






- 索引概述
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足 特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构 上实现高级查找算法,这种数据结构就是索引。
- 索引特点
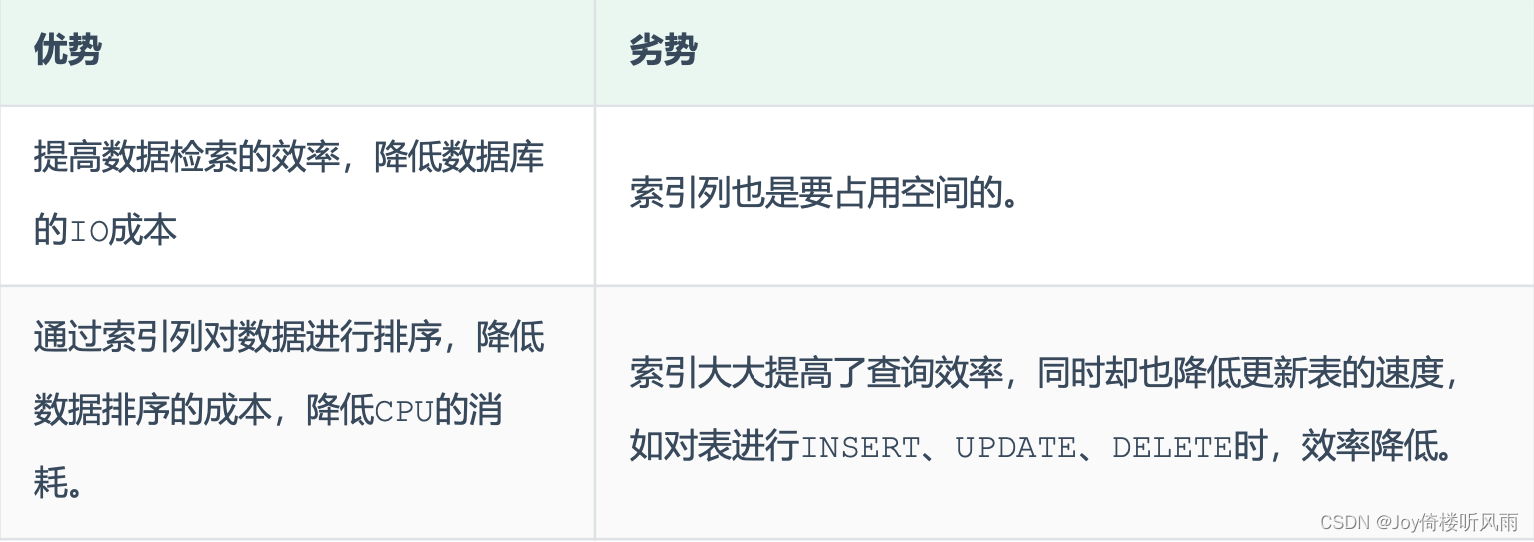
- 索引结构
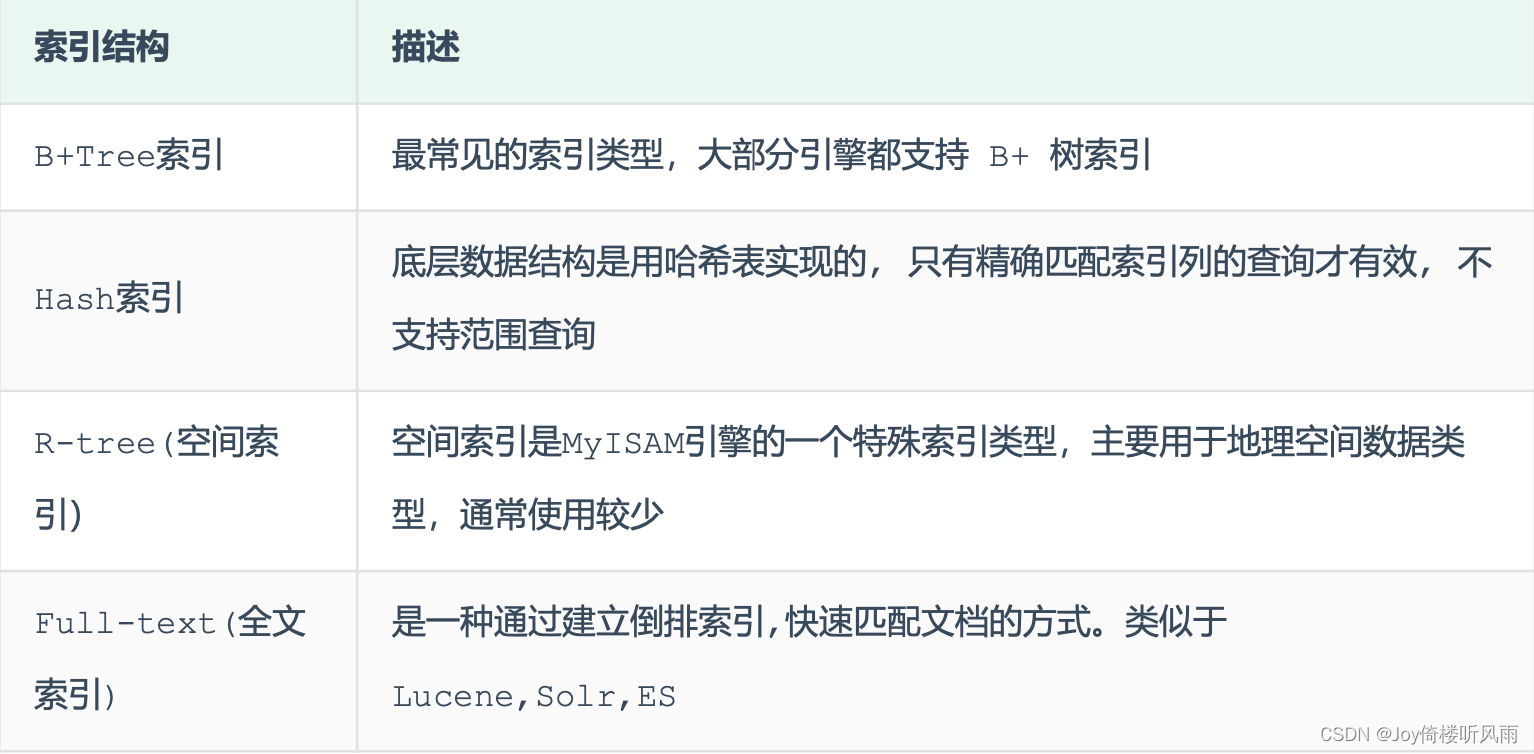
- 不同的存储引擎对于索引结构的支持 情况
- 二叉树的缺点:顺序插入时,会形成一个链表,查询性能大大降低,大数据量的情况下,层级较深,检索速度慢
