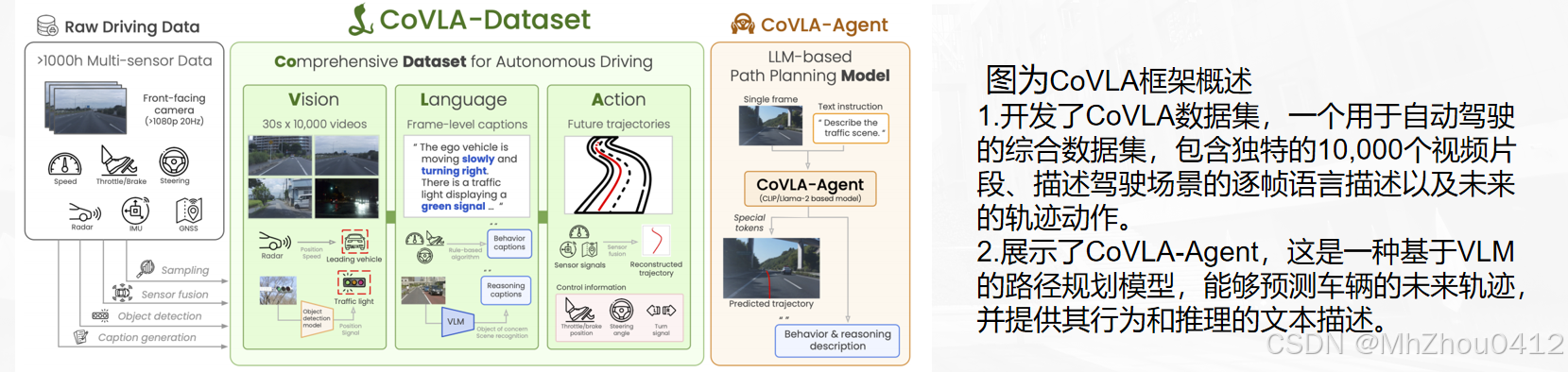
介绍了CoVLA数据集,这是一个大规模数据集,提供了多种驾驶场景的轨迹目标,以及详细的逐帧情境描述。
提出了一种可扩展的方法,通过传感器融合准确估计轨迹,并自动生成关键驾驶信息的逐帧文本描述。
开发了CoVLA-Agent,这是一种基于CoVLA数据集的新型VLA模型,用于可解释的端到端自动驾驶。本文的模型展示了持续生成驾驶场景描述和预测轨迹的能力,为更可靠的自动驾驶铺平了道路。
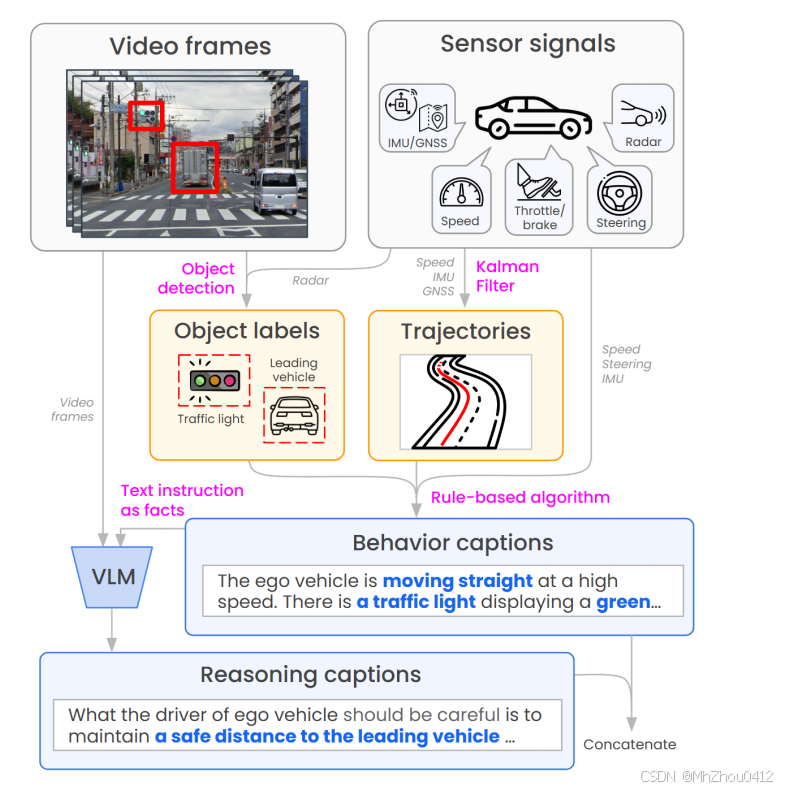
数据集生成 pipeline 概述。
1.自动标注视频帧和传感器信号以生成轨迹和其他标签。
2.对视频帧应用自动描述生成,以生成行为和推理的描述。
视频帧(Video fram
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









