






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**
一、我的环境
-
电脑系統:Windows 10
-
语言环境:Python 3.8.0
-
编译器:Jupyter Lab
-
深度学习环境:torch==1.12.1+cu113 torchvision==0.13.1+cu113
二、 前期准备
1. 导入模块

2. 导入数据
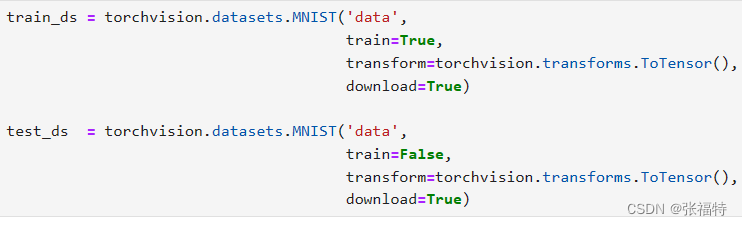
torchvision.datasets是Pytorch自带的一个数据库,我们可以通过代码在线下载数据,这里使用的是torchvision.datasets中的MNIST数据集。下载mnist数据集,数据集存放在'data'下。并人为划分训练集和测试集。
使用dataloader加载数据,并设置好基本的batch_size。

批量为32,每批加载的样本大小为32
torch.utils.data.DataLoader是Pytorch自带的一个数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。加载训练集和测试集,其中训练集每轮训练后随机打乱元素。
3、数据可视化
运行结果如下:

三、构建简单的CNN网络
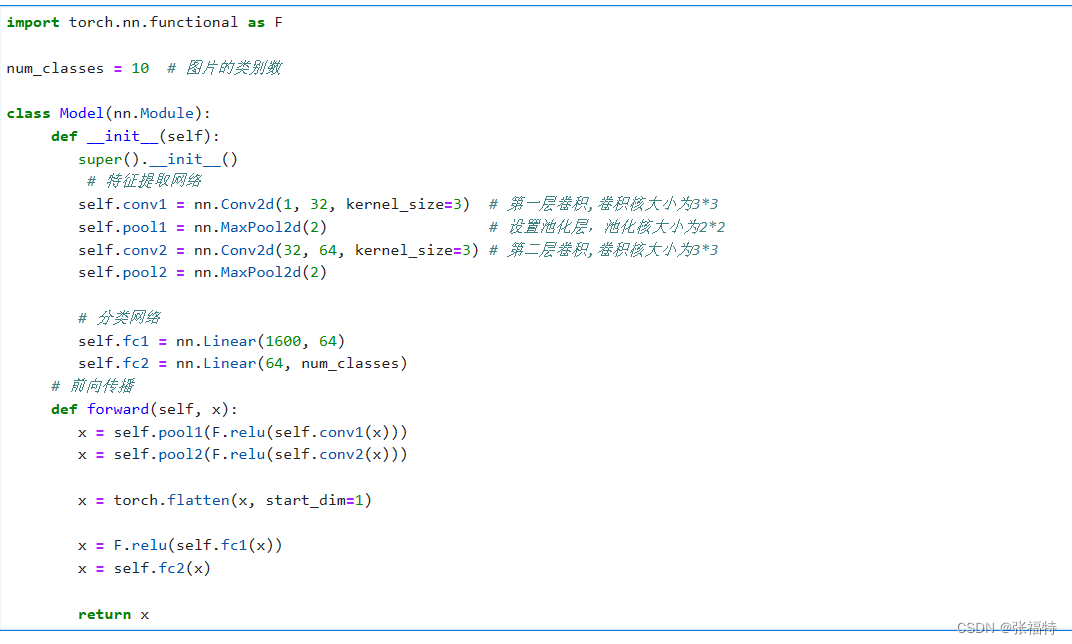
重点:卷积层池化层的分布,核子的大小,激活函数的选择,全连接神经网络的结构(权重),类继承的顺序。搭建cnn网络是为了提取图片特征,之后对特征图进行分类(10类中取概率最大的为图片数字的类别)。
四、 训练与测试模型
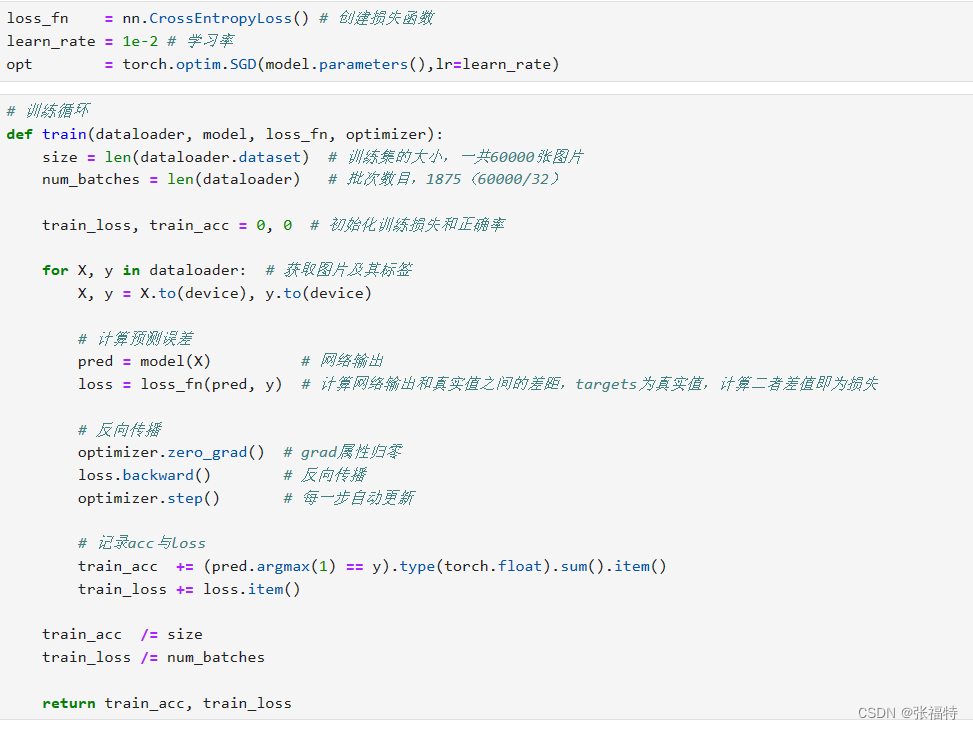
这里采用随机批量优化,采用反向传播算法。
这里的(pred.argmax(1) == y).type(torch.float).sum().item()表示计算预测正确的样本数量,并将其作为一个标量值返回。这通常用于评估分类模型的准确率或计算分类问题的正确预测数量。

