






 文章提供了一个优化后的Python脚本,用于自动识别和抢夺原神和星穹铁道等米游社游戏的二维码登录码。脚本提升了二维码识别速度,简化了填写步骤,并加入了随机延迟功能以避免被检测为脚本。用户需自行获取米游社的stuid和stoken,以及了解基本的Python知识才能使用。
文章提供了一个优化后的Python脚本,用于自动识别和抢夺原神和星穹铁道等米游社游戏的二维码登录码。脚本提升了二维码识别速度,简化了填写步骤,并加入了随机延迟功能以避免被检测为脚本。用户需自行获取米游社的stuid和stoken,以及了解基本的Python知识才能使用。
在之前的文章中我有发布关于原神抢码的分析介绍,之前的文章
我发现有很多朋友不会分析和使用,无法重现我发布的抢码py文件的功能
最近米忽悠最新的星穹铁道上线又有很多朋友让我分析一下星穹铁道,是否能实现和原神一样的抢码效果呢?
那是肯定的啦(ps:在米游社不技术升级的情况下)只要是米游社内可以扫码的游戏应用都可以使用的未来即将上线的绝区零也是一样的。
其实实现的大体框架无需改动仅是请求方面需要改动替换一下的但还是有些朋友不会使用,
今天刚好有时间给你们优化和简洁一下步骤
新版本新功能
1.简化填写步骤
2.将原来的二维码识别速度翻倍(原来30帧现在可以达到60帧)速更快
3.将所有代码都写在一个py文件中 不再使用导入的方式来进行框框的显示
4.同时支持原神和星穹铁道的抢码
5.防止二维码刚抢到就确认登陆 被主播发现异常(被觉得是脚本在抢码)特此加入了随机延迟的功能来模拟为人手点击的延迟减少被主播
怀疑的可能性
现在的最新版仅需要
stuid和
stoken即,可步骤非常简单

stuid是米游社的uid并非是游戏内的uid请勿填写错误
至于stoken是怎么获取的呢,
1.抓包在米游社app内进行获取
2.有部分教程可以获取到stoken但是步骤些许复杂自己搜索一下即可找到办法
友情提示一下stoken权限等级极高请勿分享给他人
当前版本同时支持原神和星穹铁道
# 当前抢码游戏 原神=4,星穹铁道=8
GameType = 4
当前是原神想要切换星穹铁道的话把4改成8即可请勿改成这两个数以外的数字
原神效果演示
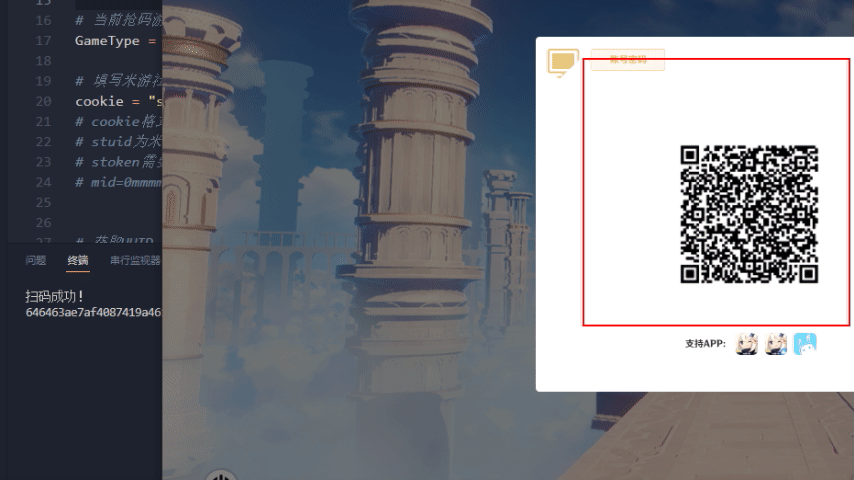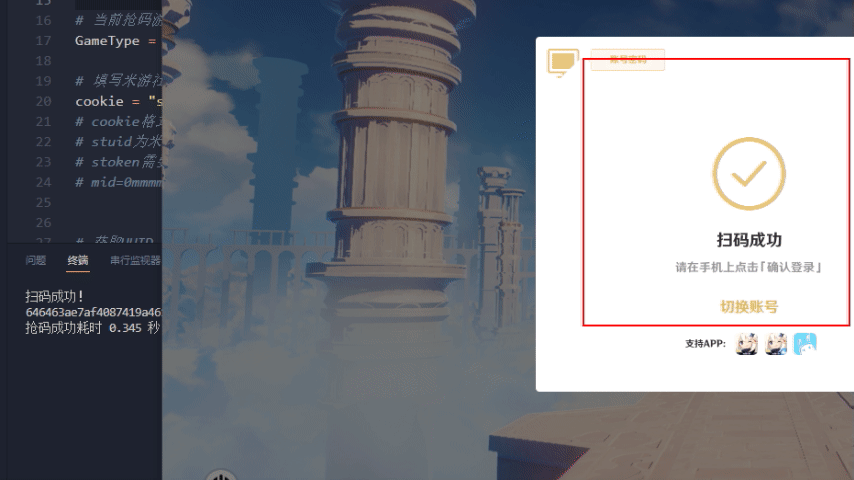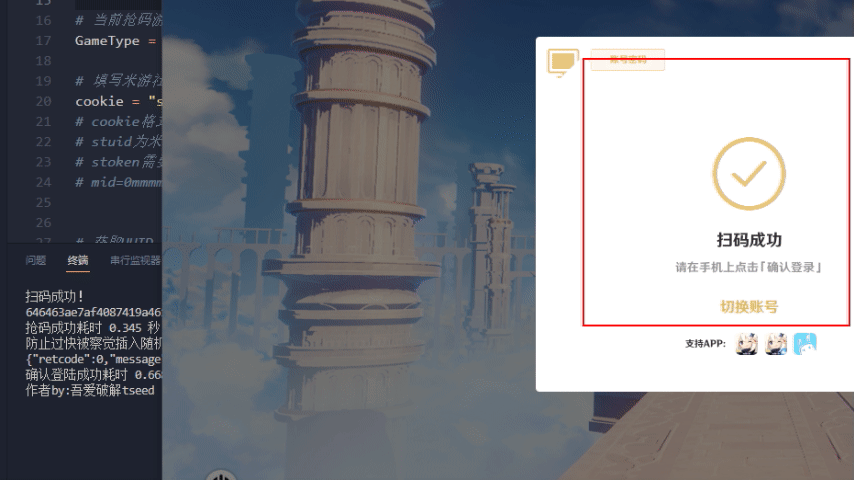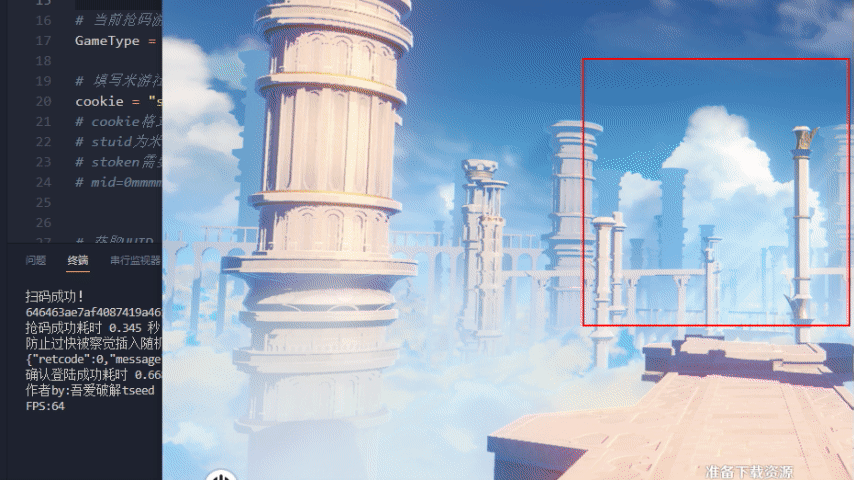
星穹铁道效果演示
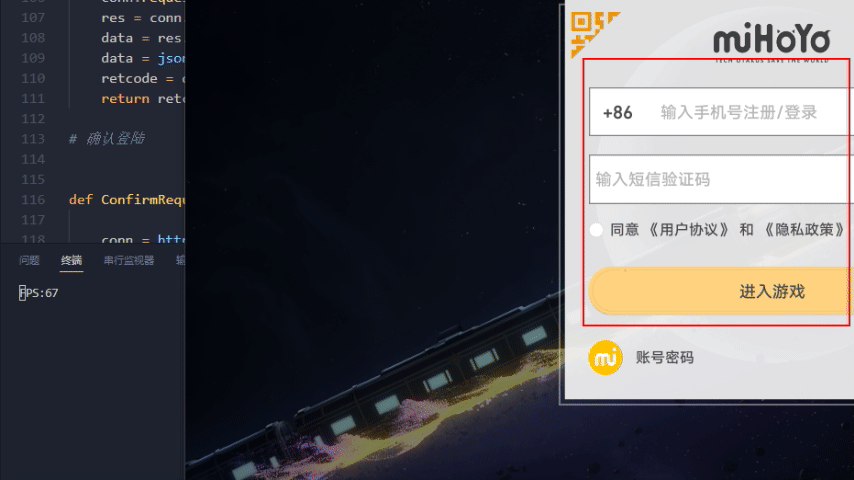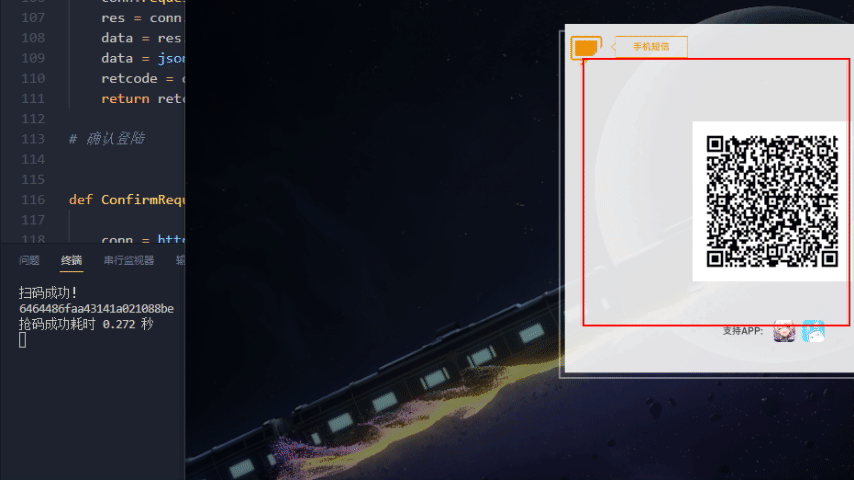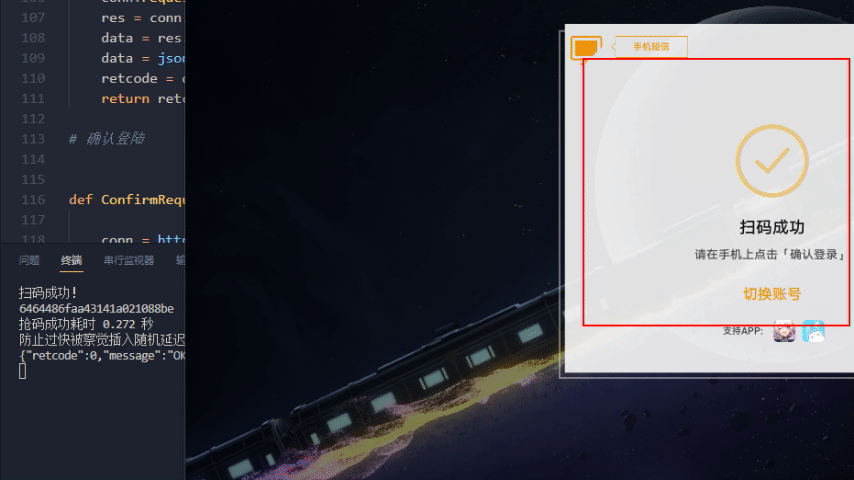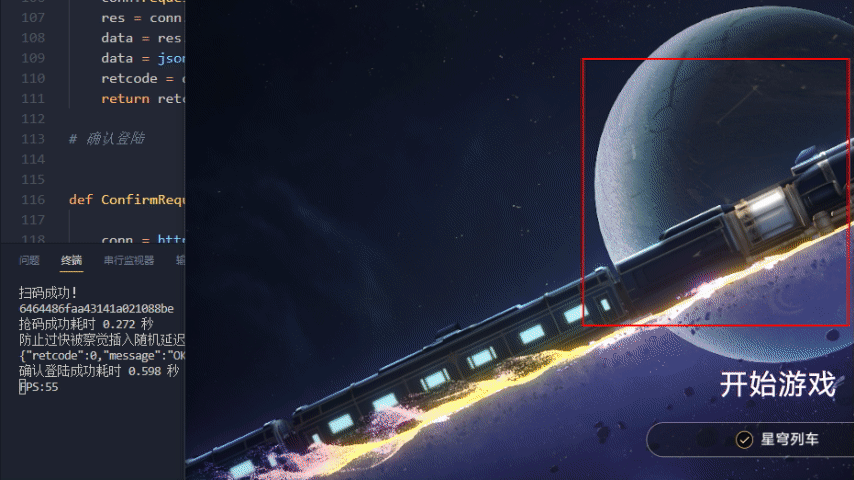
无法运行排除错误方式
1.请确保当前所有库文件抖已安装
