






MapReduce程序模块
案例需求需要实现的是将网站登录日志的数据并统计每天的访问次数。
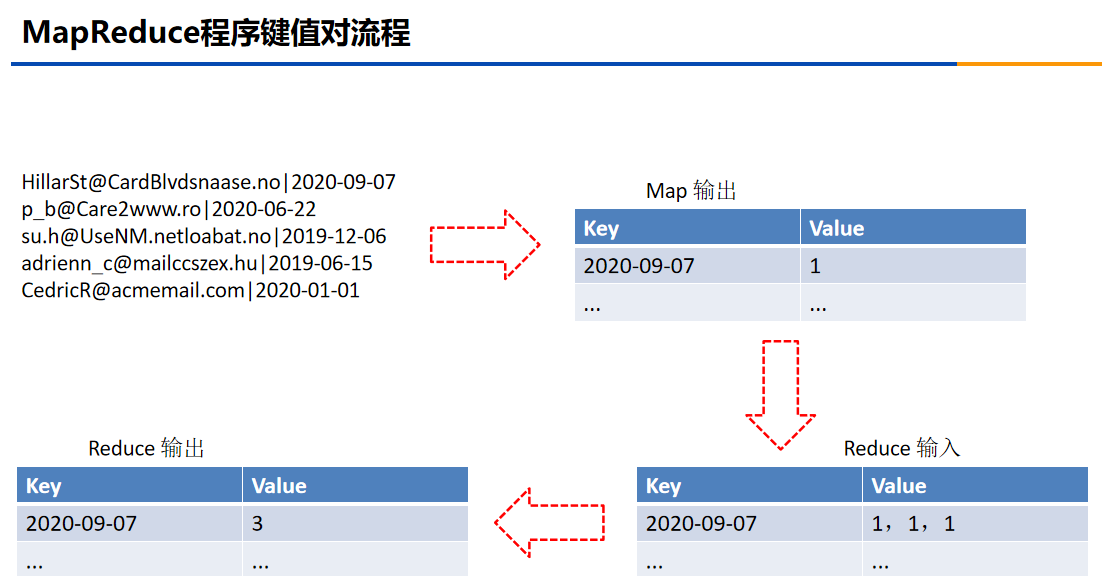
本次案例的键值对的流程:
本次的案例使用了Intellij IDEA软件创建MAVEN项目。下载网址:
Download IntelliJ IDEA: The Capable & Ergonomic Java IDE by JetBrains
以下就是MapReduce案例2_Countbydate的实现流程。
1,创建MAVEN项目
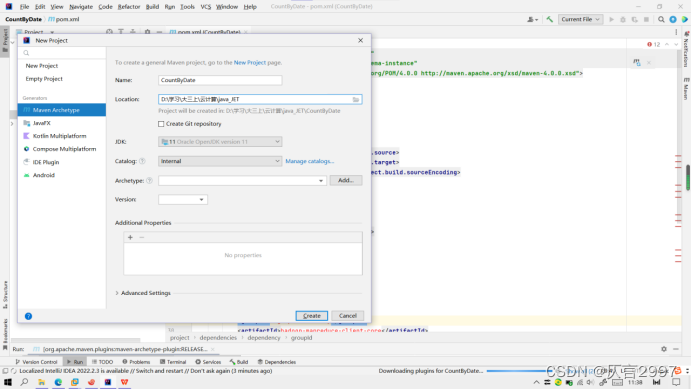
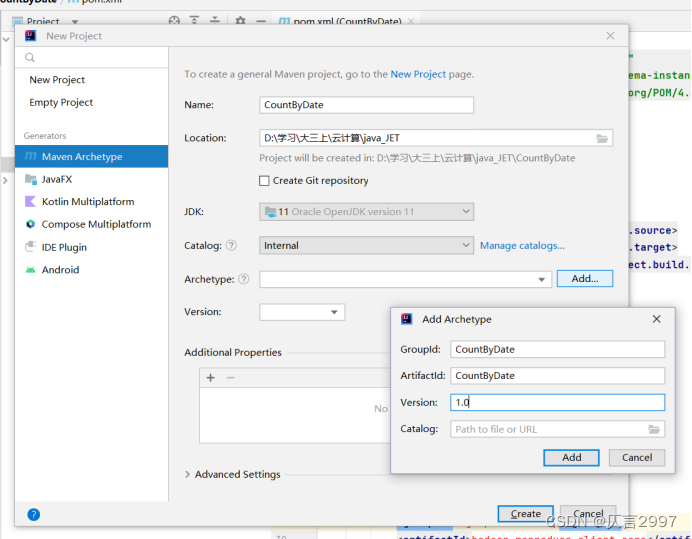
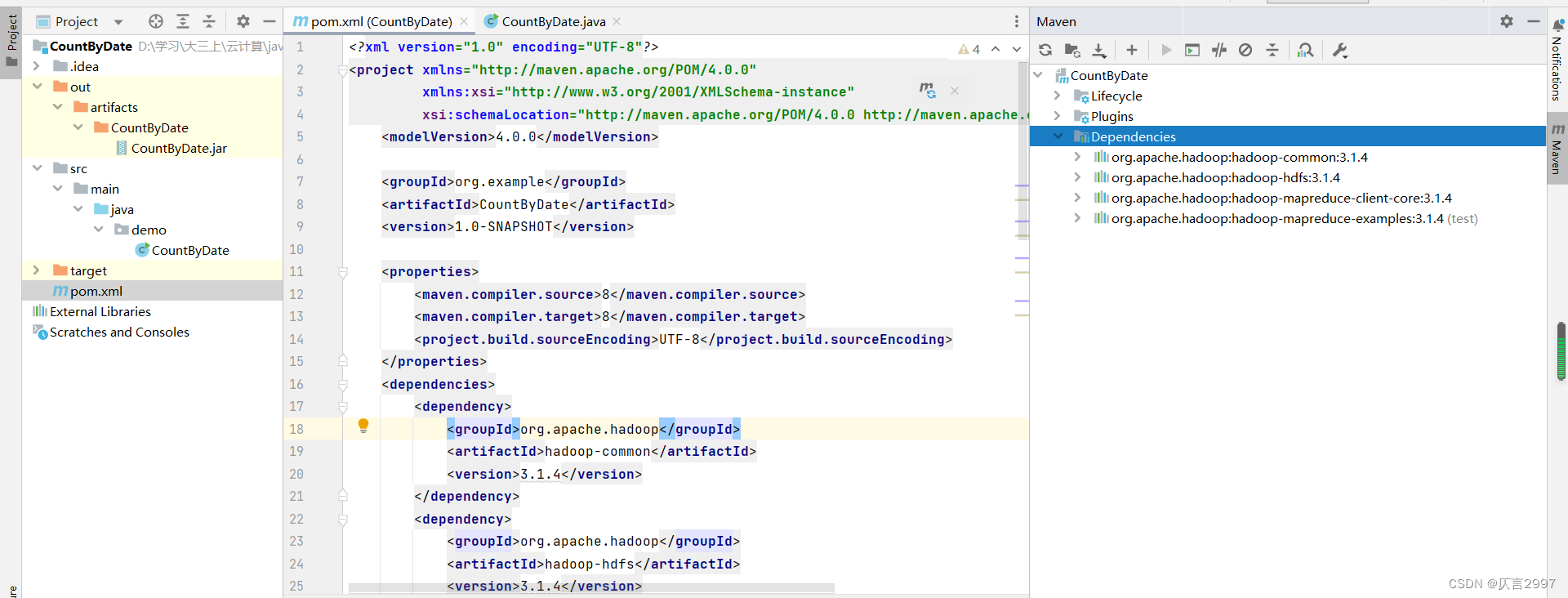
2,修改pom.xml,添加dependencies
将以下代码添加到pom.xml里面
