






目录
目录
二、为Jetson Nano安装Anaconda并创建YOLOv5运行环境
前言
使用YOLOv5训练口罩识别模型,共分为三类:未佩戴口罩、正确佩戴口罩、未正确佩戴口罩。并将pt模型部署于Jetson Nano边缘计算平台上,实现口罩识别、点亮LED和语音播报功能,识别速度为8-13帧/秒。
值得注意的是,本文并未实现在Jetson Nano使用GPU进行预测,因为当时未注意到Jetson Nano安装的CUDA版本为10.0,CUDA10.0版本对应的torch版本为1.2.0,而YOLOv5需要的torch版本>=1.7.0,在多次尝试后未果后,放弃搭建GPU环境,因而也未进行模型转换加速的工作。
因此,以后应先确定设备可安装的运行环境后,再选择模型开展训练等后续工作。
一、使用YOLv5训练口罩识别模型
可参照此篇文章进行训练:保姆式yolov5教程,训练你自己的数据集 - 知乎 (zhihu.com)
若需建立自己的数据集,可以使用labelImg软件来打标签。网上有许多打包好的labelImg.exe,但若出现报错软件会直接闪退而不是弹出报错信息,因此令人难以明了闪退原因。若出现闪退问题,可先尝试此常见问题的解决方案,若还是闪退,可以下载labelImg源码运行,以debug查看报错原因,labelImg的安装与使用可参考此文章:【教程】标注工具Labelimg的安装与使用 - 知乎 (zhihu.com)
本文前期训练了只有两个种类(戴口罩与不戴口罩)的模型,使用此数据集。
后来测试发现,当口罩佩戴不标准(例如只遮住了嘴巴而没有遮住鼻子)时,也会被识别为戴口罩,为此,本文又重新寻找使用此数据集,训练了有三种类的模型:
0:没戴口罩
1:正确佩戴口罩
2:未正确佩戴口罩
二、为Jetson Nano安装Anaconda并创建YOLOv5运行环境
1.下载Anaconda
Jetson Nano的架构为aarch64,因此需要下载aarch64架构的Anaconda安装包
wget https://github.com/Archiconda/build-tools/releases/download/0.2.3/Archiconda3-0.2.3-Linux-aarch64.sh若下载缓慢,可使用如迅雷等下载软件进行下载,然后传输到Jetson Nano中。
安装包已上传至网盘,如有需要也可以用网盘下载,网盘链接见本文“3.4 完整代码下载”一节
2.安装Anaconda
进入下载的目录,使用如下代码进行安装:
sh Archiconda3-0.2.3-Linux-aarch64.shyqlbu/archiconda3: Light-weight Anaconda environment for ARM64 devices. (github.com)
3.创建YOLOv5运行环境
下载YOLOv5源码,进入创建的虚拟环境中并进入到requirements.txt所在目录,使用pip安装依赖包:
pip install -r requirements.txt若下载缓慢,可以使用 -i 命令换源:
