






一、问题汇总
1. 计算机系统可以划分为那几个层次,各层次之间的界面是什么?你认为这样划分层次的意义何在?
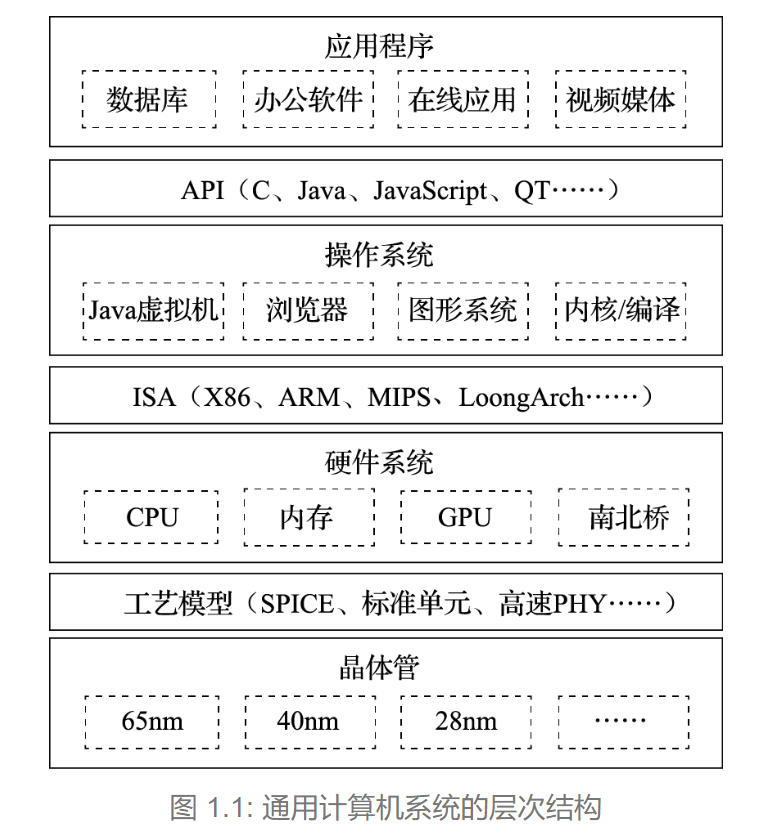
计算机系统可划分为四个层次,分别是:应用程序、 操作系统、 硬件系统、 晶体管四个大的层次。 注意把这四个层次联系起来的三个界面。各层次之间的界面如下:
第一个界面是 应用程序编程接口 API(Application Programming Interface), 也可以称作 “操作系统的指令系统”, 介于应用程序和操作系统之间。 API 是应用程序的高级语言编程接口, 在编写程序的源代码时使用。 常见的 API 包括 C 语言、 Fortran 语言、Java 语言、 JavaScript 语言接口以及 OpenGL图形编程接口等。 使用一种 API 编写的应用程序经重新编译后可以在支持该 API 的不同计算机上运行。 所有应用程序都是通过 AP编出来的, 在 IT 产业, 谁控制了 API 谁就控制了生态, API 做得好, APP(Application) 就多。 API 是建生态的起点。
第二个界面是指令系统 ISA(Instruction Set Architecture), 介于操作系统和硬件系统之间。 常见的指令系统包括 X86、ARM、 MIPS、 RISC-V 和 LoongArch 等。 由于 IT 产业的主要应用都是通过目标码的形态发布的,因此 ISA 是软件兼容的关键, 是生态建设的终点。 指令系统除了实现加减乘除等操作的指令外, 还包括系统状态的切换、 地址空间的安排、 寄存器的设置、 中断的传递等运行时环境的内容。
第三个界面是工艺模型, 介于硬件系统与晶体管之间。 工艺模型是芯片生产厂家提供给芯片设计者的界面, 除了表达晶体管和连线等基本参数的 SPICE(Simulation Program with Integrated Circuit Emphasis) 模型外, 该工艺所能提供的各种 IP 也非常重要, 如实现 PCIE 接口的物理层(简称 PHY) 等。
计算机系统划分为多个层次的意义在于:
提高代码和系统的可维护性:系统分层后,每个层次都有自己的定位和组件分工,使得系统结构更加清晰,维护起来更加明确和方便。
方便开发团队分工和开发效率的提升:有了层次的划分,开发人员可以专注于某一层的某一个模块的实现,从而提高开发效率。
提高系统的伸缩性和性能:系统分层之后,我们可以从逻辑上的分层变成物理上的分层。当系统并发量吞吐量上来了,可以将不同的层部署在不同服务器集群上,不同的组件放在不同的机器上,用多台机器去抗压力,从而提高系统的性能。压力大的时候扩展节点加机器,压力小的时候,压缩节点减机器,系统的伸缩性就是这么来的。
总的来说,通过分层,可以有效地将一个复杂的系统分解为更易于管理和理解的子系统,从而提高系统的效率和可维护性。
指令流水线
2. 流水线中的指令依赖关系
数据依赖(真依赖):指令之间有数据流动,一条指令需要使用前面另一条指令的结果,存在于寄存器或内存中。
名字依赖(假依赖):指令之间不存在数据流动,两条指令使用了相同的寄存器名字或者引用了相同的内存位置,可以用重命名技术消除。包含输出依赖(WAW:指令j试图在指令i写入结果之前就写入相应的寄存器或内存位置,从而导致错误的值被保存了下来)和反向依赖(WAR:指令j试图在指令i读取源操作数之前就写入相应寄存器或内存位置,从而导致指令i读取了更新的值)
控制依赖:指一条指令与分支指令之间存在的关系,一条指令需要根据前面另一条指令的结果进行判断是否执行。
3. RISC处理器的五阶段流水线
IF:取指令,发送PC到内存单元,取回下一条指令,PC+4
ID:指令解码,从寄存器中取操作数
EX:执行,对访存指令计算访存地址(基址寄存器+偏移量),对寄存器(r-r,r-i)运算指令进行计算
MEM:访存,对访存操作执行load/store操作(load:使用计算访存地址读取内存;store:数据写入计算访存地址)
WB:写回,对寄存器操作和load操作将结果写回寄存器
RISC如何流水化:每周期启动一条指令
| 指令 | 1 | 2 | 3 | 4 | 5 | 6 | ||
| instruction i | IF | ID | EX | MEM | WB | |||
| instruction i+1 | IF | ID | EX | MEM | WB | |||
| instruction i+2 | IF | ID | EX | MEM | WB | |||
| instruction i+3 | IF | ID | EX | MEM | WB |
4. 流水线上代码的指令周期计算
CPI:每条指令执行的周期数
CR:时钟频率
MIPS=CR/CPI:每秒执行的数百万条指令数
假设流水化前后时钟周期相同、流水线无开销:

–从公式看,增加流水线级数对提高性能有帮助,但增加流水级有几个负面影响:
• 会增加流水线控制开销所占的比例,导致功耗增加
• 会增加各种停顿的长度,拉低性能
–降低Ideal CPI和各种停顿,是提升性能的主要方向
5. 流水线的冲突及其解决方法
冲突分类:
资源冲突(structural hazard):硬件无法支持并发指令的各种可能组合产生的资源冲突,如功能部件端口不够或并未充分流水化。
数据冲突(data hazard):RAW(读取旧值错误,对应数据依赖)、WAW(保存前一个值错误,对应输出依赖)、WAR(读取新值错误,对应反向依赖),WAW/WAR冲突仅会在乱序执行流水线中出现。
控制冲突(control hazard):分支指令带来的PC取值的不确定性,从而导致计算PC耗费较长时间,导致停顿。
解决冲突的方法:
1、structural hazard:只能靠停顿来解决
2、data hazard:
(1)forwarding/bypassing:主要解决真依赖(RAW),通过抄近路的思想将产生的结果(非load产生)及时送到需要它的功能部件(ALU或者DM:lw),不是通过寄存器文件传递
实现要点:数据要前送回去;多路输入要有一个选通器;要有一个冲突检测电路来控制选通器
Load stall:无法通过前送完全消除的停顿(原因:产生结果太晚)
(2)计分板(scoreboarding)
(3)Tomasulo
3、control hazard:
(1)延迟槽(delayed slot):是为了消除分支指令引入的一个stall,编译器找到一条指令放入延迟槽,分支指令执行后必然执行延迟槽里面的指令
-
-
-
-
- 从前导指令中选择:将前面的指令复制到延迟槽,最佳策略
- 从目的地指令中选择:将目标指令复制到延迟槽,并修改跳转地址,适用于分支指令大部分情况下都跳转(taken)的情况
- 从后续指令中选择:适用于分支指令大部分情况下不跳转(no-taken)的情况
- 后面两种策略中,延迟槽指令都有可能不该执行但却被执行了,因此要求这条指令不能有副作用。同时,这两种策略要求编译器能够对分支指令跳转与否做出预测
-
-
-
(2)分支预测(Branch prediction):利用branch history table(BHT)对分支是否跳转进行判断预测(跳转是1,不跳转是0)
1位预测器:预测结果和上次实际结果一样,容易出现两个错误
2位预测器:利用两个bit位预测,错误优先翻转低位,产生一个错误
n位预测其和2位预测器预测准确度大致相同,资源浪费
6. 指令的非流水线实现
每条指令从取指(Instruction Fetch, IF)到写回(Write Back, WB)都在一个时钟周期内完成 (IF、ID、EX、MEM、WB)。
动态调度流水线和记分板算法
7. 什么是乱序执行
允许就绪指令(不存在资源冲突、操作数已经就绪的指令)越过前面的停顿指令,率先投入运行。
8. 计分板算法的原理和实例
