







目录
栈和队列是两种常用的,重要的数据结构。
栈和队列是限定插入和删除只能在表的“端点”进行的线性表。其中,栈只能插入在表尾,删除也只能在表尾。在队列中,插入元素只能在表尾,删除元素只能在表头。
由于栈的操作具有后进先出的固有特性,队的操作有先进先出的固有属性,使得栈和队列成为程序设计中的有用工具。

一. 栈的基本术语
栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构。
表尾(即端)称为栈顶Top;表头(即
端)称为栈底Base;
插入元素到栈顶(即表尾)的操作,称为入栈(进栈,压栈)。从栈顶(即表尾)删除最后一个元素的操作,称为出栈(弹栈)。
“入”=压入=PUSH (x);“出”=弹出=POP(y)
栈的示意图:

【思考】假设有3个元素a,b,c,入栈顺序是a,b,c,有多少种不同的出栈顺序?
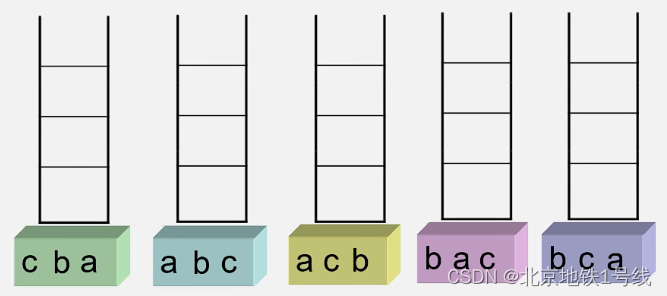
(1)a入-b入-c入-c出-b出-a出;(2)a入-a出-b入-b出-c入-c出;
(3)a入-a出-b入-c入-c出-b出;(4)a入-b入-b出-a出-c入-c出;...
【背景】组合数学里的卡特兰数。
二. 案例引入
案例1:进制转换
十进制整数N向其他进制数d(二、八、十六)的转换是计算机实现计算的基本问题。
转换法则:除以d倒取余,该转换法则对应于一个简单算法原理:
n=(n div d)* d + n mod d
其中:div为整除运算,mod为求余运算。

案例2:括号匹配的检验
假设表达式中允许包含两种括号:圆括号和方括号,其嵌套的顺序随意,如:( []())或[([ ][ ])]为正确格式;[ ( ])为错误格式;( [ ())或(()])也为错误格式。
算法:先入栈的括号后匹配,后入栈的括号先匹配;可以利用一个栈结构保存每个出现的左括号,当遇到右括号时,从栈中弹出左括号,检验匹配情况。
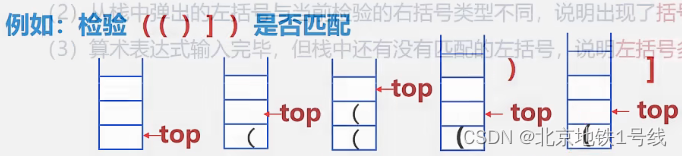
在检验过程中,若遇到以下几种情况之一,就可以得出括号不匹配的结论。
(1)当遇到某一个右括号时,栈已空,说明到目前为止,右括号多于左括号;
(2)从栈中弹出的左括号与当前检验的右括号类型不同,说明出现了括号交叉情况;
(3)算术表达式输入完毕,但栈中还有没有匹配的左括号,说明左括号多于右括号。
案例3:表达式求值
表达式求值是程序设计语言编译中一个最基本的问题,它的实现也需要运用栈。这里介绍的算法是由运算符优先级确定运算顺序的对表达式求值算法——算符优先算法。
表达式的组成:
- 操作数(operand):常数、变量。
- 运算符(operator):算术运算符、关系运算符和逻辑运算符。
- 界限符(delimiter):左右括弧和表达式结束符。
任何一个算术表达式都由操作数(常数、变量)、算术运算符(+、-、*、/)和界限符(括号、表达式结束符‘#’、虚设的表达式起始符‘#’)组成。后两者统称为算符。
例如:# 3*(7 - 2)#
为了实现表达式求值。需要设置两个栈:一个是算符栈OPTR,用于寄存运算符。另一个称为操作数栈OPND,用于寄存运算数和运算结果。求值的处理过程是自左至右扫描表达式的每一个字符:
- 当扫描到的是运算数,则将其压入栈OPND;
- 当扫描到的是运算符时:
·若这个运算符比OPTR栈顶运算符的优先级高,则入栈OPTR,继续向后处理;
·若这个运算符比OPTR栈顶运算符的优先级低,则从OPND栈中弹出两个运算数,从栈OPTR中弹出栈顶运算符进行运算,并将运算结果压入栈OPND。
- 继续处理当前字符,直到遇到结束符为止。
*也可以采用二叉树计算表达式的值,这里简单介绍,二叉树在第15节开始介绍:
以二叉树表示表达式的递归定义如下:
(1)若表达式为数或简单变量,则相应二叉树中仅有一个根结点,其数据域存放该表达式信息;
(2)若表达式为“第一操作数 运算符 第二操作数”的形式,则相应的二叉树中以左子树表示第一操作数,右子树表示第二操作数,根结点的数据域存放运算符(若为一元运算符,则左子树为空),其中,操作数本身又为表达式。