2.确保py在3.8及以上(因为文本是在3.8的环境中写的更低版是否可用用自己尝试
3.确保cookie的完整性
使用此程序的最低标准是懂编程基础如果你连一点点py基础都不会,那还是建议你还是先去学习一下py的基础教程再来使用,不然总是问我一些基础都不懂的问题我也不能从py基础开始教你用吧
好了废话不多说了下面就是代码复制粘贴之你的py文件运行即可
import json
import time
import cv2
from pyzbar.pyzbar import decode
import pyzbar.pyzbar as pyzbar
import numpy as np
import tkinter as tk
import threading
import re
import http.client
import win32gui
import win32ui
import win32con
import uuid
# 当前抢码游戏 原神=4,星穹铁道=8
GameType = 4
# 填写米游社cookie
cookie = "stuid=;stoken=;mid=0mmmmato08_mhy;"
# cookie格式stuid=xxxxxxx;stoken=v2_xxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=;mid=0mmmmato08_mhy;
# stuid为米游社UID非游戏内UID
# stoken需要此参数
# mid=0mmmmato08_mhy需要此参数
# 填写米游社uid
uid=""
# uid为米游社UID非游戏内UID可以使用上方的stuid
# 获取UUID
def get_uuid():
get_timestamp_uuid = uuid.uuid1() # 根据时间戳生成uuid,保证全球唯一
return str(get_timestamp_uuid)
# 随机获取一个UUID来作为device
device = get_uuid()
# 显示框框
def my_function():
# 创建一个Tkinter窗口
root = tk.Tk()
# 隐藏窗口标题栏和边框
root.overrideredirect(True)
# 将窗口置顶
root.wm_attributes("-topmost", True)
# 设置窗口大小和位置
win_width = 300
win_height = 300
screen_width = root.winfo_screenwidth()
screen_height = root.winfo_screenheight()
x_pos = (screen_width // 2) - (win_width // 2)
y_pos = (screen_height // 2) - (win_height // 2)
root.geometry('{}x{}+{}+{}'.format(win_width, win_height, x_pos, y_pos))