| instruction | issue | read oprands | execuet | wb | 描述 |
| MUL.D F0,F6,F4 | 1 | 2 | 3,4,5 | 6 | |
| DSUB.D F8,F0,F2 | 2 | 7 | 8 | 9 | 从第三个周期开始等待MUL.D在第6周期末写回F0,类型是RAW |
| ADD.D F2,F10,F2 | 3 | 4 | 5 | 8 | 从第六周期开始等待DSUB.D在第7周期末读取操作数F2后写回F2,类型是WAR |
9. 流水线练习题
考虑以下代码片段:

假设 R3 的初始值是:R2+396
(1) 列出以上代码中的所有数据依赖。针对每个依赖,列出相关寄存器、源指令(即产生数据的指令)和目的指令(即消费数据的指令)。例如,源指令LD 到目的指令 DADDI 存在关于寄存器 R1 的依赖关系。
(2)使用和教材中图 C.5 类似的时序图,画出以上指令在 5-阶段 RISC 流水线中的执行时序。假设流水线没有实现前送逻辑(forwarding),寄存器文件可以在一个周期内完成一次读和一次写(参见图 C.6),跳转指令通过清空整条流水线来处理,访存操作只需一个周期即可完成。以上代码需要执行几个周期?
(3) 假设流水线实现了完善的前送逻辑,分支语句在 ID 阶段出结果,其它条件不变,重新画出以上指令在 5-阶段流水线中的执行时序,并计算整个代码序列需要执行几个周期?
答:
(1)
R1 LD DADDI
R1 DADDI SD
R2 DADDI DSUB
R4 DSUB BNEZ
(2)
| 指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| LD R1,0(R2) | IF | ID | EX | MEM | WB | |||||||||||||
| DADDI R1,R1,#1 | IF | s | s | ID | EX | MEM | WB | |||||||||||
| SD R1,0(R2) | IF | s | s | ID | EX | MEM | WB | |||||||||||
| DADDI R2,R2,#4 | IF | ID | EX | MEM | WB | |||||||||||||
| DSUB R4,R3,R2 | IF | s | s | ID | EX | MEM | WB | |||||||||||
| BNEZ R4,Loop | IF | s | s | ID | EX | MEM | WB | |||||||||||
| LD R1,0(R2) | IF | ID |
注:跳转指令要等EX阶段计算出结果后才执行下一条指令。
由题可知,R3初始值为R2+396,每周期R2+4,所以一共要进行99个周期。
由于后续周期都有重复的16个cycle,第一个周期一共18个cycle,所以以上代码执行98*16+18=1586个周期。
(3)由于加入了前送逻辑并且分支语句在ID阶段出结果:
| 指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| LD R1,0(R2) | IF | ID | EX | MEM | WB | |||||||||||||
| DADDI R1,R1,#1 | IF | ID | s | EX | MEM | WB | ||||||||||||
| SD R1,0(R2) | IF | s | ID | EX | MEM | WB | ||||||||||||
| DADDI R2,R2,#4 | IF | ID | EX | MEM | WB | |||||||||||||
| DSUB R4,R3,R2 | IF | ID | EX | MEM | WB | |||||||||||||
| BNEZ R4,Loop | IF | s | ID | EX | MEM | WB | ||||||||||||
| incorrect instruction | IF | s | s | s | s | |||||||||||||
| LD R1,0(R2) | IF | ID | EX |
98*9+12=894个周期。
10. 分支指令练习题
假设分支指令占全部指令的比例如下:
条件跳转:15%
无条件跳转:2%
并假设,条件跳转指令中,60%发生了跳转。
(1)假设有一条4阶段流水线,其中,无条件跳转指令在第二个周期的未尾执行完毕,条件跳转指令在第三个周期的末尾执行完毕,同时只有第一阶段不受分支指令目的地址的影响,也不存在其它因素造成的停顿。请分析,对于这样一条流水线,如果完全消除控制冲突,它能够加速多少?
(2)假设有另一条 15 阶段的高性能流水线,其中,无条件跳转指令在第五个周期的末尾执行完毕,条件跳转指令在第十个周期的末尾执行完毕,其它条件不变,请分析,对于这样一条流水线,如果完全消除控制冲突,它能加速多少?
答:
(1)speedup=pipeline depth/(ideal cpi+pipeline stalls)
理想情况下加速比:4/(1+0)=4
实际加速比:
无跳转指令(call)在第二个周期末执行完毕,引入一个周期stall;条件跳转中发生跳转的指令(taken condition)在第三个周期末执行完毕,引入两个周期stall;条件跳转中未发生跳转的指令(untaken condition)引入一个周期stall;
根据分支指令的各种比例:call:2%;taken contidion:15%*60%=9%;untaken condition:15%*40%=6%
实际引入的stalls:2%*1+9%*2+6%*1=0.26
实际加速比:4/(1+0.26)=3.17
所以如果完全消除控制冲突,实际加速:4/3.17=1.26
所以能够加速26%
(2)理想加速比:15/(1+0)=15
实际引入的stalls:4*2%+9*9%+8*6%=1.37
实际加速比:15/(1+1.37)=6.33
所以如果完全消除控制冲突,实际加速:2.37
所以能够加速137%
11. 计分板练习题
假设有一台采用计分板算法的计算机。考虑以下代码序列:
MUL.D F0,F6,F4
DSUB.D F8,F0,F2
ADD.D F2,F10, F2
假设 MUL.D 的 Execute 阶段需要三个周期,DSUB.D 和 ADD.D 的 Execute 需要一个周期,其它阶段都只需要一个周期。同时假设处理器有2 个乘法部件,2个加法部件。
(1)假设 MUL.D 指令在第一个周期完成了发射,请在下表中标出每条指令的每个阶段的执行周期数(一直标到出现首个停顿为止)。
| instruction | issue | read oprands | execuet | wb | 描述 |
| MUL.D F0,F6,F4 | 1 | 2 | 3,4,5 | 6 | |
| DSUB.D F8,F0,F2 | 2 | 7 | 8 | 9 | 从第3周期开始等待第6周期末MUL.D写回F0,RAW类型,在第7周期读取操作数F0 |
| ADD.D F2,F10,F2 | 3 | 4 | 5 | 8 | 从第6周期开始等待第7周期末DSUB.D读取F2,WAR类型,在第8周期写回F2 |
(2)对于停顿的指令,在对应的列上标出它是从哪个周期开始等待的,并在说明栏中说明冲突的类型,和它在等待哪条指令。
(3)对于停顿的指令,在对应的列上标出它是在哪个周期执行完毕的,并在说明栏说明是什么事件恢复了停顿指令的执行。
(4)重复 2)、3),直到将整个表格填写完毕。
12. 周期计算练习题
假设有一台非流水化的计算机,它的时钟周期是 7ns。在将它改造成 5-阶段流水线计算机后,各阶段的执行时间分别是:IF:1ns;ID:1.5ns;EX:1ns;MEM:2ns;WB:1.5ns,同时流水线寄存器引入的延时为 0.1ns。
1)改进后计算机的时钟周期是多少 ns?