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-examples -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-examples</artifactId>
<version>3.1.4</version>
<scope>test</scope>
</dependency>
</dependencies>修改完pom.xml之后在右侧的maven中就可以看见dependencies
3、 编辑CountByDate程序参考WordCount,修改Mapper,复制Reducer程序,复制Main函数,并做相应修改。
(1)添加src\main文件
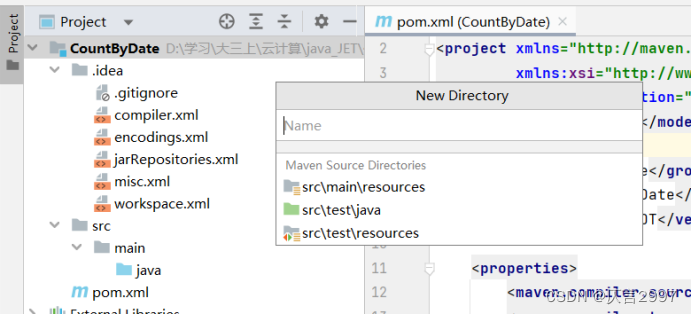
(2)创建CountByDate.java文件,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class CountByDate {
public static class SplitMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//value email | date
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String data[] = value.toString().split("\\|", -1);
word.set(data[1]);
context.write(word, one);
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(CountByDate.class);
job.setMapperClass(SplitMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
