







AWS Glue DataBrew (AWS Glue DataBrew)
数据预处理是任何数据分析任务之前的重要步骤。AWS Glue DataBrew 是一个可视化工具,允许我们预处理数据,包括清洗和规范化数据。此AWS服务提供许多数据准备功能,包括分组、联接、过滤、重新采样、排序、处理缺失和重复实例、应用聚合等。该服务的交互性质使得没有太多技术知识的用户也能轻松使用。数据预处理管道是基于一系列步骤构建的,称为“配方”(recipe)。配方不过是我们想要应用于数据的技术的顺序步骤。总体上,我们需要遵循以下步骤:
- 导入数据集。我们可以将自己的数据集上传到S3存储桶,然后将其添加为Glue DataBrew中的数据集,或者我们可以使用AWS存储库中的示例数据集。
- 创建项目。步骤1和步骤2是可互换的,我们可以先创建项目然后导入数据集。
- 创建配方。一旦创建项目,我们就可以对数据应用多种技术。
- 发布和导入配方。配方通常处于“工作版本”状态,直到发布。一旦发布,我们可以导入配方,或者在未来的项目中使用配方。
让我们看一个这个管道的示例。
创建项目 (Creating a project)
我们首先为准备特定数据集创建一个新项目。不幸的是,我们在一个项目中只能使用一个数据集(而不是多个)。从Glue DataBrew主页,我们点击“创建项目”按钮。我们可以在主页上找到这个按钮,也可以在左侧的“项目”标签中找到。

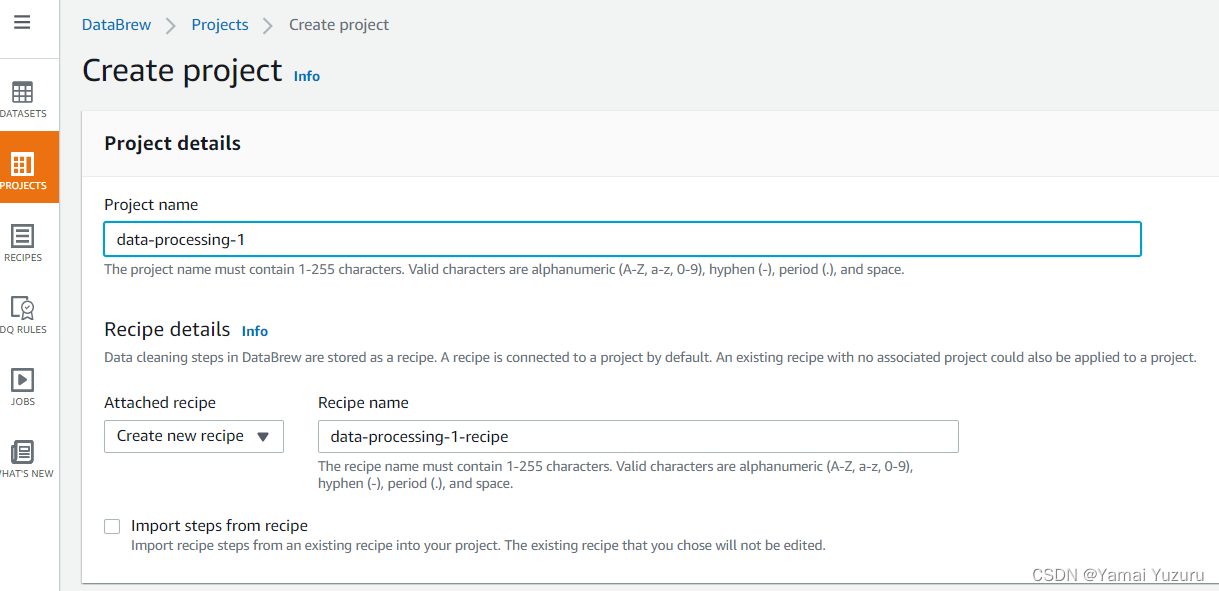
这将带我们进入“创建项目”页面,我们需要提供项目的详细信息。项目的关键要素是:名称、配方、数据集、样本数量和权限。我们按照“项目名称”部分的指示给项目命名。在此示例中,项目名称为“data-processing-1”。然后我们为项目添加配方。我们可以“创建新配方”,也可以使用现有配方(即发布的配方)。配方是清理数据的一系列步骤的组合。由于我们要进行数据清理,我们将“创建”一个新配方,而不是使用现有的。默认情况下,配方的名称格式为“项目名称-配方”。
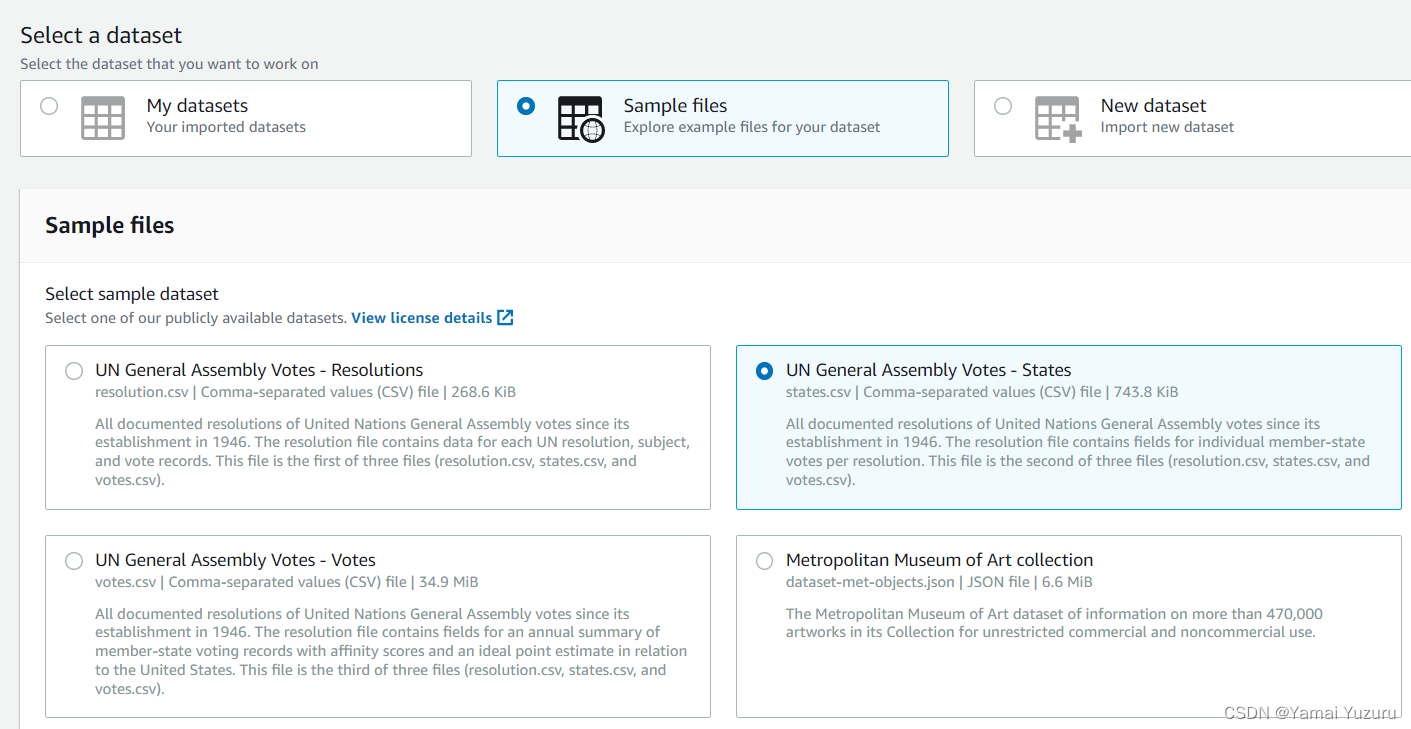
现在,我们需要为项目添加数据集,它可以是AWS存储库中的示例数据集,也可以是我们上传到S3存储桶的自己的数据集。在此示例中,我们将使用“联合国大会投票 - 国家”示例数据集。我们可以给数据集命名。我们可以选择在项目中使用数据的样本数量。我们有一些数值选项以及自定义大小。在此示例中,我们将处理前500个样本。