pip install -r requirements.txt -i https://pypi.douban.com/simple三、代码
代码共分为四个线程:
主线程:获取最新的图像并进行预测
其它三个子线程:获取视频流、语音播报、LED灯控制
1.读取模型并调用摄像头进行预测
因为算法帧输达不到视频帧速,而VideoCapture总是一帧不落地输出帧,导致旧帧越积越多。不能实现处理最新帧的目的。因此开启一个线程读取最新帧保存到缓存里,用户读取的时候只返回最新的一帧。
# coding: utf-8
import sys
sys.path.append(r'./yolov5')
import numpy as np
import torch
import time
import threading
from yolov5.models.common import DetectMultiBackend
from yolov5.utils.general import (check_img_size, cv2, non_max_suppression, scale_boxes)
from yolov5.utils.plots import Annotator
from yolov5.utils.augmentations import letterbox
# from LED_control import led_control
# from voice_play import mp3_play
# 创建一个新线程,用于读取摄像头的图像并返回最新的一帧
class CameraThread(threading.Thread):
def __init__(self):
super(CameraThread, self).__init__()
self.ret = None
self.frame = None
self.is_running = True
def run(self):
self.is_running = True
cap = cv2.VideoCapture(0) # 设置摄像头索引,0表示默认摄像头
if not cap.isOpened():
print("无法打开摄像头")
else:
while self.is_running:
ret, frame = cap.read()
if not ret:
break
self.frame = frame
cap.release()
def stop(self):
self.is_running = False
self.join()
def get_latest_frame(self):
return self.frame
def mask_predict(frame, model, color_list, stride, names, pt , imgsz,
conf_thres=0.5, # 置信阈值
iou_thres=0.45, # 网管IOU阈值
max_det=1000, # 每张图像的最大检测数
classes=None, # 按类别过滤:--class 0,或--class 0 2 3
agnostic_nms=False, # 类别无关的 NMS
