






前言:
之前已有一篇创建决策树的文章,本文是在此基础之上优化,建议不了解的看官先熟悉一下如何生成一颗决策树。上一篇文章地址:
信息营地:
连续值处理:
上一节中由于圆周长和重量两个数据属性属于连续性变量,致使最后的生成树没有用到它们。今天的任务之一就是解决连续型变量怎么处理的问题。
对于连续特征,不能再根据连续属性的可取值对节点进行划分,而是应该使用取值范围进行划分。最简单的策略是二分法,即先将所有样本的取值排序,然后去两个样本取值的中点作为一个切分点,如有n个样本,则共计生成n-1个切分点。任选一个切分点,将样本按照小于切分点值和大于切分点值分为两部分去,计算划分后的信息增益,选取让信息增益最大的划分点作为最优切分点。
直接上代码操作:
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet, n): # n是连续性特征数,且在数据集中应排在前列
numFeatures = len(dataSet[0]) - 1 # 特征数
baseEntropy = calcShannonEnt(dataSet) # 数据集整体信息熵
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
if i < n:
conVal = True
else:
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) # 创建唯一的分类标签列表
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 计算每种方式的信息熵
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i # 计算最好的信息增益
if conVal:
return cal_information_gain_continuous(dataSet, i)
else:
return bestFeature
# 对于连续特征b,计算给定数据属性b的信息增益
def cal_information_gain_continuous(data, a):
n = len(data) # 共有n条数据,会产生n-1个划分点,选择信息增益最大的作为最优划分点
temp = []
for line in data:
temp.append(line[a])
Ent = calcShannonEnt(data) # 原始数据集的信息熵Ent(D)
select_points = []
data_left = []
data_right = []
for i in range(n-1):
val = int(float(temp[i]) + float(temp[i+1])) / 2 # 两个值中间取值为划分点
if float(temp[i]) < val:
data_left.append(data[i])
else:
data_right.append(data[i])
ent_left = calcShannonEnt(data_left)
ent_right = calcShannonEnt(data_right)
result = Ent - len(data_left)/n * ent_left - len(data_right)/n * ent_right
select_points.append([val, result])
divpoint = i
select_points.sort(key=lambda x: x[1], reverse=True) # 按照信息增益排序
return select_points[0][0], divpoint # 返回信息增益最大的点, 以及对应的下标# 创建树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList): # classList只剩下一种值
return classList[0]
if len(dataSet[0]) == 1: # dataSet中属性使用完毕,剩下一个类别标签
return majorityCnt(classList) # 取数量最多作为分类
bestFeat = chooseBestFeatureToSplit(dataSet, 2)
if isinstance(bestFeat, tuple):
bestFeatLabel = str(labels[bestFeat[0]]) + '小于' + str(bestFeat[1]) # 修改分叉点信息
midSeries = bestFeat[1] # 得到当前的划分点
bestFeat = bestFeat[0] # 得到下标值
else:
bestFeatLabel = labels[bestFeat] # 得到分叉点信息
myTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) # 去掉重复特征值
for value in uniqueVals:
subLabels = labels[:] # 剩余属性列表
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree只是对之前的部分代码做出了修改,现在可以将数据集前两列的连续值进行处理。
结果如下:

结果上看代码的效果仍旧不太好,由于数据过多但个属性类别鲜明使现在的树属性单一却复杂,接着继续解决这个问题。
剪枝:
创建决策树后会出现某些数据单独成一类的情况。这样执行分类时,很容易造成“过拟合”现象。即本身就不存在该类,但因为数据采集错误或标注错误等会使一个数据单独成类,这种情况下,有类似的错误样本进来时一定会分类成功;相反,真实的数据反而可能找不到属于自己的类别。
为了解决这类“过拟合”问题,有专家学者提出了剪枝策略。那怎么减呢?举个栗子:
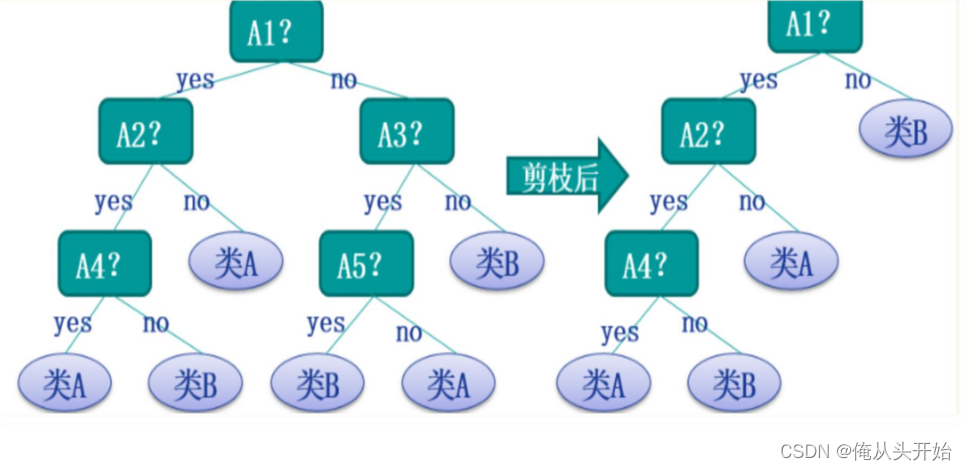
剪枝指的是剪去根部节点,换个词应该叫替换。因为你不能凭空的剪去某一部分。比如上面A4的左孩子类A,直接剪去会发生什么呢?如果分类为A4的Yes情况,机器将不知道该给出什么样子的分类结果。所以剪枝只能是直接将A4根节点替换为类A或是类B的一种。
那怎样验证一下剪枝之后的效果呢?或者说,你如何保证剪枝操作是有必要的。我们选择直接用数据说话,保留出一组验证集来计算剪枝前后的增益效果。效果好证明当前节点有必要进行剪枝。
预剪枝:
剪枝策略一般可以分为预剪枝和后剪枝两种,先看预剪枝。预剪枝是发生在树的创建过程中,创建树的同时以某种衡量指标确定是否要建立当前分支。
一般方法有下面几种:
1.当决策树达到预设的高度时就停止决策树的生长。
2.达到某个节点的实例具有相同的特征向量,即使这些实例不属于同一类,也可以停止决策树的生长。
3.定义一个阈值,当达到某个节点的实例个数小于阈值时就可以停止决策树的生长。
4.通过计算每次扩张对系统性能的增益,决定是否停止决策树的生长。
上述不足:阈值属于超参数,很难找到过拟合--欠拟合的tradeoff。
优缺点:
优点一是降低过拟合风险。二是显著减少训练时间和测试时间开销。
缺点主要是欠拟合风险:有些分支的当前划分虽然不能提升泛化性能,但在其基础上进行的后续划分却有可能显著提高性能。预剪枝基于“贪心”本质禁止这些分支展开,带来了欠拟合风险。
代码展示:
# 创建预剪枝决策树
def createTreePrePruning(dataTrain, labelTrain, dataTest, labelTest, names, method='id3'):、
trainData = np.asarray(dataTrain)
labelTrain = np.asarray(labelTrain)
testData = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labelTrain)) == 1:
return labelTrain[0]
# 如果没有待分类特征
elif trainData.size == 0:
return voteLabel(labelTrain)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(dataTrain, labelTrain, method=method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据最优特征进行分割
dataTrainSet, labelTrainSet = splitFeatureData(dataTrain, labelTrain, bestFeat)
# 预剪枝评估
# 划分前的分类标签
labelTrainLabelPre = voteLabel(labelTrain)
labelTrainRatioPre = equalNums(labelTrain, labelTrainLabelPre) / labelTrain.size
# 划分后的精度计算
if dataTest is not None:
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, bestFeat)
# 划分前的测试标签正确比例
labelTestRatioPre = equalNums(labelTest, labelTrainLabelPre) / labelTest.size
# 划分后 每个特征值的分类标签正确的数量
labelTrainEqNumPost = 0
for val in labelTrainSet.keys():
labelTrainEqNumPost += equalNums(labelTestSet.get(val), voteLabel(labelTrainSet.get(val))) + 0.0
# 划分后 正确的比例
labelTestRatioPost = labelTrainEqNumPost / labelTest.size
# 如果没有评估数据 但划分前的精度等于最小值0.5 则继续划分
if dataTest is None and labelTrainRatioPre == 0.5:
decisionTree = {bestFeatName: {}}
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue),
labelTrainSet.get(featValue)
, None, None, names, method)
elif dataTest is None:
return labelTrainLabelPre