2)假如每 4条指令有一个停顿,改进后计算机的 CPI是多少?
3) 改进后的计算机,加速比有多少?
答:
(1)2ns+0.1ns=2.1ns
(2)一共五个周期,四条指令,CPI=5/4=1.25
(3)程序的执行时间=IC(指令数)*CPI*Clocktime
所以加速比为IC*1*7/IC*1.25*2.1=2.67
高速缓存一致性
13. Cache的工作原理
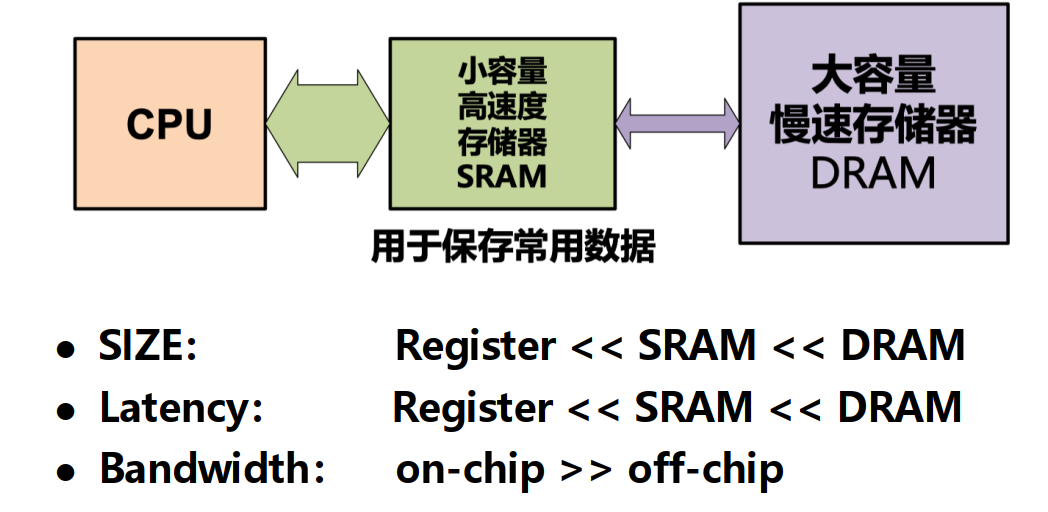
(1)策略:使用小容量、高速存储器作为cache,降低平均访存延迟
(2)cache是一种减少访存延迟的机制,它基于经验观察,即处理器进行的内存访问模式通常是高度可预测的
两种可预测的模式:
(1)时间局部性:保持最近访问的数据项最接近微处理器(如果一个地址被访问过,在不久的将来很可能还会被访问)
(2)空间局部性:以由地址连续的若干个字构成的块为单位,从底层复制到上一层(如果一个地址被访问过,在不久的将来该地址的临近地址很可能会被访问)
cache和主存数据映射方式:直接映射、全相联、组相联
14. 什么是缓存一致性问题
cache一致性问题:多个处理器或核心之间共享数据时,由于Cache的存在,可能导致不同处理器对同一块内存数据的缓存内容不一致的情况
15. 实现监听一致性协议的两种策略
-
- Write Invalidate(写作废策略) :一写就作废,当一个处理器更新某共享单元(如存储行或存储页)时(之前或之后),通过某种机制(发送一个无效信号 )使该共享单元的其它备份作废无效;当其它处理器访问该共享单元时,访问失效,需要重新从主存中读取该单元的新值,常配合write back策略
- Write Update(写更新策略) :当一个处理器更新某共享单元时,把更新的内容传播给所有拥有该共享单元备份的处理器
16. MSI协议问题
(1)根据一致性协议对处理器缓存的状态和值进行跟踪计算MSI协议(3种状态I/S/M)
假设在一个双CPU多处理器系统中,两个CPU用单总线连接,并目采用监听一致性协议(MSl),cache的初始状态均为无效,然后两个PU对内存中同一块数据进行如下操作:CPU A读、CPU A写、CPU B写、CPU A读,写出每次访问后两个CPU各自的cache的状态变化,并简述过程~
| 事件 | A状态 | B状态 |
| 初始状态 | I | I |
| CPU A读 | S | I |
| CPU A写 | M | I |
| CPU B写 | I | M |
| CPU A读 | S | S |
(2)MSI目录协议例题(第三次作业)
虚拟内存
17. 虚拟内存的基础机制
-
- 非直接寻址
- 每个应用进程都使用虚拟地址(linear address),不直接使用物理内存地址
- 构建一个地址转换机制来把虚拟地址映射为物理地址(real address),映射机制可以是纯软的也可以是软硬结合的
18. 虚拟内存中页、页表和TLB的概念
页: 虚拟内存和物理内存都被划分成大小相等的固定大小的块,这些块在虚拟内存中称为页(Page),在物理内存中称为页框(Frame)。
- 页的划分使得虚拟地址和物理地址可以通过简单的映射关系进行转换。
- 页的大小通常是操作系统定义的一个固定值,例如 4KB 或 8KB。
- 虚拟地址通常分为两部分:
-
- 页号(Page Number): 标识虚拟地址属于哪一页。
- 页内偏移量(Offset): 标识虚拟地址在页内的位置。
页表: 页表是存储虚拟地址与物理地址映射关系的一个数据结构。 每个进程都有一个自己的页表,操作系统通过它将虚拟地址映射到实际的物理地址。
页表条目(PTE, Page Table Entry)包含的信息:
-
- 物理页框号(Frame Number): 对应的物理内存位置。
- 标志位: 如有效位(Valid Bit)、读写权限位(R/W Bit)等。
多级页表:
-
- 为了降低页表占用的空间,现代系统通常使用多级页表,例如二级页表、三级页表,甚至四级页表。
- 每一级页表将虚拟地址进一步分段,用于减少内存中同时驻留的页表大小。
TLB: TLB 是一种小型的硬件高速缓存,用于加速虚拟地址到物理地址的转换。
-
- 在地址转换过程中,如果 TLB 中命中(即找到对应的页表条目),则可以直接得到物理地址,避免访问主存中的页表,提高效率。如果未命中(TLB Miss),则需要查找页表,将结果加载到 TLB。
19. 根据给定的处理器位数、页大小和页表项大小,计算线性页表模型中的页表大小
32位处理器、32-bit 地址:
每页Page Size :4 KB
每个页表项PTE:4-byte
共有 2^20 PTEs,每个用户进程的页表4MB
为备份全部虚拟地址空间,需要4GB 的swap存储空间;
计算过程:
处理器为32bit地址,所以需要总内存空间为2^32bytes=4GB
每页大小为4KB=2^12bytes
所以一共需要的页数为2^32/2^12=2^20个,也就是2^20PTEs(页表项)
因为每个页表项大小是4byte
所以每个用户进行的页表大小为4*2^20=4MB
如果是64位处理器,虚拟地址64 bits:
每页Page Size :4KB
每个页表项PTE:4-byte PTEs
页的数量是:?
