







记录一次大材小用,我在将.csv电影数据集
电影json数据
导入MySQL时,出现了报错:

很明显,意味着.csv中的数据有非utf8编码的,
尝试使用file查看了下.csv文件的编码格式:
如果不确定原始编码,可以先用file命令尝试检测一下:
file -i input.csv
该命令会显示文件的MIME类型和字符编码信息。

猜测可能是特殊格式的问题导致的!
首先想到了是使用iconv命令强转下编码格式,来实现数据的预处理
iconv -f utf-8 -t utf-8 -c movieSet.csv > movies.csv
解释下:
-f utf-8表示原始文件编码是UTF-8。-t utf-8由于你想要保持UTF-8编码不变,所以目标编码也是UTF-8。虽然这个设置在这种情况下看起来可能多余,但结合-c选项,它可以帮助过滤掉任何非法的UTF-8序列。-c参数表示在转换过程中丢弃无效字符(即无法转换为UTF-8的字符)。
movieSet.csv是源文件名。movies_utf8_cleaned.csv将转换后的内容重定向到新的文件movies_utf8_cleaned.csv。- 如果
movieSet.csv实际不是UTF-8编码,请先确定其实际编码,然后替换-f utf-8后的编码类型。
与此同时,也看了下MySQL的编码:
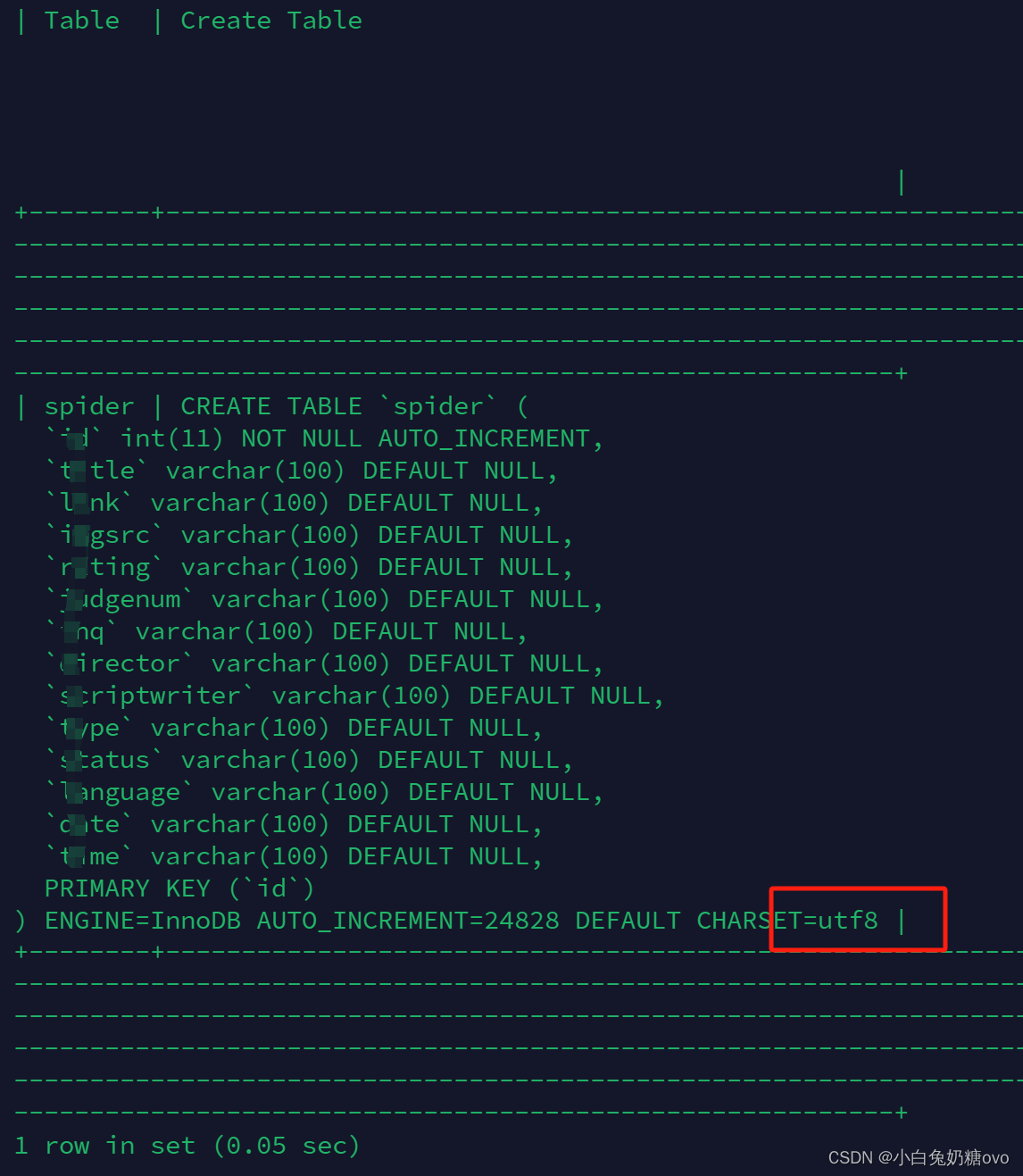
其实,感觉用Python预处理会好点
利用codecs模块或正则表达式来清除非法的UTF-8编码序列:
给出了之前使用的代码:
import codecs
import re
# 定义清理非法UTF-8编码序列的函数
def clean_utf8_string(input_str) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