# 将窗口背景设为透明
root.attributes('-transparentcolor', 'white')
# 将窗口的画布设为透明
canvas = tk.Canvas(root, bg='white', highlightthickness=0)
canvas.pack(fill='both', expand=True)
# 绘制一个红色空心正方形
canvas.create_rectangle(
5, 5, win_width-5, win_height-5, outline='red', width=2)
# 进入循环让窗口保持打开状态
root.mainloop()
# 启动线程
my_thread = threading.Thread(target=my_function)
my_thread.start()
# 设置扫描区域
width, height = 300, 300
# 获取屏幕尺寸
screen_width = tk.Tk().winfo_screenwidth()
screen_height = tk.Tk().winfo_screenheight()
# 计算识别区域左上角
left = (screen_width - width) // 2
top = (screen_height - height) // 2
# 计算识别区右下角
right = left + width
bottom = top + height
# 获取屏幕DC
hwnd = win32gui.GetDesktopWindow()
hdc = win32gui.GetWindowDC(hwnd)
dc = win32ui.CreateDCFromHandle(hdc)
def capture_screen():
saveDC = dc.CreateCompatibleDC()
# 创建位图对象
saveBitMap = win32ui.CreateBitmap()
saveBitMap.CreateCompatibleBitmap(dc, right-left, bottom-top)
# 将位图选入到DC中
saveDC.SelectObject(saveBitMap)
# 截屏并保存到位图中
saveDC.BitBlt((0, 0), (right-left, bottom-top),
dc, (left, top), win32con.SRCCOPY)
# 将位图对象转换为numpy数组并进行颜色空间转换
bmpinfo = saveBitMap.GetInfo()
bmpstr = saveBitMap.GetBitmapBits(True)
screenshot = np.frombuffer(bmpstr, dtype='uint8').reshape(
(bmpinfo['bmHeight'], bmpinfo['bmWidth'], 4))[:, :, :3]
screenshot = cv2.cvtColor(screenshot, cv2.COLOR_BGR2GRAY)