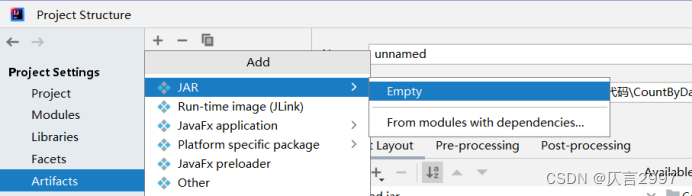
6、新的jar文件的创建
(1)在file-->project Structure-->artifacts中添加一个jar包
重新命名,并将‘CountByDate’ complie output 加载过去。
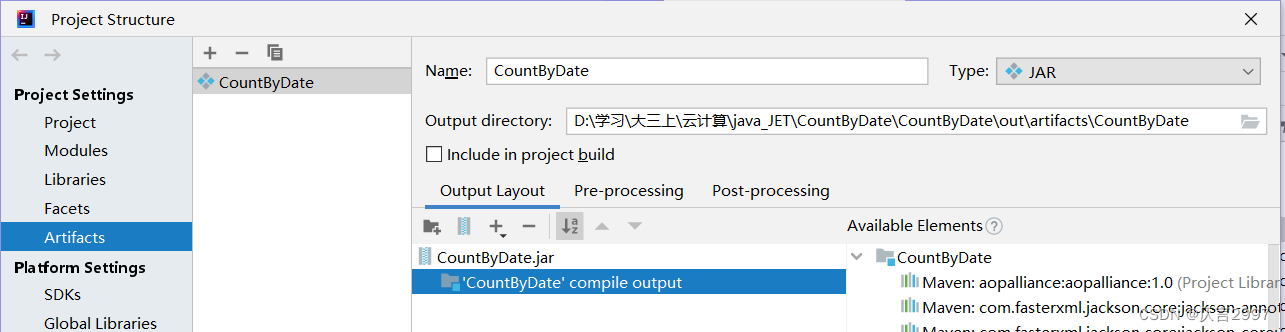
(2) 添加Build-->build artifacts-->countbydate-->build,将jar包放在out文件里面。
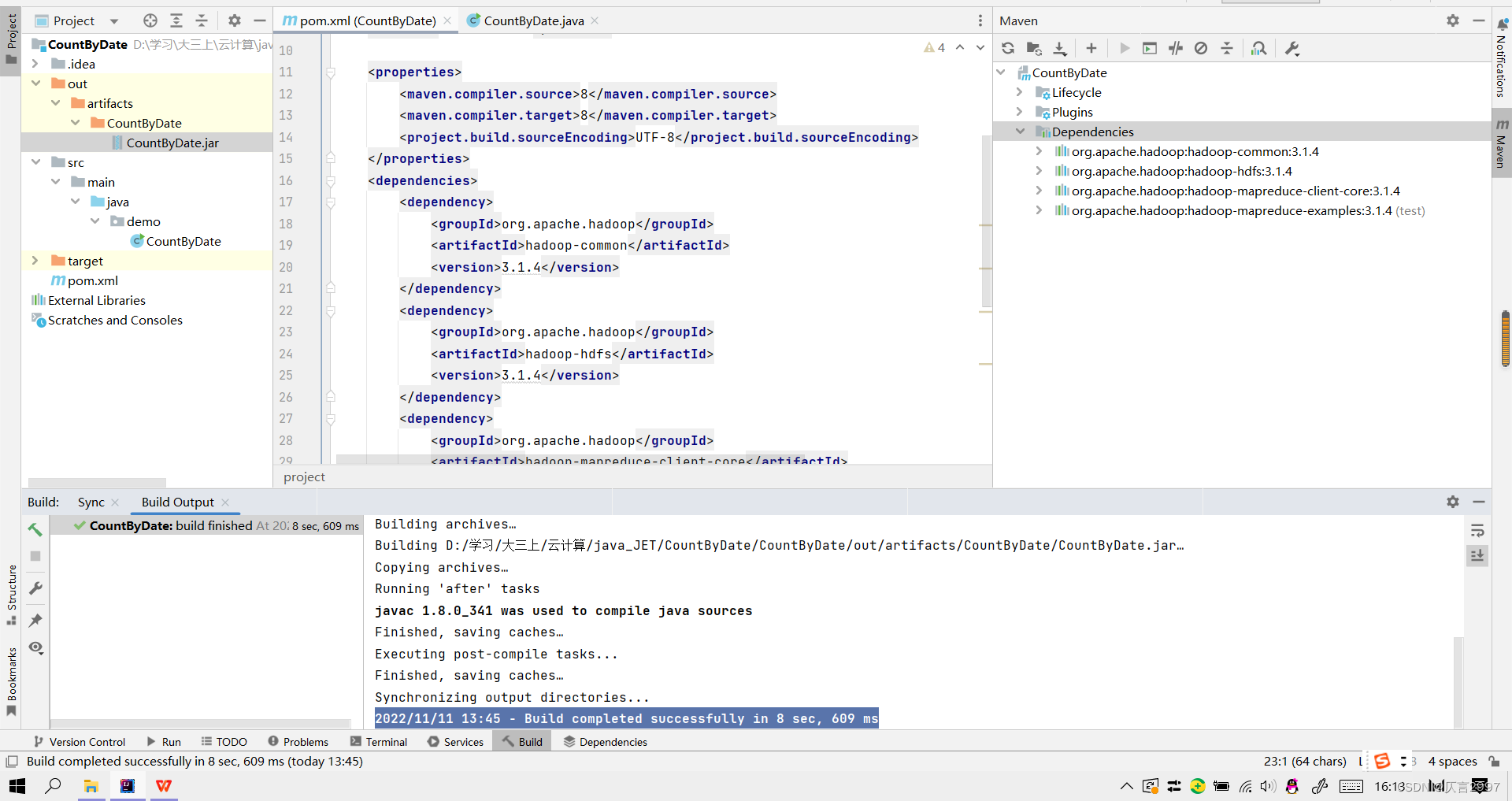
7、上传java文件并编译和打包,上传Jar包,上传数据到虚拟机。
(1)创建一个文件放本次案例的java文件以及jar包,用xftp上传文件。
命令:mkdir ~/cd00
!!!注意一定要先编译打包之后再上传jar包!!!