line_thickness=3 # 边界框厚度(像素)
):
# 数据加载器
bs = 1 # batch_size
# 运行推理
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # 模型预热
# path:路径 im:处理后的图片 im0s:原图 vid_cap:none s:图片的打印信息
im = letterbox(frame, imgsz, stride=stride, auto=pt)[0] # padded resize
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im) # contiguous
im = torch.from_numpy(im).to(model.device) # 将im转化为pytorch支持的格式并放到设备中
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # 扩增批次维度
# 推理,对上面整理好的图片进行预测
pred = model(im, augment=False, visualize=False)
# NMS,进行非极大值过滤
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
det = pred[0]
# 过程预测
im0 = frame.copy()
annotator = Annotator(im0, line_width=line_thickness, example=str(names)) # 定义绘图工具
data = dict.fromkeys(names.values(), 0)
if len(det):
# 坐标映射,方便在原图上画检测框
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det): # xyxy是识别结果的标注框的坐标,conf是识别结果的置信度,cls是识别结果对应的类别
c = int(cls)
data[names[c]] += 1
label = (f'{names[c]}{data[names[c]]} {round(float(conf), 2)}')
# label = (f'{names[c]}{data[names[c]]}')
annotator.box_label(xyxy, label, color=color_list[c]) # 对图片进行标注,就是画框
im0 = annotator.result()
return data, im0
if __name__ == "__main__":
# 加载预训练的YOLOv5模型
weights = "best_6.pt" # 模型路径或 triton URL
color_list = [(0, 0, 255), (0, 255, 0), (255, 0, 0)]
dnn = False # 使用 OpenCV DNN 进行 ONNX 推理
data = "data/mask.yaml" # dataset.yaml路径