每个用户的页表大小:?Byte,可以换算成TB、GB、MB等单位
计算过程:
同上文计算一样:
一共需要虚拟内存大小为2^64byte,每页大小是2^12byte
所以页的数量(也就是页表项的数量为)2^64/2^12=2^52个
每个页表项大小为4byte,所以每个用户进程的页表大小为:2^52*4=2^54byte=16PB
20. 缺页异常及其处理方法
缺页异常:CPU把虚拟地址给MMU,MMU从页表里取PTE,物理内存中没有这一页,而是在硬盘里,会触发缺页异常,OS陷入中断处理。
处理方法:OS选一页进行换出(从物理内存选择一页放到磁盘中,腾位置),如果这一页在内存中被修改过,要注意写回(要将修改的内容更新到磁盘中);从磁盘中读入新页,更新PTE;OS回到原进程执行。
换出的算法:LRU、ARC等(了解)
21. TLB相关问题
(1)TLB的作用是什么?
(2)请阐述TLB、TLB失效例外、页表和Page Fault之间的关系
(3)现代计算机普遍买用页表层次化的方式,请解释原因
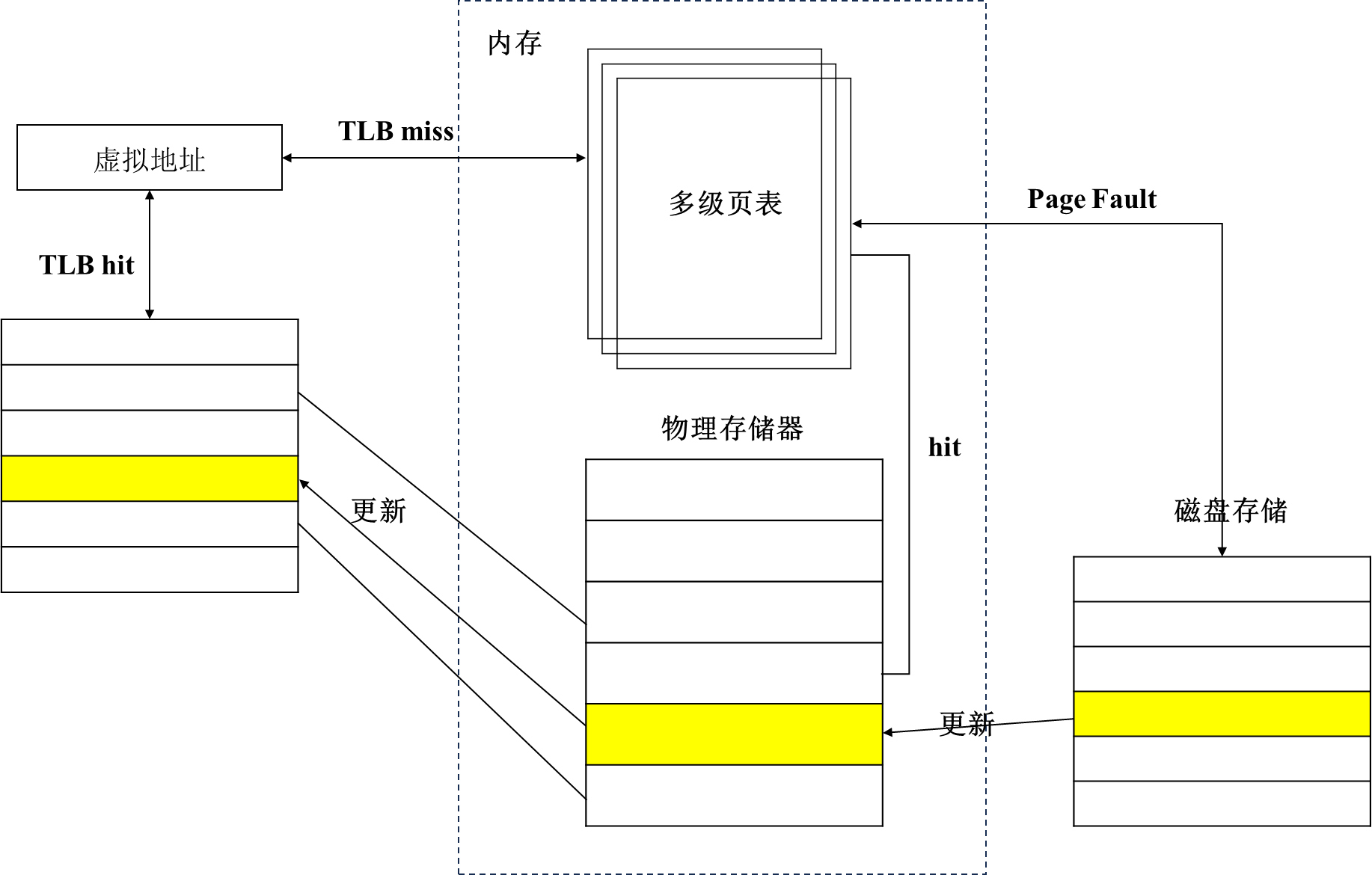
答:(1)在处理器中利用专用硬件来缓存PTEs,减少了虚拟地址与物理地址转换时访问内存的开销,利用空间局部性原理缓存最近最多使用的PTEs同时可以减少load/store访存的次数
TLB是指页表转换后援缓冲器(Translation Lookaside Buffer),与Cache原理类似,把常用的虚实地址转换表项缓存在TLB内部,可以加快虚地址到物理地址的转换速度,提高访存性能。
(2)四者关系可以简单理解为:
虚拟地址 --> TLB --> (TLB Miss) --> 页表 --> (缺页异常) --> 磁盘/存储介质
TLB:是存放虚拟地址与物理地址转换的高速缓存,存放页表的副本,用于减少地址转换的开销;
页表:存放于内存,用于虚拟地址与物理地址的转换;
当CPU访问虚拟地址时,先检查TLB是否保存转换关系:
如果命中,则直接返回物理地址,不需要访问内存;
如果没有命中,也就是TLB失效例外,到内存查询页表:
如果找到,返回物理地址,更新TLB;
如果没有找到,则发生Page Fault,说明物理内存不够,就需要访问磁盘,更新内存和TLB。
(3)原因:
-
- 减少内存消耗:单级页表对于大地址空间(如 64 位地址空间)来说,页表会非常大,占用大量内存。层次化页表通过分层次存储映射信息,减少了内存消耗。
- 提高查找效率:层次化页表将地址空间划分为多个较小的部分,每一层只需处理当前层次的部分地址,从而提高查找效率。
- 支持大页和小页:层次化页表可以灵活支持不同大小的页面,提高内存管理的灵活性和效率。
内存一致性
22. TSO相关问题
- 考虑一个多核处理器系统,采用 Total Store Order (TSO) 内存一致性模型。有两个处理器,处理器 A 和处理器 B,它们在共享变量 value 上进行读写操作。下面是两个处理器的执行序列
- 请回答以下问题:这两个处理器的执行序列中,是否存在可能导致 r3 不一致的情况?如果存在,请说明具体的情况。

答:在TSO模型中,load操作可以越过之后store操作,但不能越过之前的store操作。如果处理器B在处理器A的store操作完成之前完成了这两个load操作。由于处理器A的store操作的延迟,可能导致到处理器B读取到的value的旧值,从而导致r3不一致。
并行计算
23. 算力评估指标
Flops=【CPU核数】 *【单核主频】 *【CPU单个周期浮点计算能力】
– 以Intel Xeon 6348 CPU为例
– 28核,主频2.6GHz,支持AVX512指令集,且FMA系数=2
– CPU单周期单精度浮点计算能力=2(FMA数量) *2(同时加法和乘法)*512/32=64
– CPU单周期双精度浮点计算能力=2(FMA数量) *2(同时加法和乘法)*512/64=32
– 6348的单精度算力=28x2.6x64=4659Gflops=4.6Tflops
– 6348的双精度算力=28x2.6x32=2329Gflops=2.3Tflops
如何计算GPU的算力?
