









本文使用yolov5模型实现对人脸是否佩戴口罩进行检测,检测结果的类别为两种情况,一是佩戴口罩,二是没有佩戴口罩。
先上模型训练后的测试结果:
第一种情况:没有佩戴口罩,标签简称为(no_mask)。

第二种情况:佩戴口罩,标签简称为(mask)。

一、目标检测简介
计算机视觉中有一项重要的任务为目标检测,与图像分类任务相比,图像分类任务仅仅把一张图片进行不同种类的分类(类别标签),而在目标检测是将输入的一张图片到网络模型中,不仅要进行分类,还要把分出的类别在图片中找到对应的位置(boundingBox)。基于深度模型的目标检测有很多,这里只介绍YOLO系列。
1.yolo系列的简介
yolo是一个one-stage单阶段的网络,他的精度虽然没有two-strage(Faster-rcnn,Mark-rcnn)两阶段的精度高,但是他最核心的优势是检测速度十分快,目前yolo系列从v3到v8,如果想了解更详细点的同学可以去网上查阅资料。
2.yolov5简介
yolov5网络结构主要可以分为以下三个部分,在backbone中先使用卷积进行特征的提取或代替maxpooling;在neck中使用了SPPF结构,改变了SPP原来的分开卷积操作变为进行连续卷积,在保证内容相同的同时,提高了模型的运行速度;在head中使用特征向上融合和向下融合相结合提高了精度。
二、环境安装及代码下载
这里就不重点讲解环境的搭建了,若没有搭建环境的同学,这里给出笔者前期的文章:
yolov5源码下载:github网址下载:mirrors / ultralytics / yolov5 · GitCode
这里给出我的运行环境:
操作系统:windows 11
GPU信息:NVIDIA GeForce RTX 4070 Ti
CUDA版本选择11.7
cuDNN版本-8.7.0.84
anaconda 2021 对应python 版本3.7
pytorch虚拟环境的python版本3.9.16
pytorch版本2.0.1+cu117
torchvision版本'0.15.2+cu117'
在conda虚拟环境搭建了yolov5项目的运行。
三、数据集的准备
1、下载数据集
如果你用自己的图片准备制作数据集,可以利用labelimg来制作。可以参考笔者的另外一篇博客:
本文就不手工制作数据集进行演示了,直接给出网上收集关于是否佩戴口罩的数据集,百度网盘链接 需要的评论区联系我。
下载后的数据集并且由我整理后的结构如下:
其中Annotations目录是参考voc数据集的格式,里面都是xml配置文件信息。
JPEGImages目录存放的是原图片,共7959张,分为两大类:一是没有佩戴口罩,二是佩戴口罩,下图是部分截图:


YOLOLabels目录是yolo格式下存放图片对应的标签信息,都是txt文件,表示的每张图片的类别以及标记框的位置和大小信息。

2、数据集的划分( 训练集和验证集)
将上面下载后的数据集进行划分训练集(80%)和验证集(20%),将数据集划分后的建议直接将数据集文件夹放在项目的根目录,如下:
数据集划分好后,建议检查下里面的训练集和验证集中的图片名称是否和标签要对应上。
这里直接给出笔者参考的数据集的格式转换(txt与xml格式的转换,即voc格式与yolo格式的转换),并且给出数据集划分的代码,参考博客
四、下载预训练模型
预训练权重是yolo官方提前根据一些数据集进行训练好的网络参数,这样我们可以借助已有的网络参数进一步进行微调,就可以缩短网络的训练时间,达到更好的精度。yolov5的版本目前更新了,也提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。给出yolov5预训练模型下载地址
本次训练的口罩数据集用的预训练权重为yolov5s.pt。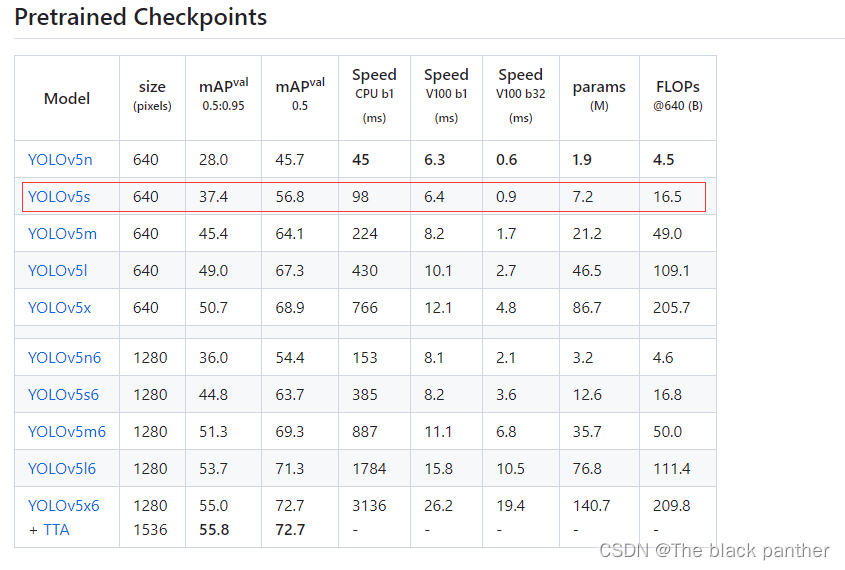
将下载的权重放到文件夹项目目录中。
至此:数据集和预训练模型就已经准备好了,接下来就可以准备开始训练自己的yolov5佩戴口罩检测模型了。
五、训练是否佩戴口罩检测模型
在开始训练前还需要对项目里的相关文件进行修改,一个是数据集配置文件,另一个是模型配置文件。
1、配置数据集文件
到yolov5原项目的data目录下复制一份数据集配置文件,如coco.yaml

将数据配置文件重命名,如“mask_noMask.yaml”(名称自己取),它是一个yolov5模型进行训练时加载的数据集配置文件。并将其里面的内容进行修改,大致内容参考如下:
path: ./mask_noMask train: images/train val: images/val #test: images/test # number of classes nc: 2 # class names names: ['no_mask','mask']
其中需要自己修改的内容为:
train与val后的地址,地址均指向训练图集的文件夹。以及names后的内容,nc类别数。
注意 :label不用配置,rain.py在训练过程中,会将路径中的images替换为 labels来寻找labels数据
并将数据配置文件放在自己定义的数据集目录中:如下
2、编辑models模型配置文件
在yolov5项目下进入models/目录,可以看到有四个模型配置的yaml文件:

表示训练时,你选中的yolov5的模型结构,这里根据自己的需求选择其中一个的模型,并将模型的配置文件yaml进行修改。
这些Model的yaml文件中都是模型网络相关配置参数,例如nc下面的depth_multiple是指网络的深度,width_multiple是网络的宽度, anchors是锚标(标出物体的方框),backbone既骨干网络。
我在这里选择了yolov5s.yaml文件进行复制一份,并修改了里面模型的nc(类别参数)为2(这里要和你提前训练时设定的类别数一直),以下为我自己编辑的模型配置文件部分截图:
并将文件重命名,自行将他放在一个位置处,我这为了方便,直接放在之前制作的数据集下的目录里,如下:
3、开始训练
前期的数据集准备好后,以及创建了数据集配置文件和模型配置文件,就可以在项目路径里的终端下执行下面的命令,开始训练了:
python train.py --data mask_noMask/mask_noMask.yaml --weights yolov5s.pt --epoch 100 --batch-size 32 --cfg mask_noMask/yolov5s_my.yaml
这里需要注意的是,终端的路径要执行到train.py文件的目录下,后面的几个参数,如 --data就是数据集的配置文件,--weights是你自己是否需要预训练模型(提前下载好),--epoch 100是迭代的次数, --cfg为模型的配置文件。总之,就是使用前期步骤的工作。
训练过程:

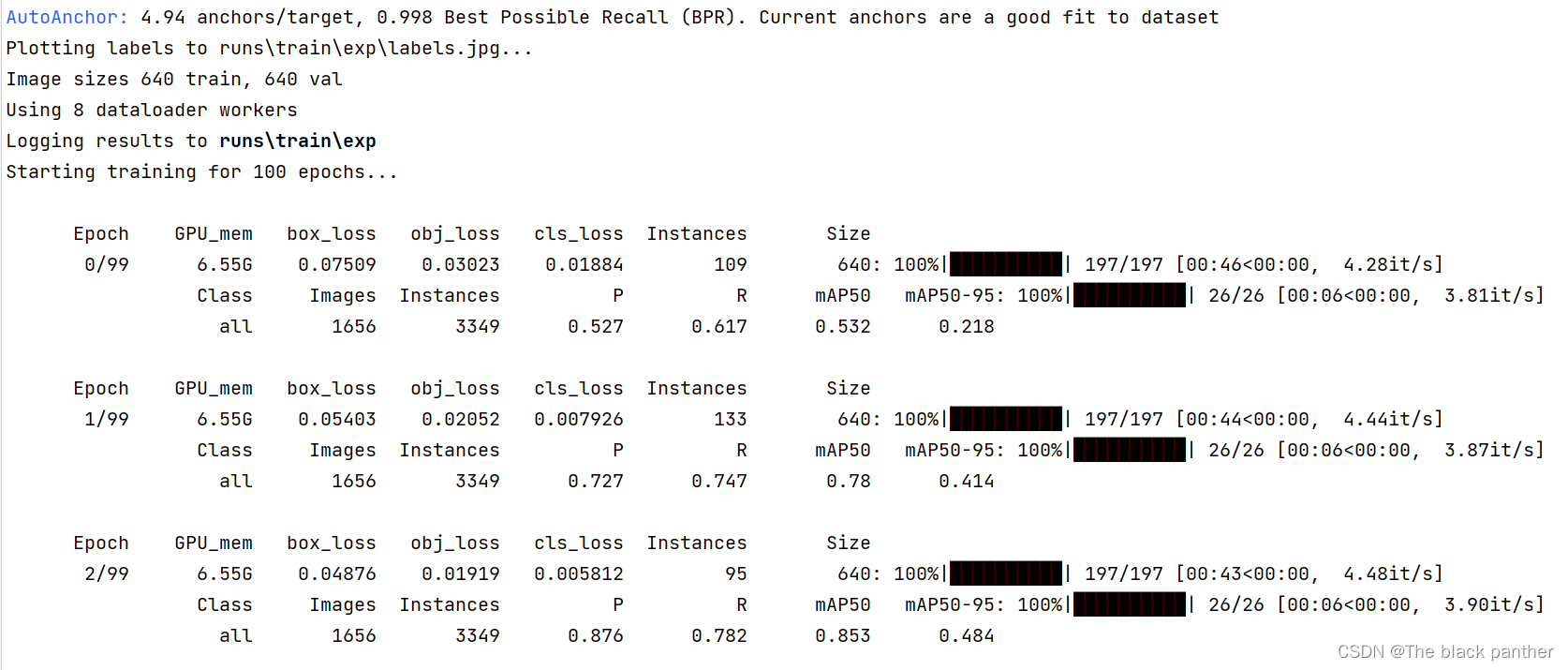 笔者训练了 6303张图片,迭代100次,大约花了一个半小时,训练后的结果如下:
笔者训练了 6303张图片,迭代100次,大约花了一个半小时,训练后的结果如下:
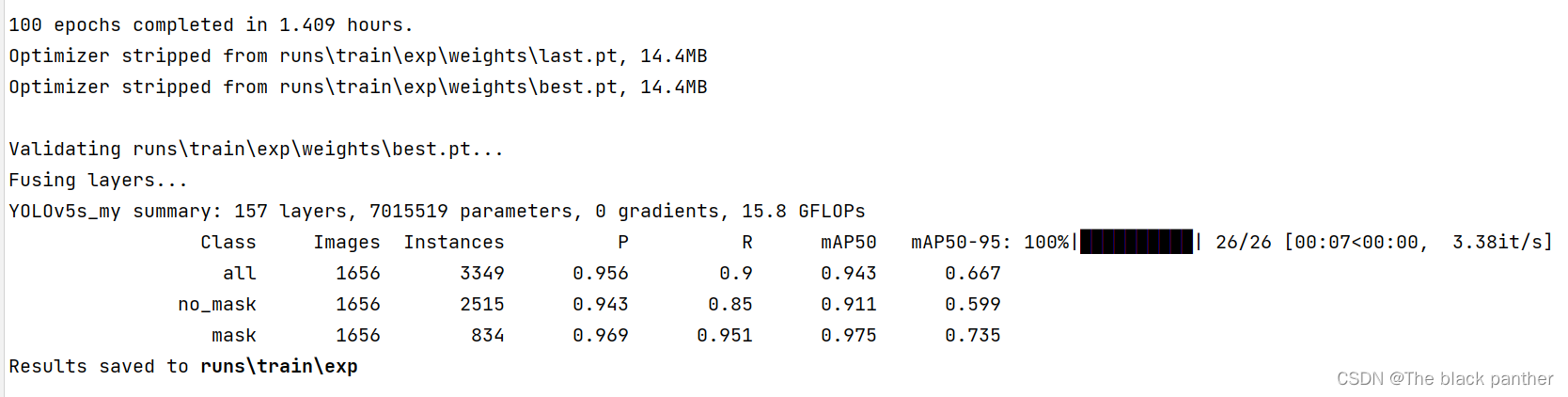
根据提示,到 runs\train\exp目录下找训练好的模型。目录/weights/last.pt和best.pt
其中还包括了PR Curve 曲线、Confusion matric (混淆矩阵)、results.png/txt 等训练过程数据,如下:
这里再补充下train.py文件里的常用参数及解释:
weights:权重文件路径,如果是’'则重头训练参数,如果不为空则做迁移学习,权重文件的模型需与cfg参数中的模型对应
epochs:指的就是训练过程中整个数据集将被迭代多少次
batch-size:每次梯度更新的批量数,指一次看完多少张图片才进行权重更新
config-thres: 模型目标检测的置信度阈值
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片的宽高
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