half = False # 使用 FP16 半精度推理
imgsz = (160, 160) # 推断尺寸(高度、宽度)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # cuda 设备,即 0 或 0,1,2,3 或 cpu
conf_thres = 0.7 # 置信阈值
iou_thres = 0.45 # 网管IOU阈值
max_det = 100 # 每张图像的最大检测数
classes = None # 按类别过滤:--class 0,或--class 0 2 3
agnostic_nms = False # 类别无关的 NMS
line_thickness = 3 # 边界框厚度(像素)
print(f"device = {device}")
# 载入模型
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half) # 选择模型
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # 检查图像尺寸
# 打开摄像头
# cap = cv2.VideoCapture(0)
# 创建摄像头线程并启动
camera_thread = CameraThread()
camera_thread.daemon = True
camera_thread.start()
cv2.namedWindow("Mask_Detection")
# cv2.resizeWindow("Mask_Detection", int(imgsz[0]*1), int(imgsz[1]*1))
flag = [True, True]
mask_data = [{'no_mask': 0, 'mask': 0, "not_standard": 0}]
# # 创建一个新线程,并将函数 led_control 作为目标函数传入
# led_control_thread = threading.Thread(target=led_control, args=(flag[0], mask_data))
# led_control_thread.daemon = True
# led_control_thread.start()
#
# # 创建一个新线程,并将函数 mp3_play 作为目标函数传入
# mp3_play_thread = threading.Thread(target=mp3_play, args=(flag[1], mask_data))
# mp3_play_thread.daemon = True
# mp3_play_thread.start()
# 创建一个计时器对象
fps_timer = time.time()
while True:
# 从摄像头读取帧
# ret, frame = cap.read()
frame = camera_thread.get_latest_frame()
if frame is None:
continue
frame = cv2.flip(frame, 1) # 镜像