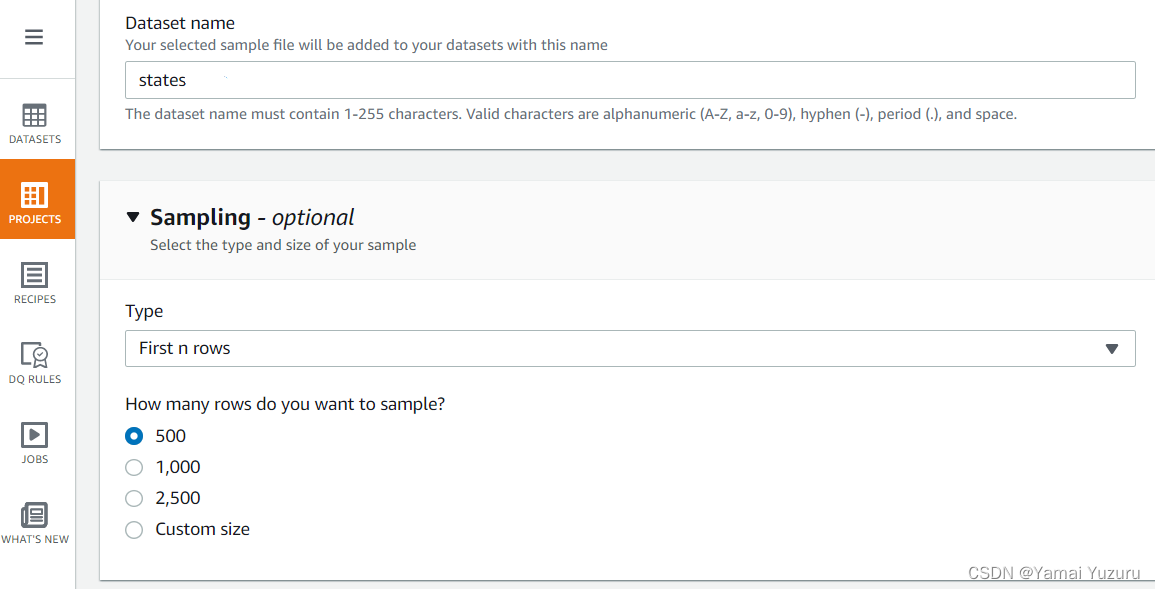
接下来,我们需要为项目提供权限,以便它可以连接到指定的数据集。为此,我们需要为项目添加一个角色。由于我们的IAM访问非常有限,我们没有太多选择,只能使用默认角色。在此示例中,我们使用“LabRole”。之后,我们可以点击“创建项目”按钮开始创建项目。
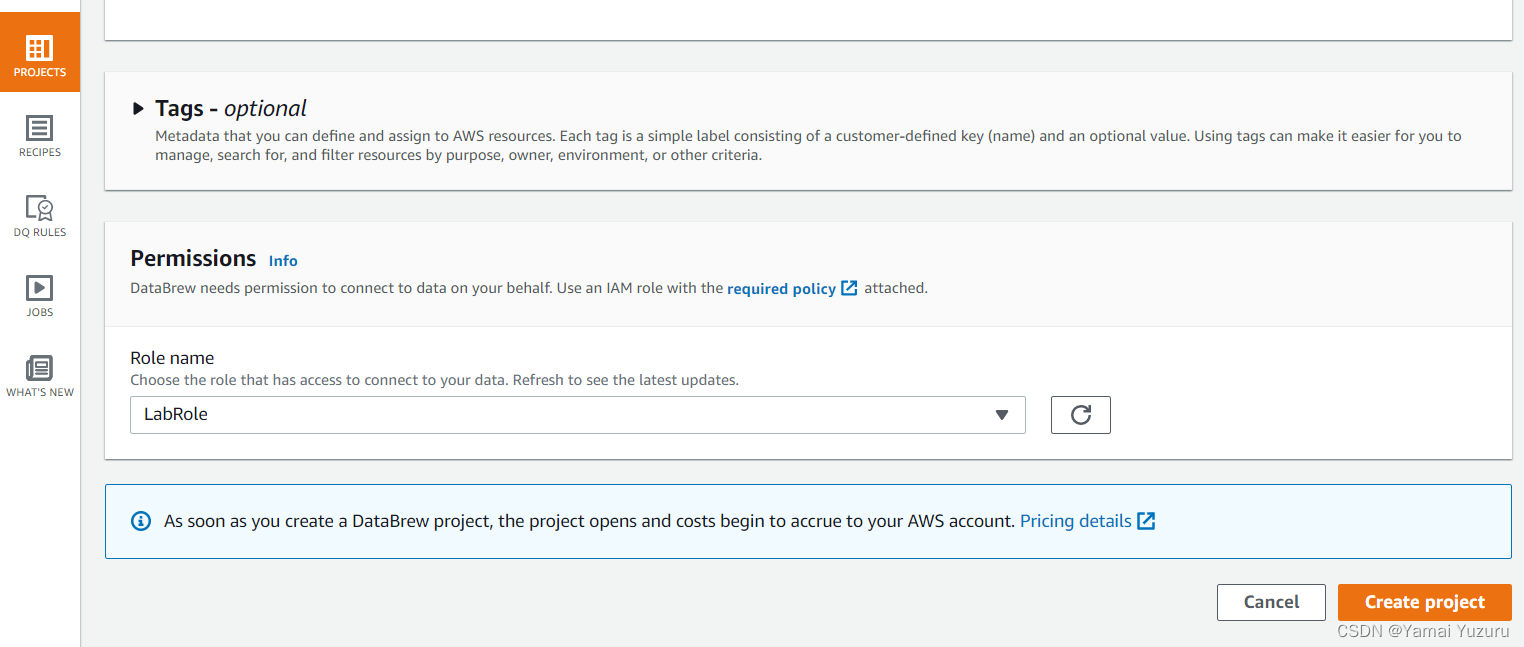
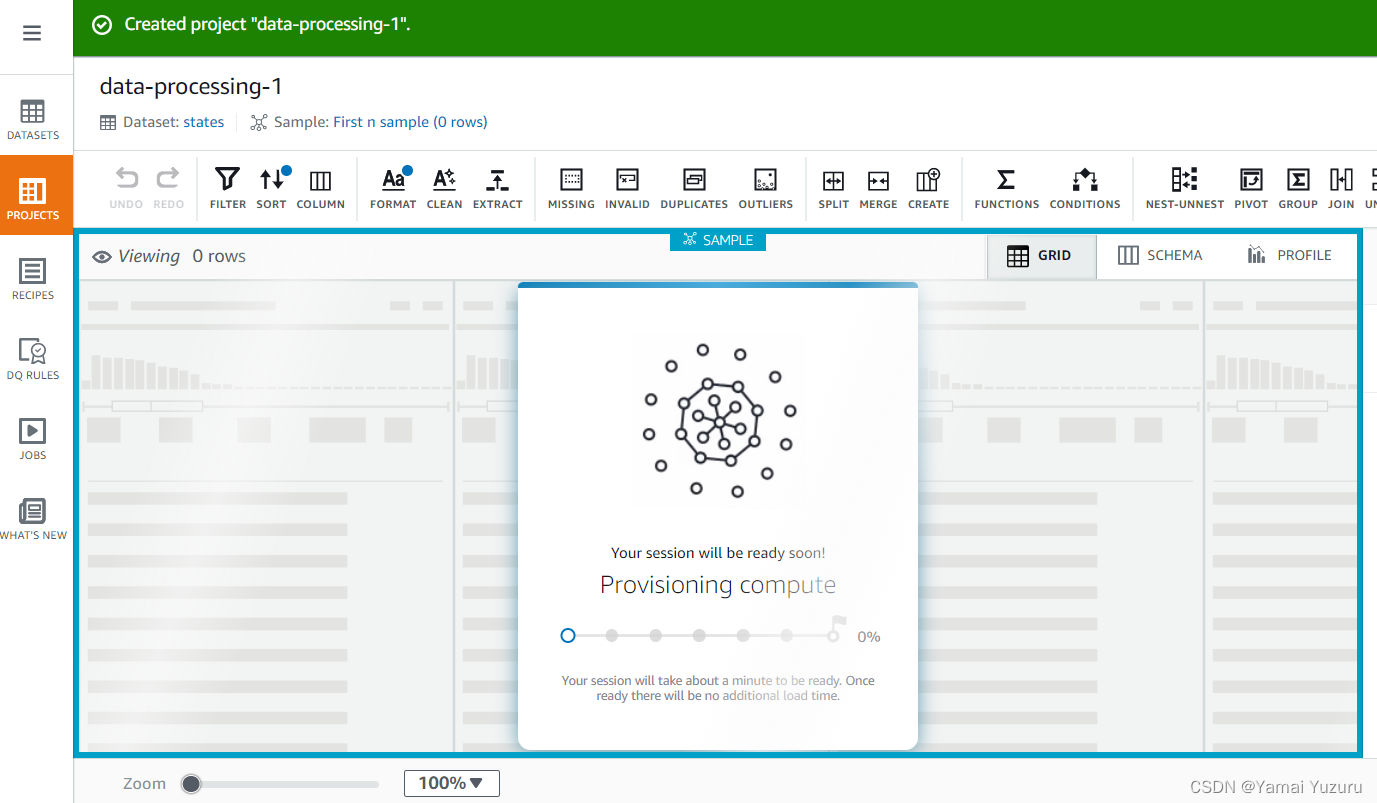
项目将开始配置,如下所示。一旦项目创建完成,我们可以从左侧的“数据集”标签中导航,查看数据集存储的位置。在此示例中,数据集位于AWS S3存储桶中。
创建自定义数据集 (Creating Custom Dataset)
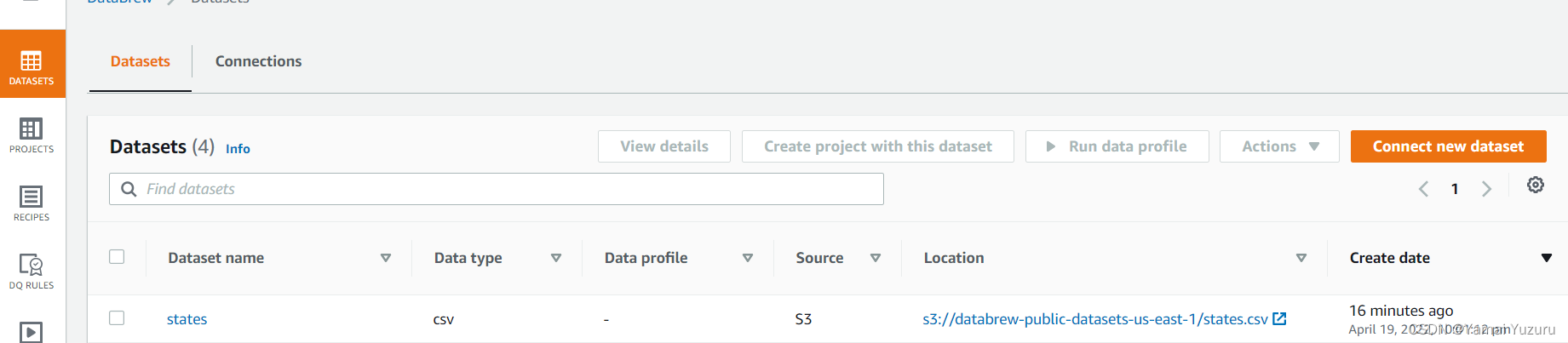
如前所述,我们可以先将数据集上传到S3存储桶,然后使用它创建项目。假设我们在S3存储桶中有一个“employee.json”文件。我们将使用这个文件创建一个数据集。我们点击左侧的“数据集”标签,然后点击“连接新数据集”按钮。