cache-images:缓存图像以加快训练速度
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
4、训练过程中的可视化:
我们可以在模型训练过程时,查看模型权重、损失、精确度、网络结构等的可视化,这里需要使用tensorboard工具进行可视化(需要提前安装)
在项目根路径执行:tensorboard --logdir runs\train
 并浏览器打开http://localhost:6006/
并浏览器打开http://localhost:6006/
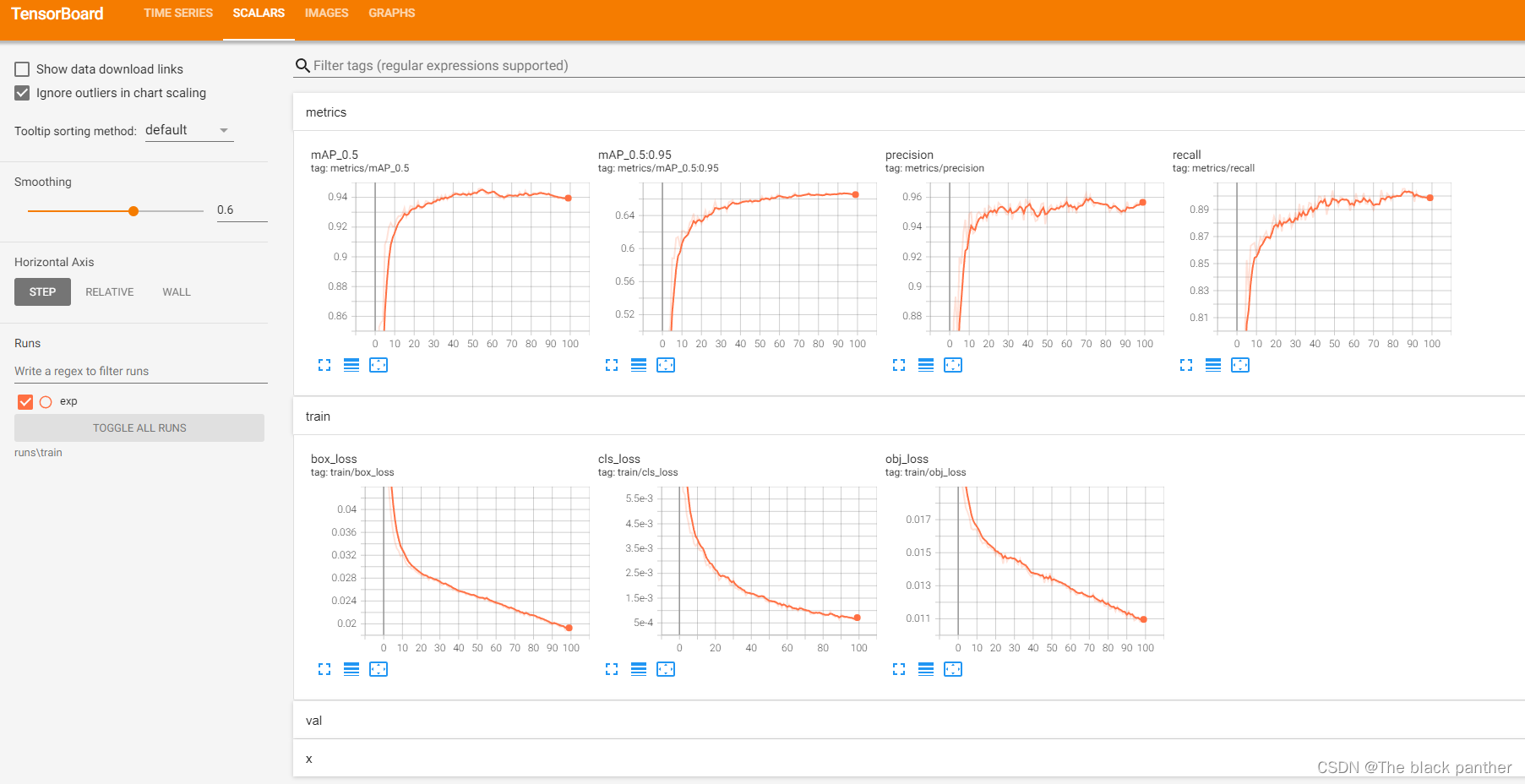
可以看出第一次训练的精确度达到95%左右。
5、 测试训练后的模型:
使用detect.py,weights使用新训练后的best.pt,测试图片可以拍一个新照片,或者找一个之前没有用到的图片,也可以是视频,也可以是事实摄像头,执行以下命令 :
注意,一些参数要换成自己的测试图片的路径,权重的路径等,最后,到run文件夹下查看测试结果。
(1)测试一张图片
python detect.py --weights runs/train/exp/weights/best.pt --source mask_noMask/images/val/test_00002501.jpg
结果展示:

(2)测试一个文件夹(里面放置多张图片或者视频):
python detect.py --weights runs/train/exp/weights/best.pt --source data/images/testfiles
结果展示
 (3)测试摄像头
(3)测试摄像头
python detect.py --weights runs/train/exp/weights/best.pt --source 0
执行上述代码,电脑的摄像头会启动并实时进行检测。 这里就不截结果图了。
以上就是使用yolov5模型实现对人脸是否佩戴口罩进行检测,大致总结下步骤:数据集笔者没有手工制作,是下载网上提供的图片,但是期间参考了一些博客对数据集进行转换和划分等,以及数据配置文件和模型配置文件的更换。只要环境搭建成功,换成一些特有的数据集,就可以去做一些验证算法了,并且可以进一步优化。
各位只要知道整体步骤即可,哪怕其中一个步骤就会踩很大一个坑,不要放弃,一步一步来。


















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