– Nvidia A100核心参数:
• CUDA cores: 6912个,加速频率: 1.41GHz
• GPU每核心单个周期浮点计算系数是2
➢A100的标准算力(FP32单精) =6912x1.41x2= 19491.84 Gflots=19.5Tflops
➢FP64双精算力= 19.5Tflops/2=9.7Tflops
向量处理器
24. 向量处理器的工作原理
一条向量指令可以同时处理N个或N对操作数(处理对象是向量)。
基本思想: 两个向量的对应分量进行运算,产生一个结果向量
简单的一条向量指令包含了多个操作 -> fewer instruction fetches
每一条结果独立于前面的结果
– 长流水线, 编译器保证操作间没有相关性
– 硬件仅需检测两条向量指令间的相关性,较高的时钟频率
向量指令以已知的模式访问存储器
– 可有效发挥多体交叉存储器的优势
– 仅使用指令Cache也可以提高系统的整体性能
25. 向量处理器的基本组成
(1)存储器型:所有的向量操作都是存储器到存储器;直接从内存中获取操作数和指令,启动时间很长
(2)寄存器型:除了Load和store操作外,所有的操作是向量寄存器与向量寄存器的操作;向量处理器的Load/Store结构
⚫ Vector Register: 固定长度的一块区域,存放单个向量– 至少2个读端口和1个写端口(一般最少16个读端口, 8个写端口)– 典型的有8-32个向量寄存器,每个寄存器长度为32、 64等
⚫ Vector Functional Units (FUs): 全流水化的,每一个clock启动一个新的操作– 一般4到8个FUs: FP add, FP mult, FP reciprocal (1/X), integer add, logical,shift;可能有些重复设置的部件
⚫ Vector Load-Store Units (LSUs): 全流水化地load或store一个向量,可能会配置多个LSU部件
⚫ Scalar registers: 存放单个元素用于标量处理或存储地址
⚫ 用交叉开关连接(Cross-bar) FUs, LSUs, registers
26. 向量处理器的典型应用场景
-
- 科学计算
- 例如矩阵运算、数值模拟、流体动力学等。
- 图像和多媒体处理
- 图像滤波、视频编码/解码等。
- 机器学习
- 神经网络推理与训练中的矩阵乘法加速。
- 加密和哈希运算
- 并行处理大量的数据块。
27. SIMD的概念和GPU体系结构
SIMD:单指令流多数据流,相同的指令作用在不同的数据
GPU体系结构:
-
- 大量并行计算单元
-
-
- GPU 的设计以大量小型计算核心为主,可以同时执行成千上万的线程,擅长处理数据并行任务。
- 相比 CPU 的少量高性能核心,GPU 更注重宽并行性(Wide Parallelism)。
-
-
- SIMT(Single Instruction, Multiple Threads)模型
-
-
- GPU 使用单指令多线程(SIMT)执行模型:
-
-
-
-
- 一条指令控制多个线程,并行处理多个数据。
- 每个线程可以访问不同的数据。
-
-
-
- 高内存带宽
-
-
- 为支持图形渲染和大规模并行计算,GPU 配备了高带宽的显存(如 GDDR、HBM),可以快速读写数据。
-
-
- 深度流水线
-
-
- GPU 内部通过流水线技术,将指令分解为多个阶段,同时执行多个指令,提高吞吐量。
-
-
- 线程分组与调度
-
-
- GPU 将线程组织成线程块(Thread Block)和网格(Grid),以便于高效管理和调度线程。
-
a. GPU 的硬件组成
- 流处理器(Streaming Processor, SP)
-
- GPU 的基本计算单元,相当于 CPU 的核心。
- 每个流处理器包含 ALU(算术逻辑单元)、寄存器等,支持浮点运算和整数运算。
- SM(Streaming Multiprocessor)
-
- 一个 SM 包含多个流处理器,以及共享的寄存器文件、共享内存等资源。
- 每个 SM 能同时调度和执行多个线程块。
- 显存(Global Memory)
-
- GPU 的主要存储单元,用于存储全局数据。
- 显存带宽高,但访问延迟相对较大。
- 共享内存(Shared Memory)
-
- 位于 SM 内部,线程块内部的线程可以快速共享数据。
- 共享内存访问速度比显存快,适合线程间协作。
- 寄存器文件(Register File)
-
- 每个线程都有自己的私有寄存器,用于存储局部变量。
- 纹理单元和渲染单元(主要用于图形渲染)
-
- 纹理单元:处理纹理映射操作。
- 渲染单元:负责光栅化和像素处理。
- 线程调度器
-
- 负责管理和调度 GPU 的大量线程,确保硬件资源的高效利用。
b. GPU 的编程模型
GPU 的编程通常采用并行编程框架,例如:
- CUDA(Compute Unified Device Architecture)
-
- 由 NVIDIA 提供,允许开发者使用 C/C++ 编写并行程序,直接控制 GPU 硬件。
- OpenCL(Open Computing Language)
-
- 开放标准,支持多种硬件平台(包括 GPU 和 CPU)。