- 红黑树缺点:大数据量的情况下,层级较深,检索速度慢
- B-Tree(多路平衡查找树)
- B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉
- B+Tree
- B+Tree 与 B-Tree相比,主要有以下三点区别:
- 所有的数据都会出现在叶子节点。
- 叶子节点形成一个单向链表。
- 非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的
- B+Tree 与 B-Tree相比,主要有以下三点区别:
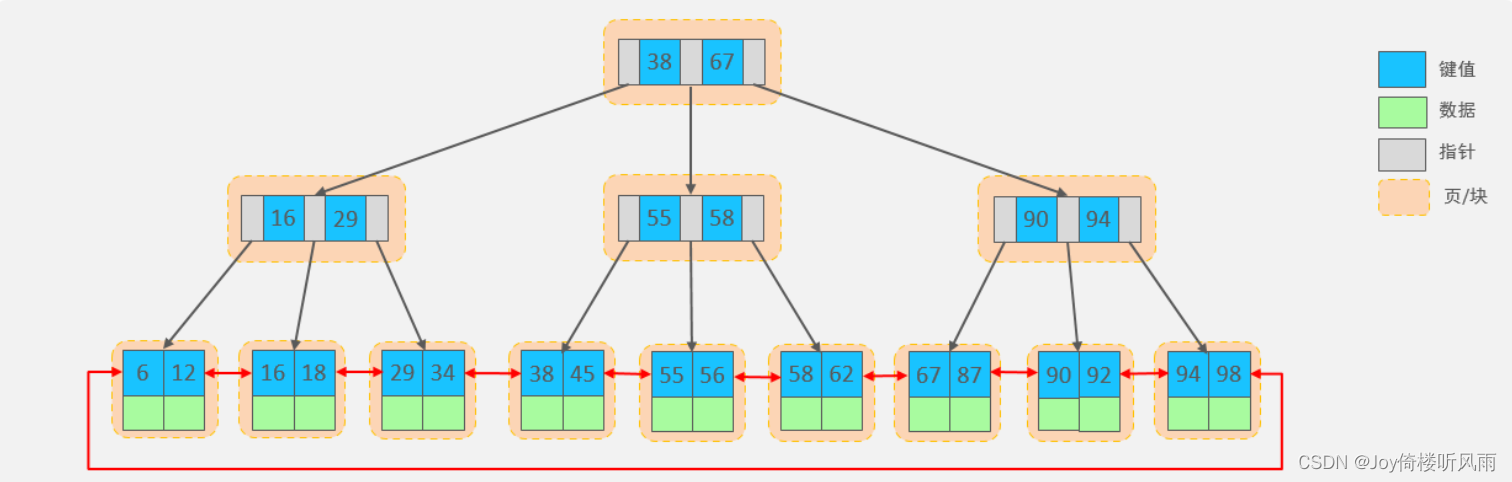
- MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点 的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
- Hash索引
- 哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在 hash表中。
- 特点:
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,...)
- 无法利用索引完成排序操作
- 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
- 存储引擎支持:
- 在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是 InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
- 索引分类
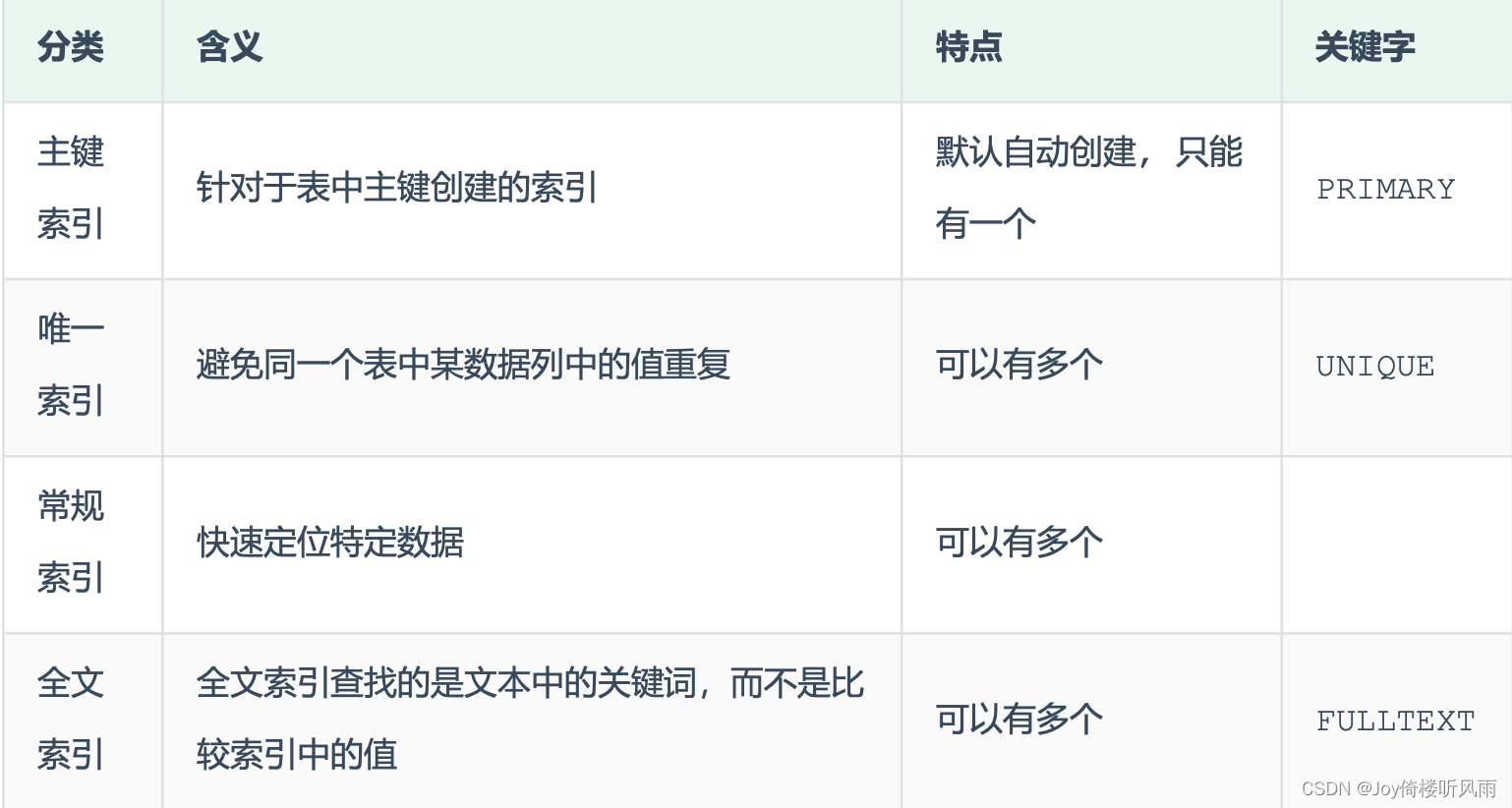
- 将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引
- 聚集索引&&二级索引
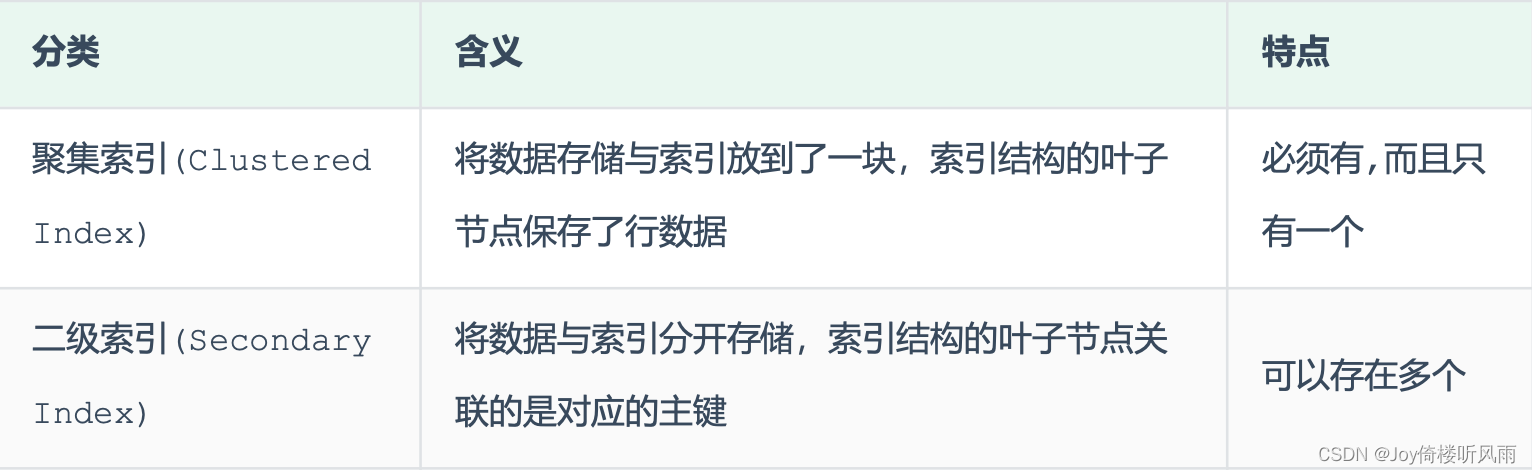
- 在InnoDB存储引擎中,根据索引的存储形式,分为:
- 聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
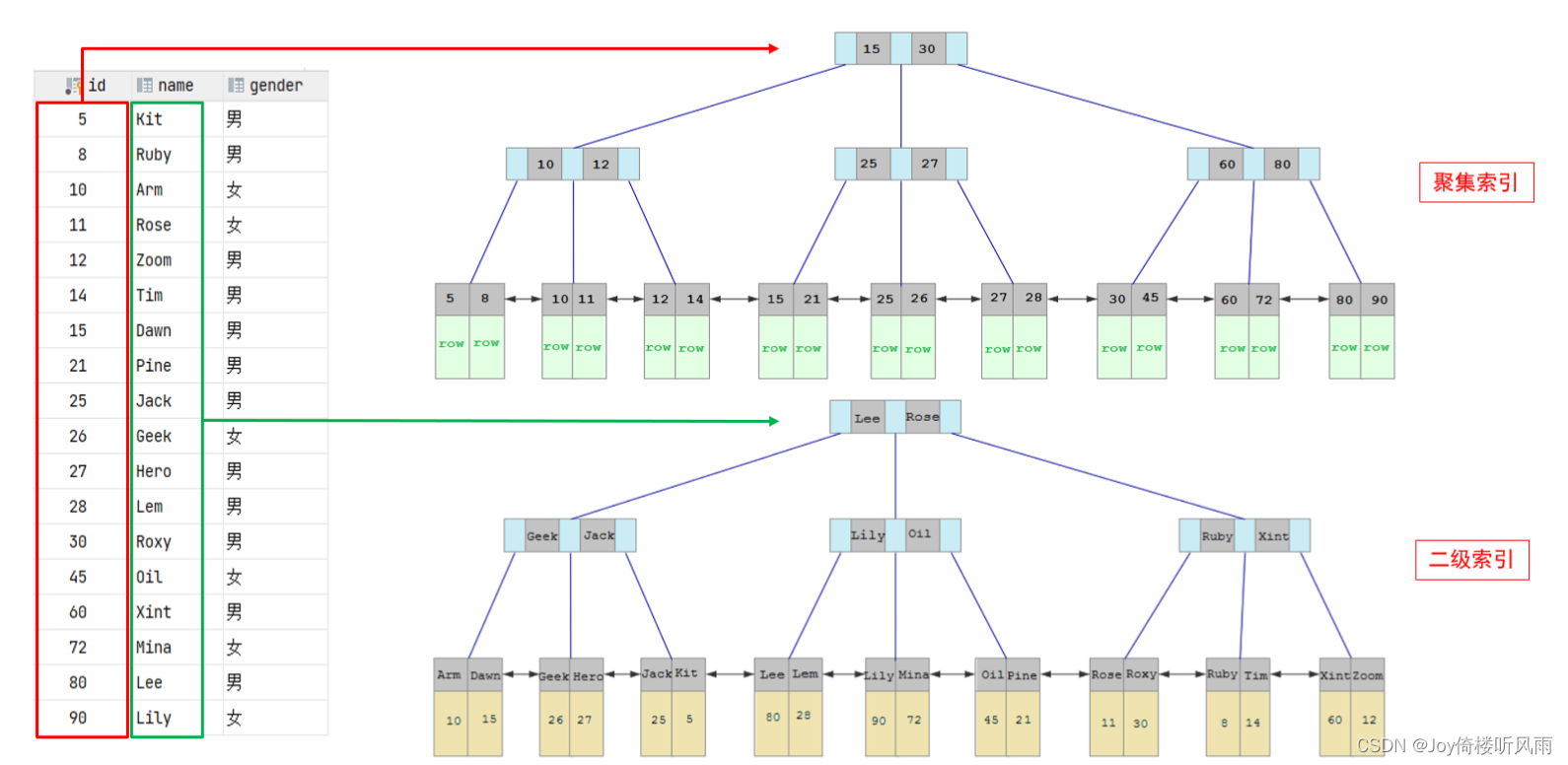
- 聚集索引和二级索引的具体结构如下:
-
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
- 回表查询
- 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取 数据的方式,就称之为回表查询。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