三. 栈的表示与操作实现
首先描述栈的抽象数据类型:
ADT Stack{
数据对象:D={ ai | ai ∈ElemSet, i=1,2..,n, n≥0 }
数据关系:R1= { <ai-1, ai >| ai-1, ai∈D, i=2,...,n }
约定an端为栈顶,a1端为栈底。
基本操作:
InitStack(&S) //初始化操作
操作结果:构造一个空栈S。
DestroyStack(&S) //销毁栈操作
初始条件:栈S已存在。
操作结果:栈S被销毁。
StackEmpty(S) //判定S是否为空栈
初始条件:栈S已存在。
操作结果:若栈S为空栈,则返回TRUE, 否则FALSE。
StackLength(S) //求栈的长度
初始条件:栈S已存在。
操作结果:返回S的元素个数,即栈的长度。
GetTop(S,&e) //取栈顶元素
初始条件:栈S已存在且非空。
操作结果:用e返回S的栈顶元素。
ClearStack(&S) //栈置空操作
初始条件:栈S已存在。
操作结果:将S清为空栈。
Push(&S, e) //入栈操作
初始条件:栈S已存在。
操作结果:插入元素e为新的栈顶元素。
Pop(&S,&e) //出栈操作
初始条件:栈S已存在且非空。
操作结果:删除S的栈顶元素an,并用e返回其值。
}ADT Stack
由于栈本身就是线性表,所以栈也有顺序存储和链式存储两种实现方式。
栈的顺序存储---顺序栈;栈的链式存储---链栈;
(1)栈的顺序表示
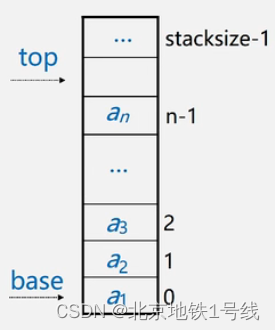
顺序栈的存储方式:同一般线性表的顺序存储结构完全相同,利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素。栈底一般在低地址端。此外:
- 附设top指针,指示栈顶元素在顺序栈中的位置。但是,为了方便操作,通常top指示真正的栈顶元素之上的下标地址;
- 另设base指针,指示栈底元素在顺序栈中的位置;
- 另外,用stacksize表示栈可使用的最大容量;