- Vulkan 和 DirectCompute
-
- 面向图形和计算的 API,用于高性能应用开发。
c. GPU 的执行模型
- 线程组织
-
- GPU 的线程组织分为三层:
-
-
- 线程:最小的执行单位。
- 线程块(Thread Block):由多个线程组成,线程块内的线程可以通过共享内存协作。
- 网格(Grid):由多个线程块组成。
-
- Warp 执行
-
- GPU 将线程划分为 Warp(通常为 32 个线程),Warp 内的线程以 SIMD 模式并行执行。
- 指令调度
-
- 如果某些线程因数据依赖或内存访问而延迟,GPU 会调度其他线程执行,充分利用硬件资源。
28. 向量处理器深度流水化开销计算
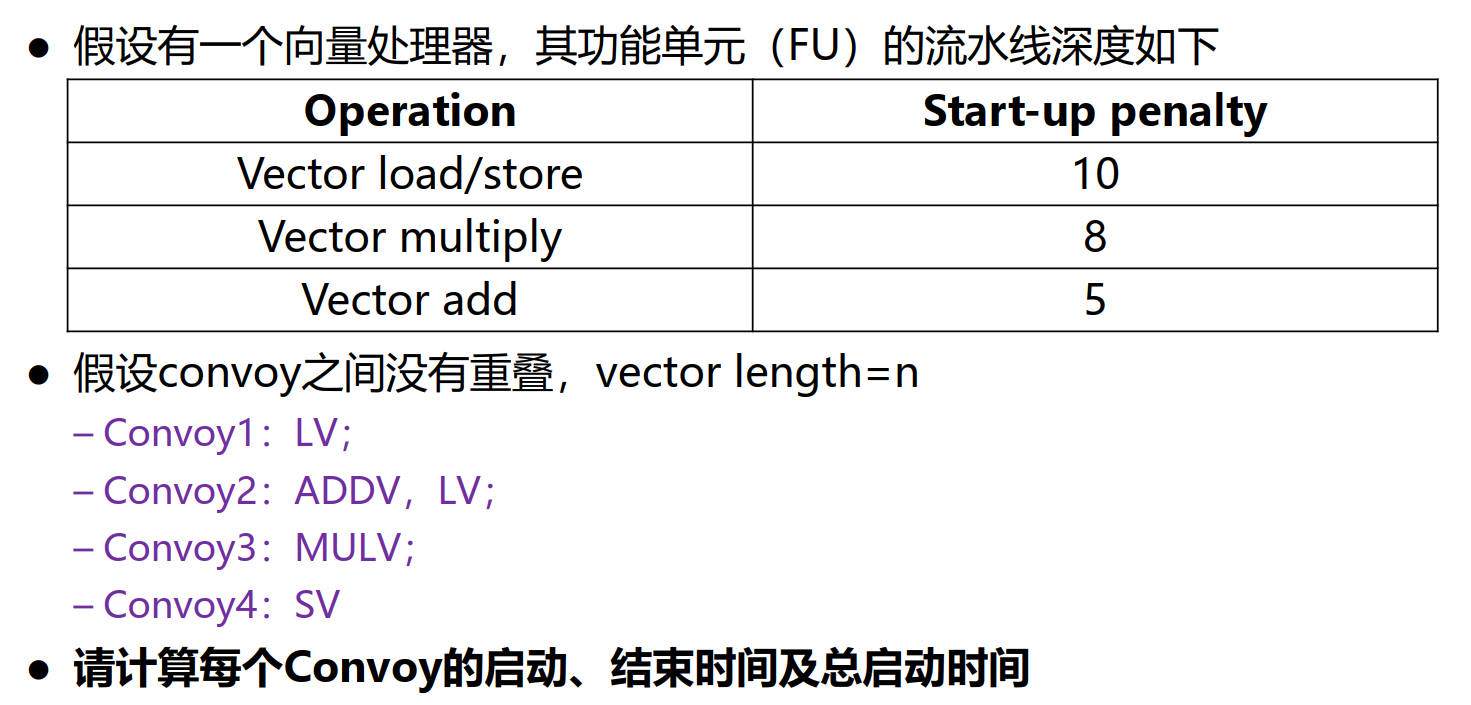
| Convoy | Start | 1st result | last result | 解释 |
| 0 | 10 | 9+n | load流水线深度为10,启动时间为10,往后n-1条向量并行执行 |
| 10+n | 15+n | 14+2n | add流水线深度为5 |
| 10+n | 20+n | 19+2n | load与add不重合,同时启动,启动事件不同 | |
| 20+2n | 28+2n | 27+3n | 以上一个convoy最长时间启动,启动时间为8 |
| 28+3n | 38+3n | 37+4n | store启动时间为10 |
29. SIMD处理器的GPU体系结构计算题
假定有一种包含10个 SIMD 处理器的 GPU 体系结构。每条 SIMD 指令的宽度为32,每个
SIMD 处理器包含8个车道(lane),用于执行单精度运算和载入/存储指令,也就是说,每个
非分岔 SIMD 指令每4个时钟周期可以生成32个结果。假定内核的分岔分支将导致平均80%
的线程为活动的。假定在所执行的全部 SIMD 指令中,70%为单精度运算、20%为载入/存
储。由于并不包含所有存储器延迟,所以假定 SIMD 指令平均发射率为0.85。假定 GPU 的
时钟速度为1.5 GHZ。
a.计算这个内核在这个GPU上的吞吐量,单位为GFLOP/S。
解答:由于每条SIMD指令宽度为32,每个SIMD包含8个lane,所以一个周期可以产生8个结果,每条SIMD执行完可以产生32个结果,需要4个周期
10*8*0.8*0.7*0.85*1.5GHZ=57.12GFLOP/S
b.假定我们有以下选项:
(1)将单精度车道数增大至16.
(2)将SIMD处理器数增大至15(假定这一改变不会影响所有其他性能度量,代码会扩展到
增加的处理器上)。
(3)添加缓存可以有效地将存储器延迟缩减40%,这样会将指令发射率增加至0.95,对
于这些改进中的每一项。
吞吐量的加速比为多少?
解答:
(1)每周期产生16个结果:
吞吐量:57.12*2=114.24
加速比为2
(2)处理器数量为15:
吞吐量:57.12*1.5=85.68
加速比为1.5
(3)指令发射率为0.95
吞吐量:57.12*(0.95/0.85)=63.84
加速比为1.12
硬件加速器
30. 什么是硬件加速器
硬件加速器是面向特定领域、针对有限算法定制设计的专用计算架构。其主要目的是提升特定计算的性能或减少功耗需求。在现代计算机体系结构中,随着通用处理器性能提升遇到瓶颈,硬件加速器应运而生,在如机器学习、图计算等领域发挥关键作用,通过定制化的硬件设计来高效执行特定算法,弥补通用处理器在某些任务上的不足,满足不断增长的计算需求。
31. 硬件加速器的两大类设计实现的方向
1. 设计专用集成电路(ASIC)
• ASIC 是最高效的
2. 基于可重构器件开发(如FPGA)
• 设计灵活,开发周期更短
• Xilinx和Altera
指令集与超长指令字
32. RISC和CISC执行时间
RISC的指令系统精简了, CISC中的一条指令可能由一串指令才能完成,那么为什么RISC执行程序的速度比CISC还要快?
程序的执行时间: ExecuteTime = CPI*IC*T
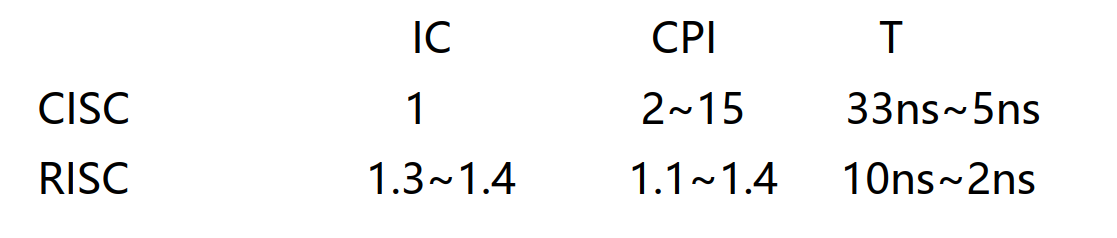
(1)根据给定的参数,计算CISC和RISC在最理想情况下的执行时间;
解答:CISC:1*2*5=10;RISC:1.3*1.1*2=2.86
(2) 比较CISC和RISC的执行时间,并解释为什么RISC的执行时间可能更短;
解答:
IC : 实际统计结果, RISC的IC只比CISC 长30%~40%
CPI: CISC CPI一般在4~6之间, RISC 一般CPI =1 , Load/Store 为2
T: RISC采用硬布线逻辑,指令要完成的功能比较简单
33. 超长指令字计算
假设一个 VLIW 处理器的指令包含五个操作, 每个时钟周期最多同时发射两个memory操作, 两个浮点(FP) 操作, 一个整型或者分支操作。 通过循环展开的形式来提升ILP, 假设展开循环7次, 使VLIW处理器没有任何stall(即完全空的事件周期),忽略分支延迟间隙。
(1) 请写出完整的VLIW处理器的调度过程,(2) 调度后的指令发射速率是多少? (3) 调度中使用的操作槽(slot) 的百分比是多少?