(2)编译、打包 CountByDate程序:
命令:javac CountByDate.java
命令:jar -cvf CountByDate.jar ./CountByDate*.class
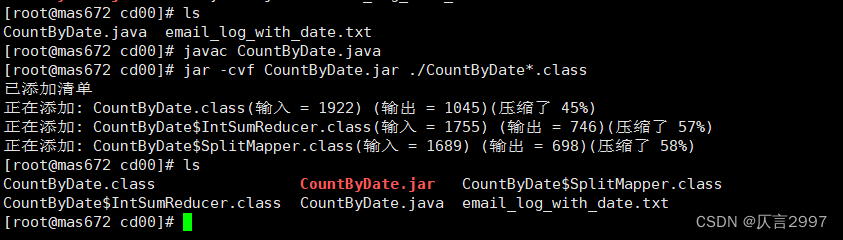 (3) 上传jar包
(3) 上传jar包

9,运行程序
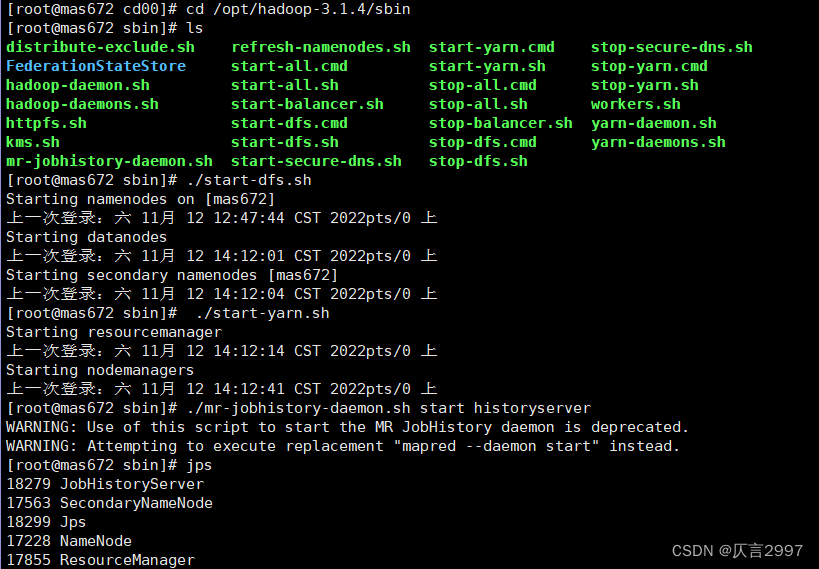
(1)启动集群:( cd /opt/hadoop-3.1.4/sbin)
命令: ./start-dfs.sh
命令: ./start-yarn.sh
命令:./mr-jobhistory-daemon.sh start historyserver
(2)在分布式文件系统上面创建一个新的cdinput文件夹并上传email_log_with_date.txt到cdinput文件。