使用数组作为顺序栈存储方式的特点:简单、方便、但易产生溢出(数组大小固定);
上溢(overflow):栈已经满,又要压入元素;下溢(underflow):栈已经空,还要弹出元素;
注:上溢是一种错误,使问题的处理无法进行;而下溢一般认为是一种结束条件,即问题处理结束。
综上,顺序栈的表示如下:
# define MAXSIZE 100
typedef struct{
SElemType *base; //栈底指针
SElemType *top; //栈顶指针
int stacksize; //栈可用最大容量
}SqStack;其中,SElemType是栈中元素的数据类型,可以根据实际需要进行定义。下面介绍几种基本操作:
1)顺序栈的初始化
Status InitStack(SqStack &S){ //构造一个空栈
S.base=new SElemType[MAXSIZE]; //注意这里传入的是结构体的引用不是指针的引用,不用->
//或S.base=(SElemType*)malloc(MAXSIZE*sizeof(SElemType));
if(!S.base) exit(OVERFLOW); //存储分配失败
S.top=S.base; //栈顶指针等于栈底指针
S.stacksize=MAXSIZE;
return OK;
}2)判断顺序栈是否为空
Status StackEmpty(SqStack S){
//若栈为空返回TRUE,否则返回FALSE
if(S.top==S.base)
return TRUE;
else
return FALSE;
}3)求顺序栈的长度
int StackLength(SqStack S){
return S.top-S.base;
}4)清空顺序栈
Status ClearStack(SqStack S){
if (S.base)S.top=S.base; //使栈顶指针等于栈底指针
return OK;
}
5)销毁顺序栈
Status DestroyStack(SqStack &S){
if (S.base){
delete S.base;
S.stacksize=0;
S.base=S.top=NULL;
}
return OK;
}
6)顺序栈的入栈
Status Push(SqStack &S,SElemType e){
if (S.top-S.base == S.stacksize) //栈满
return ERROR;
*S.top=e; //注意这里栈顶指针指向栈顶元素的下一个位置
S.top++; //以上两行可以合并为*S.top++=e;
//回顾一下:++i是自增后赋值,i++是先赋值后自增
return OK;
}7)顺序栈的出栈
Status Pop(SqStack &S,SElemType &e){
if (S.top == S.base) //栈空
return ERROR;
--S.top;
e=*S.top; //以上两行可以合并为e=*--S.top;
return OK;
}(2)栈的链式表示
链栈的表示:链栈是运算受限的单链表,只能在链表头部进行操作。
typedef struct StackNode
{
SElemType data; //结点的数据域
struct StackNode *next; //结点的指针域,指向定义的结构体,嵌套定义
}StackNode,*LinkStack; 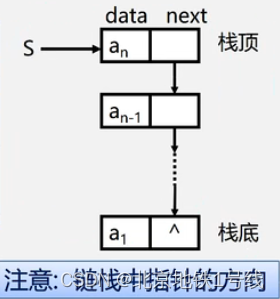
注意链栈的几个特点:链栈中指针的方向从a_n到a_1,这是和单链表不同的地方;链表的头指针就是栈顶;不需要头结点;基本不存在栈满的情况;空栈相当于头指针指向空;插入和删除仅在栈顶处执行。
1)链栈的初始化
Status InitStack(LinkStack &S){
//构造一个链栈,栈顶指针指向空
S=NULL;
return OK;
}2)判断链栈是否为空
Status StackEmpty(LinkStack S){
if(S==NULL) return TRUE;
else return FALSE;
}3)链栈的入栈
Status Push(LinkStack &S,SElemType e){
p=new StackNode; //生成新结点p
p->data=e; //将新结点数据域置为e
p->next=S; //插入栈顶
S=p; //修改栈顶指针
return OK;
}4)链栈的出栈
Status Pop(LinkStack &S,SElemType &e){
if(S==NULL) return ERROR; //空栈报错
e=S->data; //将数据保存在e
p=S; //另起一个指针指向被删除的结点
S=S->next; //修改栈顶指针
delete p;
return OK;
}5)取栈顶元素
SElemType GetTop(LinkStack S){
if(S!=NULL)
return S->data;
}四. 栈与递归
递归的定义:若一个对象部分地包含它自己,或用它自己给自己定义,则称这个对象是递归的;
若一个过程直接地或间接地调用自己,则称这个过程是递归的过程。以下是一个递归求阶乘的例子:
long Fact(long n){
if (n==0) return 1;
else return n*Fact(n-1);
}
以下三种情况常常用到递归方法:递归定义的数学函数,具有递归特性的数据结构,可递归求解的问题。对递归问题经常采用分治法求解。分治法指的是对于一个较为复杂的问题,能够分解成几个相对简单的且解法相同或类似的子问题来求解。因此递归必须具备下面三个条件:
- 能将一个问题转变成一个新问题,而新问题与原问题的解法相同或类同,不同的仅是处理的对象,且这些处理对象是变化有规律的
- 可以通过上述转化而使向题简化
- 必须有一个明确的递归出口,或称递归的边界
分治法求解递归问题算法的一般形式如下:
void p(参数表){
if (递归结束条件) 可直接求解步骤; //基本项
else p(较小的参数); //归纳项
}在上面提到的函数调用过程中,函数调用系统一般要完成以下几步:
调用前,系统完成:
- 将实参,返回地址等传递给被调用函数;
- 为被调用函数的局部变量分配存储区;
- 将控制转移到被调用函数的入口;
调用后,系统完成:
- 保存被调用函数的计算结果;
- 释放被调用函数的数据区;
- 依照被调用函数保存的返回地址将控制转移到调用函数;
以下展示了求解阶乘的一些过程,和栈的后入先出规则很类似:

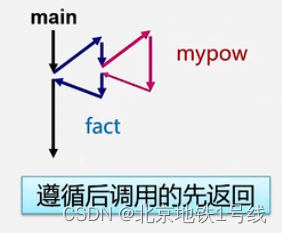
当多个函数构成嵌套调用时,遵循后调用先返回的原则。例如:
int main(void){
...
y=fact(3);
...
}
double fact(int n){
...
z=mypow(3,5)
...
}
double mypow(int m,int n){
...
}
递归的优缺点:
- 优点:结构清晰,程序易读;
- 缺点:每次调用要生成工作记录,保存状态信息,入栈;返回时要出栈,恢复状态信息。时间开销大;
递归问题→非递归问题,一般有两种思路:
- 方法1:尾递归、单向递归→循环结构
- 方法2:自用栈模拟系统的运行时栈(了解即可)

















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