测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器。
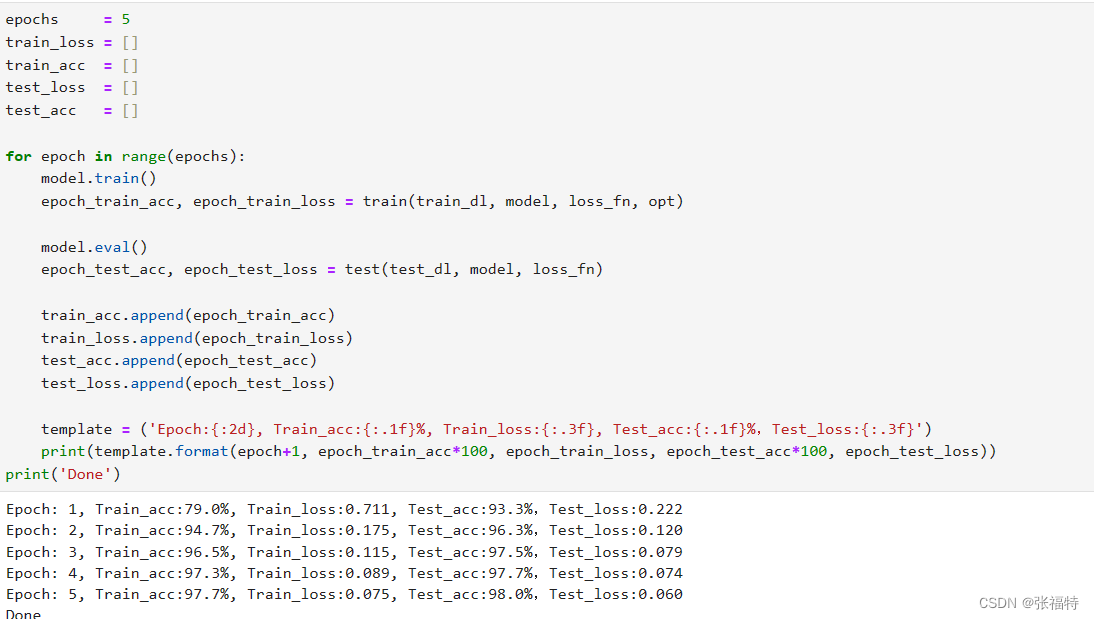
训练5轮,计算每轮训练集和测试集的准确率和损失。
五、 结果可视化
运行结果如下图所示:
 整体轮数可能不太够。
整体轮数可能不太够。
六、 个人总结
1.动手跟着教案敲一遍代码,把代码跑通
2.理解了代码各个部分的含义,补习了一些神经网络的基础知识















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