命令: hdfs dfs -mkdir /cdinput
命令: hdfs dfs -put email_log_with_date.txt /cdinput
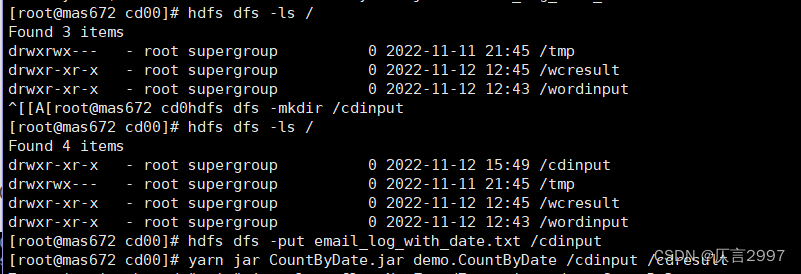 (3)运行程序:
(3)运行程序:
命令: yarn jar CountByDate.jar demo.CountByDate /cdinput /cdresult
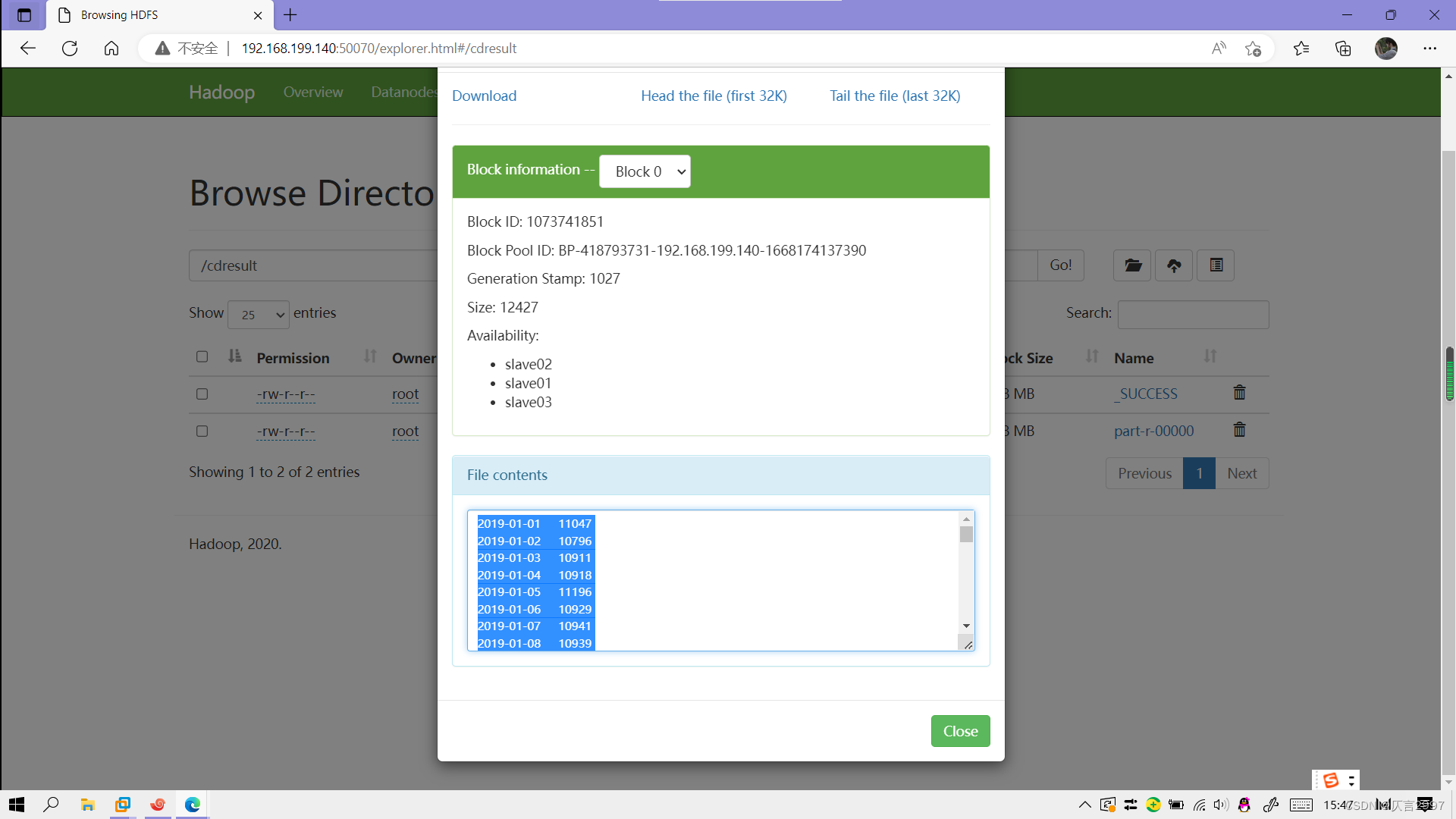
 10,查看运行结果
10,查看运行结果

















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









