






1.基于概率论的分类算法:朴素贝叶斯概述:
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
2.朴素贝叶斯 的优缺点:
优点:在数据比较少的情况下仍然有效,可以处理多类别问题。
缺点,对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
3.朴素贝叶斯 算法步骤:
1)收集数据:可以使用任何方法;
2)准备数据:需要数值型或布尔型数据。如果是文本文件,要解析成词条向量bai;
3)分析数据:有大量特征时,用直方图分析效果更好;
4)训练算法:计算不同的独立特征的条件概率;
5)测试算法:计算错误率;
6)使用算法:一个常见的朴素贝叶斯应用是文档分类。
4.贝叶斯定理
条件概率就是事件 A 在另外一个事件 B 已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在 B 发生的条件下 A 发生的概率”。
联合概率表示两个事件共同发生(数学概念上的交集)的概率。A 与 B 的联合概率表示为。
推导:
我们可以从条件概率的定义推导出贝叶斯定理。
根据条件概率的定义,在事件 B 发生的条件下事件 A 发生的概率为:
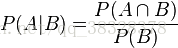
同样地,在事件 A 发生的条件下事件 B 发生的概率为:
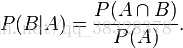
结合这两个方程式,我们可以得到:
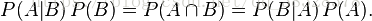
这个引理有时称作概率乘法规则。上式两边同除以 P(A),若P(A)是非零的,我们可以得到贝叶斯定理:
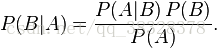
5.朴素贝叶斯分类器
首先要清楚朴素贝叶斯分类器是基于“属性条件独立性假设”,即所有属性相互独立,换句话说就是,假设每个属性独立的对分类结果产生影响。
显然,朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率 P(C),并为每个属性估计条件概率P(xi | c)。说到底,朴素贝叶斯分类器就是由先验概率和条件概率组成。
1、 先验概率
其中D表示的是总共有多少个样本,Dc表示的是整体样本中c类样本的数量;
2、条件概率
在该式中,Dc所代表的意思与先验概率相同,即整体样本中c类样本的数量;Dc,xi 表示的是在c类样本的数量中第i个属性取值为xi的样本数量,就比如说:(红)苹果中(脆)苹果的数量。
其中,µc,i 表示的是第c类样本在第i个属性上取值的均值;σc,i 表示的是第c类样本在第i个属性上取值的方差。
3. 极大似然估计
另D_{i}表示训练集D中第i类样本组成的集合,假设这些样本是独立分布同分布的,则参数 θcθc对于数据集D_{i}的似然是:
P(Di|θc)=∏x∈DiP(x|θc)
P(Di|θc)=∏x∈DiP(x|θc)
对 θcθc进行极大似然估计,就是寻找能最大化似然 P(Di|θc)P(Di|θc)的参数值 θc^θc^,连乘操作容易造成下溢,因此一般取对数。
3. 朴素贝叶斯
其基本假设是条件独立性,即
P(A=a|B=Bi)=P(A1=a1,…An=an|B=Bi)=∏nj=1P(Aj=aj|B=Bi)P(A=a|B=Bi)=P(A1=a1,…An=an|B=Bi)=∏j=1nP(Aj=aj|B=Bi)
4. 拉普拉斯平滑
防止分子相乘项出现0导致整体为0,常采用拉普拉斯平滑进行修正,修正后的公式如下:
P(Bi)^=Bi+1B+N
P(Bi)^=Bi+1B+N
其中N表示训练集B中可能的类别数
P(Ai|B)^=Bi,Ai+1Bi+Ni
P(Ai|B)^=Bi,Ai+1Bi+Ni
其中Ni表示第i个属性可能出现的取值数
6.实现垃圾邮件过滤
(1)收集数据:提供文本文件。
(2)准备数据:将文本文件解析成词条向量。
(3)分析数据:检查词条确保解析的正确性。
(4)训练算法:计算不同的独立特征的条件概率。
(5)测试算法:计算错误率。
(6)使用算法:构建一个完整的程序对一组文档进行分类
从文本构建词向量:
第一个函数 loadDataSet() 创建了一些实验样本。该函数返回的第一个变量是进行词条切分后的文档集合,返回的第二个变量是一个类别标签的集合。函数createVocabList()会创建一个包含在所有文档中出现的不重复词的列表,为此使用set 数据类型。将词条列表输给set构造函数,set就会返回一个不重复词表。使用函数setOfWords2Vec(),该函数的输人参数为词汇表及某个文档,输出的是文档向量,向量的每一元素为1或0,分别表示词汇表中的单词在输人文档中是否出现。函数首先创建一个和词汇表等长的向量,并将其元素都设置为0 。接着,遍历文档中的所有词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1。
# 函数loadDataSet() 创建了一些实验样本。该函数返回的第一个变量是进行词条切分后的文档集合,第二个变量为自定义的类别
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
return postingList, classVec
# 创建不重复词库列表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空集
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集
return list(vocabSet)
# 输出文档向量
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList) #创建一个元素都为0的向量
#遍历数据集单词
for word in inputSet:
#存在单词在词袋中则
if word in vocabList:
#index用于找到第一个与之匹配的下标
returnVec[vocabList.index(word)] = 1
else:
print ("the word: %s is not in my Vocabulary!" % word)
return returnVec
dataSet,classVec = loadDataSet()
vocabset = createVocabList(dataSet)
print(vocabset)
returnVec = setOfWords2Vec(vocabset,dataSet[0])
print(returnVec)
结果:

训练算法:从词向量计算概率:
接下来运用上面介绍的朴素贝叶斯公式计算概率:

# 函数loadDataSet() 创建了一些实验样本。该函数返回的第一个变量是进行词条切分后的文档集合,第二个变量为自定义的类别
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
return postingList, classVec
# 创建不重复词库列表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空集
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集
return list(vocabSet)
# 输出文档向量
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList) #创建一个元素都为0的向量
#遍历数据集单词
for word in inputSet:
#存在单词在词袋中则
if word in vocabList:
#index用于找到第一个与之匹配的下标
returnVec[vocabList.index(word)] = 1
else:
print ("the word: %s is not in my Vocabulary!" % word)
return returnVec
# 训练算法,求概率
"""
该函数的伪代码如下:
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现文档中―增加该词条的计数值
增加所有词条的计数值
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到条件概率
返回每个类别的条件概率
"""
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
# 初始化概率
p0Num = zeros(numWords); p1Num = zeros(numWords)
p0Denom = 0.0; p1Denom = 0.0
# 遍历文档,向量相加
for i in range(numTrainDocs):
if trainCategory[i] == 1: # 侮辱类文档,向量相加
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: # 非侮辱类文档向量相加
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom # 各个单词在侮辱类中出现的概率
p0Vect = p0Num/p0Denom # 各个单词在非侮辱类中出现的概率
return p0Vect,p1Vect,pAbusive
dataSet, classVec = loadDataSet()
vocabset = createVocabList(dataSet)
trainMat = []
for postinDoc in dataSet:
trainMat.append(setOfWords2Vec(vocabset,postinDoc))
p0Vect, p1Vect, pAbusive = trainNB0(trainMat,classVec)
print(p0Vect) # 非侮辱类词向量概率
print(p1Vect) # 侮辱类词向量概率
print(pAbusive) #侮辱性文档的概率
结果:

3.测试算法
利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算P(b1|A)(b2|A)(b3|A)…(bn|A) 。如果其中一个概率值为0 ,那么最后的乘积也为0。
为降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。
p0Num = ones(numWords); p1Num = ones(numWords)
p0Denom = 2.0; p1Denom = 2.0另一个问题时下溢出,这是由于太多很小的数相乘造成的
所以,在实际中对概率取对数的形式,可以防止相乘是溢出。
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
from numpy import *
# 函数loadDataSet() 创建了一些实验样本。该函数返回的第一个变量是进行词条切分后的文档集合,第二个变量为自定义的类别
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
return postingList, classVec
# 创建不重复词库列表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空集
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集
return list(vocabSet)
# 输出文档向量
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList) #创建一个元素都为0的向量
#遍历数据集单词
for word in inputSet:
#存在单词在词袋中则
if word in vocabList:
#index用于找到第一个与之匹配的下标
returnVec[vocabList.index(word)] = 1
else:
print ("the word: %s is not in my Vocabulary!" % word)
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = zeros(numWords); p1Num = zeros(numWords)
p0Denom = 0.0; p1Denom = 0.0
# 遍历文档,向量相加
for i in range(numTrainDocs):
if trainCategory[i] == 1: # 侮辱类文档,向量相加
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: # 非侮辱类文档向量相加
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom # 各个单词在侮辱类中出现的概率
p0Vect = p0Num/p0Denom # 各个单词在非侮辱类中出现的概率
return p0Vect,p1Vect,pAbusive
# 测试算法
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
#计算abusive的概率
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
#计算not abusive概率
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
#看哪个概率大
if p1 > p0:
return 1
else:
return 0
def testingNB():
# test_list=[]; test_class=[0,1]
#加载数据集
listOPosts,listClasses = loadDataSet()
#创建词汇袋
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testingNB()
结果:

4.实现垃圾邮件分类:
from numpy import *
#统计列表中所有不重复的单词,词汇袋
def createVocabList(dataSet):
#定义词汇集
vocabSet = set([]) #set集合为不会有重复词的集合
#遍历数据集
for document in dataSet:
#把每个文档合并到词汇袋中
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
# 训练算法
def trainNB0(trainMatrix,trainCategory):
#计算文档的数目
numTrainDocs = len(trainMatrix)
#计算词袋单词的数目
numWords = len(trainMatrix[0])
#计算类别的概率 abusive的文档站文档总数的百分比
pAbusive = sum(trainCategory)/float(numTrainDocs)
#初始化计数器,1行*numWords列
#p0是not abusive p1是abusive
#为什么是不是0矩阵?
#因为如果是0的话,按照贝叶斯公式,p(W0|1)*p(W1|1)
#如果任意概率为0则全为0所以初始值为1
#同时下面分母初始化2
p0Num = ones(numWords); p1Num = ones(numWords)
#初始化分母
p0Denom = 2.0; p1Denom = 2.0
#遍历数据集中每个文档
for i in range(numTrainDocs):
#如果这文档是abusive类的计算它的abusive比例
if trainCategory[i] == 1:
#储存每个词在abusive下出现次数
p1Num += trainMatrix[i]
#储存abusive词的总数目
p1Denom += sum(trainMatrix[i])
else:
#储存每个词在not abusive的出现次数
p0Num += trainMatrix[i]
#储存not abusive词的总数目
p0Denom += sum(trainMatrix[i])
#使用log是为了防止数据向下溢出
# 计算abusive下每个词出现的概率
p1Vect = log(p1Num/p1Denom) #change to log()各个单词在侮辱类中出现的概率
# 计算not abusive下每个词出现的概率
p0Vect = log(p0Num/p0Denom) #change to log()各个单词在非侮辱类中出现的概率
#返回词出现的概率和文档为abusice的概率
return p0Vect,p1Vect,pAbusive
#贝叶斯分类
#第一个参数是要被训练的向量
#后面三个参数是根据上面一个函数处理训练样本后得到的参数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
#计算abusive的概率
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
#计算not abusive概率
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
#看哪个概率大
if p1 > p0:
return 1
else:
return 0
#计算文档单词在某个词袋中出现的次数
# 把单词转换成向量,用对比已经有得词袋,计算词出现的次数
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
# 输入字符串,输出单词列表
def textParse(bigString):
import re
listOfTokens = re.split(r'\W+', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
def spamTest():
# 定义docList文档列表,classList类别列表,fullText所有文档词汇
docList=[]; classList = []; fullText =[]
#遍历文件夹内文件
for i in range(1,26):
# 定义并读取垃圾邮件文件的词汇分割列表
wordList = textParse(open('D:\\email/spam/%d.txt' % i).read())
# 将词汇列表加到文档列表中
docList.append(wordList)
# 将所有词汇列表汇总到fullText中
fullText.extend(wordList)
# 文档类别为1,spam
classList.append(1)
# 读取非垃圾邮件的文档
wordList = textParse(open('D:\\email/ham/%d.txt' % i).read())
# 添加到文档列表中,注意append和extend的区别,append直接加列表,extend加元素
docList.append(wordList)
# 添加到所有词汇列表中
fullText.extend(wordList)
# 类别为0,非垃圾邮件
classList.append(0)
# 创建词汇列表
vocabList = createVocabList(docList)
# 定义训练集的索引和测试集
trainingSet = list(range(50)); testSet=[]
# 随机的选择10个作为测试集
for i in range(10):
#随机索引
randIndex = int(random.uniform(0,len(trainingSet)))
#将随机选择的文档加入测试集
testSet.append(trainingSet[randIndex])
#从训练集中删除随机选择的文档
del(trainingSet[randIndex])
#定义训练集的矩阵和类别
trainMat=[]; trainClasses = [];
# test_list=[];test_class=[]
#遍历训练集,求先验概率和条件概率
for docIndex in trainingSet:
#将词汇列表变成向量放到trainList中
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
#添加训练集的类标签
trainClasses.append(classList[docIndex])
#计算先验概率,条件概率
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
#对测试集分类
for docIndex in testSet: #classify the remaining items
#将测试集向量化
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) #bagOfWords2VecMN函数将词汇向量化和计算次数 setOfWords2Vec将词汇向量化
# 对测试数据进行分类
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
#错误的话错误计数加一
errorCount += 1
print( "classification error",docList[docIndex])
print ('the error rate is: ',float(errorCount)/len(testSet))
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
return vocabList,fullText
spamTest()
结果:
本文章参考《机器学习实战》--Peter Harrington














 2332
2332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