# 获取当前时间
current_time = time.time()
mask_data[0], frame = mask_predict(frame=frame, model=model, color_list=color_list, stride=stride, names=names, pt=pt,
imgsz=imgsz, conf_thres=conf_thres, iou_thres=iou_thres, max_det=max_det,
classes=classes, agnostic_nms=agnostic_nms, line_thickness=line_thickness)
# 计算帧率
fps = 1 / (current_time - fps_timer)
fps_timer = current_time
cv2.putText(frame, f"FPS: {int(fps)}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# 显示帧
# frame = cv2.resize(frame, (int(imgsz[0]*2), int(imgsz[1]*2)))
cv2.imshow('Mask_Detection', frame)
# 按'q'键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
flag[0] = False
flag[1] = False
# 停止摄像头线程
camera_thread.stop()
break
# 释放资源并关闭窗口
# cap.release()
cv2.destroyAllWindows()
2.语音播放
若视频中的人都标准佩戴口罩,则没有语音提醒;若有未正确佩戴口罩的人,则语音提示“未正确佩戴口罩”;若仅有未佩戴口罩的人,则语音提示“未佩戴口罩”。
# coding: utf-8
import pygame
import time
def mp3_play(mp3_play_flag, mask_data_list):
pygame.mixer.init()
while mp3_play_flag:
mask_data_dict = mask_data_list[0]
numbers = []
for value in mask_data_dict.values():
if isinstance(value, int) or isinstance(value, float):
numbers.append(value)
if numbers[0] >= 1: # 有未带口罩者
# pygame.mixer.init()
pygame.mixer.music.load('no_mask.mp3')
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
continue
time.sleep(3)
elif numbers[2] >= 1: # 有佩戴口罩不标准者
pygame.mixer.init()