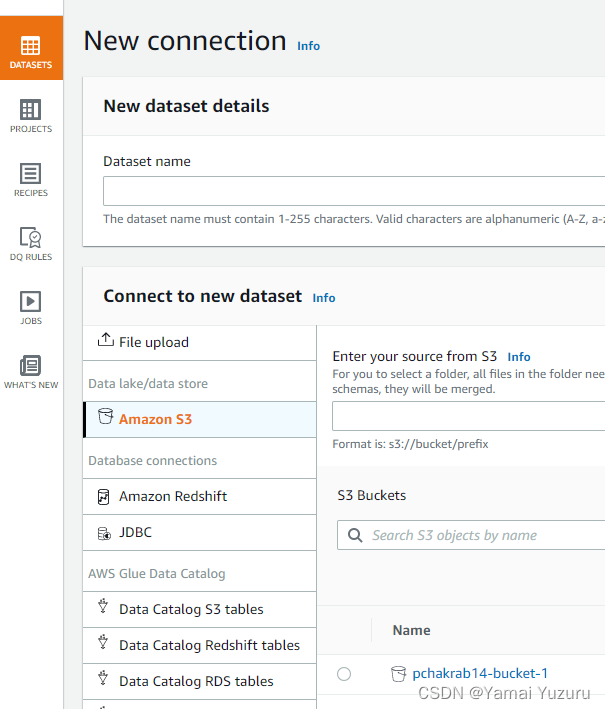
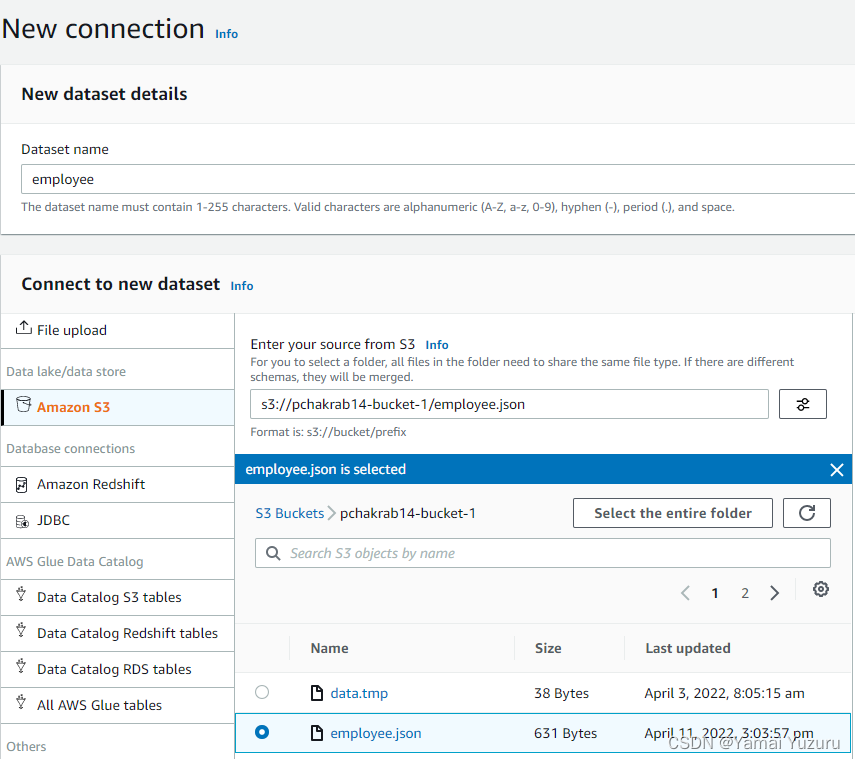
我们需要给数据集命名并指定数据文件的位置。一旦选择“Amazon S3”,所有现有的存储桶(在此示例中列出一个存储桶)将出现在“S3存储桶”列表中。一旦选择存储桶,它的所有对象(即文件)将被列出,我们可以选择“employee.json”。在“其他配置”部分,我们为“选择的文件类型”选择“JSON”选项。然后我们为“JSON文件类型”选择“JSON文档”选项。最后,我们点击“创建数据集”按钮。
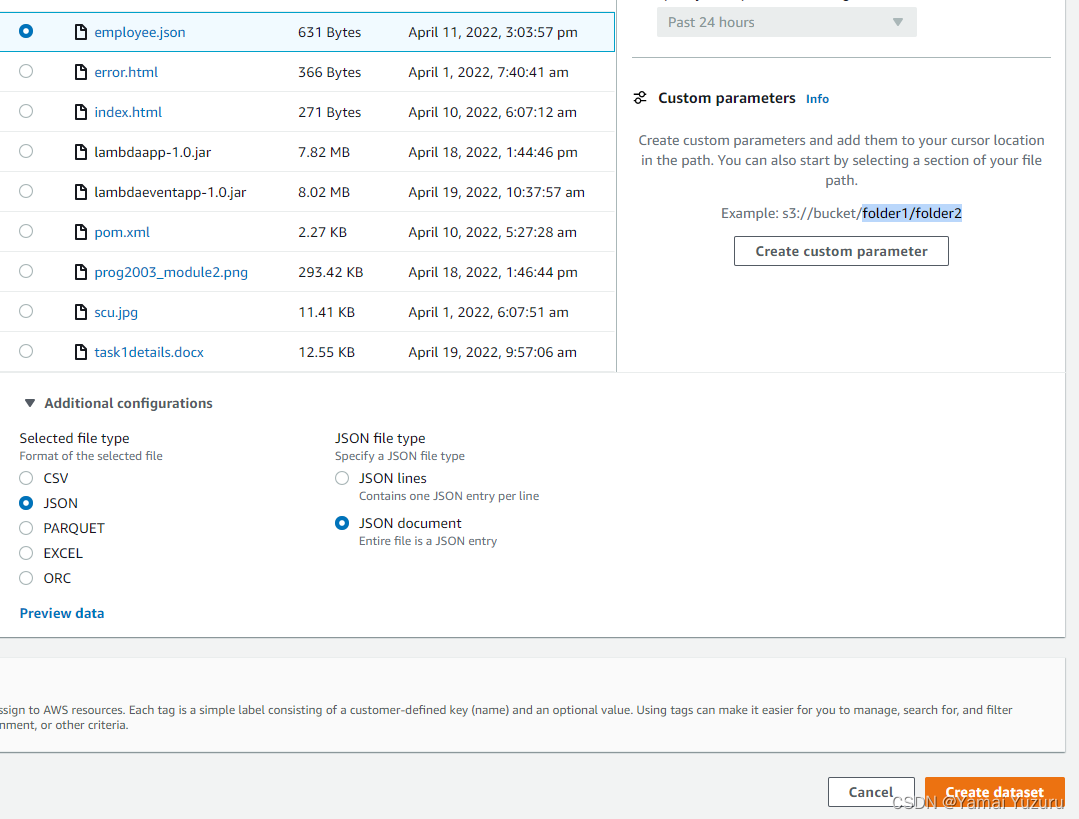
创建配方 (Creating a Recipe)
在上一节中,我们已经看到我们可以创建项目并向其添加数据集。我们看到的数据集示例基于“联合国大会对国家的投票”。如果我们启动项目,我们应该能够看到数据的每个属性的初步概览。
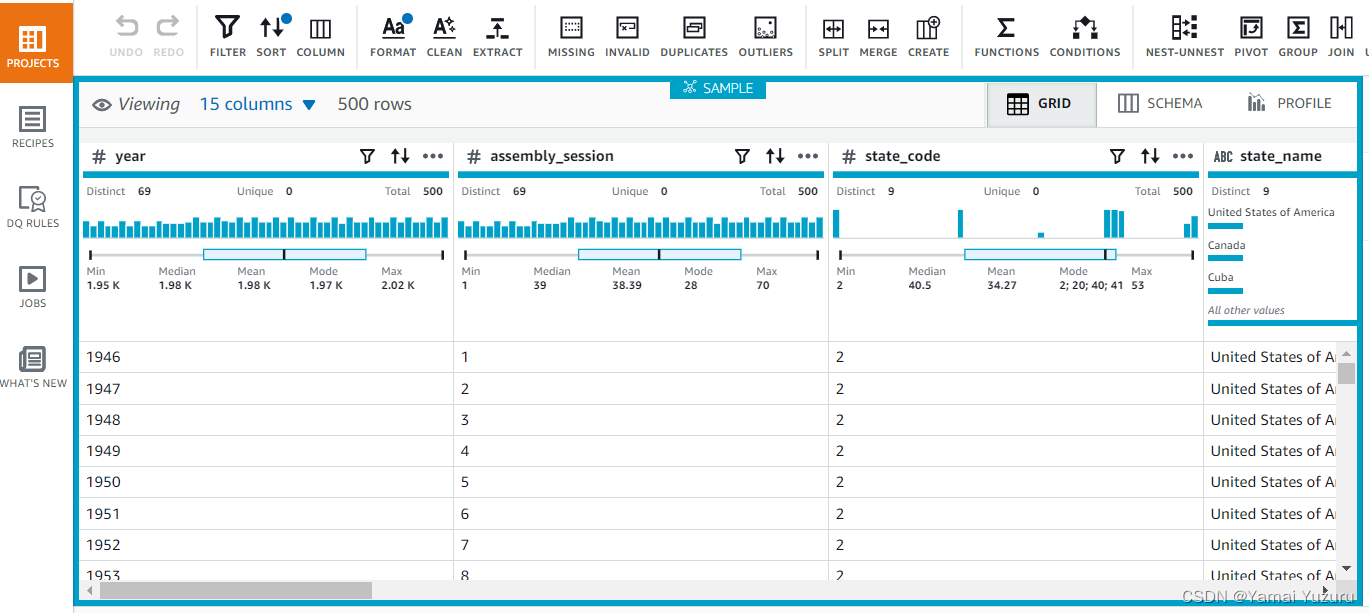