# 如果划分后的精度相比划分前的精度下降, 则直接作为叶子节点返回
elif labelTestRatioPost < labelTestRatioPre:
return labelTrainLabelPre
else:
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue),
labelTrainSet.get(featValue)
, dataTestSet.get(featValue),
labelTestSet.get(featValue)
, names, method)
return decisionTree后剪枝:
先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行分析计算,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
图例:
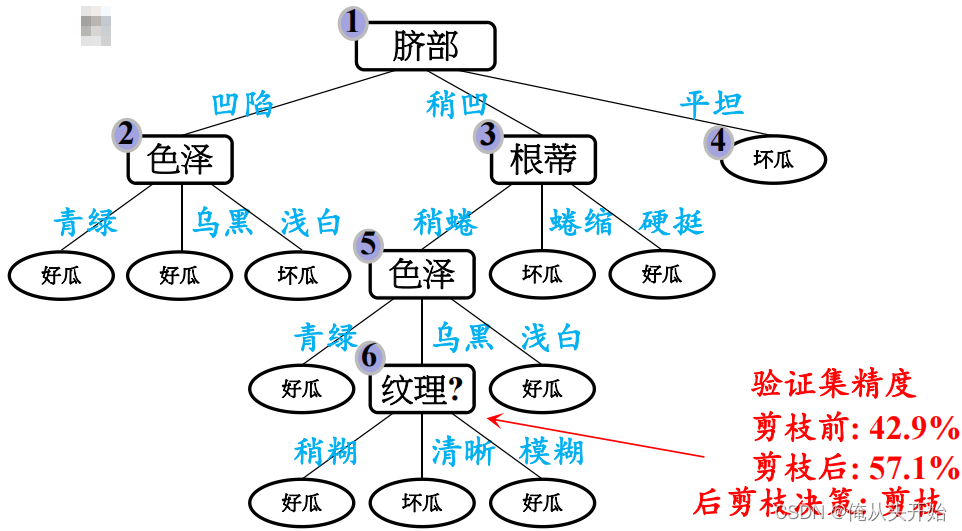
与预剪枝的区别在于:预剪枝策略是在创建树的时候剪枝,或者说创建树的时候不合适点就不去建;后剪枝是按照正常的步骤建造一棵树,然后再去评估剪枝。
优缺点:
优点是后剪枝比预剪枝保留了更多的分支,欠拟合风险小,泛化性能往往优于预剪枝决策树。
缺点是训练时间开销大:后剪枝过程是在生成完全决策树之后进行的,需要自底向上对所有非叶结点逐一计算。
代码如下:
def treePostPruning(labeledTree, dataTest, labelTest, names):
newTree = labeledTree.copy()
dataTest = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 取决策节点的名称 即特征的名称
featName = list(labeledTree.keys())[0]
# print("\n当前节点:" + featName)
# 取特征的列
featCol = np.argwhere(names == featName)[0][0]
names = np.delete(names, [featCol])
newTree[featName] = labeledTree[featName].copy()
featValueDict = newTree[featName]
featPreLabel = featValueDict.pop("_vpdl")
# print("当前节点预划分标签:" + featPreLabel)
# 是否为子树的标记
subTreeFlag = 0
# 分割测试数据 如果有数据 则进行测试或递归调用 np的array我不知道怎么判断是否None, 用is None是错的
dataFlag = 1 if sum(dataTest.shape) > 0 else 0
if dataFlag == 1:
# print("当前节点有划分数据!")
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, featCol)
for featValue in featValueDict.keys():
# print("当前节点属性 {0} 的子节点:{1}".format(featValue ,str(featValueDict[featValue])))
if dataFlag == 1 and type(featValueDict[featValue]) == dict:
subTreeFlag = 1
# 如果是子树则递归
newTree[featName][featValue] = treePostPruning(featValueDict[featValue], dataTestSet.get(featValue),
labelTestSet.get(featValue), names)
# 如果递归后为叶子 则后续进行评估
if type(featValueDict[featValue]) != dict:
subTreeFlag = 0
if dataFlag == 0 and type(featValueDict[featValue]) == dict:
subTreeFlag = 1
newTree[featName][featValue] = convertTree(featValueDict[featValue])
if subTreeFlag == 0:
ratioPreDivision = equalNums(labelTest, featPreLabel) / labelTest.size
equalNum = 0
for val in labelTestSet.keys():
equalNum += equalNums(labelTestSet[val], featValueDict[val])
ratioAfterDivision = equalNum / labelTest.size
if ratioAfterDivision < ratioPreDivision:
newTree = featPreLabel
return newTree















 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