pygame.mixer.music.load('not_standard.mp3')
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
continue
time.sleep(3)
else: # 都正确带了口罩或没有检测到人
# 此情况不需要执行任何操作,但若不执行任何指令,视频便会十分卡顿,因此让线程执行睡眠指令。
# 因能力有限,尚不清楚产生此问题的具体原因,求教
time.sleep(0.5)
# 停止音乐播放器
pygame.mixer.music.stop()
# 退出pygame
pygame.quit()
3.LED灯控制
若视频中的人都标准佩戴口罩,则亮绿灯;若仅有未正确佩戴口罩的人和未佩戴口罩的人,则亮红灯;若既有正确佩戴的人,又有未佩戴口罩或不正确佩戴的人,则红绿灯交替闪烁。
在虚拟环境中无法调用系统用于控制GPIO相关的包,因为将系统中控制GPIO需要的包RPi和Jetson复制到项目的同级目录下,以方便导入
# coding: utf-8
import sys
sys.path.append(r'./RPi')
import RPi.GPIO as GPIO
import time
def led_control(flag, mask_data_list):
pin_R = 12 # 定义红色LED灯PIN
pin_G = 11 # 定义黄色LED灯PIN
GPIO.setmode(GPIO.BOARD) # Numbers GPIOs by physical location
GPIO.setwarnings(False) # 忽略GPIO警告
GPIO.setup(pin_R, GPIO.OUT)
GPIO.setup(pin_G, GPIO.OUT)
led_green_state = None # 绿灯状态(亮/灭)
led_red_state = None # 红灯状态(亮/灭)
while flag:
mask_data_dict = mask_data_list[0]
print(mask_data_dict)
if (mask_data_dict["no_mask"] + mask_data_dict["not_standard"]) != 0 and mask_data_dict["mask"] != 0: # 有人戴口罩也有人没戴
while mask_data_dict["no_mask"] != 0 and mask_data_dict["mask"] != 0:
GPIO.output(pin_R, GPIO.HIGH)
GPIO.output(pin_G, GPIO.LOW)
time.sleep(0.5)
GPIO.output(pin_R, GPIO.LOW)
GPIO.output(pin_G, GPIO.HIGH)
time.sleep(0.5)
mask_data_dict = mask_data_list[0]
elif mask_data_dict["no_mask"] != 0 or mask_data_dict["not_standard"] != 0: # 没戴口罩 或 口罩佩戴不标准