我们可以看到快速分布、独特和唯一实例的数量、平均值、中位数和其他统计数据。假设我们要计算每个国家的总票数和“yes_votes”列的实例数。如果你熟悉SQL查询,你可以猜到我们可以使用“group by”查询来完成这项任务。我们将在这里以交互方式完成相同的任务。我们将编写步骤来在配方中完成这些任务。在编写配方之前,让我们看看AWS Glue DataBrew可以做什么。

我们可以看到此服务允许我们通过单击这些选项来对数据进行许多操作。这个选项栏在项目视图的顶部可用。我们现在必须添加步骤来完成这些任务。可以从顶部栏(如上所示)或从右侧的“配方”菜单中添加配方。我们可以“添加步骤”来定义我们想要对数据应用的内容。
让我们定义一个包含以下步骤的配方:
- 处理缺失值
- 计算每个国家的总票数
- 计算每个国家的“yes_votes”实例数
在查看数据时,我们可以看到一些列有缺失(即“null”)值,其中之一是“affinityscore_china”。
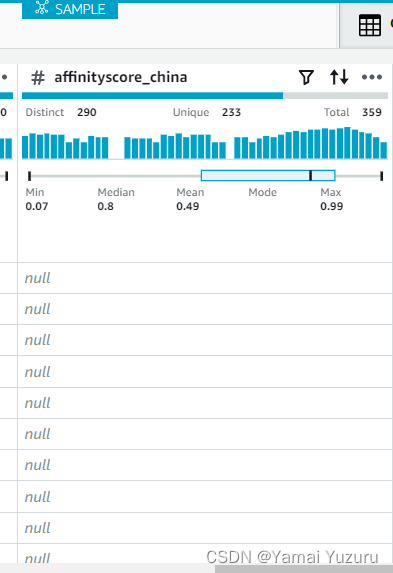