# 释放资源
saveDC.DeleteDC()
win32gui.DeleteObject(saveBitMap.GetHandle())
return screenshot
# 抢码开始
def Request(ticket):
conn = http.client.HTTPSConnection("api-sdk.mihoyo.com")
payload = json.dumps({
"app_id": GameType,
"device": device,
"ticket": ticket
})
headers = {}
if GameType == 4 :# 原神
conn.request("POST", "/hk4e_cn/combo/panda/qrcode/scan", payload, headers)
elif GameType == 8 :# 星穹铁道
conn.request("POST", "/hkrpg_cn/combo/panda/qrcode/scan", payload, headers)
res = conn.getresponse()
data = res.read()
data = json.loads(data.decode("utf-8"))
retcode = data["retcode"]
return retcode
# 确认登陆
def ConfirmRequest(ticket):
conn = http.client.HTTPSConnection("api-takumi.miyoushe.com")
payload = ''
headers = {
'cookie': cookie,
}
conn.request("GET", "/auth/api/getGameToken",
'', headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
data = json.loads(data.decode("utf-8"))
token = data["data"]["game_token"]
conn = http.client.HTTPSConnection("api-sdk.mihoyo.com")
payload = json.dumps({
"app_id": GameType,
"device": device,
"payload": {
"proto": "Account",
"raw": f"{{\"uid\":\"{uid}\",\"token\":\"{token}\"}}"
},
"ticket": ticket
})
headers = {
'cookie': cookie,
}
conn.request("POST", "/hk4e_cn/combo/panda/qrcode/confirm",
payload, headers)
res = conn.getresponse()