(1)
| M1 | M2 | FP1 | FP2 | Int/Branch |
| L.D F0,0(R1) | L.D F6,-8(R1) | |||
| L.D F10,-16(R1) | L.D F14,-24(R1) | |||
| L.D F18,-32(R1) | L.D F22,-40(R1) | ADD.D F4,F0,F2 | ADD.D F8,F6,F2 | |
| L.D F26,-48(R1) | ADD.D F12,F10,F2 | ADD.D F16,F14,F2 | ||
| ADD.D F20,F18,F2 | ADD.D F24,F22,F2 | |||
| S.D F4,0(R1) | S.D F8,-8(R1) | ADD.D F28,F26,F2 | ||
| S.D F12,-16(R1) | S.D F16,-24(R1) | |||
| S.D F20,-32(R1) | S.D F24,-40(R1) | |||
| S.D F28,-48(R1) | DADDUI R1,R1,#-56 | |||
| BNE R1,R2,Loop |
(2)10个cycle发射23条指令,发射速率为2.3
(3)使用槽百分比为23/50=46%
34. 提高指令级并行(ILP)的有效方法
– 流水线,多处理器,超标量处理器,超长指令字VLIW
片上网络
35. 列举片上网络的经典拓扑结构,并说明该结构的优缺点
1、总线 Bus:所有节点都连在一个连接上
优点:
-
- 简单
- 小规模下低成本
- 一致性保持成本低
缺点:
-
- 扩展性差
- 网络高竞争
2、点对点网络:每个节点都与其他节点相连
- 低竞争 、 低延迟
- 非常理想
-- 最高的成本
-- 扩展性差
-- 布线难度大
3、交叉开关 :每个节点均通过共享链路相连
优点:
不同目的地之间可并行传输
低延迟高吞吐
缺点:
-- 高成本
-- 扩展性差
-- 大规模仲裁困难
4、环
优点:
简单
低成本
缺点:
高延迟:0(N)
节点的增加分段带宽保持不变
5、网格
优点:低成本,易于片上部署、路由简单
缺点:延迟高、功耗高
6、树状网络:平面、分层拓扑结构
+适合本地流量
+ 廉价: O(N) 成本
+ 易于布局
-- 根可能成为瓶颈
36. 片上网络路由算法可分为哪几种类型?
(1)确定性路由:总是为通信源-目的地对选择相同的路径。
(2)流量无关路由:选择不同的路径,不考虑网络状态
(3)自适应路由:可以选择不同路径,适应网络状态。
37. 在自适应路由算法中,可采用哪几种方法避免网络死锁
死锁问题 (Deadlock):由资源的循环依赖引起,每个数据包等待一个由下游其他数据包占用的缓冲区,形成阻塞。网络中无法前进的状态,没有前向进展。
死锁的解决方案 (Handling Deadlock):
- 避免循环依赖
-
- 维度顺序路由:
规定数据包按照特定的维度顺序进行路由,避免在路径中形成循环依赖。例如,先路由 X 维度,再路由 Y 维度。 - 限制转向 :
分析数据包可能的转向方式,禁止部分转向以打破循环。例如,使用转向模型限制某些关键转向。
- 维度顺序路由:
- 增加缓冲
-
- 提供额外的缓冲区或设计逃逸路径 (Escape paths),以减少资源阻塞的可能性。
- 监测和打破死锁
-
- 死锁检测:通过监测网络状态识别死锁的发生。
- 抢占缓冲区:在死锁检测后,强制回收某些资源,例如抢占缓冲区,来打破死锁
虚拟化
38. 计算机虚拟技术
(1)简述Type-1和Type-2 Hypervisor的区别,可画简图
type 1 hypervisor:直接运行在硬件上,不需要宿主机操作系统

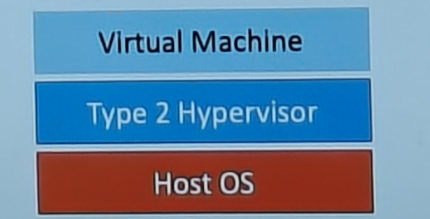
type 2 hypervisor:作为应用程序运行在宿主机操作系统之上
(2)简述虚拟机监控器技术和容器技术技术原理差异,可画简图
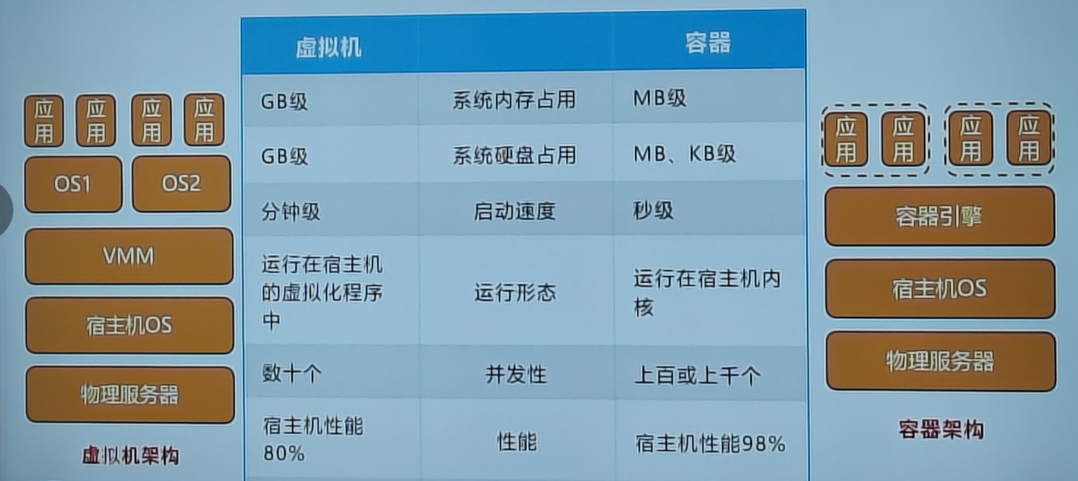
- Hypervisor 是一种运行在硬件或操作系统上的软件层,用于创建和管理虚拟机(VM)。每个虚拟机都有自己的完整操作系统实例,以及虚拟化的硬件资源(CPU、内存、存储、网络等)。
- 容器技术利用操作系统级虚拟化,通过共享主机操作系统内核来实现资源隔离和限制。容器中的应用运行在彼此隔离的用户空间,但共享底层的操作系统内核。
分布式系统
39. 分布式文件存储系统
对于如下分布式文件存储系统,回答问题:
1)chunk的位置是否需要持久化?
解答:不需要,因为master在重启的时候,可以从各个chunkserver处收集chunk的位置信息。
2)如果一个chunk大小64MB,元数据64B,每个文件独立存储三份,那么1TB数据对应的元数据大小是多少?