我们可以点击顶部标签栏中的“缺失”标签。我们将看到如何处理缺失值的多个选项 - 通常可以替换值或删除整行。在此示例中,我们将通过所有现有/有效值的平均值替换缺失值。我们可以展开“缺失”标签,选择要处理的列。然后我们需要选择“填充数值聚合”。接下来,我们需要选择聚合方法,在此示例中是所有有效值的“平均值”。我们还可以指定我们要在“应用转换到”中应用此过程的行数。
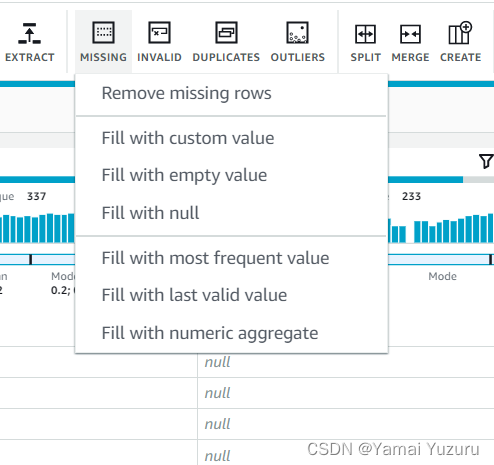
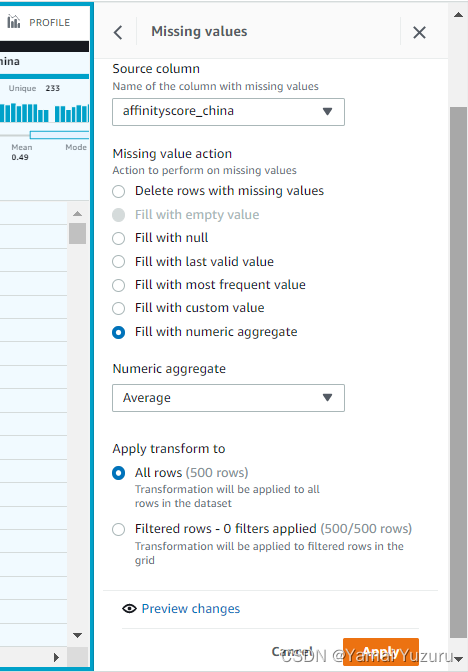
我们可以点击“应用”按钮,将聚合方法应用于数据列。
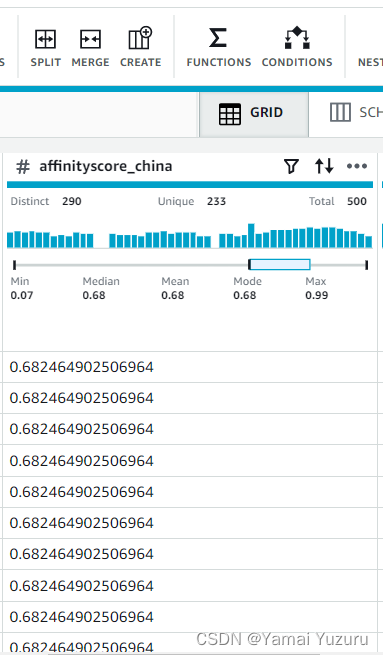
一旦应用,此过程将作为步骤添加到我们的配方中。
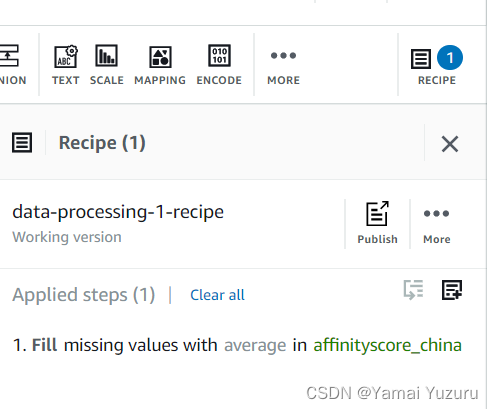
接下来,我们要计算“all_votes”的总票数和“yes_votes”列的实例总数。我们可以点击顶部标签栏中的“分组”标签。这将带来以下界面。
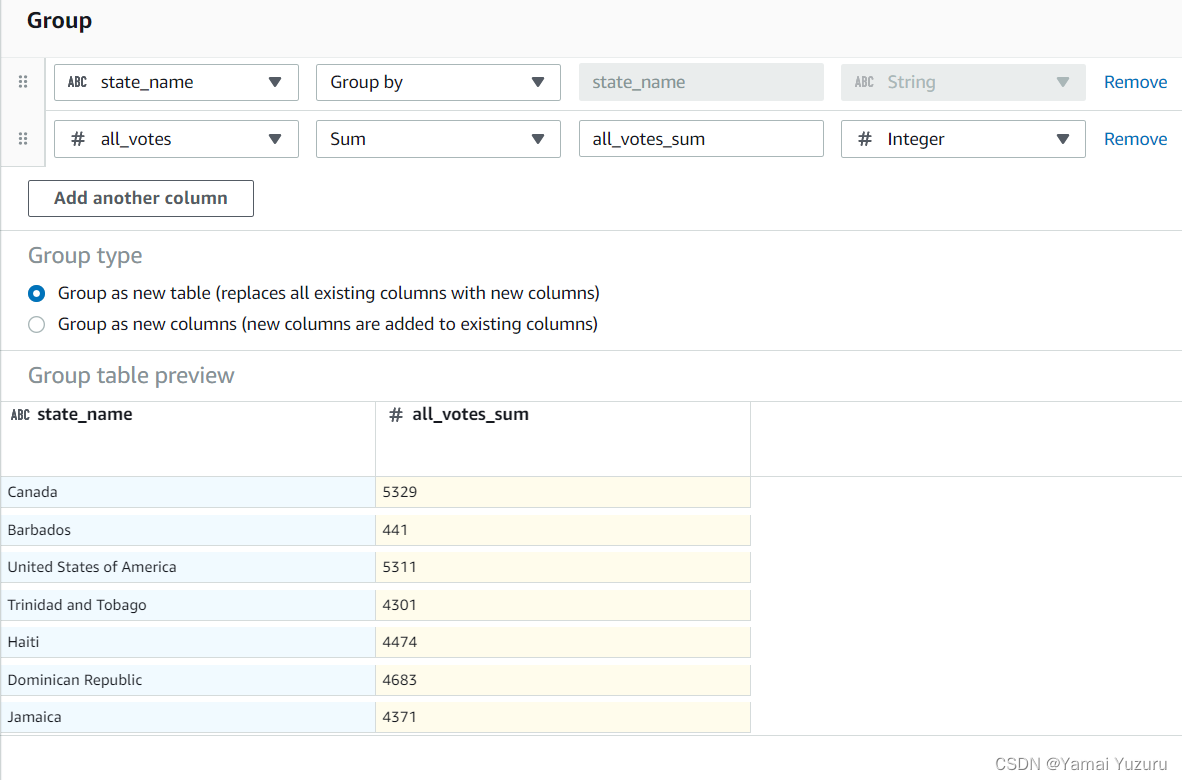
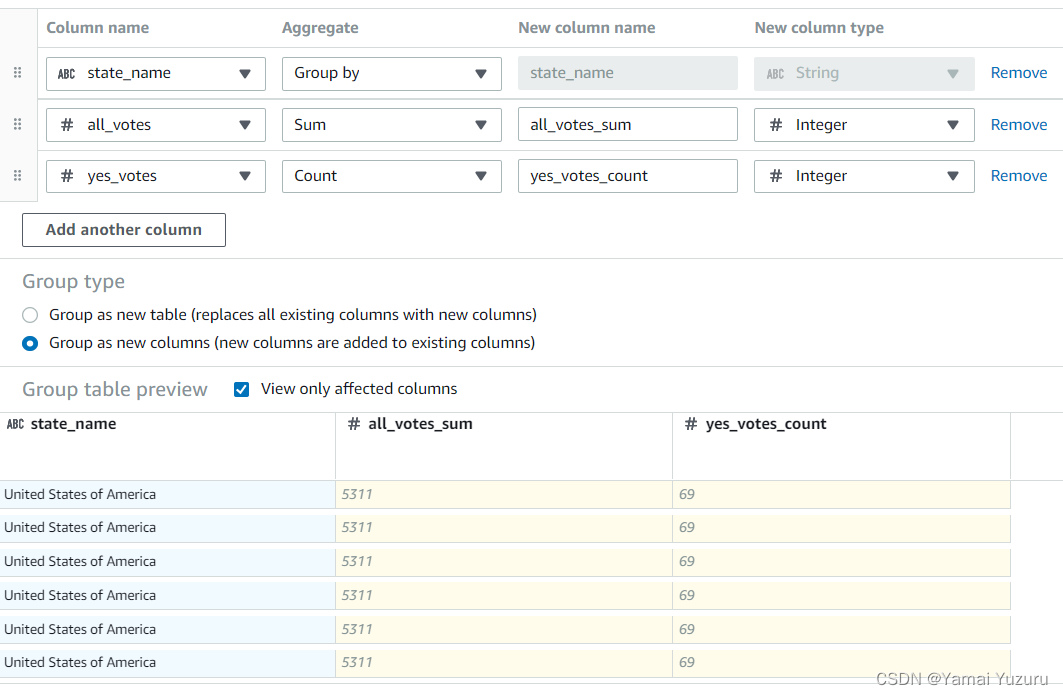
