







回顾,上节课我们学了什么?
response=requests.get(url,params,headers)
response=requests.post(url,data,headers)
URL参数
UA伪装
F12抓包工具的爬取Ajax局部页面的请求
json数据格式的保存
前言:这篇文章是我第二次重写了,由于爬取了付费网站的图片教学,被官方版权警告,所以有一句名言说“爬虫爬的好,牢饭少不了”,大家使用爬虫千万要谨言慎行
目录
1.聚焦爬虫:爬取页面中指定的页面内容。
2.编码流程:
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
3.数据解析方式分类:
- 正则表达式正则表达式的语法汇总_神奇洋葱头的博客-CSDN博客_正则表达式 结束符
- bs4模块
- xpath模块
4.数据解析原理概述:
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储,列如图片在<img>标签中,列表数据在<li>标签中
-1.进行指定标签的定位
-2.标签或者标签对应的属性中存储的数据值进行提取(解析)
5.正则表达式 数据解析应用
1.获取一张图片
每个图片右击就会出现“复制图片地址选项”,将进入图片地址(即向该地址发送get请求)就能得到该图片。


因此回顾上节课内容,简单的爬取一张
#2.1
import requests # 指定图片网址url url = "http://tva3.sinaimg.cn/bmiddle/0085wA6egy1h4h85lyscxj30j60j6mzh.jpg" # UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0", } # 发起请求 r = requests.get(url=url, headers=headers) r_con=r.content#转化为二进制格式 图片 #持久化存储,os库读写文件 with open( "pic.jpg", "wb") as f:#wb二进制方式打开文件 f.write(r_con) f.close()
结果:

2.通过正则表达式爬取页面的所有图片
表情包网址:热门表情_发表情,表情包大全fabiaoqing.com
#正则匹配
import re
list=re.findall(pattern,string,flags)
list:匹配的字符串列表
pattern:正则表达式
string:匹配的字符串
flags:匹配模式- re.M :多行匹配
- re.S :单行匹配 如果分行则显示/n
- re.I : 忽略大小写
- re.sub(正则表达式, 替换内容, 字符串)当设置成re.S之后,可以简单理解为:. 可以匹配换行符,所以 . 可以匹配所有字符
(1)查看页面格式,找到图片标签
打开F12控制台管理器,通过鼠标移动点击标签找到图片的标签