1TB的数据分成chunk存储,每个文件需要备份三份,每个chunk都需要元数据保存位置等信息
1TB*3/64MB*64B=3MB,所以对应的元数据是3MB。
二、存储相关内容
1. 典型存储系统层次结构
2. Cache的工作机制
(1)策略:使用小容量、高速存储器作为cache,降低平均访存延迟
(2)cache是一种减少访存延迟的机制,它基于经验观察,即处理器进行的内存访问模式通常是高度可预测的
两种可预测的模式:
(1)时间局部性:保持最近访问的数据项最接近微处理器(如果一个地址被访问过,在不久的将来很可能还会被访问)
(2)空间局部性:以由地址连续的若干个字构成的块为单位,从底层复制到上一层(如果一个地址被访问过,在不久的将来该地址的临近地址很可能会被访问)
cache和主存数据映射方式:直接映射、全相联、组相联
3. cache一致性
集中式共享存储结构
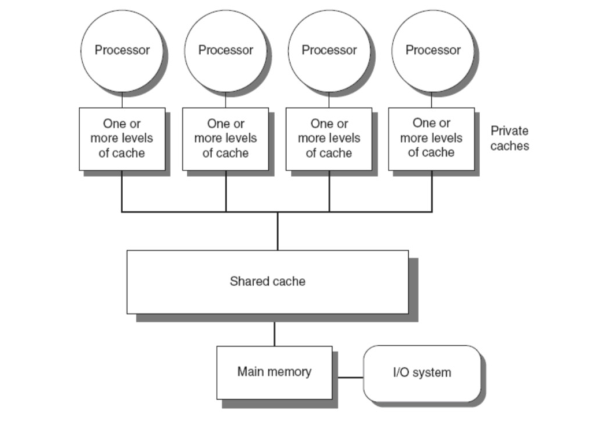
-
- 存储一致性:不同处理器发出的所有存储器操作的顺序问题,所有存储器访问的全序问题
- cache一致性:不同处理器访问相同存储单元时的访问顺序问题,访问每个Cache块的局部序问题
cache一致性问题:多个处理器或核心之间共享数据时,由于Cache的存在,可能导致不同处理器对同一块内存数据的缓存内容不一致的情况
cache写机制:
-
- Write-back:写回模式 :更新cache时,并不同步更新memory,只是在数据被替换出cache时,被修改的数据才更新到内存中
- Write-through:写直达模式 :CPU向cache写入数据时,同时向memory写一份,使得cache和memory的数据保持一致
- Write-miss:写失效 :所要写的数据的地址不在cache中
-
-
- no write allocate policy:将要写的内容直接写回memory;
- write allocate policy:将要写的地址所在的块先从memory调入cache中,然后写cache;
-
cache一致性协议:关键:跟踪共享数据块的状态
(1)基于监听的协议
两种策略:
-
-
- Write Invalidate(写作废策略) :一写就作废,当一个处理器更新某共享单元(如存储行或存储页)时(之前或之后),通过某种机制使该共享单元的其它备份作废无效;当其它处理器访问该共享单元时,访问失效,需要重新从主存中读取该单元的新值
- Write Update(写更新策略) :当一个处理器更新某共享单元时,把更新的内容传播给所有拥有该共享单元备份的处理器
-
协议:
-
-
- valid/invalid协议
- MSI协议
- MESI协议
-
(2)基于目录的协议
-
-
- MSI协议
-
三、内存一致性相关内容
缓存一致性(Cache Coherence)
– 缓存一致性关注共享存储系统中多个处理器对同一内存位置进行读写的情况
– 软件无需显式地管理私有缓存,这一切都由硬件来处理
内存一致性(Memory consistency)
– 定义:内存一致性模型定义了多处理器系统中的内存访问规则,以确保多个处理器在读写共享内存时能够获得一致的结果
– 内存一致性模型涉及到对多个内存位置的读写操作
顺序一致性模型(强定序模型):
–所有读写操作执行以某种顺序执行
–每一个处理器看到的操作顺序是相同的
完全存储定序模型(Total Store Order(TSO)) :
规则:
– 全局顺序存储: store操作存在一个全局的顺序
– Store缓冲: 允许处理器使用 Store buffer来缓存即将写入内存的数据,但必须确保缓冲中的数据在全局上有序提交
– load同样按顺序执行,但可穿插到多个store执行过程中
• 若存在一组store->load操作,如果由同一处理器执行且地址相关,则TSO允许该load操作在store操作完成之前就执行;但如果由多个core执行且地址相关,那TSO要求load指令在store执行完成后才能执行
四、多线程相关内容

流水线的平均CPI: Pipeline CPI = Ideal Pipeline CPI + Struct Stalls+ RAW Stalls + WAR Stalls + WAW Stalls + Control Stalls +Memory Stalls
CPI=Ideal CPI=1 :消除所有停顿(动态调度、分支预测和猜测执行等)
CPI<1:Superscalar(多发射处理器) 、 VLIW
多线程处理器基本思想:多线程应用可以用线程级并行来提高单个处理器的利用率
针对单个处理器: 多个线程一交叉重叠方式共享单个处理器的功能单元
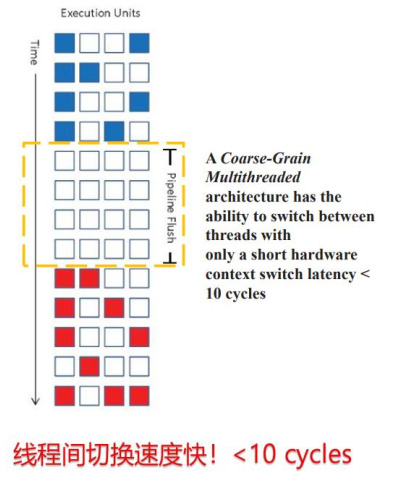
粗粒度多线程(CGMT):减少了时间维度(vertical)的浪费,但仍存在空间维度的浪费
细粒度多线程(FGMT):多个线程的指令交叉执行;线程切换的频率高、周期短。减少时间维度的浪费,当线程数足够多时,可消除时间维度的浪费,仍然存在空间维度的浪费
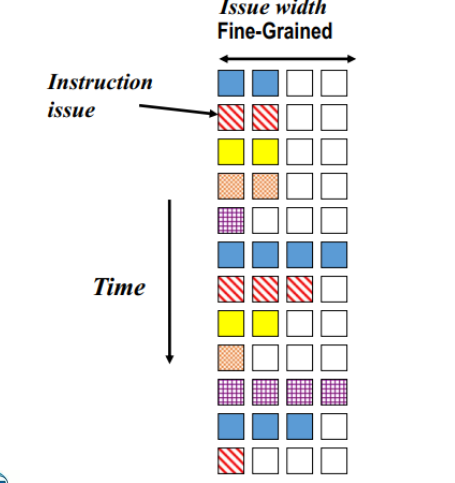
⚫ 细粒度多线程 – 每个周期在线程之间进行上下文切换,即使线程可以连续执行
⚫ 粗粒度多线程 – 每隔几个周期在线程之间进行一次上下文切换,隐藏较长的stall
同步多线程(SMT): 使用OoO Superscalar细粒度控制技术在相同时钟周期运行多个线程的指令,以更好的利用系统资源

五、并行计算相关内容
高性能计算机(HPC)算力评估指标:
⚫ 如何计算CPU的算力?– 除了与CPU的核心数目、主频以外,是否还有其他因素?
⚫ Flops=【CPU核数】 *【单核主频】 *【CPU单个周期浮点计算能力】
– 以Intel Xeon 6348 CPU为例
– 28核,主频2.6GHz,支持AVX512指令集,且FMA系数=2
六、向量处理器相关内容
向量执行时间

– 如果每个向量长度为n, 那么m个convoys 所花费的时间是m个chimes
– 每个chime所花费的时间是n个clocks,该程序所花费的总时间大约为 m*n clockcycles (忽略额外开销;当向量长度较长时这种近似是合理的)
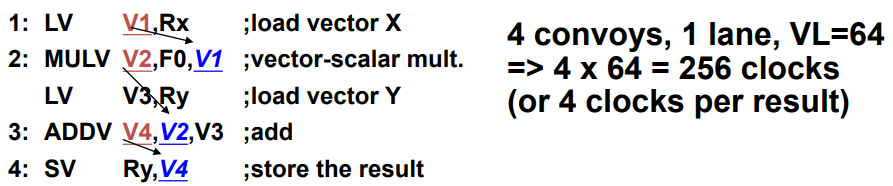
提高指令级并行(ILP)的有效方法
– 流水线,多处理器,超标量处理器,超长指令字VLIW

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