# data = res.read()
# print(data.decode("utf-8"))
# 记录FPS开始时间
frame_count = 0
frame_start_time = time.time()
while True:
# 截取指定区域的屏幕截图
# 将截图转换为灰度图像
screenshot = capture_screen()
# 尝试使用pyzbar库识别二维码
codes = decode(screenshot, symbols=[pyzbar.ZBarSymbol.QRCODE])
# 如果找到了二维码,输出其内容
if codes:
print("扫码成功!")
pattern = r"ticket=([a-f0-9]+)"
match = re.search(pattern, codes[0].data.decode())
# 正则请求地址
if match:
print(match.group(1))
# 进入抢码
start_time = time.time()
retcode = Request(match.group(1))
end_time = time.time()
if retcode == 0:
# 计算代码执行时间并输出
elapsed_time = end_time - start_time
print("抢码成功耗时 %.3f 秒" % elapsed_time)
random = 1.3
time.sleep(random)
print("防止过快被察觉插入随机延迟")
# 确认登陆
start_time = time.time()
ConfirmRequest(match.group(1))
end_time = time.time()
# 计算代码执行时间并输出
elapsed_time = end_time - start_time
print("确认登陆成功耗时 %.3f 秒" % elapsed_time)
# print("作者by:吾爱破解tseed")
# 等待一下
time.sleep(1)
else:
print("未知二维码抢码失败")
# 等待一下
time.sleep(1)
# 记录每秒帧数
frame_count += 1
if time.time() - frame_start_time >= 1:
fps = frame_count
print(f"FPS:{fps}" + "\r", end='', flush=True)
frame_count = 0
frame_start_time = time.time()
# 在窗口中显示截图
cv2.imshow("QR Code Scanner", screenshot)
# 检查是否按下了键盘上的任意键
if cv2.waitKey(1) != -1:
break
# 关闭窗口
cv2.destroyAllWindows()

















 2459
2459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