if led_red_state != "on": # 需要的状态与目前LED状态不相符,再设置针脚电平
print("红灯引脚拉高")
print("亮红灯")
GPIO.output(pin_G, GPIO.LOW)
GPIO.output(pin_R, GPIO.HIGH)
led_red_state = "on"
led_green_state = "off"
else:
# 此情况不需要执行任何操作,但若不执行任何指令,视频便会十分卡顿,因此让线程执行睡眠指令。
# 因能力有限,尚不清楚产生此问题的具体原因,求教
time.sleep(0.5)
else: # 都带了口罩或没有检测到人
if led_green_state != "on": # 需要的状态与目前LED状态不相符,再设置针脚电平
print("绿灯引脚拉高")
print("亮绿灯")
GPIO.output(pin_R, GPIO.LOW)
GPIO.output(pin_G, GPIO.HIGH)
led_green_state = "on"
led_red_state = "off"
else:
# 此情况不需要执行任何操作,但若不执行任何指令,视频便会十分卡顿,因此让线程执行睡眠指令。
# 因能力有限,尚不清楚产生此问题的具体原因,求教
time.sleep(0.5)
4.完整代码下载
选择一个链接下载即可,内容都一样,共5个文件

蓝奏云:https://wwi.lanzoup.com/b0czs85hg 密码:e3w9
百度云盘:https://pan.baidu.com/s/1IRPbF9Lbb67pBTlUvaC7QA 提取码:pse2
谷歌云盘:https://drive.google.com/drive/folders/1L2IcY_0ZC-Lv8BpIrmZBmcPHPLup3QpG?usp=sharing
四、效果展示
由于三分类模型的训练数据量少,在使用时,将摄像头正面面对人脸时识别效果最佳,若从其它角度拍摄,效果可能不会很理想。
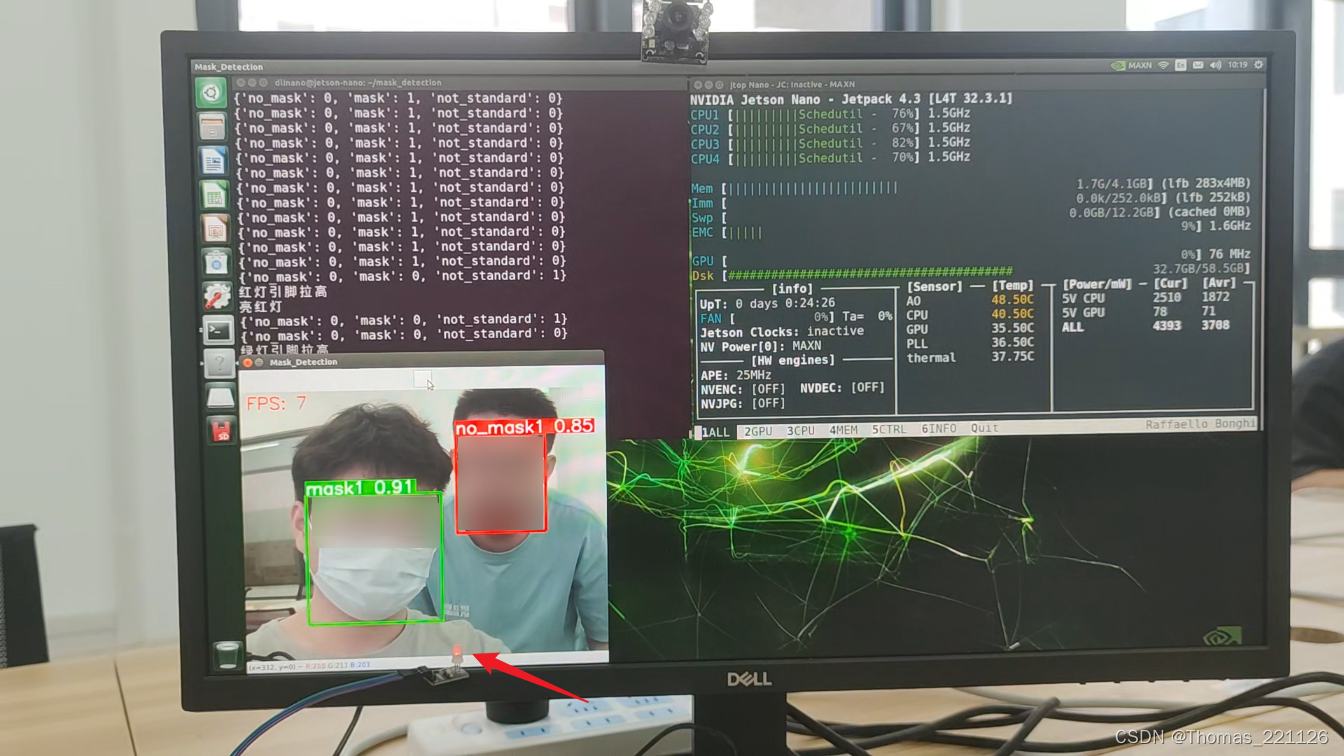
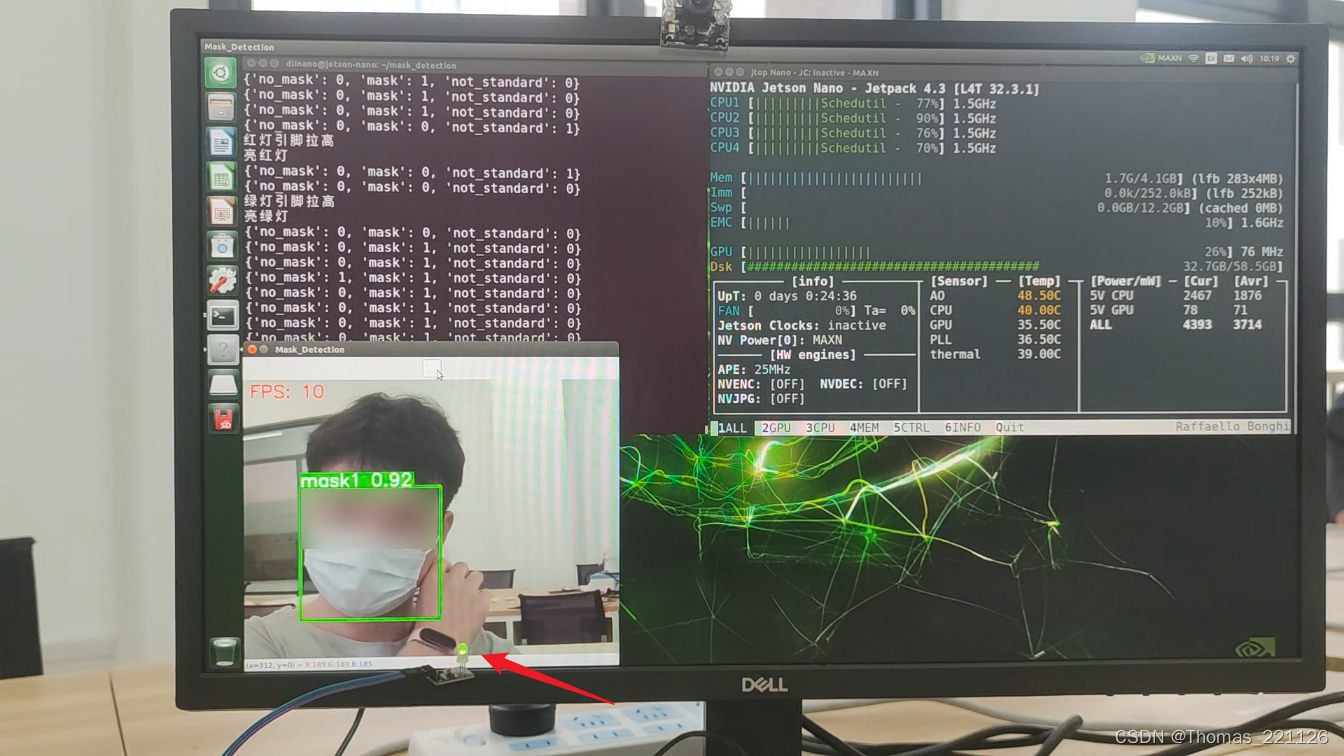
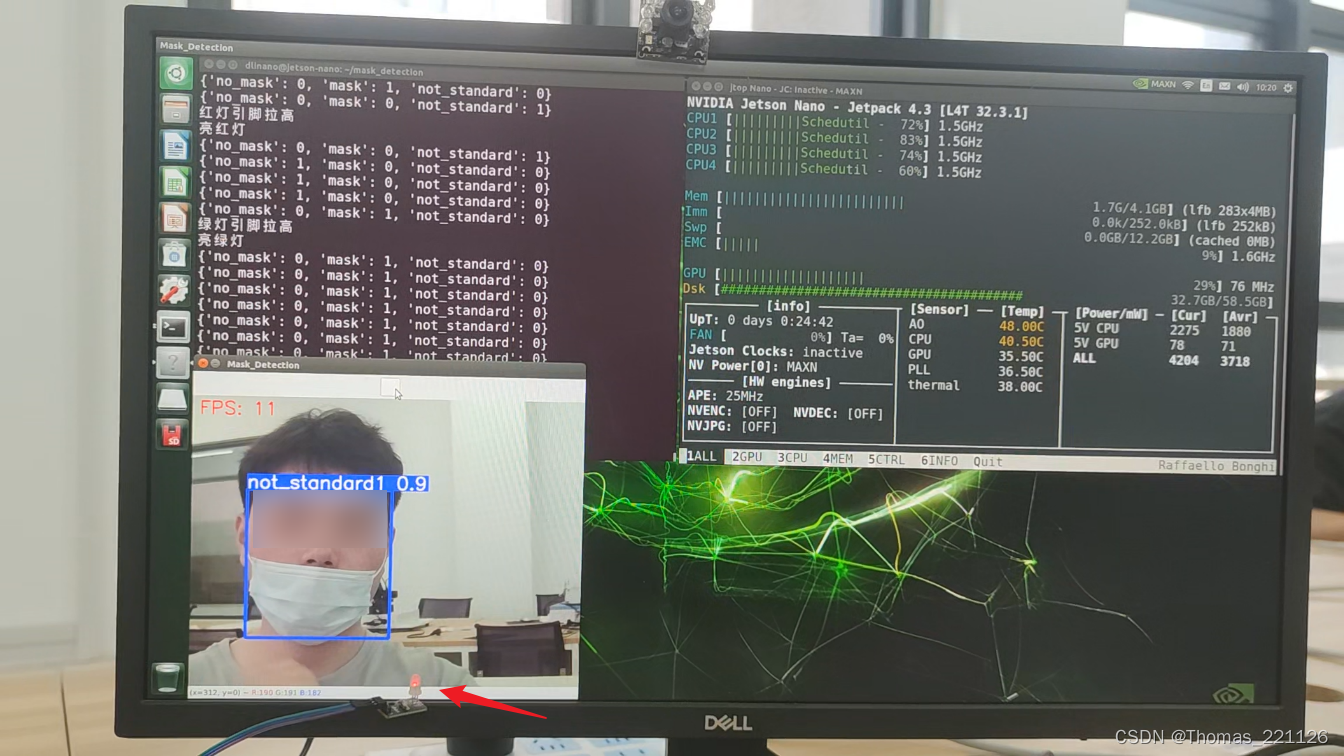
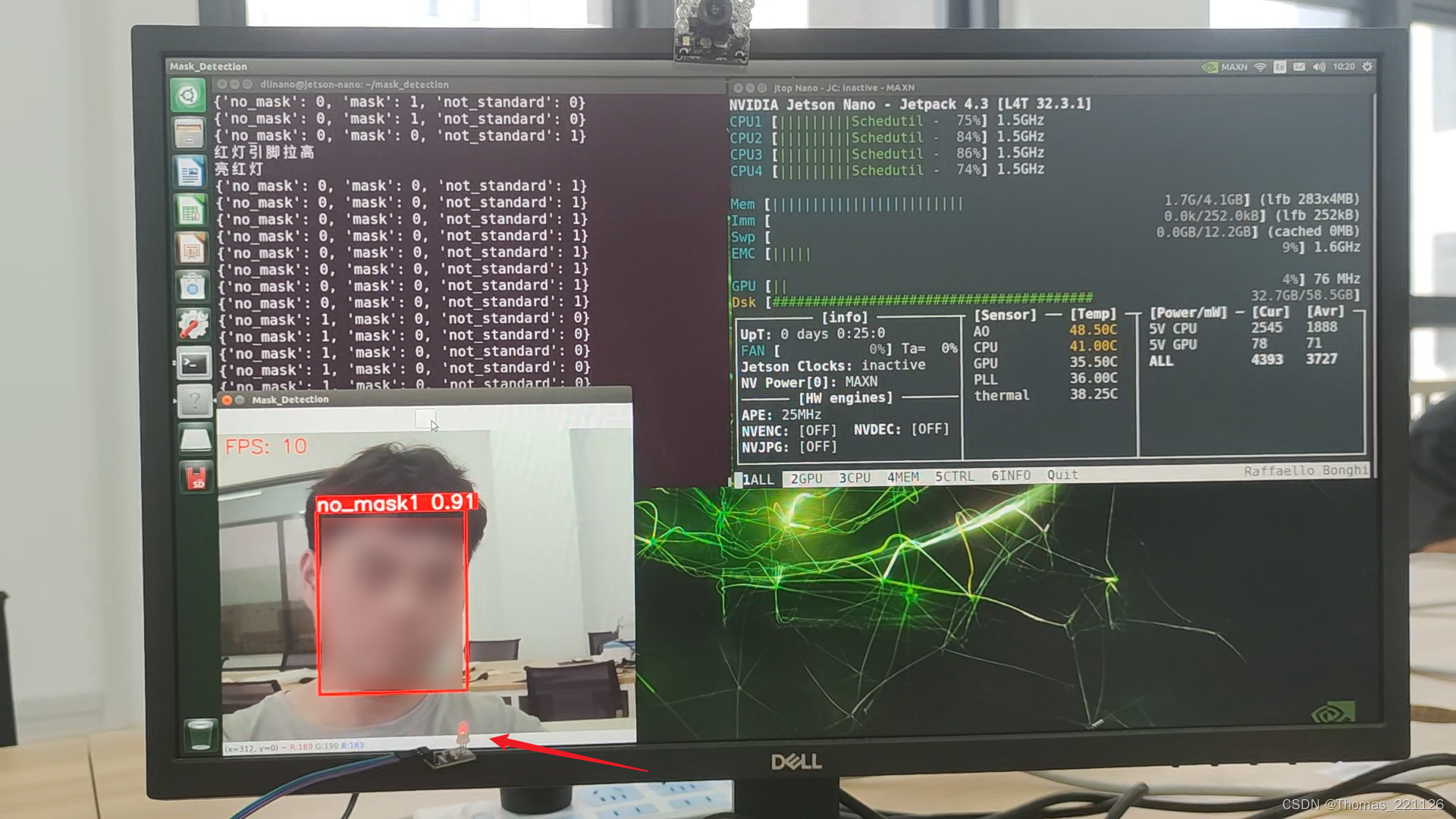
五、本文参考链接
1.保姆式yolov5教程,训练你自己的数据集 - 知乎 (zhihu.com)
2.【教程】标注工具Labelimg的安装与使用 - 知乎 (zhihu.com)
3.Aarch64 安装Anaconda 和 pytorch_无穷QQ君的博客-CSDN博客
4.GitHub - yqlbu/archiconda3: Light-weight Anaconda environment for ARM64 devices.















 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