(2)仔细分析图片标签特点,找到图片地址
可以看到这些图片的img的class标签一致,可以作为正则表达式的筛选条件
图片格式如下html
<a href="/biaoqing/detail/id/683557.html" title="假期来了鼠不尽的欢乐">
<img class="ui image lazy" data-original="http://tva3.sinaimg.cn/bmiddle/ceeb653ely8h6osu8twngg20fc0ejqby.gif" src="http://tva3.sinaimg.cn/bmiddle/ceeb653ely8h6osu8twngg20fc0ejqby.gif" title="假期来了鼠不尽的欢乐" alt="假期来了鼠不尽的欢乐" style="max-height: 188px; margin: 0px auto; display: block;">
</a>其中data-original描述的是图片地址,需要我们用正则表达式获取
开始:
#2.2
import requests import re import os #创建放图片的文件夹 if not os.path.exists("./picLib"): os.mkdir("./picLib") # 指定网址url url = "https://fabiaoqing.com/biaoqing" # UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0", } # 通用爬虫对页面提取 text = requests.get(url=url, headers=headers).text # 聚焦爬虫爬取img标签的图片 #正则表达式 ex='<img class="ui image lazy" data-original="(.*?)" src.*?</a>' pic_list=re.findall(ex,text,re.S) print(pic_list) for picurl in pic_list: #发起请求获取每一张图片 picdata=requests.get(picurl,headers).content#二进制 picname=picurl.split('/')[-1]#从后面切割遇到第一个/为止,作为图片名 picpath="./picLib/"+picname #保存图片 with open(picpath,'wb') as f: f.write(picdata) print("已保存"+picname)
结果:
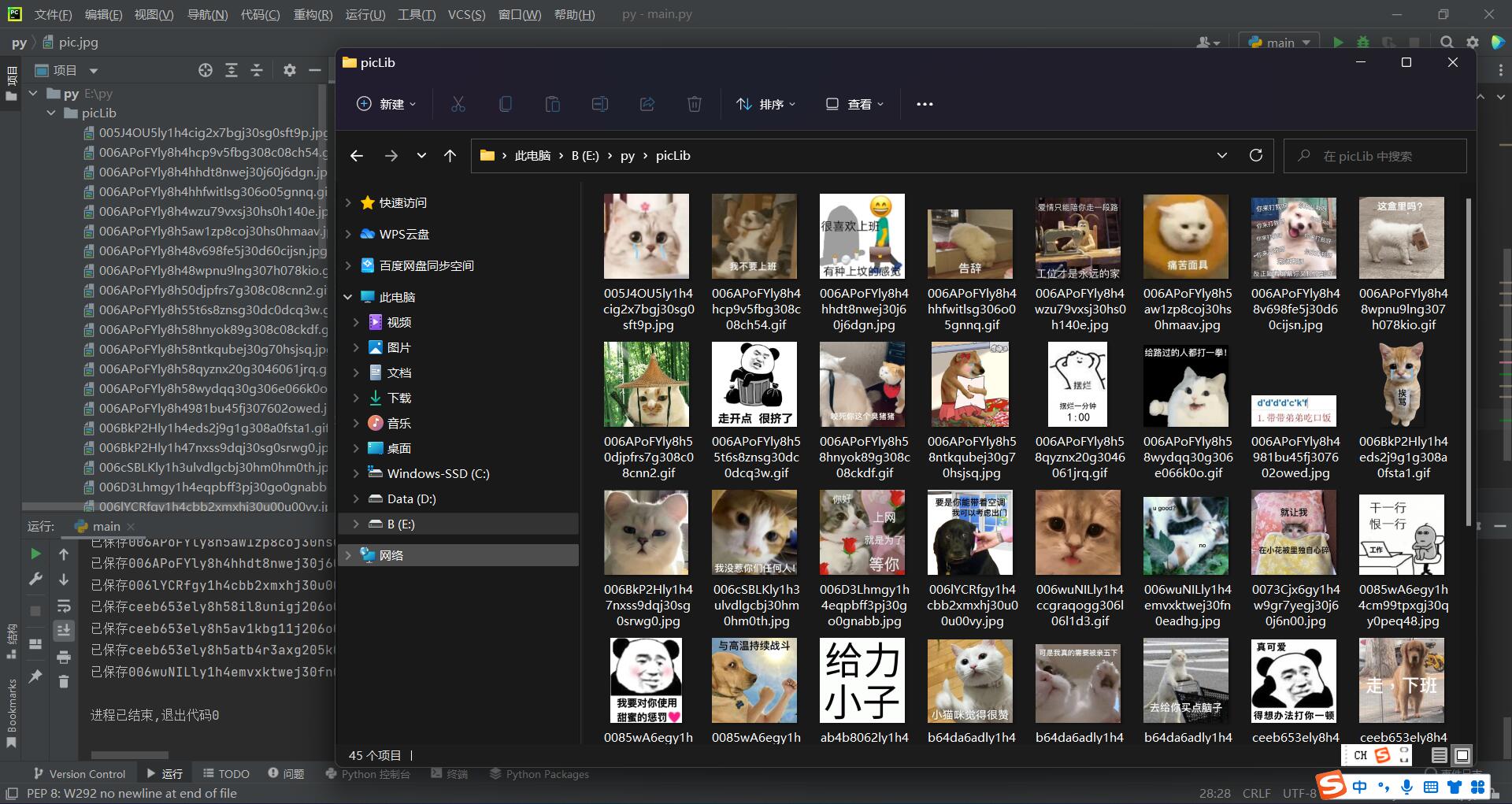
3.爬取可翻页网站的所有图片
上面案例只是爬取了首页的图片,针对于翻页,还需要继续补充
图库:热门表情_发表情,表情包大全fabiaoqing.com
(1)和上一个例子一样,查看图片的标签格式不再多叙
<a href="/biaoqing/detail/id/683557.html" title="假期来了鼠不尽的欢乐">
<img class="ui image lazy" data-original="http://tva3.sinaimg.cn/bmiddle/ceeb653ely8h6osu8twngg20fc0ejqby.gif" src="http://tva3.sinaimg.cn/bmiddle/ceeb653ely8h6osu8twngg20fc0ejqby.gif" title="假期来了鼠不尽的欢乐" alt="假期来了鼠不尽的欢乐" style="max-height: 188px; margin: 0px auto; display: block;">
</a>
(2)点击翻页,查看变化特点


发现仅仅是网址有规律的发生了改变,比较简单。如果在其他网站遇到网址.html之前的没有发生变化,但可以翻页,说明是局部页面刷新,需要通过上节课讲的F12抓包工具进行分析,找到翻页的Ajax请求,模拟发送翻页请求就行。
当然,这个网站不是局部页面刷新,仅仅是网址有规律变化,字符串拼接网址就行。
#2.3
import requests import re import os #创建放图片的文件夹 if not os.path.exists("./picLib"): os.mkdir("./picLib") star=eval(input("输入起始图片页:")) end=eval(input("输入终止图片页:")) piclists=[]#所有图片的地址集合 for i in range(star,end+1): # 指定网址url url = "https://fabiaoqing.com/biaoqing/lists/page/"+str(i)+".html" # UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0", } # 通用爬虫对页面提取 text = requests.get(url=url, headers=headers).text # 聚焦爬虫爬取img标签的图片 #正则表达式 ex='<img class="ui image lazy" data-original="(.*?)" src.*?</a>' pic_list=re.findall(ex,text,re.S) piclists+=pic_list for picurl in piclists: #发起请求获取每一张图片 picdata=requests.get(picurl,headers).content#二进制 picname=picurl.split('/')[-1].split("!")[0]#从后面切割遇到第一个/为止,再将!切去 picpath="./picLib/"+picname #保存图片 with open(picpath,'wb') as f: f.write(picdata) print("已保存"+picname) print(piclists) print("共抓取图片数量"+str(len(piclists)))
结果:

2到4页共抓取了135张图片
总结,这节课学了什么?
聚焦爬虫
数据解析方式分类:正则表达式;bs4模块;xpath模块
F12查看网页标签的html格式
正则表达式详细表示方法
正则匹配
import re
list=re.findall(pattern,string,flags)
创建文件夹
爬取和保存页面所有图片格式















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