我们需要选择要“分组依据”的列。然后选择要聚合的列。我们可以根据需要添加多个列。“作为新表分组”选项将替换原始表,因此在应用前需要仔细检查。我们可以将结果添加为“新列”和“仅查看受影响的列”。所有这些操作应用后将添加到我们的配方中。
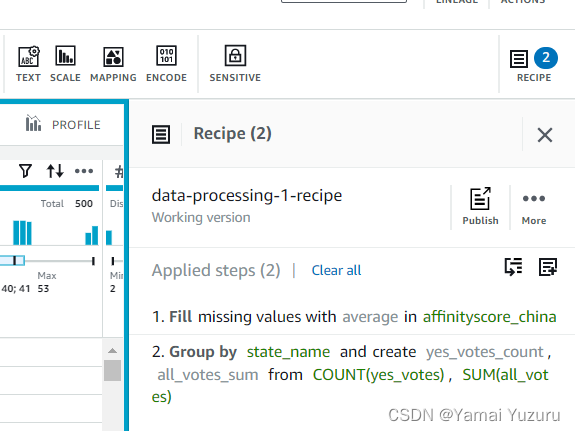
发布和下载配方 (Publishing and Downloading Recipe)
一旦创建配方,我们可以发布它。未发布之前,我们无法导出或在其他项目中使用它。发布前,配方处于“工作版本”状态。我们可以点击“配方”界面右上角的“发布”按钮。
然后点击“发布”按钮。
配方将立即发布,版本将变为“版本1.0”。
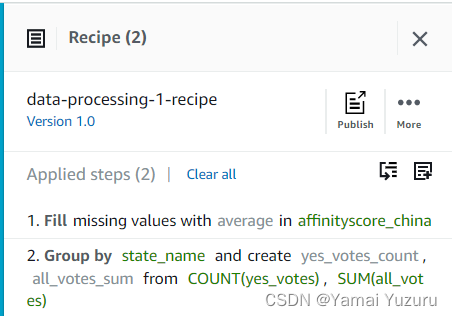
一旦发布,我们可以通过点击“更多”按钮,然后选择“下载为JSON”来下载配方。JSON文件将如下所示。
[
{
"Action": {
"Operation": "FILL_WITH_AVERAGE",
"Parameters": {
"sourceColumn": "affinityscore_china"
}
}
},
{
"Action": {
"Operation": "GROUP_BY",
"Parameters": {
"groupByAggFunctionOptions": "[{\"sourceColumnName\":\"yes_votes\",\"targetColumnName\":\"yes_votes_count\",\"targetColumnDataType\":\"int\",\"functionName\":\"COUNT\"},{\"sourceColumnName\":\"all_votes\",\"targetColumnName\":\"all_votes_sum\",\"targetColumnDataType\":\"int\",\"functionName\":\"SUM\"}]",
"sourceColumns": "[\"state_name\"]",
"useNewDataFrame": "false"
}
}
}
]


















 2806
2806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











